
vc6内存管理 笔记
VC6内存管理
以VC6为基础,了解大概的内存管理
主要关注管理内存的方式,不关注内存的申请、分布等
-
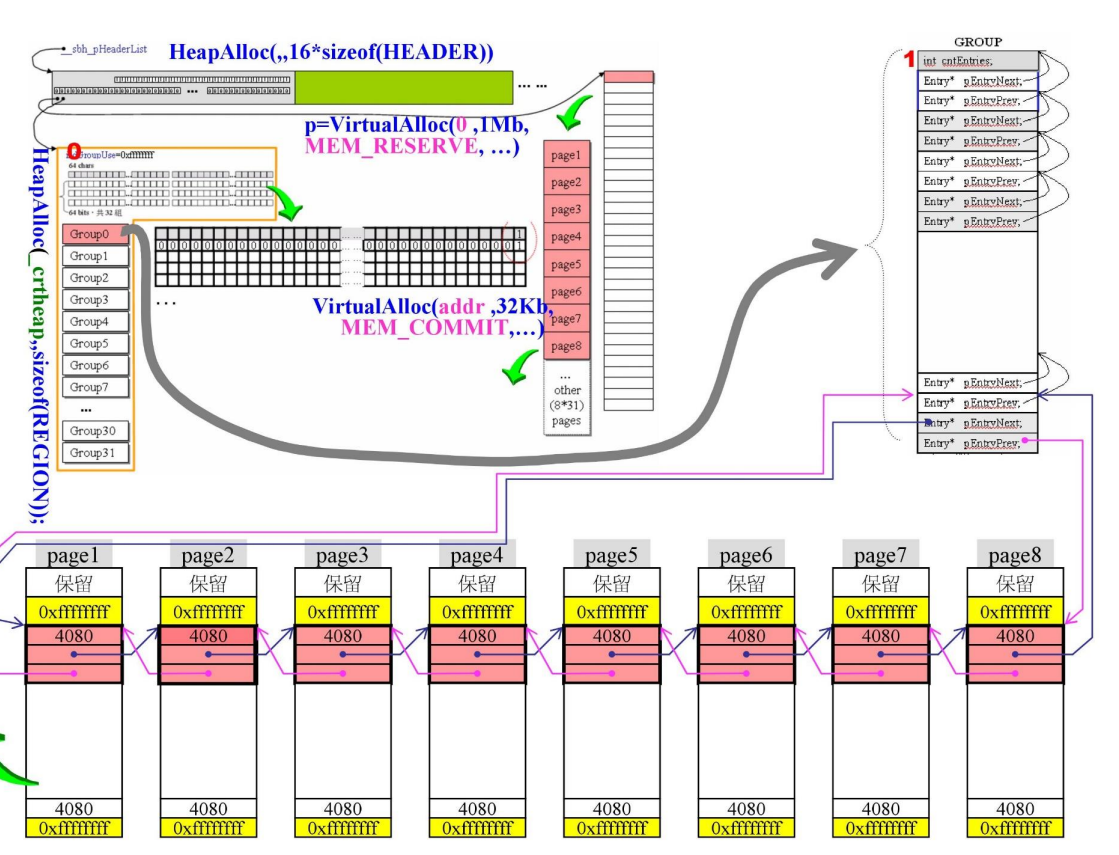
VC6内存管理的调用步骤
![]()
-
几个概念:
-
sbh:small block heap -
crt:c runtime
-

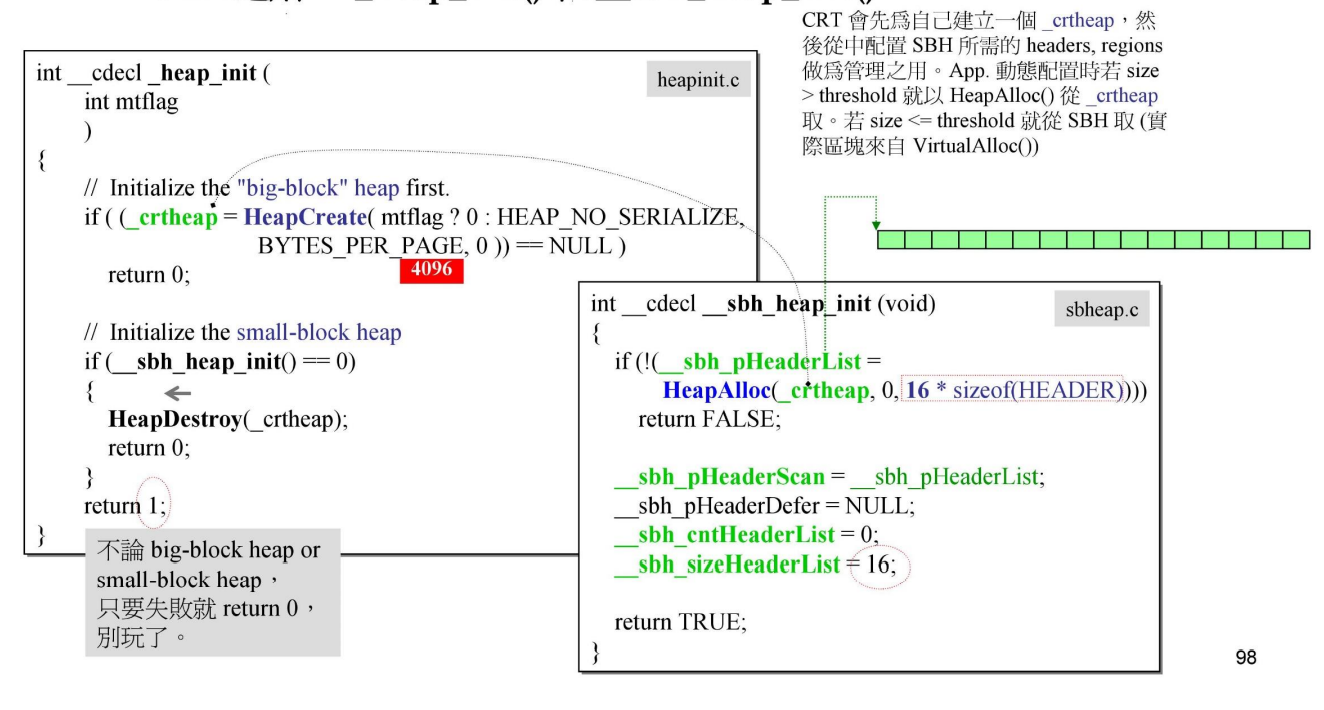
_heap_init与_sbh_heap_init
-
_heap_init:申请了一块heap -
_sbh_heap_init:配置了SBH,分配16个HEADER
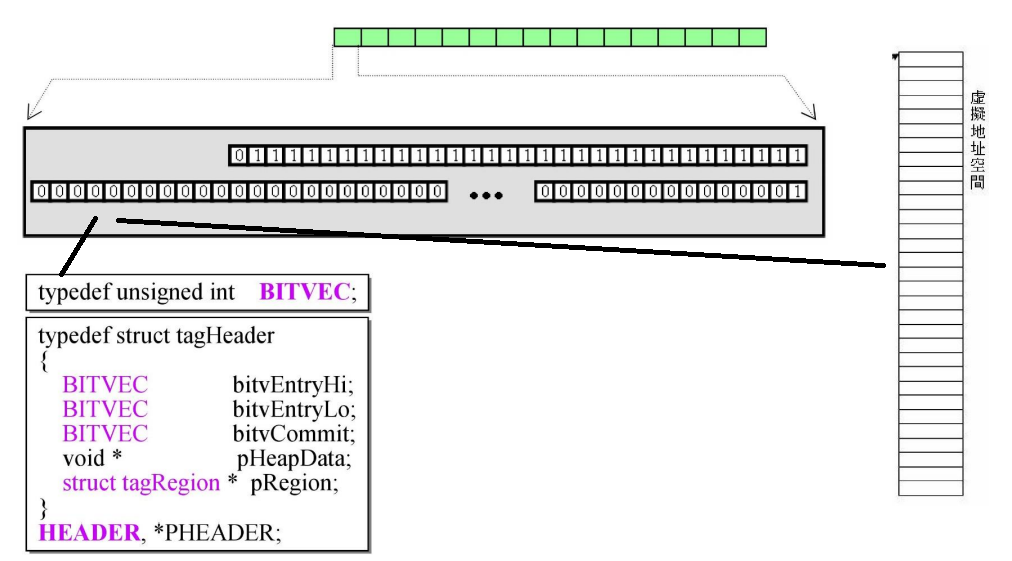
HEADER的结构
-
三个unsigned int
