

linux常用命令
linux常用命令
大牛笔记-www.weixuehao.com
来自:http://www.weixuehao.com/archives/25
Linux,免费开源,多用户多任务系统。基于Linux有多个版本的衍生。RedHat、Ubuntu、Debian
安装VMware或VirtualBox虚拟机。具体安装步骤,找百度。
再安装Ubuntu。具体安装步骤,找百度。
安装完后,可以看到Linux系统的目录结构,见链接http://www.cnblogs.com/laov/p/3409875.html
标准linux的目录结构http://www.cnblogs.com/laov/p/3409875.html
ls 显示文件或目录
-l 列出文件详细信息l(list)
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
mkdir 创建目录
-p 创建目录,若无父目录,则创建p(parent)
cd 切换目录
touch 创建空文件
echo 创建带有内容的文件。
cat 查看文件内容--例子:查找名称为zz.txt 的文件并输出内容:cat sudo find /-name "zz.txt"
cp 拷贝 --例子:cp zz.txt /home/zyy
mv 移动或重命名
rm 删除文件--例子:强制删除多级目录 rm -rf /home/zyy
-r 递归删除,可删除子目录及文件
-f 强制删除
find 在文件系统中搜索某文件--
例子:在某个目录下查找包含__AaBbCc_字符串的文件并打印出出特殊字符出现的行号
find 目录 -print|grep “*__AaBbCc_*”
例子:列出某个路径下的文件或者目录:查找t1路劲改下的文件:find t1/ -type f,查找t2路劲下的目录:find t2/ -type d
匹配a开头下的所有文件:find t1/ -name "a*"
查找1天前以aa开头的文件:find t1/ -type f/d -mtime+1 -name "aa*"
查找并删除30天前的文件或目录:find t1/ -mtime+30 [type f/d] -exec rm -rf {}\
例子2:查找当前路劲改下 .log文件包含error
find . -name "*.log"|grep "error"
wc 统计文本中行数、字数、字符数---将后缀为.log的日志文件行数追加到zz.txt 后:cat *.log |wc -l>>zz.txt
grep 在文本文件中查找某个字符串:查找进程中是否有tomcat在运行的命令:ps -ef|grep “tomcat”
rmdir 删除空目录
tree 树形结构显示目录,需要安装tree包
pwd 显示当前目录:
例子:从当前目录下查找所有扩展名为.log的文本文件,并找到包含error的行:
cat find 'pwd' -name "*.log"|grep "ERROR"
ln 创建链接文件
more、less 分页显示文本文件内容
head、tail 显示文件头、尾内容---实例:
sed --实例删除中间中hello的字符串 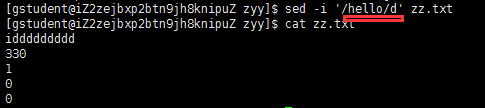
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。</p> <p>动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』</p> <p>function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
以行为单位的新增/删除
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~]# nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
.....(后面省略).....
sed 的动作为 '2,5d' ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行罗~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 '' 两个单引号括住喔!
只要删除第 2 行
nl /etc/passwd | sed '2d'
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@www ~]# nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
那如果是要在第二行前
nl /etc/passwd | sed '2i drink tea'
如果是要增加两行以上,在第二行后面加入两行字,例如『Drink tea or .....』与『drink beer?』
[root@www ~]# nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
每一行之间都必须要以反斜杠『 \ 』来进行新行的添加喔!所以,上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。
以行为单位的替换与显示
将第2-5行的内容取代成为『No 2-5 number』呢?
[root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
.....(后面省略).....
透过这个方法我们就能够将数据整行取代了!
仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~]# nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。
数据的搜寻并显示
搜索 /etc/passwd有root关键字的行
nl /etc/passwd | sed '/root/p'
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
....下面忽略
如果root找到,除了输出所有行,还会输出匹配行。
使用-n的时候将只打印包含模板的行。
nl /etc/passwd | sed -n '/root/p'
1 root:x:0:0:root:/root:/bin/bash
数据的搜寻并删除
删除/etc/passwd所有包含root的行,其他行输出
nl /etc/passwd | sed '/root/d'
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
3 bin:x:2:2:bin:/bin:/bin/sh
....下面忽略
#第一行的匹配root已经删除了
数据的搜寻并执行命令
找到匹配模式eastern的行后,
搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p}' 1 root:x:0:0:root:/root:/bin/blueshell
如果只替换/etc/passwd的第一个bash关键字为blueshell,就退出
nl /etc/passwd | sed -n '/bash/{s/bash/blueshell/;p;q}'
1 root:x:0:0:root:/root:/bin/blueshell
最后的q是退出。
数据的搜寻并替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代。基本上 sed 的搜寻与替代的与 vi 相当的类似!他有点像这样:
sed 's/要被取代的字串/新的字串/g'
先观察原始信息,利用 /sbin/ifconfig 查询 IP
[root@www ~]# /sbin/ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
.....(以下省略).....
