
【rust】《Rust整合OpenCV实现图片特征提取并合成整图 》
前言
环境搭建文章请看博文:Window10环境搭建 或者 Ubuntu22环境搭建
opencv环境依赖
opencv 4.5.5
LLAM 11.0.0Rust依赖项
[dependencies]
# opencv版本
opencv = { version = "0.75.0"}实现步骤
1. 加载图像
2. 图像置灰、图像归一化、高斯模糊
3. 特征点提取
4. 匹配特征点、汉明距离删选特征数据
5. 绘制特征关联图
6. 计算变换矩阵
7. 计算透视矩阵与图像对齐
8. 保存图片博主一直想研究深度学习领域,奈何专业数学知识懂的太少,又没有从代码层面切入的合适路线,但是接触机器视觉后发现是个不错的切入点,可以通过这个项目简单理解CNN卷积层的部分操作。
这里也有些深度学习的示例文章:线性网络示例、卷积神经网络示例、逻辑回归示例等,感兴趣可以看看。
加载图片
首先就是读取图片数据放到内存中,以方便后续的操作;这里准备的是有重叠的两张图片。
fn main() {
// 图片路径
let image1_path = "path/img1.png";
let image2_path = "path/img2.png";
// 加载图片数据
let image_01 = imgcodecs::imread(&image1_path, imgcodecs::IMREAD_COLOR).unwrap();
let image_02 = imgcodecs::imread(&image2_path, imgcodecs::IMREAD_COLOR).unwrap();
// 开辟窗口显示图片并设置窗口名称
highgui::imshow("result.png", &image_01).unwrap();
// 让图像窗口保持打开状态,直到用户按下任意键或点击X退出。
// 这里的 0 参数表示无限等待,直到触发任意键或点击X时结束
highgui::wait_key(0).unwrap();
}可以通过highgui依赖下的函数显示图片。
图像置灰、归一化、高斯模糊
图像置灰是为了后续提取特征点时更准确些,但是实际与彩色也没多大区别。
这里的置灰和后续的图像归一化、高斯模糊都是为了能更好的提取特征点,所以需要将两张图片信息复制一份出来做处理。
// 这里单独写了一个函数用来做置灰、归一化、高斯模糊处理
/**
* 图片置灰、归一化、高斯模糊处理
* 通过传递图片路径进行处理图片信息
*/
fn normalizetion(paths: &Vec<String>) -> Vector<Mat> {
// 处理之后的图片集合
let mut images = VectorOfMat::new();
for path in paths.iter() {
// 将图片灰度
// 将彩色图像的RGB三个通道的值加权平均,得到一个灰度值,再用这个灰度值代替RGB三个通道的值,从而得到灰度图像
let image = imgcodecs::imread(&path, imgcodecs::IMREAD_GRAYSCALE).unwrap();
// 归一化后的图片结果
let mut image_rust = Mat::default();
// 图像归一化
// 归一化是一种线性变换操作,通过对图像每个像素值进行特定的变换,将其限制在[0, 1] 或 [-1, 1] 的范围内。
// 归一化的目的是使图像的像素值分布更均匀,更有利于后续的图像处理和分析
normalize(
&image,
&mut image_rust,
0.0,
255.0,
core::NORM_MINMAX,
core::CV_8UC1,
&core::no_array(),
).unwrap();
// 高斯模糊之后的图片结果
let mut img = Mat::default();
// 进行高斯模糊
// 高斯模糊能够更加自然地平滑图像,同时较好地保留边缘信息,如果有高清图像且特征点相似度很高就会出现拼接异常的情况
// 这种时候可以通过模糊图片减少部分无用的特征点信息,使匹配更精准
// 第三个参数是高斯核的大小 (必须是正数和奇数)
// 第四个和第五个参数是 X 和 Y 方向的标准偏差
imgproc::gaussian_blur(&image_rust, &mut img, core::Size::new(9, 9), 0.0, 0.0, core::BORDER_DEFAULT).unwrap();
images.push(img);
}
images
}特征点提取
特征点提取就是将两张图片的共性提取出来,用于后续的计算与拼接;通过特征点的关联性就可以做相应的偏移。
下面提供两种特征提取算法,ORB算法 与 SIFT算法,算法具体原理可以自行查找;我使用的是SIFT算法进行的特征提取。
/**
* ORB算法提取特征点
*/
fn extract_features_orb(image: &Mat) -> (Vector<core::KeyPoint>, Mat) {
// 使用ORB特征检测器和描述子提取器进行特征提取
