
词云
中文词频统计
1. 下载白鹿原
2. 从文件读取待分析文本。
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
jieba.lcut(text)
4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word('天罡北斗阵') #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
参考词库下载地址:https://pinyin.sogou.com/dict/
转换代码:scel_to_text
5. 生成词频统计
6. 排序
7. 排除语法型词汇,代词、冠词、连词等停用词。
stops
tokens=[token for token in wordsls if token not in stops]
8. 输出词频最大TOP20,把结果存放到文件里
9. 生成词云。
代码如下:

import re # 正则表达式库
import collections # 词频统计库
import numpy as np # numpy数据处理库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
# 读取文件
fn = open("D:\\白鹿原 (1).txt",'rt',encoding='utf-8') # 打开文件
string_data = fn.read() # 读出整个文件
fn.close() # 关闭文件
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.lcut(string_data) # 精确模式分词
object_list = []
remove_words = [u'的', u',',u'和', u'是', u'随着', u'对于', u'对',u'等',u'能',u'都',\
u'。',u' ',u'、',u'中',u'在',u'了',u'通常',u'如果',u'我们',u'需要',\
u'…',u':',u'你',u'我',u'他',u'这',u'那',u'着',u'?',u'也',u'又',\
u';',u'!',u'”',u'“',u'说',u'就',u'上',u'把',u'到',u'不',u"她",u"人",u'里',u"去",u"给",u"地"
,u"一个",u"来",u"\u3000",u"得",u"从",u"有",u"被",u"再",u"走",u"还",u'下',u'要'] # 自定义去除词库
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
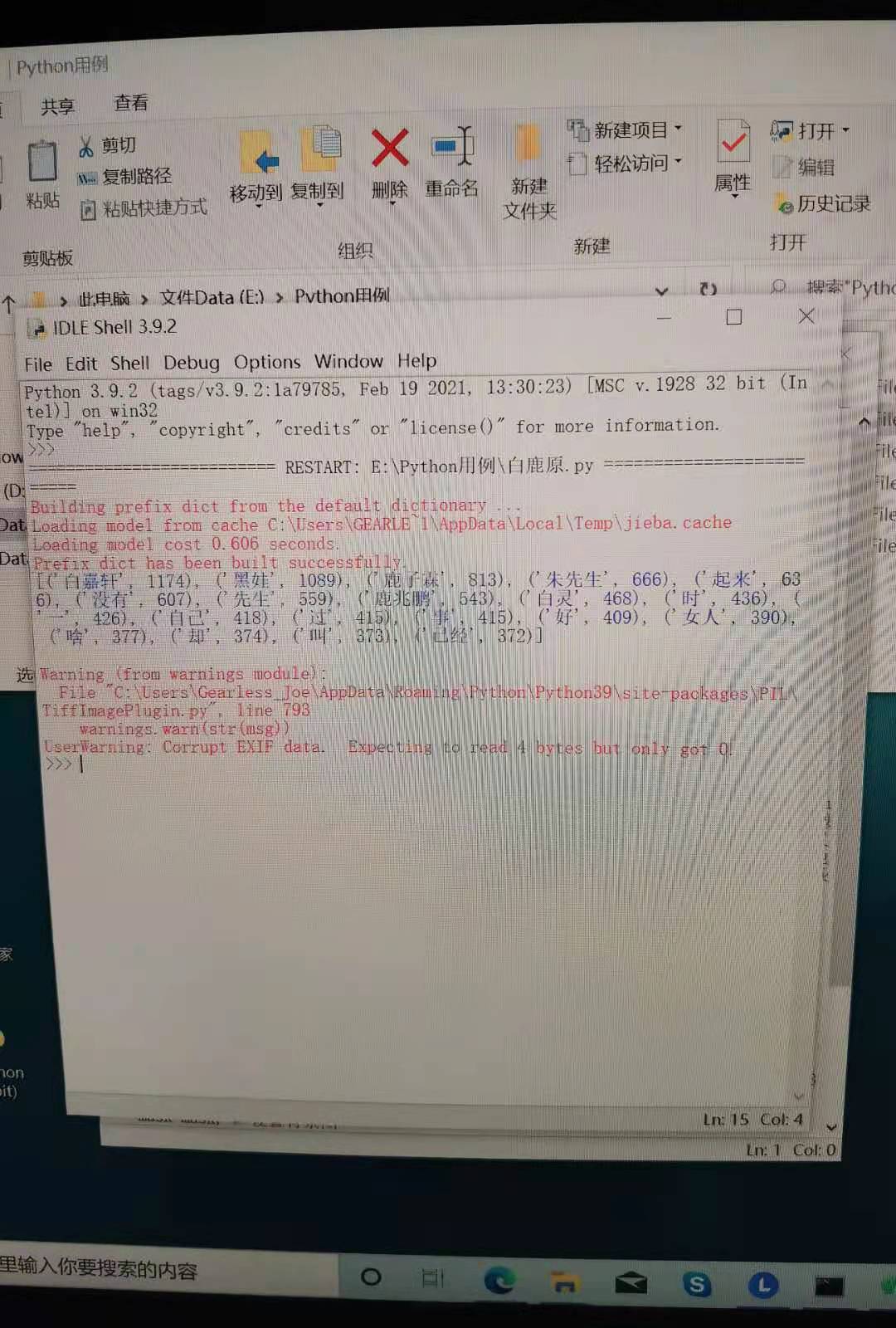
word_counts_top20 = word_counts.most_common(20) # 获取前20最高频的词
print (word_counts_top20) # 输出检查
# 词频展示
mask = np.array(Image.open('E:\\图片\\图片\\c771422e974dbd57c51ed6789a53bf65e8c30dee_raw.jpg'))
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=50, # 最多显示词数
max_font_size=500 # 字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
词频


 浙公网安备 33010602011771号
浙公网安备 33010602011771号