本机的ip是192.168.1.100。
将 IP 前面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g'
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
接下来则是删除后续的部分,亦即: 192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
将 IP 后面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
192.168.1.100
多点编辑
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1 root:x:0:0:root:/root:/bin/blueshell
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
-e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。
直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试! 我们还是使用下载的 regular_express.txt 文件来测试看看吧!
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~]# sed -i 's/\.$/\!/g' regular_express.txt
利用 sed 直接在 regular_express.txt 最后一行加入『# This is a test』
[root@www ~]# sed -i '$a # This is a test' regular_express.txt
由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增『# This is a test』!
sed 的『 -i 』选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订!
流编辑器sed:
sed一次处理一行文件并把输出送往屏幕。sed把当前处理的行存储在临时缓冲区中,称为模式空间(pattern space)。一旦sed完成对模式空间中的行的处理,模式空间中的行就被送往屏幕。行被处理完成之后,就被移出模式空间,程序接着读入下一行,处理,显示,移出......文件输入的最后一行被处理完以后sed结束。通过存储每一行在临时缓冲区,然后在缓冲区中操作该行,保证了原始文件不会被破坏。
1. sed的命令和选项:
| 命令 | 功能描述 |
| a\ | 在当前行的后面加入一行或者文本。 |
| c\ | 用新的文本改变或者替代本行的文本。 |
| d | 从pattern space位置删除行。 |
| i\ | 在当前行的上面插入文本。 |
| h | 拷贝pattern space的内容到holding buffer(特殊缓冲区)。 |
| H | 追加pattern space的内容到holding buffer。 |
| g | 获得holding buffer中的内容,并替代当前pattern space中的文本。 |
| G | 获得holding buffer中的内容,并追加到当前pattern space的后面。 |
| n | 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 |
| p | 打印pattern space中的行。 |
| P | 打印pattern space中的第一行。 |
| q | 退出sed。 |
| w file | 写并追加pattern space到file的末尾。 |
| ! | 表示后面的命令对所有没有被选定的行发生作用。 |
| s/re/string | 用string替换正则表达式re。 |
| = | 打印当前行号码。 |
| 替换标记 | |
| g | 行内全面替换,如果没有g,只替换第一个匹配。 |
| p | 打印行。 |
| x | 互换pattern space和holding buffer中的文本。 |
| y | 把一个字符翻译为另一个字符(但是不能用于正则表达式)。 |
| 选项 | |
| -e | 允许多点编辑。 |
| -n | 取消默认输出。 |
需要说明的是,sed中的正则和grep的基本相同,完全可以参照本系列的第一篇中的详细说明。
2. sed实例:
/> cat testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
/> sed '/north/p' testfile #如果模板north被找到,sed除了打印所有行之外,还有打印匹配行。
northwest NW Charles Main 3.0 .98 3 34
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
#-n选项取消了sed的默认行为。在没有-n的时候,包含模板的行被打印两次,但是在使用-n的时候将只打印包含模板的行。
/> sed -n '/north/p' testfile
northwest NW Charles Main 3.0 .98 3 34
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
/> sed '3d' testfile #第三行被删除,其他行默认输出到屏幕。
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
/> sed '3,$d' testfile #从第三行删除到最后一行,其他行被打印。$表示最后一行。
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
/> sed '$d' testfile #删除最后一行,其他行打印。
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
/> sed '/north/d' testfile #删除所有包含north的行,其他行打印。
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
central CT Ann Stephens 5.7 .94 5 13
#s表示替换,g表示命令作用于整个当前行。如果该行存在多个west,都将被替换为north,如果没有g,则只是替换第一个匹配。
/> sed 's/west/north/g' testfile
northnorth NW Charles Main 3.0 .98 3 34
northern WE Sharon Gray 5.3 .97 5 23
southnorth SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
