MIT 6.830 Lab1 实验记录
Lab1
启动
先 Fork 后 Clone,直接用 IDEA 打开,然后可以看到 test 文件是绿色的,右键 test 文件夹可以看到 Run 'All Tests',这样就可以运行测试用例了,至于用不用 Ant 就看情况了。
SimpleDB 架构
Lab1 实验指导中指出,SimpleDB 包括如下几个部分:
- 域,元组,模式
- 谓词,条件
- 读取磁盘的方法,遍历元组的方法
- 操作类(select, join, insert, delete)
- 缓冲池
- 目录(表,模式)
Database Class:可以从这个类中获取数据库状态,主要包括 Catalog,Buffer Pool,Log File。
Exercies 1
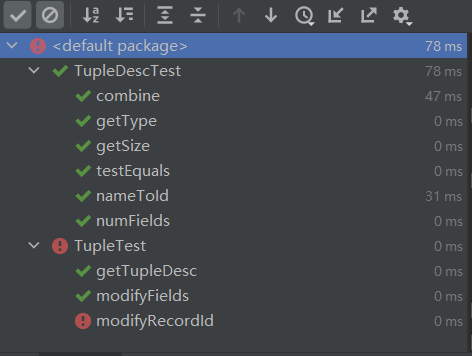
实现 Tuple 和 TupleDesc,前者是元组 Tuple,后者是关于元组的描述即 Schema。
Tuple 里面需要存储 Field,Schema 需要存储 Type,暂且都使用 List 来存储好了。List 具体实现采用 ArrayList,因为 ArrayList 随机访问比 LinkedList 快。对于一个数据库来说,往 List 里面插入删除(属性)次数应该不多,更多的是设置获取值。暂且不考虑线程安全的问题。
在 Tuple 中,存储每个域的值,初始化为 null,其他的方法和 List 基本接口一致,直接调用就好。
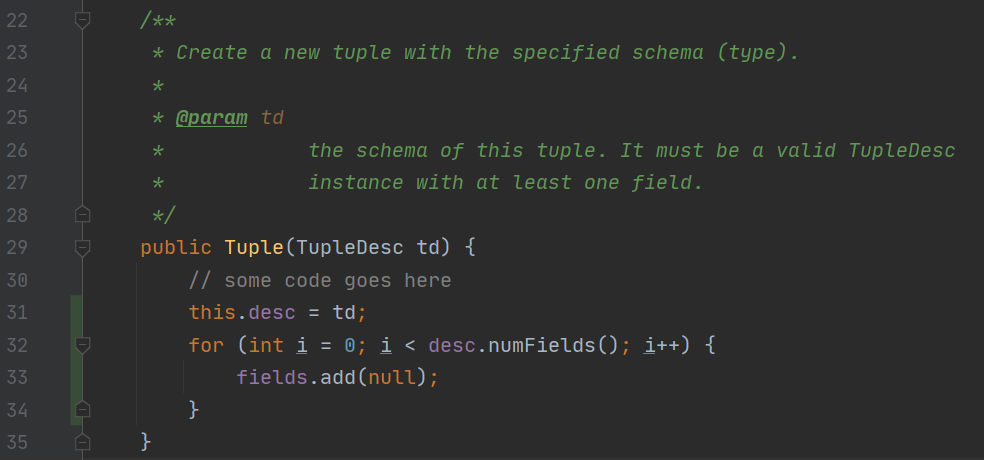
在 TupleDesc 中,第一次写 fieldNameToIndex failed 了,空指针异常,因为没有判断 name 是否为空。如果 name 为空,即使 TupleDes 中存在为空的 fieldName,也不能相等,直接抛出没有这个元素即可。
难度:easy
Exercises 2
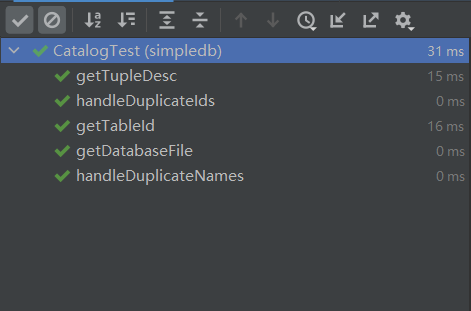
实现 Catalog,Catalog 负责存储表。一个表的元数据有如下信息:Id,文件,表名,主键,这些表的元数据使用一个内部类存储起来。Id 用 long 类型存储,每次自增 1,需要一个静态的变量来计数。使用 List 存储,选择 LinkedList,因为每次都要遍历才能获取到节点上的信息,除非用节点信息建立散列表。
- 后面有个接口,getTableId 返回的类型是 int,所以 Id 还是用 int 来存储吧
- 需要仔细阅读 DbFile 接口,DbFile 有获取 id 的操作,并且可以唯一标识,getTableId 还是用这个吧
