什么是分词器
- 给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行时态转换(单复数、同义词)
- 分词器的组成部分如下:
- 字符过滤:在一段文本进行分词之前,先进行预处理,比如过滤 HTML 标签
- 分词:hello world java → hello, world, java
- 字符处理:字母转小写,去掉语气词,同义词转换,dogs → dog,liked → like,Tom → tom,a / the / an → 干掉,mother → mom,small → little
- 选用好特定的分词器很重要,一段文本只有经过合适的处理之后才能拿去建立倒排索引
ES内置分词器
- 对这句话进行分词:Set the shape to semi-transparent by calling set_trans(5)
standard analyzer:标准分词器(默认)分词之后的语句 → set, the, shape, to, semi, transparent, by, calling, set_trans, 5simple analyzer:简单分词器,分词之后的语句 → set, the, shape, to, semi, transparent, by, calling, set, transwhitespace analyzer 空白分词器,分词之后的语句 → Set, the, shape, to, semi-transparent, by, calling, set_trans(5)language analyzer(特定的语言的分词器,比如说,english,英语分词器)分词之后的语句 → set, shape, semi, transpar, call, set_tran, 5
测试分词器
POST /_analyze
{
"analyzer":"standard",
"text":"Set the shape to semi-transparent by calling set_trans(5)"
}
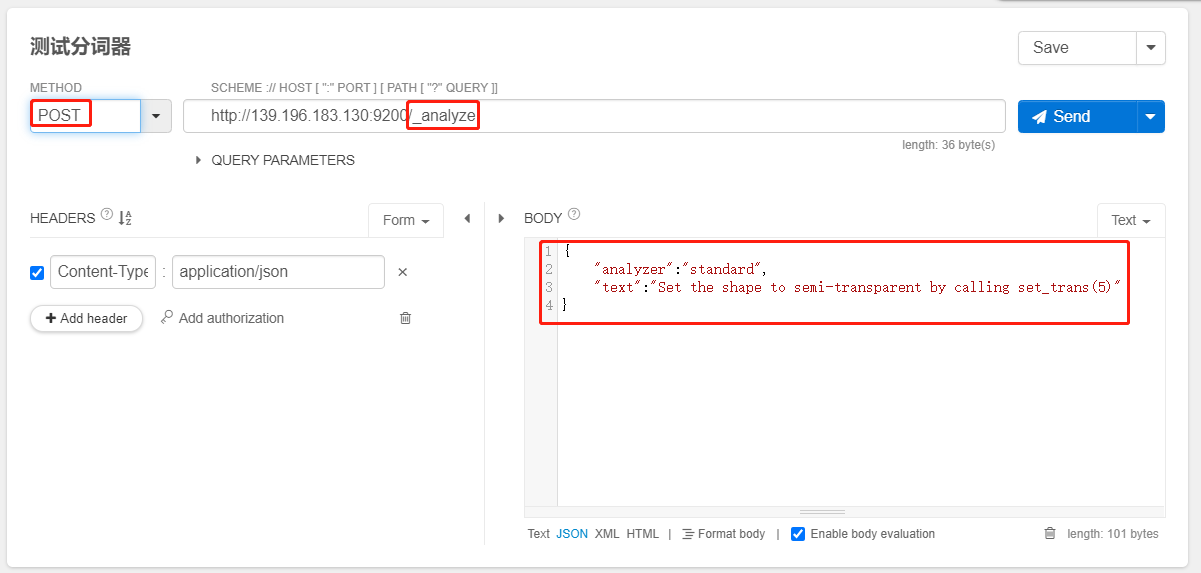
