
陈坤亮--第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | <采集腾讯视频里电视剧《在一起》的全部评论信息,将采集到的评论信息做成词云图并熟练使用github> |
| 作业源代码 | https://github.com/Chenkunliang/first-personal-work |
| 学号 | <211806106> |
时间记录
| 步骤 | 具体操作 | 花费时间 |
|---|---|---|
| 1. 进行数据采集 | 编写代码爬取当前时间的所有评论 | 4h |
| 2.数据处理 | 将爬取的评论jiebe分词处理保存到comment.json文件 | 3h |
| 3.数据分析 | 将提取出的信息制作成词云图 | 3h |
| 4.上传代码 | 将代码上传到GitHub | 3h |
一.爬取腾讯视频电视剧《在一起》的评论
1.分析网页
(1)打开《在一起》的网页,进入评论界面,多次点击查看更多评论,通过f12进入开发者模式,会发现多个变化的网址
在上图中沿着蓝色方框把标签逐级打开,进行分析,经过分析可知网站用的是异步加载。
然后我通过搜索找到类似的代码,将代码进行稍微的修改爬取对应的评论,并且保存为txt文件
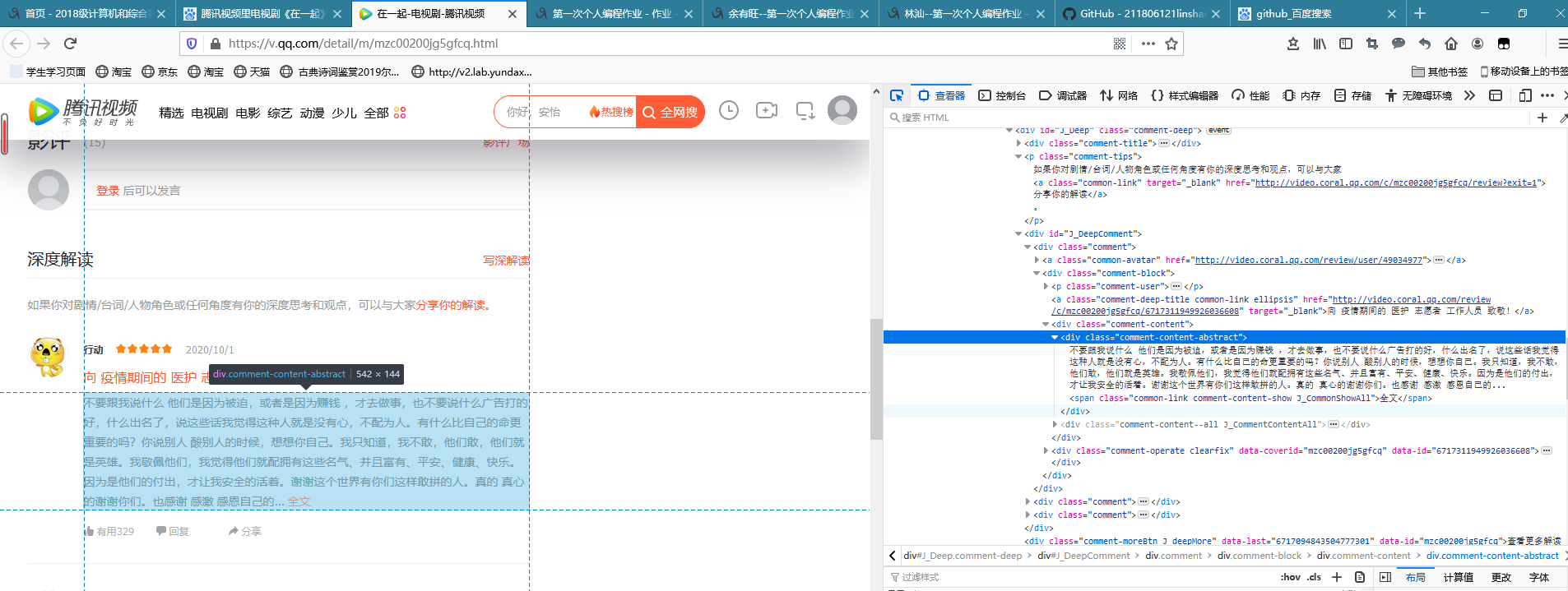
(2)通过观察发现网站评论是用了Ajax异步加载技术,经过多次寻找规律,找到了规律,请求URL 中只有 cursor 和 source 进行了改变,其他是不变的;
找到source