// 创建 ORB 特征检测器
let mut orb = <dyn ORB>::create(
500,
1.2,
8,
31,
0,
2,
features2d::ORB_ScoreType::HARRIS_SCORE,
31,
20,
).unwrap();
// 提取之后的特征点集合
let mut keypoints = types::VectorOfKeyPoint::new();
// 提取之后的描述符信息
let mut descriptors = Mat::default();
// 提取特征点
orb.detect_and_compute(&image, &Mat::default(), &mut keypoints, &mut descriptors, false).unwrap();
// 绘图,通过图片直观的了解特征点的关联信息
let mut dst_img = Mat::default();
features2d::draw_keypoints(
&image,
&keypoints,
&mut dst_img,
core::VecN([0., 255., 0., 255.]),
features2d::DrawMatchesFlags::DEFAULT,
).unwrap();
highgui::imshow("window", &dst_img).unwrap();
highgui::wait_key(0).unwrap();
(keypoints, descriptors)
}
/**
* SIFT算法提取特征点
*/
fn extract_features_sift(image: &Mat) -> (Vector<core::KeyPoint>, Mat) {
// 使用SIFT算法提取特征点
let mut sift = features2d::SIFT::create(0, 3, 0.04, 10., 1.6).unwrap();
// 提取之后的特征点集合
let mut keypoints = Vector::default();
// 提取之后的描述符信息
let mut descriptors = Mat::default();
// 提取特征点
sift.detect_and_compute(&image, &Mat::default(), &mut keypoints, &mut descriptors, false).unwrap();
// 创建一个新的 Mat 来存储转换后的描述符信息
let mut descriptors_u8 = Mat::default();
// 由于后面操作需要CV_8U类型的数据,所以需要将SIFT返回的 CV_32F 类型数据转换为 CV_8U 类型
// ORB 特征检测器的返回结果就是CV_8U类型,所以不需要转换
descriptors.convert_to(&mut descriptors_u8, core::CV_8U, 1.0, 0.0).unwrap();
// 绘图,通过图片直观的了解特征点的关联信息
let mut dst_img = Mat::default();
features2d::draw_keypoints(
&image.clone(),
&keypoints,
&mut dst_img,
core::VecN([0., 0., 255., 255.]),
features2d::DrawMatchesFlags::DEFAULT,
).unwrap();
highgui::imshow("window", &dst_img).unwrap();
highgui::wait_key(0).unwrap();
(keypoints, descriptors_u8)
} 

匹配特征点
两张图的特征点都提取出来后,就需要将他们匹配在一起,这样才清楚两张图片的共同特征在哪,方便后续拼接图片。
/**
* 匹配特征点(匹配描述符)
*/
fn match_features(descriptors1: &Mat, descriptors2: &Mat) -> Vector<DMatch> {
// 创建Brute-Force匹配器
let mut matcher = features2d::BFMatcher::new(core::NORM_HAMMING, true).unwrap();
// 首先添加训练集信息,这里放的是图片2的描述符信息
matcher.add(&descriptors2).unwrap();
// 特征匹配之后的关联信息
let mut matches = types::VectorOfDMatch::new();
// 添加比对图片的描述信息,开始匹配
matcher.match_(&descriptors1, &mut matches, &Mat::default()).unwrap();
// 由于特征点集内不全是优秀的特征点,所以可以通过算法筛去部分无用特征点信息
// 通过汉明距离删选特征数据
let mut min_dist = 1000.;
let mut max_dist = 0.;
