第二次作业
作业1:
1.在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
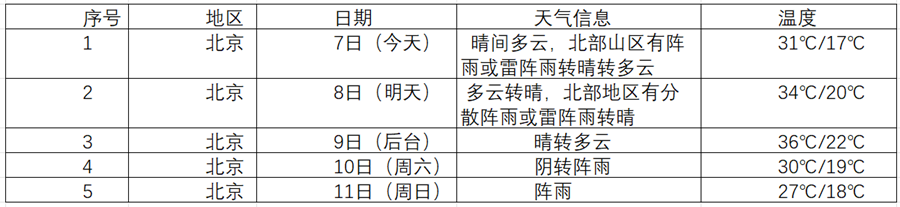
核心代码:
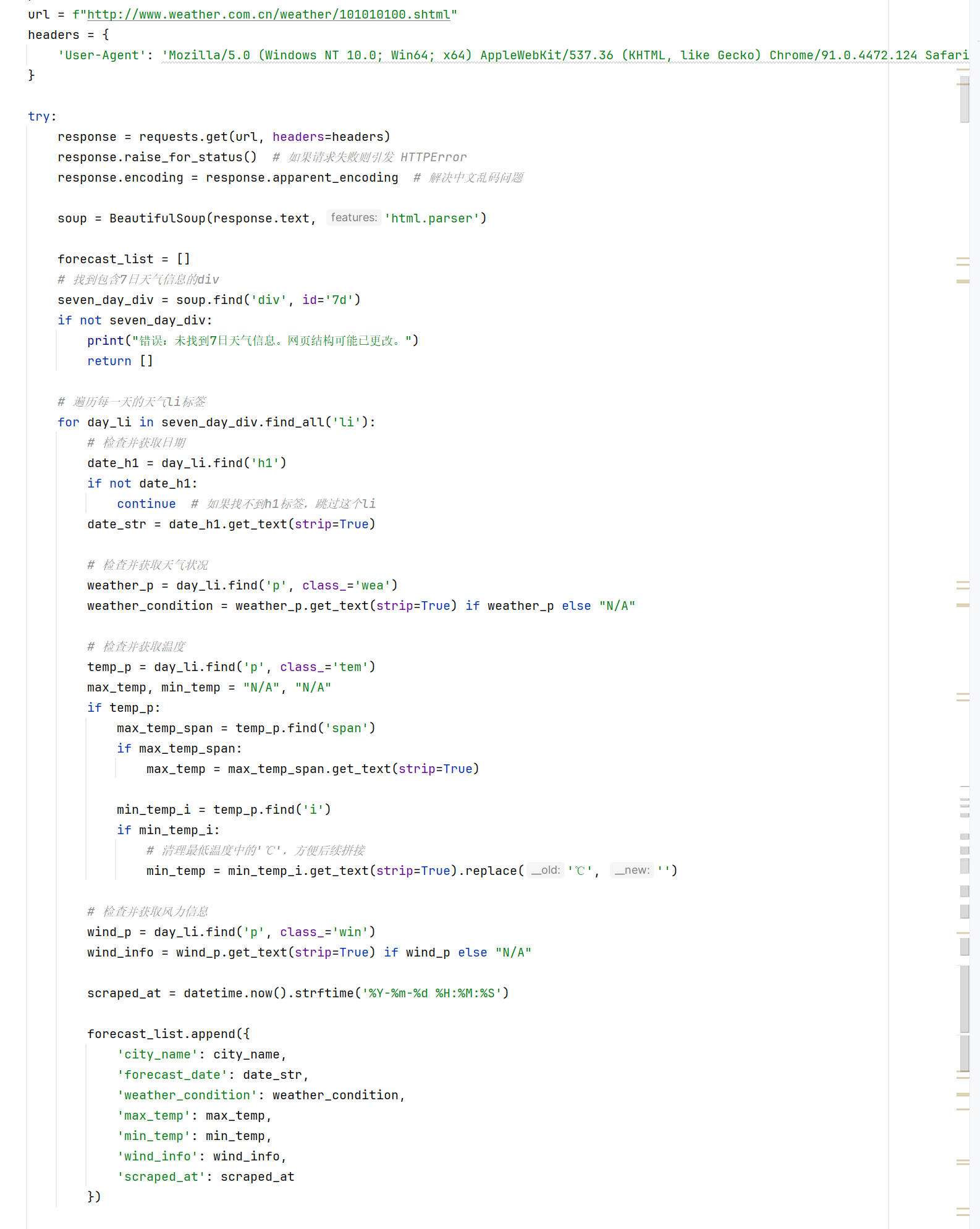
从中国气象网上获取天气预报的原始 HTML 数据,并解析出需要的信息。将抓取到的干净数据存入一个 SQLite 数据库文件中,实现数据的持久化。
