102302143郑泽雄第一次作业
1.用requests和BeautifulSoup库方法爬取大学排名信息。
核心代码及结果
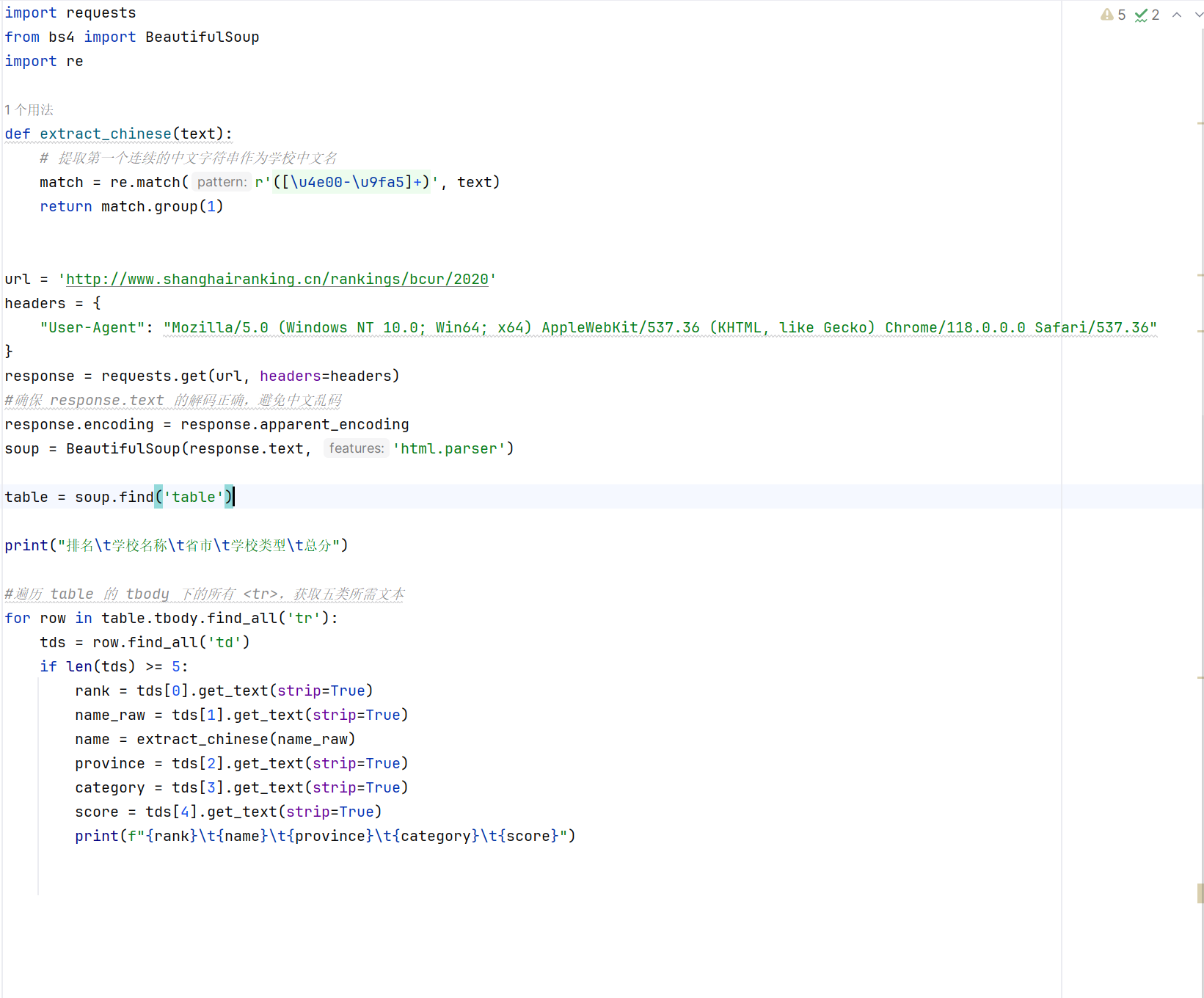
