

用雪花算法就不会产生重复的ID?
前言
今天想和大家聊聊分布式系统中常用的雪花算法(Snowflake)——这个看似完美的ID生成方案,实际上暗藏玄机。
有些小伙伴在工作中一提到分布式ID,第一个想到的就是雪花算法。
确实,它简单、高效、趋势递增,但你知道吗?
雪花算法的隐蔽的坑不少。
今天这篇文章跟大家一起聊聊雪花算法的5大坑,希望对你会有所帮助。
一、雪花算法:美丽的陷阱
先简单回顾一下雪花算法的结构。
标准的雪花算法ID由64位组成:
// 典型的雪花算法结构
public class SnowflakeId {
// 64位ID结构
// 1位符号位(始终为0) +
// 41位时间戳(毫秒级) +
// 10位机器ID +
// 12位序列号
private long timestampBits = 41; // 时间戳占41位
private long workerIdBits = 10; // 机器ID占10位
private long sequenceBits = 12; // 序列号占12位
// 最大支持值
private long maxWorkerId = -1L ^ (-1L << workerIdBits); // 1023
private long maxSequence = -1L ^ (-1L << sequenceBits); // 4095
// 偏移量
private long timestampShift = sequenceBits + workerIdBits; // 22
private long workerIdShift = sequenceBits; // 12
}
看起来很美,对吧?
但美丽的背后,是五个需要警惕的深坑:
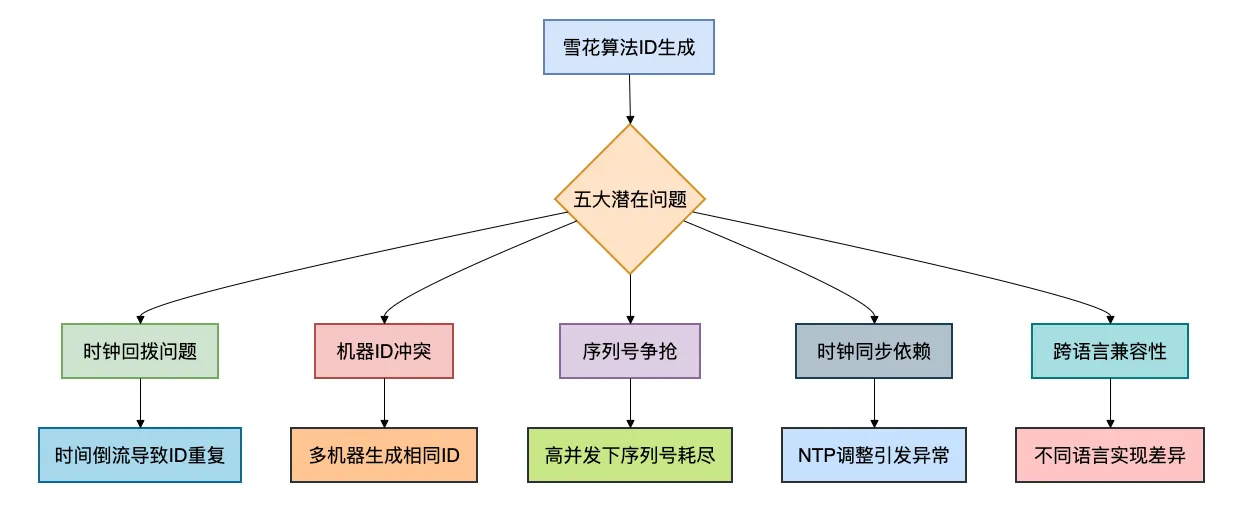
接下来,我们逐一深入分析这五个坑。
二、坑一:时钟回拨——最致命的陷阱
问题现象
有一天,我们线上订单系统突然出现大量重复ID。
排查后发现,有一台服务器的时间被NTP服务自动校准,时钟回拨了2秒钟。
// 有问题的雪花算法实现
public synchronized long nextId() {
long currentTimestamp = timeGen();
// 问题代码:如果发现时钟回拨,直接抛异常
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨异常");
}
// ... 生成ID的逻辑
}
结果就是:时钟回拨的那台服务器完全不可用,所有请求都失败。
深度剖析
时钟为什么会回拨?
