
vllm
!声明:本文部分框架及理论来自于 【大猿搬砖简记】 的公众号文章,但为了方便本人学习,进行了整理,同时在这个清晰的框架内添加了一些总结性质的内容,如需看原文请在其公众号中搜索:图解大模型计算加速系列。特此声明。
一、背景知识
LLM推理通常为两阶段: prefill 和 decode。
通常会使用KV cache技术加速推理。
1. 什么是KV cache?
KV Cache 通俗理解
-
Cache 缓存的原理是什么?
要多次使用的东西,暂存起来,下次直接快速拿过来使用就行了。(热水器) -
为何只对 Key 和 Value 使用 Cache?
因为只有 Key 和 Value 需要重复使用,Query 不需要重复使用。 -
是针对推理阶段的优化技术。
因为只有推理阶段才是一个个往外出字的
代码实现
🌴 1. use_cache = True 参数控制 past_key_values 表示 KV Cache
🌴 2. Huggingface Cache 类: https://huggingface.co/docs/transformers/en/kv_cache
🌴 3. 两个列表,每个列表分别存储每一层的 K 和 V 的 Cache,具体每一个值形状是:
[batch_size, num_heads, seq_len, head_dim]- 添加新 cache 值时,就在
seq_len这个维度上concat新的值
对 KV Cache 的总结:
- 以空间换时间加速优化
- 只在推理阶段使用,因为训练时是一起算的,不用一步一步算
- 只在 Decoder 结构中使用
- Encoder 中的 self-attention 是并行计算的,一次就算出了全部结果
- Decoder 中的 cross-attention 计算,其 Key 和 Value 是 Encoder 输出的结果,本来也缓存
- LLM 都是 Decoder-only 的结构,不涉及以上两种 Attention 的计算
2.1 Prefill
在这个阶段中,我们把整段prompt喂给模型做forward计算。如果采用KV cache技术,在这个阶段中我们会把prompt过后 \(W_k\), \(W_v\) 得到的 \(X_k\), \(X_v\) 保存在cache_k和cache_v中。这样在对后面的token计算attention时,我们就不需要对前面的token重复计算了,可以帮助我们节省推理时间。
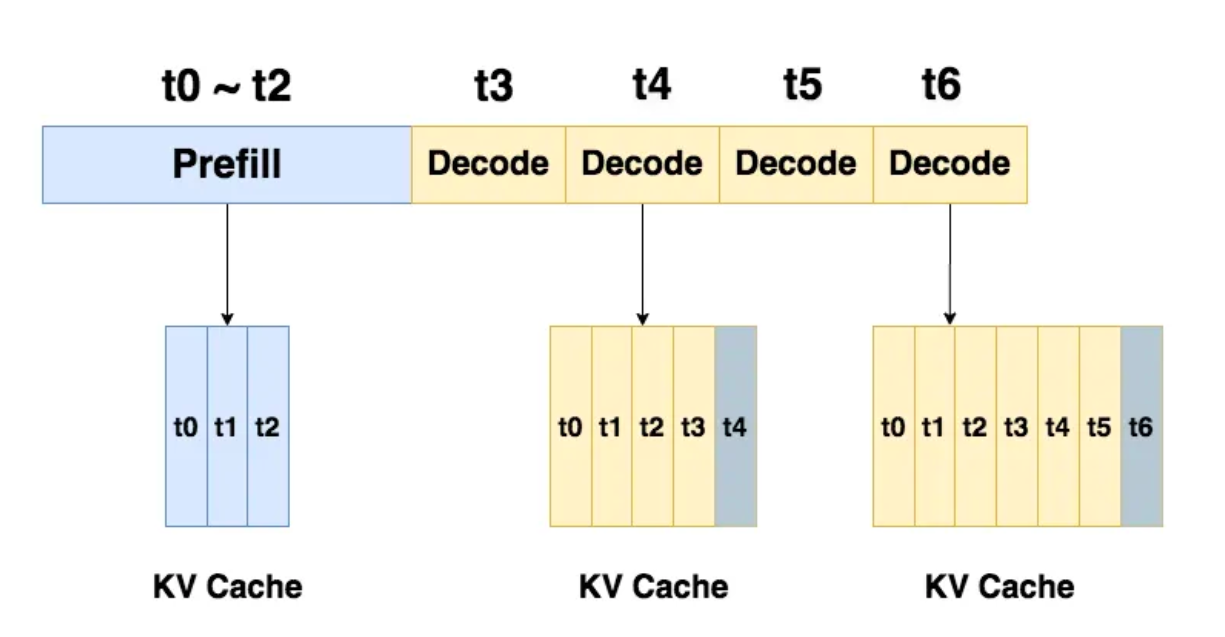
2.2 Decode
生成response的阶段。在这个阶段中,我们根据prompt的prefill结果,一个token一个token地生成response。
同样,如果采用了KV cache,则每走完一个decode过程,我们就把对应response token的KV值存入cache中,以便能加速计算。例如对于图中的t4,它与cache中t0~t3的KV值计算完attention后,就把自己的KV值也装进cache中。对t6也是同理。
由于Decode阶段的是逐一生成token的,因此它不能像prefill阶段那样能做大段prompt的并行计算,所以在LLM推理过程中,Decode阶段的耗时一般是更大的。