2.爬取评论的具体代码
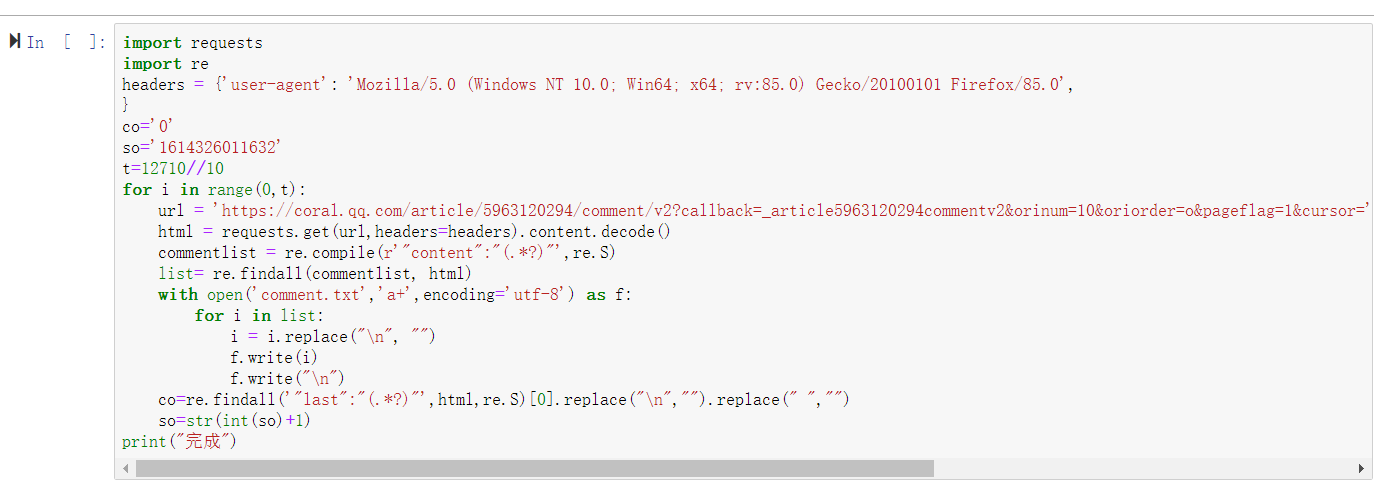
将评论爬取保存到comment.txt中方便后面处理
3.分词处理
这是我第一次用jieba进行分词处理,电脑没有pycharm 一开始用Anonada来爬,可是没有jieba库也没有wordcloud,经过一番尝试选择了上学期用过的阿里云天池平台来进行分词操作,并去GitHub中找到了国内常用停词表
编写代码进行分词处理 将前面爬取的评论处理保存
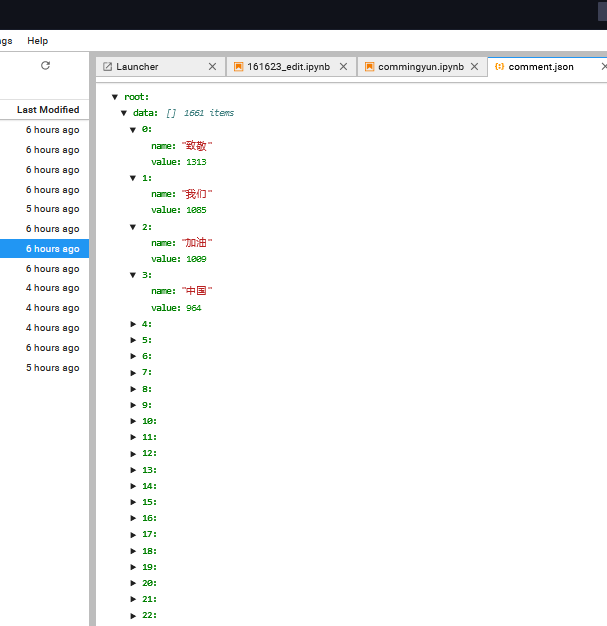
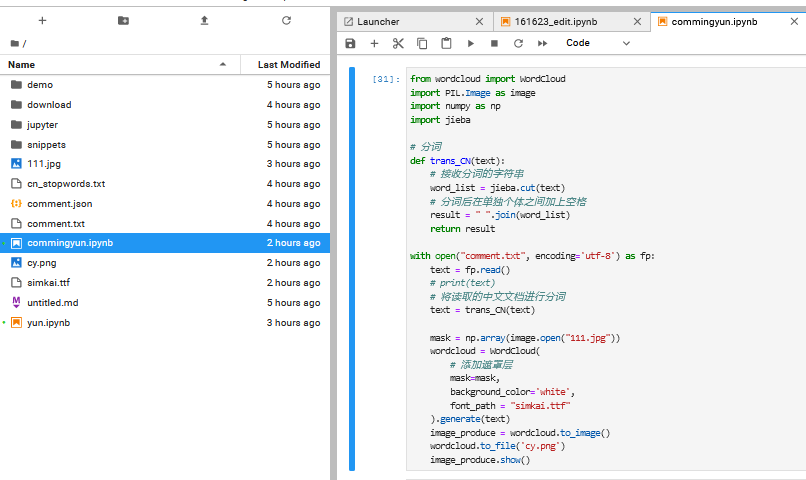
4.数据处理并制作出云词图,这个直接在阿里云天池平台导库就可以做