- DbFile 内部还有 Page 的读写操作,元组的插入删除,获取 TupleDesc 等操作。
- 有了 DbFile 的 getId 方法,我们应该在 CatalogItem 中存储 id 吗?这里考虑到 id 是 DbFile 决定的,而且需要用这个 id 去获取 DbFile 内部信息,所以每次需要 id 的时候,调用 DbFile 的 getId 方法。
- 之后几个 for 循环遍历来查信息,第一次 test 失败了两个:handleDuplicateIds,handleDuplicateNames
- handleDuplicateIds,遇到一样的 id,表明这个 DbFile 已经存在,不需要再次添加了。
- handleDuplicateNames,这个好处理,用一个 Map 存储表名计次,第一次是原名,后面出现一样名字的时候,新名字为 tableName
- 上面两个方法都需要判重,使用两个 HashMap 好了
- 写完后,发现还是通过不了。仔细看 handleDuplicateNames 的测试用例,发现获取名字也是用的相同的名字,那相同的表名,我怎么确定呢?那应该是覆盖了。后面加入的表,在表名相同的情况下,覆盖前面的表。两个方法都是都采用覆盖的策略。
- 要怎么覆盖呢?一开始我的办法是找到那个 item,然后修改里面的内容。但是转念一下,有一种情况,名字和 id 同时都冲突了,这怎么处理?列表里有两个节点需要覆盖!因此,这里采用的方法是,找到那个 item 的下标,然后如果找得到就移除。最后在 add
- 后面突然意识到,如果表明是空串呢?这里暂且不处理,因为即使是空串,也不影响它的行为。一方面,获取表明,拿到空串是 ok。另一方面,如果插入的表名为空,前面已经有一个空串表名了,那我们就直接覆盖好了。
- BTW,使用内部类的时候,IDEA 建议使用静态的内部类。因为内部类没有用到外部的普通成员和方法,因此这种依赖是单向的,外部依赖内部,所以可以使用静态内部类。内部类对象需要拥有外部对象的引用,因此理论上应该是比静态内部类占用多几个字节的。其他对比看一看:https://www.zhihu.com/question/263827779
难度:easy,要考虑的东西多了一点点
Exercises 3
实现 BufferPool 中的 getPage 方法,还有构造器。BufferPool 中 Page 的数量是固定的,直接用一个数组来存。后面可能还要实现页面置换的算法,比如 LRU,最近最少使用。那么我们需要维护所有页的下标,然后再置换。这样看来选择数组,应该不会导致实现页面置换算法过程中,有什么不方便的地方。