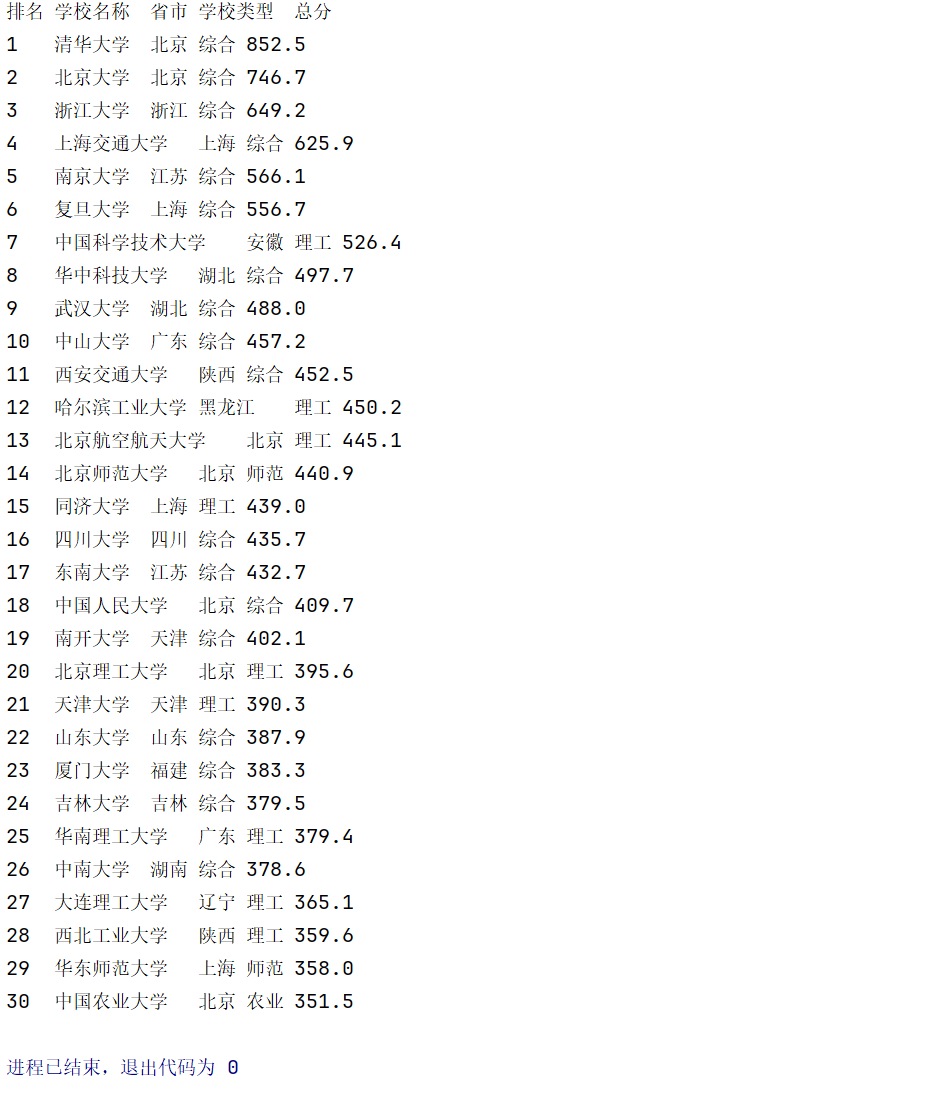
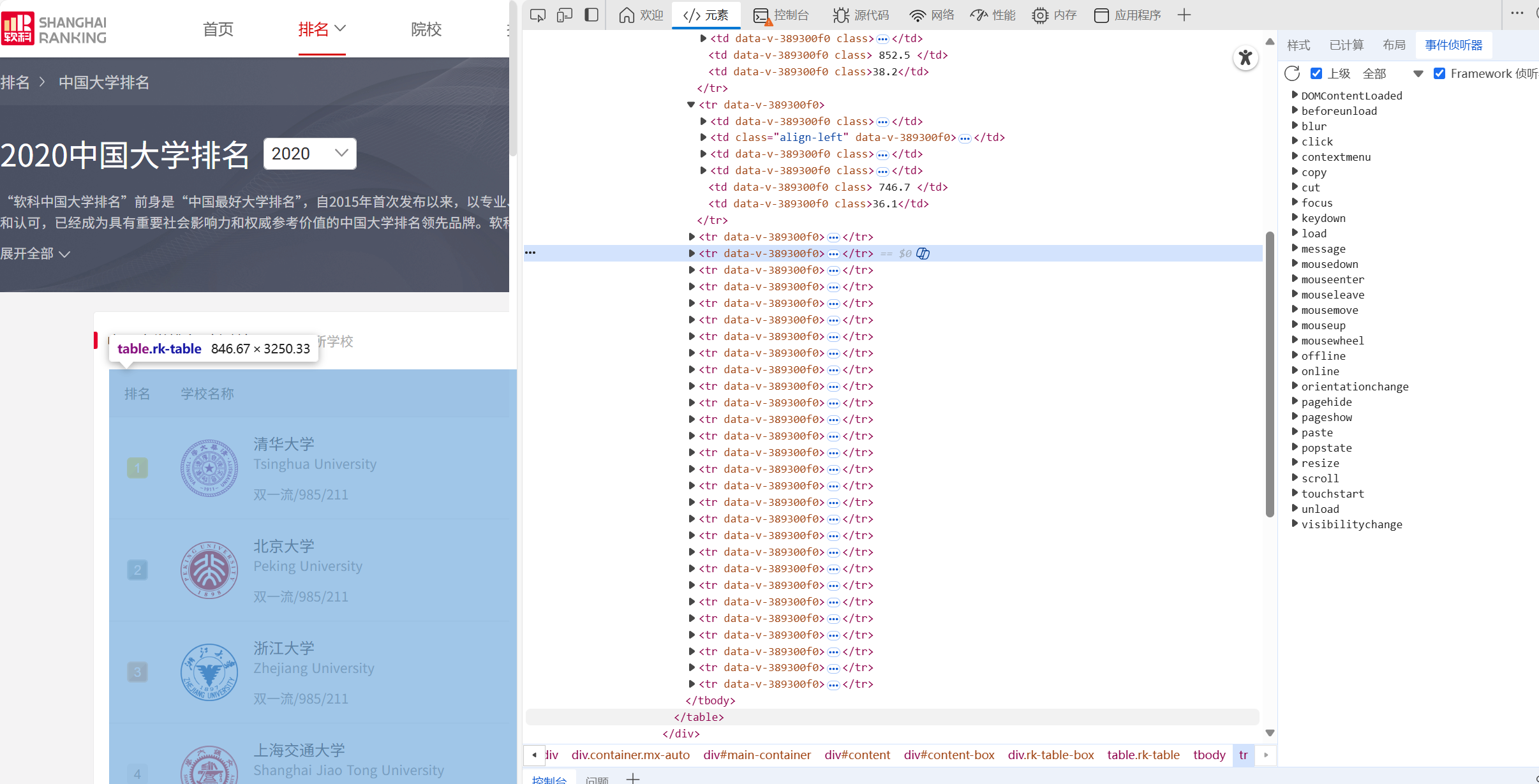
由图可知,所需信息在table的tbody下的 标签,然后逐一排查寻找需要的5个标签即可。