在处理制图的过程中,发生了font_path = "simkai.ttf"的代码无法执行,生成的图片都是框框,经过一番求解更改了路径,将字体源文件导入阿里云天池平台
5.上传代码
(1)右键本地文件夹 Git Bash Here
(2) 在命令行中,输入“git init”,使“第一次编程”文件夹加入git管理

(3)输入“git remote add origin xxxx“ (git remote add origin 你自己的https地址),连接你的guthub仓库。

(4)将Git中的仓库内容复制到该文件夹中,这时文件夹会新建一个first-personal-work文件
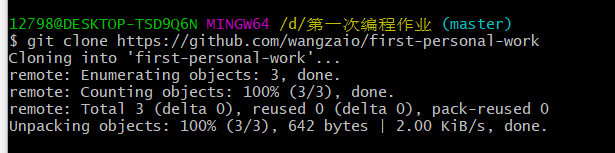
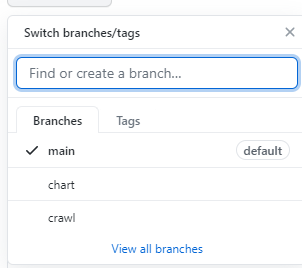
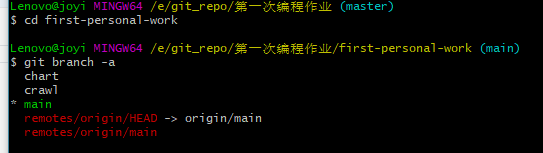
(5)进去first-personal-work文件,查看所有分支,如需更换(输入 “git checkout crawl”)
我在创仓库的时候直接在github仓库就建立了
(6)输入“git add .”(不要漏了“.”),将文件夹全部内容添加到git;也可以输入“git add 上传文件的名字” ,将此文件内容添加到git

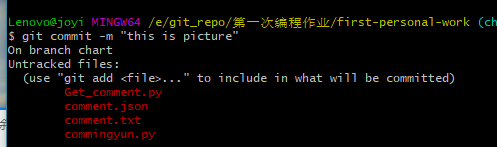
(7)输入“git commit -m "first"”(“git commit -m "提交信息"”)
(8)输入“git push -u origin master(可以更换其他分支)”,上传项目到Github。这里会要求输入Github的账号密码,按要求输入就可以。
(9)切换分支后重复操作将剩下的文件上传并备注
(10).将两个分支分别合并到主分支,合并后的分支不要删除
上传结果
总结
本次作业有着一定的难度,有挑战性,对个人处理突发事件的能力有一定的要求,陌生的知识点比较多,尤其在jieba还有wordcloud这部分耗时比较久。再遇到这样的情况,我想我会处理的更加得心应手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号