【学习笔记】树链剖分
浅谈dfs序与树链剖分
声明:本文萌新友好向,看这篇文章之前你只需会:
- 二叉树基本知识
- 线段树板子
- 简单 dfs
引入
我们先从一个问题引入:
如题,已知一棵包含 \(N(N \le 10^5)\) 个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作:
1 x y z,表示将树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值都加上 \(z\)。2 x y,表示求树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值之和。3 x z,表示将以 \(x\) 为根节点的子树内所有节点值都加上 \(z\)。4 x,表示求以 \(x\) 为根节点的子树内所有节点值之和。
首先,大家肯定做过序列的类似问题吧,只需要打一个线段树板子就好了。
那既然我们会做序列,我们就要想有什么办法可以将树上问题转换成序列问题?而本篇所介绍的dfs序与树链剖分就是答案。
dfs 序
我们先看较简单的操作 \(3\) 和 \(4\) 。
既然是 dfs 序,肯定要把树 dfs 一遍嘛,先随便观察遍历一颗树(红色数字为 dfs 遍历的顺序):
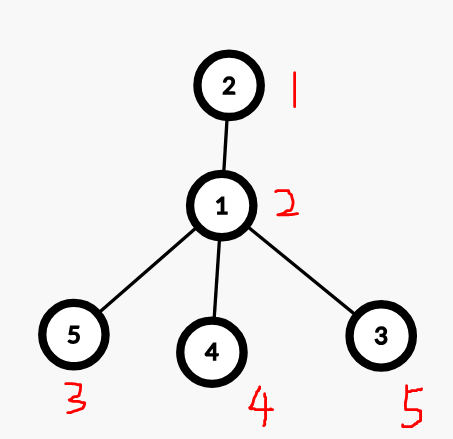
然后我们就会惊奇地发现:子树的 dfs 序是连续的!
这个也很好感性证明,dfs 性质显示了自身子树遍历完了才能遍历其他节点。
那节点 \(x\) 的子树就可以转换成 \([in_x,in_x+sz_x-1]\),\(in\) 为节点 dfs 序,\(sz\) 为节点子树大小。
操作 \(3\) 和 \(4\) 不就是区间修改和区间查询了吗?线段树,启动。
最后我们来理一下这一部分的过程:
- 先 dfs 遍历一遍树,求出每个节点的 dfs 序和子树大小。
void dfs(int u){
b[u]=1;
in[u]=++cnt;
siz[u]=1;
for(auto it:v[u]){
if(!b[it]){
dfs(it);
siz[u]+=siz[it];
}
}
}
- 然后码个线段树板子,操作转换成区间查询和修改就行了。
update(1,in[x],in[x]+sz[x]-1,z);
query(1,in[x],in[x]+sz[x]-1);
注意:本篇文章线段树均是根据 \(dfs\) 序建的,不是源节点编号,不要把 \(in_x\) 写成 \(x\)。
树链剖分
以上其实是铺垫,现在才进入正题。
操作 \(3\) 和操作 \(4\) 是解决了,但是 \(1\) 和 \(2\) 的查询修改路径怎么办呢?
别忘了,我们的本质是将树上查询修改信息转换成连续的一段区间。
树链剖分(本篇讲解默认重链剖分)顾名思义就是将一条路径拆分成不超过 \(𝑂(\log𝑛)\) 条连续的链,且每条链上的点深度互不相同。
条连续的链,且每条链上的点深度互不相同。
如何实现呢,我们先来定义几个概念:
一个结点的子节点中子树 \(sz\) 最大的子结点为重子节点。每个节点道重子节点的边称之为重边,其他边和点分别称之为轻边与轻子节点。
则若干条首尾衔接的重边构成重链,落单节点也当作一条重链。
太复杂了没看懂?来张图理解一下:
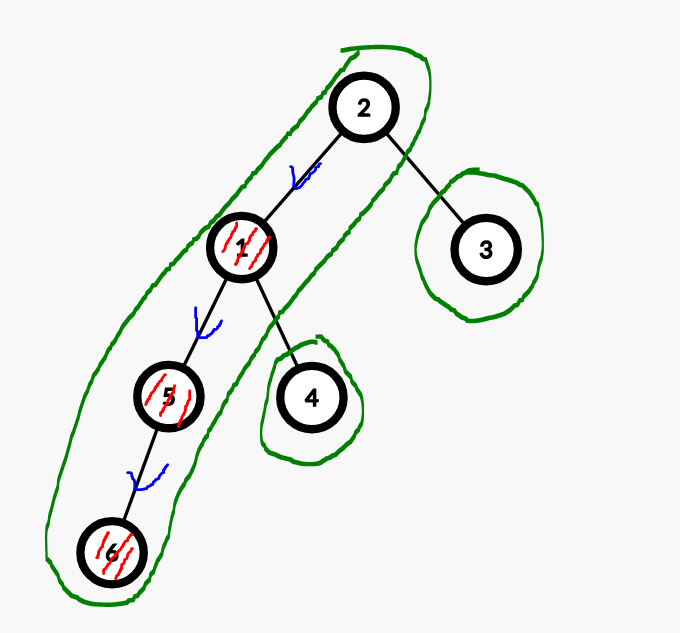
(红色为重子节点,蓝色为重边,绿色为重链)。
至于为什么这么分一定至多 \(\log n\) 条链,请读者自行查阅相关资料。
我们先 dfs 一遍处理需要的东西:
- \(sz[x]\) :\(x\) 的子树大小
- \(f[x]\):\(x\) 的父亲(过会会用)
- \(d[x]\):\(x\) 的度数(过会会用)
- \(son[x]\):\(x\) 的重儿子
void dfs1(int u,int fa){
sz[u]=1;
f[u]=fa;
for(int v:ve[u]){
if(v==fa) continue;
d[v]=d[u]+1;
dfs1(v,u);
sz[u]+=sz[v];
son[u]=(sz[v]>sz[son[u]]?v:son[u]);
}
}
讲到这里,我们一直在下定义,该怎么体现连续区间这一特点呢?
