
关于Graphx大规模图的计算系统介绍
Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。
GraphX支持的语言有python,java,scala等等,但是网上的教程以后面两种居多...
要先介绍Graphx,首先得知道什么是分布式图处理系统
一、我们先来了解分布式图计算系统的两个常见问题:
1、图存储模式
巨型图的存储总体上有边分割和点分割两种存储方式
边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
如下图:
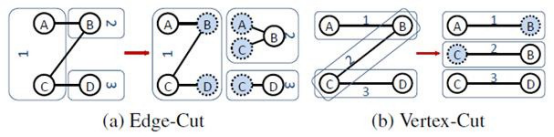
而我们所研究的Graphx存储模式采用的是Vertex-Cut(点分割)方式存储图,用三个RDD(存储图的数据信息)
主要原因有:
1.磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵。这点就类似于常见的空间换时间的策略。
2.在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊。而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。
2、图计算模式
目前的图计算框架基本上都遵循BSP计算模式,即整体同步并行,它将计算分为一系列的超步的迭代。
###此处的超步是指:每一个计算的迭代
1、执行compute函数,每一个processor(执行器)利用上一个超步(superstep)传过来的信息和本地的数据进行本地计算
2、消息传递,每一个processor(执行器)计算完毕后(即执行compute函数),将消息传递给与之关联的其他processors(执行器)
3、整体同步点,用于整体同步,即确定所有的计算和消息传递都进行完毕后,再执行下一个superstep(超步)
###
从纵向上看,它是一个串行模式,而从横向上看,它是一个并行模式,每两个superstep(超步)之间都会设置一个栅栏,用于作整体同步点,即确定所有的计算以及消息传递之后再启动下一轮superstep(超步)。

此处为水平方向的
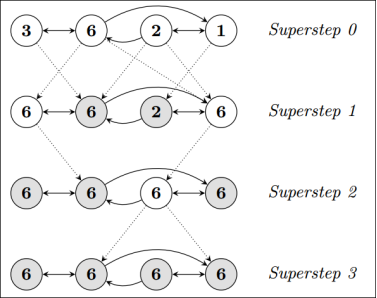
此处为竖直方向的
###以上即为分布式图计算系统的基本介绍
而我们所研究的Graphx存储模式采用的是Vertex-Cut(点分割)方式存储图,用三个RDD(存储图的数据信息),我们所研究的Graphx计算模式采用的也是BSP模式。
二、Graphx图属性操作总结:
以下代码基于Scala语言编写:
/** 图属性操作总结 */
class Graph[VD, ED] {
// 图信息操作
// 获取边的数量
val numEdges: Long
// 获取顶点的数量
val numVertices: Long
// 获取所有顶点的入度
val inDegrees: VertexRDD[Int]
// 获取所有顶点的出度
val outDegrees: VertexRDD[Int]
// 获取所有顶点入度与出度之和
val degrees: VertexRDD[Int]
// 获取所有顶点的集合
val vertices: VertexRDD[VD]
// 获取所有边的集合
val edges: EdgeRDD[ED]
// 获取所有triplets表示的集合
val triplets: RDD[EdgeTriplet[VD, ED]]
// 缓存操作
def persist(newLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED]
def cache(): Graph[VD, ED]
// 取消缓存
def unpersist(blocking: Boolean = true): Graph[VD, ED]
// 图重新分区
def partitionBy(partitionStrategy: PartitionStrategy): Graph[VD, ED]
// 顶点和边属性转换
def mapVertices[VD2](map: (VertexID, VD) => VD2): Graph[VD2, ED]
def mapEdges[ED2](map: Edge[ED] => ED2): Graph[VD, ED2]
def mapEdges[ED2](map: (PartitionID, Iterator[Edge[ED]]) => Iterator[ED2]): Graph[VD, ED2]
def mapTriplets[ED2](map: EdgeTriplet[VD, ED] => ED2): Graph[VD, ED2]
def mapTriplets[ED2](map: (PartitionID, Iterator[EdgeTriplet[VD, ED]]) => Iterator[ED2]): Graph[VD, ED2]
// 修改图结构
// 反转图
def reverse: Graph[VD, ED]
// 获取子图
def subgraph(
epred: EdgeTriplet[VD, ED] => Boolean = (x => true),
vpred: (VertexID, VD) => Boolean = ((v, d) => true))
: Graph[VD, ED]
def mask[VD2, ED2](other: Graph[VD2, ED2]): Graph[VD, ED]
def groupEdges(merge: (ED, ED) => ED): Graph[VD, ED]
// Join RDDs with the graph
def joinVertices[U](table: RDD[(VertexID, U)])(mapFunc: (VertexID, VD, U) => VD): Graph[VD, ED]
def outerJoinVertices[U, VD2](other: RDD[(VertexID, U)])
(mapFunc: (VertexID, VD, Option[U]) => VD2)
: Graph[VD2, ED]
// Aggregate information about adjacent triplets
def collectNeighborIds(edgeDirection: EdgeDirection): VertexRDD[Array[VertexID]]
def collectNeighbors(edgeDirection: EdgeDirection): VertexRDD[Array[(VertexID, VD)]]
def aggregateMessages[Msg: ClassTag](
sendMsg: EdgeContext[VD, ED, Msg] => Unit,
mergeMsg: (Msg, Msg) => Msg,
tripletFields: TripletFields = TripletFields.All)
: VertexRDD[A]
// Iterative graph-parallel computation
def pregel[A](initialMsg: A, maxIterations: Int, activeDirection: EdgeDirection)(
vprog: (VertexID, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexID, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
// Basic graph algorithms
def pageRank(tol: Double, resetProb: Double = 0.15): Graph[Double, Double]
def connectedComponents(): Graph[VertexID, ED]
def triangleCount(): Graph[Int, ED]
def stronglyConnectedComponents(numIter: Int): Graph[VertexID, ED]
}
三、Graphx的转换操作
Graphx的转换操作主要有mapVertices、mapEdges和mapTriplets三个。
mapVertices操作:
mapVertices 用来更新顶点属性。从图的构建那章我们知道,顶点属性保存在边分区中,所以我们需要改变的是边分区中的属性。
对当前图每一个顶点应用提供的 map 函数来修改顶点的属性,返回一个新的图。
###以下代码基于Scala编写
override def mapVertices[VD2: ClassTag]
(f: (VertexId, VD) => VD2)(implicit eq: VD =:= VD2 = null): Graph[VD2, ED] = {
if (eq != null) {
vertices.cache()
// 使用方法 f 处理 vertices
val newVerts = vertices.mapVertexPartitions(_.map(f)).cache()
// 获得两个不同 vertexRDD 的不同
val changedVerts = vertices.asInstanceOf[VertexRDD[VD2]].diff(newVerts)
// 更新 ReplicatedVertexView
val newReplicatedVertexView = replicatedVertexView.asInstanceOf[ReplicatedVertexView[VD2, ED]]
.updateVertices(changedVerts)
new GraphImpl(newVerts, newReplicatedVertexView)
} else {
GraphImpl(vertices.mapVertexPartitions(_.map(f)), replicatedVertexView.edges)
}
}
Graphx的操作总结暂且到这里结束,以后会有更多的操作补充上来~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号