
爬虫和反爬虫
基本概念
爬虫:自动获取网站数据的程序,关键是批量的获取
反爬虫:使用技术手段防止爬虫程序的方法
误伤:反爬虫技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
成本:反爬虫需要的人力和机器成本
拦截:成功拦截,一般拦截率越高,误伤率越高
反爬虫的目的:
初级爬虫:简单粗暴,不管对服务器造成了多少压力,容易让网站服务器崩溃,这种爬虫也是最容易被检测到的
数据保护
失控的爬虫:由于某些情况,忘记或者无法关闭的爬虫
商业竞争对手
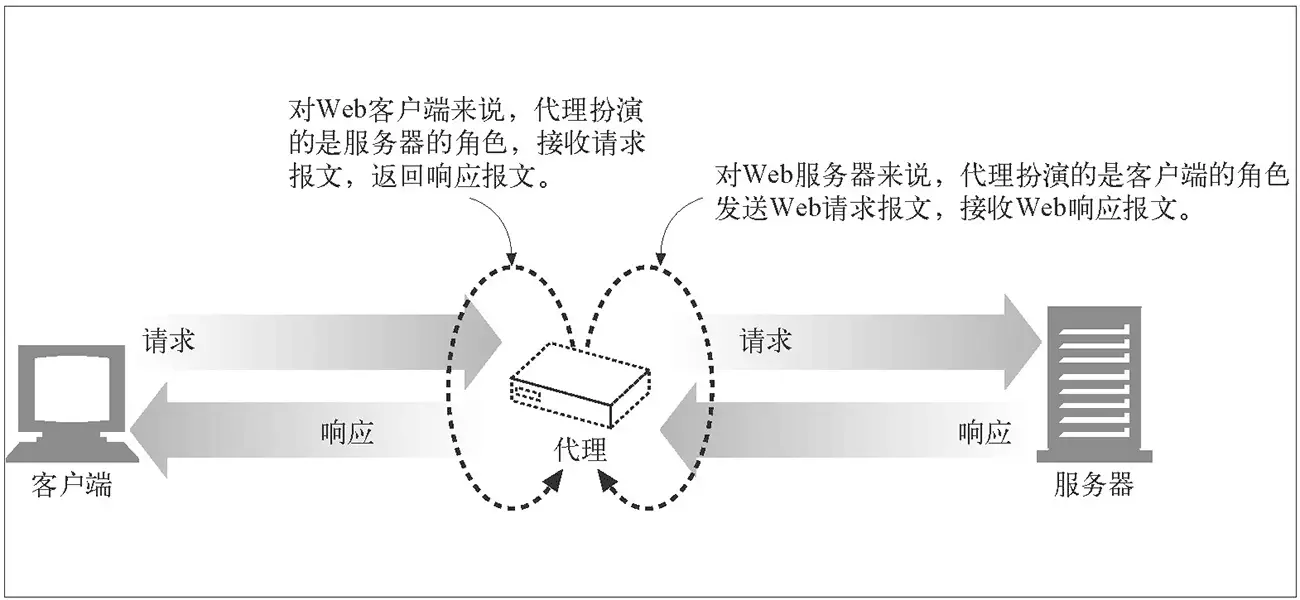
代理ip及原理:


基本概念
爬虫:自动获取网站数据的程序,关键是批量的获取
反爬虫:使用技术手段防止爬虫程序的方法
误伤:反爬虫技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
成本:反爬虫需要的人力和机器成本
拦截:成功拦截,一般拦截率越高,误伤率越高
反爬虫的目的:
初级爬虫:简单粗暴,不管对服务器造成了多少压力,容易让网站服务器崩溃,这种爬虫也是最容易被检测到的
数据保护
失控的爬虫:由于某些情况,忘记或者无法关闭的爬虫
商业竞争对手
代理ip及原理:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号