10.22
10/22
M:322. 零钱兑换
题意描述:
给你一个整数数组
coins,表示不同面额的硬币;以及一个整数amount,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回
-1。你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11 输出:3 解释:11 = 5 + 5 + 1示例 2:
输入:coins = [2], amount = 3 输出:-1示例 3:
输入:coins = [1], amount = 0 输出:0提示:
1 <= coins.length <= 121 <= coins[i] <= 2^31 - 10 <= amount <= 104
思路
在动态规划:518.零钱兑换II (opens new window)中我们已经兑换一次零钱了,这次又要兑换,套路不一样!
题目中说每种硬币的数量是无限的,可以看出是典型的完全背包问题。
动规五部曲分析如下:
- 确定dp数组以及下标的含义
dp[j]:凑足总额为j所需钱币的最少个数为dp[j]
- 确定递推公式
凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] + 1就是dp[j](考虑coins[i])
所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最小的。
递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
- dp数组如何初始化
首先凑足总金额为0所需钱币的个数一定是0,那么dp[0] = 0;
其他下标对应的数值呢?
考虑到递推公式的特性,dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖。
所以下标非0的元素都是应该是最大值。
代码如下:
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
- 确定遍历顺序
本题求钱币最小个数,那么钱币有顺序和没有顺序都可以,都不影响钱币的最小个数。
所以本题并不强调集合是组合还是排列。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
在动态规划专题我们讲过了求组合数是动态规划:518.零钱兑换II (opens new window),求排列数是动态规划:377. 组合总和 Ⅳ (opens new window)。
所以本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的!
那么我采用coins放在外循环,target在内循环的方式。
本题钱币数量可以无限使用,那么是完全背包。所以遍历的内循环是正序
综上所述,遍历顺序为:coins(物品)放在外循环,target(背包)在内循环。且内循环正序。
- 举例推导dp数组
以输入:coins = [1, 2, 5], amount = 5为例
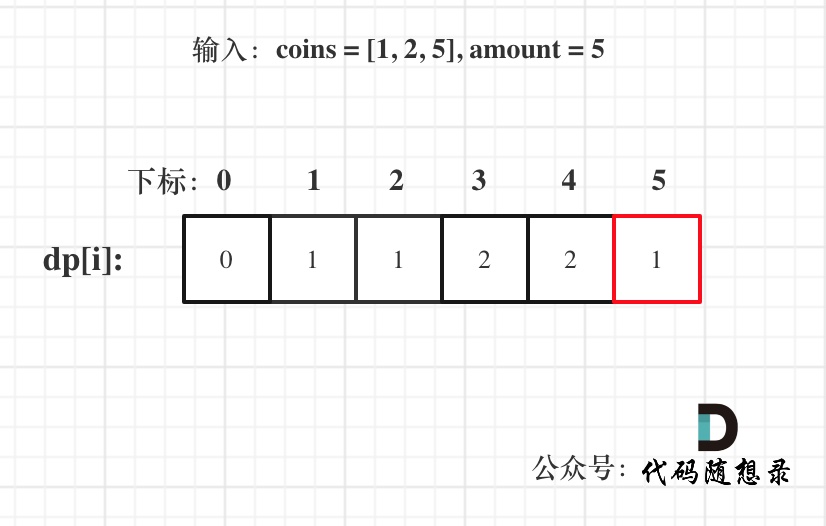
dp[amount]为最终结果。
以上分析完毕,C++ 代码如下:
// 版本一
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
if (dp[j - coins[i]] != INT_MAX) { // 如果dp[j - coins[i]]是初始值则跳过
dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};
- 时间复杂度: \(O(n * amount)\),其中 n 为 coins 的长度
- 空间复杂度: \(O(amount)\)
对于遍历方式遍历背包放在外循环,遍历物品放在内循环也是可以的,我就直接给出代码了
// 版本二
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i <= amount; i++) { // 遍历背包
for (int j = 0; j < coins.size(); j++) { // 遍历物品
if (i - coins[j] >= 0 && dp[i - coins[j]] != INT_MAX ) {
dp[i] = min(dp[i - coins[j]] + 1, dp[i]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};
- 同上
总结
细心的同学看网上的题解,可能看一篇是遍历背包的for循环放外面,看一篇又是遍历背包的for循环放里面,看多了都看晕了,到底两个for循环应该是什么先后关系。
能把遍历顺序讲明白的文章几乎找不到!
