2025.7.23学习日记【To Be Continue...】
1.读取图像像素
1.1 PIL访问
PIL是python中处理图像的第三方库,关于煮啵今天遇到的一些使用PIL的细节如下:首先PIL不支持下标操作,原因是因为在Python中只有实现getitem的方法的对象才支持下标操作,由于PIL的Image对象没有实现该方法,因此使用pixel=image[x,y]的做法是错误的,为了实现从Image中获取像素值的操作应该使用pixel=image.getpixel((x,y))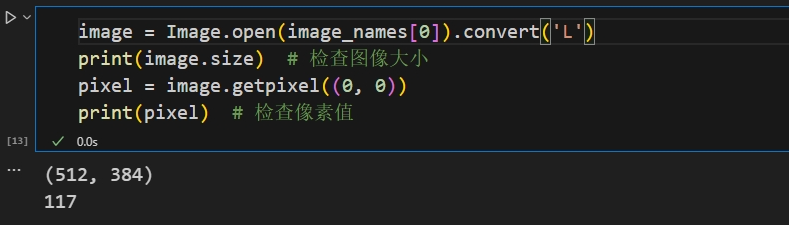
1.2 Numpy访问
PIL的Image对象中提供了访问像素值的方法,但更为好的方式是将Image对象转换为nparray对象,然后使用下标去访问,如果操作像素值后,需要重新保存为PIL的image对象使用image=Image.fromarray(image.astype(np.uint8))实现
