2025.7.15学习日记
1.训练集微调
1.1 trainer.py
- run:
现在介绍training文件夹中的trainer文件,trainer文件中较为重要的方法是run,run_train,run_value。run方法中有一句断言用来表示模型的模式只能是train或者val;run_train中所做的包括获得数据加载器,而后使用train_epoch训练,而后保存模型 - epoch
trainer文件中另外两个较为重要的方法是train_epoch和val_epoch。煮啵调试失败也是在这个train_epoch方法里,在dataloader里遍历失败
1.2 co3d.py
1.2.1 line.92
现在介绍co3d.py,首先我想提及一下line.92,有一个super().__init__(common_conf=common_conf)的操作,这个操作具体实现原理煮啵不太清楚,但是根据煮啵之前打印的trainer的数据成员来看,他是直接使用了部分trainer的数据成员

1.2.2 line.133
line.133这个循环内主要做的操作如下:
- 遍历类别和数据集类型
for c in category:
for split_name in split_name_list:
annotation_file = osp.join(self.CO3D_ANNOTATION_DIR, f"{c}_{split_name}.jgz")
- 外层循环遍历所有类别(如不同物体类别)。
- 内层循环遍历所有数据集划分(如train/val/test)。
- 读取标注文件
with gzip.open(annotation_file, "r") as fin:
annotation = json.loads(fin.read())
- 尝试打开并读取每个组合对应的压缩标注文件(.jgz),内容为JSON格式。
- 如果文件不存在,则记录日志并跳过。
- 遍历序列数据
for seq_name, seq_data in annotation.items():
if len(seq_data) < min_num_images:
continue
if seq_name in self.invalid_sequence:
continue
total_frame_num += len(seq_data)
self.data_store[seq_name] = seq_data
- 遍历标注文件中的每个序列。
- 如果该序列图片数量小于min_num_images,跳过。
- 如果该序列在self.invalid_sequence(无效序列列表)里,跳过。
- 否则,将该序列的数据存入self.data_store,并累计图片数量。
1.3 标注解压
煮啵还没有完全写完,等煮啵先忙完,马上整理
设置vscode打开文件的最大大小,workbench.editorLargeFileConfirmation
解压jgz文件的步骤,我让AI编写了两个脚本去实现,结果如下
 调整1e5次的num_batches怎么调整
调整1e5次的num_batches怎么调整
2.SAM训练
sam2训练的过程,配置项目的过程中SSH URL+学术加速,依旧给力👍.
2.1 前置概念
图片分类,目标检测,语义分割,实例(语义)分割。图片分类单纯地将图片分类成物体,目标检测为图片上的对象划分出框标注并标注为相应的物体,语义分割检测到图片的进行蒙版标注并标注为相应的物体(蒙版标注的工作量比框标注要大),实例分割为语义分割的升级,不仅标注物体,还标注是哪一个物体。

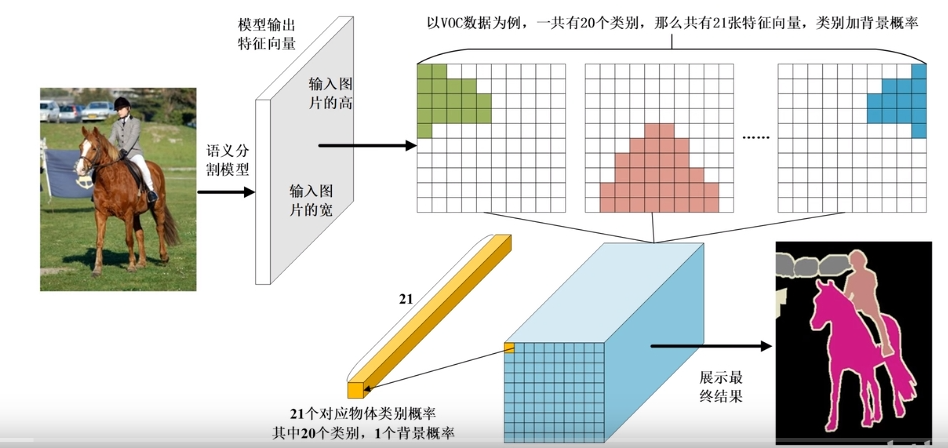
- 语义分割的目的是为了从像素级别理解图像的内容,并为图像中的每个像素分配一个对象类。通常最后的处理方法是输出一个二维数组
【注】当时的全像素级的语义分割是FCN(全卷积神经网络),而后的任务中使用的是U-Net,现在较为先进的语义分割网络是Deeplab - 实例分割的目的是为了理解同一类别的不同物体,回答"图像里有几头牛的问题🐂"。实例分割的算法有两种发展路线。

但是这两种发展路线其实都不够简介明了,于是出现了这样的想法,和逐像素的语义类别标注一样,进行逐像素的实例类别标记,提出这个想法的论文的作者认为实例类别标记是位置+尺寸,简单来说就是,两个物体如位置和尺寸都是一样的话,那么这两个物体就是一个物体,
【注】实例分割最先使用的是MaskRCNN,而后面出现的SOLO使用的mask分支与classifier分支使得整个实例分割的原理变得十分简单
2.1.1 语义分割-FCN
我们知道卷积神经网络可以用于分类任务,主要流程通过不断的下采样与增加通道数,最后进行全连接输出概率;在语义分割的任务中,差别就在于最后进行一个上采样,随机概率图
2.1.2 实例分割-SOLO
SOLO提出的实例类别(Instance Category)的概念,作者指出,实例类别就是量化后的物体中心位置(location)和物体的尺寸(size)。
- 位置:SOLO将图片划分S×S的网格,网格输出两种分支,分别为分类分支与mask分支。分类分支的大小为[S,S,C],C为类别数量(我可以提前规定分类别最多有多少个);mask分支的大小为[H,W,S2],S2为最大预测实例数量,由于网格中每个格子都有可能存在着一个实例,所以类似于遍历的想法,也就是说每个网格都有C种可能,
- 尺寸:通用的做法为FPN,用于输出特征图
【注】:Pillow支持的常用图像模式有8bit灰度图,8bitRGB,8bitRGBA,二值图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号