

爬虫的亲生体验
最近找到一个IT网站,想了解下IT热门文章下的重点词。http://blog.jobbole.com/category/it-tech/
下面介绍下在爬虫遇到的坑:
1、wordcloud 第三方插件导入问题。
大部分人出现过,首先PyCharm在setting下导入会报错误。毕竟我的python3.7这个有点坑,然后删除这个3.7,下载了3.6版本的python。
解决方案
在http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载
wordcloud-1.4.1-cp36-cp36m-win_amd64.whl文件,然后到本文件所在目录执行 因为这个细节没注意到,结果随便在一个目录下pip install wordcloud-1.4.1-cp36-cp36m-win_amd64.whl
这就导致在已建的项目中无法导入wordcloud。不得不通过新建环境来导入wordcloud,因为wordcloud导入python本地环境不是你项目环境的原因。
2.在爬取数据的坑:
该网站通过中断远程来阻止爬取数据。

对于这个问题只能采取一页一页的爬取。
下面介绍下我爬取的关键代码
#存储文件 def storefile(content): f=open('detail.txt','a',encoding='UTF-8') f.write(content) f.closed #获取详情 def getDetail(url): res2 = requests.get(url) res2.encoding = 'UTF-8' detailsoup = BeautifulSoup(res2.text, 'html.parser') de=detailsoup.select('.entry') for i in de: for j in i.select('p'): if (len(j.select('img')) == 0): storefile(j.text); print(j.text); #获取页数 def getPage(url): res = requests.get(url); res.encoding = 'UTF-8'; soup = BeautifulSoup(res.text, 'html.parser'); return int(soup.select('.page-numbers')[4].text); #获取每一页的条数 def getEveryPageUrl(count): if(count==1): url = 'http://blog.jobbole.com/category/it-tech/'; res = requests.get(url); res.encoding = 'UTF-8'; soup = BeautifulSoup(res.text, 'html.parser'); for i in soup.select('.post-meta'): if (len(i.select('.archive-title')) > 0): getDetail(i.select('a')[0].attrs['href']); else: url = 'http://blog.jobbole.com/category/it-tech/page/{}/'; getUrl=url.format(count) res = requests.get(getUrl); res.encoding = 'UTF-8'; soup = BeautifulSoup(res.text, 'html.parser'); for i in soup.select('.post-meta'): if (len(i.select('.archive-title')) > 0): getDetail(i.select('a')[0].attrs['href']);
#保存数据到文本中 def storefile(date): # 将结果存放在文件夹 f = open("getDate.txt", 'w',encoding='utf-8') for i in range(150): f.write(date[i][0] + " " + str(date[i][1]) + '\n') f.close() #将list数据统计放在字典 def getDiet(list): diet = {} for j in list: count = list.count(j) diet[j] = count return diet def extract_words(): with open('detail.txt','r',encoding='utf-8') as f: comment_subjects = f.readlines() #加载stopword stop_words = set(line.strip() for line in open('stopwords.txt', encoding='utf-8')) commentlist = [] for subject in comment_subjects: if subject.isspace():continue word_list = pseg.cut(subject) for word, flag in word_list: #排除stopwords文件中的不需要的词 if not word in stop_words and flag == 'n': commentlist.append(word) # 排序 date = sorted(getDiet(commentlist).items(), key=lambda items: items[1], reverse=True) storefile(date) #加载需要生成词云图片的图片模板 d = path.dirname(__file__) mask_image = imread(path.join(d, "pikaqiu.jpg")) content = ' '.join(list(getDiet(commentlist).keys())) wordcloud = WordCloud(font_path='font/AdobeSongStd-Light.otf', background_color="grey", mask=mask_image, max_words=150).generate(content) # 生成图片: plt.imshow(wordcloud) plt.axis("off") wordcloud.to_file('wordcloud.jpg') plt.show() if __name__ == "__main__": extract_words()
保存字典的前150个词
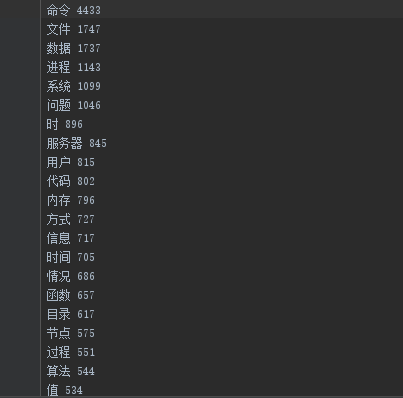
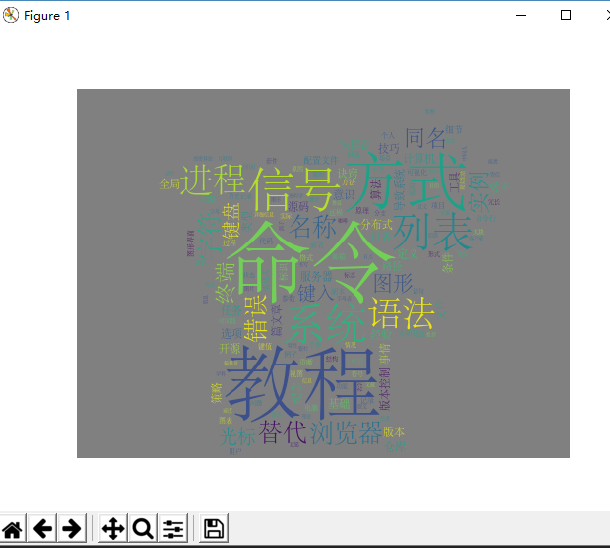
下面是通过可爱的皮卡丘模板生成的词云,通过词云可以查看到命令一词占居多,命令可以推导出该IT技术关于linux 技术文章居多,进程、信号等涉及计算机重要知识点。
总结在工作或者学习中linux系统命令学习很重要。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号