这也是大多数同学学习动态规划的苦恼所在,有的时候递推公式很简单,难在遍历顺序上!
但最终又可以稀里糊涂的把题目过了,也不知道为什么这样可以过,反正就是过了。
那么这篇文章就把遍历顺序分析的清清楚楚。
动态规划:518.零钱兑换II (opens new window)中求的是组合数,动态规划:377. 组合总和 Ⅳ (opens new window)中求的是排列数。
而本题是要求最少硬币数量,硬币是组合数还是排列数都无所谓!所以两个for循环先后顺序怎样都可以!
这也是我为什么要先讲518.零钱兑换II 然后再讲本题即:322.零钱兑换,这是Carl的良苦用心那。
相信大家看完之后,对背包问题中的遍历顺序有更深的理解了。
M:279.完全平方数
题意描述:
给你一个整数
n,返回 和为n的完全平方数的最少数量 。完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,
1、4、9和16都是完全平方数,而3和11不是。示例 1:
输入:n = 12 输出:3 解释:12 = 4 + 4 + 4示例 2:
输入:n = 13 输出:2 解释:13 = 4 + 9提示:
1 <= n <= 104
思路
可能刚看这种题感觉没啥思路,又平方和的,又最小数的。
我来把题目翻译一下:完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品?
感受出来了没,这么浓厚的完全背包氛围,而且和昨天的题目动态规划:322. 零钱兑换 (opens new window)就是一样一样的!
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[j]:和为j的完全平方数的最少数量为dp[j]
- 确定递推公式
dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] + 1 便可以凑成dp[j]。
此时我们要选择最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]);
- dp数组如何初始化
dp[0]表示 和为0的完全平方数的最小数量,那么dp[0]一定是0。
有同学问题,那0 * 0 也算是一种啊,为啥dp[0] 就是 0呢?
看题目描述,找到若干个完全平方数(比如 1, 4, 9, 16, ...),题目描述中可没说要从0开始,dp[0]=0完全是为了递推公式。
非0下标的dp[j]应该是多少呢?
从递归公式dp[j] = min(dp[j - i * i] + 1, dp[j]);中可以看出每次dp[j]都要选最小的,所以非0下标的dp[j]一定要初始为最大值,这样dp[j]在递推的时候才不会被初始值覆盖。
- 确定遍历顺序
我们知道这是完全背包,
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
在动态规划:322. 零钱兑换 (opens new window)中我们就深入探讨了这个问题,本题也是一样的,是求最小数!
所以本题外层for遍历背包,内层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的!
