2025.7.7学习日记
1.ViT复习
1.1 Embedding
【ADD】加入Class Token
由于标准的block要求的输入是[num_token,token_dim],对于图片数据[H,W,C]来说无法直接输入,所以需要进行处理。这里以ViT-B为例
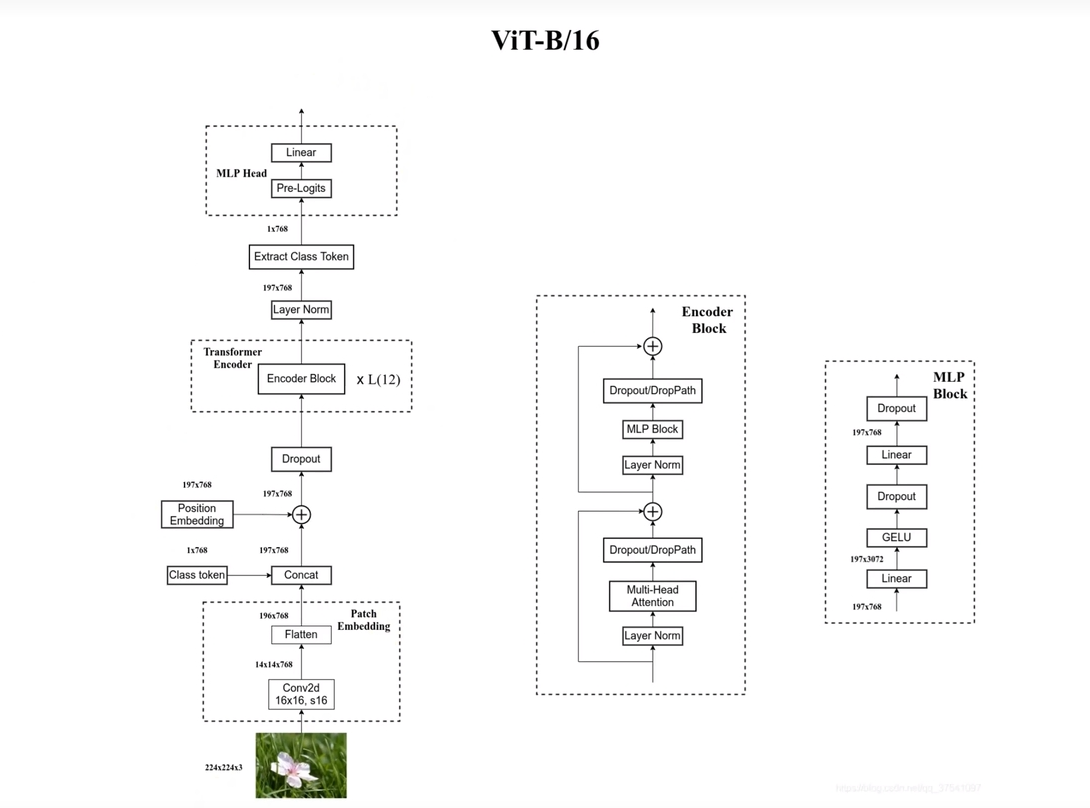
从图片上来看ViT-B的输入图片为[224,224,3],需要将其调整为token_dim=768才可以送入模型中,这里可以简单做一个乘除可以知道最后输入为[196,768],拼接一个class_token[1,768],cat([196,768],[1,768])->[197,768],并且进行位置编码最后送入blocks即可
1.2 Encoder
Encoder包括了12个Encoder Block,每个Encoder Block中又包含了一个MLP Block
- Encoder Block:
依靠Multi-Head Attention与MLP Block实现注意力机制和特征重构 - MLP Block:
两个线性层,实现[197,768]->[197,3072]->[197,768]的特征重构。
1.3 MLP Head