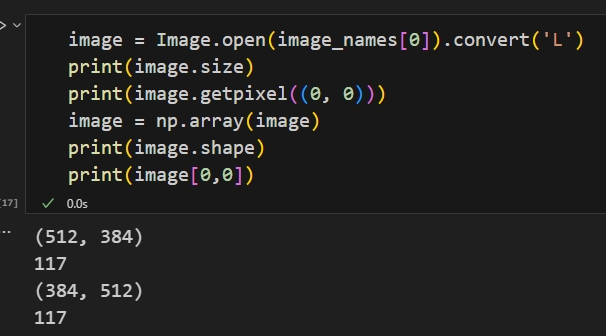
【注】如下是Image(PIL)和nparray(numpy)的访问区别

2.导出图像
2.1 操作图像格式
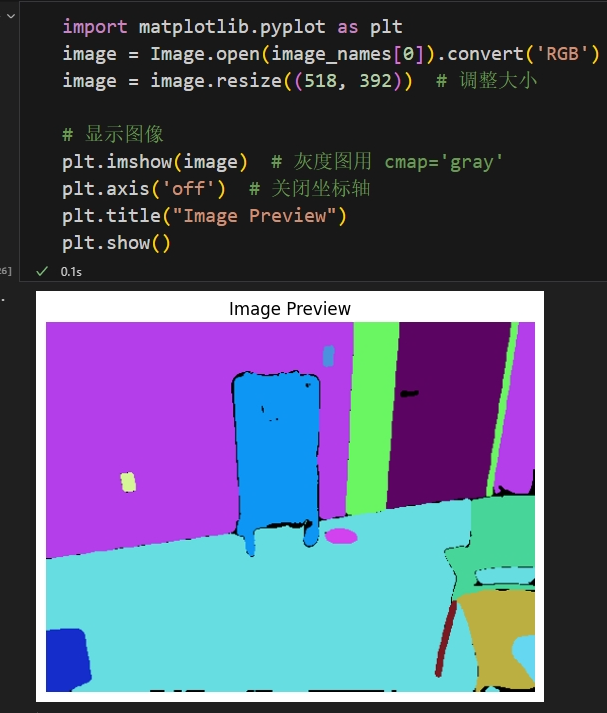
在PIL中可以使用Image对象的convert方法,将图像转为灰度图,RGB图等格式,例如将图像转为RGB格式效果如下
而转换为灰度图的效果如下:
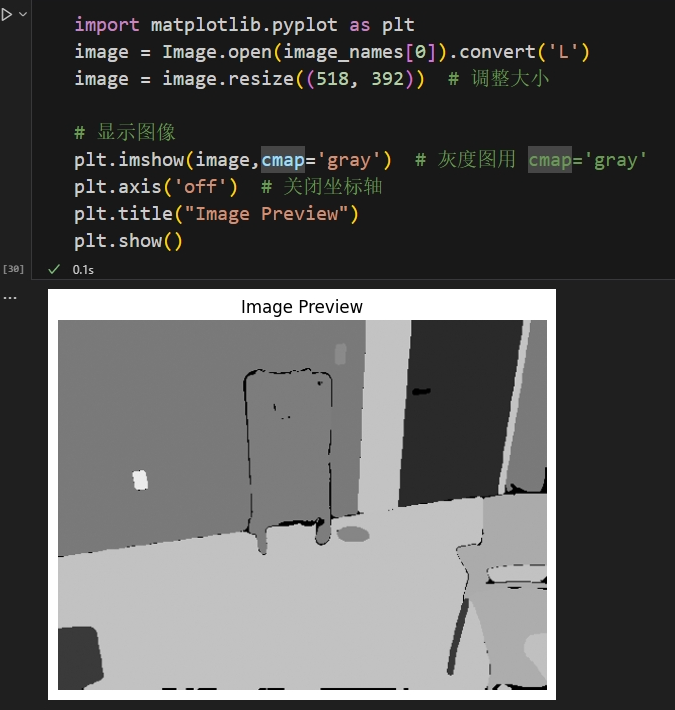
很明显对于图像分类来说,将灰度作为标签读入
2.2 修改导出格式
这一部分介绍一下torch.stack方法,该方法将以张量为元素的列表,直接转换为一个增加了新的维度的张量主要使用images=torch.stack(images,dim=0),意思为在维度0上堆叠,通过这种方法就可以把list转为纯tensor了
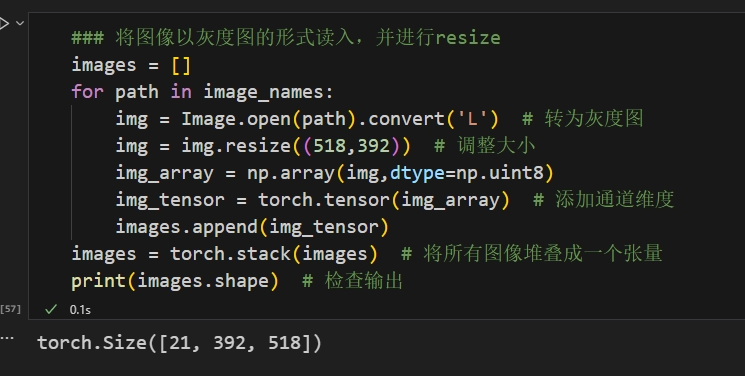
煮啵终于把自己的数据集做好了!!!