-
bitvEntryHi与bitvEntryLo合并起来使用,即使图下面的 64个bit -
上面 32个bit指的是
bitvCommit
-
-
pHeapData:指向虚拟地址空间 -
pRegion:指向Region,Region是SBH管理分配内存空间的主要结构
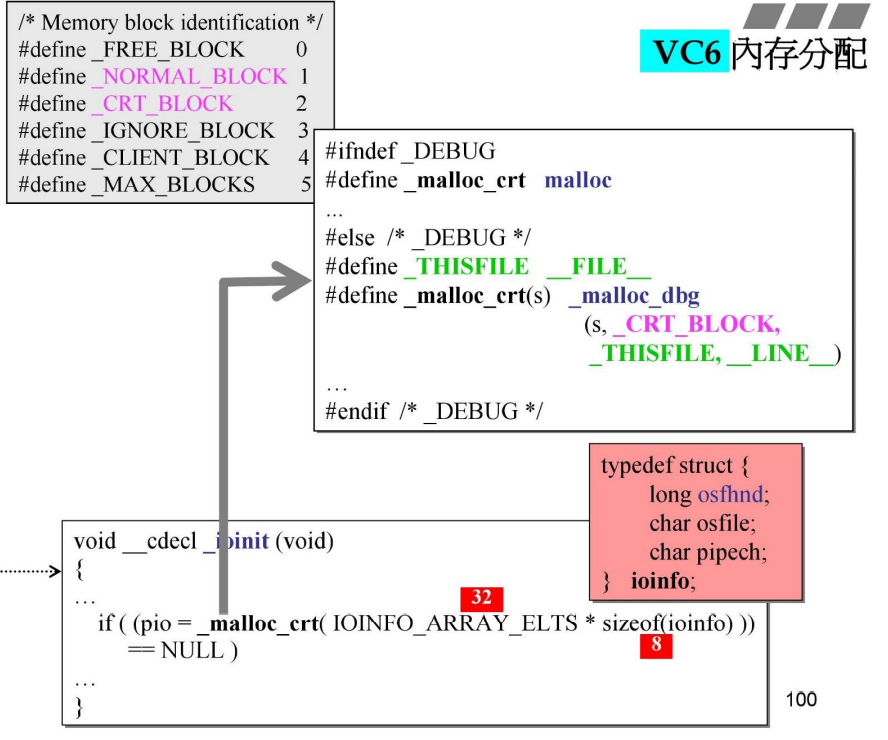
_ioinit()
-
ioinit中,调用
_malloc_crt,分配 32*8B(256B,0x100) 的内存 -
_malloc_crt:在未定义_DEBUG时调用malloc,否则调用_malloc_dbg-
两个函数的差别是 DEBUG 模式下,会在内存安插一些用于debug监管的东西(例如是否越界等)
-
_heap_alloc_dbg(...)
