
软工结对编程
PSP表格
|||
|:--|:--|:--|:--|
|PSP2.1|Personal Software Process Stages|预估耗时(分钟)|实际耗时(分钟)|
|Planning|计划|60|60|
|· Estimate|· 估计这个任务需要多少时间|1440|1500|
|Development|开发|120|180|
|· Analysis|· 需求分析 (包括学习新技术)|60|60|
|· Design Spec|· 生成设计文档|30|40|
|· Design Review|· 设计复审 (和同事审核设计文档)|20|40|
|· Coding Standard|· 代码规范 (为目前的开发制定合适的规范)|20|20|
|· Design|· 具体设计|180|180|
|· Coding|· 具体编码|720|800|
|· Code Review|· 代码复审|180|200|
|· Test|· 测试(自我测试,修改代码,提交修改)|100|120|
|Reporting|报告|30|40|
|· Test Report|· 测试报告|20|20|
|· Size Measurement|· 计算工作量|20|30|
|· Postmortem & Process Improvement Plan|· 事后总结, 并提出过程改进计划|40|60|
||合计|3040|3350|
感受:复习了文件操作,感觉还是很不错的一次作业。通过结对编程,可以让我们体验到1+1>2的效果,完成项目速度远远超过以前一个人的时候,是相当快的。
过程:我们先是一起讨论了如何实现代码的编写,大致确定了方向,就开始写。自己想写哪部分就先写,最后在一起写最难的一部分。写代码途中互相讨论,思考,查阅相关资料,最终共同完成任务。
bool isnum_str(char str) //判断是否是字符或数字
{
if ((str >= 'A' && str <= 'z') || (str >= '0' && str <= '9'))
return true;
else
return false;
}
void count(fstream &outfile, int *cnt) //统计函数
{
char str[100000];
while (outfile.getline(str, 100000))
{
int tmp = 0;
for (int i = 0; i < strlen(str); i++)
{
if (str[i] == ' ' || str[i] == '.' || str[i] == ',' || str[i] == '?' || str[i] == '!')
cnt[1]++; //统计单词数
if (isnum_str(str[i]))
{
cnt[0]++; //计算字符数
tmp++; //tmp局部变量用来区分是不是一个空行
}
}
if (tmp != 0)
cnt[2]++; //计算行数
tmp = 0;
}
return;
}
这儿主要用了fstream函数(对文件进行读写操作,对打开的文件可进行读写操作 )
void frequency(char s[]) //统计单词频率函数
{
int i, j;
int flag = 0;
for (i = 0; i <= sum; i++) //单词频率统计
{
if (strcmp(A[i].str, s) == 0)
{
A[i].num++;
flag = 1;
sum++;
}
}
if (flag == 0)
{
for (j = 0; j<30; j++)
A[sum].str[j] = s[j];
A[sum].num++;
sum++;
}
struct word a;
for (i = 0; i<sum; i++) //单词频率排序
{
for (j = i + 1; j<sum; j++)
if (A[i].num<A[j].num)
{
a = A[j];
A[j] = A[i];
A[i] = a;
}
}
}
如何计算单词频率并排序
FILE *fp;
fp = fopen(filename, "r");
if (fp == NULL)
{
printf("此文件不存在!\n");
}
sum = 0;
ch = NULL;
for (i = 0; i<100000; i++)
A[i].num = 0;
while (ch != -1)
{
for (i = 0; i<30; i++)
s[i] = '\0';
ch = fgetc(fp);
if ((65 <= ch&&ch <= 90) || (ch >= 97 && ch <= 122))
{
for (i = 0;; i++)
{
s[i] = ch;
ch = fgetc(fp);
if ((65 <= ch&&ch <= 90) || (ch >= 97 && ch <= 122))continue;
else break;
}
frequency(s);//调用frequency函数统计单词频率并排序
}
}
代码不足之处主要是这儿写在主函数中了,并没有和主函数分开。
创建的文本文件
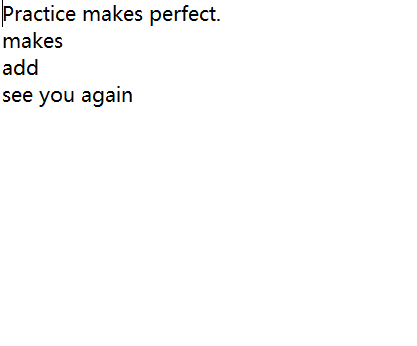
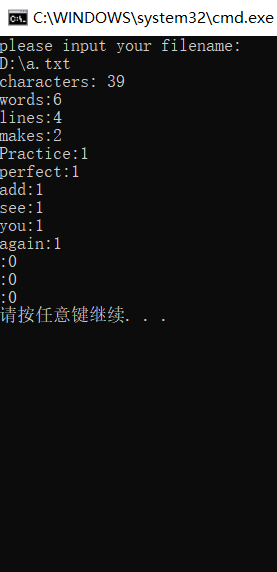
运行结果
照片


 浙公网安备 33010602011771号
浙公网安备 33010602011771号