第四次作业
作业①:
要求:
1.熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
2.使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、 “上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站: 东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
1.核心代码:
def parse_rows_and_store(driver, field_index, db, board_name):
# 获取表格所有行
rows = driver.find_elements(By.XPATH, "//table//tbody//tr")
code_col = field_index.get("bStockNo", 2) # 获取代码所在列索引
valid_rows = []
found_first_valid = False
for row in rows:
code_text = get_cell_text(row, code_col)
if not found_first_valid:
if is_valid_stock_code(code_text): # 正则判断是否为6位数字
found_first_valid = True
valid_rows.append(row)
else:
valid_rows.append(row)
# 数据提取与入库
for row in valid_rows:
try:
tds = row.find_elements(By.XPATH, "./td")
get_val = lambda f: tds[field_index[f]-1].text.strip() if f in field_index else ""
code = get_val("bStockNo"
data = {
"bStockNo": code,
"bStockName": get_val("bStockName"),
"latest_price": try_float(get_val("latest_price")),
"change_percent": get_val("change_percent"),
"board": board_name
}
db.insert_stock(data)
except Exception:
continue
#动态表头映射防止网站调整列顺序导致抓错数据
def build_header_index(driver):
# 抓取表头文字
ths = driver.find_elements(By.XPATH, "//table//thead//tr//th")
headers = [th.text.strip().replace("\n","") for th in ths]
field_index = {}
for i, h in enumerate(headers, start=1):
if h in HEADER_TO_FIELD:
field_index[HEADER_TO_FIELD[h]] = i
return field_index
#翻页
def robust_pagination(driver):
# 1. 记录翻页前特征
old_key = get_table_first_row_key(driver)
# 2. 点击下一页按钮
click_next_page(driver)
end_time = time.time() + 10