- NTP自动校准:网络时间协议会自动同步时间
- 人工误操作:运维手动调整了服务器时间
- 虚拟机暂停/恢复:虚拟机暂停后恢复,时钟可能跳跃
- 闰秒调整:UTC闰秒可能导致时钟回拨
在分布式系统中,你无法保证所有服务器时钟完全一致,这是物理限制。
解决方案
方案1:等待时钟追上来(推荐)
public class SnowflakeIdWorker {
private long lastTimestamp = -1L;
private long sequence = 0L;
public synchronized long nextId() {
long timestamp = timeGen();
// 处理时钟回拨
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
// 如果回拨时间较小(比如5毫秒内),等待
if (offset <= 5) {
try {
wait(offset << 1); // 等待两倍时间
timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨过大");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("等待时钟同步被中断");
}
} else {
// 回拨过大,抛出异常
throw new RuntimeException("时钟回拨过大: " + offset + "ms");
}
}
// 正常生成ID的逻辑
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & maxSequence;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampShift) |
(workerId << workerIdShift) |
sequence;
}
// 等待下一个毫秒
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
}
方案2:使用扩展的workerId位
// 将部分workerId位用作回拨计数器
public class SnowflakeWithBackward {
// 调整位分配:39位时间戳 + 13位机器ID + 3位回拨计数 + 9位序列号
private static final long BACKWARD_BITS = 3L; // 支持最多7次回拨
private long backwardCounter = 0L; // 回拨计数器
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
// 时钟回拨,增加回拨计数器
backwardCounter = (backwardCounter + 1) & ((1 << BACKWARD_BITS) - 1);
if (backwardCounter == 0) {
// 回拨计数器溢出,抛出异常
throw new RuntimeException("时钟回拨次数过多");
}
// 使用上次的时间戳,但带上回拨标记
timestamp = lastTimestamp;
} else {
// 时钟正常,重置回拨计数器
backwardCounter = 0L;
}
// ... 生成ID,将backwardCounter也编码进去
}
}
方案3:兜底方案——随机数填充
public class SnowflakeWithFallback {
// 当时钟回拨过大时,使用随机数生成器兜底
private final Random random = new Random();
public long nextId() {
try {
return snowflakeNextId();
} catch (ClockBackwardException e) {
// 当时钟回拨无法处理时,使用随机ID兜底
log.warn("时钟回拨,使用随机ID兜底", e);
return generateRandomId();
}
}
private long generateRandomId() {
// 生成一个基于随机数的ID,但保证不会与正常ID冲突
// 方法:最高位置1,标识这是兜底ID
long randomId = random.nextLong() & Long.MAX_VALUE;
return randomId | (1L << 63); // 最高位置1
}
}
方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 等待时钟 | 保持ID连续性 | 可能阻塞线程 | 回拨小的场景(<5ms) |
| 回拨计数器 | 不阻塞线程 | ID不连续 | 频繁小回拨场景 |
| 随机数兜底 | 保证可用性 | ID可能重复 | 紧急情况备用 |
三、坑二:机器ID分配难题
问题现象
假如公司有300多台服务器,但雪花算法只支持1024个机器ID。
更糟糕的是,有次扩容时,两台机器配了相同的workerId,导致生成的ID大量重复。
深度剖析
机器ID分配为什么难?
