
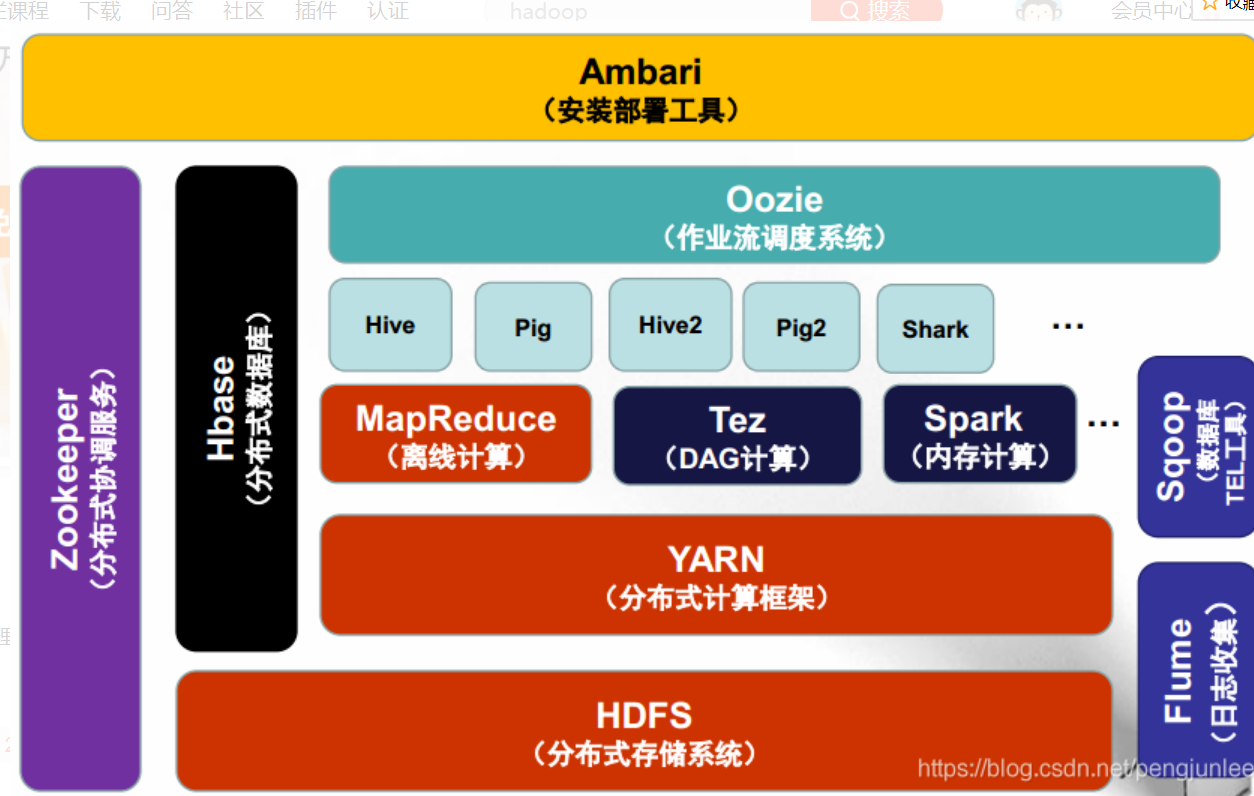
04 Hadoop思想与原理
Hadoop的起源
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它的关键技术和核心思想来源于 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
Google的几个核心思想:
大量使用廉价的普通PC服务器替代价格昂贵的超级计算机;
不使用存储(阿里的去IOE,去掉IBM的小型机、Oracle数据库、EMC存储设备);
提供冗余的高可靠集群服务;
TIPS:Google使用集装箱来搭建数据中心,每个集装箱中的服务器多达上千台,为了降低能源损耗每一个数据中心还可自带发电厂,想在哪里建立数据中心就将集装箱移动到哪里。
此外 Google 还有两个对网页检索与排序具有非常重要指导意义的算法:
倒排索引法----如何通过关键词检索出网页;
Page-Rank----如何给网页的价值评分,用于网页检索结果排序,是Google“在垃圾中找黄金”的关键算法;
Hadoop 1.0 VS 2.0
下图展示了Hadoop 1.0和2.0两个版本在架构设计上面的不同之处

在Hadoop 1.0时代,Map-Reduce是分布式计算框架唯一的选择。

到了Hadoop 2.0时代,由于YARN资源管理系统的出现,使得在Hadoop集群上可以同时运行多种计算框架,Map-Reduce,Spark,Strom,Tez等。
hadoop的发展
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
从Hadoop的发展历程来看,它的思想来自于google的三篇论文。