心得
从这道题我掌握了如何使用正则化表达式匹配中文序列,当我想要爬取所有页面的信息时,这个网页的翻页无法用简单的for循环,用requests和BeautifulSoup库不能实现翻页。
2.爬取商城的书包价格
核心代码及结果
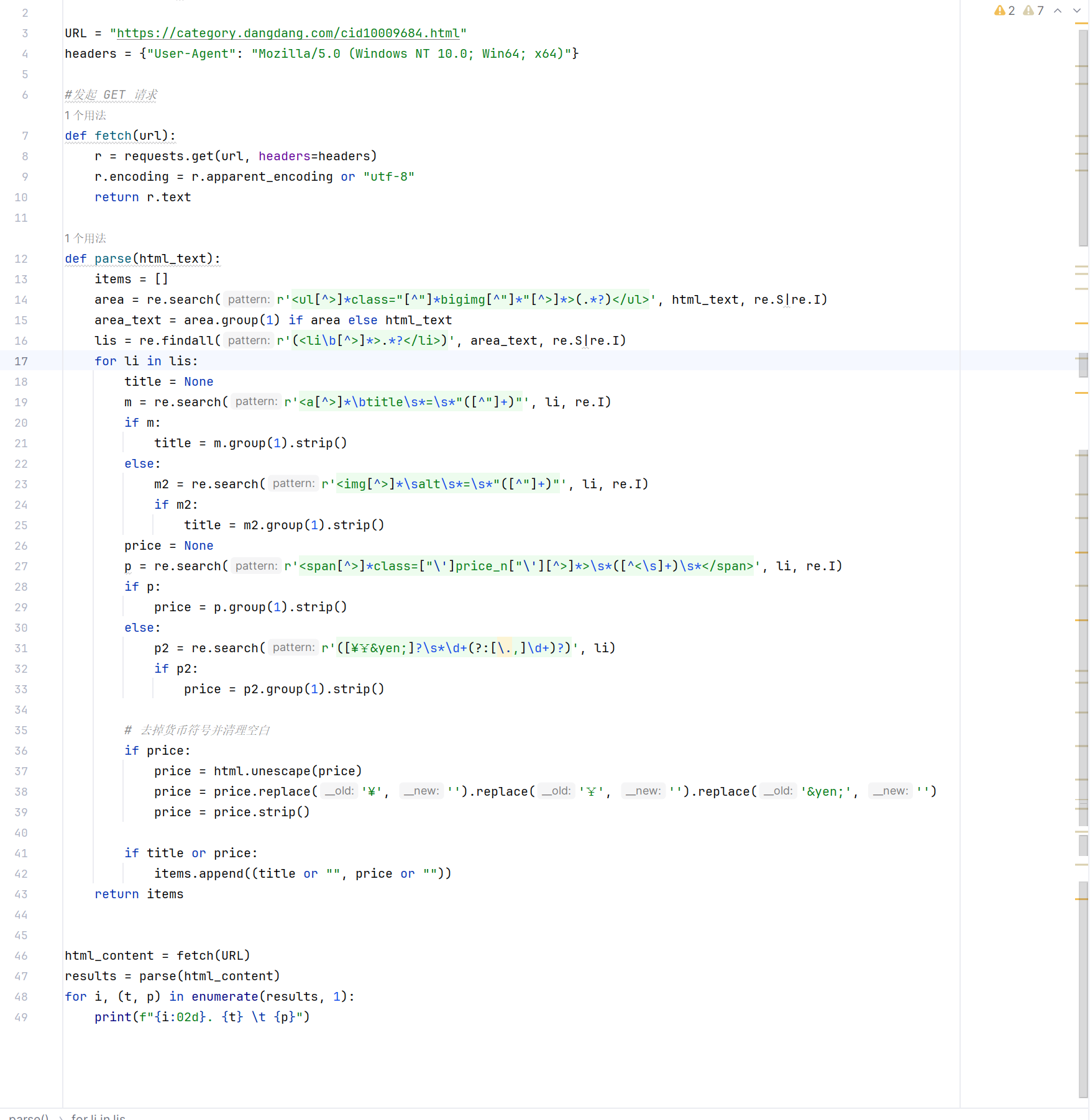

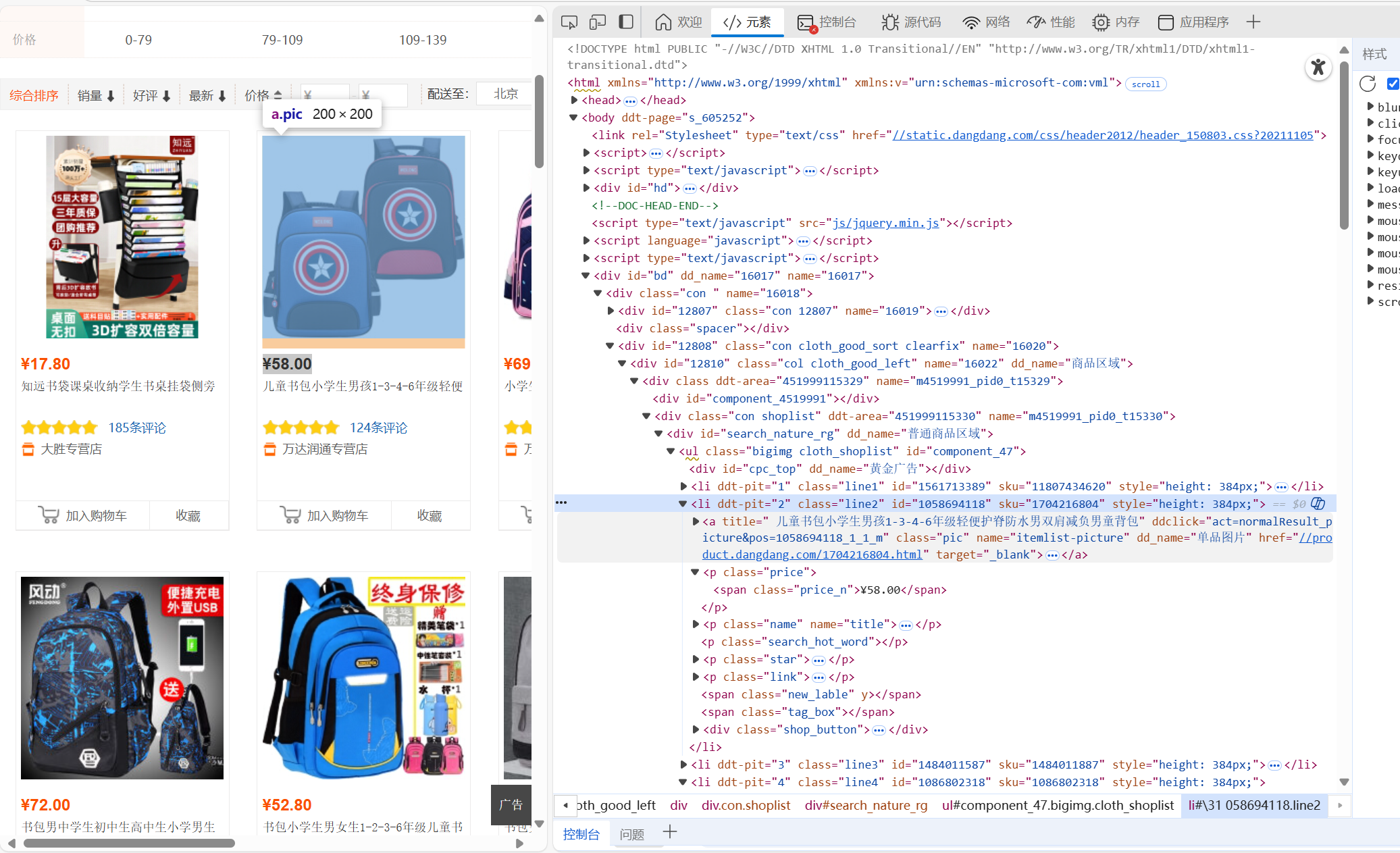
爬取网站选择了反爬机制较差的当当网。在浏览页面的时候,我发现了标签和价格都在
