


80、事务的ACID是指什么?
答:
- 原子性(Atomic):事务中各项操作,要么全做要么全不做,任何一项操作的失败都会导致整个事务的失败;
- 一致性(Consistent):事务结束后系统状态是一致的;
- 隔离性(Isolated):并发执行的事务彼此无法看到对方的中间状态;
- 持久性(Durable):事务完成后所做的改动都会被持久化,即使发生灾难性的失败。通过日志和同步备份可以在故障发生后重建数据。
补充:关于事务,在面试中被问到的概率是很高的,可以问的问题也是很多的。首先需要知道的是,只有存在并发数据访问时才需要事务。当多个事务访问同一数据时,可能会存在5类问题,包括3类数据读取问题(脏读、不可重复读和幻读)和2类数据更新问题(第1类丢失更新和第2类丢失更新)。
脏读(Dirty Read):A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 取出500元余额修改为500元 | |
| T5 | 查询账户余额为500元(脏读) | |
| T6 | 撤销事务余额恢复为1000元 | |
| T7 | 汇入100元把余额修改为600元 | |
| T8 | 提交事务 |
不可重复读(Unrepeatable Read):事务A重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务B修改过了。
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 取出100元修改余额为900元 | |
| T6 | 提交事务 | |
| T7 | 查询账户余额为900元(不可重复读) |
幻读(Phantom Read):事务A重新执行一个查询,返回一系列符合查询条件的行,发现其中插入了被事务B提交的行。
| 时间 | 统计金额事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 统计总存款为10000元 | |
| T4 | 新增一个存款账户存入100元 | |
| T5 | 提交事务 | |
| T6 | 再次统计总存款为10100元(幻读) |
第1类丢失更新:事务A撤销时,把已经提交的事务B的更新数据覆盖了。
| 时间 | 取款事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 汇入100元修改余额为1100元 | |
| T6 | 提交事务 | |
| T7 | 取出100元将余额修改为900元 | |
| T8 | 撤销事务 | |
| T9 | 余额恢复为1000元(丢失更新) |
第2类丢失更新:事务A覆盖事务B已经提交的数据,造成事务B所做的操作丢失。
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 取出100元将余额修改为900元 | |
| T6 | 提交事务 | |
| T7 | 汇入100元将余额修改为1100元 | |
| T8 | 提交事务 | |
| T9 | 查询账户余额为1100元(丢失更新) |
数据并发访问所产生的问题,在有些场景下可能是允许的,但是有些场景下可能就是致命的,数据库通常会通过锁机制来解决数据并发访问问题,按锁定对象不同可以分为表级锁和行级锁;按并发事务锁定关系可以分为共享锁和独占锁,具体的内容大家可以自行查阅资料进行了解。
直接使用锁是非常麻烦的,为此数据库为用户提供了自动锁机制,只要用户指定会话的事务隔离级别,数据库就会通过分析SQL语句然后为事务访问的资源加上合适的锁,此外,数据库还会维护这些锁通过各种手段提高系统的性能,这些对用户来说都是透明的(就是说你不用理解,事实上我确实也不知道)。ANSI/ISO SQL 92标准定义了4个等级的事务隔离级别,如下表所示:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 第一类丢失更新 | 第二类丢失更新 |
|---|---|---|---|---|---|
| READ UNCOMMITED | 允许 | 允许 | 允许 | 不允许 | 允许 |
| READ COMMITTED | 不允许 | 允许 | 允许 | 不允许 | 允许 |
| REPEATABLE READ | 不允许 | 不允许 | 允许 | 不允许 | 不允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 | 不允许 | 不允许 |
需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定合适的事务隔离级别,这个地方没有万能的原则
81、JDBC中如何进行事务处理?
答:Connection提供了事务处理的方法,通过调用setAutoCommit(false)可以设置手动提交事务;当事务完成后用commit()显式提交事务;如果在事务处理过程中发生异常则通过rollback()进行事务回滚。除此之外,从JDBC 3.0中还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点。 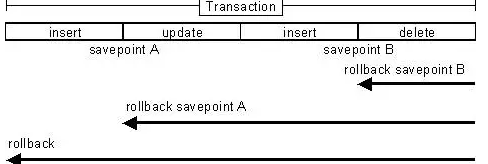
82、JDBC能否处理Blob和Clob?
