

Flink是如何实现exactly-once语义的
Flink跟其他的流计算引擎相比,最突出或者做的最好的就是状态的管理.什么是状态呢?比如我们在平时的开发中,需要对数据进行count,sum,max等操作,这些中间的结果(即是状态)是需要保存的,因为要不断的更新,这些值或者变量就可以理解为是一种状态,拿读取kafka为例,我们需要记录数据读取的位置(即是偏移量),并保存offest,这时offest也可以理解为是一种状态.
Flink是怎么保证容错恢复的时候保证数据没有丢失也没有数据的冗余呢?checkpoint是使Flink 能从故障恢复的一种内部机制。检查点是 Flink 应用状态的一个一致性副本,包括了输入的读取位点。在发生故障时,Flink 通过从检查点加载应用程序状态来恢复,并从恢复的读取位点继续处理,就好像什么事情都没发生一样。Flink的状态存储在Flink的内部,这样做的好处就是不再依赖外部系统,降低了对外部系统的依赖,在Flink的内部,通过自身的进程去访问状态变量.同时会定期的做checkpoint持久化,把checkpoint存储在一个分布式的持久化系统中,如果发生故障,就会从最近的一次checkpoint中将整个流的状态进行恢复.
下面就来介绍一下Flink从Kafka中获取数据,怎么管理offest实现exactly-once的.
Apache Flink 中实现的 Kafka 消费者是一个有状态的算子(operator),它集成了 Flink 的检查点机制,它的状态是所有 Kafka 分区的读取偏移量。当一个检查点被触发时,每一个分区的偏移量都被存到了这个检查点中。Flink 的检查点机制保证了所有 operator task 的存储状态都是一致的。这里的“一致的”是什么意思呢?意思是它们存储的状态都是基于相同的输入数据。当所有的 operator task 成功存储了它们的状态,一个检查点才算完成。因此,当从潜在的系统故障中恢复时,系统提供了 excatly-once 的状态更新语义。
下面我们将一步步地介绍 Apache Flink 中的 Kafka 消费位点是如何做检查点的。在本文的例子中,数据被存在了 Flink 的 JobMaster 中。值得注意的是,在 POC 或生产用例下,这些数据最好是能存到一个外部文件系统(如HDFS或S3)中。
第一步:
如下所示,一个 Kafka topic,有两个partition,每个partition都含有 “A”, “B”, “C”, ”D”, “E” 5条消息。我们将两个partition的偏移量(offset)都设置为0.
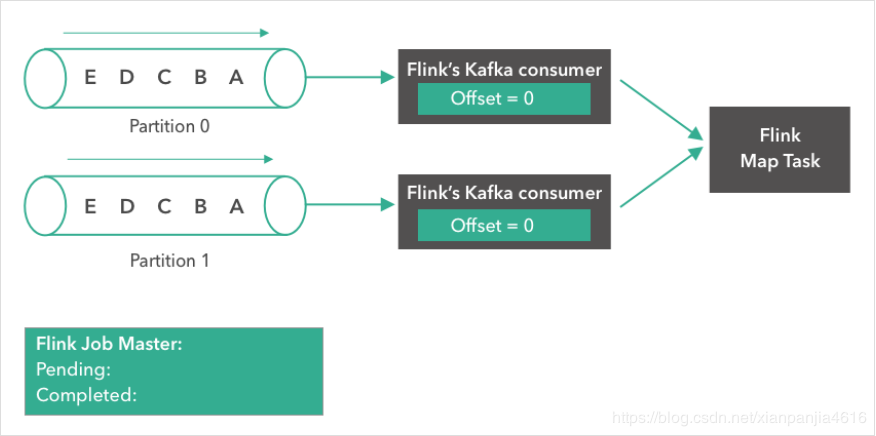
第二步:
Kafka comsumer(消费者)开始从 partition 0 读取消息。消息“A”正在被处理,第一个 consumer 的 offset 变成了1。
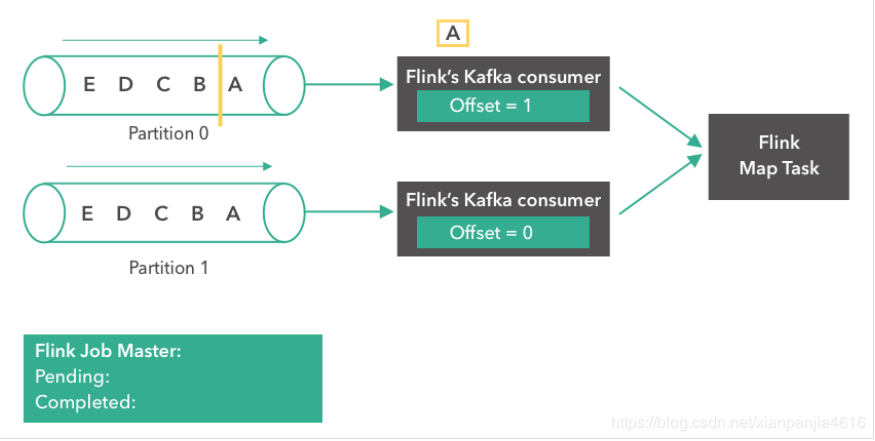