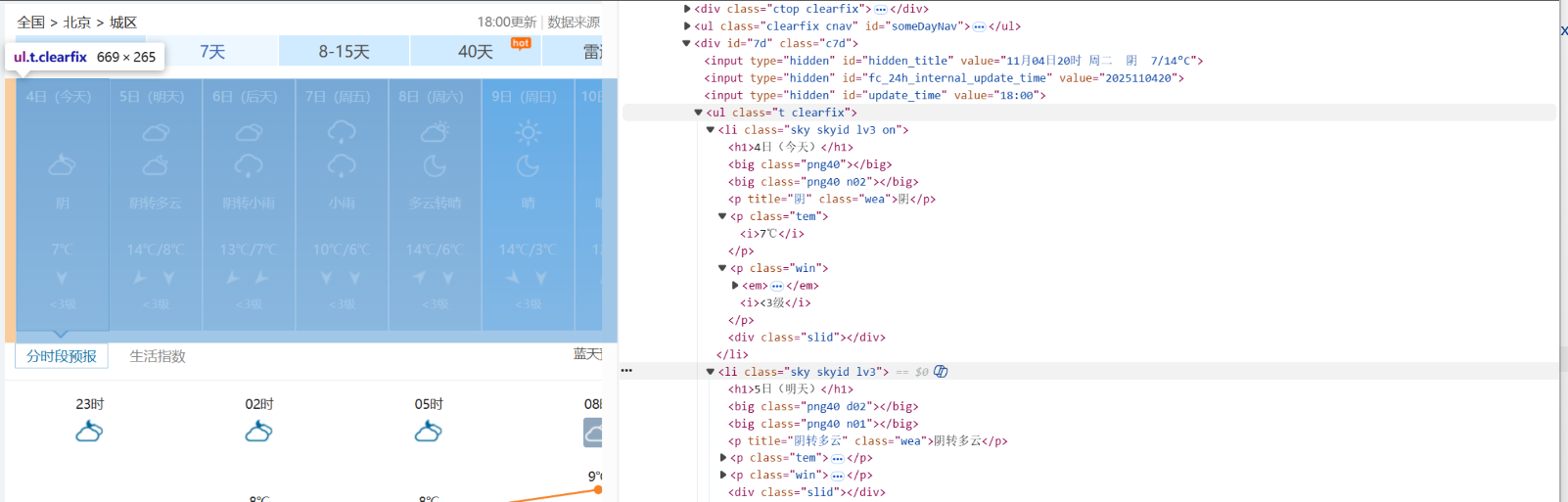
运行结果:

2.心得体会:
这道题目抓取数据不难,和前面的题目大差不差,重要的是掌握了使用sqlite3创建了一个数据库存储数据。
作业2:
1.用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
核心代码:
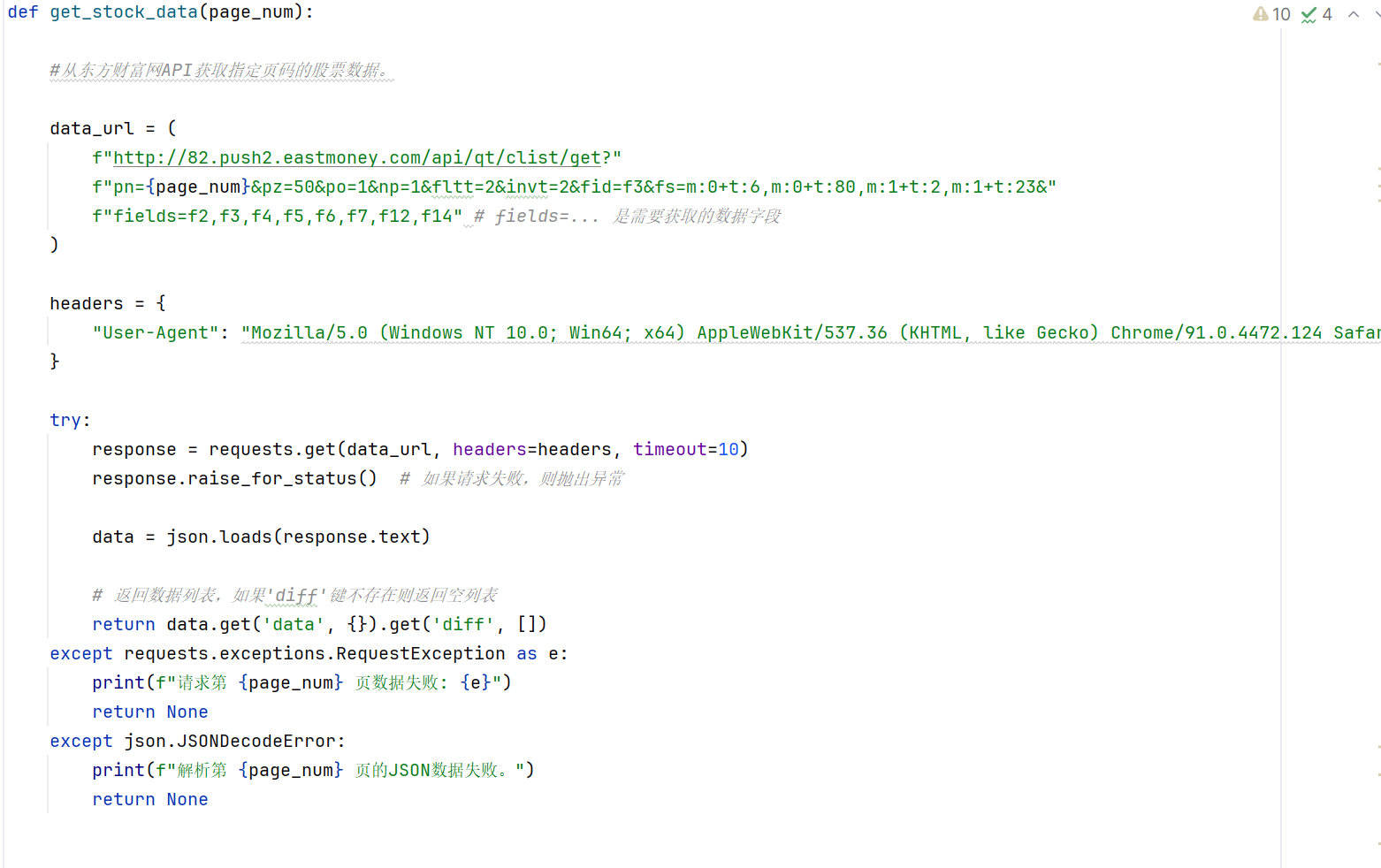
