[GenAI] 重新认识Agent
什么是 Agent

基础篇Agent概念
不是指的 AI 智能体,而是指代理服务器。
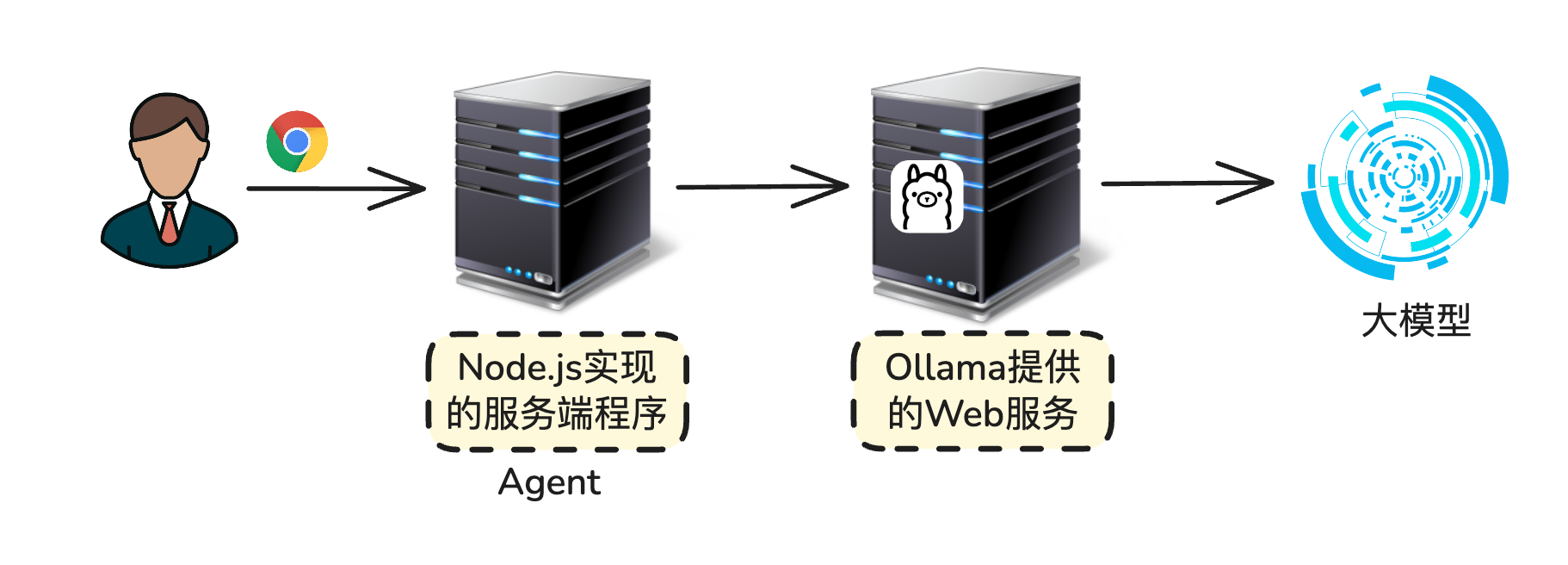
代理服务器充当用户和模型交流的中间人。
Agent:
- 狭义:代理服务器
- 广义:AI智能体(AI Agent)
什么是AI Agent
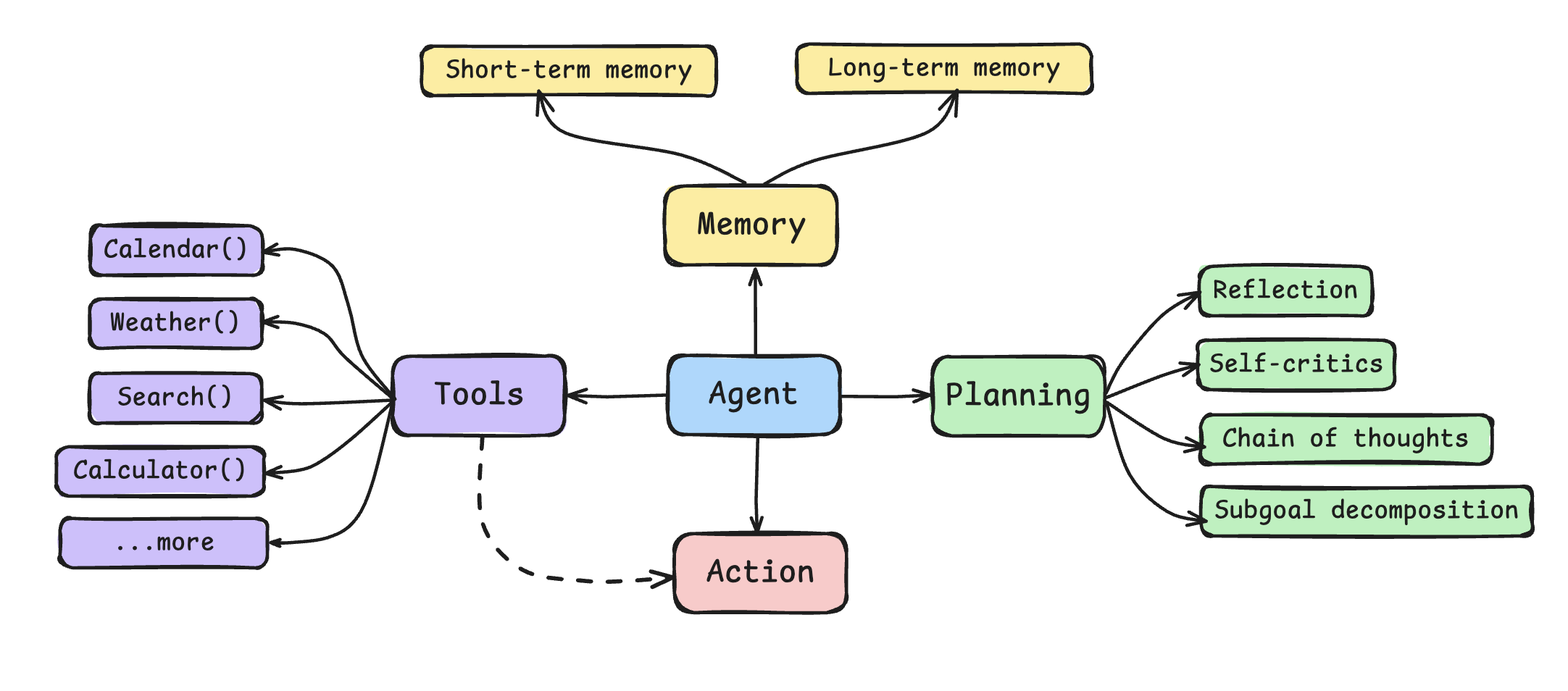
AI Agent,中文称之为“AI智能体”,本质上是能自主感知环境,进行规划与决策,并最终执行行动的智能系统。
整个系统基于四大核心能力:
- 规划
- 工具使用
- 行动执行
- 记忆管理
1. 规划(Planning)
这可以看作是智能体的认知引擎,它让系统不再是单纯被动的响应,而是具备主动思考与解决问题的能力。
规划包含下面几个环节:
- 深入理解用户意图与任务目标
- 将复杂任务分解成可执行步骤
- 制定战略行动与执行时间表
- 根据变化与反馈进行动态调整
2. 工具使用(Tools)
让智能体能够访问外部资源。
- 熟悉并管理各种工具集
- 针对特定任务智能选择工具
- 对多种工具整合与编排
3. 行动执行(Action)
这部分强调“把计划真正落地”的机制:根据当前状态选择下一步动作,调用工具或 LLM,并根据返回结果更新状态、决定是否继续。
4. 记忆管理(Memory)
让智能体“记得住”,但又不过载。常见分层:
- 短期记忆(会话级):最近若干轮对话/步骤的摘要,用于保持上下文连续
- 长期记忆(知识级):文档/知识库向量化检索(RAG)+ 命中片段的引用
Planning
Planning,也就是规划阶段,常用的思考方式有:
- Reflection
- Self-critics
- Chain of thoughts
- Subgoal decomposition
1. Reflection
让模型反思、回顾的方式。
模型在执行过程中或结束后,会回看自己的执行过程,总结错误原因与改进策略,并据此修改下一步计划或“经验库”。它关注“为什么没成 / 还能怎么更好”,偏过程级。
常见实现方式:
- Step-wise Reflection:每完成/失败一步就反思一次。
- Post-hoc Reflection:任务末尾做一次集中复盘,生成“经验片段”写入记忆。
- Memory-based Reflection:把高价值的反思写入长期记忆(向量库/摘要),供类似任务召回。
提示模板示例:
你刚完成(或失败)了步骤:{step_summary}
请反思:
1) 目的与偏差?