答: Blob是指二进制大对象(Binary Large Object),而Clob是指大字符对象(Character Large Objec),因此其中Blob是为存储大的二进制数据而设计的,而Clob是为存储大的文本数据而设计的。JDBC的PreparedStatement和ResultSet都提供了相应的方法来支持Blob和Clob操作
84、Java中是如何支持正则表达式操作的?
答:Java中的String类提供了支持正则表达式操作的方法,包括:matches()、replaceAll()、replaceFirst()、split()。此外,Java中可以用Pattern类表示正则表达式对象,它提供了丰富的API进行各种正则表达式操作
85、获得一个类的类对象有哪些方式?
答:
- 方法1:类型.class,例如:String.class
- 方法2:对象.getClass(),例如:"hello".getClass()
- 方法3:Class.forName(),例如:Class.forName("java.lang.String")
86、如何通过反射创建对象?
答:
- 方法1:通过类对象调用newInstance()方法,例如:String.class.newInstance()
- 方法2:通过类对象的getConstructor()或getDeclaredConstructor()方法获得构造器(Constructor)对象并调用其newInstance()方法创建对象,例如:String.class.getConstructor(String.class).newInstance("Hello");
89、简述一下面向对象的"六原则一法则"。
https://www.cnblogs.com/zzt-lovelinlin/p/6795849.html
答:
- 单一职责原则:一个类只做它该做的事情。(单一职责原则想表达的就是"高内聚",写代码最终极的原则只有六个字"高内聚、低耦合",就如同葵花宝典或辟邪剑谱的中心思想就八个字"欲练此功必先自宫",所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。我们都知道一句话叫"因为专注,所以专业",一个对象如果承担太多的职责,那么注定它什么都做不好。这个世界上任何好的东西都有两个特征,一个是功能单一,好的相机绝对不是电视购物里面卖的那种一个机器有一百多种功能的,它基本上只能照相;另一个是模块化,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)
- 开闭原则:软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。)
- 依赖倒转原则:面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
- 里氏替换原则:任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)
- 接口隔离原则:接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
- 合成聚合复用原则:优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
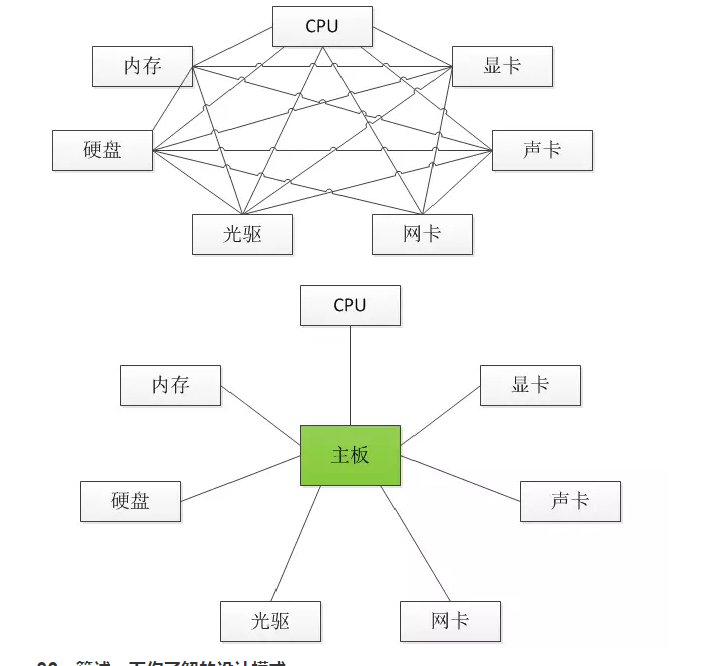
- 迪米特法则:迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。(迪米特法则简单的说就是如何做到"低耦合",门面模式和调停者模式就是对迪米特法则的践行。对于门面模式可以举一个简单的例子,你去一家公司洽谈业务,你不需要了解这个公司内部是如何运作的,你甚至可以对这个公司一无所知,去的时候只需要找到公司入口处的前台美女,告诉她们你要做什么,她们会找到合适的人跟你接洽,前台的美女就是公司这个系统的门面。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度,如下图所示。迪米特法则用通俗的话来将就是不要和陌生人打交道,如果真的需要,找一个自己的朋友,让他替你和陌生人打交道。)
92、什么是UML?
