❤️❤️建议收藏!!保姆级Python+Selenium自动化入门资料,学不会,来找我!!持续更新❤️❤️

@
目录
前言
- 本章内容需有一定Python基础,如何不懂的,请先学习Python。
什么??没有好的学习资料,给你准备好了!!
- 爆肝8万字的Python基础学习资料
- Python基础入门视频资料
- 以上资料都是本人亲自录制
Web自动化环境搭建
软件准备
- python64位安装包
- chrome64位浏览器&驱动
- 浏览器驱动下载
- 注意:chromedriver与chrome版本要对应。具体可查看该对应表
- 另外:本文主要以chromedirver为例
开始环境搭建
安装python:双击自定义安装 或者 在cmd中输入python-3.7.0-amd64.exe的路径,即在电脑中存放的位置,回车即可弹出安装页面,勾选Add Python 3.7 to PATH,即自动配置环境变量。
如图:

下图显示安装成功:

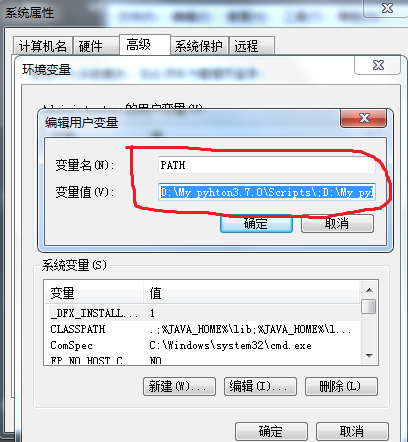
- 注:可以查看系统环境变量,发现D:\My pyhton3.7.0\Scripts;D:\My pyhton3.7.0;已经自动添加到了path中,这就是勾选Add Python 3.7 to PATH的效果.
![img]()
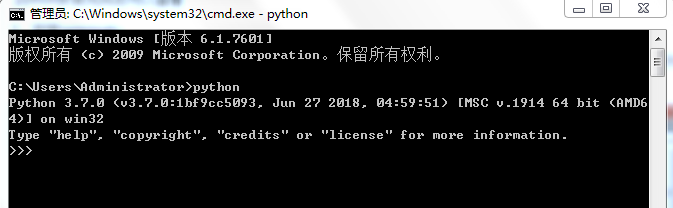
python安装完成后可以在cmd界面输入python,会出现下图内容,说明python安装成功
![img]()
- 安装selenium:
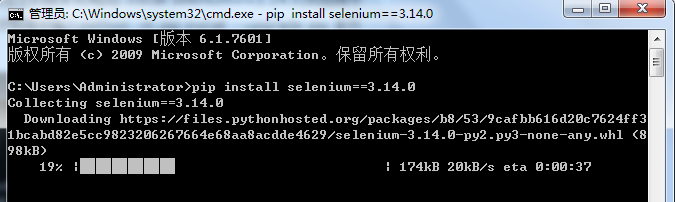
- 在cmd中运行pip install selenium 即可在线安装selenium,(ps:安装指定的版本可用pip install selenium==3.14.0)如图提示selenium安装成功。
![img]()
- 使用pip show selenium 查看selenium版本信息
- 安装chrome浏览器
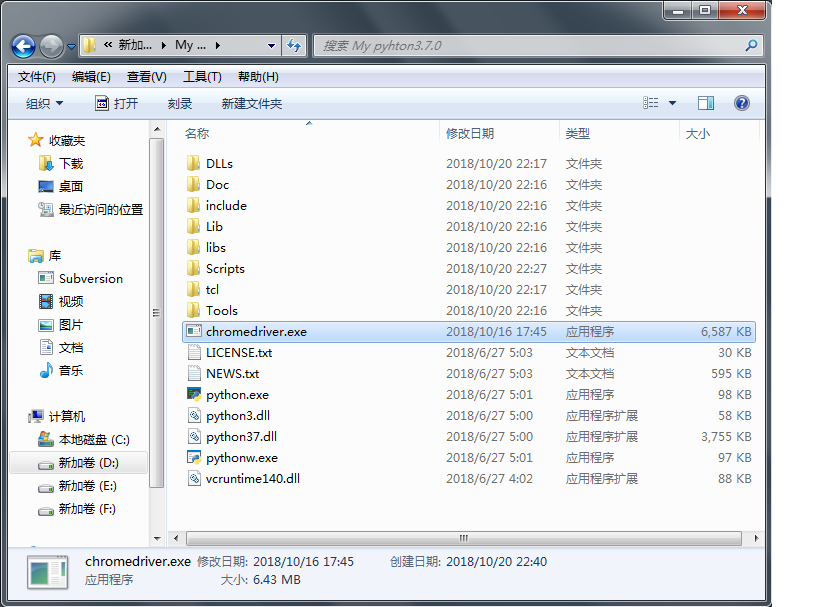
该处使用谷歌浏览器64位的版本号为70.0.3538.67 - 将chromedriver.exe放到python的安装目录下(或者目录下的scripts下)
![img]()
以上5步就搭建好python+selenium环境了
浏览器基本操作
前言
开始自动化测试之前,需了解浏览器的一些基本操作,以方便后续的自动测试。码上开始吧!
导入Selenium模块
from selenium import webdriver
浏览器基本操作
- 打开网站
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
url = "http://localhost:8080/Shopping/index.jsp"
# 也可以用其它浏览器:比如Firefox()等等
brower = webdriver.Chrome()
# 打开浏览器
brower.get(url)
- 设置休眠
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
import time
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
# 强制等待3秒
time.sleep(3)
- 页面刷新
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
# 刷新页面
brower.refresh()
- 前进和后退
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
import time
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
# 实际效果自己操作,当前就不做演式了
# 后退
brower.back()
# 前
brower.forward()
- 设置窗口大小
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
import time
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
# 设置窗口大小
brower.set_window_size(1280, 720)
# 设置全屏
# brower.maximize_window()
- 截屏
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
import time
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
brower.get_screenshot_as_file("./test.png")
# 退出浏览器进程
brower.quit()
- 退出
#! /usr/bin/python3
# @Author : 一凡
from selenium import webdriver
import time
url = "http://localhost:8080/Shopping/index.jsp"
webdriver.Firefox
brower = webdriver.Chrome()
brower.get(url)
time.sleep(3)
# 退出浏览器进程
brower.quit()
为什么要学习定位
- 让程序操作指定元素,就必须先找到此元素;
- 程序不像人类用眼睛直接定位到元素;
- webDriver提供了八种定位元素的方式。
 - 定位总结
- id、name、class_name、tag_name:根据元素的标签或元素的属性来进行定位
- link_text、partial_link_text:根据超链接的文本来进行定位(a标签)
- xpath:为元素路径定位--重点
- css:为css选择器定位(样式定位)
常见定位方式
id
- 说明:HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素;
- 前提:元素有id属性
- id定位方法:find_element_by_id()
- 实现案例-1需求:打开百度界面( https://www.baidu.com/ ),通过id定位,输入信息,点击百度的钮
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