容易发现,如果以优先遍历重儿子的顺序 dfs,重链的 dfs 序是连续的。
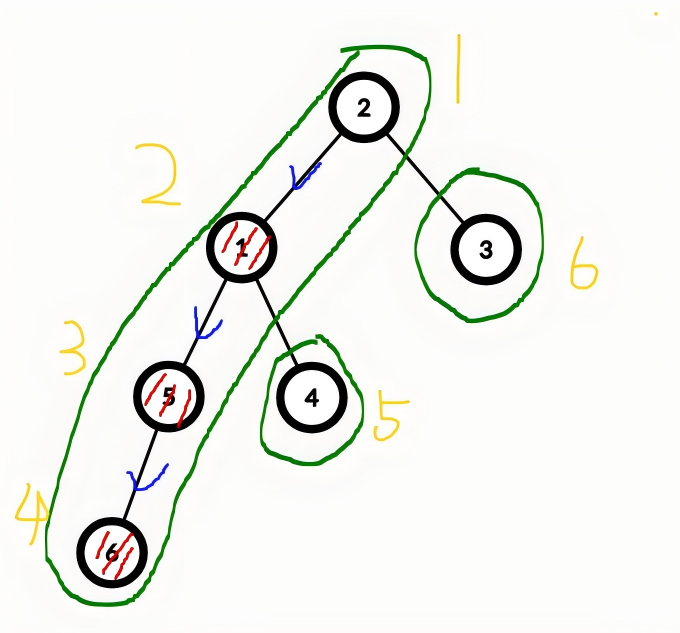
那就方便我们处理查询和修改了,再优先重儿子 dfs 一次,顺便计算 \(top_x\) : \(x\) 所处重链上的链头(例如 \(top_5 = 2\))(过会会用)
void dfs2(int u,int fa,int tt){
top[u]=tt;
in[u]=++tot;
if(son[u]){//优先遍历重儿子
dfs2(son[u],u,tt);//重儿子传递链头
}
for(int v:ve[u]){
if(v==fa||v==son[u]) continue;
dfs2(v,u,v);//轻儿子单独开一个链头
}
}
预处理好后,我们就要开始执行修改和查询 \(x,y\) 操作了。
如果 \(x\) 和 \(y\) 在一条重链上,那么就可以直接区间查询区间修改了。
如果不在呢?那深度大的链直接“跳”上来就好了,因为 \(x\) 到 \(y\) 的路径一定包含链头到 \(x\) 这一部分,修改或查询完直接将 \(x\) 跳到链头的父亲就行了。
反复执行这个操作,直到 \(x\) 和 \(y\) 在一条重链上。
void add(int u,int v,int w){
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]]) swap(u,v);//保证深度大跳到深度小
update(1,in[top[u]],in[u],w);
u=f[top[u]];
}
if(d[u]>d[v]) swap(u,v);//保证一下最后查询
update(1,in[u],in[v],w);//注意不要写成 u 和 v
}
int ask(int u,int v){
int ans=0;
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]]) swap(u,v);
ans+=query(1,in[top[u]],in[u]);
if(ans>=mod) ans-=mod;
u=f[top[u]];
}
if(d[u]>d[v]) swap(u,v);
ans+=query(1,in[u],in[v]);
if(ans>=mod) ans-=mod;
return ans;
}
那么我们整合起来,这道题就 AC 了。算法核心即为将陌生的树上问题转换为我们熟悉的区间问题。
#include<bits/stdc++.h>
#define int long long
#define PII pair<int,int>
#define INF 1e12
using namespace std;
const int N=1e5+5;
int n,m,root,mod,a[N];
struct st{
int l,r,sum,tag;
}tree[N<<2];
int ls(int p){return p<<1;}
int rs(int p){return p<<1|1;}
void push_up(int p){
tree[p].sum=(tree[ls(p)].sum+tree[rs(p)].sum)%mod;
}
void build(int p,int l,int r){
tree[p].l=l,tree[p].r=r;
if(l==r){
return;
}
int mid=(l+r)>>1;
build(ls(p),l,mid);
build(rs(p),mid+1,r);
push_up(p);
}
void push_down(int p){
if(tree[p].tag){
tree[ls(p)].tag+=tree[p].tag;
if(tree[ls(p)].tag>=mod)tree[ls(p)].tag-=mod;
tree[ls(p)].sum+=tree[p].tag*(tree[ls(p)].r-tree[ls(p)].l+1);
tree[ls(p)].sum%=mod;
tree[rs(p)].tag+=tree[p].tag;
if(tree[rs(p)].tag>=mod)tree[rs(p)].tag-=mod;
tree[rs(p)].sum+=tree[p].tag*(tree[rs(p)].r-tree[rs(p)].l+1);
tree[rs(p)].sum%=mod;
tree[p].tag=0;
}
}
void update(int p,int l,int r,int d){
if(l<=tree[p].l&&tree[p].r<=r){
tree[p].sum+=d*(tree[p].r-tree[p].l+1);
tree[p].sum%=mod;
tree[p].tag+=d;
if(tree[p].tag>=mod) tree[p].tag-=mod;