答:UML是统一建模语言(Unified Modeling Language)的缩写,它发表于1997年,综合了当时已经存在的面向对象的建模语言、方法和过程,是一个支持模型化和软件系统开发的图形化语言,为软件开发的所有阶段提供模型化和可视化支持。使用UML可以帮助沟通与交流,辅助应用设计和文档的生成,还能够阐释系统的结构和行为。
93、UML中有哪些常用的图?
答:UML定义了多种图形化的符号来描述软件系统部分或全部的静态结构和动态结构,包括:用例图(use case diagram)、类图(class diagram)、时序图(sequence diagram)、协作图(collaboration diagram)、状态图(statechart diagram)、活动图(activity diagram)、构件图(component diagram)、部署图(deployment diagram)等。在这些图形化符号中,有三种图最为重要,分别是:用例图(用来捕获需求,描述系统的功能,通过该图可以迅速的了解系统的功能模块及其关系)、类图(描述类以及类与类之间的关系,通过该图可以快速了解系统)、时序图(描述执行特定任务时对象之间的交互关系以及执行顺序,通过该图可以了解对象能接收的消息也就是说对象能够向外界提供的服务)。
94、用Java写一个冒泡排序。
/*
* 冒泡排序
*/
public class BubbleSort {
public static void main(String[] args) {
int[] arr={6,3,8,2,9,1};
System.out.println("排序前数组为:");
for(int num:arr){
System.out.print(num+" ");
}
for(int i=0;i<arr.length-1;i++){//外层循环控制排序趟数
for(int j=0;j<arr.length-1-i;j++){//内层循环控制每一趟排序多少次
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
System.out.println();
System.out.println("排序后的数组为:");
for(int num:arr){
System.out.print(num+" ");
}
}
}
95、用Java写一个折半查找。
答:折半查找,也称二分查找、二分搜索,是一种在有序数组中查找某一特定元素的搜索算法。搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组已经为空,则表示找不到指定的元素。这种搜索算法每一次比较都使搜索范围缩小一半,其时间复杂度是O(logN)。
import java.util.Comparator;
public class MyUtil {
public static <T extends Comparable<T>> int binarySearch(T[] x, T key) {
return binarySearch(x, 0, x.length- 1, key);
}
// 使用循环实现的二分查找
public static <T> int binarySearch(T[] x, T key, Comparator<T> comp) {
int low = 0;
int high = x.length - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int cmp = comp.compare(x[mid], key);
if (cmp < 0) {
low= mid + 1;
}else if (cmp > 0) {
high= mid - 1;
}else {
return mid;
}
}
return -1;
}
// 使用递归实现的二分查找
private static<T extends Comparable<T>> int binarySearch(T[] x, int low, int high, T key) {
if(low <= high) {
int mid = low + ((high -low) >> 1);
if(key.compareTo(x[mid])== 0) {
return mid;
}else if(key.compareTo(x[mid])< 0) {
return binarySearch(x,low, mid - 1, key);
} else {
return binarySearch(x,mid + 1, high, key);
}
}
return -1;
}
}说明:上面的代码中给出了折半查找的两个版本,一个用递归实现,一个用循环实现。需要注意的是计算中间位置时不应该使用(high+ low) / 2的方式,因为加法运算可能导致整数越界,这里应该使用以下三种方式之一:low + (high - low) / 2或low + (high – low) >> 1或(low + high) >>> 1(>>>是逻辑右移,是不带符号位的右移)
98、转发(forward)和重定向(redirect)的区别?
答:forward是容器中控制权的转向,是服务器请求资源,服务器直接访问目标地址的URL,把那个URL 的响应内容读取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容是从哪儿来的,所以它的地址栏中还是原来的地址。redirect就是服务器端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,因此从浏览器的地址栏中可以看到跳转后的链接地址,很明显redirect无法访问到服务器保护起来资源,但是可以从一个网站redirect到其他网站。forward更加高效,所以在满足需要时尽量使用forward(通过调用RequestDispatcher对象的forward()方法,该对象可以通过ServletRequest对象的getRequestDispatcher()方法获得),并且这样也有助于隐藏实际的链接;在有些情况下,比如需要访问一个其它服务器上的资源,则必须使用重定向(通过HttpServletResponse对象调用其sendRedirect()方法实现)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号