

metadata 和 routing
虽然在刚开始源码概述时把代码分为分布式和数据两部分,但是它们的界限并不明显。之前这几篇可以说是这两部分的衔接。我们在快速接近数据(index)部分。本篇分析一下之前分析cluster遗留下的问题:Metadata与routing,虽然这两部分的代码在cluster中,但是却直接和index相关。
metadata部分主要是和索引相关的一些元数据构建和操作。元数据部分主要包括别名元数据(AliasMetaData):索引别名相关,将索引通过别名映射到相关的路由上;索引元数据(IndexMetaData):索引相关的,如shard数目replica数目, 创建时间等;索引模板元数据(IndexTemplateMetaData):模板相关,如预设的mapping, aliases等 ;mapping元数据(MappingMetadata):mapping相关的元数据,如id,routing等;及RestoreMetadata和 SnapshortMetadata等。这些metadata囊括了索引相关的所有元数据,这些元数据都是集群级别,我个人认为这也是这部分放到cluster的原因。
metadata是相关功能集群级别的配置信息,它们大都类似于数据类本身的逻辑并不复杂,都是由field和一些对field的set和get方法组成,但是它的有些field本身又是类。而且有些metadata类提供了更加复杂的数据操作方法,如MappingMetadata会有build及对于一些数据格式分析的方法。这里简单分析两个进行说明。下图是IndexMetadata的部分fields:

可以看到就是一些index相关的元数据,很多都是使用中必须解除到的。如Mapping等。方法上也大多是get与set,并没有太多复杂的逻辑。不同于IndexMetadata,MappingMetaData的filed则多数是内部分类,如下图所示:
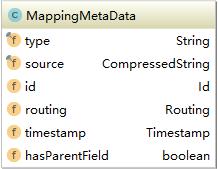
这里的id,routing和timestamp字段都是内部类,因为这些字段还包含其它逻辑,无法通过基本数据类型实现。而Mapping中的关键部分内容字段映射则是一个压缩字符串(source),这是一个json格式的字符串。因此MappingMetadata则包含了很多更复杂的方法用来解析source。
其它的metadata类跟着两个非常类似就不再一一说明,有兴趣的话请参考相关源码。最后来看一下MetaData相关的service,这些service对外提供了对相关MetaData读取和操作的接口。这里以MappingMetaDataService为例做个简单的说明,它的类图如下所示:
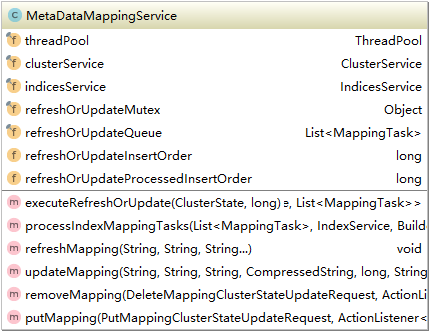
MappingMetaDataService对外提供了MappingMetaData的更新,移除等相关操作,这些方法涉及到了索引的相关操作,这里就不展开,在后面索引的分析中会有涉及。
以上就metadata的相关分析,这一部分自身不涉及太复杂的逻辑,复杂的逻辑都在service中,但是因为service的方法会牵扯到Index的操作,因此这里就先简单分析,后面索引的相关分析中再来仔细说明相关方法。
同MetaData类似,routing这一部分主要是集群中索引的路由的相关元数据,但和MetaData不同的是,这一部分有层次结构。ShardRouting是最基本元素,由它构成index的IndexRoutingTable,最后由IndexRoutingTable构成集群的RoutingTable。首先看看shardRouting,继承关系如下图所示:

一个Routing本质上是一个可以序列化的XContent,ImmutableShardRount中是Routing中不可变的字段及他们的set和get方法如id, version等。MutableShardRouting中主要是相关的shard操作,如重分配,primaryshard的变动等。一个shard的primary和所有的replica组成一个shardRoutingTable,它的部分代码如下所示:
public class IndexShardRoutingTable implements Iterable<ShardRouting> { final ShardShuffler shuffler; final ShardId shardId; final ShardRouting primary; final ImmutableList<ShardRouting> primaryAsList; final ImmutableList<ShardRouting> replicas; final ImmutableList<ShardRouting> shards; final ImmutableList<ShardRouting> activeShards; final ImmutableList<ShardRouting> assignedShards; ...... }
ShardRoutingTable中记录着一个shard所有状态的replica。index由多个shard组成,因此IndexRoutingTable由ShardRoutingTable组成,代码如下所示:
public class IndexRoutingTable implements Iterable<IndexShardRoutingTable> { private final String index; private final ShardShuffler shuffler; // note, we assume that when the index routing is created, ShardRoutings are created for all possible number of // shards with state set to UNASSIGNED private final ImmutableOpenIntMap<IndexShardRoutingTable> shards; private final ImmutableList<ShardRouting> allShards; private final ImmutableList<ShardRouting> allActiveShards; ....... }
最后所有的IndexRoutingTable组成了集群的RoutingTable:
public class RoutingTable implements Iterable<IndexRoutingTable> { public static final RoutingTable EMPTY_ROUTING_TABLE = builder().build(); private final long version; // index to IndexRoutingTable map private final ImmutableMap<String, IndexRoutingTable> indicesRouting; ......... }
这是indexRoutingTable这条线,另外还有一条RoutingTable,那就是nodeRoutingTable,这条RoutingTable线记录了每个节点上的shard的路由信息,由shardRouting构成nodeRoutingTable,然由NodeRoutingTable构成NodesRoutingTable(集群shardRouting)。
同所有是其它模块一样,这些Routing的相关操作也是由service对外提供,另外这一部分还有以下shard操作的相关类如ShardIterator,ShardShuffle等。
总结:本篇从结构上对metadata和Routing部分进行了简单说明,这两部分连接着cluster和index。这里的说明并没有深入到方法层面,一则这里的逻辑大部分很简单,另外这些方法在后面的数据(index)部分的分析中会有涉及。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号