2025.7.29学习日记【月底效率过低,内容待完善】
1.模型参数
1.1 参数加载方法
模型参数的加载分为两种,首先是使用torch.load加载,而后是使用huggingface的PyTorchModelHubMixin的from_pretrained的方法来加载.两种方法的加载格式不同,load在pytorch2.6之后才支持safetensors的格式加载,在这之前仅支持pt的格式加载,而from_pretrained支持safetensor与pt来加载,在加载时无需显式声明格式,仅需要声明模型路径即可
1.2 跨层加载参数
如果一个模型由各种模块嵌套组成,就会涉及到跨层加载参数,跨层加载参数可以理解为一个多叉树模型,主要通过路径锁定树上的节点,这里我主要做两种类型的测试,分别为内点跨层导入,叶节点跨层导入.
-
内点跨层导入:
-
叶节点跨层导入:
以下的内容是LangSplat内容的介绍
2.预训练模型的监督讯号
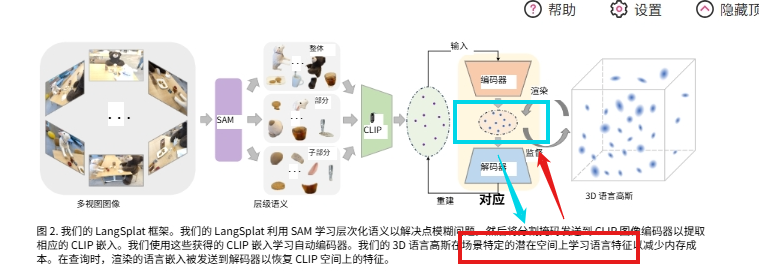
参考阅读了LangSplat这篇文章,在论文提出的方法中,首先声明了使用了SAM和CLIP这两种预训练模型。
【注】:如果不是为了适配更下层的任务,预训练模型最好还是不要动,因为里面的权重都是固定训练好的,说不定你自己带的数据集其实已经被包含在了预训练模型的任务中了,再拿来训练一边也没有作用。
- 预训练模型原因:
为什么使用SAM呢,作者主要是为了拿到像素级的多级语义特征,为什么要使用CLIP,主要是为了给像素级的语义特征给予一个具体的标签。除非要拿来监督,否则用处不大,看个效果而已 - SAM使用细节:
SAM出来的结果有一个语义尺度的概念,简单来说就是将物体分为了整体,部分,子部分,阈值越高尺度越小 - CLIP使用细节:
首先CLIP必须要预先给定词表,要处理掉词表这个问题只能让大模型根据经验直接给出词表的内容。
其次CLIP只能给出图像级的标签,为了能够处理像素级的标签,通常将图像分为图像块,让图像块级的标签去近似像素级的标签 - 编码器和解码器:
编码器是为了降低CLIP的Image嵌入(Embedding)的,解码器是为了重建CLIP的Image嵌入(Embedding),从而能够重新做到CLIP的回答功能
2.1 SAM监督讯号
SAM的监督讯号没怎么用的到,就是做了一个尺度分割的作用。
2.2 CLIP监督讯号
本文的监督讯号主要是用来监督解码器重建的CLIP的Image嵌入(Embedding)(不一定是token)是否足够好,记为loss(restruction);另外一个编码器由Gauss模型的loss传递回来进行训练
3.环境配置
3.1 安装基础环境/项目依赖
遇到使用conda env create --file environment.yml命令进行项目依赖配置的,一定要点进去查看yml文件查看源是在哪里配置的,不然很有可能出现下载缓慢的问题,例如在该项目我就看到了channels使用的不是镜像源,这时候需要切换镜像源

推荐使用清华的镜像源,我将镜像源列举在下方
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/linux-64
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
4.数据集
该项目主要使用了两个数据集进行评估,首先是LERF数据集,其次是3DOVS数据集,LERF数据集用于实现3D物体定位任务,由于原生的CLIP模型只能完成图像级别的定位任务,这里的CLIP特征是像素级的CLIP特征,初步先理解为返回的是像素级别的CLIP特征吧
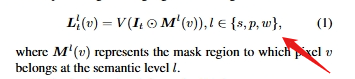
这里就是所说的3D语言场,其实就是

 浙公网安备 33010602011771号
浙公网安备 33010602011771号