心得
除了网站比较不好找,标签的爬取还是比较简单的。
3.爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)所有JPEG、JPG或PNG格式图片文件。
核心代码及结果
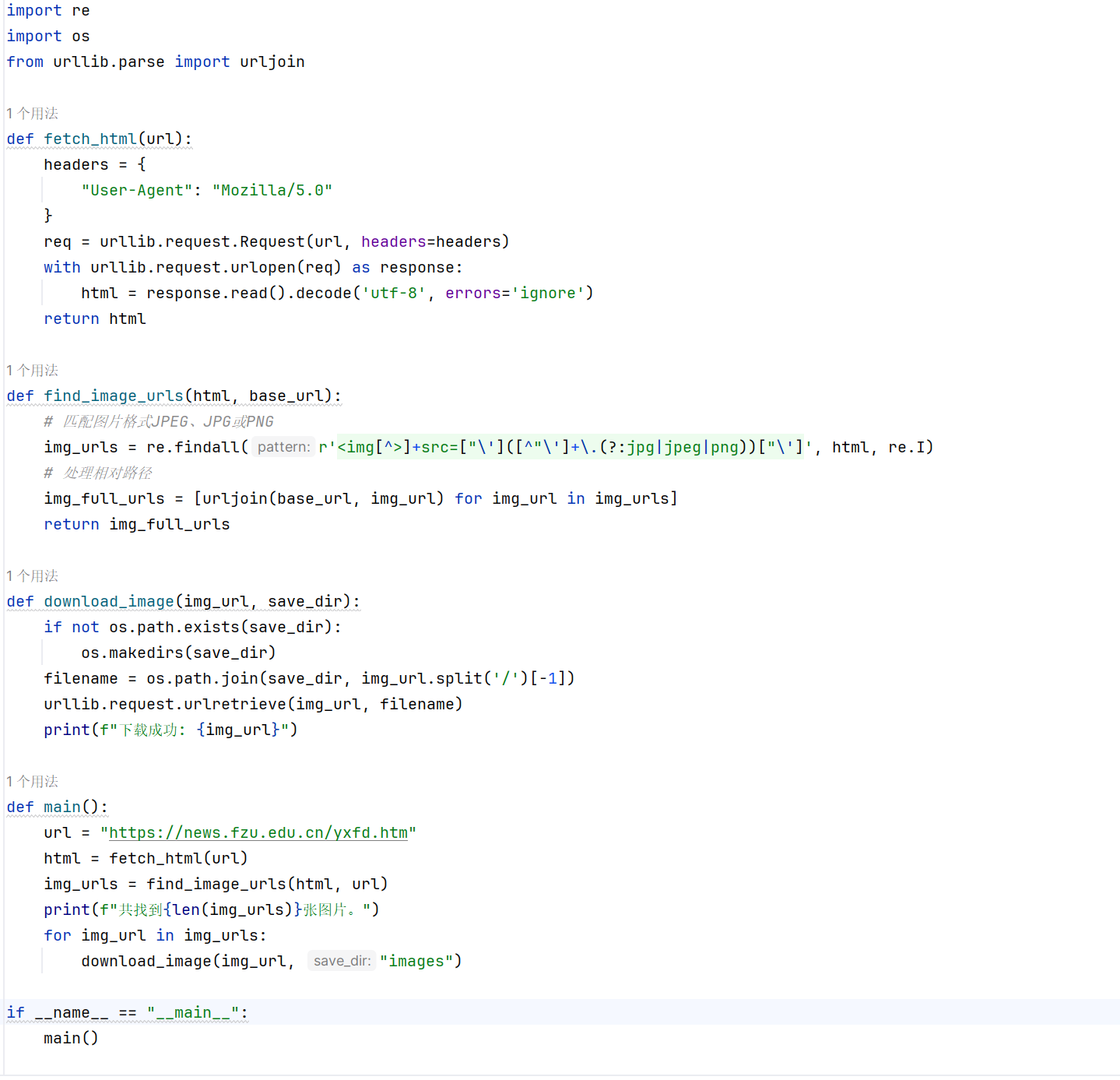

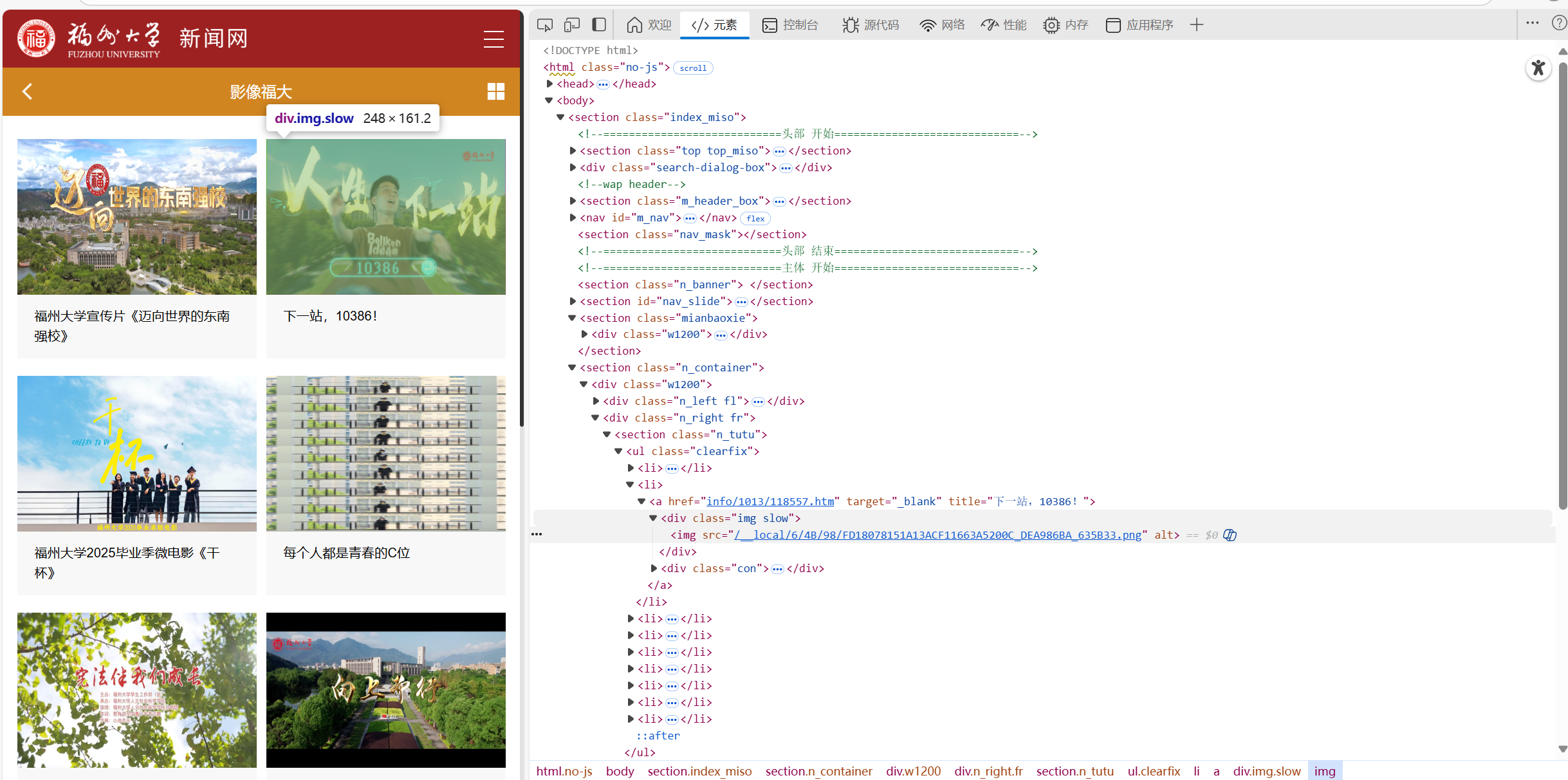
爬取的时候发现图片基本以 jpg/jpeg/png 结尾,匹配 src 属性中直接以 jpg/jpeg/png 结尾的 URL。
心得
这个网页还是比较容易爬取的,基本上没遇到什么困难。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号