-
该函数首先计算 block 的大小
-
调用
_heap_alloc_base创建Header
block
-
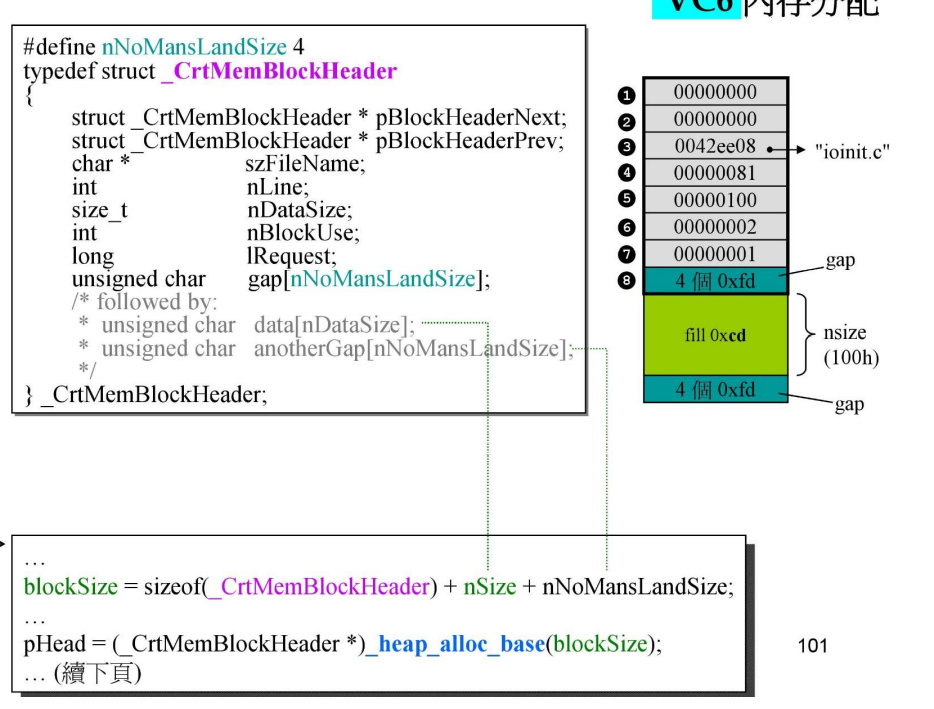
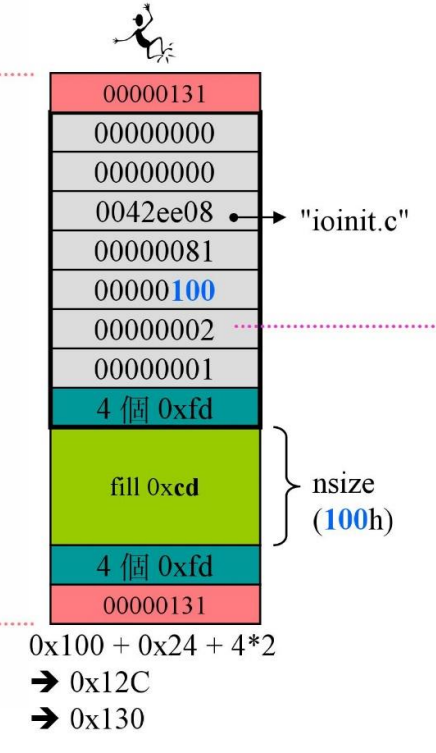
_CrtMemBlockHeader
-
指针,指向下一个 Header
-
指针,指向上一个 Header
-
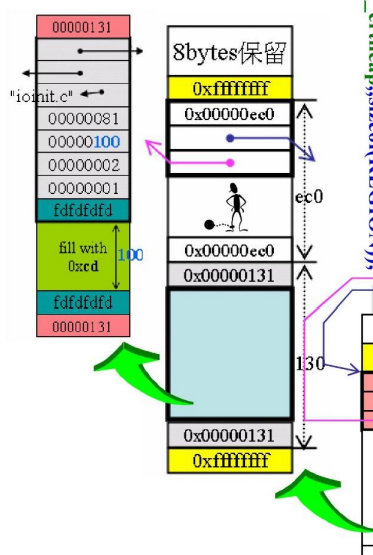
指针,这里的值是 “ininit.c",指向发出请求的文件名
-
int,第几行发出的请求(图中的81是16进制,是129行,查看源代码,就是调用
_malloc_crt那一行)![]()
-
size_t:记录数据真正的大小(nSize)
-
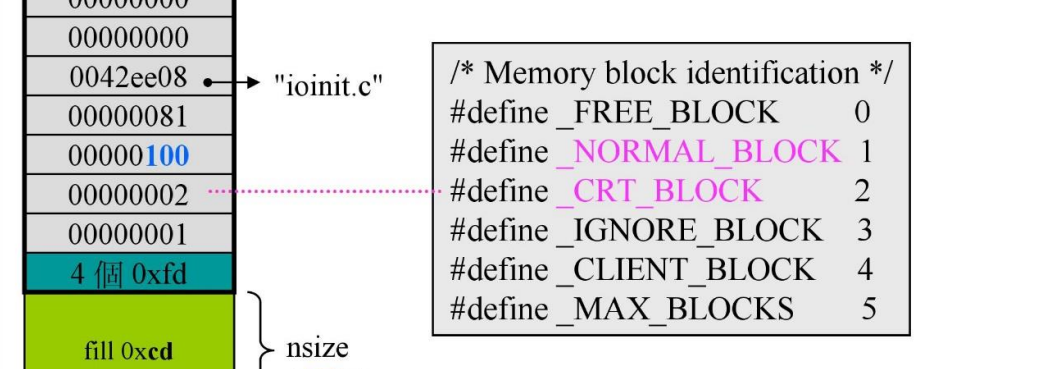
int:表示Block的属性
![]()
-
long:记录当前是第几块
-
4个字符:填入0xfd
-
-
nSize:数据的大小
-
nNoMansLandSize:填充字符的大小
填充4个字符,值为0xfd。与
_CrtMemBlockHeader中的第八个变量作用一样,用于检查读写是否越界
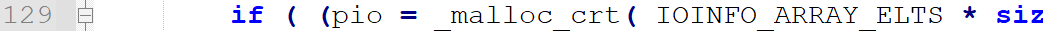
接下来是取得内存后的操作:
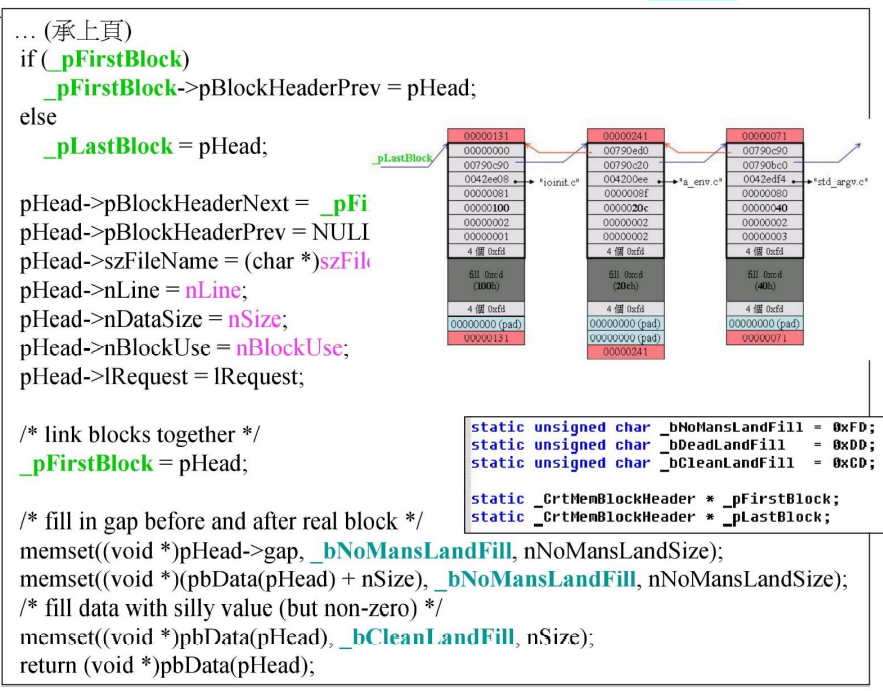
-
这里做了两件事:
-
为HEADER分配了值
-
将HEADER以链表的形式串起来
即便内存已经分配出去,指针也还是会指向它,因此,即使该内存分配出去,它也还在sbh的掌控之中
-
_heap_alloc_base(..)

-
初步计算完block的大小size之后,传入该函数
-