url = "https://www.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_id("kw").send_keys("好好学习|天天向上")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.quit()
name
- 说明:HTML规定name属性来指定元素名称,name定位就是根据name属性来定位
- 前提:元素有name属性
- name定位方法:find_element_by_name()
- 实现案例-2需求:打开百度( https://www.baidu.com/ ),通过name定位
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
url = "https://www.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_name("wd").send_keys("好好学习|天天向上")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.quit()
class_name
- 说明:HTML规定class来指定元素的类名,class定位就是根据class属性来定位,用法和name,id类似。
- 前提:元素有class属性
- class_name定位方法:find_element_by_class_name()
- 实现案例-3需求:打开百度界面( https://www.baidu.com/ ),通过class定位
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
url = "https://www.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_class_name("s_ipt").send_keys("好好学习|天天向上")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.quit()
tag_name
- tag_name是通过标签名称来定位的,如:a标签
- 注:由于HTML源码中,经常会出现很多相同的的标签名,所以一般不使用该定位方式
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
# 这里使用优设导航的百度搜索界面
# 获取浏览器对象
driver = webdriver.Chrome()
# 获取网络链接
url = "https://hao.uisdc.com/"
driver.get(url)
time.sleep(3)
# 获取搜索输入框,输入:优设导航的百度搜索
driver.find_element_by_tag_name("input").send_keys("优设导航的百度搜索")
# 暂停3秒
time.sleep(3)
# 退出浏览器驱动
driver.quit()
link_text
- 说明:link_text定位于前面4个定位有所不同,它专门用来定位超链接文本(文本值)
- 前提:定位的元素是链接标签(a标签)
- link_text定位方法:find_element_by_link_text()
- 实现案例-5需求:打开百度首页,通过link_text(链接文本)定位到【新闻】按钮,并进行点击操作
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
url = "https://www.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_link_text("新闻").click()
time.sleep(3)
driver.quit()
partial_link_text
- 说明:partial_link_text定位是对link_text定位的补充,partial_link_text为模糊匹配;link_text为全部匹配。
- 前提:定位的元素是链接标签(a标签)
- partial_link_text定位方法:find_element_by_partial_link_text()
- 通过传入a标签局部文本或全部文本来定位元素,要求输入的文本能够唯一找到这个元素
- 实现案例-6需求:打开百度新闻( http://news.baidu.com/ ),通过partial_link_text定位任何一条新闻,并进行点击操作
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
import time
url = "http://news.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_partial_link_text("守护蓝色地球").click()
time.sleep(3)
# driver.quit()
元素组
- 元素组定位方式:find_elements_by_xxx
作用:- 查找返还定位所有符合条件的元素
- 返还的定位元素格式为列表格式
说明: - 列表数据格式的读取需要指定下标(下标从0开始)
- 案例要求:打开百度页面 https://www.baidu.com/ ,通过元素组定位
 - 定位:"//*[@id='s-top-left']/a"
# -*- coding:utf-8 -*-
# @Author : 一凡
from selenium import webdriver
url = "https://www.baidu.com/"
driver = webdriver.Chrome()
driver.get(url)
path = "//*[@id='s-top-left']/a"
elements = driver.find_elements_by_xpath(path)
# 返回列表
print(len(elements))
# 通过列表方法获取相应的元素进行点击
elements[0].click()
如果想学习软件测试,就快加入:893694563,群内学软件测试,分享技术和学习资料,陪你一起成长和学习。
码字不易,小伙伴如果看到最后,烦请来个三连,谢谢拉~

好好学习,天天向上!
学习不刻苦,不如卖红薯!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号