for m in matches.iter() {
if m.distance < min_dist {
min_dist = m.distance;
}
if m.distance > max_dist {
max_dist = m.distance;
}
}
let mut good_matches = types::VectorOfDMatch::new();
for mut m in matches.iter() {
let max1 = std::cmp::max(
(2 * min_dist.round() as i32),
20
);
if m.distance <= max1 as f32 {
&good_matches.push(m);
}
}
// 最后得到的就是比较好的特征点关联信息
good_matches
}绘制特征关联图
通过得到的优秀特征点集与刚才的整体特征点集就可以绘制直观图像特征关联关系。
/**
* 通过关键点绘制图
*/
fn draw(img1: &Mat, img2: &Mat, keypoints1: &Vector<core::KeyPoint>, keypoints2: &Vector<core::KeyPoint>,
matches: &Vector<DMatch>) {
let mut img_matches = Mat::default();
draw_matches(
&img1, &keypoints1, &img2, &keypoints2, &matches, &mut img_matches,
Scalar::new(255.0, 0.0, 0.0, 0.0), Scalar::new(0.0, 255.0, 0.0, 0.0),
&Vector::default(), features2d::DrawMatchesFlags::DEFAULT,
).unwrap();
highgui::imshow("Matches", &img_matches).unwrap();
highgui::wait_key(0).unwrap();
}
计算变换矩阵
使用RANSAC算法进行求解仿射变换的仿射变换参数,仿射变换通常操作图像的旋转、缩放、平移等操作。
/**
* 计算变换矩阵
*/
fn compute_homography(points1: &Vector<KeyPoint>, points2: &Vector<KeyPoint>, matches: &types::VectorOfDMatch) -> Mat {
// 这里将特征点信息转换为Mat类型
let keypoints1 = convert_mat(points1);
let keypoints2 = convert_mat(points2);
// 转换特征点结构
let mut src_points = types::VectorOfPoint2f::new();
let mut dst_points = types::VectorOfPoint2f::new();
// 将第一幅图和第二幅图的特征点坐标拿出来
for m in matches.iter() {
// 第一幅图特征点
let src_point = Mat::at::<Point2f>(&keypoints1, m.query_idx as i32).unwrap();
// 第二幅图特征点
let dst_point = Mat::at::<Point2f>(&keypoints2, m.train_idx as i32).unwrap();
src_points.push(*src_point);
dst_points.push(*dst_point);
}
// 使用RANSAC算法计算变换矩阵
// 根据匹配上的关键点去计算单应性矩阵 第一幅图针对第二幅图的视角计算单应性矩阵
// 参数5表示:允许有5个关键点的误差
let homography = opencv::calib3d::find_homography(
&src_points,
&dst_points,
&mut core::no_array(),
opencv::calib3d::RANSAC,
5.0,
).unwrap();
homography
}计算透视矩阵与图像对齐
透视矩阵变换就是将二维图转三维进行操作后画在二维得图像平面上,通过获取的数值进行拼接图像。
/**
* 对齐图像
*/
fn align_image(image1: &Mat, image2: &Mat, homography: &mut Mat) -> Mat {
// 获取图像1和2的宽度和高度
let (width1, height1) = (&image1.size().unwrap().width, &image1.size().unwrap().height);
let (width2, height2) = (&image2.size().unwrap().width, &image2.size().unwrap().height);
// 定义原始图像的边界坐标