从上述过程中,我们可以发现使用KV cache做推理时的一些特点:
随着prompt数量变多和序列变长,KV cache也变大,对gpu显存造成压力
由于输出的序列长度无法预先知道,所以我们很难提前为KV cache量身定制存储空间。
下图展示了一个13B的模型在A100 40GB的gpu上做推理时的显存占用分配(others表示forward过程中产生的activation的大小,这些activation你可以认为是转瞬即逝的,即用完则废,因此它们占据的显存不大【激活值显存计算请参考我的这篇博客:显存计算指南 https://www.cnblogs.com/zz-w/p/18592076 】。
从这张图中我们可以直观感受到推理中KV cache对显存的占用。因此,如何优化KV cache,节省显存,提高推理吞吐量,就成了LLM推理框架需要解决的重点问题。

为KV cache分配存储空间的传统方法
对于训练好的模型,一种常用的部署方式是将其打包成一个推理服务(server),它接收客户端发送来的请求(request),读取请求中的数据(prompt)来做推理。一个请求中可以只有1个prompt,也可以包含多个prompt。
在常规的推理框架中,当我们的服务接收到一条请求时,它会为这条请求中的prompts分配gpu显存空间,其中就包括对KV cache的分配。由于推理所生成的序列长度大小是无法事先预知的,所以大部分框架会按照(batch_size, max_seq_len)这样的固定尺寸,在gpu显存上预先为一条请求开辟一块连续的矩形存储空间。
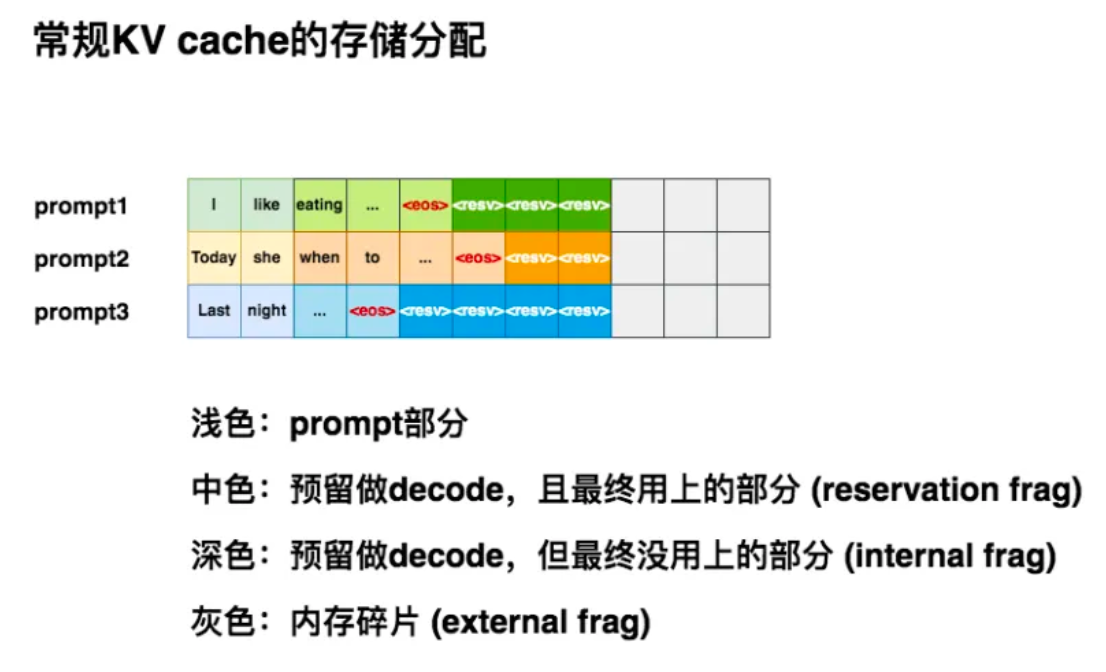
我们假设max_seq_len = 8,所以当第1条请求(prompt1)过来时,我们的推理框架为它安排了(1, 8)大小的连续存储空间。
当第2条请求(prompt2)过来时,同样也需要1块(1, 8)大小的存储空间。但此时prompt1所在的位置上,只剩3个空格子了,所以它只能另起一行做存储。对prompt3也是同理。
仔细观察这3条prompt的KV cache排布,你是不是隐约觉得这种排布似乎没有充分利用起gpu的显存?:
浅色块:观察图中的浅色块,它是prefill阶段prompt的KV cache,是无论如何都会被使用的空间,它不存在浪费。
中色块:观察图中的中色块,它是decode阶段的KV cache,其中
深色块:观察图中的深色块,它也是decode阶段的KV cache,但直到序列生成完毕,它都没有被用上。由于这些深色块是预留的KV cache的一部分,所以我们称其为内部碎片(internal fragment)。
灰色块:观察图中的灰色块,它不是我们预留的KV cache的一部分,且最终也没有被用上,我们称这些灰色块为外部碎片(external fragment)。想象一下,此时新来了一条prompt4,它也要求显存中的8个格子作为KV cache。此时你的显存上明明有9个空格子,但因为它们是不连续的碎片,所以无法被prompt4所使用。这时prompt4的这条请求只好在队列中等待,直到gpu上有足够显存资源时再进行推理,这不就对模型推理的吞吐量造成显著影响了吗?