while time.time() < end_time:
new_key = get_table_first_row_key(driver)
if new_key and new_key != old_key:
return True
time.sleep(0.5)
return False
前面的作业已经爬取过多次该网站,我们要抓去的数据都是存在很规整的td里的,所以只需要使用一个XPATH语句//table//thead//tr//th便可以抓取到。同时由于第三列相关链接不是我们需要的数据,但是属于同样的element,所以需要做动态表头映射防止网站调整列顺序导致抓错数据。

接下来做翻页处理。网页 AJAX 加载新数据需要时间。如果不加等待,代码会继续抓取上一页的数据,导致大量重复。我只根据网页是否变化判断是否翻页,这样翻页是不会依赖动态网页,能够有效翻页。
2.运行结果

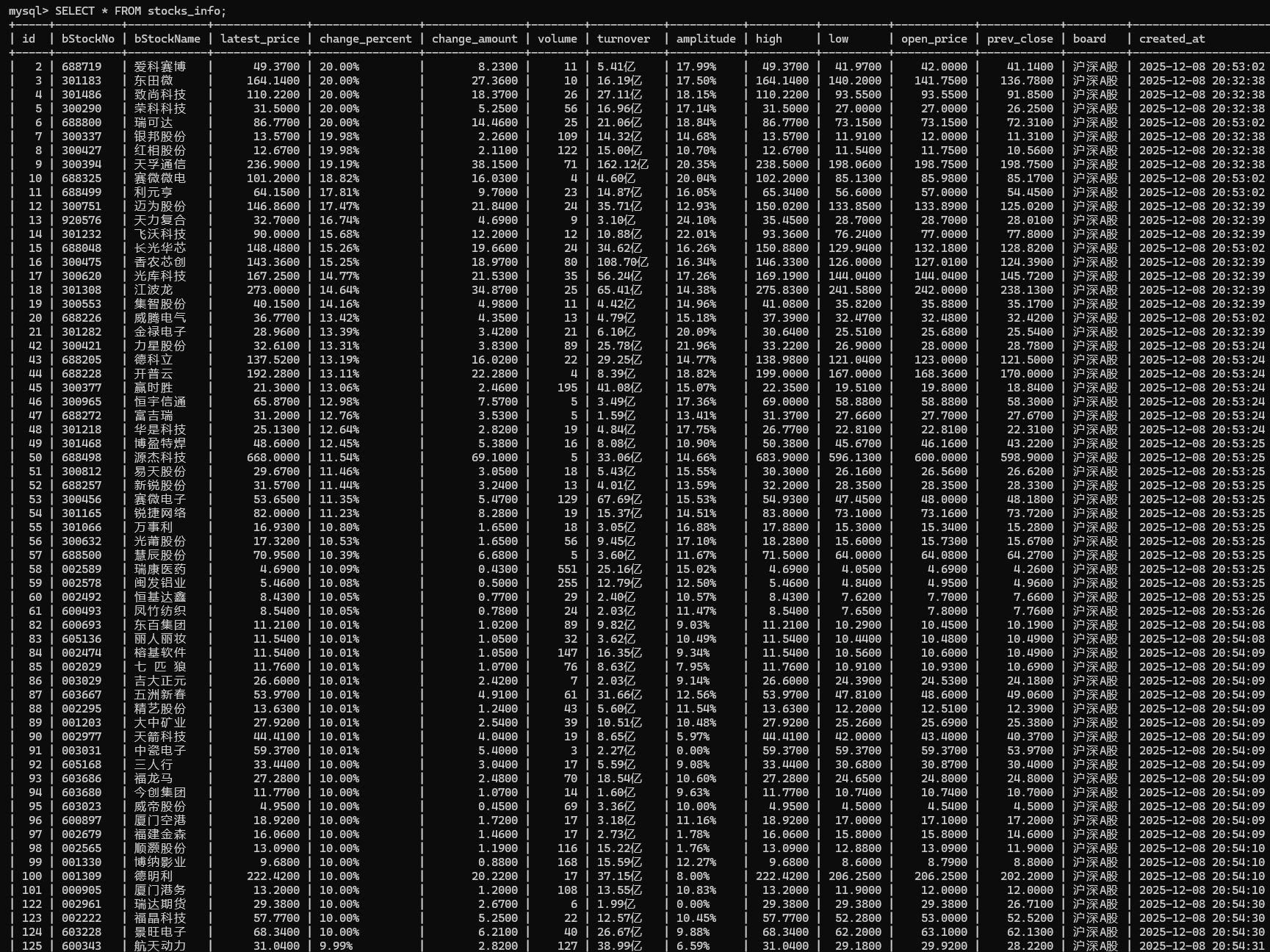
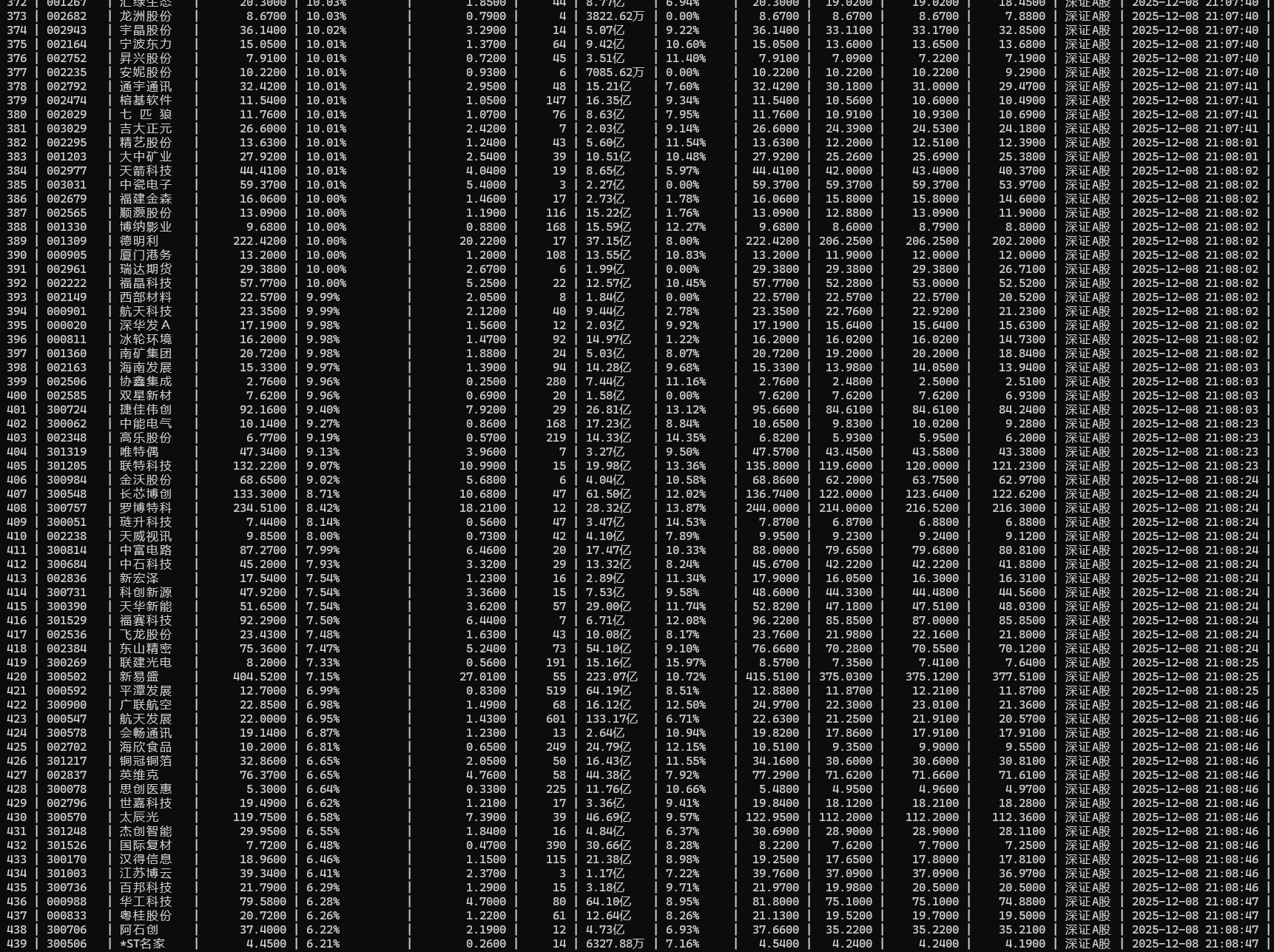
我的代码里只根据关键词爬取单种股票,所以我运行了三次并分别存入数据库,每种股票爬取五页。
3.心得体会:
这道题我学会了用动态表头映射应对列序漂移,用数据特征比对确保翻页刷新,配合正则清洗防过滤干扰,这样可以使爬虫更加稳健和精准。
作业②:
要求:
1.熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
2.使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站: 中国 mooc 网: https://www.icourse163.org
1.核心代码:
import re