- 数量限制:10位最多1024个ID
- 分配冲突:人工配置容易出错
- 动态伸缩:容器化环境下IP变动频繁
- ID回收:机器下线后ID何时可重用
解决方案
方案1:基于数据库分配
@Component
public class WorkerIdAssigner {
@Autowired
private JdbcTemplate jdbcTemplate;
private Long workerId;
@PostConstruct
public void init() {
// 尝试获取或分配workerId
this.workerId = assignWorkerId();
}
private Long assignWorkerId() {
String hostname = getHostname();
String ip = getLocalIp();
// 查询是否已分配
String sql = "SELECT worker_id FROM worker_assign WHERE hostname = ? OR ip = ?";
List<Long> existingIds = jdbcTemplate.queryForList(sql, Long.class, hostname, ip);
if (!existingIds.isEmpty()) {
return existingIds.get(0);
}
// 分配新的workerId
for (int i = 0; i < 1024; i++) {
try {
sql = "INSERT INTO worker_assign (worker_id, hostname, ip, created_time) VALUES (?, ?, ?, NOW())";
int updated = jdbcTemplate.update(sql, i, hostname, ip);
if (updated > 0) {
log.info("分配workerId成功: {} -> {}:{}", i, hostname, ip);
return (long) i;
}
} catch (DuplicateKeyException e) {
// workerId已被占用,尝试下一个
continue;
}
}
throw new RuntimeException("没有可用的workerId");
}
// 心跳保活
@Scheduled(fixedDelay = 30000)
public void keepAlive() {
if (workerId != null) {
String sql = "UPDATE worker_assign SET last_heartbeat = NOW() WHERE worker_id = ?";
jdbcTemplate.update(sql, workerId);
}
}
@PreDestroy
public void cleanup() {
// 应用关闭时释放workerId(可选)
if (workerId != null) {
String sql = "DELETE FROM worker_assign WHERE worker_id = ?";
jdbcTemplate.update(sql, workerId);
}
}
}
方案2:基于ZK/Etcd分配
public class ZkWorkerIdAssigner {
private CuratorFramework client;
private String workerPath = "/snowflake/workers";
private Long workerId;
public Long assignWorkerId() throws Exception {
// 创建持久化节点
client.create().creatingParentsIfNeeded().forPath(workerPath);
// 创建临时顺序节点
String sequentialPath = client.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(workerPath + "/worker-");
// 提取序号作为workerId
String sequenceStr = sequentialPath.substring(sequentialPath.lastIndexOf('-') + 1);
long sequence = Long.parseLong(sequenceStr);
// 序号对1024取模得到workerId
this.workerId = sequence % 1024;
// 监听节点变化,如果连接断开自动释放
client.getConnectionStateListenable().addListener((curator, newState) -> {
if (newState == ConnectionState.LOST || newState == ConnectionState.SUSPENDED) {
log.warn("ZK连接异常,workerId可能失效: {}", workerId);
}
});
return workerId;
}
}
方案3:IP地址自动计算(推荐)
public class IpBasedWorkerIdAssigner {
// 10位workerId,可以拆分为:3位机房 + 7位机器
private static final long DATACENTER_BITS = 3L;
private static final long WORKER_BITS = 7L;
public long getWorkerId() {
try {
String ip = getLocalIp();
String[] segments = ip.split("\\.");
// 使用IP后两段计算workerId
int third = Integer.parseInt(segments[2]); // 0-255
int fourth = Integer.parseInt(segments[3]); // 0-255
// 机房ID:取第三段的低3位 (0-7)
long datacenterId = third & ((1 << DATACENTER_BITS) - 1);
// 机器ID:取第四段的低7位 (0-127)
long workerId = fourth & ((1 << WORKER_BITS) - 1);
// 合并:3位机房 + 7位机器 = 10位workerId
return (datacenterId << WORKER_BITS) | workerId;
} catch (Exception e) {
// 降级方案:使用随机数,但设置标志位
log.warn("IP计算workerId失败,使用随机数", e);
return new Random().nextInt(1024) | (1L << 9); // 最高位置1表示随机
}
}
}
方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 数据库分配 | 精确控制 | 依赖DB,有单点风险 | 中小规模固定集群 |
| ZK分配 | 自动故障转移 | 依赖ZK,复杂度高 | 大规模动态集群 |
| IP计算 | 简单无依赖 | IP可能冲突 | 网络规划规范的场景 |
四、坑三:序列号争抢与耗尽
问题现象
我们的订单服务在促销期间,单机QPS达到5万,经常出现“序列号耗尽”的警告日志。
虽然雪花算法理论上支持4096/ms的序列号,但实际使用中发现,在高并发下还是可能不够用。
深度剖析
序列号为什么可能耗尽?
