
什么是Apache Spark
Apache Spark 是一个闪电般的开源数据处理引擎,用于机器学习和人工智能应用程序,由最大的大数据开源社区提供支持。
什么是Apache Spark?
Apache Spark(Spark)是一个用于大型数据集的开源数据处理引擎。它旨在提供大数据所需的计算速度、可扩展性和可编程性,特别是流数据、图形数据、机器学习和人工智能 (AI) 应用程序。
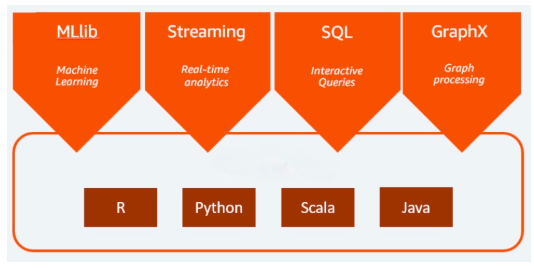
Spark 的分析引擎处理数据的速度比其他产品快 10 到 100 倍。它通过在大型计算机群集之间分配处理工作来扩展,并具有内置的并行性和容错功能。它甚至包括数据分析师和数据科学家中流行的编程语言API,包括Scala,Java,Python和R。
在大数据行业,大家经常拿Spark与Apache Hadoop进行比较,特别是Hadoop的原生数据处理组件MapReduce。Spark和MapReduce之间的主要区别在于,Spark处理数据并将其保存在内存中以供后续步骤使用,而无需写入或读取磁盘,从而大大加快了处理速度。
Spark于2009年在加州大学伯克利分校开发。今天,它由Apache软件基金会维护,并拥有最大的大数据开源社区,拥有超过1000名贡献者。它还被列为几个商业大数据产品的核心组件。
Apache Spark 的工作原理
Apache Spark采用分层的主/从架构。Spark 驱动程序是控制集群管理器的主节点,它管理工作器(从属)节点并将数据结果传送到应用程序客户端。以下是Apache Spark架构
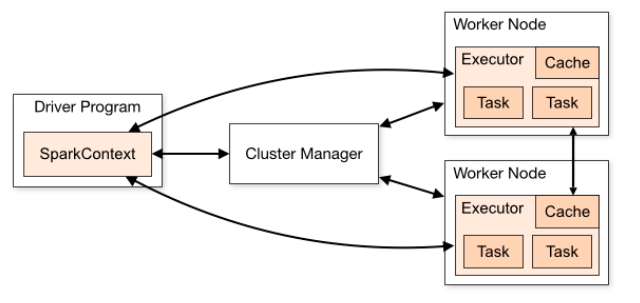
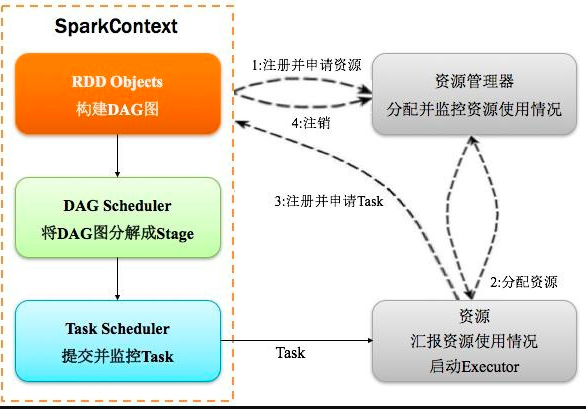
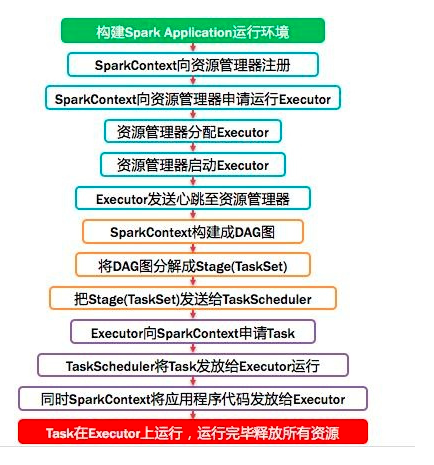
基于应用程序代码,Spark Driver 生成SparkContext,它与集群管理器(Spark 的独立集群管理器或其他集群管理器(如 Hadoop YARN、Kubernetes 或 Mesos))一起工作,并执行跨节点分发和监控。它还创建了弹性分布式数据集(RDD),这是Spark卓越处理速度的关键所在。
弹性分布式数据集 (RDD)
弹性分布式数据集 (RDD) 是元素的容错集合,可以分布在群集中的多个节点之间并并行处理。RDD是Apache Spark中的基本结构。
Spark 通过引用数据源或使用 SparkContext 并行化方法将现有集合并行化到 RDD 中进行处理。当数据加载到 RDD 后,Spark 会对内存中的 RDD 执行转换和操作,这是 Spark 速度的关键。Spark 还会将数据存储在内存中,除非系统内存不足或用户决定将数据写入磁盘以实现持久化目的。
RDD 中的每个数据集都分为逻辑分区,这些逻辑分区可以在集群的不同节点上进行计算。而且,用户可以执行两种类型的RDD操作:转换和操作。转换是应用于创建新 RDD 的操作。操作用于指示 Apache Spark 应用计算并将结果传递回驱动程序。
Spark支持RDD上的各种操作和转换。此分发由 Spark 完成,因此用户不必担心计算正确的分发。
有向无环图 (DAG)
与MapReduce中的两阶段执行过程相反,Spark创建了一个有向无环图(DAG)来调度任务和跨集群的工作节点编排。当 Spark 在任务执行过程中执行和转换数据时,DAG 计划程序通过编排群集中的工作器节点来提高效率。并对任务进行跟踪,以使容错成为可能,因为它将记录的操作并重新应用于先前状态中的数据。