2) 证据/错误点?
3) 下一步的改进指令(可直接执行的动作或重试参数)。
只输出:{"reason": "...", "fix": "...", "next_action": "..."}
注意点:
-
设步数/时间上限与重试上限,避免“反思-空转”死循环。
-
把反思结果结构化,便于控制器读取。
-
任务:调用获取天气的工具
Action: get_current_weather Args: {"location":"北京","unit":"centigrade"}"不支持的 unit 类型,请传入 celsius / fahrenheit" -
接下来就需要对上面的结果进行反思
你是“反思器”。给定一次工具调用的【动作尝试】和【观察结果】, 请输出结构化的修正建议,JSON ONLY。 【动作尝试】 tool: get_current_weather args: {"location":"北京","unit":"centigrade"} 【观察结果】 不支持的 unit 类型,请传入 celsius / fahrenheit 请只输出如下 JSON: { "reason": "出错原因的简要描述", "fix": "如何修复(人类可读)", "next_action": "retry | replan | abort", "patch": { "用于重试时的参数修正,可选" } } -
大模型就会进行反思,并且给出一个反思结果
{ "reason": "参数 unit=centigrade 不在允许列表", "fix": "将 'centigrade' 映射为 'celsius';其他参数保持不变", "next_action": "retry", "patch": { "unit": "celsius" } } -
反思控制器,针对模型的反思结果来做下一个步骤
async function reflectAndHandle(attempt, observation) { const prompt = /* 上面的反思提示,插入 attempt/observation */; const text = await llm.invoke(prompt); // 返回 JSON 字符串 const reflection = JSON.parse(text); // {reason, fix, next_action, patch?} if (reflection.next_action === "retry") { const patchedArgs = { ...attempt.args, ...reflection.patch }; return await tools[attempt.tool](patchedArgs); // 立刻带修正参数重试 } if (reflection.next_action === "replan") { return await replanner({...context, reason: reflection.reason}); // 触发重规划 } if (reflection.next_action === "abort") { throw new Error(`终止任务:${reflection.reason}`); } }
-
-
只把高价值反思入库(设打分阈值),否则记忆会淤积噪声。
2. Self-critics
让模型扮演审稿人,对“当前答案草稿”按清单逐项检查并给出修改意见,再据此修订。它关注“产物是否过关”,偏结果级。和 Reflection 的区别:
- Reflection 看“过程是否跑对”;Self-critics 看“最终交付是否合格”。
- Reflection 产出“下一步计划”;Self-critics 产出“修订后的答案”。
常见实现方式:
- 同模两段式:先“解题者草稿”,再“评审者清单”,最后“修订版”。
- 双模型(或不同温度):一个负责产出,一个更严苛/低温度负责挑错。
- 规则+模型混合:静态校验(schema/单元测试/事实核对)先跑,模型只补充语义性缺陷。
提示模板示例:
草稿:{draft}
请按清单评审:正确性、可证据、覆盖度、风格/格式。
输出 JSON:
{"defects": ["...","..."], "patch_plan": "...", "final_answer": "..."}
注意点:
- 用可执行检查(单测/数据校验/引用查验)辅助评审,减少“凭空挑错”。
- 控制评审迭代次数(1~2 轮就足够了),防止“无休止打磨”。
- 对“需要证据”的结论,强制要求出处/工具调用记录。
3. Chain of thoughts
CoT,中文为“思维链”,该模式让模型在给答案前,先分步写出推理/计算/检查。它能显著提升多步逻辑任务的稳定性。适用于算术、逻辑推理、多跳问答、要“中间结论”的任务。但不涉及外部检索或行动(那是 ReAct/工具调用的事情)。
实现过程:
-
触发:在提示中要求“逐步思考(Step-by-step)”,或 few-shot 示范“步骤→结论”的格式。
提示模板示例:
请分步骤推理并给出最终答案。 格式: - Steps: 步骤1/2/3(简短) - Answer: 最终答案 -
自一致性(Self-Consistency):让模型在同一题目上独立推理多次(温度>0),只收集每次的“最终答案”,然后用投票/统计选出最可能正确的那一个。
-
题目:商店一批苹果分给 4 个班,每班 7 个,还剩 3 个;共有多少个?