GFS:Google File System 分布式处理系统 ------》解决存储问题
Mapreduce:分布式计算模型 ------》对数据进行计算处理
BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间
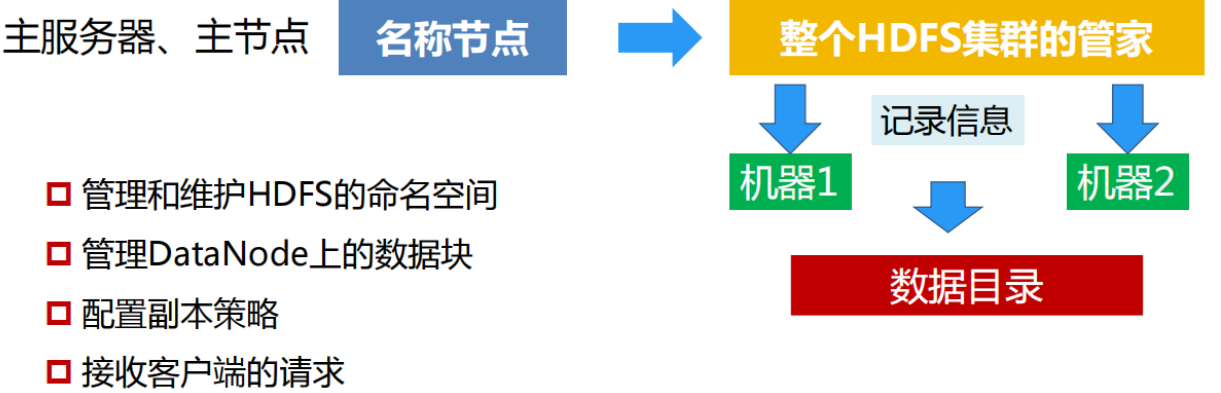
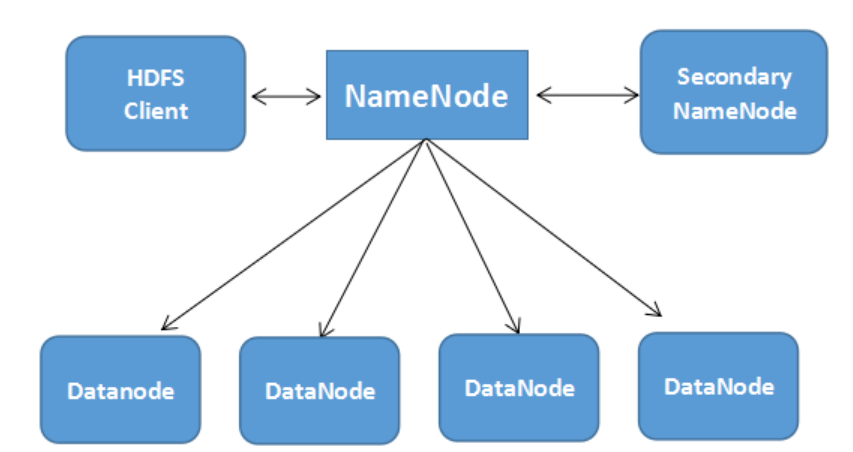
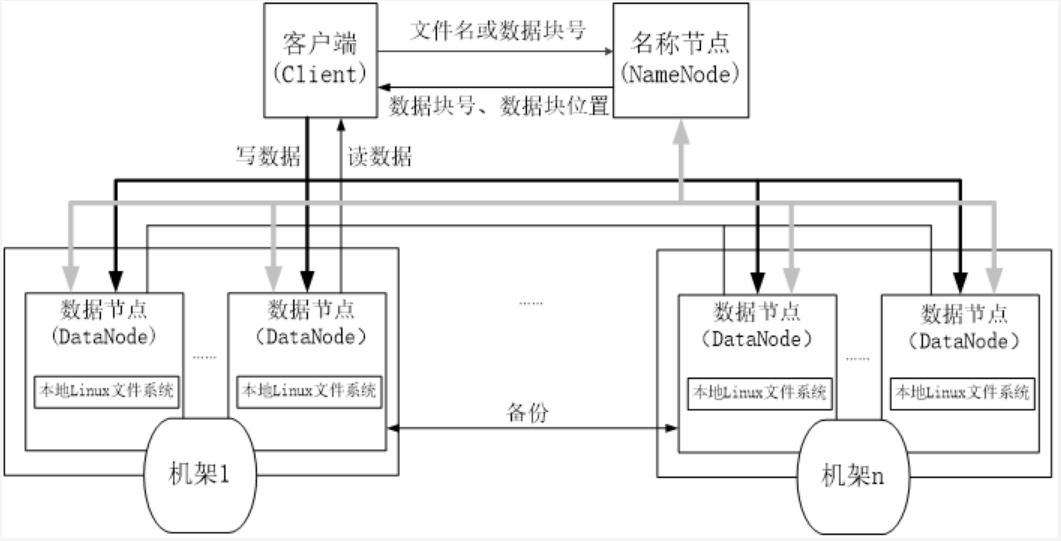
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
名称节点(Namenode)
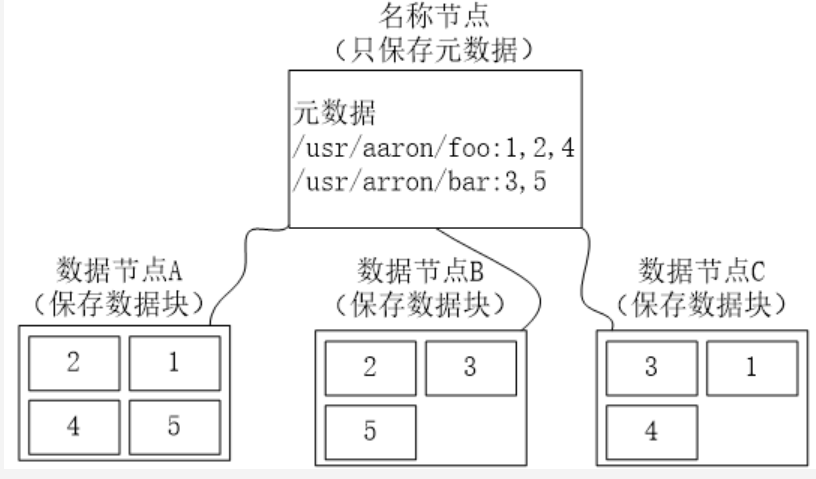
名称节点负责管理分布式文件系统系统的命名空间,记录分布式文件系统中的每个文件中各个块所在的数据节点的位置信息
第二名称节点(Secondary Namenode)
完成EditLog合并到FsImage的过程,缩短合并的重启时间,其次作为“检查点”保存元数据的信息。

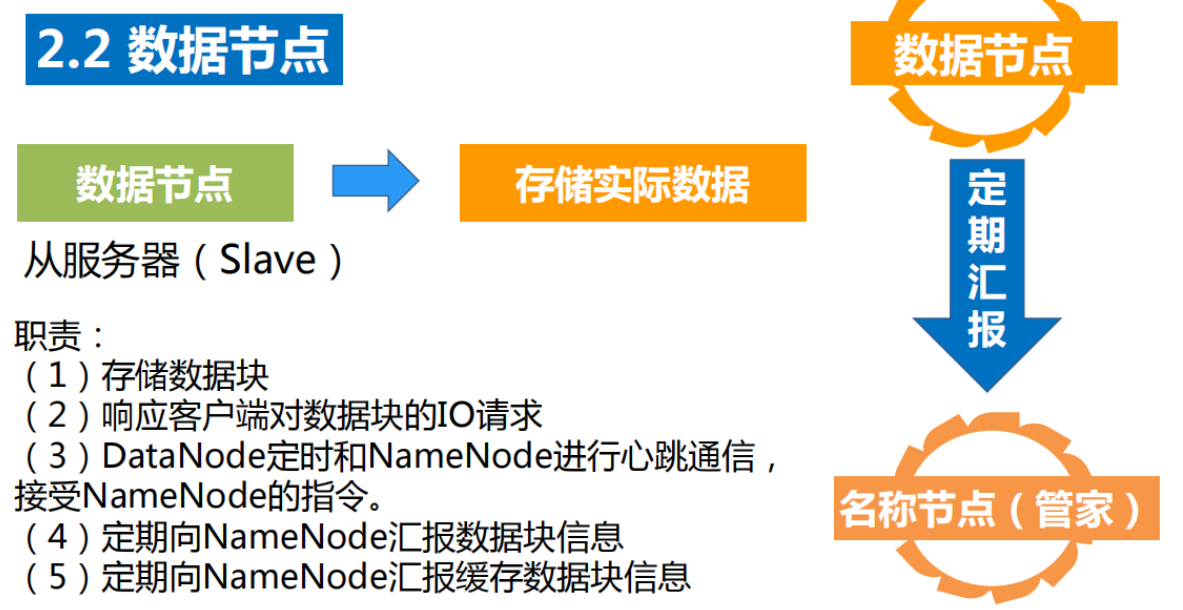
数据节点(Datanode)
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表。
三者之间的关系如下图
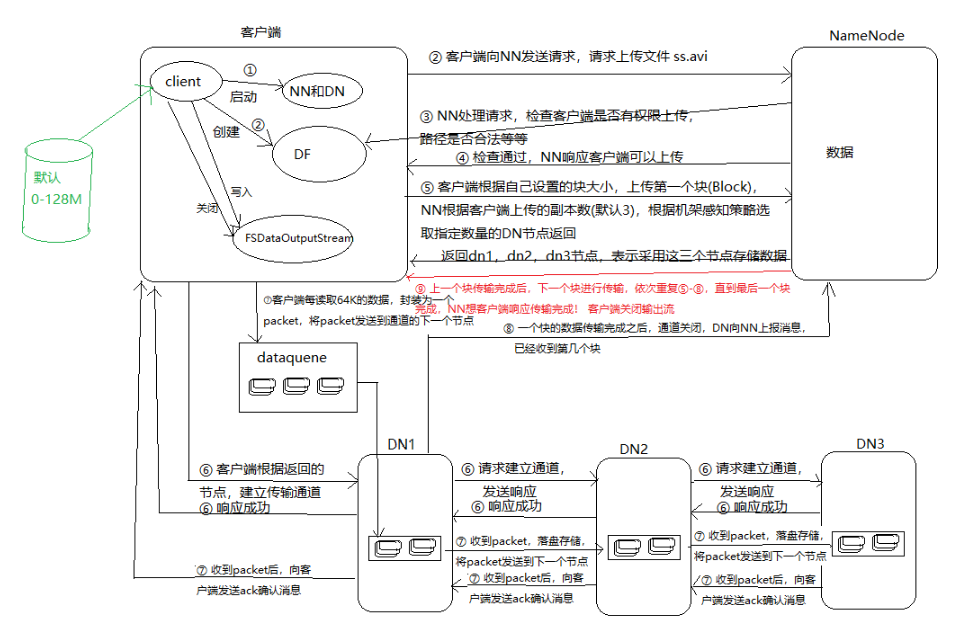
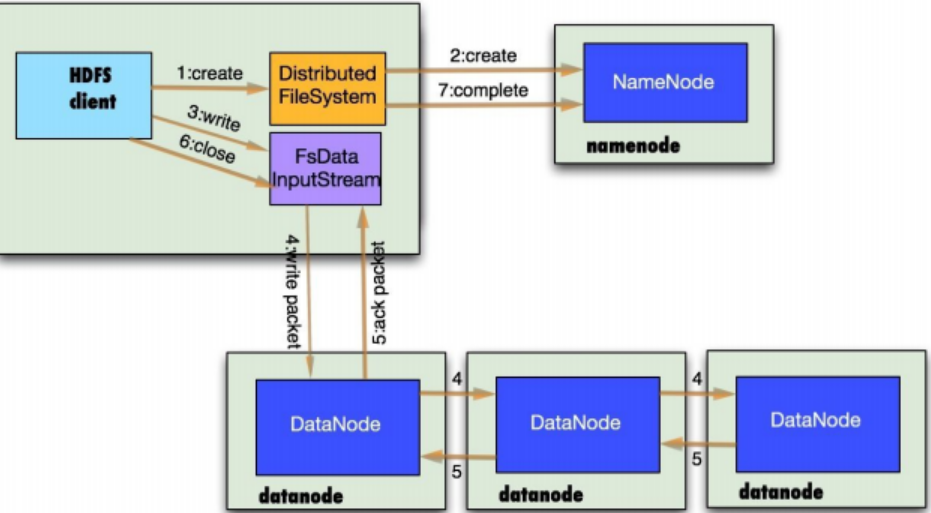
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
![]()
- 客户端读
- 客户端写
![]()
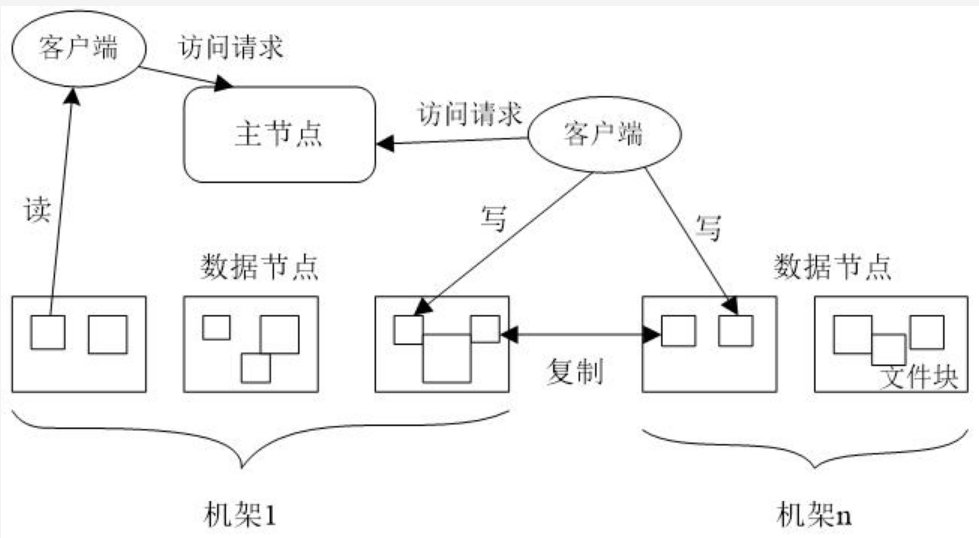