数据帧和数据集
除了RDD之外,Spark还处理另外两种数据类型:DataFrames和Datasets。
数据帧是最常见的结构化应用程序编程接口 (API),表示包含行和列的数据表。尽管RDD一直是Spark的关键功能,但它现在处于维护模式。由于Spark的机器学习库(MLlib)的普及,DataFrames作为MLlib的主要API占据了主导地位。在使用MLlib API时,这一点很重要,因为DataFrames提供了不同语言(如Scala,Java,Python和R)的一致性。
数据集是数据帧的扩展,提供类型安全、面向对象的编程接口。默认情况下,数据集是强类型 JVM 对象的集合,与数据帧不同。
Spark SQL允许从DataFrames和SQL数据存储(如Apache Hive)查询数据。Spark SQL 查询在另一种语言中运行时返回数据帧或数据集。
Spark核心
Spark Core 是所有并行数据处理的基础,可处理调度、优化、RDD 和数据抽象。Spark Core 为 Spark 库、Spark SQL、Spark Streaming、MLlib 机器学习库和 GraphX 图形数据处理提供了功能基础。Spark 核心和集群管理器在 Spark 集群中分发数据并将其抽象化。这种分布和抽象使得处理大数据非常快速和用户友好。
Spark接口
Spark 包括各种应用程序编程接口 (API),可将 Spark 的强大功能带给最广泛的受众。Spark SQL允许以关系方式与RDD数据进行交互。Spark还有一个记录良好的API,用于Scala,Java,Python和R。Spark 中的每种语言 API 在处理数据的方式上都有其特定的细微差别。RDD、数据帧和数据集在每种语言 API 中都可用。通过针对如此多语言的 API,Spark 使具有开发、数据科学和统计背景的更多不同人群可以访问大数据处理。
Apache Spark 和机器学习
Spark 具有各种各样的库,可将功能扩展到机器学习、人工智能 (AI) 和流处理。
Apache Spark MLlib
Apache Spark的关键功能之一是Spark MLlib中可用的机器学习功能。Apache Spark MLlib 提供了一个开箱即用的解决方案,用于执行分类和回归、协同过滤、聚类、分布式线性代数、决策树、随机森林、梯度提升树、频繁模式挖掘、评估指标和统计。MLlib的功能与Spark可以处理的各种数据类型相结合,使Apache Spark成为不可或缺的大数据工具。
Spark GraphX
除了具有API功能外,Spark还具有Spark GraphX,这是Spark的新功能,旨在解决图形问题。GraphX 是一种图抽象,它扩展了图和图并行计算的 RDD。Spark GraphX与存储互连信息或连接信息网络的图形数据库集成,例如社交网络。
Spark Streaming
Spark Streaming 是核心 Spark API 的扩展,可实现实时数据流的可扩展容错处理。当Spark Streaming处理数据时,它可以将数据传送到文件系统,数据库和实时仪表板,以便使用Spark的机器学习和图形处理算法进行实时流分析。Spark Streaming 基于 Spark SQL 引擎构建,还允许增量批处理,从而更快地处理流数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号