该函数做了判断:
-
如果
size <= 1016,交予 sbh 来分配内存 -
否则,交给操作系统
-
-
为何是1016?
-
因为上下会加cookie,而cookie总共是8个字节
-
_sbh_alloc_block()

-
调用 sbh 分配内存时,会先计算大小,将原来的blockSize加上cookie(即两个int)的大小,然后调整为16的倍数
// 把 a 向上调整为 2^n 的倍数
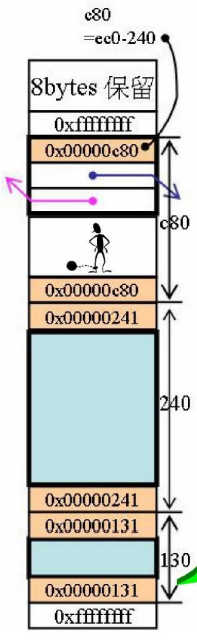
(a + (2^n - 1)) & ~(2^n - 1);size最终大小为:RoundUp(0x124+2*4)=RoundUp(0x12C)=0x130
-
上下cookie记录最终大小,
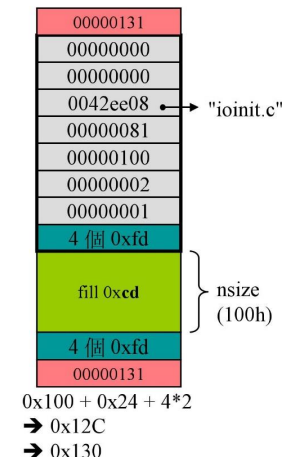
-
这里看到cookie是0x131,由于调整为16的倍数之后,最后一位必定是0(看大小时最后一位无用),因此,sbh借用最后一位来表示是否已经分配出去,0表示在sbh中,1表示分配出去
_sbh_alloc_new_region()
region的大致结构
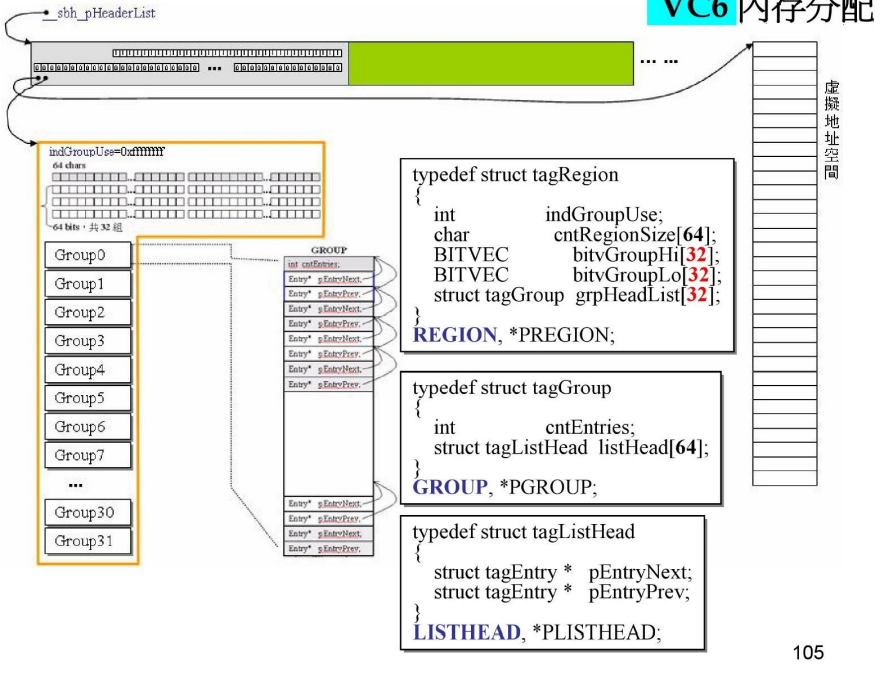
-
前面说过,每一个Header有两个指针,一个指向Region(管理内存),一个指向虚拟内存空间。
-
Header管理的大小为1M,也就是说,指针指向的虚拟内存空间大小为1M
-
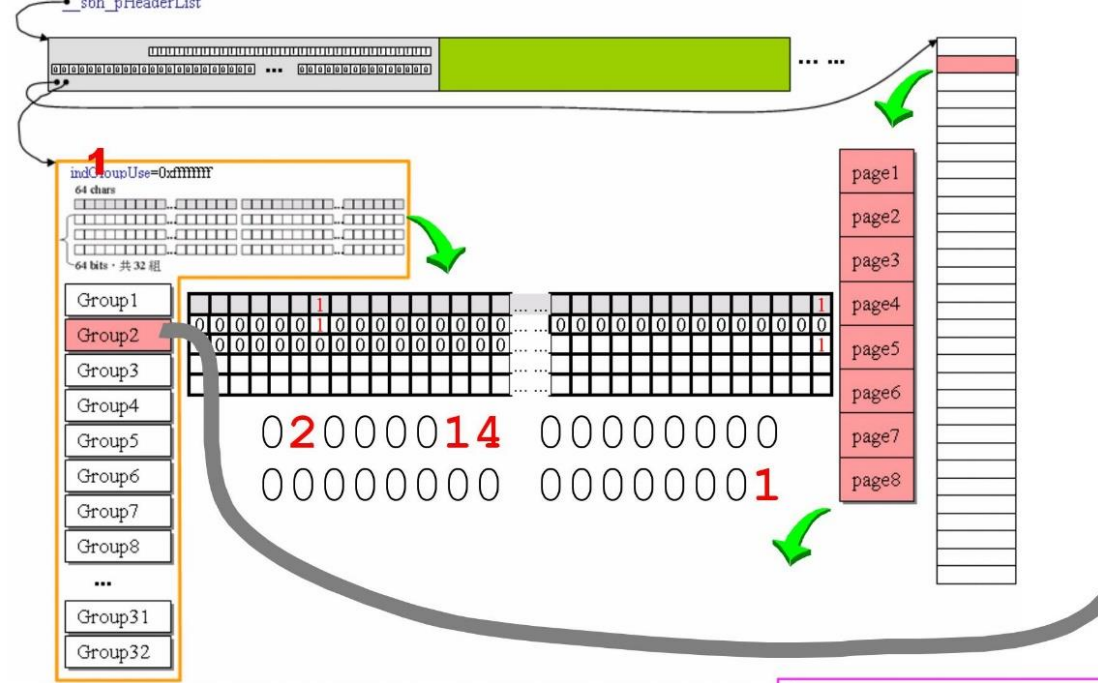
tagRegion:
-
indGroupUse: -
cntRegisonSize -
bitvGroupHi、bitvGroupLo:并在一起使用:32组64bit,用以管理区块,表示区块的状态(有或无) -