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
![]()
- 数据冗余
![]()
- 数据存取策略
- 数据错误与恢复
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。

Master主服务器的功能
1. 为Region server分配region
2. 负责region server的负载均衡
3. 发现失效的region server并重新分配其上的region
4. GFS上的垃圾文件回收
5. 处理schema更新请求
Region服务器的功能
1. Region server维护Master分配给它的region,处理对这些region的IO请求
2. Region server负责切分在运行过程中变得过大的region可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
Zookeeper协同的功能
1.Zookeeper 提供了 HBase Master 的高可用实现,并保证同一时刻有且仅有一个主 Master 可用。
2 .存贮所有Region的寻址入口。
3. 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4. 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Client客户端的请求流程
1. 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息
与HDFS的关联
HBase 是在 Hadoop 这种分布式框架中提供持久化的数据存储与管理的工具。在使用 HBase 的分布式集群模式时,前提是必须有 Hadoop 系统。
Hadoop 系统为 HBase 提供给了分布式文件存储系统,同时也使得 MapReduce 组件能够直接访问 HBase 进行分布式计算。
HBase 最重要的访问方式是 Java API(Application Programming Interface,应用程序编程接口),MapReduce 的批量操作方式并不常用。Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
5.理解并描述Hbase表与Region与HDFS的关系。
在Hbase中存在一张特殊的meta表,其中存放着HBase的元数据信息,包括,有哪些表,表有哪些HRegion,每个HRegion分布在哪个HRegionServer中。meta表很特殊,永远有且仅有一个HRegion存储meta表,这个HRegion存放在某一个HRegionServer中,并且会将这个持有meta表的Region的HRegionServer的地址存放在Zookeeper中meta-region-server下。
所以当在进行HBase表的读写操作时,需要先根据表名和行键确 定位到HRegion,这个过程就是HRegion的寻址过程。
HRgion的寻址过程首先由客户端开始,访问zookeeper 得到其中meta-region-server的值,根据该值找到唯一持有meta表的HRegion所在的HRegionServer,得到meta表,从中读取真正要查询的表和行键 对应的HRgion的地址,再根据该地址,找到真正的操作的HRegionServer和HRegion,完成HRgion的定位,继续读写操作。客户端会缓存之前已经查找过的HRegion的地址信息,之后的HRgion定位中,如果能在本地缓存中的找到地址,就直接使用该地址提升性能。
