2025.7.6学习日记【又是摸鱼🐟的一天】
1.卷积与转置卷积
1.1 卷积
卷积的本质其实是一种滑动窗口机制,卷积出的特征取决于原序列大小和滑动窗口的大小.在数学上需要将滑动窗口中的数据进行180的调转,才能达到数学概念上的卷积.
在二维图像上,卷积将原图X变为特征图Y.
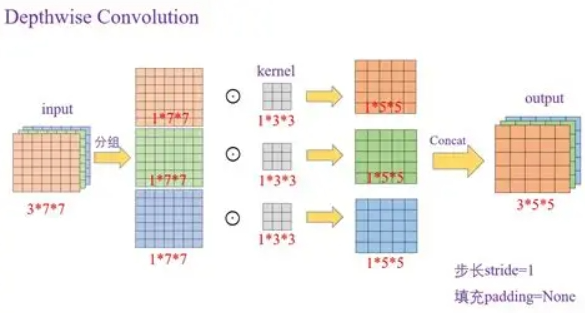
多通道图又有不同的卷积方式,包括分通道卷积,全通道卷积.采用分通道卷积,滑动窗口也需要分通道,本质上将多通道处理成多次的2维卷积,该方法能保持通道数不变;采用全通道卷积,集合三个通道的信息,该方法会使通道数变为1
- 分通道卷积(参数分离):
- 全通道卷积(参数共享):
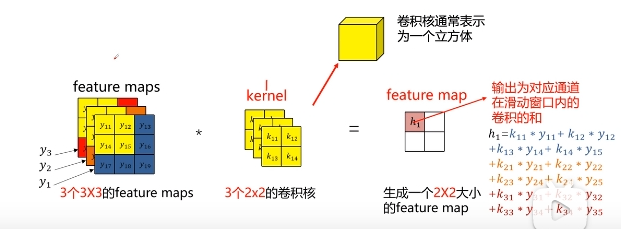
【注】:事实上卷积可以与矩阵乘法联系在一起,该做法降低了时间复杂度,提高了空间复杂度,参考文章在这里
https://blog.csdn.net/lanadeus/article/details/82534425
1.2 转置卷积
逆卷积又称为转置卷积,操作与卷积操作类似,也是基于滑动窗口机制.但是转置卷积的padding和stride参数与普通卷积不同.
- 参数解读
-
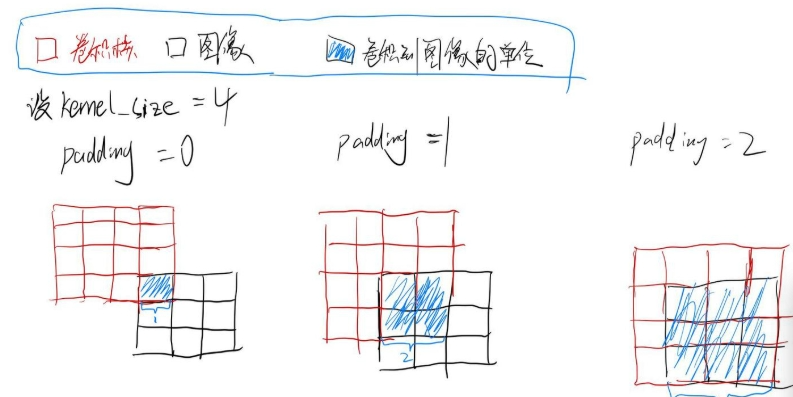
padding(图示为0)
padding是图像(特征图)四周填充的行,列数(给图像四周),具体来讲就是给图像四周填充kernel_size-padding-1个行、列
-
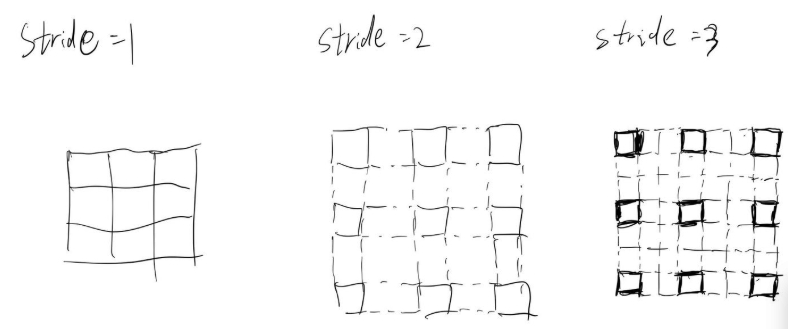
stride(图示为1)
stride是图像(特征图)的每个像素(单位)之间的距离,具体来讲给像素之间添加stride-1个元素0.
- 转置卷积步骤