3.编写DataLoader
3.1 Hydra复习
从之前的Hydra的内容(虽然我也写的不太好),这里是VGGT的hydra配置
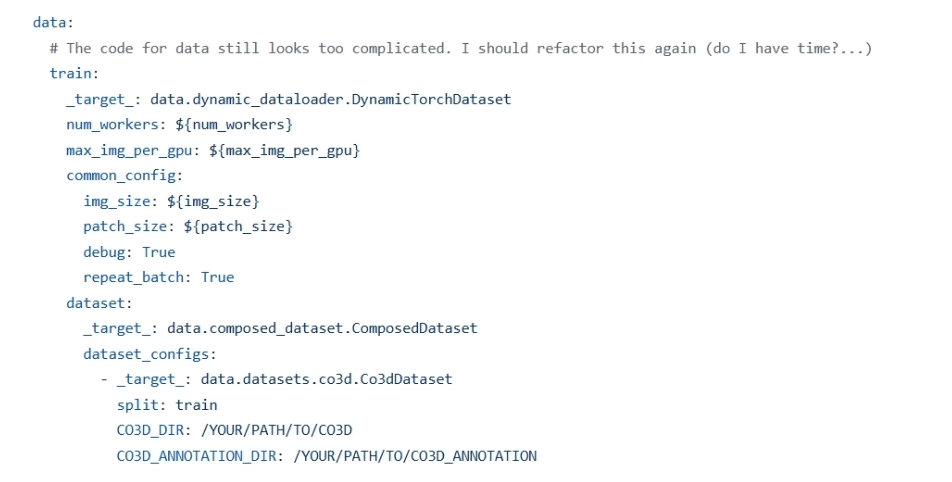
通过询问AI后我明白了Hydra自底向上的实例化过程。首先先实例化最内层的对象,有没有变量名无所谓,但是为了方便理解,我们加一个变量名
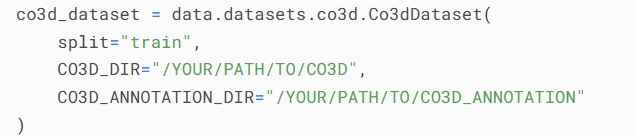
而后实例化组合数据集,同样加一个变量名

最后实例化一个加载器,同样加一个变量名
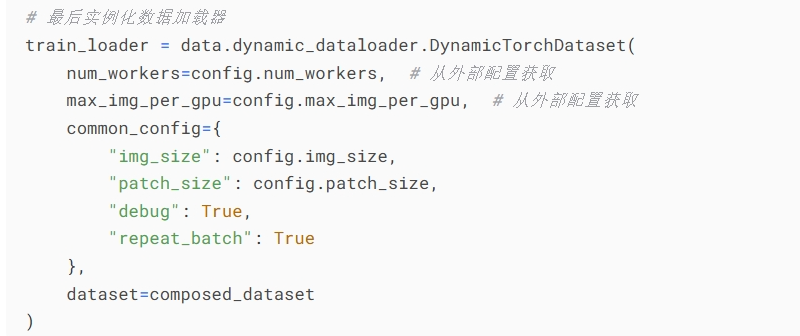
由于Co3dDataset继承自BaseDataset,这个BaseDataset又继承自torch中的Dataset,这里就到了我们熟悉的领域.
3.2 DataLoader Of Co3d
我们知道Dataset需要实现三个方法,分别是初始化(init),读取图片(getitem),获取长度(len)。在初始化中一般指定路径,在读取图片中一般使用索引,在获取长度里一般使用路径列表的长度。
【注】:getitem与len这两个方法也被称为数据集接口
Co3d的编写也类似于上面这套范式,对于路径指定这一部分,Co3d的父类BaseDataset并没有指定,而是在Co3dDataset类的init方法中指定;对于另外两个方法,则是在Co3d的父类BaseDataset中定义了getitem和len的方法。
【注】:对于数据集路径和数据集长度,必须要由BaseDataset子类来实现
在BaseDataset中定义了一个抽象方法get_data,这个方法必须由子类中的,定义的参数主要有seq_index,seq_name,ids,aspect_ratio,其中seq这几个开头的其实挺好理解,seq_name表示你的帧序列的名字(有可能是文件名),seq_index表示你的帧序列的编号。
剩余的方法就是调整图像尺寸和形状,以及预处理函数等,这些关联到具体任务,如果是想用VGGT做全新的任务,还是使用模块接入的方法,可以做到保留模型结构,进行微调的同时,重新适应下游任务
3.3 DataLoader Of Mine
由于煮啵的数据放在了实验室的服务器上,分别为./images/bookshelf与./masks/bookshelf,使用tar -cvf images.tar images/与tar -cvf masks.tar /masks打包为tar文件,上传到服务器上,使用tar -xvf images.tar与tar -xvf masks.tar解压
4.增加输出头
其实没有想象中复杂例如,我在原来的VGGT模型中,在深度输出头部分加一个映射模块,将输入的深度图转换为分割概率图,写一个decoder文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号