2025.7.4学习日记【写的内容太多了/(ㄒoㄒ)/~~】
1.VGGT
1.1 VGGT交互组件
VGGT官方提供三种交互组件,分别为demo_colmap.py,demo_gradio.py,demo_viser.py。后两者为网页式交互组件,官方版本使用的gradio在autodl上复现可能会出现错误,需要更换版本,viser可正常使用。
1.2 VGGT模型架构/模型流水线
模型架构为Transformer架构,模型的流水线如下图
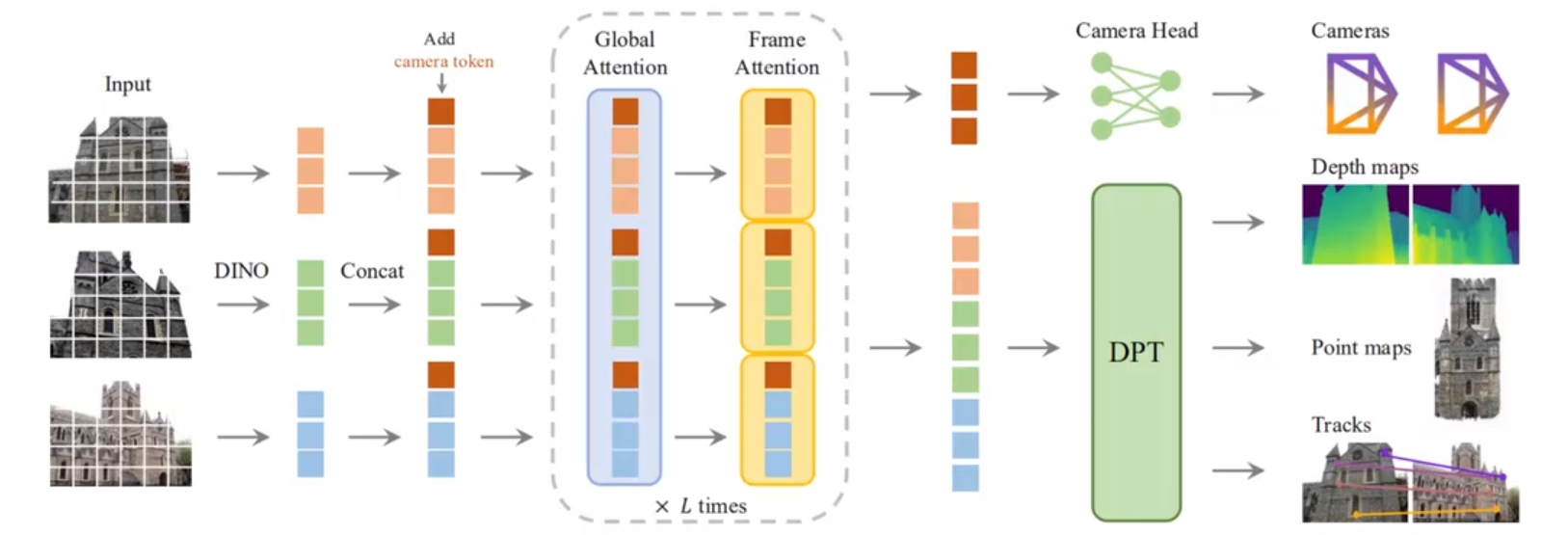
模型的流水线图中可以明显地看出VGGT有一个ADD和DEDUCE的操作,DEDUCE操作将Token分解,传给相机与DPT,相机和DPT分别对应camara_head,depth_head,points_head,track_head
1.3 VGGT模型参数
VGGT主要包括的组件有aggregator,camera_head,depth_head,point_head,track_head
- aggregator:
组件包括了patch_embed,frame_blocks,global_blocks三种组件。每个组件均包含了24个对应名称的blocks(编号0-23),每个blocks又是标准的Transformer序列中的block的堆叠。
【注】该部分其实对应了架构中的Dino,GlobalAttention,FrameAttention的步骤。论文中还提及到tokens的数量取决于图像的分辨率 - camera_head:
主要组件包括trunk,其余组件请使用如下命令,找到相应位置查看。
model = VGGT.from_pretrained("./vggt/ckpt/")
for name, param in model.named_parameters():
print(name, param.size(), param.requires_grad)
trunk组件由默认由4个block组成,可以修改trunk_depth来调整block的个数。
trunk的输入来自vggt主模型的aggregator,输出用于计算相机姿态参数的特征。
该组件的处理逻辑写在了trunk_fn函数中,概括起来大致步骤为归一化与modulate(被单独写成一个函数),trunk进一步处理(blocks),经过pose_branch处理(mlp)。trunk在每次迭代时都被调用,用于细化相机预测,处理逻辑在forward函数中
【注】:论文中有提及到,VGGT使用共享主干(shared backbone)来预测3D量
- point_head和depth_head:
这两个head均是单独创建的DPT实例,在参数和方法上有着高度的重叠。具体来说DPT包括的组件如下
1.特征投影(projects):
包含4个1×1的卷积层,用于处理aggregator的global_blocks,frame_blocks的中间特征,对应模型流水线传入DPT的Token,在代码中体现在如下部分


然后将不同blocks的特征处理到统一的特征空间,在代码中体现为:
图片等待中...
2.尺度调整(resize_layers):
等待中...
3.特征融合(scratch):
等待中...
2.SAM详细解读
SAM由三个神经网络模块组成,ImageEncoderViT,PromptEncoder和MaskDecoder。PromptEncoder支持四种类型的输入为
2.1 模型加载
官方提供了三种不同大小的模型,sam_model_registry函数字典在build_sam.py文件中定义
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
SAM的函数字典如下
sam_model_registry = {
'default':build_sam_vit_h,
'vit_h':build_sam_vit_h,
'vit_l':build_sam_vit_l,
'vit_b':build_sam_vit_b
}
SAM函数字典中对应的函数如下
def build_sam_vit_h(checkpoint=None):
return _build_sam(
encoder_embed_dim=1280, #l系列模型为1024,b系列模型为768
encoder_depth=32,
encoder_num_heads=16,
encoder_global_attn_indexes=[7,15,23,31],
checkpoint = checkpoint
)
不同系列模型参数参照本文章,最后通过_build_sam函数完成模型的初始化与权重加载
https://blog.csdn.net/yangyu0515/article/details/130319437
【注1】:如果想要修改buildsam的默认启动模型,需要修改build_sam = build_sam_vit_h,替换成需要的模型,再将其放在对应函数def build_sam_vit_x的后面即可。
【注2】:函数/类字典及其调用方法,Python支持将函数/类保存在字典中,并通过func[]()的形式调用函数/类字典中的函数/构造方法
3.ViT
ViT又称为VisionTransformer,是Transformer在视觉领域的应用。在这里先回顾下Transformer的处理流程,对于一段文本,会经过如下步骤:
Action:Tokenizer->Embedding->AddPosition
Result:Sentence->Token->Token Embedded->Token Positioned
【注】:Token又称为向量化
3.1 ViT模型架构
ViT由三个模块组成,包括LPFP层,Transformer Encoder层,MLP Head层。LPFP又称为Embedding层,作用在于分割图片(num_token)并展平(token_dim);Encoder层传统结构一致,MLP Head层用于实现分类。
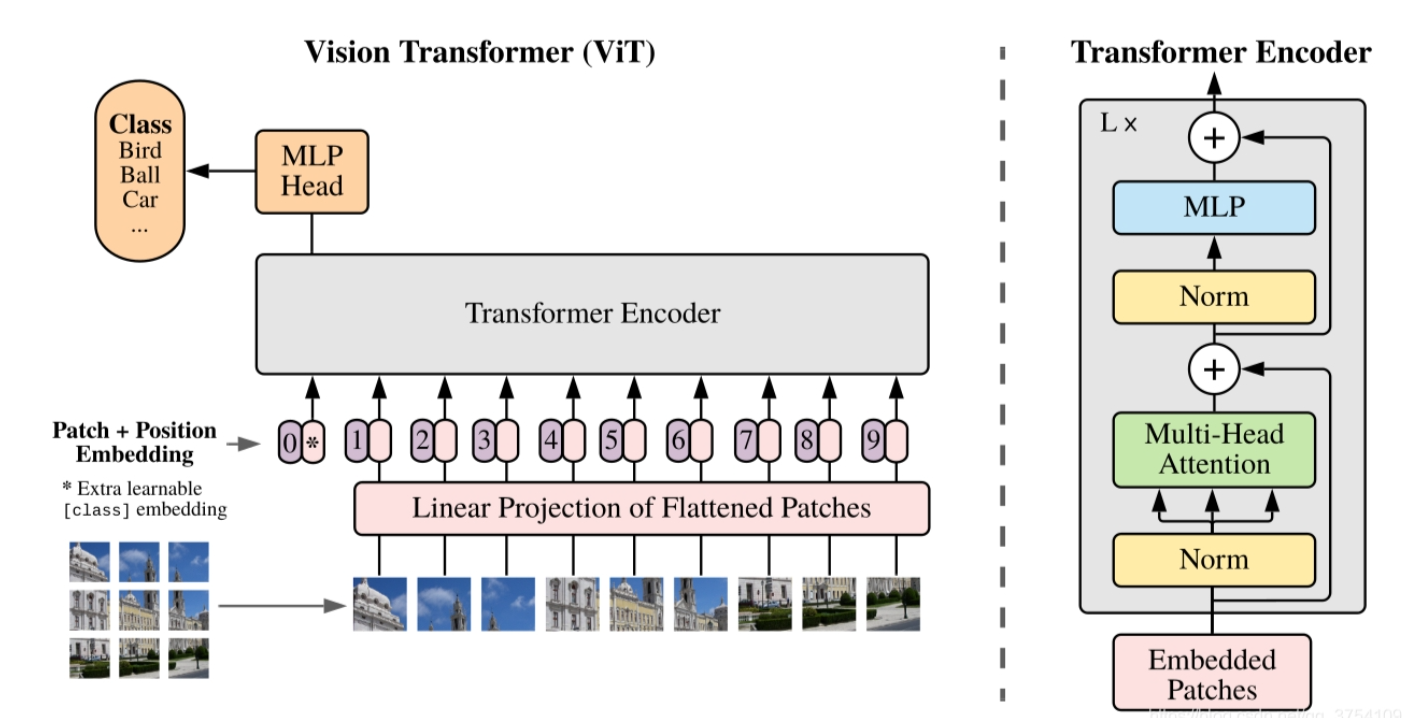
3.2 Embedding层结构详解
对于标准的Transformer模块,要求输入的是token序列,即一个二维矩阵结构为[num_token,token_dim]。以VIT-B/16为例,token_dim为768。
对于图像数据而言,其数据格式为[H,W,C],无法作为输入进入,需要通过Embedding层对数据做变换。以VIT-B/16为例,输入图片为[224,224,3],按照16×16的大小划分Patch得到196个Patch,而后将Patches[196,16,16,3]映射到768维[196,768]满足ViT-B/16的输入要求
- 卷积操作获得token
在代码实现中,直接通过一个卷积层来实现,以VIT-B/16为例,使用卷积核大小为16×16,stride为16,卷积核个数为768的卷积层,将[224,224,3]->[14,14,768],最后将H,W展平得到[196,768]. - 加上可训练的分类token以及Position
在输入到Encoder之前需要加上[class]token以及Position,以VIT-B/16为例,[class]token需要与之前的token拼接,Cat([1,768],[196,768])->[197,768];Position采用的是一个可训练的参数(1D Pos.Emb.),其shape和拼接后的token一致为[197,768]
4.PyTorch部分知识点
4.1 查看模型参数
模型参数在可以使用model的named_parameters查看,方法如下:
for name, param in model.named_parameters():
print(name, param.size(), param.requires_grad)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号