

elasticsearch index 之merge
merge是lucene的底层机制,merge过程会将index中的segment进行合并,生成更大的segment,提高搜索效率。segment是lucene索引的一种存储结构,每个segment都是一部分数据的完整索引,它是lucene每次flush或merge时候形成。每次flush就是将内存中的索引写出一个独立segment的过程。所以随着数据的不断增加,会形成越来越多的segment。因为segment是不可变的,删除操作不会改变segment内部数据,只是会在另外的地方记录某些数据删除,这样可能会导致segment中存在大量无用数据。搜索时,每个segment都需要一个reader来读取里面的数据,大量的segment会严重影响搜索效率。而merge过程,会将小的segment写到一起形成一个大的segment,减少其数量。同时重写过程会抛弃那些已经删除的数据。因此segment的merge是有利于查询效率的。
elasticsearch的merge其实就是lucene的merge机制。merge过程是lucene有一个后台线程,它会根据merge策略来决定是否进行merge,一旦merge的条件满足,就会启动后台merge。merge策略分为两种,这也是大多数大数据框架所采用的,segment的大小和segment中doc的数量。以这两个标准为基础实现了三种merge策略:TieredMergePolicy、LogDocMergePolicy 及LogByteSizeMergePolicy。elasticsearch这一部分就是对这三种合并策略的封装,并提供了对于的配置。它的实现方式如下所示:
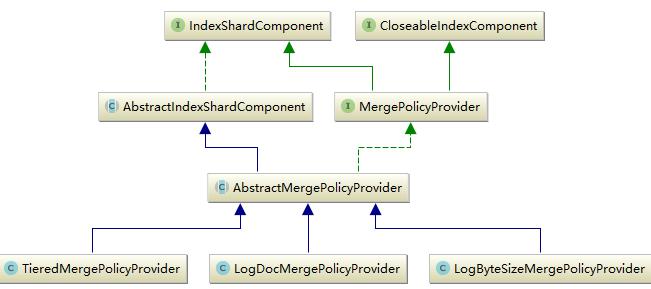
底层mergeprovider实现了对三种合并策略的初始化和配置,并通过getMergePolicy()方法对外提供。这三种合并策略中LogDocMergePolicy是根据doc数量进行合并,其它两种都是根据segment的大小,只是TieredMergePolicy合并过程是分层进行,它会把小于某一值的所有segment合并成一个大的segment,然后再一次进行。
以上是合并策略,除了合并策略还有一个要说的就是合并线程。前面说过,merge是通过独立线程完成的,lucene对于线程策略也有两种,一种是顺序,另外一种就是并发。顺序合并策略会阻止索引的进行,因此多数情况先不会使用,而并发合并则是和index过程同时进行,这样不会影响索引和搜索。elasticsearch同样通过provider的形式提供这两种合并线程配置。
总结:merge能够通过减少segment数量来提高搜索速度。但是merge的过程会对索引吞吐量及搜索速度有一定的影响,因此需要配置适当的合并策略参数。对于资源不足的环境,最好禁止自动merge,选择空闲时段手动进行merge。
,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号