计算机视觉课后作业6——图像检索
图像检索
1.实验目的:
从内容检索CBIR。外部给定一张图片,能够从内部数据库中找到相似的数张图片。
2.实验原理:
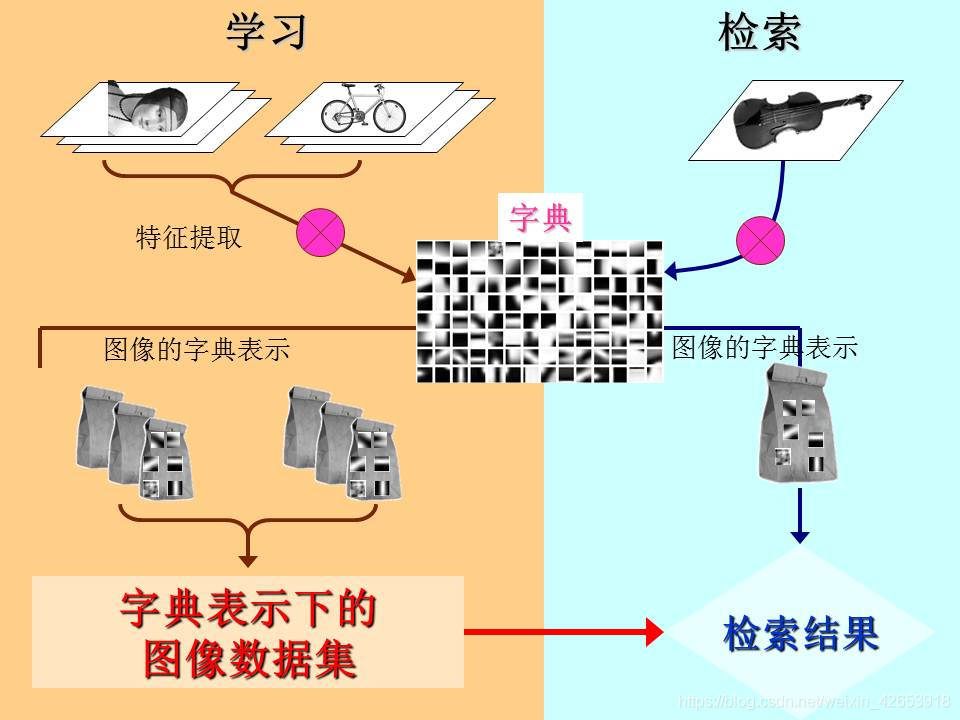
图像检索过程:查询图像输入——>预处理(尺寸归一化)(图像数据库)——>特征提取(图像特征库)——>特征欧氏距离——>相似性搜索——>得到结果
图像检索的本质是特征提取和相似度计算的过程。
关键问题1.怎么抽取图像众多像素点中的有效特征?
2.如何进行相似度计算?
我们要提取局部特征而非全局特征,主要是以下原因:
图像局部特征:角点,关键点,N*128维,N为关键点数,针对不同图像可能提取到不同特征个数,SIFT算法,尺度不变性,转换角度特征不变
全局特征:整体,512维
局部特征优于全局特征
图像局部特征进行相似点计算,利用局部特征点的匹配个数,越多越相似,匹配繁杂,次数非常大,所以我们考虑聚类分析,构建词袋模型
词袋模型:提取所有图片的sift特征(全部是向量),统计在一起得到N*128维的矩阵,对该矩阵进行聚类(合并相近特征),得到的聚类矩阵(分为几类)的聚类中心就类似我们做文字统计的单词空间(所有单词)——拿图像二次分类的矩阵来对应简单例子的一次汇总。
这边涉及到两个主要算法:
首先是特征提取——SIFT算法,遍历检测数据集图片的角点。
其次是聚类分析——K_means算法,对于得到的特征的向量矩阵进行分类,相似特征归为一类,以聚类中心代替该类向量描述,得到的N个聚类中心相当于词典中的“字母”,简化匹配流程,构成视觉词典模型。
3.实验思路:
1、构造一个数据集
2、sift算子提取特征点及描述符
3、采用k-means算法对特征点进行训练生成聚类中心
4、计算每个视觉单词的权重生成直方图
5、对于输入的检索图像计算sift特征生成直方图
6、构造检索图像到数据库图像的倒排表,针对候选图像集与检索图像进行匹配
4.具体实验:
1、构造数据集并生成.sift文件:
sift算法在之前的实验已经写过,主要是对于图片角点的检测。
if __name__ == '__main__':
download_path = "C:/Users/oulia/Pictures/TXJS"
path = "C:/Users/oulia/Pictures/TXJS"
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print('comparing ', imlist[i], imlist[j])
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print('number of matches = ', nbr_matches)
matchscores[i, j] = nbr_matches
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
# 可视化
threshold = 20 # min number of matches needed to create link 创建链接所需匹配的最小数量
g = pydot.Dot(graph_type='graph') # don't want the default directed graph
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = path + str(i) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = path + str(j) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
数据集以及运行结果
2、提取特征点并生成视觉词汇词典:
k_means算法 创建直方图 生成视觉词汇词典