我这里先给出外层遍历背包,内层遍历物品的代码:
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i <= n; i++) { // 遍历背包
for (int j = 1; j * j <= i; j++) { // 遍历物品
dp[i] = min(dp[i - j * j] + 1, dp[i]);
}
}
- 举例推导dp数组
已输入n为5例,dp状态图如下:

dp[0] = 0
dp[1] = min(dp[0] + 1) = 1
dp[2] = min(dp[1] + 1) = 2
dp[3] = min(dp[2] + 1) = 3
dp[4] = min(dp[3] + 1, dp[0] + 1) = 1
dp[5] = min(dp[4] + 1, dp[1] + 1) = 2
最后的dp[n]为最终结果。
以上动规五部曲分析完毕C++代码如下:
// 版本一
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i <= n; i++) { // 遍历背包
for (int j = 1; j * j <= i; j++) { // 遍历物品
dp[i] = min(dp[i - j * j] + 1, dp[i]);
}
}
return dp[n];
}
};
- 时间复杂度:$ O(n * \sqrt{n})$
- 空间复杂度:$ O(n)$
同样我在给出先遍历物品,在遍历背包的代码,一样的可以AC的。
// 版本二
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i * i <= n; i++) { // 遍历物品
for (int j = i * i; j <= n; j++) { // 遍历背包
dp[j] = min(dp[j - i * i] + 1, dp[j]);
}
}
return dp[n];
}
};
总结
如果大家认真做了昨天的题目动态规划:322. 零钱兑换 (opens new window),今天这道就非常简单了,一样的套路一样的味道。
M:139.单词拆分
题意描述:
给你一个字符串
s和一个字符串列表wordDict作为字典。如果可以利用字典中出现的一个或多个单词拼接出s则返回true。注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。 注意,你可以重复使用字典中的单词。示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅由小写英文字母组成wordDict中的所有字符串 互不相同
思路
看到这道题目的时候,大家应该回想起我们之前讲解回溯法专题的时候,讲过的一道题目回溯算法:分割回文串 (opens new window),就是枚举字符串的所有分割情况。
回溯算法:分割回文串 (opens new window):是枚举分割后的所有子串,判断是否回文。
本道是枚举分割所有字符串,判断是否在字典里出现过。
那么这里我也给出回溯法C++代码:
class Solution {
private:
bool backtracking (const string& s, const unordered_set<string>& wordSet, int startIndex) {
if (startIndex >= s.size()) {
return true;
}
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, i + 1)) {
return true;
}
}
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
return backtracking(s, wordSet, 0);
}
};
- 时间复杂度:\(O(2^n)\),因为每一个单词都有两个状态,切割和不切割
- 空间复杂度:\(O(n)\),算法递归系统调用栈的空间
那么以上代码很明显要超时了,超时的数据如下:
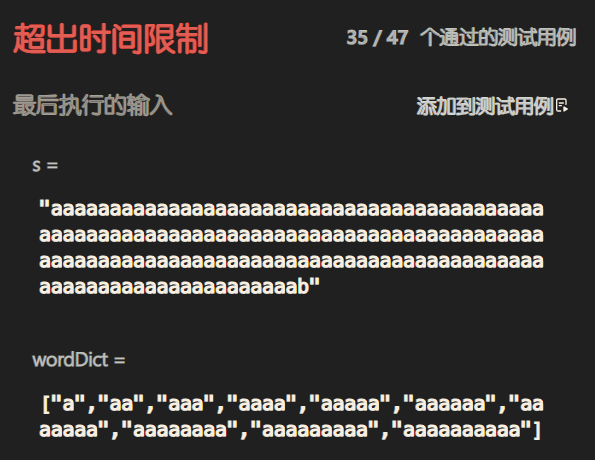
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab"
["a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa","aaaaaaaaa","aaaaaaaaaa"]
递归的过程中有很多重复计算,可以使用数组保存一下递归过程中计算的结果。
这个叫做记忆化递归,这种方法我们之前已经提过很多次了。
使用memory数组保存每次计算的以startIndex起始的计算结果,如果memory[startIndex]里已经被赋值了,直接用memory[startIndex]的结果。
C++代码如下:
class Solution {
private:
bool backtracking (const string& s,
const unordered_set<string>& wordSet,
vector<bool>& memory,
int startIndex) {
if (startIndex >= s.size()) {
return true;
}
// 如果memory[startIndex]不是初始值了,直接使用memory[startIndex]的结果
if (!memory[startIndex]) return memory[startIndex];
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, memory, i + 1)) {
return true;
}
}
memory[startIndex] = false; // 记录以startIndex开始的子串是不可以被拆分的
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> memory(s.size(), 1); // -1 表示初始化状态
return backtracking(s, wordSet, memory, 0);
}
};
这个时间复杂度其实也是:\(O(2^n)\)。只不过对于上面那个超时测试用例优化效果特别明显。
这个代码就可以AC了,当然回溯算法不是本题的主菜,背包才是!