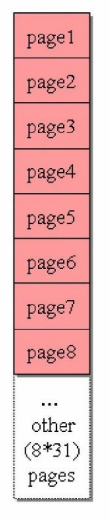
tagGroup[32]:32个组别,每一组管理32k(1M / 32),每4k分为一个page,即一组有8page![]()
-
-
tagGrop:
-
int
-
tagListHead[64]:64对指针,形成双向链表
-
-
tagListHead:
-
两个指针:
tagEntry*,next与prev
-
Region各部分
可以看出,Region中分为几块:
bit块

-
32组64bit:用以管理区块,表示链表的状态(有或无内存区块可分配)
-
indGroupUse:用来记录当前正在使用哪一个Group
Groups块

-
32组,每一组管理1M
-
当我们用完一组之后,它会寻找另一组
-
注意:虽然说管理1M,但是一开始操作系统实际只分配了32k,其他是虚地址(具体看操作系统),用时再分配
单个Group与page:最关键的部分
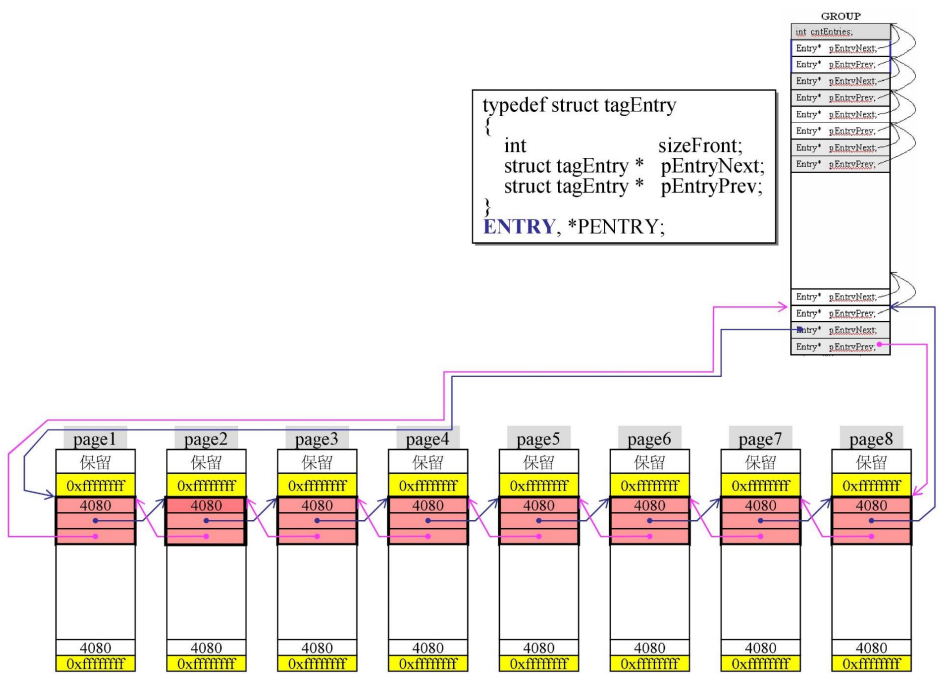
-
上下两个黄色区块:0xffffffff(-1)
-
当我们分配内存出去的时候,并不是一个page一个page分的,而是按照实际需求切割page分配。
-
当sbh回收内存的时候,它需要合并,合并的过程,-1作为一个隔离器,表示边界
-
-
tagEntry:红色部分
![]()
-
sizeFont:表示黄色区块(不包括)之间区块大小
-
由于每个block都要是16的倍数(block指黄色中间部分),而整个page为4096,4096-size_{黄}=4088,4088不是16倍数,因此上面保留,让block调整为16的倍数。
-
16的倍数是规定好的。
至于为什么?block是分配出去的时候实际使用的,因此可能调整成16的倍数比较方便?