多次的采样结果:
[31, 31, 31, 30, 31],投票:31占 4/5 ⇒ 选31。 -
示例代码:
import { ChatOpenAI } from "@langchain/openai"; const llm = new ChatOpenAI({ model: "gpt-4o-mini", temperature: 0.9 }); const PROMPT = (q) => [ { role: "system", content: "请先逐步思考,再给出最终答案,最后一行用 `Answer: <值>` 格式。" }, { role: "user", content: q } ]; /** * 假设外部已创建好一个可用的 LLM 客户端 `llm` * 且有一个 PROMPT(question) 能返回“系统+用户”消息数组, * 其中系统提示会要求模型: * 1) 先逐步思考(CoT) * 2) 最后一行用 `Answer: <值>` 给出最终答案 */ // 1) 采样一次:向模型发一次请求,返回“整段文字输出” async function sampleOnce(question) { // llm.invoke(...) 返回的是一个 Message(里头的 .content 是文本) const msg = await llm.invoke(PROMPT(question)); return msg.content; // 例如:多行字符串,包含 Steps... 和最后的 `Answer: ...` } // 2) 抽取“最终答案”:从整段文本中截取 `Answer: ...` 后面的内容 function extractAnswer(text) { // 使用正则匹配 “Answer: <非换行的一串字符>” // - `i` 忽略大小写,所以 `answer:` 也能匹配 // - 只取第一个分组 ([^\n]+) 作为答案主体 const m = String(text).match(/Answer:\s*([^\n]+)/i); return m ? m[1].trim() : null; // 匹配不到就返回 null } /** * 3) 多数表决:对多次采样得到的答案做投票,返回得票最高的那个 * @param {string[]} answers 多次采样后抽取出的“最终答案”数组 * @param {object} opts * @param {boolean} opts.numeric 是否将答案视为“数值”,做归一化计票 * * numeric = true 的含义: * - 在数字类问题里,同一个答案可能有不同写法,比如 '9' / '09' / '9.0' * - 我们希望它们被当成“相同答案”来计票 * - 于是把字符串先转 Number 再转回字符串:'9.0' -> 9 -> '9','09' -> 9 -> '9' * - 注意:如果是 '9 个' 这种非纯数字,Number('9 个') 会变 NaN(会计为 'NaN') * 如需更鲁棒,可用更宽松的解析(见下文“可选改进”) */ function majorityVote(answers, opts = {}) { // 针对“数字题”的简单归一化规则:字符串 -> Number -> 字符串 const norm = (a) => (opts.numeric ? String(Number(a)) : a); // tally 是一个 Map:key 