背包问题
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。
拆分时可以重复使用字典中的单词,说明就是一个完全背包!
动规五部曲分析如下:
- 确定dp数组以及下标的含义
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
- 确定递推公式
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
- dp数组如何初始化
从递推公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递推的根基,dp[0]一定要为true,否则递推下去后面都都是false了。
那么dp[0]有没有意义呢?
dp[0]表示如果字符串为空的话,说明出现在字典里。
但题目中说了“给定一个非空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。
下标非0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为一个或多个在字典中出现的单词。
- 确定遍历顺序
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
还要讨论两层for循环的前后顺序。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
我在这里做一个总结:
求组合数:动态规划:518.零钱兑换II (opens new window)求排列数:动态规划:377. 组合总和 Ⅳ (opens new window)、动态规划:70. 爬楼梯进阶版(完全背包) (opens new window)求最小数:动态规划:322. 零钱兑换 (opens new window)、动态规划:279.完全平方数(opens new window)
而本题其实我们求的是排列数,为什么呢。 拿 s = "applepenapple", wordDict = ["apple", "pen"] 举例。
"apple", "pen" 是物品,那么我们要求 物品的组合一定是 "apple" + "pen" + "apple" 才能组成 "applepenapple"。
"apple" + "apple" + "pen" 或者 "pen" + "apple" + "apple" 是不可以的,那么我们就是强调物品之间顺序。
所以说,本题一定是 先遍历 背包,再遍历物品。
- 举例推导dp[i]
以输入: s = "leetcode", wordDict = ["leet", "code"]为例,dp状态如图:
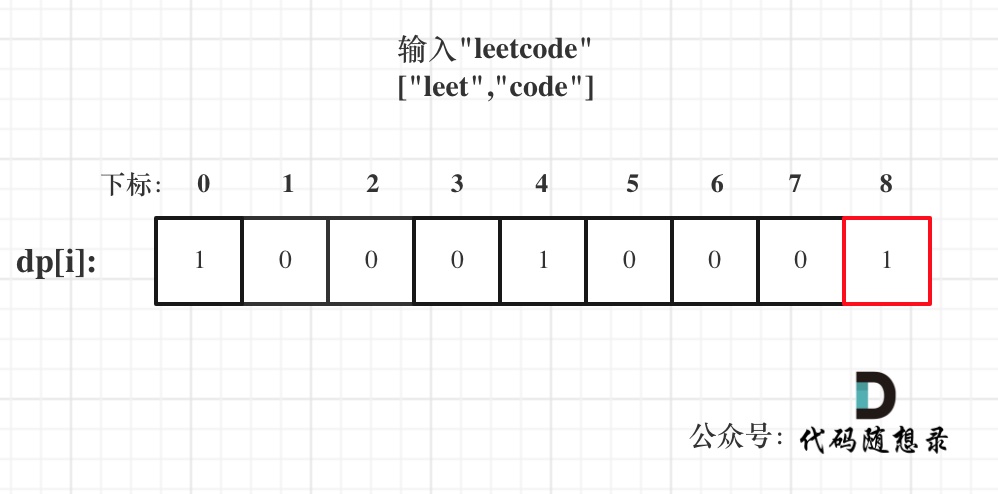
dp[s.size()]就是最终结果。
动规五部曲分析完毕,C++代码如下:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int i = 1; i <= s.size(); i++) { // 遍历背包
for (int j = 0; j < i; j++) { // 遍历物品
string word = s.substr(j, i - j); //substr(起始位置,截取的个数)