from selenium.webdriver.common.by import By
def parse_detail_page_core(driver):
# 获取课程名
cCourse = "未知课程"
title_xpaths = ["//span[contains(@class,'course-title')]", "//h1", "//h4"]
for xp in title_xpaths:
try:
cCourse = driver.find_element(By.XPATH, xp).text.strip()
break
except: continue
# 获取学校 -
cCollege = "未知学校"
try:
school_img = driver.find_element(By.XPATH, "//div[contains(@class,'m-teachers')]//a//img")
cCollege = school_img.get_attribute("alt")
except:
pass
# 获取人数
cCount = "统计中"
try:
# 定位包含人数的元素
raw_text = driver.find_element(By.XPATH, "//div[@id='course-enroll-info']//span[contains(@class,'count')]").text
# 使用正则表达式提取纯数字部分
match = re.search(r'(\d+(?:\.\d+)?[万]?)', raw_text)
if match:
cCount = match.group(1) # 提取结果:1.2万
except:
pass
return {"cCourse": cCourse, "cCollege": cCollege, "cCount": cCount}
def main_loop_core(driver, course_urls):
all_data = []
# 记录当前主窗口(课程列表页)的句柄
original_window = driver.current_window_handle
for url in course_urls:
# 1. 打开新标签页
driver.execute_script(f"window.open('{url}');")
# 2. 切换 Selenium 的视角到最新的标签页
driver.switch_to.window(driver.window_handles[-1])
# 3. 执行解析
data = parse_detail_page_core(driver)
if data: all_data.append(data)
# 4. 关闭当前详情页,切回主窗口,准备处理下一个
driver.close()
driver.switch_to.window(original_window)
return all_data
刚开始爬取mooc上的数据时,我发现mooc网页的数据比较杂乱,很多页面数据存储的地方不一样,所以我退而求其次,只爬取我账号课程里的数据。之后我逐一定位所需字段所在位置,利用XPATH爬取指定字段

代码主要是首先通过模拟登录进入个人中心提取所有课程链接,随后利用 Selenium 的多窗口切换机制逐一访问详情页,结合正则清洗提取人数与学校信息,最后将清洗后的数据批量存入 MySQL 数据库。
2.结果展示:


3.心得体会:
我从简单的脚本编写进阶到具备工程思维的自动化开发,不仅掌握了 Selenium 多窗口调度与动态页面交互,更学会了通过动态表头映射和正则数据清洗 来构建抗干扰、高稳定的数据采集系统。
作业③:
要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验
任务一:Python 脚本生成测试数据
1.编写Python脚本
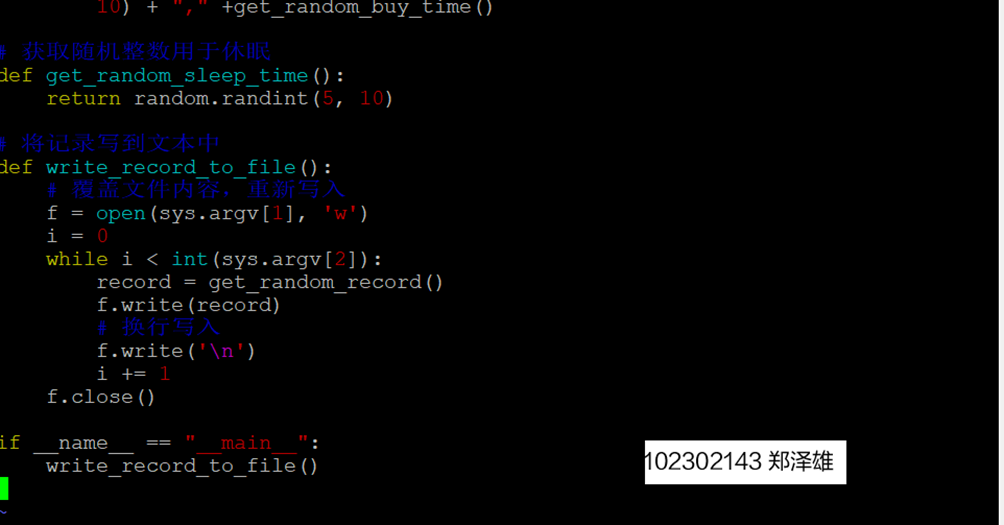
2.执行脚本测试


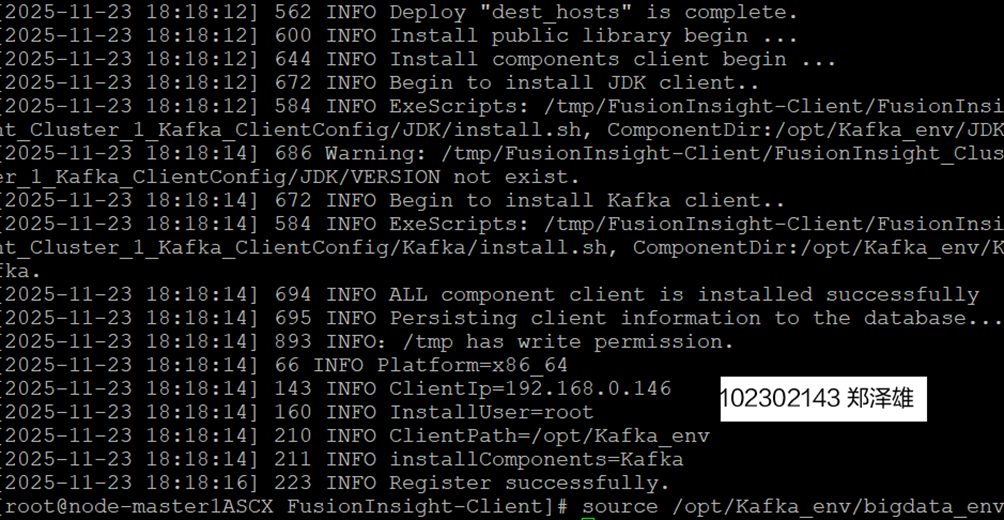
任务二:配置 Kafka
1.下载Flume客户端

2.安装Kafka客户端

3.在kafka中创建topic
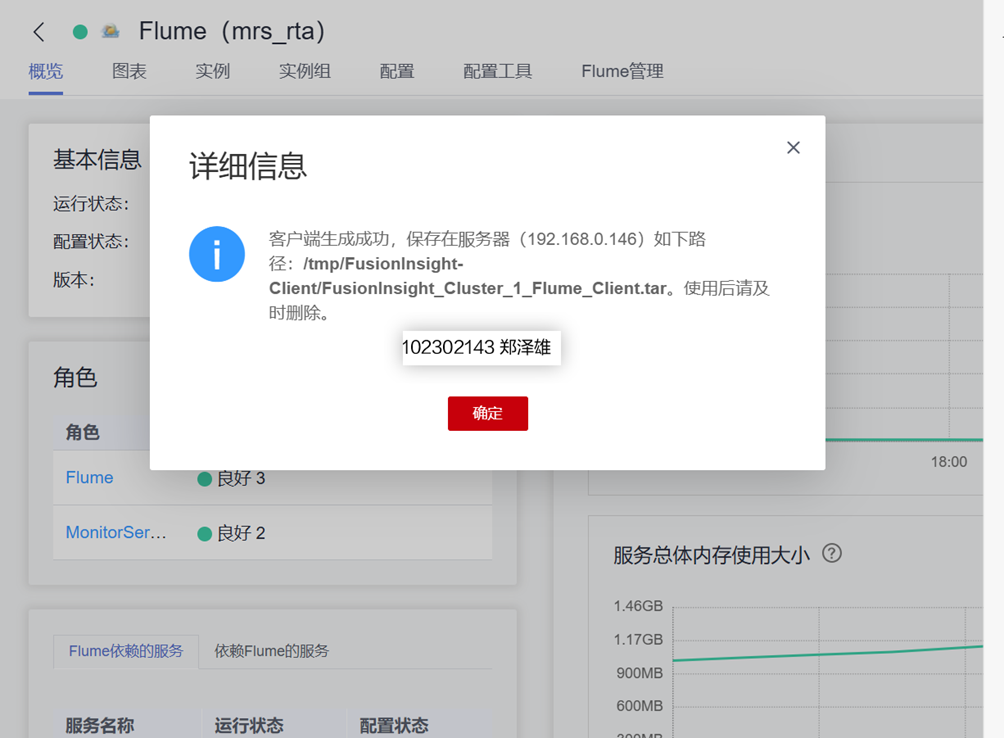
任务三:安装Flume客户端
1.下载Flume客户端
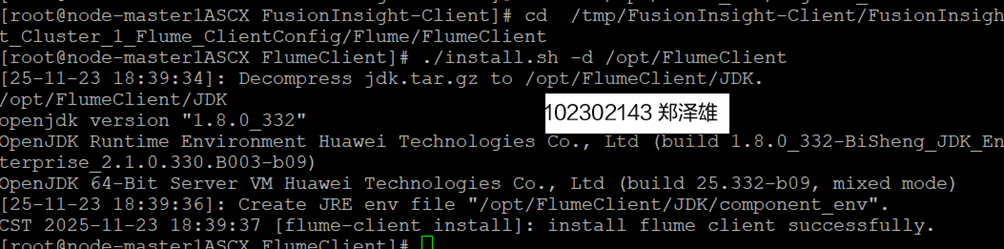
2.安装Flume客户端
任务四:配置Flume采集数据
1.修改配置文件
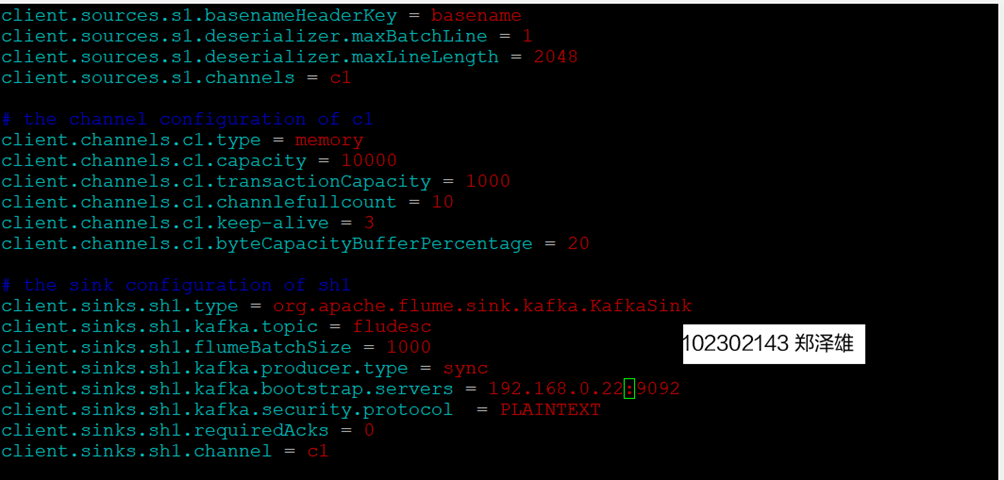
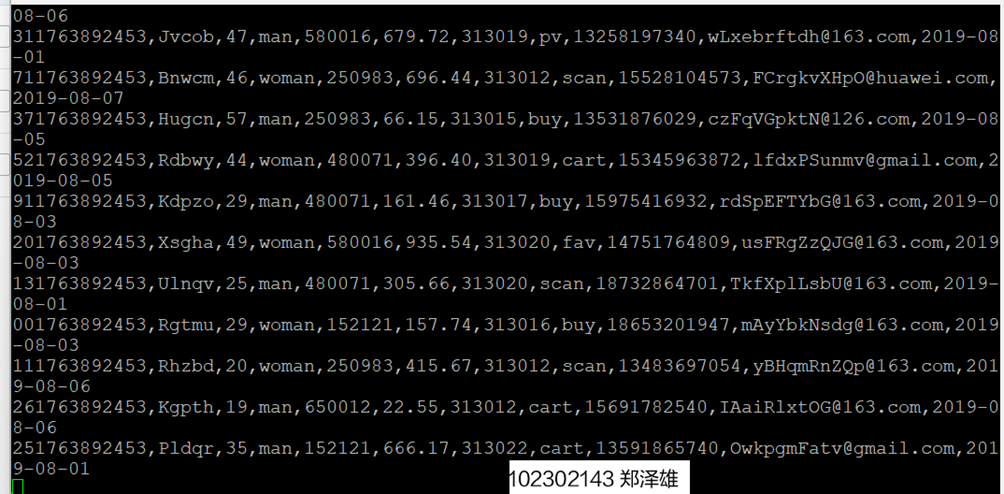
2.创建消费者消费kafka中的数据
心得体会
我通过构建端到端的实时数据处理流水线,深入掌握了从数据模拟、Flume 采集、Kafka 消息缓冲、Flink 实时计算到 MySQL 存储及 DLV 可视化的全链路技术。在实践中,我成功部署并联动了 MRS、DLI、RDS 等云原生大数据组件,验证了各组件在架构中的核心作用。特别是在解决跨源连接、安全组配置及网络互通等复杂工程问题时,我利用日志分析与连通性测试等手段,显著提升了全链路排查与系统调试的能力。
Gitee 文件夹:https://gitee.com/zzzzcsx/zzx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号