2025.7.12学习日记【实际上是12+13号的,周末在爽玩HSR今晚留下来😋】
1.训练集微调-1
在这一部分我将先介绍training文件夹本身包含的的.py文件以及config文件夹中.yaml文件
1.1 launch.py
在VGGT的官方提供的训练代码launch.py中,流程十分简单,解析命令行参数,撰写API,传入训练器训练
- 命令行解析:主要使用argparse模块,将默认文件配置文件设置为default.yaml
- 撰写API:这一名称出自Hydra官方文档的参考手册部分,使用方法为
initialize()+compose(),模板如下:
with initialize(version_base=None,config_path='YourPath'):
cfg = compose(config_name='YouYamlFile')
实际实现的效果等同于装饰器@hydra.main(version_base=None,config_path='YourPath',config_name='YourYamlFile')
- 传入训练器:主要使用重星号
**将cfg解析为关键字参数传入Trainer训练器,执行Trainer类的run()方法
1.2 trainer.py
官方提供的训练代码trainer.py中定义了训练器类Trainer,注明了DDP,初始化,检查点,训练,指标记录5类功能
如果仅需在特定数据集上进行微调,需要关注的在_init_方法(line143),与_setup_dataloaders_方法(line270)
- setup_dataloaders():
在该方法中需要关注self.data_conf.get数据成员,这个数据成员实例化自Python的一个类。
在Hydra的参考手册中提及到了如下内容,该内容中编写了一个基类及其子类同时又编写了一个config.yaml文件和mysql.yaml文件
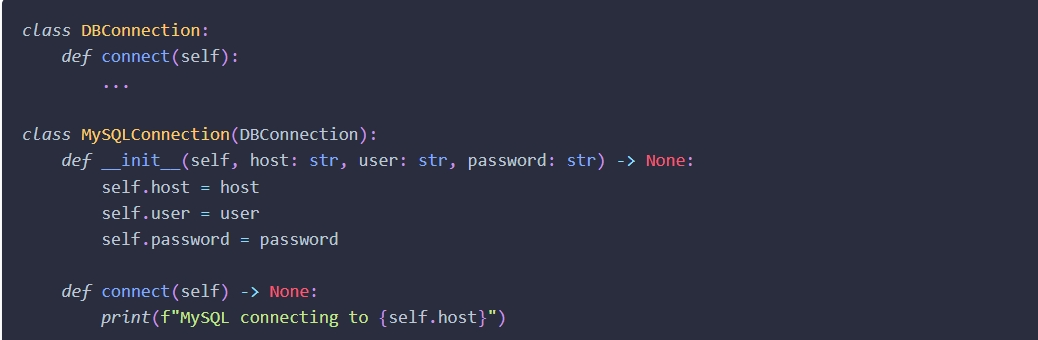


编写完毕后直接使用hydra.utils.instantiate()方法,传入cfg(DictConf对象),即可。