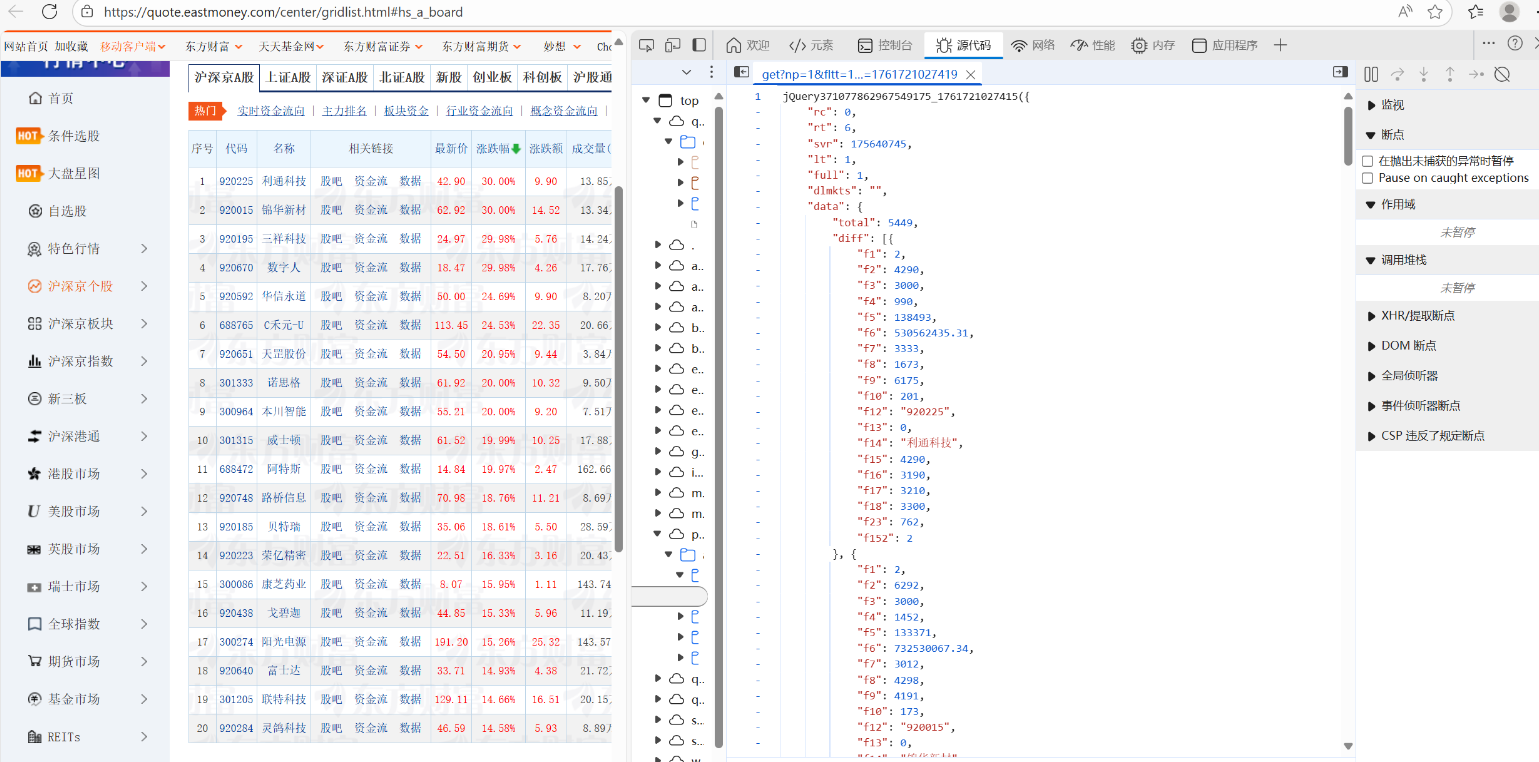
在进入开发者工具后,我通过查询网页的api得知股票的数据都存在一个get请求文档内,在里面寻找所需的数据字段。
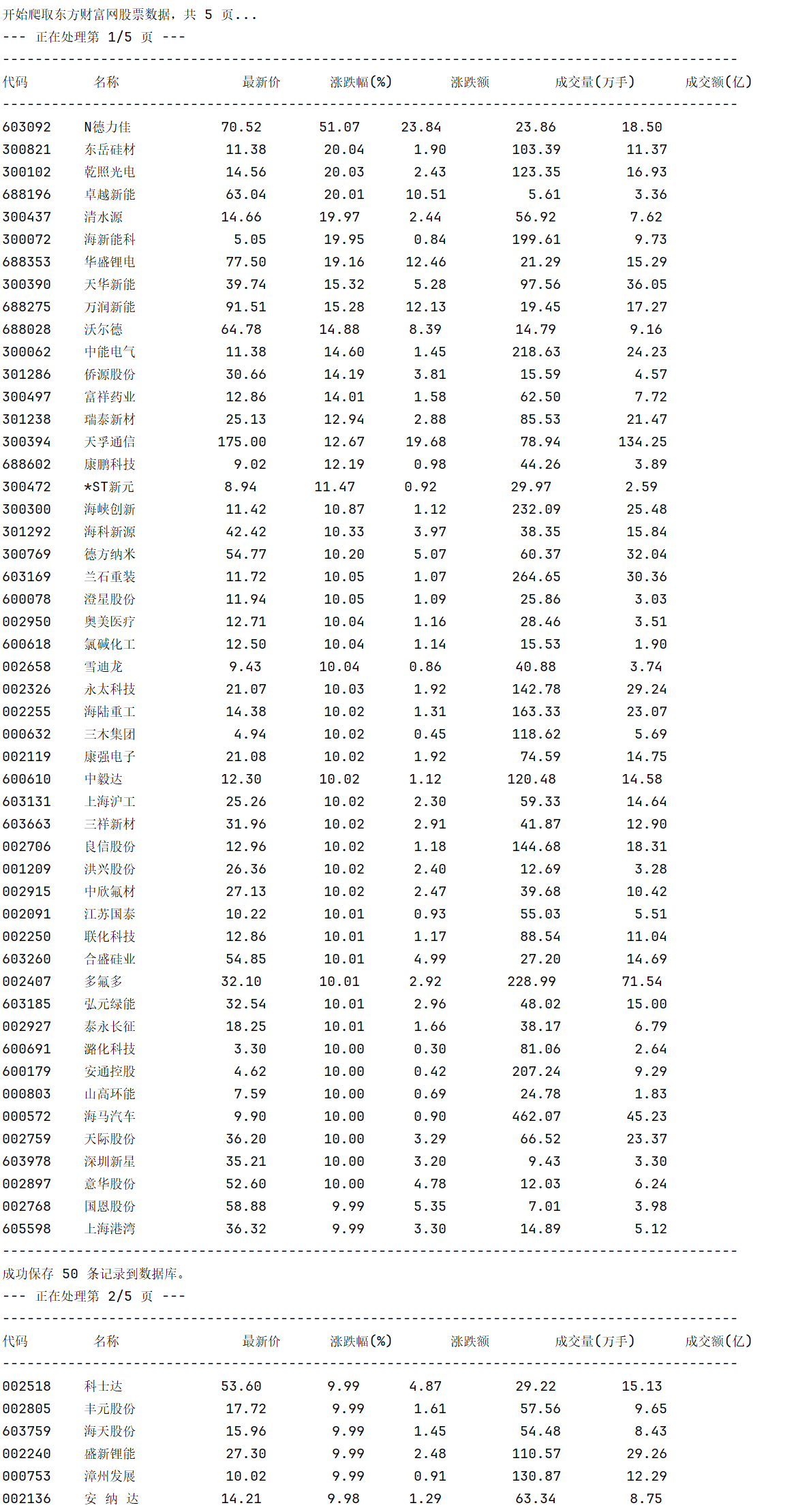
运行结果:
2.心得体会:
由于数据较多,我在爬取全部信息的时候遭到了网页的“拒绝”,之后我也尝试了下载对应的js到