if (wordSet.find(word) != wordSet.end() && dp[j]) {
dp[i] = true;
}
}
}
return dp[s.size()];
}
};
- 时间复杂度:\(O(n^3)\),因为
substr返回子串的副本是O(n)的复杂度(这里的n是substring的长度) - 空间复杂度:\(O(n)\)
拓展
关于遍历顺序,再给大家讲一下为什么 先遍历物品再遍历背包不行。
这里可以给出先遍历物品再遍历背包的代码:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int j = 0; j < wordDict.size(); j++) { // 物品
for (int i = wordDict[j].size(); i <= s.size(); i++) { // 背包
string word = s.substr(i - wordDict[j].size(), wordDict[j].size());
// cout << word << endl;
if ( word == wordDict[j] && dp[i - wordDict[j].size()]) {
dp[i] = true;
}
// for (int k = 0; k <= s.size(); k++) cout << dp[k] << " "; //这里打印 dp数组的情况
// cout << endl;
}
}
return dp[s.size()];
}
};
使用用例:s = "applepenapple", wordDict = ["apple", "pen"],对应的dp数组状态如下:
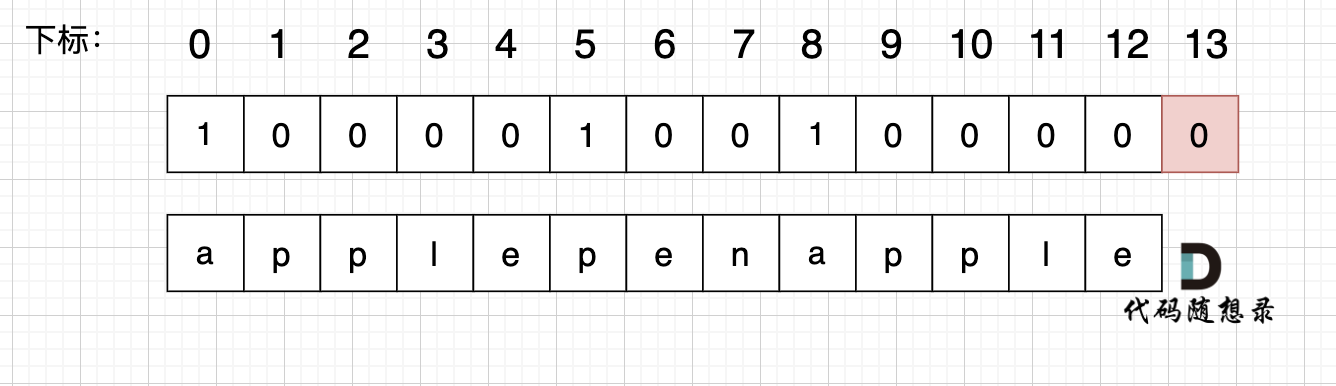
最后dp[s.size()] = 0 即 dp[13] = 0 ,而不是1,因为先用 "apple" 去遍历的时候,dp[8]并没有被赋值为1 (还没用"pen"),所以 dp[13]也不能变成1。
除非是先用 "apple" 遍历一遍,再用 "pen" 遍历,此时 dp[8]已经是1,最后再用 "apple" 去遍历,dp[13]才能是1。
如果大家对这里不理解,建议可以把我上面给的代码,拿去力扣上跑一跑,把dp数组打印出来,对着递推公式一步一步去看,思路就清晰了。
总结
本题和我们之前讲解回溯专题的回溯算法:分割回文串 (opens new window)非常像,所以我也给出了对应的回溯解法。
稍加分析,便可知道本题是完全背包,是求能否组成背包,而且这里要求物品是要有顺序的。
多重背包问题
对于多重背包,我在力扣上还没发现对应的题目,所以这里就做一下简单介绍,大家大概了解一下。
有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
多重背包和01背包是非常像的, 为什么和01背包像呢?
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了。
例如:
背包最大重量为10。
物品为:
| 重量 | 价值 | 数量 | |
|---|---|---|---|
| 物品0 | 1 | 15 | 2 |
| 物品1 | 3 | 20 | 3 |
| 物品2 | 4 | 30 | 2 |
问背包能背的物品最大价值是多少?