getPage 的参数列表中,有三个:事务的 id,Page 的 id,权限。因此,还需要记录 page 的权限,开一个和 pages 一样大的数组。getPage 的时候,遍历,然后判断权限,如果请求的权限大于实际的权限,就抛出异常。
Exercises 4
这个部分主要完成 Heap 开头的几个文件。
HeapFile 是 DbFile 的一个具体实现,DbFile 代表了一个存储在磁盘上的文件,一个 DbFile 存储一个表(因此还有一个模式),需要提供一个唯一的 id 来标识,DbFile 上提供了 IO 相关的接口,比如按 Page 读写,从文件插入删除元素。
HeapPage 是 Page 的一个具体实现,Page 接口表示 BufferPool 中存储的一个 Page,因此可以说 Page 在内存中。Page 接口提供了一个 getPageData 方法,返回值是 byte[],其实 Page 就是一个 byte[] 数组的封装。封装了什么东西呢?有 id,dirty 等字段,还要能支持事务,用以恢复数据。
HeapPageId 是 PageId 的一个具体实现,PageId 接口,顾名思义就是 Page 的 Id,为什么需要封装起来呢?我也不懂啊。封装了这个 Page 归属的表的 Id,还有这个 Page 的序号。
HeapPageId.java
- 留着 hashCode 方法没写,然后跑了测试,失败了一个 testHashCode,看来 hashCode 这个方法需要实现
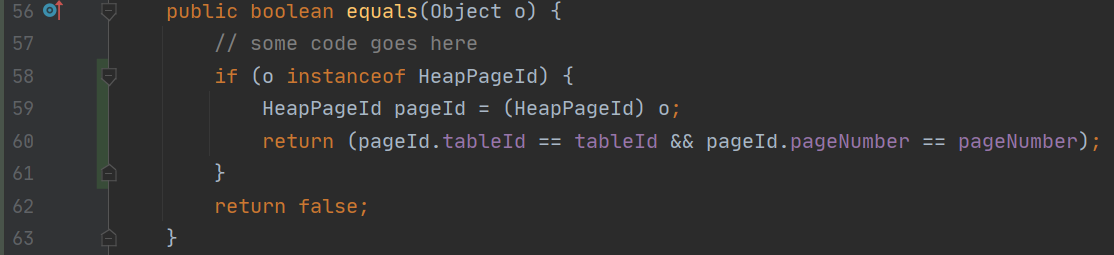
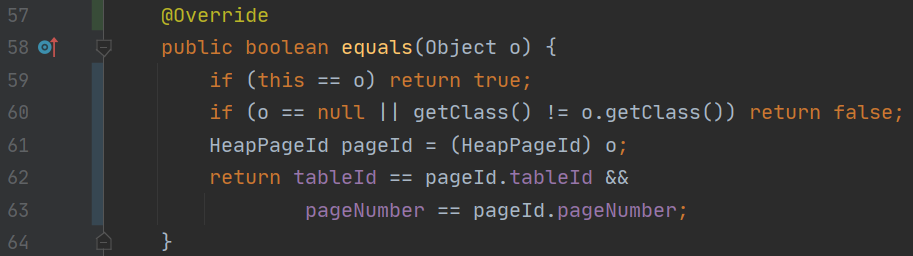
- 于是查一查该如何实现 hashCode,一查发现 IDEA 中可以自动生成,于是生成了 equals 和 hashCode 方法。这个 equals 方法和我之前写的略有区别。第一个是我写的,后面那个是 IDEA 生成的。区别在于
instanceof和getClass() == o.getClass()。前者子类都会包括在内,因此可能子类都一起 equals 了,所以我的那个做法是错误的,不能使用instanceof。
原来的实现:
IDEA 生成的实现:
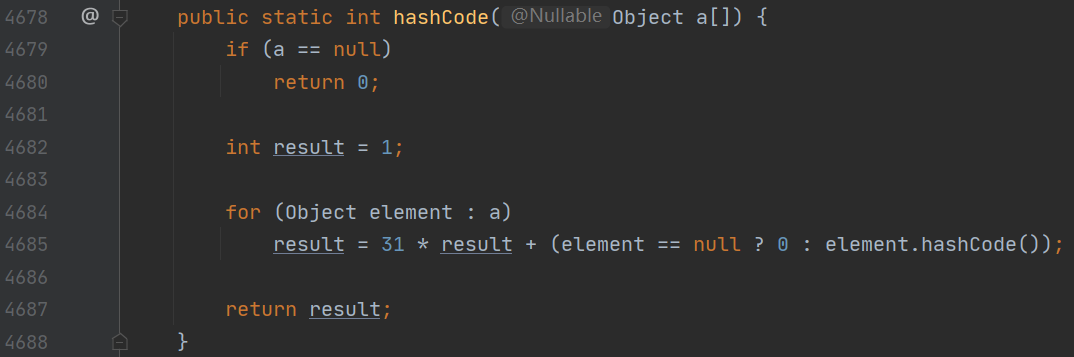
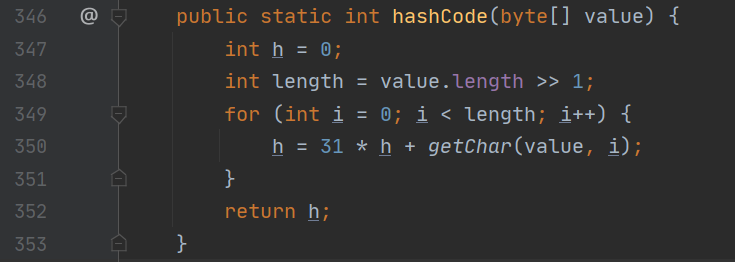