为“归一化后的答案字符串”,value 为计数 const tally = new Map(); for (const a of answers) { if (!a) continue; // 跳过 null / 空串 const key = norm(a); // 归一化(数字题会把 '9.0'/'09' 归一到 '9') tally.set(key, (tally.get(key) || 0) + 1); // 累计票数 } // 从 tally 中找出“票数最多”的那个答案 let best = null; let max = -1; for (const [k, v] of tally.entries()) { if (v > max) { max = v; best = k; // k 是“归一化后的答案字符串” } } // 返回:最终答案(best)与完整计票表(tally) return { answer: best, tally }; } /** * 4) 自一致性主流程:并行采样 k 次 → 抽取答案 → 多数表决 * @param {string} question 题目/问题 * @param {number} k 采样次数(默认 5) * @param {boolean} numeric 是否把答案当做“数字”来归一化计票 * 当你的题目是数字类(数学/统计/算术)时,不同采样可能给出等价的数值但写法不同: * "9" / "9.0" / "09" * 如果不开 numeric,这三种写法会被当成三个不同字符串计票,可能导致误判为“分散意见”。 * 开了 numeric: true 后,会把每个答案先 Number(...) 再 String(...) * 从而统一到 "9",计票更稳。 */ export async function selfConsistency(question, k = 5, numeric = false) { // 并发发起 k 次请求(Promise.all),拿到 k 个“整段输出” const samples = await Promise.all( [...Array(k)].map(() => sampleOnce(question)) ); // 把“整段输出”映射为“最终答案”(只取 `Answer: ...`) const answers = samples.map(extractAnswer); // 多数表决:numeric 决定是否数字归一化计票 const { answer, tally } = majorityVote(answers, { numeric }); // 返回:最终答案、每次的答案列表、计票表、原始整段输出(便于审计) return { answer, answers, tally, samples }; } // 用例 const q = "盒子里有 5 颗红球和 7 颗蓝球,取走 3 颗蓝球后还剩多少颗球?"; const res = await selfConsistency(q, 5, true); console.log(res);
-
-
展示策略:对用户只展示“结论/要点”,把长推理藏在系统/后台,减少噪声。
注意:
- 限制步长与字数,避免冗长胡思。
- 给结构化框架(编号/小标题)few shot,降低漫游。
4. Subgoal decomposition
翻译成中文就是“子目标分解”。顾名思义:把宏大目标拆成可执行、可验证的小目标(带先后关系/依赖),并给每个子目标指派工具/检查。适用于任务跨度大、步骤多、依赖复杂的场景(旅行筹划、数据管道、报表自动化)。