token:实际存储的 term 关键字position:此词条在原文本中的位置start_offset / end_offset:字符在原始字符串中的位置
IK分词器
背景
- 用标准的分词器对下面的文本进行分词
北京市朝阳区人民群众
{
"analyzer":"standard",
"text":"北京市朝阳区人民群众"
}
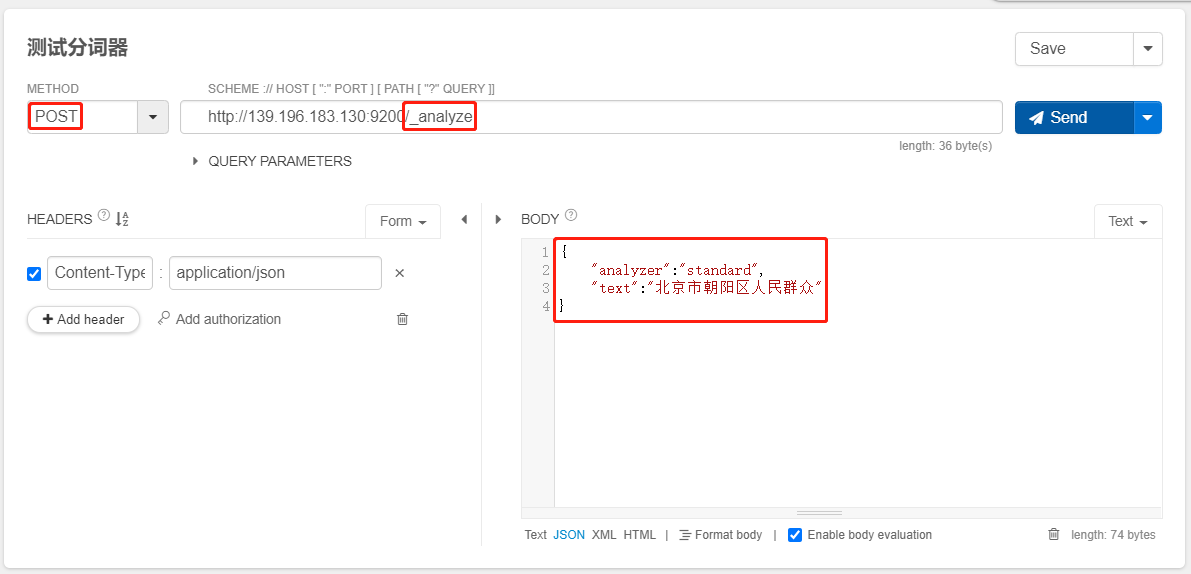
- 分词结果发现,标准的分词器相当的不标准
- 标准的分词器只对英文进行标准分词,并不支持中文,因此需要选用三方的中文分词器
IK 分词器是目前最流行的中文分词器,2012年12月 之后停止了更新,elasticsearch-analyzer-ik 依然在持续更新中
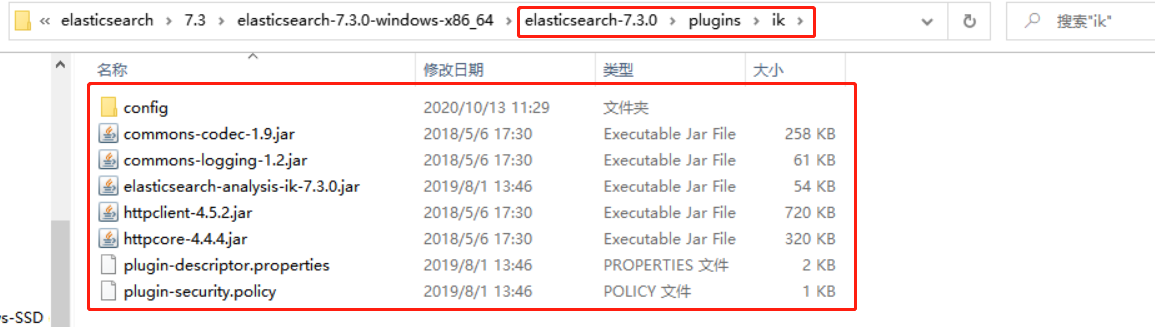
安装IK分词器
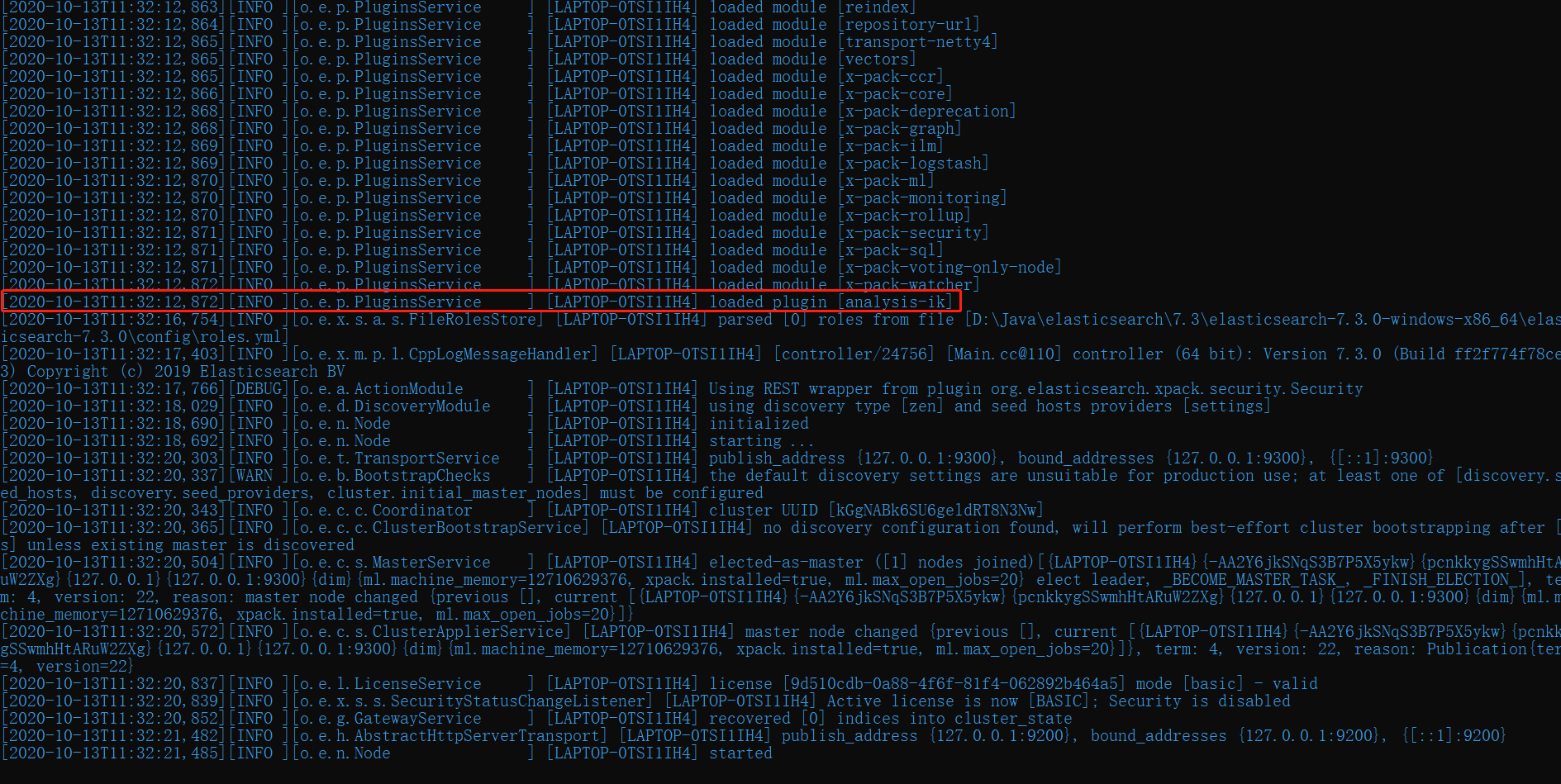
- 重启 ES,可以看到如下图加载到了我们刚刚解压的 IK
使用IK分词器
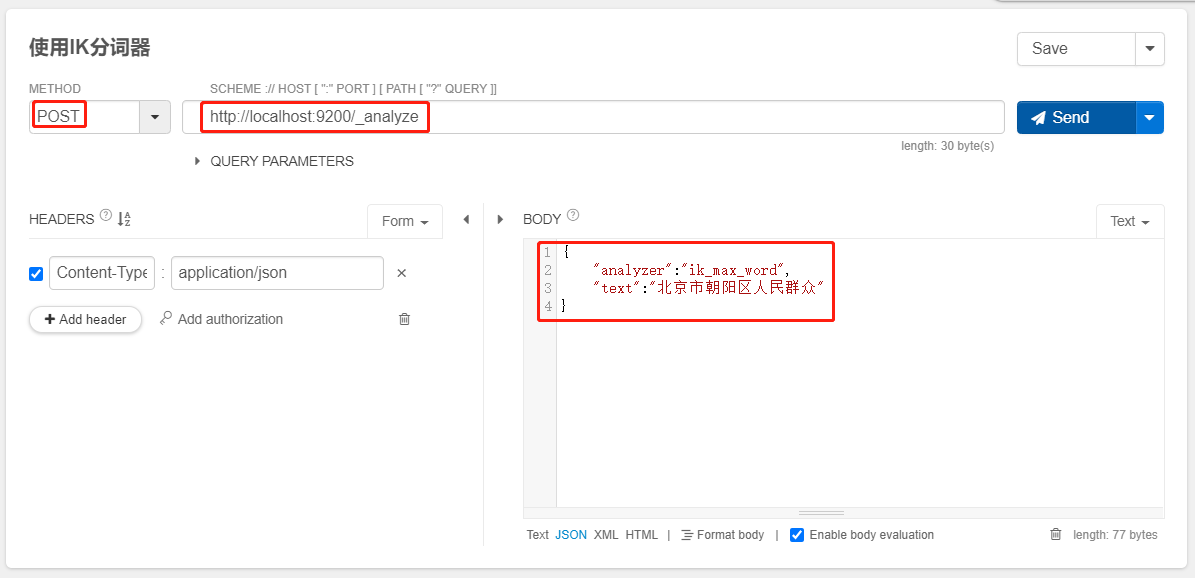
POST _analyze
