【rust】《Rust深度学习[5]-理解卷积神经网络(Candle)》
卷积神经网络
Convolutional Neural Network,简称为CNN。CNN与一般的顺传播型神经网络不同,它不仅是由全结合层,还由卷积层(Convolution Layer)和池层(Pooling Layer)构成的神经网络。
在卷积层和池化层中,如下图所示,缩小输入神经元的一部分区域,局部地与下一层进行对应。每一层都有一个称为过滤器的探测器。
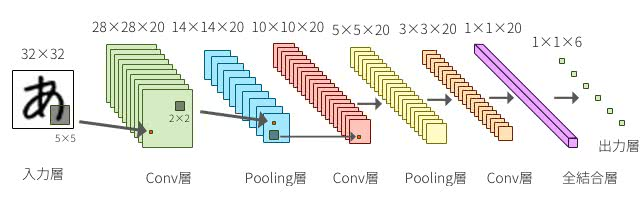
在图像识别的例子中,在第一层检测边缘,在下一层检测纹理,然后在下一层检测更抽象的特征,如猫的耳朵。CNN自动学习过滤器的参数,过滤器是提取这些特征的检测器。
依赖
[package]
name = "mnist-ml-cnn"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
anyhow = "1.0.82"
candle-core = "0.4.1"
candle-datasets = "0.4.1"
candle-nn = "0.4.1"
rand = "0.8.5"代码
use candle_core::{DType, Result, Tensor, D, Device};
use candle_nn::{loss, ops, Conv2d, Linear, Optimizer, VarBuilder, VarMap};
use rand::prelude::*;
// 0 - 10 数字分析的常量
const LABELS: usize = 10;
// 模型接口
trait Model: Sized {
// 创建实例
fn new(vs: VarBuilder) -> Result<Self>;
// 执行函数
fn forward(
&self,
xs: &Tensor,
) -> Result<Tensor>;
}
// 卷积神经网络
#[derive(Debug)]
struct ConvolutionalNetwork {
// 卷积一层
conv1: Conv2d,
// 卷积二层
conv2: Conv2d,
// 线性一层
fc1: Linear,
// 线性二层
fc2: Linear,
}
// 卷积神经网络实现模型接口
impl Model for ConvolutionalNetwork {
// 实例化对象
fn new(vs: VarBuilder) -> Result<Self> {
// 创建一层卷积层
let conv1 = candle_nn::conv2d(
// 输入通道
1,
// 输出通道
32,
// 内核大小
5,
Default::default(),
vs.pp("c1"),
)?;
let conv2 = candle_nn::conv2d(
// 输入通道(接收一层的输出)
32,
// 输出通道
64,
// 内核大小
5,
Default::default(),
vs.pp("c2"),
)?;
// 创建线性一层 输入维度1024 输出维度1024
let fc1 = candle_nn::linear(1024, 1024, vs.pp("fc1"))?;
// 创建线性二层 输入维度1024 输出维度10
let fc2 = candle_nn::linear(1024, LABELS, vs.pp("fc2"))?;
// 返回对象
Ok(Self {
conv1,
conv2,
fc1,
fc2,
})
}
// 执行函数
fn forward(
&self,
xs: &Tensor,
) -> Result<Tensor> {
// 拆分数组为 (批量大小, 图像尺寸)
let (batch_size, _image_dimension) = xs.dims2()?;
// 四维数组,格式化为28 * 28灰度图像
xs.reshape((batch_size, 1, 28, 28))?
// 应用卷积一层
.apply(&self.conv1)?
// 应用第一个池化层来压缩
.max_pool2d(2)?
// 应用卷积二层
.apply(&self.conv2)?
// 应用第二个池化层来压缩
.max_pool2d(2)?
// 平铺成一维向量
.flatten_from(1)?
// 应用第一层线性层
.apply(&self.fc1)?
// 调用ReLU激活函数
.relu()?
// 应用第二层线性层
.apply(&self.fc2)
}
}
// 调用传参实体
struct TrainingArgs {
// 学习率
learning_rate: f64,
// 参数
load: Option<String>,
// 保存
save: Option<String>,
// 迭代次数
epochs: usize,
}
// 循环训练
fn training_loop(
dateset: candle_datasets::vision::Dataset,
args: &TrainingArgs,
) -> anyhow::Result<()> {
const BSIZE: usize = 64;
// let device = candle_core::Device::cuda_if_available(0)?;
// cpu资源
let device = Device::Cpu;
// 训练集的标签集
let train_labels = dateset.train_labels;
// 训练集的图片集(数据集)
let train_images = dateset
.train_images
// 加载到Cpu
.to_device(&device)?;
// 训练集的标签集
let train_labels = train_labels
// 设置类型为U32
.to_dtype(DType::U32)?
// 加载到Cpu
.to_device(&device)?;
// 声明Var集合(VarMap用于管理超参数的集合)
let mut var_map = VarMap::new();
// Var构建参数
let var_builder_args =
VarBuilder::from_varmap(&var_map, DType::F32, &device);
// 创建卷积神经网络模型
let model = ConvolutionalNetwork::new(var_builder_args.clone())?;
// 将传入参数解构出来
if let Some(load) = &args.load {
println!("loading weights from {load}");
var_map.load(load)?