第三步:
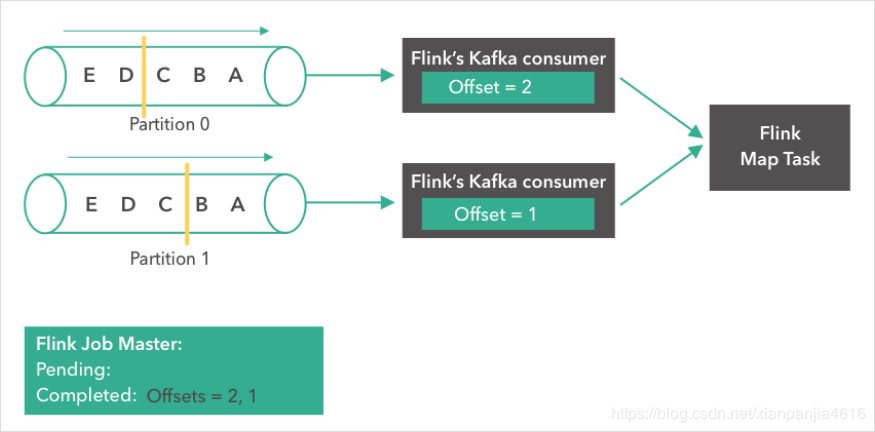
消息“A”到达了 Flink Map Task。两个 consumer 都开始读取他们下一条消息(partition 0 读取“B”,partition 1 读取“A”)。各自将 offset 更新成 2 和 1 。同时,Flink 的 JobMaster 开始在 source 触发了一个检查点。
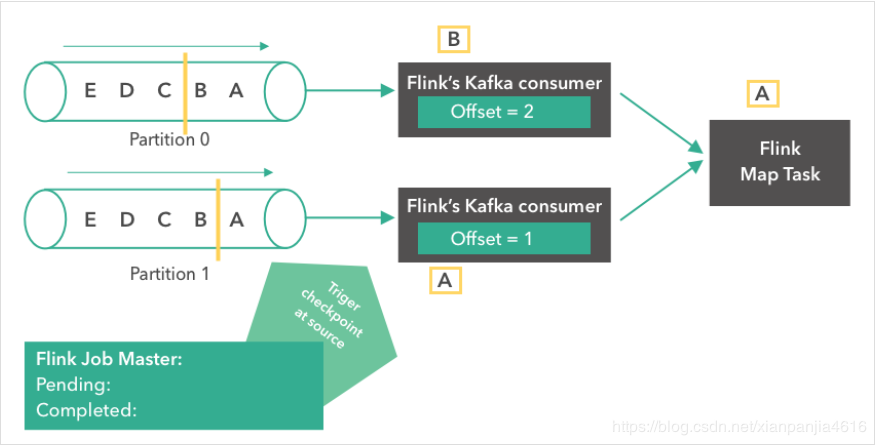
第四步:
接下来,由于 source 触发了检查点,Kafka consumer 创建了它们状态的第一个快照(”offset = 2, 1”),并将快照存到了 Flink 的 JobMaster 中。Source 在消息“B”和“A”从partition 0 和 1 发出后,发了一个 checkpoint barrier。Checkopint barrier 用于各个 operator task 之间对齐检查点,保证了整个检查点的一致性。消息“A”到达了 Flink Map Task,而上面的 consumer 继续读取下一条消息(消息“C”)。
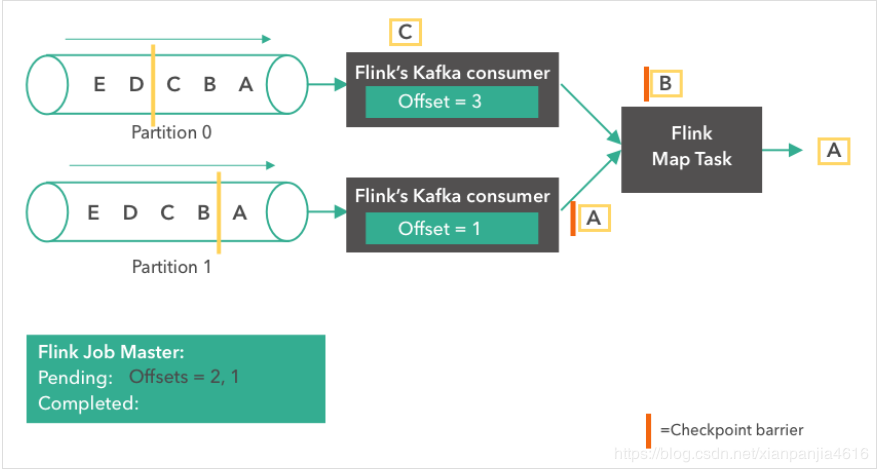
第五步:
Flink Map Task 收齐了同一版本的全部 checkpoint barrier 后,那么就会将它自己的状态也存储到 JobMaster。同时,consumer 会继续从 Kafka 读取消息。

第六步:
Flink Map Task 完成了它自己状态的快照流程后,会向 Flink JobMaster 汇报它已经完成了这个 checkpoint。当所有的 task 都报告完成了它们的状态 checkpoint 后,JobMaster 就会将这个 checkpoint 标记为成功。从此刻开始,这个 checkpoint 就可以用于故障恢复了。值得一提的是,Flink 并不依赖 Kafka offset 从系统故障中恢复。

故障恢复
在发生故障时(比如,某个 worker 挂了),所有的 operator task 会被重启,而他们的状态会被重置到最近一次成功的 checkpoint。Kafka source 分别从 offset 2 和 1 重新开始读取消息(因为这是完成的 checkpoint 中存的 offset)。当作业重启后,我们可以期待正常的系统操作,就好像之前没有发生故障一样。如下图所示:
Flink的checkpoint是基于Chandy-Lamport算法的分布式一致性快照,如果想更加深入的了解Flink的checkpoint可以去了解一下这个算法.
原文地址:https://www.da-platform.com/blog/how-apache-flink-manages-kafka-consumer-offsets

 浙公网安备 33010602011771号
浙公网安备 33010602011771号