总的来说,在大模型推理时,按照可生成最长序列长度分配显存:(利用率只有20%-40%)
造成三种类型的浪费:
- 预分配,但是不会用到:按照生成参数里设置的最大token数预分配,比如最大的token数量为1000,就设置为1000。但可能只生成到100个的时候就输出了终止符结束了,那么预分配的900个token就浪费了。
- 预分配被,但是尚未用到:即使一个样本真的可以输出1000个token,这是其他的请求也无法被响应,如果这个未被响应的有可能只需要输出10个token就结束了,就很不划算。
- 显存之间的间隔碎片,不足以预分配给下一个文本生成:当一个请求生成完毕,释放显存,但是如果下一个请求的prompt的长度大于释放的这个请求的prompt的长度,所以无法被放入被释放的缓存中,这种无法被使用的缓存就是碎片。
观察整个KV cache排布,你会发现它们的毛病在于太过“静态化”。当你无法预知序列大小时,你为什么一定要死板地为每个序列预留KV cache空间呢?为什么不能做得更动态化一些,即“用多少占多少”呢?这样我们就能减少上述这些存储碎片,使得每一时刻推理服务能处理的请求更多,提高吞吐量,这就是vLLM在做的核心事情,我们先通过一张实验图来感受下vLLM在显存利用上的改进效果(VS 其它推理框架):
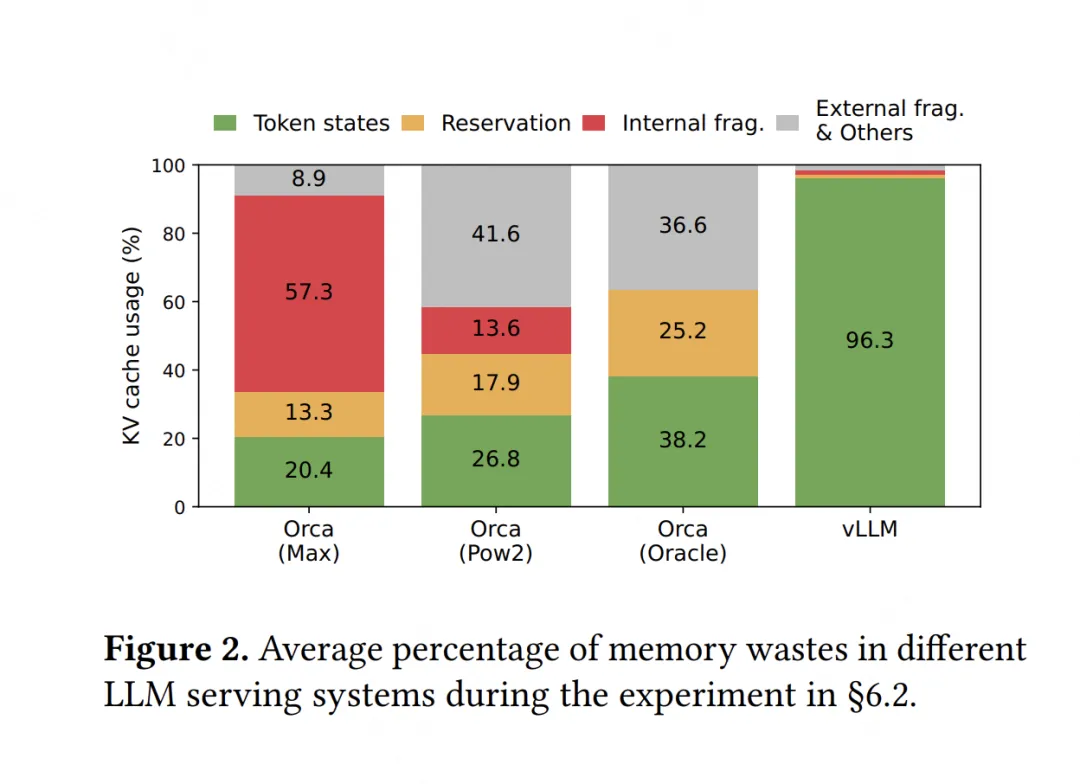
不难发现,相比于别的推理框架,vLLM几乎能做到将显存完全打满。
三、PagedAttention原理
PagedAttention的设计灵感来自操作系统中虚拟内存的分页管理技术。
3.1 操作系统的虚拟内存
3.2 PagedAttention
四、示例:PagedAttention在不同decoding场景下的运作流程和优势
4.1 Parallel Sampling
4.2 Beam Search
五、vLLM的调度与抢占
5.1 总原则
5.2 终止和恢复被抢占的请求
六、分布式管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号