实现方式:
- Plan-then-Execute:先产出计划清单,再逐步执行。
- DAG/状态机:显式维护依赖,失败可回退重试或Replan。
-
DAG(有向无环图):把一个大任务拆成很多子任务节点(Node),用有向边表示“谁依赖谁”。“无环”保证你能按依赖顺序往前跑。(LangGraph)
-
状态机(State Machine):给每个节点定义明确的生命周期状态与转移条件,让执行可控可观测。
-
显式维护依赖:依赖关系写在图里(代码/配置里看得见),调度器只运行“所有前置都成功”的节点,失败就阻断后续依赖节点。
目标:输出“上海 3 日游”行程单。拆分成几个子任务,部分子任务之间会有依赖关系:
[PickCity] → [GetFlights] → [Itinerary] └────→ [GetHotels] ──┘PickCity:确定出发/目的地与日期GetFlights:查航班(依赖 PickCity)GetHotels:查酒店(依赖 PickCity)Itinerary:汇总航班+酒店,生成行程(依赖二者)
-
失败可回退重试或 Replan:节点(图里面的一个任务节点)失败时有三种“兜底策略”:
- 重试(Retry):同一节点再次执行(带退避、改参数、换副通道)。
- 回退(Rollback):若该节点产生副作用(下单、写库),先撤销/抵消,把系统退回到安全状态。
- Replan(重规划):改图——替换失败节点、插入新的“补救节点”、或改路径;然后继续调度。
ReAct模式
AI 智能体核心能力:
- 规划
- 行动执行
- 工具使用
- 记忆管理
ReAct 模式则是将这些能力具体落地的一种形式。
ReAct 是两个单词的组合:Reason + Act,也就是“推理 + 行动”的缩写。
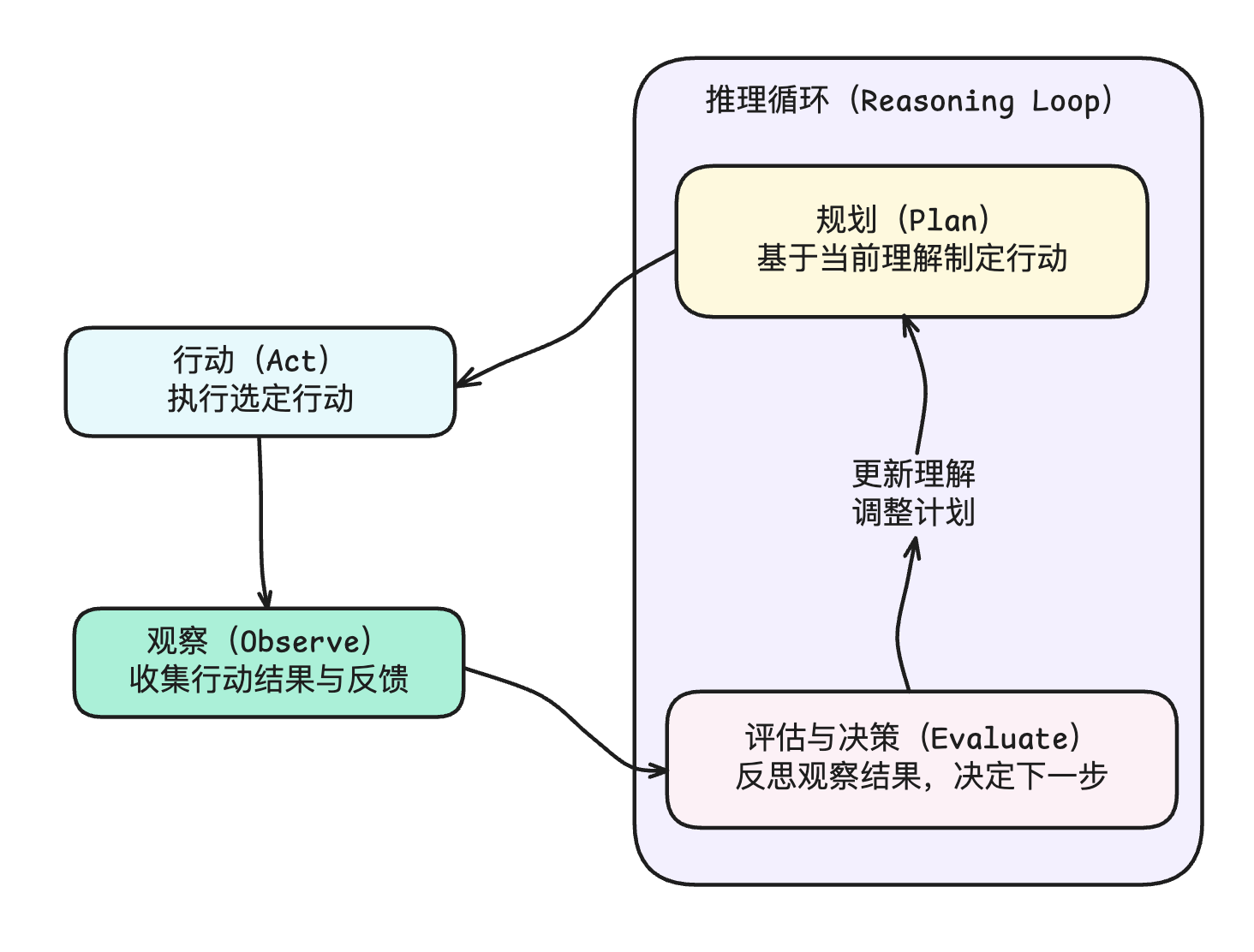
ReAct 的完整流程如下:
1. 规划
整个循环从规划(Plan)阶段开始。在这个阶段,AI 智能体通过推理来理解当前情况,分析任务需求,并设计潜在的行动方案。
此阶段利用大语言模型的自然语言处理和生成能力来生成推理轨迹。
在规划阶段,需要做如下的事情:
- 解释用户请求或目标
- 从记忆中提取相关信息
- 制定计划或策略
- 选择潜在的工具
- 证明所选行动的合理性
2. 行动计划
在完成规划阶段后,AI 智能体进入行动阶段。在该阶段,智能体执行计划中的一个或多个任务,并且通过与环境交互或者利用外部工具来收集信息。
此阶段常见任务如下:
-
选择要执行的特定任务
-
格式化并执行行动:准备所选任务所需的输入参数,并使用适当的工具或接口执行它。
-
等待任务完成
3. 观察
接下来是观察阶段。该阶段智能体会处理任务得到的结果,并进行反馈。
主要流程有:
- 接收任务的输出结果
- 解析和解释观察结果(Reflection)
- 将观察结果整合到记忆中
4. 评估与决策
这是最后一个阶段,在该阶段智能体会花时间反思观察结果,评估当前行动的成功程度,并决定下一个步骤应该是啥。
具体要做的事情如下:
- 评估先前行动的成功程度(Self-critics)
- 识别错误
- 更新内部状态
- 决定下一步行动
- 生成推理轨迹
该阶段结束后,会重新回到规划阶段,计划和执行下一个行动。
-EOF-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号