同理self.train_dataset = instantiate(self.data_conf.train, _recursive_=False)直接调用了instantiate()方法将train(DictConf)传入,以此来实例化数据集
【注1】:DictConf与Python原生的数据集不同,可以直接使用key.value的形式来直接获取键值
【注2】:现在还未实践,如果将Default Lists与Config Value同时配置到config.yaml中使用cfg.defaults是否是default_dataset - setup_ddp_ditributed_training():
在VGGT的官方训练代码中注释到 #wrap the model with ddp,说明模型被分布式训练所包装,如果是多卡,其实这个参数不用改动,但如果是单卡需要去了解这里的详细工作流程。
【注】:遗憾的是,主播现在单卡和多卡都还没有试成功😥
1.3 default.yaml
- 默认列表与配置值
在default.yaml中包括了Default List和Config Value,在Hydra的参考文档中提到,可以将两者配置到一起。
default.yaml文件中将Default List和Config Value配置在一起,Default List指向了default.dataset.yaml文件,Config Value配置了model等参数设置
参考文档链接(跳转标题Composition order of primary config):
https://hydra.cc/docs/tutorials/basic/your_first_app/defaults/#composition-order-of-primary-config - 非递归实例化
在hydra的官方文档中,介绍到了非递归实例化的操https://hydra.cc/docs/advanced/instantiate_objects/overview/
在演示示例一共创建了三个类Trainer,Dataset,Optimizer。其中Trainer类接收Dataset类和Optimizer类的OmegaConf字典,让内部自己去实现实例化