【Extract】提取出Class Token
送入MLP Head实现分类任务,输出概率
1.4 其他
Encoder注重理解,完成的任务有文本问答,分类等任务;Decoder注重生成,完成的任务有机器翻译,文本生成等任务。Encoder与Decoder一同使用,完成理解生成的任务。

2.SAM复习
详细可以参考这三篇文章
- prompt encoder:
https://blog.csdn.net/qq_43426908/article/details/133283192 - image encoder:
https://blog.csdn.net/qq_43426908/article/details/132939732 - mask decoder:
https://blog.csdn.net/qq_43426908/article/details/133877154
2.1 Prompt Encoder
Prompt的输入一共有四种,分为点(point),框(box),文本(text),掩码(mask)。
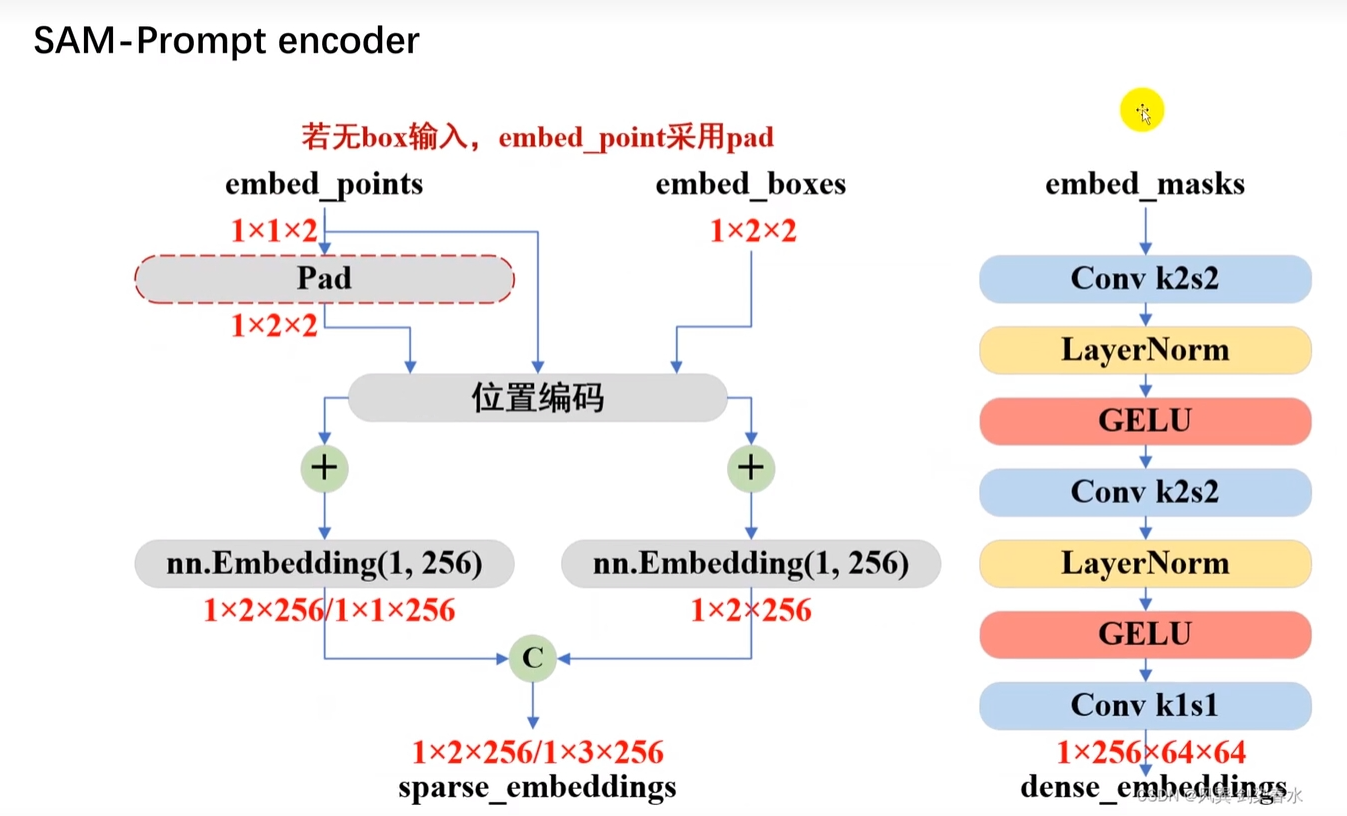
2.2 Image Encoder