import pickle from PCV.imagesearch import vocabulary from PCV.tools.imtools import get_imlist from PCV.localdescriptors import sift #获取图像列表 imlist = get_imlist('C:/Users/oulia/Pictures/TXJS/') nbr_images = len(imlist) #获取特征列表 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] #提取文件夹下图像的sift特征 for i in range(nbr_images): sift.process_image(imlist[i], featlist[i]) #生成词汇 构建视觉词典 voc = vocabulary.Vocabulary('ukbenchtest') voc.train(featlist, 18, 3) # 使用k-means算法在featurelist里边训练处一个词汇 # 注意这里使用了下采样的操作加快训练速度 # 将描述子投影到词汇上,以便创建直方图 #保存词汇 # saving vocabulary with open('C:/Users/oulia/PycharmProjects/untitled/BagOfFeature/BOW/vocabulary.pkl', 'wb') as f: pickle.dump(voc, f) print ('vocabulary is:', voc.name, voc.nbr_words)
运行截图:

生成码本:
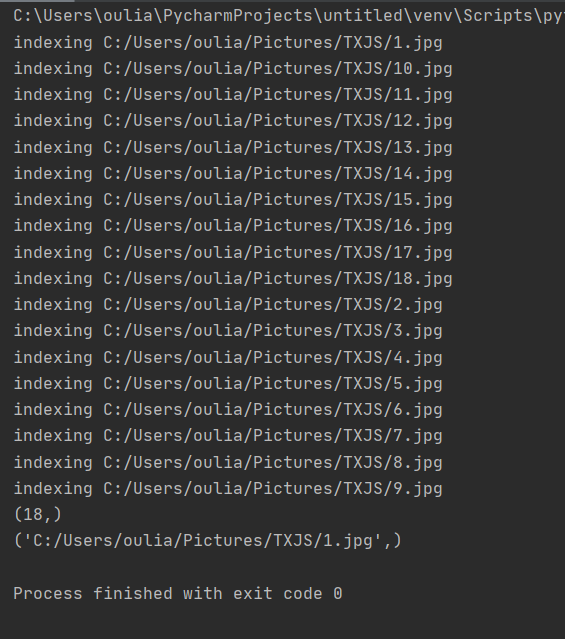
3、遍历特征投影到词汇上存入数据库 建立数据库 testImaAdd
建立数据库:有了视觉单词和对应的直方图后,就可以保存为一个数据库,当需要检索的时候输入图像在数据库中进行查询,返回一个匹配的搜索结果。
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from sqlite3 import dbapi2 as sqlite # 使用sqlite作为数据库
#获取图像列表
imlist = get_imlist('C:/Users/oulia/Pictures/TXJS/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('C:/Users/oulia/PycharmProjects/untitled/BagOfFeature/BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc) # 在Indexer这个类中创建表、索引,将图像数据写入数据库
indx.create_tables() # 创建表
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:18]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr) # 使用add_to_index获取带有特征描述子的图像,投影到词汇上
# 将图像的单词直方图编码存储
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
运行截图:
创建数据库
4、进行图像内部检索
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
from BagOfFeature.PCV.imagesearch import vocabulary
imlist = get_imlist('C:/Users/oulia/Pictures/TXJS/')
nbr_images = len(imlist)
print(nbr_images)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('C:/Users/oulia/PycharmProjects/untitled/BagOfFeature/BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 7
nbr_results = 5
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)
imagesearch.plot_results(src,res_reg[:5]) #常规查询
运行截图:
![]()

5.实验中遇到的问题:
实验要求外部输入图像进行数据库检索部分尚未实现,由于数据库图片数量的局限性,在聚类方面的划分还可以进一步优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号