-
-
两根指针:形成双向链表
-
-
Group的listhead部分
-
最后的listHead指向page,形参双向链表
-
即next指针指向首个page
-
prep指针指向最后一个page
-
-
从上到下,第n个listHead(从1计数)负责一块大小的内存(16*n-1,16*n]
即最大一块负责1k(16B * 64 = 1024B)
-
不是重点,只是一个技巧,还不好理解
注意上面的listhead的指针,都指向上面,它是借用了上面的那一个。
entry其实是1个int+2个指针,而listhead只有2根指针,它两根指针都指向了 自己整个listEntry + 上面4个字节
为了省内存,没省多少
![]()
-

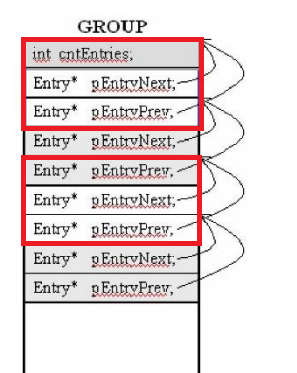
内存的分配
前面说,每一个listHead负责一块大小的分配
从16开始到1024
现在我们来讨论分配内存是如何分配的,第一块分配的内存是谁?就是 ioinit申请的256B,加上Debug Head与Cookie,调整边界之后,是0x130(304)
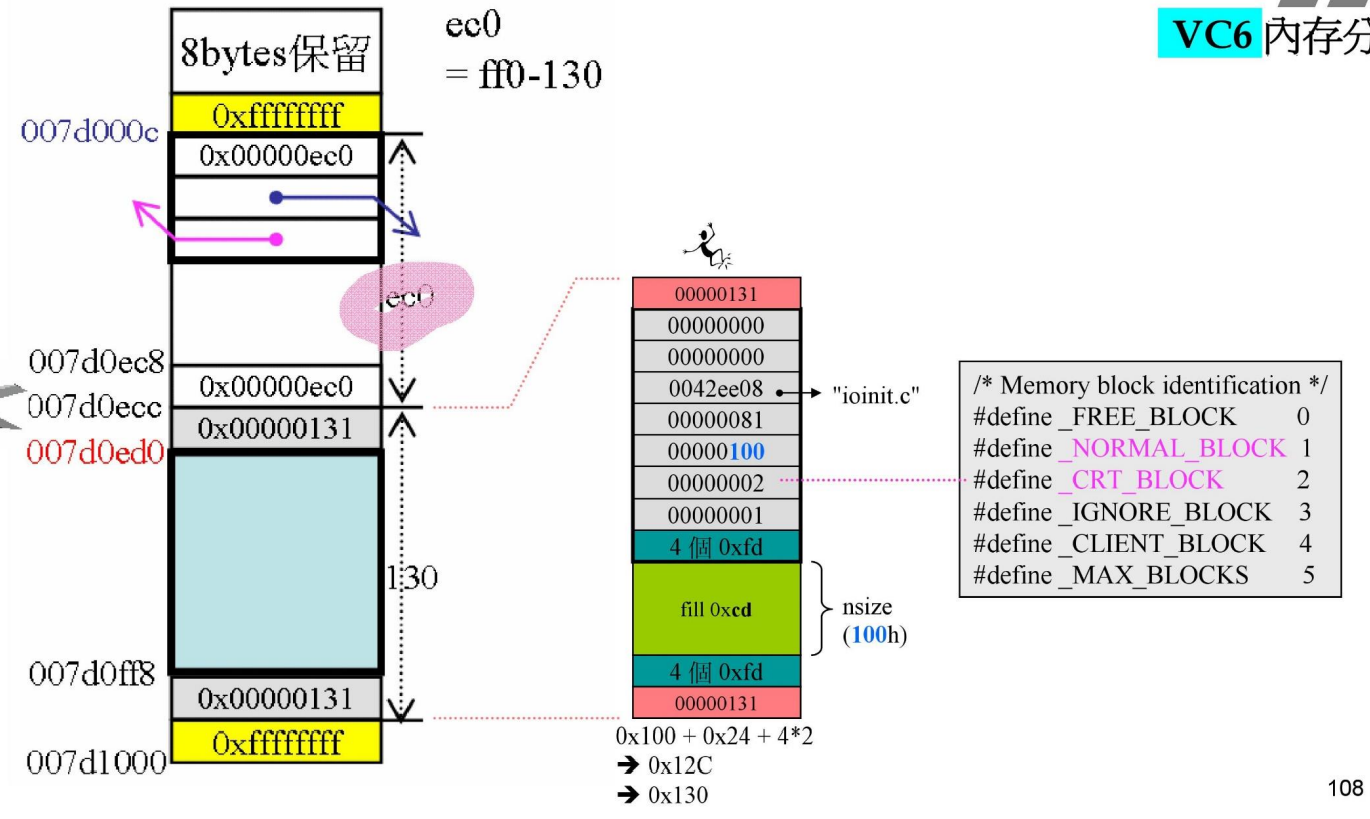
-
ec0:ff0(4080) - 130
-
131:1表示该内存已经分配出去了
分配步骤:
-
得到分配请求之后,计算从哪里开始切割(将分配内存的首地址)
-
得到将分配内存的首地址之后,在区块之前与之后设置cookie,将指针返回
![]()
-
将未分配区块的cookie改变为剩余空间
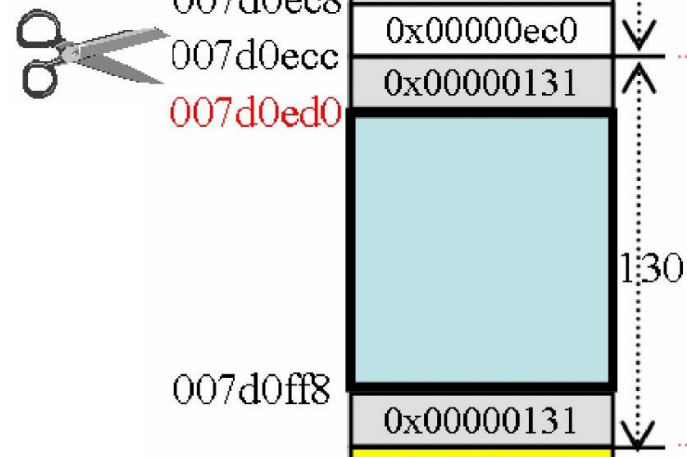
细节:如果ioinit是debug模式,那么返回指针之后,还需要将指针指向用户实际需要的区块的首地址,而隐藏掉其他部分
那么,现在在main结束之前,}结束之前,走一遍这些区块,然后你发现还有一些区块是分配出去的,就是上图红色区块的末尾为1,那么表示内存泄露了吗(有些内存你分配了但是还没释放)
答案是否
因为,它有可能是CRT_BLOCK,也就是CRT时,进入main之前就分配了的区块,不一定是main(用户)分配的,因此也就不是泄露,但是当图中粉色线(DEBUG HEAD第六个数)为1,即NORMAL_BLOCK时,就表示内存泄露了
sbh分配、回收与释放
分配内存的时候,在确定了Header与Group之后,应该由对应的listHead来分配内存,第n条链表负责的size为 n*16
