
在讲解K近邻分类器之前,我们先来看一下最近邻分类器(Nearest Neighbor Classifier),它也是K = 1时的K近邻分类器。
最近邻分类器
定义
最近邻分类器是在最小距离分类的基础上进行扩展的,将训练集中的每一个样本作为判断依据,寻找距离待分类样本中最近的训练集中的样本,以此依据进行分类。

如上图所示,我们的训练集代表了二维平面上的点,而不同的颜色代表了不同的类别(标签).
存在问题
噪声(图像噪声是指存在于图像数据中的不必要的或多余的干扰信息。)我们从上面的图中可以看出,绿色的区域内还有一个黄色区域,此时这个区域应该是绿色,因为黄色的点很有可能是噪声,但我们使用最近邻算法就有可能出现上面的问题。
K近邻分类器(KNN)
定义
与最近邻分类器类不同的是,k近邻分类器是几个测试的样本共同抉择属于哪一个样本,如下所示,当k = 1(也就是最近邻分类器),3,5时的分类器抉择结果。

为了帮助大家更好地理解,我们引入下面一个示例:
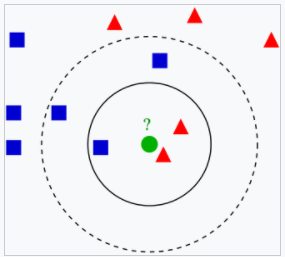
k近邻算法例子。测试样本(绿色圆形)应归入要么是第一类的蓝色方形或是第二类的红色三角形。如果k=3(实线圆圈)它被分配给第二类,因为有2个三角形和只有1个正方形在内侧圆圈之内。如果k=5(虚线圆圈)它被分配到第一类(3个正方形与2个三角形在外侧圆圈之内)。
距离测量
现在有一个问题,那就是我们如何比较相对近邻距离值,下面给出两种方法

对于这两种方法,大家可以参考下面的博文:欧氏距离,曼哈顿距离,余弦距离,汉明距离
L1距离:它上面的点的横坐标的绝对值与纵坐标的绝对值之和总是相等,也就是到原点在坐标轴度量上是相等的。
L2距离:它上面的每一个点的坐标到原点的距离都相等。
大家有兴趣的可以在斯坦福大学的实验平台上调试数据进行试验
附:cs231n-demo实验
参数选择
我们通过试验,可以找出最优值k。当然,在CS231n当中,我们也看到了一种新的方法,在有限数据集的情况之下进行的实验:K折交叉验证

从实验的结果,大约在k = 7时,我们能得到最优的解。
存在问题
(1)Distance Matrix
我们假定使用L1距离,则计算过程如下:

但是计算标尺与邻近特定距离标尺之间的关系并不会给我们带来什么太有用的讯,如下,

Boxed,Shifted,Tinted与Original不同,但是 K-Nearest Neighbor 结果出来的确实一样的。
(2)计算时间过长。
源代码
import pickle
import os
import numpy as np
n = 2
def unpickle_as_array(filename):
with open(filename, 'rb') as f:
dic = pickle.load(f, encoding='latin1')
dic_data = dic['data']
dic_labels = dic['labels']
dic_data = np.array(dic_data).astype('int')
dic_labels = np.array(dic_labels).astype('int')
return dic_data, dic_labels
def load_batches(root, n):
train_data = []
train_labels = []
for i in range(1, n + 1, 1):
f = os.path.join(root, 'data_batch_%d' % i)
data, labels = unpickle_as_array(f)
train_data.append(data)
train_labels.append(labels)
train_data_r = np.concatenate(train_data)
train_labels_r = np.concatenate(train_labels)
del train_data, train_labels
test_data, test_labels = unpickle_as_array(os.path.join(root, 'test_batch'))
return train_data_r, train_labels_r, test_data, test_labels
def knn_classification(train_d, test_d, train_l, k):
count = 0
result = np.zeros(10000)
for i in range(10000):
d_value = test_d[i] - train_d
distance = np.sum(np.abs(d_value), axis=1)
dis_sort = np.argsort(distance)
vote_label = np.zeros(10)
for j in range(k):
vote_label[train_l[dis_sort[j]]] += 1
result[i] = np.argmax(vote_label)
print('the %dth image\'s label: %d' % (count, result[i]))
count = count + 1
return result
train_data, train_labels, test_data, test_labels = load_batches('D:/data/cifar-10-python/cifar-10-batches-py', n)
result = knn_classification(train_data, test_data, train_labels, 3)
print('the algorithm\'s accuracy: %f' % (np.mean(result == test_labels)))
CIFAR的下载:https://www.cs.toronto.edu/~kriz/cifar.html
大家进入官网后,可以选择CIFAR-10 python进行下载,然后修改
train_data, train_labels, test_data, test_labels = load_batches('D:/data/cifar-10-python/cifar-10-batches-py', n)
中的路径。
大家也可以参考我的GitHub:-cifar-10-KNN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号