}
// 创建一个新的学习率(learning rate)调度器实例
let mut optimizer =
// 学习率是优化算法中非常重要的超参数,它控制模型在训练过程中权重更新的速度。通过调整学习率,可以影响模型的训练效果和收敛速度
candle_nn::AdamW::new_lr(var_map.all_vars(), args.learning_rate)?;
// 测试集图片集(数据集)
let test_images = dateset
.test_images
// 加载到Cpu
.to_device(&device)?;
// 测试集标签集
let test_labels = dateset
.test_labels
// 设置类型为U32
.to_dtype(DType::U32)?
// 加载到Cpu
.to_device(&device)?;
// 获取训练集的图片集第一个维度的大小 并除以 64
let batches = train_images.dim(0)? / BSIZE;
// 通过一层维度长度创建Vec一维数组
let mut batch_indices = (0..batches).collect::<Vec<usize>>();
// 开始迭代训练
for epoch in 1..args.epochs {
// 损失值总和
let mut sum_loss = 0f32;
// 对向量 vec 中的元素进行随机重排,使用当前线程的随机数生成器来生成随机性。
// &mut thread_rng():用于生成随机数的线程本地的随机数生成器(thread-local random number generator)
// thread_rng() 函数可以获取一个可变引用(&mut)到当前线程的随机数生成器,这样可以确保在多线程环境下每个线程都有自己的随机数生成器,避免竞争条件
batch_indices.shuffle(&mut thread_rng());
// 迭代Vec数组
for batch_index in batch_indices.iter() {
// 获取指定大小的训练图像集切片
let train_images =
// 0维, 随机数值*64, 64
train_images.narrow(0, batch_index * BSIZE, BSIZE)?;
// 获取指定大小的训练标签集切片
let train_labels =
// 0维, 随机数值*64, 64
train_labels.narrow(0, batch_index * BSIZE, BSIZE)?;
// 通过卷积神经网络训练
let logits = model.forward(&train_images)?;
// 调用激活函数(将输出转换为概率分布)
let log_softmax = ops::log_softmax(&logits, D::Minus1)?;
// 调用损失函数(计算损失值)
let loss = loss::nll(&log_softmax, &train_labels)?;
// 使用 AdamW 优化器进行反向传播更新模型参数
// .backward_step(&loss) 表示对给定的损失值进行反向传播并更新模型参数
// 更新模型参数: 根据 AdamW 优化算法的规则,利用计算得到的梯度来更新模型参数。
// AdamW 是 Adam 优化算法的一种变体,它在梯度更新时引入了权重衰减(weight decay)的概念,以减少过拟合的风险
optimizer.backward_step(&loss)?;
// 将历史损失值相加
// loss.to_vec0::<f32>() 将损失值转换为一个长度为 1 的向量,并且将其中的元素类型转换为 f32 类型。
sum_loss += loss.to_vec0::<f32>()?;
}
// 计算平均损失值
let avg_loss = sum_loss / batches as f32;
// 通过卷积神经网络训练测试集的图像集
let test_logits = model.forward(&test_images)?;
// 计算模型在测试集上正确分类的样本数量
let sum_ok = test_logits
// 对 test_logits 进行 argmax 操作,返回沿着最后一个维度的最大值的索引
.argmax(D::Minus1)?
// 将上一步得到的索引与 测试集的标签集 进行逐元素比较,生成一个布尔类型的张量,表示对应位置的元素是否相等
.eq(&test_labels)?
// 将上一步得到的布尔类型的张量转换为 f32 类型的张量,其中 true 被转换为 1.0,false 被转换为 0.0
.to_dtype(DType::F32)?
// 对上一步得到的张量进行求和操作,将所有元素相加得到一个标量(scalar)
.sum_all()?
// 将上一步得到的标量转换为 f32 类型的数值
.to_scalar::<f32>()?;
// 正确分类的样本数量除以测试集中样本的总数,以得到模型在测试集上的准确率
let test_accuracy = sum_ok / test_labels.dims1()? as f32;
println!("{epoch:4} train loss {:8.5} test acc: {:5.2}%",
avg_loss, 100. * test_accuracy);
}
// 保存模型的参数到指定的路径
if let Some(save) = &args.save {
println!("saving trained weights in {save}");
var_map.save(save)?
}
Ok(())
}
pub fn main() -> anyhow::Result<()> {
// 下载数据集
let dataset = candle_datasets::vision::mnist::load()?;
println!("train-images: {:?}",dataset.train_images.shape());
println!("train-labels: {:?}",dataset.train_labels.shape());
println!("test-images: {:?}",dataset.test_images.shape());
println!("test-labels: {:?}",dataset.test_labels.shape());
// 模拟参数
let training_args = TrainingArgs {
// 迭代次数
epochs: 10,
// 学习率
learning_rate: 0.001,
// 参数
load: None,
// 保存
save: None,
};
// 训练模型
training_loop(dataset, &training_args)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号