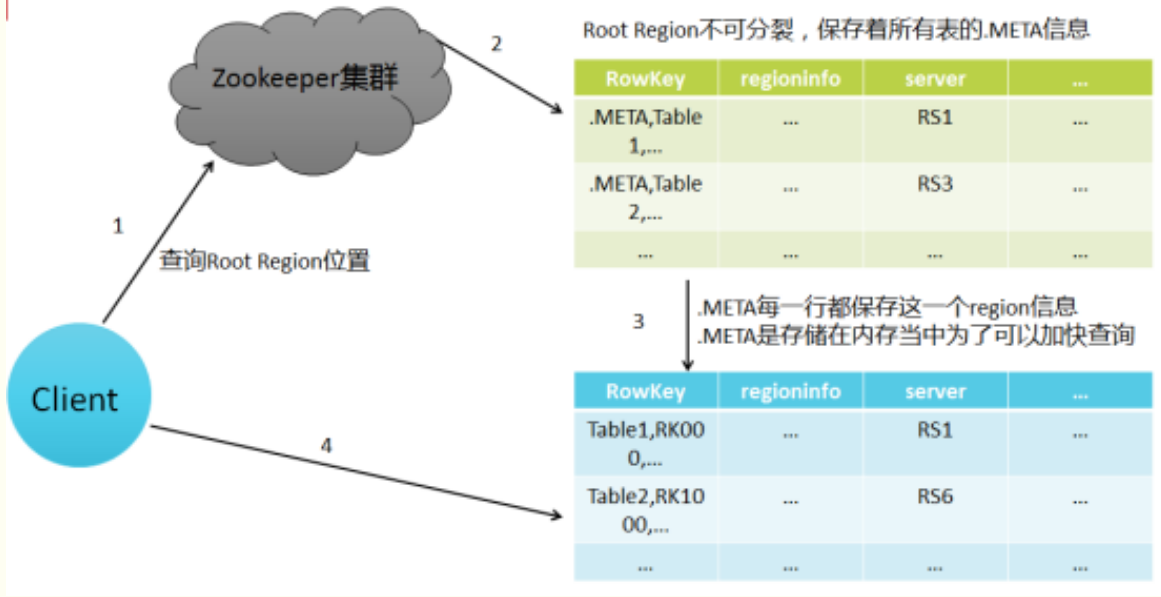
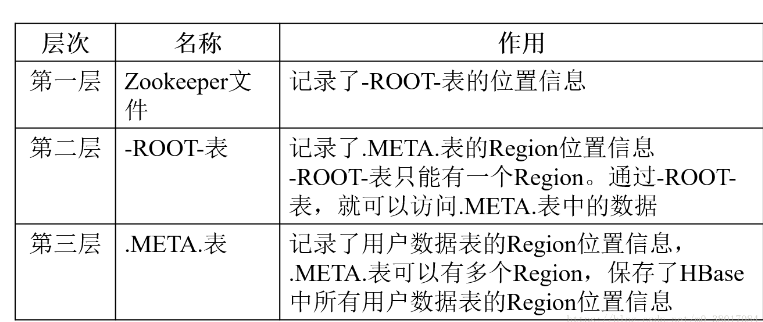
6.理解并描述Hbase的三级寻址。
Region标识符:表名+开始主键+RegionId
元数据表(又名.META.表),存储了Region和Region服务器的映射关系:Region标识符+Region服务器标识
当HBase表很大时, .META.表会被分裂成多个Region
根数据表(又名-ROOT-表),记录所有元数据(即Region和Region服务器的映射关系)的具体位置。-ROOT-表只有唯一一个Region,名字在程序中被写死,Master主服务器永远知道它的位置。Zookeeper文件记录了-ROOT-表的位置
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
一个-ROOT-表最多只能有一个Region,也就是最多只能有2GB,按照每行(一个映射条目)占用1KB内存计算,2GB空间可以容纳2GB/1KB=2的21次方行,也就是说,一个-ROOT-表可以寻址2的21次方个.META.表的Region。同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是2GB/1KB=2的21次方。最终,三层结构可以保存的Region数目是(2GB/1KB) × (2GB/1KB) = 2的42次方个Region
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
和HDFS一样,MapReduce也是採用Master/Slave的架构,其架构图例如以下所看到的。