- 时间戳粒度:毫秒级时间戳,1ms内最多4096个ID
- 突发流量:秒杀场景下,1ms可能收到上万请求
- 时钟偏差:多台机器时钟不完全同步
- 序列号重置:每毫秒序列号从0开始
解决方案
方案1:减少时间戳粒度(微秒级)
public class MicrosecondSnowflake {
// 调整位分配:使用微秒级时间戳
// 1位符号位 + 36位微秒时间戳 + 10位机器ID + 17位序列号
private static final long TIMESTAMP_BITS = 36L; // 微秒时间戳
private static final long SEQUENCE_BITS = 17L; // 13万/微秒
private long lastMicroTimestamp = -1L;
private long sequence = 0L;
public synchronized long nextId() {
long currentMicros = getCurrentMicroseconds();
if (currentMicros < lastMicroTimestamp) {
// 处理时钟回拨
throw new RuntimeException("时钟回拨");
}
if (currentMicros == lastMicroTimestamp) {
sequence = (sequence + 1) & ((1 << SEQUENCE_BITS) - 1);
if (sequence == 0) {
// 等待下一个微秒
currentMicros = waitNextMicros(lastMicroTimestamp);
}
} else {
sequence = 0L;
}
lastMicroTimestamp = currentMicros;
return ((currentMicros) << (SEQUENCE_BITS + WORKER_BITS)) |
(workerId << SEQUENCE_BITS) |
sequence;
}
private long getCurrentMicroseconds() {
// 获取微秒级时间戳
return System.currentTimeMillis() * 1000 +
(System.nanoTime() / 1000 % 1000);
}
}
方案2:分段序列号
public class SegmentedSequenceSnowflake {
// 为不同的业务类型分配不同的序列号段
private Map<String, Long> sequenceMap = new ConcurrentHashMap<>();
public long nextId(String businessType) {
long timestamp = System.currentTimeMillis();
// 获取该业务类型的序列号
Long lastTimestamp = sequenceMap.get(businessType + "_ts");
Long sequence = sequenceMap.get(businessType);
if (lastTimestamp == null || lastTimestamp != timestamp) {
// 新的毫秒,重置序列号
sequence = 0L;
sequenceMap.put(businessType + "_ts", timestamp);
} else {
// 同一毫秒内,递增序列号
sequence = sequence + 1;
if (sequence >= 4096) {
// 等待下一个毫秒
timestamp = waitNextMillis(timestamp);
sequence = 0L;
sequenceMap.put(businessType + "_ts", timestamp);
}
}
sequenceMap.put(businessType, sequence);
// 将业务类型编码到workerId中
long businessWorkerId = encodeBusinessType(workerId, businessType);
return ((timestamp - twepoch) << timestampShift) |
(businessWorkerId << workerIdShift) |
sequence;
}
private long encodeBusinessType(long baseWorkerId, String businessType) {
// 使用workerId的高几位表示业务类型
int typeCode = businessType.hashCode() & 0x1F; // 5位,32种业务
return (typeCode << 5) | (baseWorkerId & 0x1F);
}
}
方案3:预生成ID池
public class IdPoolSnowflake {
// 预生成ID池,缓解瞬时压力
private BlockingQueue<Long> idQueue = new LinkedBlockingQueue<>(10000);
private volatile boolean isGenerating = false;
// 后台线程预生成ID
private Thread generatorThread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
if (idQueue.size() < 5000 && !isGenerating) {
isGenerating = true;
generateBatchIds(1000);
isGenerating = false;
}