SAM参考的是ViT模型系列架构,所以SAM的模型拥有sam_vit_b,sam_vit_l,sam_vit_h,三种
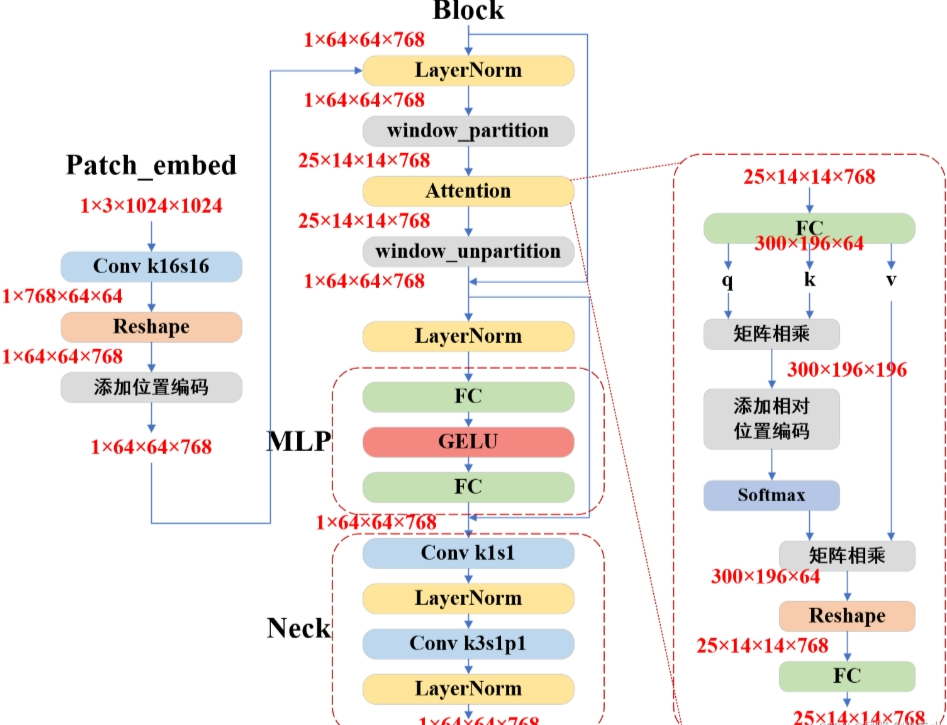
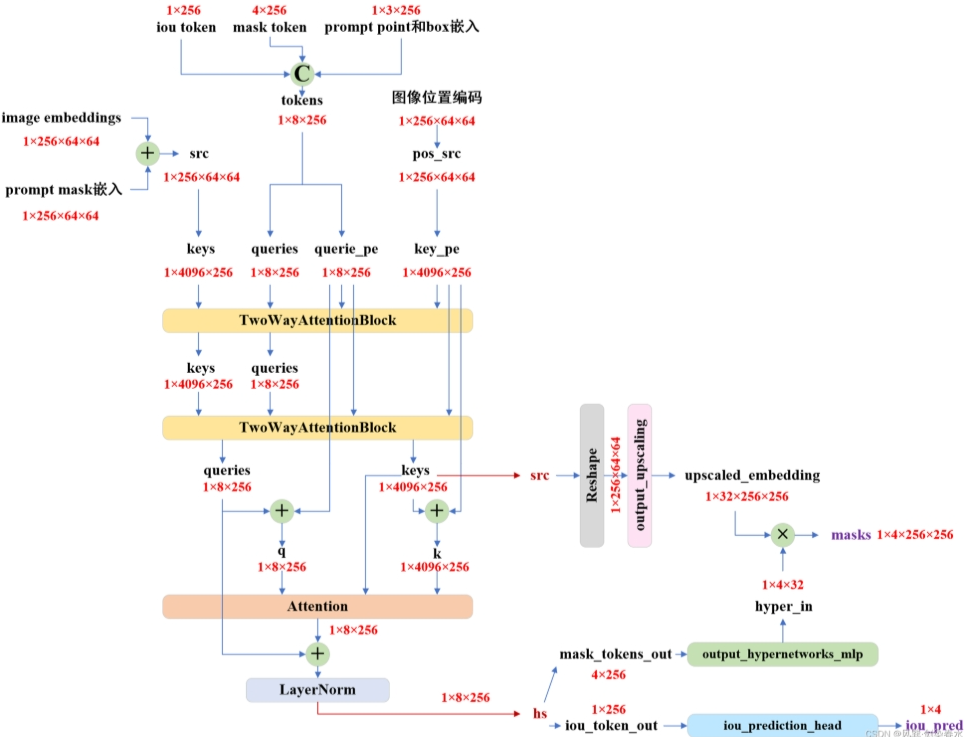
2.3 Mask Decoder
用于生成掩码的任务
3.Python知识点
3.1 模块和命名空间
- 文件
以.py结尾的文件都可以称为模块。 - 文件夹
为什么有些文件夹被称为模块,有些文件夹被称为命名空间,简单理解下来就是,有__init__.py的文件夹被称为模块,没有的则成为命名空间
3.2 模型结构
获取模型结构的办法有手动打印,使用torchsummary或者使用torchinfo。
手动打印可以获取模型的参数所占大小;使用torchsummary可以看到模型的编号结构以及输入输出张量的大小,但有时候会失效;使用torchinfo,可以查看到输入输出张量大小,但是结构编号没有torchsummary清晰。三种方法在测试时可以一起使用
4.任务清单
- [√]了解如何添加class_token,简要实现一个ViT

 浙公网安备 33010602011771号
浙公网安备 33010602011771号