{
"analyzer":"ik_max_word",
"text":"北京市朝阳区人民群众"
}
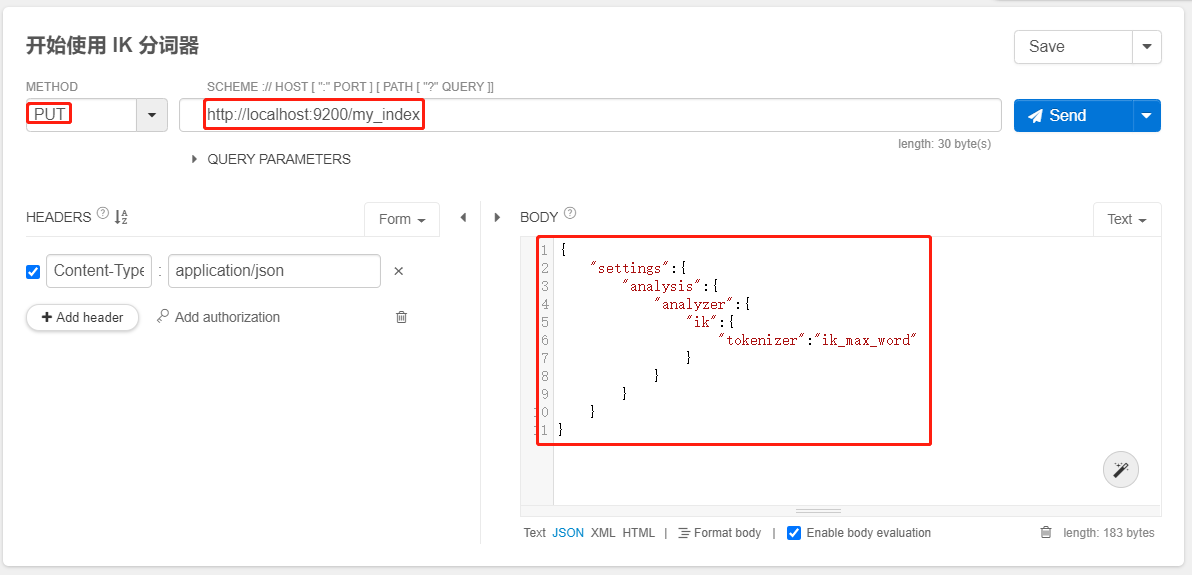
PUT /my_index
{
"settings":{
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_max_word"
}
}
}
}
}
ik_max_word:会将文本做最细粒度的拆分ik_smart:会做最粗粒度的拆分
- 一般存储时用
细粒度 存储,查询时没有特殊要求的话用 粗粒度 查询
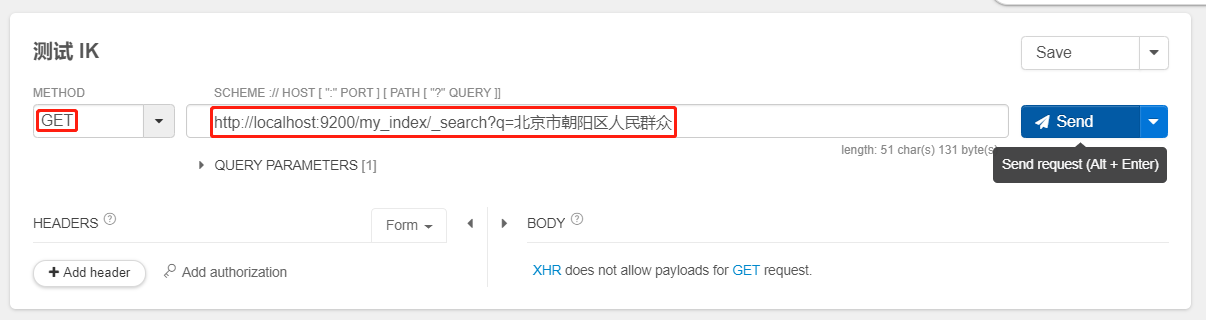
- 测试 IK
GET /my_index/_search?q=北京市朝阳区人民群众
IK 配置文件
- IK 配置文件地址:
plugins/ik/config 目录,你们的可能就不是的了,如果没有跟着我走的你们自定义的自己按照你们自定义的路径找即可