本地运行,发现是可行的,这让我明白了在爬取网页时只要找到了核心的数据,就可以绕过网页爬取我们想要的数据。最后我爬取了5页内容并存在数据库中。
作业3:
1.爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
核心代码:
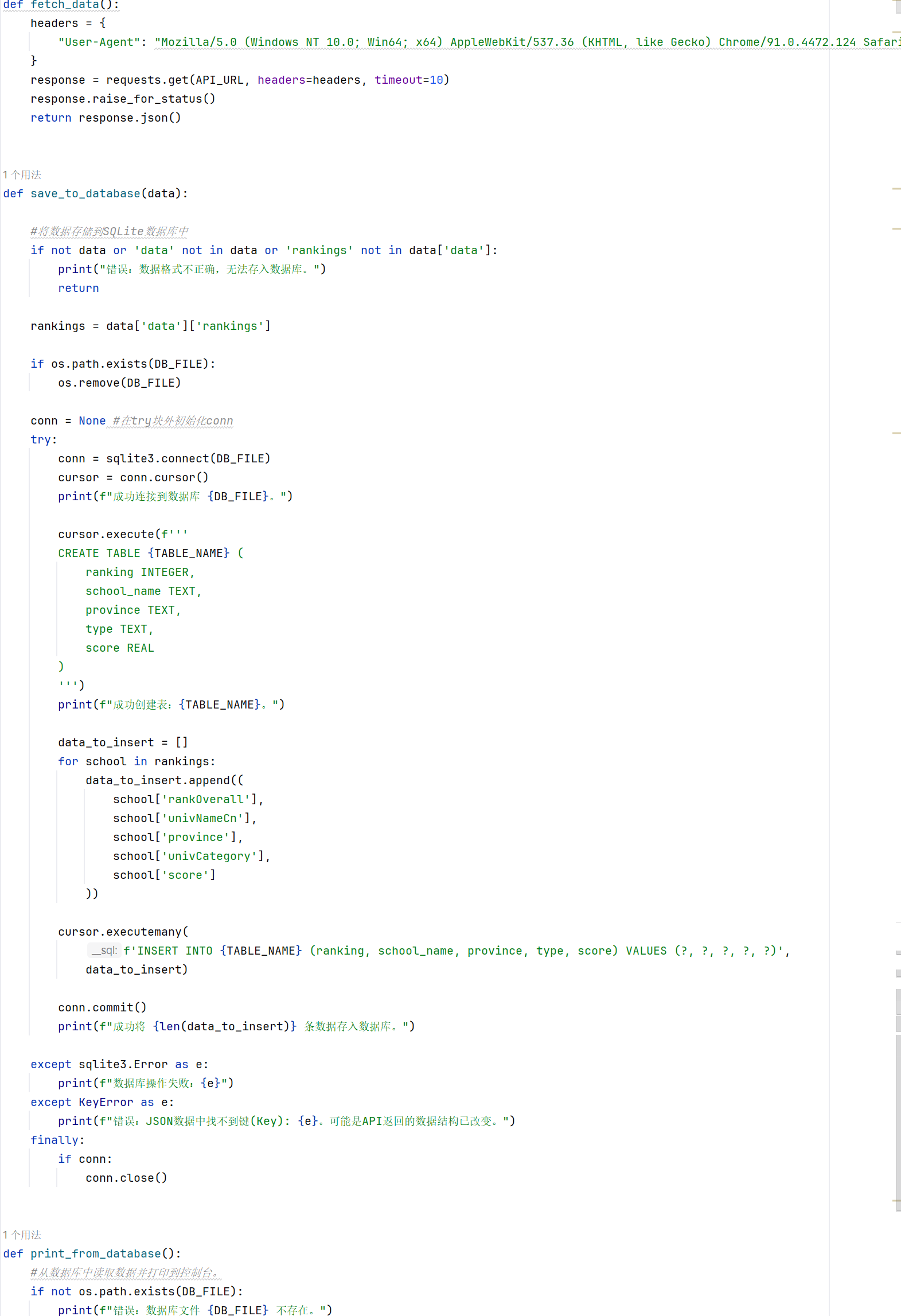
使用requests库来模拟浏览器向网站的数据接口(API)发送请求。