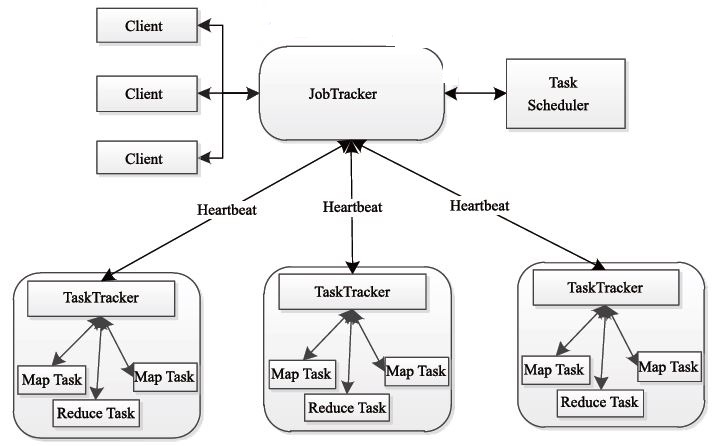
MapReduce包括四个组成部分,分别为Client、JobTracker、TaskTracker和Task,下面我们具体介绍这四个组成部分。
1)Client client
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置參数 Configuration 打包成 JAR 文件存储在 HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和 ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。
2)JobTracker
JobTracke负责资源监控和作业调度。
JobTracker 监控全部TaskTracker 与job的健康状况。一旦发现失败,就将相应的任务转移到其它节点。同一时候。JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空暇时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块。用户能够依据自己的须要设计相应的调度器。
3)TaskTracker
TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的执行进度汇报给JobTracker,同一时候接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
TaskTracker 使用“slot”等量划分本节点上的资源量。