【注】上下镜像翻转和左右镜像翻转的效果等同于将图像旋转180°一致,与SE3内容相近(旋转,平移,反射) - 图示说明
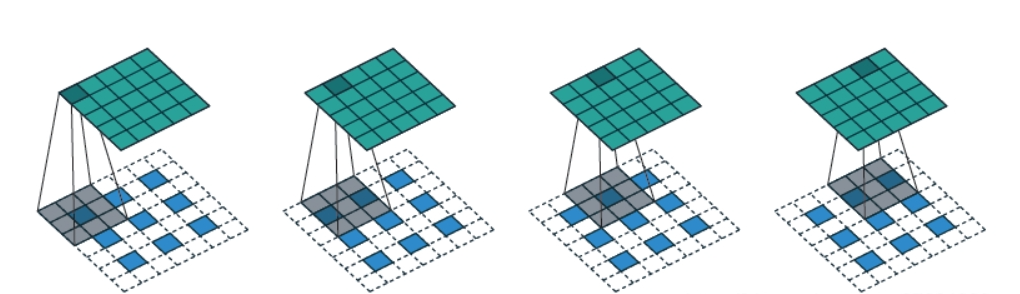
输入特征图A:3×3
卷积核:卷积核大小为3,stride为1,padding为1
1.3 应用
卷积一般用于下采样,缩小图像分辨率;转置卷积用于上采样,增大图像分辨率,两者通常一起被用于做特征融合.
2.VGGT
2.1 论文解读
- Introduction
论文在Introduction部分介绍到,VGGT与CV和NLP领域的大型模型同源 - RelatedWork
- 论文在Relatedwork中介绍到SFM问题(Structure from motion),获得相机位姿重建稀疏点云,以及在解决传统SFM问题时,CLOMAP是流行的传统框架。
- 此外论文还介绍到了MVS问题,MVS是在SFM算法得到的稀疏点和相机位姿基础上进行,获得相机深度重建密集点云,
- Method
- 论文在Method中提及到主模型f根据图片数输出结果数,例如输入3张图片,输出的深度结果为[1,3,350,518,1] ([B,N,H,W,C])
- 注意到主模型f输出的track并非为轨迹,而是特征图,使用了另一个网络T来实现i张图上第j个的2d轨迹点的预测。此外这个网络T与f是联合训练的
- Appendix
作者在附录中提及到,VGGT主模型f使用了24个blocks,每个blocks都带有frame和global。此外还有一些需要注意的细节,我将从以下几个方面说明
- 架构:
对于每个block来说,作者使用的是ViT-L模型,注意力的特征维度为1024;
对于图像的token化,作者使用的是DinoV2论文的做法;
对于上采样,作者使用的是Depth anythingv2论文的做法,将序号为4,11,17,23的block送入DPT - 训练
对于训练数据来说,作者采用了DUSt3R的做法,每个场景选择2-24帧,并保持批次中48帧的恒定总数
2.2 VGGT模型参数
这一部分在7.4号的1.3部分有写,补充一部分
- DPTHead:
resize_layers-尺度调整层:
该组件负责调整不同中间特征的分辨率,包含四种操作,用到了三种组件,分别为:

scratch-特征融合网络:
特征融合网络通过_make_scratch函数创建,包含

3.任务清单
- [×]复现DINO论文,至少要到数据集的处理方法
- [×]密集点云分割的论文,至少要看到可视化的实现方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号