起初,我尝试直接分析网页,但很快发现数据并不是写死在HTML里的。通过F12开发者工具,我开始学习分析网站的网络请求,发现了那个苦苦寻找的API——bcur?bcur_type=11&year=2021

这个网站的 API 接口会发生变化,里面的数据结构也会发生变化,我分析api发现rank 这个字段的名称从 rank 变成了 rankOverall,修改后就正确了。
运行结果:
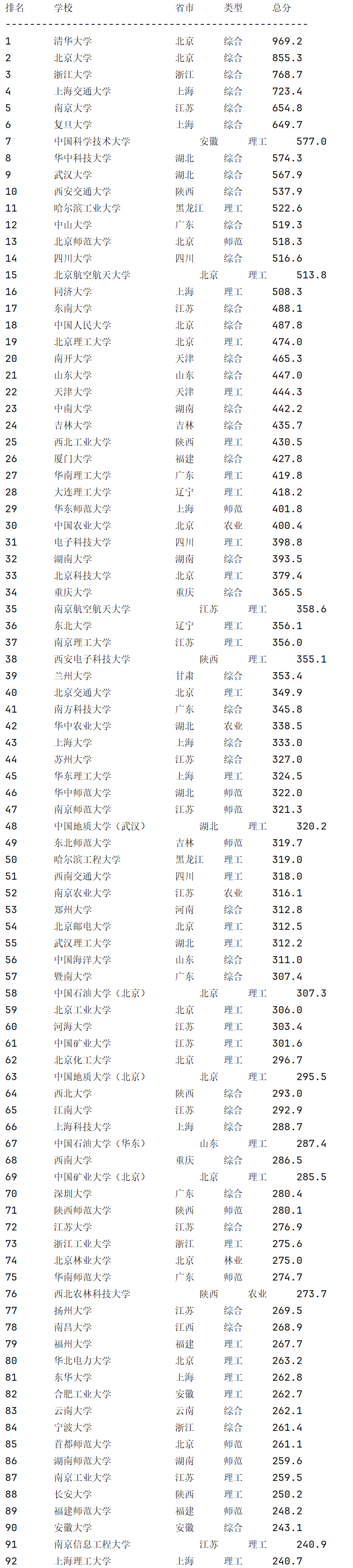
2.心得体会:
这个网站是一次性加载所有大学的数据,然后在前端进行分页展示的。不需要进行翻页操作,只需要找到存储数据的文档和正确的api。刚开始我一直找不到想要的js,耗费了大量时间。让我明白了必须熟练使用它,不仅要看XHR,还要懂得分析缓存、插件甚至是Document本身的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号