Thread.sleep(1); // 短暂休眠
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
public IdPoolSnowflake() {
generatorThread.setDaemon(true);
generatorThread.start();
}
public long nextId() {
try {
// 从队列中获取预生成的ID
Long id = idQueue.poll(10, TimeUnit.MILLISECONDS);
if (id != null) {
return id;
}
// 队列为空,同步生成
log.warn("ID队列空,同步生成ID");
return snowflake.nextId();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return snowflake.nextId();
}
}
private void generateBatchIds(int count) {
for (int i = 0; i < count; i++) {
try {
idQueue.put(snowflake.nextId());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
}
性能优化对比
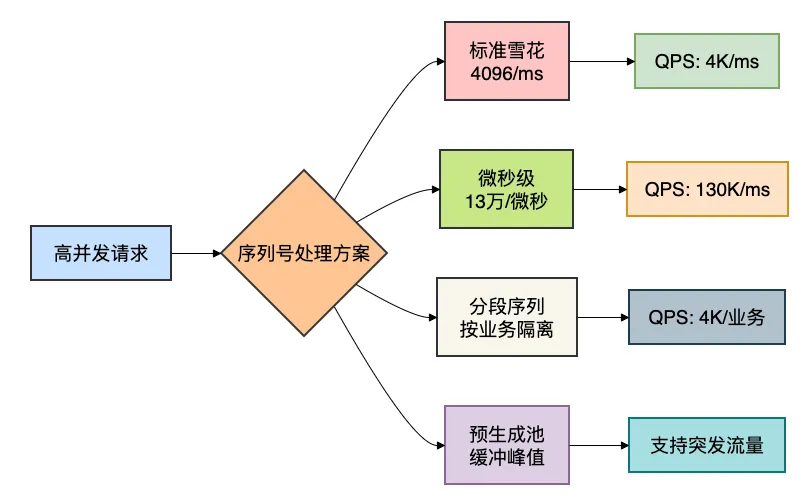
五、坑四:时间戳溢出危机
问题现象
雪花算法的41位时间戳能表示多少时间?
2^41 / 1000 / 60 / 60 / 24 / 365 ≈ 69年
看起来很长?
但这里有个大坑:起始时间的选择。
如果起始时间设置不当,系统可能很快就面临时间戳溢出问题。
深度剖析
时间戳为什么可能溢出?
- 起始时间过早:比如从1970年开始,到2039年就溢出
- 时间戳位数不足:41位在微秒级下很快耗尽
- 系统运行时间超预期:很多系统需要运行几十年
解决方案
方案1:选择合适的起始时间
public class SnowflakeWithCustomEpoch {
// 自定义起始时间:2020-01-01 00:00:00
private static final long CUSTOM_EPOCH = 1577836800000L; // 2020-01-01
// 计算剩余可用时间
public void checkRemainingTime() {
long maxTimestamp = (1L << 41) - 1; // 41位最大时间戳
long currentTime = System.currentTimeMillis();
long elapsed = currentTime - CUSTOM_EPOCH;
long remaining = maxTimestamp - elapsed;
long remainingYears = remaining / 1000 / 60 / 60 / 24 / 365;
log.info("雪花算法剩余可用时间: {}年 ({}毫秒)",
remainingYears, remaining);
if (remainingYears < 5) {
log.warn("雪花算法将在{}年后溢出,请准备升级方案", remainingYears);
}
}
public long nextId() {
long timestamp = System.currentTimeMillis() - CUSTOM_EPOCH;
if (timestamp > maxTimestamp) {
throw new RuntimeException("时间戳溢出,请升级ID生成方案");
}
// ... 生成ID
return (timestamp << timestampShift) |
(workerId << workerIdShift) |
sequence;
}
}
方案2:时间戳扩展方案
public class ExtendedSnowflake {
// 扩展方案:使用两个字段表示时间
// 高32位:秒级时间戳(可表示到2106年)
// 低32位:毫秒内序列 + workerId
private static final long SECONDS_SHIFT = 32;
public long nextId() {
long seconds = System.currentTimeMillis() / 1000;
long milliseconds = System.currentTimeMillis() % 1000;
// 将毫秒、workerId、序列号编码到低32位
long lowerBits = ((milliseconds & 0x3FF) << 22) | // 10位毫秒(0-999)
((workerId & 0x3FF) << 12) | // 10位workerId
(sequence & 0xFFF); // 12位序列号
return (seconds << SECONDS_SHIFT) | lowerBits;
}
public void parseId(long id) {
long seconds = id >>> SECONDS_SHIFT;
long lowerBits = id & 0xFFFFFFFFL;
long milliseconds = (lowerBits >>> 22) & 0x3FF;
long workerId = (lowerBits >>> 12) & 0x3FF;
long sequence = lowerBits & 0xFFF;
long timestamp = seconds * 1000 + milliseconds;
log.info("解析ID: 时间={}, workerId={}, 序列号={}",