let mut corners1 = types::VectorOfPoint2f::new();
corners1.push(Point2f::new(0.0, 0.0));
corners1.push(Point2f::new(0., (*height1 - 1) as f32));
corners1.push(Point2f::new((*width1 - 1) as f32, (*height1 - 1) as f32));
corners1.push(Point2f::new((*width1 - 1) as f32, 0.));
let mut corners2 = types::VectorOfPoint2f::new();
corners2.push(Point2f::new(0.0, 0.0));
corners2.push(Point2f::new(0., (*height2 - 1) as f32));
corners2.push(Point2f::new((*width2 - 1) as f32, (*height2 - 1) as f32));
corners2.push(Point2f::new((*width2 - 1) as f32, 0.));
let mut img_transform = types::VectorOfPoint2f::new();
// 计算透视变换矩阵
perspective_transform(&corners1, &mut img_transform, homography).unwrap();
// 把图片2的坐标与转换后的边界坐标合并
corners2.extend(img_transform);
// 获取 x 坐标的最大值与最小值
let max_x = corners2.iter().map(|p| p.x).fold(f32::NEG_INFINITY, f32::max);
let min_x = corners2.iter().map(|p| p.x).fold(f32::INFINITY, f32::min);
// 获取 y 坐标的最大值与最小值
let max_y = corners2.iter().map(|p| p.y).fold(f32::NEG_INFINITY, f32::max);
let min_y = corners2.iter().map(|p| p.y).fold(f32::INFINITY, f32::min);
// 将 homography 转换为 Vec<Point2f> 类型
let homography_vec: Vec<Vec<f64>> = homography.to_vec_2d::<f64>().unwrap();
// 这里做矩阵相乘
let mut mat_vec: Vec<Vec<f64>> = Vec::new();
mat_vec.push([1., 0., -min_x as f64].into());
mat_vec.push([0., 1., -min_y as f64].into());
mat_vec.push([0., 0., 1.].into());
let mut vec = dot_product(&mat_vec, &homography_vec);
let mut aligned_image = Mat::default();
// 应用透视变换进行画布内图像填充
warp_perspective(
&image1,
&mut aligned_image,
&mut vec,
core::Size::new((max_x.round() - min_x.round() + 1.) as i32, (max_y.round() - min_y.round() + 1.) as i32),
imgproc::INTER_LINEAR,
core::BORDER_CONSTANT,
Scalar::default(),
).unwrap();
// 定义ROI并将img2复制到aligned_image画布的指定区域
let roi = Rect::new(
-min_x as i32,
-min_y as i32,
image2.size().unwrap().width,
image2.size().unwrap().height);
let mut mat = Mat::roi(&aligned_image, roi).unwrap();
image2.copy_to(&mut mat).unwrap();
aligned_image
}保存图片
将拼接后的图像进行保存。
// 保存图像
let output_path = "path/save/result.png";
imgcodecs::imwrite(output_path, &aligned_image, &Vector::<i32>::new()).unwrap(); 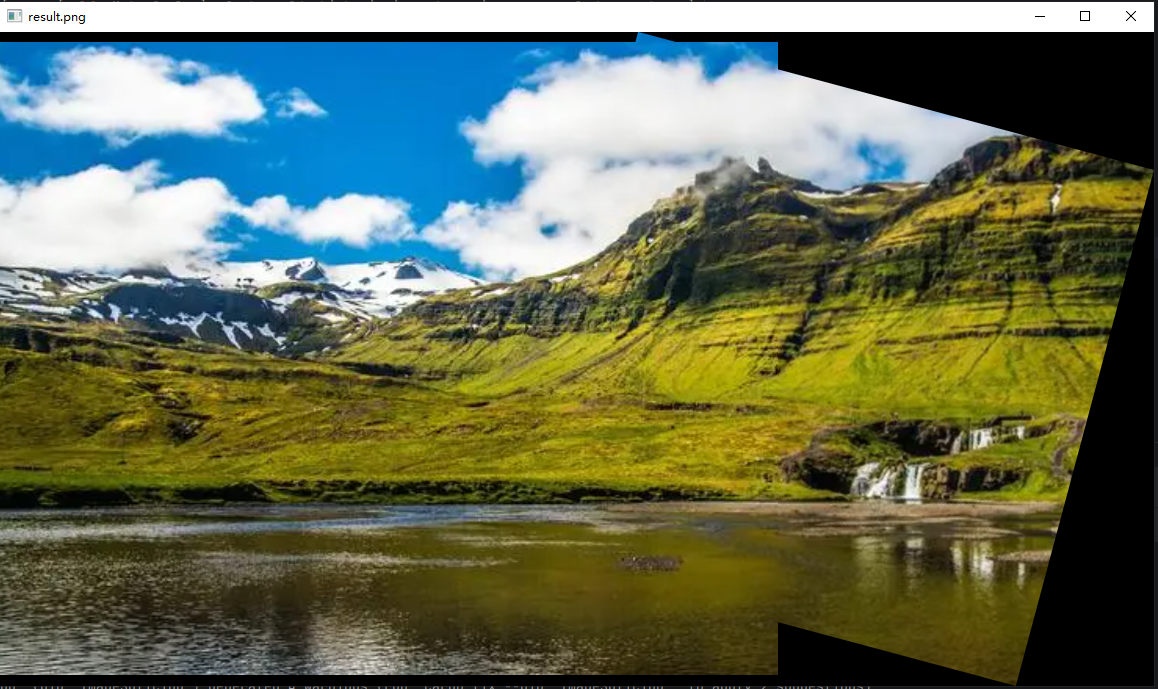
完成!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号