

C语言博客作业04--数组
0.展示PTA总分
0.1 c07-一维数组

0.2 2019-c08-二维数组

0.3 2019-c09-字符数组

1.本章学习总结
1.1 学习内容总结
数组中如何查找数据
1.顺序查找法:依次将数组中的元素与被查找的数相比较,若相等则查找到该数据,若遍历完数组后仍然没有数与其相等则该数不在数组中。
这种做法思路十分简单,但效率很低。
2.二分查找法:首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
这种做法效率较高,不过要求数组是有序的。
数组中如何插入数据
- 步骤如下:
1.找到数据需要插入的位置
2.将插入位置之后的元素(包括插入位置)右移一位
3.将插入数放入应插入的位置 - 伪代码(以升序数组为例):
for i=0 to 数组最大下标 do
if 插入数大于数组元素 then
退出循环
end if
end for
for j=数组最大下标 to i+1 do
后一个数等于前一个数
end for
在插入位置放入插入数
数组中如何删除数据
1.删除某个位置或者特定的数:找到需要删除的数据的位置,依次让后一个数等于前面一个数直至数组末尾为止。通过直接覆盖掉删除数来达到删除的目的。
2.删除数组中的重复数据:使用两层for循环嵌套,对数组遍历,判断如果出现相同数据,则将后面的数据往前移一位,记录数组长度的变量相应减1
3.删除特定数:定义变量i,k并初始化为0 ,使用for循环遍历数组,若不是要删除的数,就让第k个元素等于第i个元素,k,i自增
- 伪代码如下
for i=0 to 数组末尾 do
if 第i个元素不是要删除的数 then
第k个元素等于第i个元素
k自增
end if
end for
数组中目前学到排序方法
1.选择排序:选择排序是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
2.冒泡排序:这种排序方法就是重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如数字从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。
- 冒泡排序算法的原理如下:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
数组做枚举用法
- 例如题集c07-一维数组中的7-5 有重复的数据I 这一题:通过设置一个hash数组,以空间换时间,将数组初始化为0,每出现一个数就让hash数组中下标为该数的元素等1,若对应元素已经是1了,就可以判断该数已经出现过了,即有重复数据。
哈希数组用法
- 仍然是题集c07-一维数组中的7-5 有重复的数据I 这一题:设置hash数组,通过对hash数组元素的检查得出是否有重复数据