new Date(timestamp), workerId, sequence);
}
}
方案3:动态位分配
public class DynamicBitsSnowflake {
// 根据时间动态调整位分配
private long timestampBits = 41L;
private long sequenceBits = 12L;
@PostConstruct
public void init() {
// 根据已用时间调整位数
long elapsed = System.currentTimeMillis() - twepoch;
long maxTimestamp = (1L << timestampBits) - 1;
// 如果已用超过80%,准备减少时间戳位数,增加序列号位数
if (elapsed > maxTimestamp * 0.8) {
log.warn("时间戳使用超过80%,准备调整位分配");
adjustBitsAllocation();
}
}
private void adjustBitsAllocation() {
// 减少1位时间戳,增加1位序列号
timestampBits = 40L;
sequenceBits = 13L; // 序列号从4096增加到8192
log.info("调整位分配: 时间戳={}位, 序列号={}位",
timestampBits, sequenceBits);
// 重新计算偏移量
timestampShift = sequenceBits + workerIdBits;
// 通知集群其他节点(需要分布式协调)
notifyOtherNodes();
}
// 为了兼容性,提供版本号
public long nextIdWithVersion() {
long version = 1L; // 版本号,标识位分配方案
long id = nextId();
// 将版本号编码到最高几位
return (version << 60) | (id & 0x0FFFFFFFFFFFFFFFL);
}
}
六、坑五:跨语言与跨系统兼容性
问题现象
假如在微服务架构中,Java服务生成的ID传给Python服务,Python服务再传给Go服务。
结果发现:不同语言对长整型的处理方式不同,导致ID在传输过程中被修改。
深度剖析
跨语言兼容性为什么难?
- 有符号与无符号:Java只有有符号long,其他语言有无符号
- JSON序列化:大整数可能被转换为字符串
- 前端精度丢失:JavaScript的Number类型精度只有53位
- 数据库存储:不同数据库对bigint的处理不同
解决方案
方案1:字符串化传输
public class SnowflakeIdWrapper {
// 生成ID时同时生成字符串形式
public IdPair nextIdPair() {
long id = snowflake.nextId();
String idStr = Long.toString(id);
// 对于可能溢出的前端,提供分段字符串
String safeStr = convertToSafeString(id);
return new IdPair(id, idStr, safeStr);
}
private String convertToSafeString(long id) {
// 将64位ID转换为两个32位数字的字符串表示
// 避免JavaScript精度丢失
int high = (int) (id >>> 32);
int low = (int) (id & 0xFFFFFFFFL);
// 格式:高32位-低32位
return high + "-" + low;
}
// 解析前端传回的字符串ID
public long parseFromString(String idStr) {
if (idStr.contains("-")) {
// 处理分段字符串
String[] parts = idStr.split("-");
long high = Long.parseLong(parts[0]);
long low = Long.parseLong(parts[1]);
return (high << 32) | low;
} else {
return Long.parseLong(idStr);
}
}
}
// 统一的ID响应对象
@Data
@AllArgsConstructor
class IdPair {
private long id; // 原始long型,用于Java内部
private String idStr; // 字符串型,用于JSON传输
private String safeStr; // 安全字符串,用于前端
}
方案2:自定义JSON序列化器
public class SnowflakeIdSerializer extends JsonSerializer<Long> {
@Override
public void serialize(Long value, JsonGenerator gen, SerializerProvider provider)
throws IOException {
// 对于雪花算法ID(通常大于2^53),转换为字符串
if (value != null && value > 9007199254740992L) { // 2^53
gen.writeString(value.toString());
} else {
gen.writeNumber(value);
}
}
}
// 在实体类中使用
@Data
public class Order {
@JsonSerialize(using = SnowflakeIdSerializer.class)
private Long id;
private String orderNo;