先来看看
分配与回收
首次:分配
由前面可知道,首次分配的内存请求是由_ioinit发出的,它要求的内存大小经处理发到sbh之后是0x130,那么,就应该是第19个链表为它分配
分配之后的结果

本来应该由第19个单元来分配,但是只有最后一个单元它有区块可以分配,因此由它来分配
管理这些单元下有无区块可分配的是region的bit部分,32组64bit(对应 32个Group * 64个链表),如图

第二次:分配
第二次分配假设为0x240(可计算的,但是每台电脑会有所区别)
那么应该由第 36 个链表来分配
第二次分配的结果
观察Group的cntEntries可以知道,它是记录已分配出去的内存区块的数量。
....
第十五次:回收
假设当前归还的区块(调用了free)大小为0x240,0x240由第36条链表管理,应该归还第36号链表
归还之后的结果
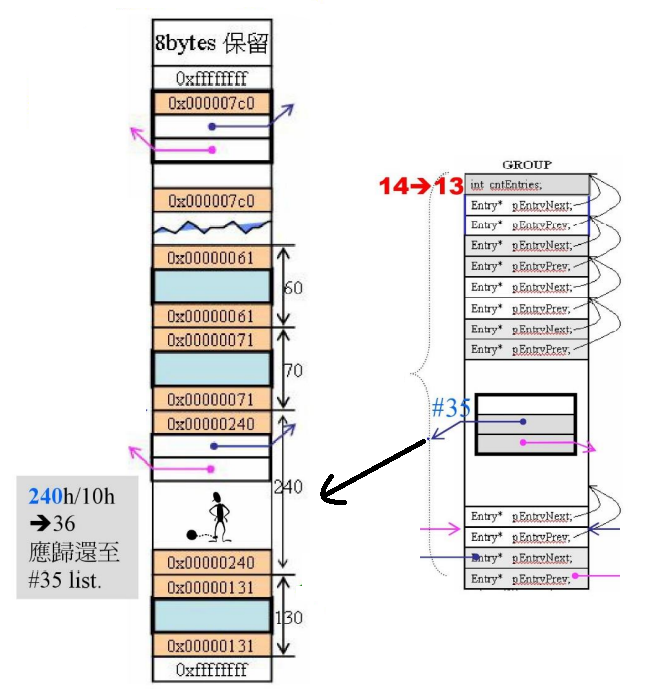
因此,bit块里 Group0的第36号链表对应的bit更改为1(假设本来为0),表示第36号链表挂上了一个区块,由它管理
第十六次:分配
假设当前分配的区块大小为 0xb0,应该由第11号链表为它分配,但是当前只有第36号、第62号链表有区块,由谁为他分配?
它会去找最近的(向上找)链表,即第36号链表
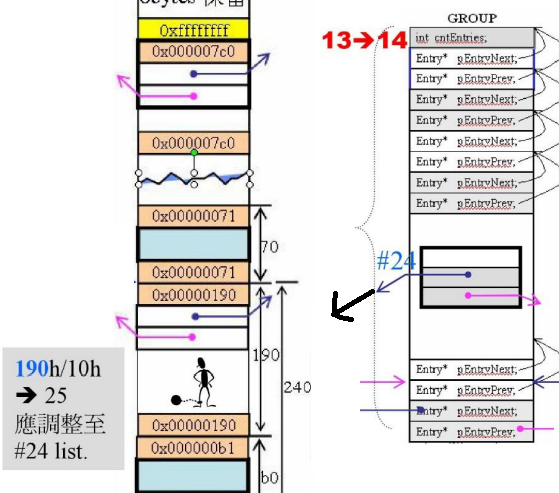
0x240分配出去0xb0,剩余0x190
第n次:分配
看第一组64bit:为1的是:第7、28、30位,则Group0中对应链表有区块,最大区块为0x1e0,此时分配一个0x230的给他,那么
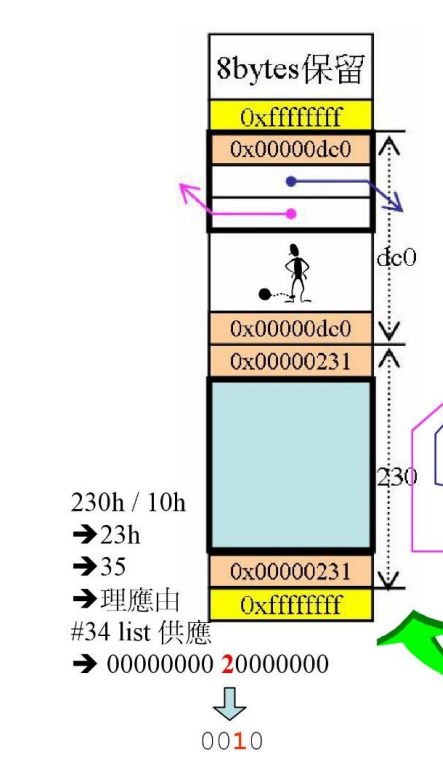
Group0中没有区块可以分了,因此由下一个Group来分配,index变为1

当Group
上下cookie的作用
cookie的作用是在内存合并中体现的,如果只需要记录大小,那么一块cookie足矣,而不需要上下都有
当我们回收内存的时候,如果总是不合并,那么内存就会越来越碎片化,导致大内存无法分配,因此应该合并内存
何时合并?先想想什么时候需要合并?只有在归还(合并之后交给另一条链表也算归还)的时候,因此我们只需要在归还的时候检查上下区块是否在sbh中(并且在同一个page中),是就合并
那么怎么检查呢?