IKAnalyzer.cfg.xml:用来配置 自定义词库main.dic:IK 原生内置的中文词库,总共有 27万多条,只要是这些单词,都会被分在一起preposition.dic:介词quantifier.dic:放了一些单位相关的词,量词suffix.dic:放了一些后缀surname.dic:中国的姓氏stopword.dic:英文停用词
main.dic:包含了原生的中文词语,会按照这个里面的词语去分词stopword.dic:包含了英文的停用词
自定义词库
- 每年都会出现一些流行词,比如 鬼畜、空耳、老铁、666、233 等,一般不会出现在 IK 内置的词库中,需要自己进行扩展
- 自己补充自己的最新的词语,到 IK 的词库里面
- 修改
IKAnalyzer.cfg.xml 配置文件来进行自定义词库
- 在
config 目录下新建一个 mydict.dic 文件,在文件中添加自定义的词语
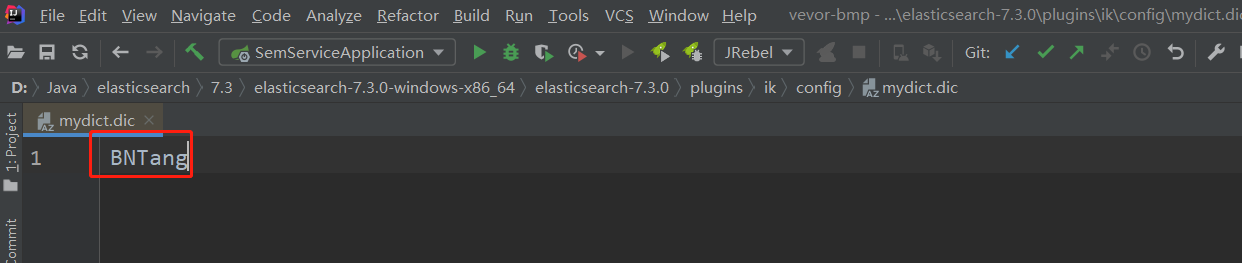
- 配置自定义词语文件修改
IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydict.dic</entry>
...