- 那 hashCode 该如何实现呢?IDEA 生成的方法调用了 Objects 工具类中的 hash 方法,而 Objects.hash 实际上这些可变参数当成数组传入 Arrays.hash 中。在 Arrays.hash 中,它是有个迭代公式 hash = hash * 31 + element.hashCode(),如果 element 为 null,那么是 0。element 如果是 Integer,那 hashCode 就是它的值。如果 element 是 Integer,那么使用字符串的一半字符和类似上面的公式来计算字符串的 hash 值,并且字符串中这个值需要被缓存下来,使用字符串来构造字符串的话,可以用之前的字符串的 hash 值。
Arrays.hash 方法
StringUTF16.hashCode 方法
RecordId.java
RecordId 是一条元组的 id,是一个实体类。写好之后 equals failed 了,主要是因为判断 pageId 相等用的是 ==,而不是调用它的 equals 方法🐷。
HeapPage.java
- 自己来分析一遍一个 Page 可以存储多少个元组。假设一个元组的长度是 len,那么需要 len * 8 bit 来存储实际的数据,还需要在头部放一个比特来表示这个元组是否有效(被删除了,或者还没有初始化)。那么实际上一个元组消耗的比特数是 len * 8 + 1 bit。Page 的长度是固定的,在 BufferPool 中有一个属性确定了这个值,记作 pageSize。所以用 pageSize 去除一个元组的实际消耗长度就可以得到可以存储多少个元组,结果向下取整即可。
头部的长度如何确定呢?一个字节可以存储 8 个元组,因此 numSlots 除以 8,就可以得到至少需要这么多个字节,结果要向上取整。因为是至少需要。
- 后面需要获取空的 slot 的数量,这里暂时假设空的 slot 存放的内容是 null。不不不,仔细看看代码,这里应该需要用的是头部的 bitmap,那就统计 bitmap 中 1 的个数。统计比特也没有想到什么特别好的办法,只好一个一个比特统计了。最多就开个多线程,或者使用 Java8 的流处理。
突然想到一个办法,因为一个字节最多 256 中状态,所以可以开一个数组来存储每一种状态中 1 的比特个数。之后处理的时候,就不需要每次都逐位统计了。可以设置成静态的,然后用静态代码块初始化。用下面的代码来初始化。之后统计的时候,直接映射就可以得到用了几个 slot。
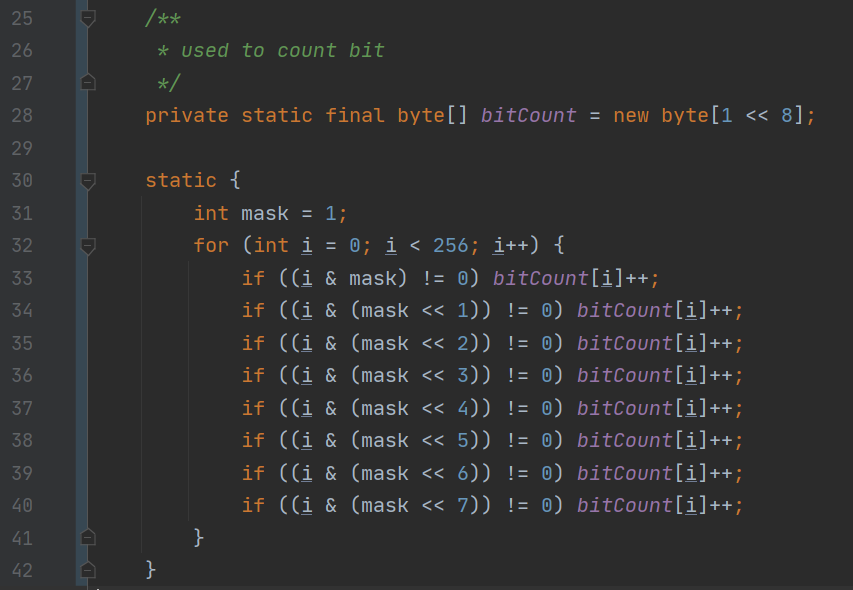
- 判断一个 slot 是否被用过。首先定位到 header 中对应的字节,然后找到对应的 bit。
- 哇。一跑,四个测试都 failed...