private BigDecimal amount;
}
方案3:中间件统一转换
@RestControllerAdvice
public class SnowflakeIdResponseAdvice implements ResponseBodyAdvice<Object> {
@Override
public boolean supports(MethodParameter returnType,
Class<? extends HttpMessageConverter<?>> converterType) {
return true;
}
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType,
MediaType selectedContentType,
Class<? extends HttpMessageConverter<?>> selectedConverterType,
ServerHttpRequest request, ServerHttpResponse response) {
if (body == null) {
return null;
}
// 递归处理所有Long类型字段
return convertSnowflakeIds(body);
}
private Object convertSnowflakeIds(Object obj) {
if (obj instanceof Long) {
Long id = (Long) obj;
// 如果是雪花算法ID(根据特征判断),转换为字符串
if (isSnowflakeId(id)) {
return new IdWrapper(id);
}
return obj;
}
if (obj instanceof Map) {
Map<?, ?> map = (Map<?, ?>) obj;
Map<Object, Object> newMap = new LinkedHashMap<>();
for (Map.Entry<?, ?> entry : map.entrySet()) {
newMap.put(entry.getKey(), convertSnowflakeIds(entry.getValue()));
}
return newMap;
}
if (obj instanceof Collection) {
Collection<?> collection = (Collection<?>) obj;
List<Object> newList = new ArrayList<>();
for (Object item : collection) {
newList.add(convertSnowflakeIds(item));
}
return newList;
}
// 普通对象,反射处理字段
if (obj != null && !isPrimitive(obj.getClass())) {
try {
Object newObj = obj.getClass().newInstance();
// 使用反射复制并转换字段(简化版)
return convertObjectFields(obj, newObj);
} catch (Exception e) {
return obj;
}
}
return obj;
}
private boolean isSnowflakeId(long id) {
// 判断是否为雪花算法ID:时间戳部分在合理范围内
long timestamp = (id >> 22) + twepoch; // 假设标准雪花算法
long current = System.currentTimeMillis();
// 时间戳应该在最近几年内
return timestamp > current - (365L * 24 * 60 * 60 * 1000 * 5) &&
timestamp < current + 1000;
}
}
// ID包装器,用于JSON序列化
@Data
@AllArgsConstructor
class IdWrapper {
@JsonProperty("id")
private String stringId;
@JsonProperty("raw")
private long rawId;
public IdWrapper(long id) {
this.rawId = id;
this.stringId = Long.toString(id);
}
}
跨语言兼容性测试表
| 语言/环境 | 最大安全整数 | 处理方案 | 示例 |
|---|---|---|---|
| JavaScript | 2^53 (9e15) | 字符串化 | "12345678901234567" |
| Python | 无限制 | 直接使用 | 12345678901234567 |
| Java | 2^63-1 | 直接使用 | 12345678901234567L |
| MySQL BIGINT | 2^63-1 | 直接存储 | 12345678901234567 |
| JSON传输 | 2^53 | 大数转字符串 | {"id": "12345678901234567"} |
总结
1. 时钟问题:必须处理的现实
最佳实践:
- 使用
waitNextMillis处理小范围回拨(<5ms) - 记录回拨日志,监控回拨频率
- 准备随机数兜底方案
// 综合方案
public long nextId() {
try {
return snowflake.nextId();
} catch (ClockBackwardException e) {
if (e.getBackwardMs() < 5) {
waitAndRetry(e.getBackwardMs());
return snowflake.nextId();