</properties>
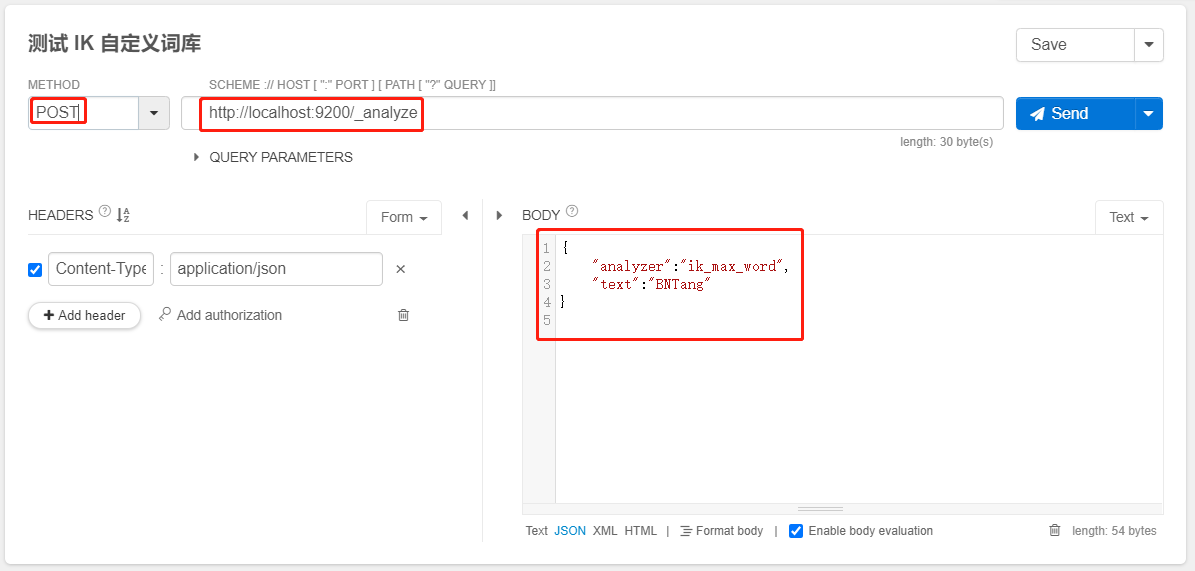
- 补充自己的词语,然后需要重启 es,即可生效
- 测试如下:
配置停用词
- 自己建立停用词库:比如 了,的,啥,么,我们可能并不想去建立索引,让人家搜索
config/extra_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,配置好,然后重启 es,配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">extra_stopword.dic</entry>
...
</properties>
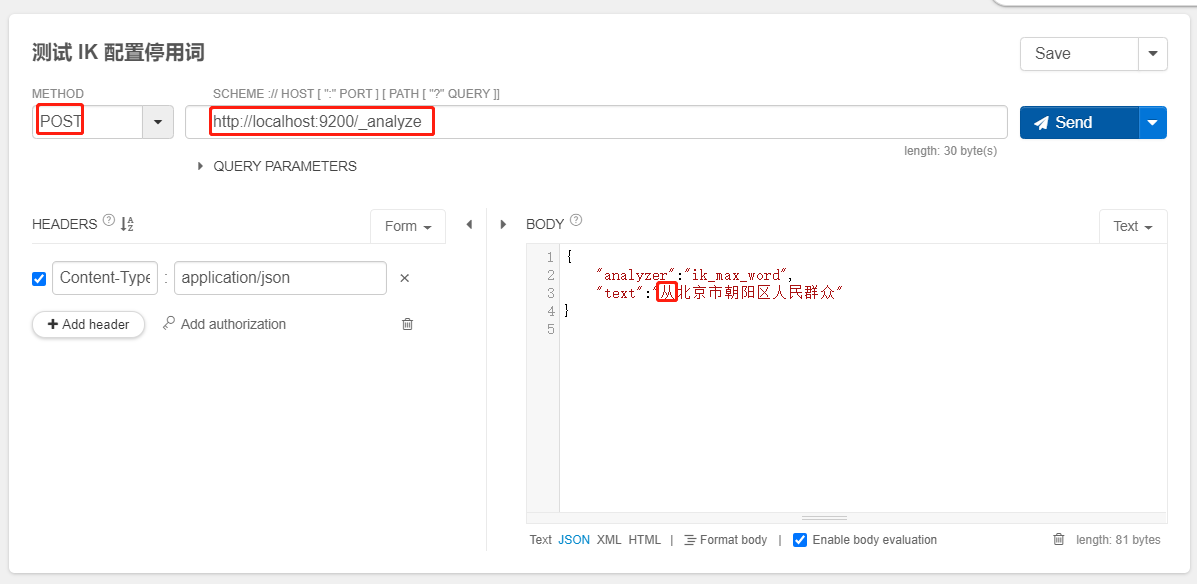
- 你可以查看测试结果,从是没有的因为在停用词中配置了从

 浙公网安备 33010602011771号
浙公网安备 33010602011771号