reuqest模块及UA反扒机制
requests模块
- 爬虫中一个基于网络请求的模块
- pip install requests
- 作用:模拟浏览器发起请求
- 编码流程:
- 1 . 指定url
- 2 . 发起请求
- 3 . 获取响应数据(爬取到的页面源码数据)
- 4 . 进行持久化存储
简单例子:
#指定爬取的url (以搜狗为例)
url = "https://www.sogou.com"
# 发起请求get方法返回值为响应对象
response = requests.get(url=url)
#获取响应数据,由于是对象,所以你需要展示内容有text,json
page_text = response.text
#持久化存储
with open("./zhou.html","w") as f:
f.write(page_text) #这里获取的是html代码,所以存储要是html后缀文件,要不然无法读取内容的
实现一个简易网页采集器
- 基于搜狗针对指定不同的关键字将其对应的页面数据进行爬取
- 参数动态化:
- 如果请求的url携带参数,且我们想要将携带的参数进行动态化操作那么我们必须:
- 1.将携带的动态参数以键值对的形式封装到一个字典中
- 2.将该字典作用到get方法的params参数中即可
- 3.需要将原始携带参数的url中将携带的参数删除
- 如果请求的url携带参数,且我们想要将携带的参数进行动态化操作那么我们必须:
keyWord = input('enter a key word:')
#携带了请求参数的url.如果想要爬取不同的关键字对应的页面,我们徐娅将url携带的参数进行动态化
params ={"query":keyword }
#其实至于携带的参数不是咱们决定的,你得实验看看搜索的时候,搜狗网站的url的变化,由于尝试过了,搜索之后网址会带这/web?query = "zhou" 所以按照他的url发起请求
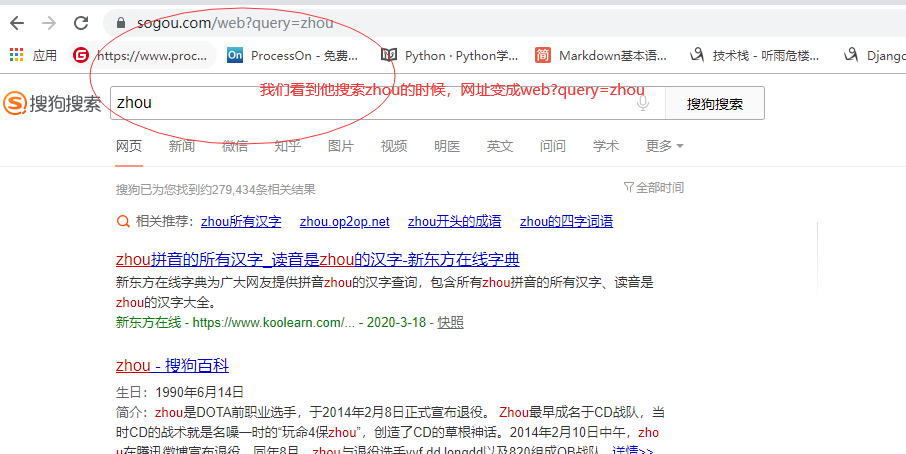
所以后续写法:
url = 'https://www.sogou.com/web'
#params参数(字典):保存请求时url携带的参数
response = requests.get(url=url,params=params)
#此时redponse可以查看到是乱码形式。你只需要修改编码即可持久化储存
#修改响应数据的编码格式
#encoding返回的是响应数据的原始的编码格式,如果给其赋值则表示修改了响应数据的编码格式
response.encoding = 'utf-8' #如果还是乱码可以尝试gbk gbk2312 等编码
page_text = response.text
fileName = keyWord+'.html'
#别忘了存入的时候用utf-8编码
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'爬取完毕!!!')
后续发现
处理了乱码。但是页面显示【异常访问】。导致请求失败
异常的访问请求
- 网站后台已经检测出该次请求不是通过浏览器发起的请求而是通过爬虫程序发起的请求。(不是通过浏览器发起的请求都是异常请求)
网站的后台是如何知道请求是不是通过浏览器发起的呢?
-
是通过判定请求的请求头中的user-agent判定的
什么是User-Agent
- 请求载体的身份标识
- 什么是请求载体:
- 浏览器
- 浏览器的身份标识是统一固定,身份标识可以从抓包工具中获取。
- 爬虫程序
- 身份标识是各自不同
- 浏览器
反扒机制之一:UA
-
- UA检测:网站后台会检测请求对应的User-Agent,以判定当前请求是否为异常请求。
- 反反爬策略:
- UA伪装:被作用到了到部分的网站中,日后我们写的爬虫程序都默认带上UA检测操作。
- 伪装流程:
- 从抓包工具中捕获到某一个基于浏览器请求的User-Agent的值,将其伪装作用到一个字典中,将该字典作用到请求方法(get,post)的headers参数中即可。
url = 'https://www.sogou.com/web'
params={"query":"zhou"}
#带上伪装请求载体。伪装成浏览器的身份
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
response = requests.get(url = url,params=params,headers=headers)
response.encoding="utf-8"
page_text = response.text
with open("homework(3)/zhou.html","w",encoding = "utf-8") as f:
f.write(page_text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号