和如下情况有区别么?
| 重量 | 价值 | 数量 | |
|---|---|---|---|
| 物品0 | 1 | 15 | 1 |
| 物品0 | 1 | 15 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品1 | 3 | 20 | 1 |
| 物品2 | 4 | 30 | 1 |
| 物品2 | 4 | 30 | 1 |
毫无区别,这就转成了一个01背包问题了,且每个物品只用一次。
练习题目:卡码网第56题,多重背包(opens new window)
题目描述
你是一名宇航员,即将前往一个遥远的行星。在这个行星上,有许多不同类型的矿石资源,每种矿石都有不同的重要性和价值。你需要选择哪些矿石带回地球,但你的宇航舱有一定的容量限制。
给定一个宇航舱,最大容量为 C。现在有 N 种不同类型的矿石,每种矿石有一个重量 w[i],一个价值 v[i],以及最多 k[i] 个可用。不同类型的矿石在地球上的市场价值不同。你需要计算如何在不超过宇航舱容量的情况下,最大化你所能获取的总价值。
输入描述
输入共包括四行,第一行包含两个整数 C 和 N,分别表示宇航舱的容量和矿石的种类数量。
接下来的三行,每行包含 N 个正整数。具体如下:
第二行包含 N 个整数,表示 N 种矿石的重量。
第三行包含 N 个整数,表示 N 种矿石的价格。
第四行包含 N 个整数,表示 N 种矿石的可用数量上限。
输出描述
输出一个整数,代表获取的最大价值。
输入示例
10 3 1 3 4 15 20 30 2 3 2输出示例
90提示信息
数据范围:
1 <= C <= 10000;
1 <= N <= 10000;
1 <= w[i], v[i], k[i] <= 10000;
代码如下:
// 超时了
#include<iostream>
#include<vector>
using namespace std;
int main() {
int bagWeight,n;
cin >> bagWeight >> n;
vector<int> weight(n, 0);
vector<int> value(n, 0);
vector<int> nums(n, 0);
for (int i = 0; i < n; i++) cin >> weight[i];
for (int i = 0; i < n; i++) cin >> value[i];
for (int i = 0; i < n; i++) cin >> nums[i];
for (int i = 0; i < n; i++) {
while (nums[i] > 1) { // 物品数量不是一的,都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品,注意此时的物品数量不是n
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
大家去提交之后,发现这个解法超时了,为什么呢,哪里耗时呢?
耗时就在 这段代码:
for (int i = 0; i < n; i++) {
while (nums[i] > 1) { // 物品数量不是一的,都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
如果物品数量很多的话,C++中,这种操作十分费时,主要消耗在vector的动态底层扩容上。(其实这里也可以优化,先把 所有物品数量都计算好,一起申请vector的空间。