- 又如:"abcd"用各个字符的值直接相加,再取对10的余数,既(a+b+c+d)%10,来得到一个数字,比方说结果为5,那么这个5就能在一定意义上代表这个字串abcd了。或者说这个5也可以说是这个字串的一个标记性的东西,而且是简化了的标记,所以又有人叫这个5为字串的摘要,或指纹。将一个个这样子的标记放入数组中就组成了hash数组。这时要查询一个字串是否存在,就不需要对一个数组使用字符串循环对比这样的慢操作,而直接先得到某个字串的hash值,再用这个hash值,在数组下标里直接找,这样速度要快上很多,特别是数据比较多的时候。
1.2 本章学习体会
- 学习感受:随着学习的知识不断增多,发现自己真的还有很多的知识和思维方法需要学习,自己不足的地方还有很多,有待进一步地弥补。两周以来,通过课堂的课堂的学习和自己动手实践,感觉自己又在学习C语言的过程中迈出了一小步。这两周主要就是学习了数组和指针,基础知识部分算是合格了,但是要熟练应用的话还是需要多加练习。
- 计算这两周代码量:
| PTA题集 | c07-一维数组 | 2019-c08-二维数组 | 2019-c09-字符数组 | 总计 |
|---|---|---|---|---|
| 代码量 | 355 | 365 | 248 | 968 |
2.PTA实验作业
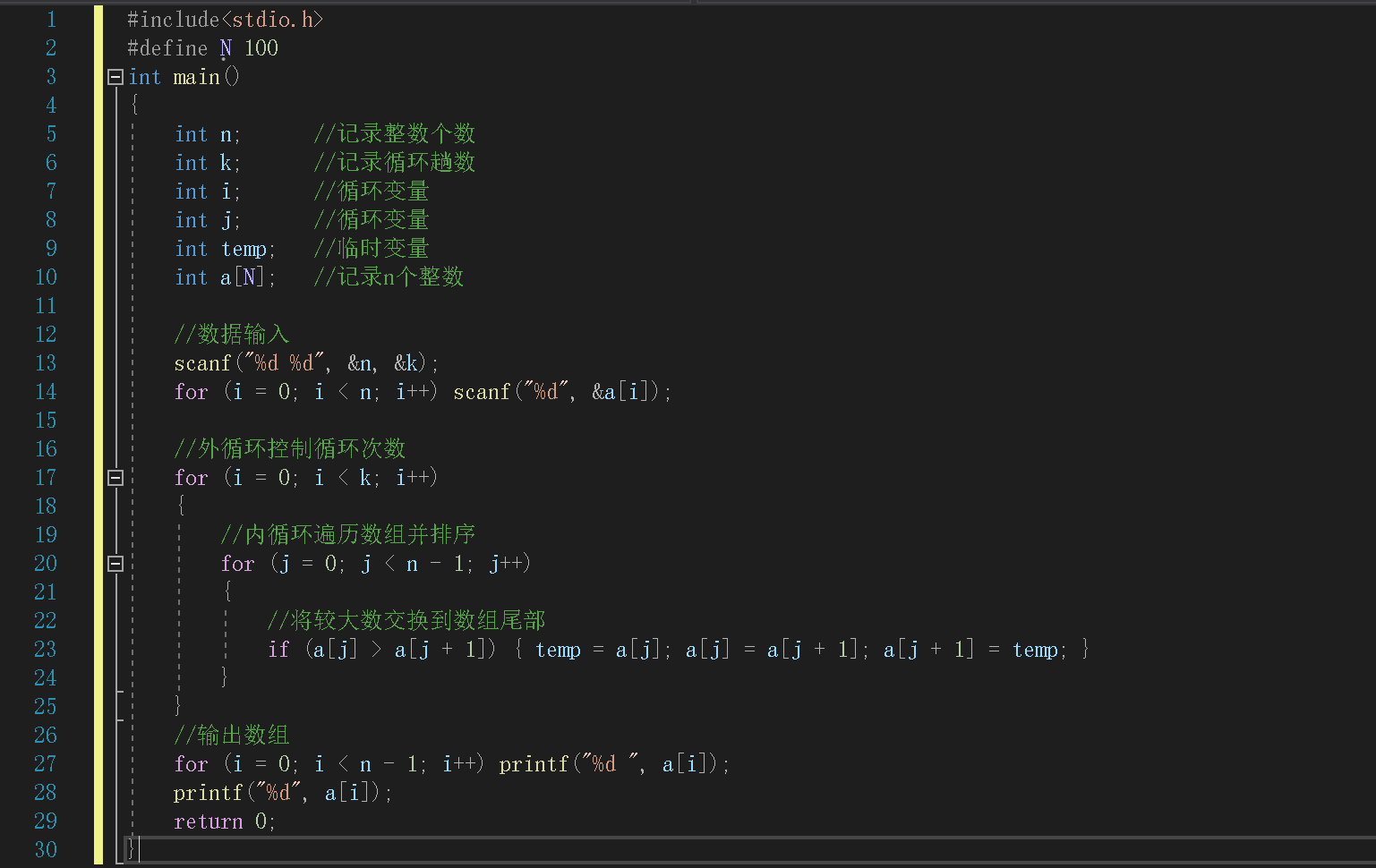
2.1 7-7 冒泡法排序
2.1.1 伪代码
- 数据处理:
| 类型 | 变量名 | 由来 |
|---|---|---|
| int | n | 记录整数个数 |
| int | k | 记录循环趟数 |
| int | temp | 临时变量 |
| int | a[N] | 记录n个整数 |
| int | i,j | 循环变量 |
- 伪代码:
定义N作为100的标志
定义变量n记录整数个数
定义变量k记录循环趟数
定义变量temp作为临时变量
定义变量a[N]记录n个整数
定义变量i,j作为循环变量
输入n,k
for i=0 to n do
输入数组
end for
for i=0 to k do
for j=0 to n-1 do
if 前一个数大于后一个数 then
交换它们
end if
end for
end for
for i=0 to n-1 do
输出数组
end for
输出数组最后一个数
2.1.2 代码截图
2.1.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 6 2 2 3 5 1 6 4 | 2 1 3 4 5 6 | sample 未完成排序 |
| 2 1 2 1 | 1 2 | 最小N,1次排序,顺序 |
| 10 3 10 9 8 7 6 5 4 3 2 1 | 7 6 5 4 3 2 1 8 9 10 | 较大N,逆序 |
2.1.4 PTA提交列表及说明
- PTA提交列表:

- PTA提交列表说明:
| 结果 | 原因 |
|---|---|
| 部分正确 | 思路不清晰导致有些测试点无法通过 |
| 部分正确 | 题目要求输出扫描完第K遍后的中间结果数列,而我直接输出最终的排序结果 |
| 答案正确 | 修改了循环条件后答案正确 |
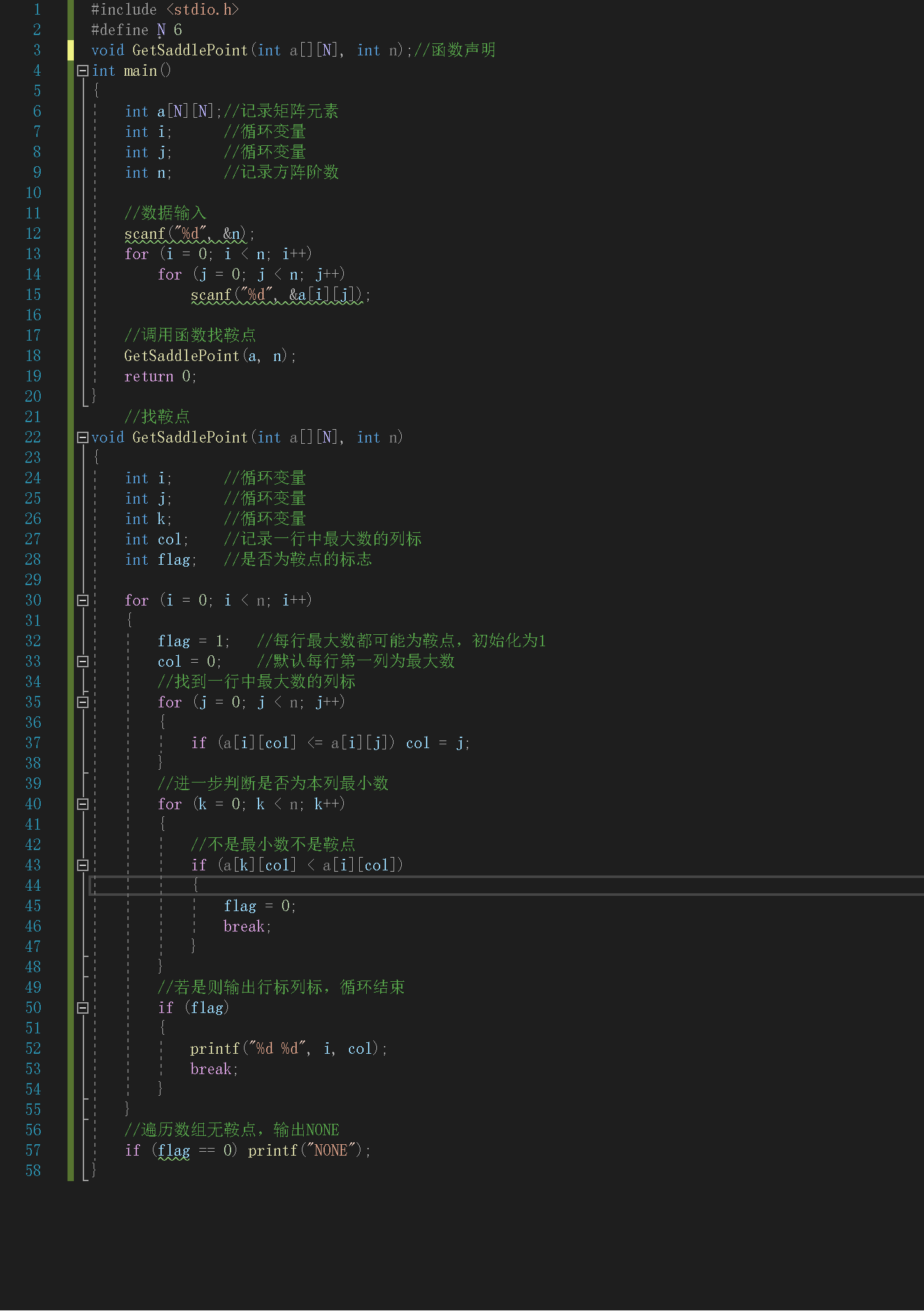
2.2 7-5 找鞍点
2.2.1 数据处理
- 数据处理:
| 类型 | 变量名 | 由来 |
|---|---|---|
| int | a[N][N] | 记录矩阵元素 |
| int | n | 记录方阵阶数 |
| int | col | 记录一行中最大数的列标 |
| int | flag | 是否为鞍点的标志 |
| int | i,j,k | 循环变量 |
- 伪代码:
定义N作为6的标志
GetSaddlePoint()函数声明
定义变量a[N][N]记录矩阵元素
定义变量n记录方阵阶数
定义变量i,j作为循环变量
输入n和矩阵
调用函数GetSaddlePoint()找鞍点
定义函数void GetSaddlePoint(形参为int a[][N], int n)
定义变量col记录一行中最大数的列标
定义变量flag作为是否为鞍点的标志
定义变量i,j,k作为循环变量
for i=0 to n do
flag初始化为1
col初始化为0
for j=0 to n do
if 本行的数大于等于原最大数 then
令col等于较大数的列标
end if
end for
for k=0 to n do
if 本行最大数不是本列最小数 then
赋值flag为0
退出循环
end if
end for
if 该数为鞍点 then
输出行标列标
结束循环
end if
end for
if 没有鞍点 then
输出NONE
end if
2.2.2 代码截图
2.2.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 4(1 7 4 1)(4 8 3 6)(1 6 1 2)(0 7 8 9) | 2 1 | sample1等价,存在鞍点 |
| 2(1 7)(4 1) | NONE | sample2等价,不存在 |
| 6(1 1 1 2 1 2)(1 1 1 3 1 3)(1 1 1 3 1 3)(1 1 1 3 1 3)(1 1 1 3 1 3)(1 1 1 3 1 3) | 0 5 | 最大规模,有并列极值元素,最后一个是鞍点 |
| 1 1 | 0 0 | 最小规模 |
2.2.4 PTA提交列表及说明
- PTA提交列表:

- PTA提交列表说明:
| 结果 | 原因 |
|---|---|
| 部分正确 | 有并列极值时无法移动到下一个极值的位置 |
| 答案正确 | 修改代码在两数相等时也移动即可 |
2.3 7-1 判断E-mail地址是否合法
2.3.1 数据处理
- 数据处理:
| 类型 | 变量名 | 由来 |
|---|---|---|
| char | str[N] | 记录E-mail地址 |
| int | flag | 是否已经遇到@的标志,1为否,0为是 |
| int | i | 循环变量 |
- 伪代码:
定义N作为10000的标志
JudgeAddress()函数声明
定义变量str[N]|记录E-mail地址
输入地址
if JudgeAddress返回值为1 then
输出YES
else
输出NO
end if
定义函数int JudgeAddress(形参为char str[])
定义变量flag作为是否已经遇到@的标志,1为否,0为是
定义变量i作为循环变量
for i=0 循环条件为 str[i] && str[i] != '\n' do
if str[i]是数字或者字母或者_ then
啥也不做
else if str[i]为@且flag值为1 then
if @前后为数字或者字母 then
赋值flag为0
else
结束函数返回0
end if
else if str[i]为. then
if .后面只有com then
啥也不做
else
结束函数返回0
end if
else
结束函数返回0
end if
end for
结束函数返回1
2.3.2 代码截图

2.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 123@123.com1 | NO | .com后有多余字符 |
| 123.@123.com | NO | .@ |
| 123@1_23@1a23.com | NO | @@ |
| 1_a @1.com | NO | 字符串中有空格 |
| 123_a@a.com; | NO | 合法地址后有非法字符 |
2.3.4 PTA提交列表及说明
-
PTA提交列表:

-
PTA提交列表说明:
| 结果 | 原因 |
|---|---|
| 段错误 | 大概是数组可存放的元素过少,增大数组空间即可 |
| 部分正确 | 对.com的判断条件不正确,最后一个元素应为'\n'或者'\0'都可以 |
| 答案正确 | 修改条件之后答案正确nice |
3.阅读代码
-
题目如下:

-
题解如下:

-
所选代码优点及可以学习地方:
1.对numsSize=0和numsSize=1的情况单独处理,既提高了效率也让程序更加严谨。
2.使用计数器k计算表中不同的元素个数,清晰明了。
3.灵活地应用数组下标来比较数组前后两个数是否相等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号