“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会执行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空暇slot 分配给Task 使用。slot 分为Map slot 和Reduce slot 两种。分别供Map Task 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置參数)限定Task 的并发度。
4)Task
Task 分为Map Task 和Reduce Task 两种。均由TaskTracker 启动。HDFS 以固定大小的block 为基本单位存储数据。而对于MapReduce 而言,其处理单位是split。
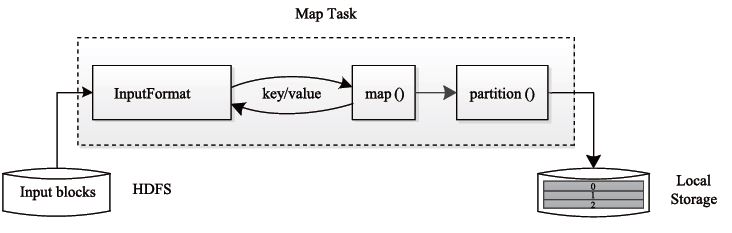
Map Task 执行步骤例如以下图 所看到的:由该图可知。Map Task 先将相应的split 迭代解析成一个个key/value 对,依次调用用户 自己定义的map() 函数进行处理。终于将暂时结果存放到本地磁盘上, 当中暂时数据被分成若干个partition。每一个partition 将被一个Reduce Task 处理。
Reduce Task 执行过程下图所看到的。该过程分为三个阶段:
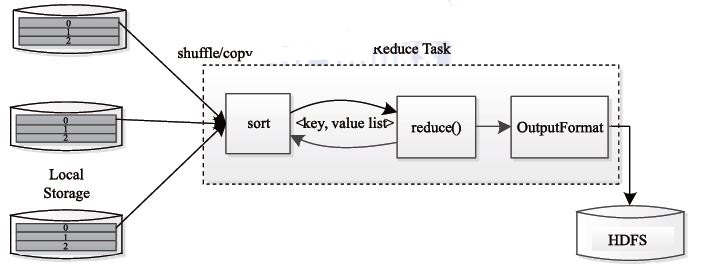
①从远程节点上读取Map Task 中间结果(称为“Shuffle 阶段”)。
②依照key 对key/value 对进行排序(称为“Sort 阶段”);
③依次读取< key, value list>,调用用户自己定义的reduce() 函数处理,并将终于结果存到HDFS 上(称为“Reduce 阶段”)。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号