现在回到VGGT的default.yaml中,在train.py中实例化了DynamicTorchDataset,传入了四个参数,其中dataset是ComposedDataset的实例,dataset_config是是列表,作者想同时加入vkitti数据集但事实上未加入,所以实际上列表类只有一个Co3dDataset的实例。
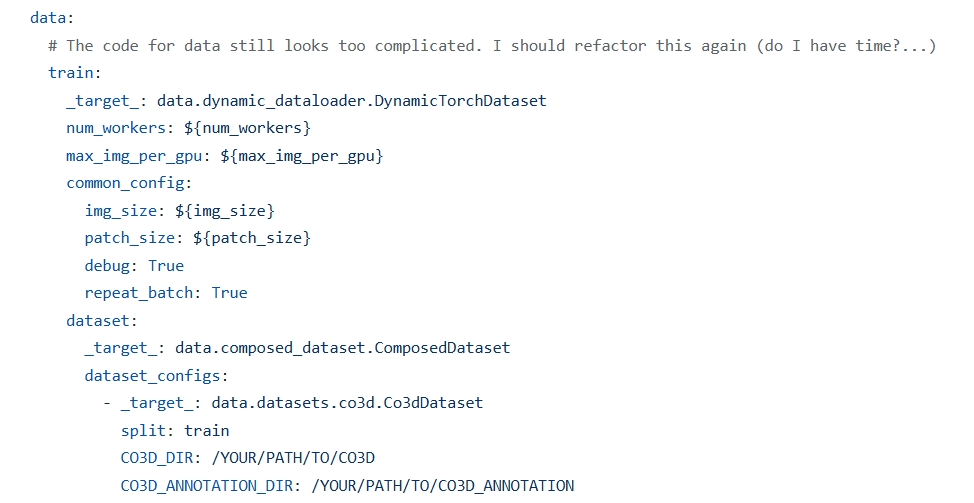
禁止递归实例化结构: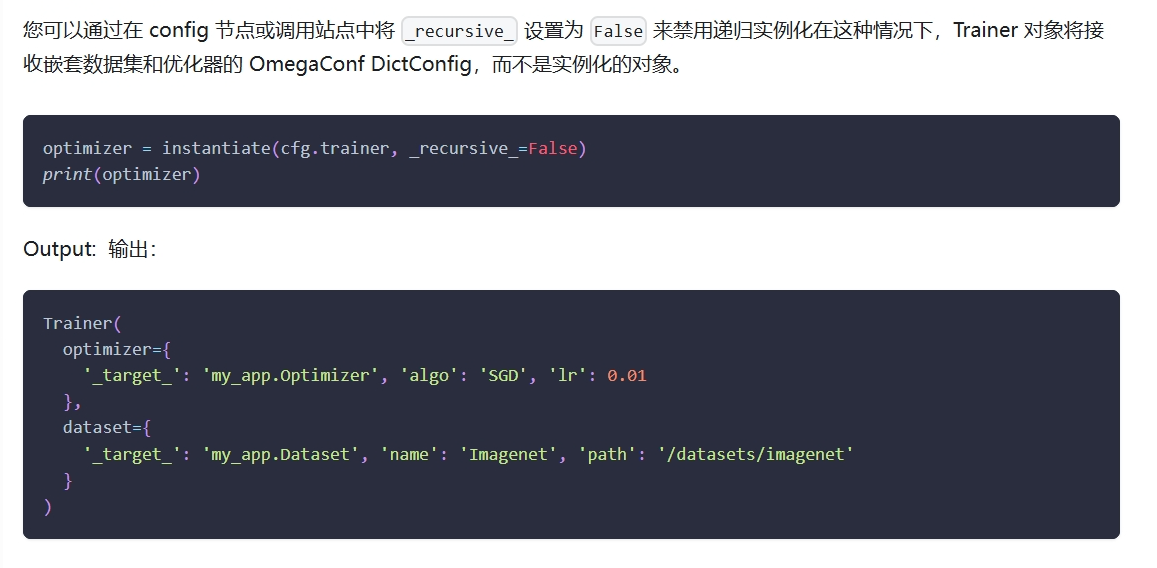
Trainer实例化解读:
由于在创建实例时采用了非递归的形式,所以直接创建时,传入的参数基本上是字典(DictConf)与基本数据类型,创建完毕后类的数据成员如下,均为OmegaConf对象或者基本数据类型对象,完成实例化后才是对应的类对象:
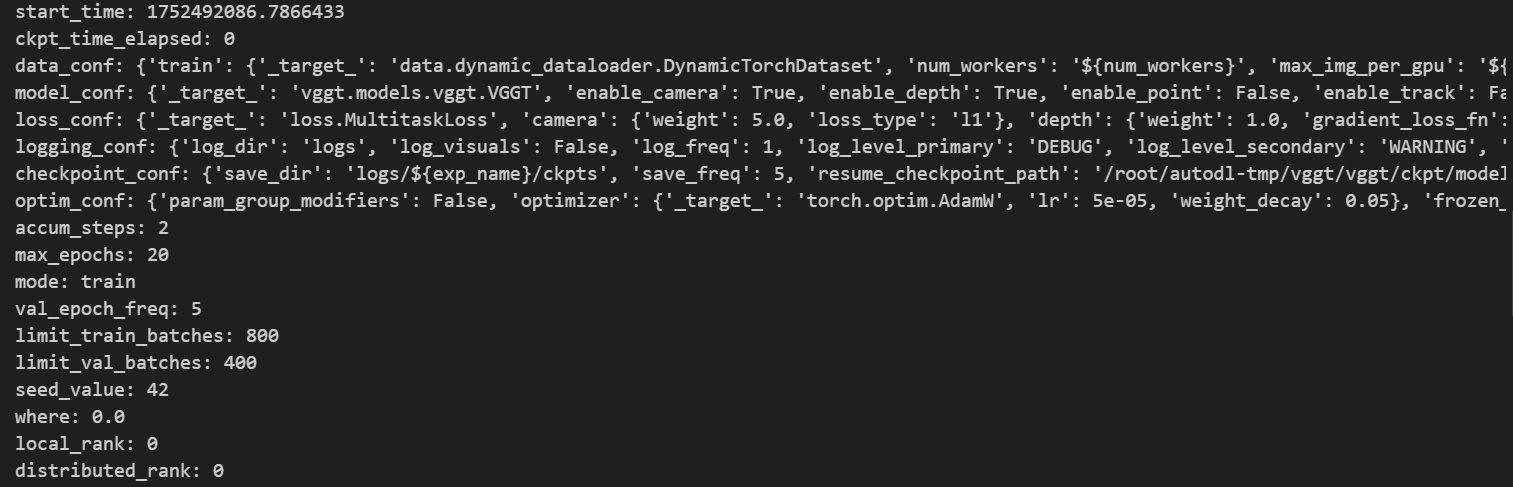
这里想稍微解释下那个data_conf这个数据成员,这个数据成员的类型其实是字典。分别指向两片不同的空间,用以完成train与val的实例化,在没有实例化前,存储的OmegaConf对象,在完成实例化后,指向对应的Class对象
【注】:请注意分清参数,数据成员的区别,
2.训练集微调-2
这一部分将介绍data文件夹下的部分.py文件以及dataset文件夹下的文件
2.1 dynamic_dataloader.py
在dynamic_dataloader.py定义了DynamicTorchDataset,DynamicBatchSampler,DynamicDistributedSampler三个类。DynamicTorchDataset由抽象基类ABC实现,其余两个类扩展了pytorch中的相应类的功能
- DynamiTorchDataset:继承自抽象基类ABC,但这里的抽象基类并没有使用
@abstractmethod装饰的抽象方法,其实可以直接实例化
【注】:使用抽象基类的步骤与规则
1.导入ABC类和abstractmethod方法 // 2.创建继承自ABC的抽象基类 // 3.在需要子类实现的方法上添加@abstractmethod装饰器 // 4.创建抽象基类的子类,实现所有的抽象方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号