return;
}
push_down(p);
int mid=(tree[p].l+tree[p].r)>>1;
if(l<=mid) update(ls(p),l,r,d);
if(r>mid) update(rs(p),l,r,d);
push_up(p);
}
int query(int p,int l,int r){
if(l<=tree[p].l&&tree[p].r<=r){
return tree[p].sum;
}
push_down(p);
int mid=(tree[p].l+tree[p].r)>>1,cnt=0;
if(l<=mid) cnt=query(ls(p),l,r);
if(r>mid) cnt+=query(rs(p),l,r);
if(cnt>=mod) cnt-=mod;
return cnt;
}
vector<int> ve[N];
int tot,sz[N],son[N],top[N],in[N],d[N],f[N];
void dfs1(int u,int fa){
sz[u]=1;
f[u]=fa;
for(int v:ve[u]){
if(v==fa) continue;
d[v]=d[u]+1;
dfs1(v,u);
sz[u]+=sz[v];
son[u]=(sz[v]>sz[son[u]]?v:son[u]);
}
}
void dfs2(int u,int fa,int tt){
top[u]=tt;
in[u]=++tot;
if(son[u]){
dfs2(son[u],u,tt);
}
for(int v:ve[u]){
if(v==fa||v==son[u]) continue;
dfs2(v,u,v);
}
}
void add(int u,int v,int w){
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]]) swap(u,v);
update(1,in[top[u]],in[u],w);
u=f[top[u]];
}
if(d[u]>d[v]) swap(u,v);
update(1,in[u],in[v],w);
}
int ask(int u,int v){
int ans=0;
while(top[u]!=top[v]){
if(d[top[u]]<d[top[v]]) swap(u,v);
ans+=query(1,in[top[u]],in[u]);
if(ans>=mod) ans-=mod;
u=f[top[u]];
}
if(d[u]>d[v]) swap(u,v);
ans+=query(1,in[u],in[v]);
if(ans>=mod) ans-=mod;
return ans;
}
signed main(){
//freopen(".in","r",stdin);
//freopen(".out","w",stdout);
ios::sync_with_stdio(false);
#define da cin
#define na cout
#define lv tie(0)
da.lv;
na.lv;
#undef da
#undef na
#undef lv
cin>>n>>m>>root>>mod;
for(int i=1;i<=n;i++){
cin>>a[i];
}
for(int i=1,u,v;i<n;i++){
cin>>u>>v;
ve[u].push_back(v);
ve[v].push_back(u);
}
dfs1(root,0);
dfs2(root,0,root);
build(1,1,n);
for(int i=1;i<=n;i++){
update(1,in[i],in[i],a[i]);
}
while(m--){
int op,x,y,z;
cin>>op;
if(op==1){
cin>>x>>y>>z;
add(x,y,z);
}
else if(op==2){
cin>>x>>y;
cout<<ask(x,y)<<"\n";
}
else if(op==3){
cin>>x>>y;
update(1,in[x],in[x]+sz[x]-1,y);
}
else{
cin>>x;
cout<<query(1,in[x],in[x]+sz[x]-1)<<"\n";
}
// for(int i=1;i<=n;i++){
// cout<<query(1,in[i],in[i])<<" ";
// }
// cout<<"\n";
}
return 0;
}
拓展
树链剖分还可以用极小的常数 \(\log n\) 求 \(lca\),就可以摆脱倍增了。
用类似的方法往上跳,一条链上时深度最小的即为 \(lca\)。
一时找不到代码了,就不放了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号