这里也有另一种实现方式,就是把每种商品遍历的个数放在01背包里面在遍历一遍。
代码如下:(详看注释)
#include<iostream>
#include<vector>
using namespace std;
int main() {
int bagWeight,n;
cin >> bagWeight >> n;
vector<int> weight(n, 0);
vector<int> value(n, 0);
vector<int> nums(n, 0);
for (int i = 0; i < n; i++) cin >> weight[i];
for (int i = 0; i < n; i++) cin >> value[i];
for (int i = 0; i < n; i++) cin >> nums[i];
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < n; i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
// 以上为01背包,然后加一个遍历个数
for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { // 遍历个数
dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);
}
}
}
cout << dp[bagWeight] << endl;
}
时间复杂度:\(O(m * n * k)\),m:物品种类个数,n背包容量,k单类物品数量
从代码里可以看出是01背包里面在加一个for循环遍历一个每种商品的数量。 和01背包还是如出一辙的。
当然还有那种二进制优化的方法,其实就是把每种物品的数量,打包成一个个独立的包。
和以上在循环遍历上有所不同,因为是分拆为各个包最后可以组成一个完整背包,具体原理我就不做过多解释了,大家了解一下就行,面试的话基本不会考完这个深度了,感兴趣可以自己深入研究一波。
总结
多重背包在面试中基本不会出现,力扣上也没有对应的题目,大家对多重背包的掌握程度知道它是一种01背包,并能在01背包的基础上写出对应代码就可以了。
至于背包九讲里面还有混合背包,二维费用背包,分组背包等等这些,大家感兴趣可以自己去学习学习,这里也不做介绍了,面试也不会考。
听说背包问题很难? 这篇总结篇来拯救你了
年前我们已经把背包问题都讲完了,那么现在我们要对背包问题进行总结一番。
背包问题是动态规划里的非常重要的一部分,所以我把背包问题单独总结一下,等动态规划专题更新完之后,我们还会在整体总结一波动态规划。
关于这几种常见的背包,其关系如下:
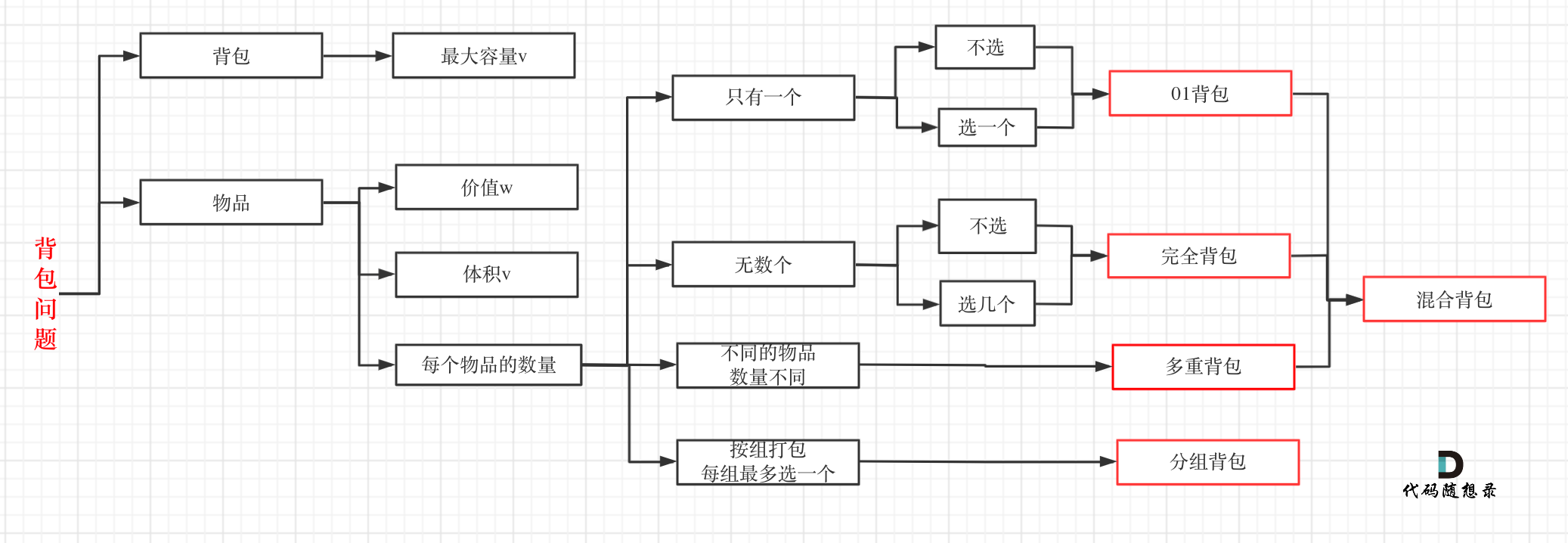
通过这个图,可以很清晰分清这几种常见背包之间的关系。
在讲解背包问题的时候,我们都是按照如下五部来逐步分析,相信大家也体会到,把这五部都搞透了,算是对动规来理解深入了。
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
其实这五部里哪一步都很关键,但确定递推公式和确定遍历顺序都具有规律性和代表性,所以下面我从这两点来对背包问题做一做总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号