- 仔细排查才发现错误在定位对应的比特那里,首先找到对应的字节,我用 i 除以 8,然后向上取整。这就出错了,因为不足的部分应该对应于某个 bit,所以出错了,改成向下取整。再跑一次测试,还有两个测试没有过,一个是关于迭代器的(忘了实现),一个是关于获取空闲数目的。
- getNumEmptySlots,这里面错误的地方,是因为忘记了 byte 其实是有符号整数,我直接遍历 header 里面的字节然后用 bitCount 做映射,这样就可能出现越界的问题。另一方面,还要注意到整数的表示方法,-1 对应的是全 1,所以需要做点小操作。
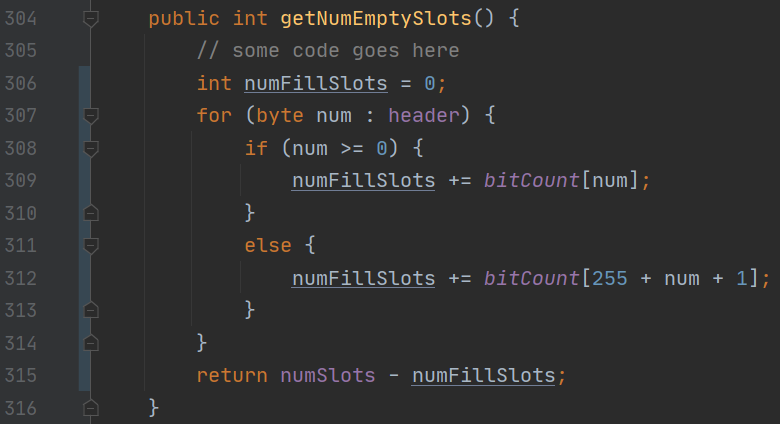
- 把迭代器的代码补上,再跑一次,ok
Exercises 5
实现 HeapFile,从磁盘中读取数据。迭代器中迭代的 Page 需要从 BufferPool 中获取。
- readPage 方法从磁盘中读写 Page,可能读写的是任意一页,因此这里使用 RandomAccessFile 来进行读写。getId 就按照注释中建议的那样,使用传入的文件绝对路径做散列来得到 hashCode。numPages 需要计算这个 HeapFile 的大小,直接文件长度除以每页的长度即可,小学数学呵 ( •̀ ω •́ )✧
- 迭代器,需要自己实现一个 DbFileIterator,这次实现的内部类不选择静态的,因为需要访问外部的变量,比如 BufferPool 的实例对象。Iterator 中读取 Tuple 时读取页面,要求只能从 BufferPool 中获取页面。写到这里,突然意识到 BufferPool 是全局变量,要从 Database 那个类中获取才行。另外,还要获取总的页数,这是外部类的一个普通方法。一开始采用的是普通内部类,经过这么一分析,还是选择静态内部类,因为 BufferPool 可以从 Database 获取,总页数传入构造器即可。后来发现,要存储两个外部类的域,emmm,我还是选择普通静态类吧。
- 跑一下测试,失败了两个,两个都是关于 Iterator 的,失败的原因是,测试用例中,会测试在不 open 的情况下调用 hasNext,这样就触发了空指针异常。修改成测试用例的预期行为之后,再跑一下,发现还是没通过。仔细一看,是 BufferPool 中找不到这个页面,所以是 HeapFile 读取了页面之后没有放入到 BufferPool 中,但是放入其中又需要页面置换算法,所以这两个测试应该不是这个 exercise 要通过的。
- 仔细往后看练习 6,就会发现需要一个迭代器,加入我们这个练习不通过那个迭代器的测试,那么后面就没办法继续了。于是,还是得通过这两个测试用例。在 BufferPool 中 getPage 如果找不到,那么可以 readPage,然后放入到 BufferPool 中。页面置换的方法,就用最简单的 FIFO。改完之后,还剩下一个测试没有通过。这个测试用例说的是,如果 close,那么之后的 next,getNext 操作需要抛出异常。在 HeapFileIterator 中增加一个表示关闭的布尔变量,如果关闭,那就抛出异常。测试用例,通过。
Exercise 6
实现 SeqScan,它是 OpIterator 的具体实现。OpIterator 是所有操作符需要实现的 Iterator 接口,要求在 open 中调用成员中的 open,close 中调用成员的 close。刚刚想到如果 open 了两次,或者 close 两次,那么应该是怎么样的行为呢?这里就让 open 抛出异常好了,不然会产生奇怪的现象,要么不跑出异常,直接返回也可以。在完成前面的基础上,实现一个扫描操作其实不难,只需要将前面实现的迭代器经过封装一下就好了。测试一下,通过。Lab1 完。
小结
前面记录的内容,都是边做边写的,整个过程比较意识流,想到什么写什么。继续往后面看,后面给出了一个例子,将前面构建的元素全部组合到一起,实现一个简单的查询语句:select * from table。虽然是自己写的工具,但我发现如果不看文档,我还写不好呢。基本的步骤是:需要自己手动组合每一列的类型,名字,然后新建一个 TupleDesc,再用这个 desc 去读取本地文件,这样就产生了一个有 schema,有数据的表,再将这个表放入到数据库中。为了遍历所有的元组,需要新建一个事务的 id,然后开始遍历,遍历前后记得 open,close。完成遍历,还要设置事务已经完成。
总的来说,第一个实验不算太难,基本上就是按部就班的做。做不出来就面向测试编程,总可以做对的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号