cookie的作用就来了,检查当前区块的上一个末位是否是0,下一个末位是否是0,是就合并(顺序并不重要)
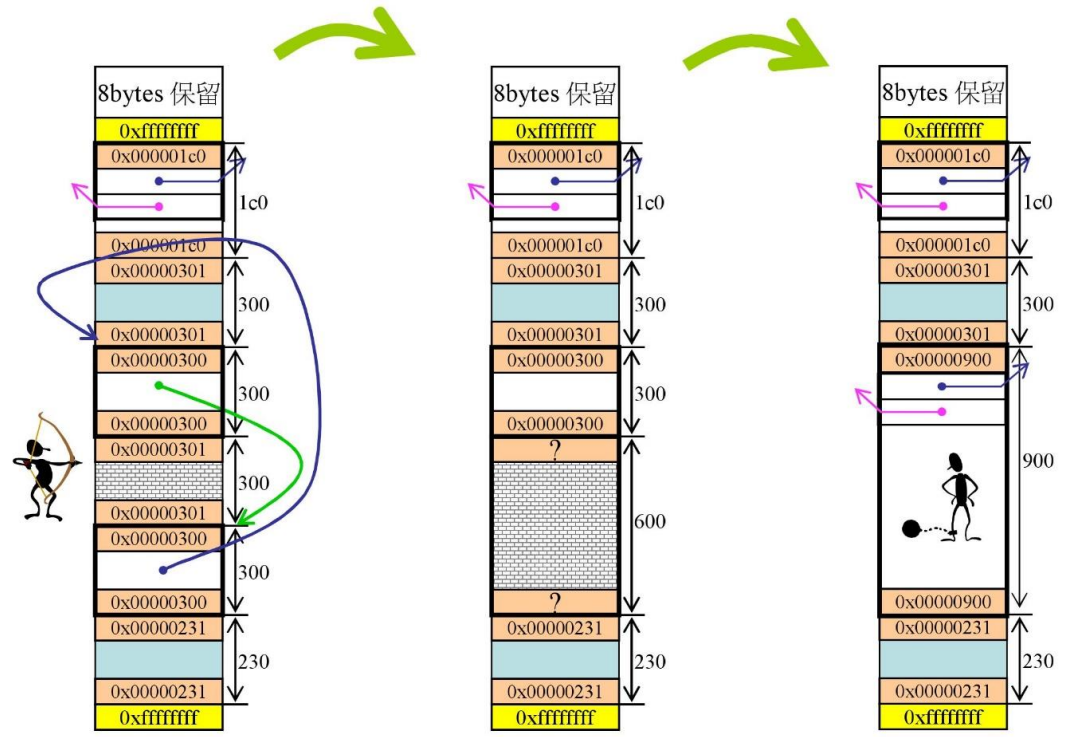
回收的问题
假设我们现在调用free(p)归还内存,现在有三个问题
-
p在哪一个Header里
-
每一个Header记录着虚拟空间地址的头指针,且知道虚拟空间大小,那么我们就可以知道p是否落在当前区块内,只要一个一个Header判断,就知道p落在哪一个Header里了
-
-
p在哪一个Group里
-
p - 虚拟空间地址的头指针,得到偏移量,便可以知道他在第几组
-
-
p在哪一个free-list里
-
有cookie知道大小,之后再合并
-
释放(归还操作系统)的问题

win的几个内存API
https://docs.microsoft.com/zh-cn/windows/win32/api
HeapCreate([1],[2],[3])
-
作用:创建一个堆对象,为后面分配空间使用
-
参数
-
[1]:指定堆分配选项,对后续调用使用该堆分配内存有影响
-
[2]:指定堆的初始大小
-
[3]:指定堆的最大大小,若为0,则可自动增长,直到内存不够
-
-
返回:返回堆对象指针
HeapAlloc([1],[2],[3])
-
作用:从堆里分配一块(a block)内存
-
参数:
-
[1]:指定的堆对象,可以是
HeapCreate或GetProcessHeap的返回对象 -
[2]:指定堆分配选项,指定之后会覆盖创建堆时的选项,0不会
-
[3]:需要多大
-
VirtualAlloc([1],[2],[3],[4])
-
作用:保留、提交或更改调用者进程的虚地址空间的页面区域的状态。内存分配自动初始化为0
-
参数:
-
[1]:指定分配区域的起始地址,若为null(0),那么由系统决定
-
[2]:区域大小
-
[3]:内存分配的类型
-
MEM_RESERVE:仅保留虚拟地址,并不实际分配空间。
ps:虚拟地址实际使用需要与实际地址对应(操作系统),这里仅保留了页面而不建立页关联
-
MEM_COMMIT:分配空间
-
-
[4]:略
-
有关内存的分配时机

一开始,这一条是由如下函数分配的,也就是说,不分配实际空间

而分配8个Page给Group0的时候,使用的是MEM_COMMIT,要求分配空间,并且指定了以addr为起始(猜想:addr应该与p相同,分配后应该需要增加偏移量,到下一个未实际分配的地方)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号