【sparkSQL】SparkSession的认识
在Spark1.6中我们使用的叫Hive on spark,主要是依赖hive生成spark程序,有两个核心组件SQLcontext和HiveContext。
这是Spark 1.x 版本的语法
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
而Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6中的SQLcontext和HiveContext
来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。
我们在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。
然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
创建SparkSession
SparkSession 是 Spark SQL 的入口。
使用 Dataset 或者 Datafram 编写 Spark SQL 应用的时候,第一个要创建的对象就是 SparkSession。
Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置。
Builder 的方法如下:
| Method | Description |
|---|---|
| getOrCreate | 获取或者新建一个 sparkSession |
| enableHiveSupport | 增加支持 hive Support |
| appName | 设置 application 的名字 |
| config | 设置各种配置 |
你可以通过 SparkSession.builder 来创建一个 SparkSession 的实例,并通过 stop 函数来停止 SparkSession。
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder
.appName("My Spark Application") // optional and will be autogenerated if not specified
.master("local[*]") // avoid hardcoding the deployment environment
.enableHiveSupport() // self-explanatory, isn't it?
.config("spark.sql.warehouse.dir", "target/spark-warehouse")
.getOrCreate
这样我就就可以使用我们创建的SparkSession类型的spark对象了。
设置参数
创建SparkSession之后可以通过 spark.conf.set 来设置运行参数
//set new runtime options
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//get all settings
val configMap:Map[String, String] = spark.conf.getAll()//可以使用Scala的迭代器来读取configMap中的数据。
读取元数据
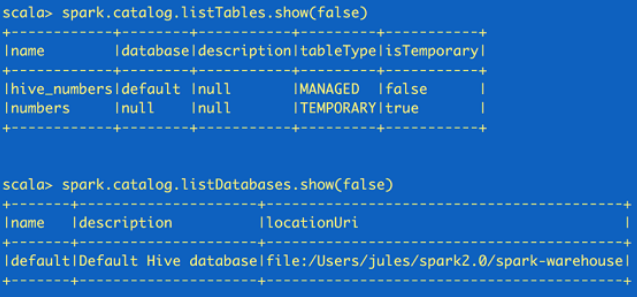
如果需要读取元数据(catalog),可以通过SparkSession来获取。
//fetch metadata data from the catalog spark.catalog.listDatabases.show(false) spark.catalog.listTables.show(false)
这里返回的都是Dataset,所以可以根据需要再使用Dataset API来读取。
注意:catalog 和 schema 是两个不同的概念
Catalog是目录的意思,从数据库方向说,相当于就是所有数据库的集合;
Schema是模式的意思, 从数据库方向说, 类似Catelog下的某一个数据库;
创建Dataset和Dataframe
通过SparkSession来创建Dataset和Dataframe有多种方法。
最简单的就是通过range()方法来创建dataset,通过createDataFrame()来创建dataframe。
//create a Dataset using spark.range starting from 5 to 100, with increments of 5
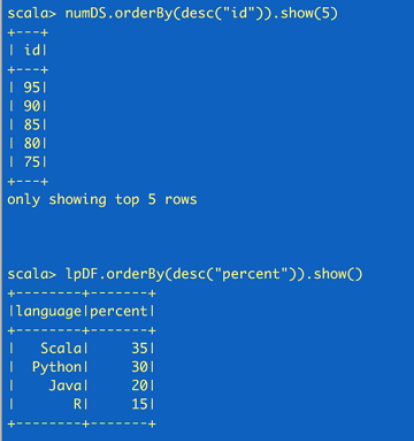
val numDS = spark.range(5, 100, 5)//创建dataset
// reverse the order and display first 5 items
numDS.orderBy(desc("id")).show(5)
//compute descriptive stats and display them
numDs.describe().show()
// create a DataFrame using spark.createDataFrame from a List or Seq
val langPercentDF = spark.createDataFrame(List(("Scala", 35), ("Python", 30), ("R", 15), ("Java", 20)))//创建dataframe
//rename the columns
val lpDF = langPercentDF.withColumnRenamed("_1", "language").withColumnRenamed("_2", "percent")
//order the DataFrame in descending order of percentage
lpDF.orderBy(desc("percent")).show(false)
读取数据
可以用SparkSession读取JSON、CSV、TXT和parquet表。
import spark.implicits //使RDD转化为DataFrame以及后续SQL操作 //读取JSON文件,生成DataFrame val jsonFile = args(0) val zipsDF = spark.read.json(jsonFile)
使用SparkSQL
借助SparkSession用户可以像SQLContext一样使用Spark SQL的全部功能。
zipsDF.createOrReplaceTempView("zips_table")//对上面的dataframe创建一个表
zipsDF.cache()//缓存表
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table")//对表调用SQL语句
resultsDF.show(10)//展示结果
存储/读取Hive表
下面的代码演示了通过SparkSession来创建Hive表并进行查询的方法。
//drop the table if exists to get around existing table error
spark.sql("DROP TABLE IF EXISTS zips_hive_table")
//save as a hive table
spark.table("zips_table").write.saveAsTable("zips_hive_table")
//make a similar query against the hive table
val resultsHiveDF = spark.sql("SELECT city, pop, state, zip FROM zips_hive_table WHERE pop > 40000")
resultsHiveDF.show(10)
下图是 SparkSession 的类和方法, 这些方法包含了创建 DataSet, DataFrame, Streaming 等等。
| Method | Description |
|---|---|
| builder | "Opens" a builder to get or create a SparkSession instance |
| version | Returns the current version of Spark. |
| implicits | Use import spark.implicits._ to import the implicits conversions and create Datasets from (almost arbitrary) Scala objects. |
| emptyDataset[T] | Creates an empty Dataset[T]. |
| range | Creates a Dataset[Long]. |
| sql | Executes a SQL query (and returns a DataFrame). |
| udf | Access to user-defined functions (UDFs). |
| table | Creates a DataFrame from a table. |
| catalog | Access to the catalog of the entities of structured queries |
| read | Access to DataFrameReader to read a DataFrame from external files and storage systems. |
| conf | Access to the current runtime configuration. |
| readStream | Access to DataStreamReader to read streaming datasets. |
| streams | Access to StreamingQueryManager to manage structured streaming queries. |
| newSession | Creates a new SparkSession. |
| stop | Stops the SparkSession. |
当我们使用Spark-Shell的时候,Spark会自动帮助我们建立好了一个名字为spark的SparkSesson和一个名字为sc的SparkContext。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号