
正则表达式匹配流程解析
1. 编译阶段
正则表达式会被编译成 确定性有限自动机(DFA) 或 非确定性有限自动机(NFA),不同引擎实现不同。
JavaScript 使用 回溯型 NFA 引擎(特点:支持复杂语法,但可能效率低)。
示例:
const regex = /a+b/; // 编译为内部状态机
2. 匹配过程
2.1 字符匹配
"cab".match(/ab/); // 匹配成功:从索引1开始匹配 'ab'
-
引擎从字符串起始位置逐个尝试匹配
-
失败则前进到下一位置重新尝试
2.2 量词处理
-
贪婪模式:尽可能多匹配(回溯风险高)
-
非贪婪模式(加
?):尽可能少匹配
2.3 回溯机制
当路径匹配失败时,引擎回退到最近决策点尝试其他分支:
// 正则表达式:/.*abc/ const str = "xyzabc123abc";
// 匹配过程:
1. .* 吞并整个字符串
2. 无法匹配 'abc' → 回溯到最后一个字符
3. 逐步释放字符,直到找到 'abc'
.test() 方法深度解析
1. 基础行为
const regex = /\d{3}/; console.log(regex.test("abc123")); // true
-
仅检查是否存在匹配
-
不返回匹配内容
-
不修改原始字符串
2. 全局标志 (g) 的影响
const regex = /a/g; const str = "abcabc"; console.log(regex.test(str)); // true (索引0) console.log(regex.lastIndex); // 1 console.log(regex.test(str)); // true (索引3) console.log(regex.lastIndex); // 4 console.log(regex.test(str)); // false console.log(regex.lastIndex); // 0 (自动重置)
-
lastIndex属性 跟踪匹配位置 -
多次调用时状态保留
-
匹配失败后重置为 0
性能优化建议
1. 避免灾难性回溯
// 危险写法:嵌套量词 /(a+)+b/.test("aaaaaaaaac"); // 指数级回溯 // 优化方案: /a+b/.test("aaaaaaaaac"); // 线性复杂度
2. 预编译正则
// 低效:每次创建新正则 function check(str) { return /\d{5}/.test(str); } // 高效:复用编译好的正则 const zipRegex = /\d{5}/; function checkOptimized(str) { return zipRegex.test(str); }
3. 使用锚定符加速
// 未锚定:全字符串搜索 /^\d+$/.test("12345"); // 严格检查全数字 // 等效但更高效: function isAllDigits(str) { return /^\d+$/.test(str); }
.test() 与 .exec() 对比
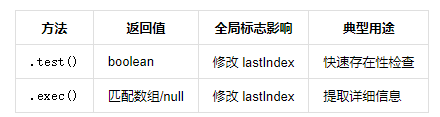
const regex = /(\d{4})-(\d{2})/g; const str = "2023-01 2024-02"; while ((match = regex.exec(str)) { console.log(`Year: ${match[1]}, Month: ${match[2]}`); } // Output: // Year: 2023, Month: 01 // Year: 2024, Month: 02
常见误区
1. 错误使用全局标志
const regex = /a/g; // 第一次测试 console.log(regex.test("abc")); // true // 第二次测试不同字符串 console.log(regex.test("aaa")); // false(因为 lastIndex=1)
2. 忽略 Unicode 特性
// 错误匹配 emoji /^.$/.test("👽"); // false(普通 . 无法匹配代理对) // 正确方式: /^.$/u.test("👽"); // true(使用 unicode 标志)
最佳实践总结
-
简单检查用
.test():需要快速判断是否存在匹配时使用 -
避免滥用全局标志:除非需要迭代匹配
-
注意性能陷阱:复杂正则需进行压力测试
-
优先使用字面量:
/pattern/比new RegExp更高效 -
必要时使用现代 API:如
String.prototype.includes()代替简单字符串检查
作者关于此主题其他文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号