} else {
log.error("严重时钟回拨", e);
return fallbackIdGenerator.nextId();
}
}
}
2. 机器ID:自动分配优于手动配置
最佳实践:
- 使用IP计算 + ZK持久化的混合方案
- 实现workerId心跳保活
- 支持workerId动态回收
public class WorkerIdManager {
// IP计算为主,ZK注册为辅
public long getWorkerId() {
long ipBasedId = ipCalculator.getWorkerId();
// 在ZK注册,如果冲突则重新计算
boolean registered = zkRegistrar.register(ipBasedId);
if (registered) {
return ipBasedId;
} else {
// 冲突,使用ZK分配的ID
return zkRegistrar.assignWorkerId();
}
}
}
3. 并发性能:预留足够余量
最佳实践:
- 监控序列号使用率
- 为突发流量预留buffer(如使用80%容量预警)
- 考虑升级到微秒级时间戳
public class SnowflakeMonitor {
@Scheduled(fixedRate = 60000) // 每分钟检查
public void monitorSequenceUsage() {
double usageRate = sequenceCounter.getUsageRate();
if (usageRate > 0.8) {
log.warn("序列号使用率过高: {}%", usageRate * 100);
alertService.sendAlert("SNOWFLAKE_HIGH_USAGE",
"序列号使用率: " + usageRate);
// 自动扩容:调整时间戳粒度
if (usageRate > 0.9) {
upgradeToMicrosecond();
}
}
}
}
4. 时间戳溢出:早做规划
最佳实践:
- 选择合理的起始时间(如项目启动时间)
- 定期检查剩余时间
- 准备升级方案(如扩展位数)
public class SnowflakeHealthCheck {
public Health check() {
long remainingYears = getRemainingYears();
if (remainingYears < 1) {
return Health.down()
.withDetail("error", "时间戳即将溢出")
.withDetail("remainingYears", remainingYears)
.build();
} else if (remainingYears < 5) {
return Health.outOfService()
.withDetail("warning", "时间戳将在5年内溢出")
.withDetail("remainingYears", remainingYears)
.build();
} else {
return Health.up()
.withDetail("remainingYears", remainingYears)
.build();
}
}
}
5. 跨系统兼容:设计时就考虑
最佳实践:
- ID对象包含多种表示形式
- API响应统一使用字符串ID
- 提供ID转换工具类
// 最终的雪花算法ID对象
@Data
@Builder
public class DistributedId {
// 核心字段
private long rawId;
private String stringId;
// 元数据
private long timestamp;
private long workerId;
private long sequence;
private long version;
// 工厂方法
public static DistributedId generate() {
long id = snowflake.nextId();
return DistributedId.builder()
.rawId(id)
.stringId(Long.toString(id))
.timestamp(extractTimestamp(id))
.workerId(extractWorkerId(id))
.sequence(extractSequence(id))
.version(1)
.build();
}
// 序列化
public String toJson() {
return "{\"id\":\"" + stringId + "\"," +
"\"timestamp\":" + timestamp + "," +
"\"workerId\":" + workerId + "}";
}
}
最后的建议
雪花算法虽然优雅,但它不是银弹。
在选择ID生成方案时,需要考虑:
- 业务规模:小系统用UUID更简单,大系统才需要雪花算法
- 团队能力:能处理好时钟回拨等复杂问题吗?
- 未来规划:系统要运行多少年?需要迁移方案吗?
如果决定使用雪花算法,建议:
- 使用成熟的开源实现(如Twitter的官方版)
- 完善监控和告警
- 准备降级和迁移方案
记住:技术选型不是寻找完美方案,而是管理复杂度的艺术。
雪花算法有坑,但只要我们知道坑在哪里,就能安全地跨过去。
如果你在雪花算法使用中遇到其他问题,欢迎留言讨论。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
更多项目实战在我的技术网站:http://www.susan.net.cn/project

 浙公网安备 33010602011771号
浙公网安备 33010602011771号