2025.7.31学习日记【正在补充中...】
1.内网穿透
好像内网穿透后,访问外部网站的速度会加快
2.模拟测试
【经验1】:模拟测试的时候要使用需要梯度的操作来生成输出,例如Conv2,Linear等nn.module,不要使用torch.rand()去生成,不然更新参数的时候会报错
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
【经验2】:init.py文件的作用,将文件夹注册成python包,有暴露接口和简化导入的作用,例如在segment-anything中,有如下py文件,automatic_mask_gennerator.py,build_sam.py,predictor.py如果不注册成python包的话,就需要一级一级导入,注册成python包,由init.py直接暴露接口,简化导入路径
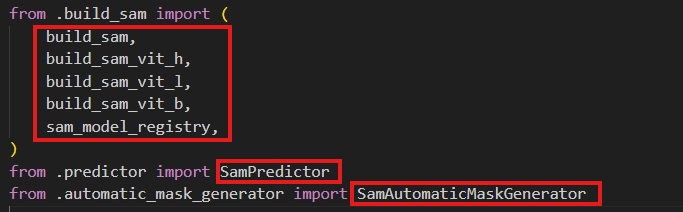
# 未注册成python包
from segment_anything.build_sam import sam_model_registry
# 注册成python包,并暴露相应接口
from segment_anything import sam_model_registry
【经验3】:你可以将已经注册成python包的文件夹中导入类后,然后再注册成python包,可以做到跨文件夹导入类例如图片中modeling和models已经被我注册成包,暴露了两个类的接口,然后我继续将project/models注册成包,而后将暴露的两个类导入

最后再将project/models/下的模块导入,并使用__all__关键字来暴露需要导入的类
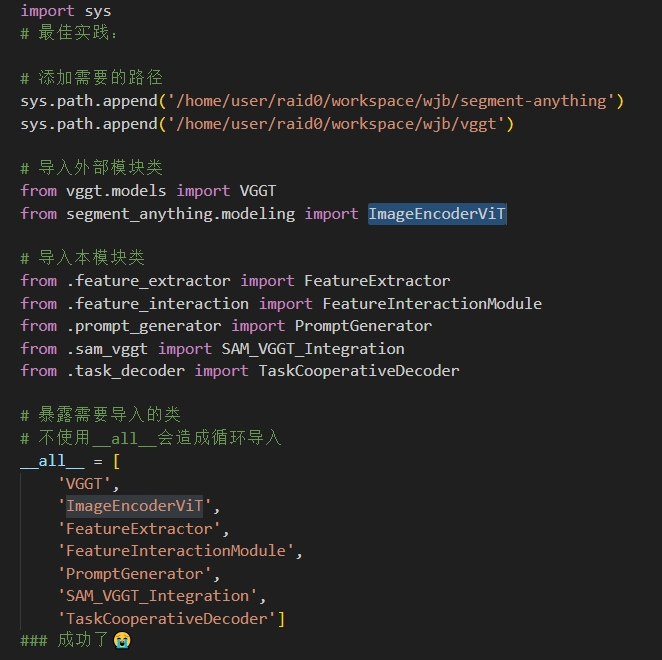
【经验4】:Transformer的输出格式一般为[B,H,W,C]格式,一般需要经过维度重排,使用x.permute(0,3,1,2)重排输出为[B,C,H,W]
2.1 Feature_extractor模块
该模块主要用于集成模型中的第一个过程,即获取两个预训练模型的特征,结果如下

- VGGT特征详解
VGGT3D点云特征其实是一种密集的,像素级别的特征,每张图都会带像素级别的点云特征, - SAM特征详解
SAM的ImageEncoderViT对于单张图像,保留批次,重构成特征图
【经验1】:端到端的模型的forward推理,一般输入为列表嵌套字典List[Dict[str,Any]]其中str表示键类型为文字,Any表示值类型为任意,最后返回也为列表嵌套字典List[Dict[str,torch.Tensor]],列表内部表示键值类型
【经验2】:一般以元素为张量的列表输入时,在进行处理时一般认为列表的长度为批次大小,并使用torch.stack([preprocess(item) for item in batch_input],dim=0)预处理item并在批次维度上进行堆叠
【经验3】:图像归一化主要先定义像素的均值和标准差,创建如下两个张量,并从[1,3]重塑为[3,1,1],方便之后的自动广播机制,此外这些数值通常来自大规模数据集(如ImageNet)的统计结果,用于将图像像素值标准化到接近零均值和单位方差。
pixel_mean = torch.tensor([123.675, 116.28, 103.53]).view(-1,1,1)
pixel_mean = torch.tensor([123.675, 116.28, 103.53]).view(-1,1,1)
- 图像归一化注意:
图像归一化时由于均值和方差为固定统计量,不需要梯度,最佳实践是先将统计量注册为buffer(var_name,tensor)
self.register_buffer('pixel_mean', torch.Tensor[...]) # 推荐方式
self.register_buffer('pixel_std', torch.Tensor[...])
- 自动广播机制:numpy也有这个自动广播机制,一下是自动广播机制的详细规则

首先对于两个模型来讲,VGGT输入的H与W必须是14的整数,而SAM的ImageEncoder中要求image_size的H与W是1024,在sam.py中其实对image_size的处理,是预先写了一个预处理函数preprocess,在forward方法中调用,调整为1024的尺寸,通过preprocess实现了端到端的推理
【注1】:python中将函数是为first-class citizens,这意味着:
- 函数可以赋值给变量
- 函数可以作为参数传递给其他函数
- 函数可以作为其他函数的返回值
- 函数可以存储在数据结构中(如列表、字典、类属性等)
实际应用中可以实现策略模式,回调函数,动态方法替换
【注2】:python在类中定义的方法被称为绑定方法(bound method),具有自动绑定实例的特性(使用self)。虽然函数可以作为数据成员,但它们与类方法有重要区别:
- 绑定关系:类方法自动绑定实例(self),而作为数据成员的函数不会自动绑定
- 继承行为:类方法参与继承,而数据成员函数不参与
- 可访问性:类方法可以访问私有成员(通过名称修饰),而数据成员函数不能
2.2 Feature Interaction模块
【经验1】:给定一个2D卷积,Conv2d(32,2,1),他接收形如[B,C(32),H,W]格式的数据,通过2D(1×1)卷积核,将输出变为形如[B,C(2),H,W]格式的数据.卷积核内部的形状为

而且对于输入格式来说,conv2d会自动处理最后两个维度,所以对于和其他库联动时,需要使用permute调整位置(例如对于PIL将数据读入成[B,H,W,C])
所以说对于Conv2d(32,2,1)这个API的话,只用关注通道即可,把一个张量的最后两个维度去掉,然后倒数第三个维度变成2;输入的不是4维张量会使用view重新调整为4维
【经验2】:对于其他卷积也是同理,Conv1d处理3维张量(B,C,D),conv3d处理5维张量(B,C,D,H,W),这里需要特别注意,虽然说conv2d与conv3d被设计为处理图像数据和体素数据,但他们确实都可以处理视频数据,对于如[B,C,S,H,W]类型的数据如果使用conv2d来处理需要合并批次与序列维度为[B*S,C,H,W],但如果使用conv3d处理的话,直接输入即可.差别是
- Conv2d
适合时序关系不强的任务(如逐帧分类),无法直接捕获帧间运动信息,需要后期融合时序信息LSTM - Conv3d
需要同时分析空间内容和时间运动(如动作识别、视频分割),能直接学习时空特征(如运动模式),适合对时序敏感的任务(如动作识别)
【经验3】:空间对齐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号