/> sed -n 's/^west/north/p' testfile #-n表示只打印匹配行,如果某一行的开头是west,则替换为north。
northern WE Sharon Gray 5.3 .97 5 23
#&符号表示替换字符串中被找到的部分。所有以两个数字结束的行,最后的数字都将被它们自己替换,同时追加.5。
/> sed 's/[0-9][0-9]$/&.5/' testfile
northwest NW Charles Main 3.0 .98 3 34.5
western WE Sharon Gray 5.3 .97 5 23.5
southwest SW Lewis Dalsass 2.7 .8 2 18.5
southern SO Suan Chin 5.1 .95 4 15.5
southeast SE Patricia Hemenway 4.0 .7 4 17.5
eastern EA TB Savage 4.4 .84 5 20.5
northeast NE AM Main Jr. 5.1 .94 3 13.5
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13.5
/> sed -n 's/Hemenway/Jones/gp' testfile #所有的Hemenway被替换为Jones。-n选项加p命令则表示只打印匹配行。
southeast SE Patricia Jones 4.0 .7 4 17
#模板Mar被包含在一对括号中,并在特殊的寄存器中保存为tag 1,它将在后面作为\1替换字符串,Margot被替换为Marlianne。
/> sed -n 's/MarMargot/\1lianne/p' testfile
north NO Marlianne Weber 4.5 .89 5 9
#s后面的字符一定是分隔搜索字符串和替换字符串的分隔符,默认为斜杠,但是在s命令使用的情况下可以改变。不论什么字符紧跟着s命令都认为是新的分隔符。这个技术在搜索含斜杠的模板时非常有用,例如搜索时间和路径的时候。
/> sed 's#3#88#g' testfile
northwest NW Charles Main 88.0 .98 88 884
western WE Sharon Gray 5.88 .97 5 288
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 88 188
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 188
#所有在模板west和east所确定的范围内的行都被打印,如果west出现在esst后面的行中,从west开始到下一个east,无论这个east出现在哪里,二者之间的行都被打印,即使从west开始到文件的末尾还没有出现east,那么从west到末尾的所有行都将打印。
/> sed -n '/west/,/east/p' testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
/> sed -n '5,/^northeast/p' testfile #打印从第五行开始到第一个以northeast开头的行之间的所有行。
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
#-e选项表示多点编辑。第一个编辑命令是删除第一到第三行。第二个编辑命令是用Jones替换Hemenway。
/> sed -e '1,3d' -e 's/Hemenway/Jones/' testfile
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Jones 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
/> sed -n '/north/w newfile' testfile #将所有匹配含有north的行写入newfile中。
/> cat newfile
northwest NW Charles Main 3.0 .98 3 34
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
/> sed '/eastern/i\ NEW ENGLAND REGION' testfile #i是插入命令,在匹配模式行前插入文本。
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
NEW ENGLAND REGION
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
#找到匹配模式eastern的行后,执行后面花括号中的一组命令,每个命令之间用逗号分隔,n表示定位到匹配行的下一行,s/AM/Archie/完成Archie到AM的替换,p和-n选项的合用,则只是打印作用到的行。
/> sed -n '/eastern/{n;s/AM/Archie/;p}' testfile
northeast NE Archie Main Jr. 5.1 .94 3 13
#-e表示多点编辑,第一个编辑命令y将前三行中的所有小写字母替换为大写字母,-n表示不显示替换后的输出,第二个编辑命令将只是打印输出转换后的前三行。注意y不能用于正则。
/> sed -n -e '1,3y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/' -e '1,3p' testfile
NORTHWEST NW CHARLES MAIN 3.0 .98 3 34
WESTERN WE SHARON GRAY 5.3 .97 5 23
SOUTHWEST SW LEWIS DALSASS 2.7 .8 2 18
/> sed '2q' testfile #打印完第二行后退出。
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
#当模板Lewis在某一行被匹配,替换命令首先将Lewis替换为Joseph,然后再用q退出sed。
/> sed '/Lewis/{s/Lewis/Joseph/;q;}' testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Joseph Dalsass 2.7 .8 2 18
#在sed处理文件的时候,每一行都被保存在pattern space的临时缓冲区中。除非行被删除或者输出被取消,否则所有被处理过的行都将打印在屏幕上。接着pattern space被清空,并存入新的一行等待处理。在下面的例子中,包含模板的northeast行被找到,并被放入pattern space中,h命令将其复制并存入一个称为holding buffer的特殊缓冲区内。在第二个sed编辑命令中,当达到最后一行后,G命令告诉sed从holding buffer中取得该行,然后把它放回到pattern space中,且追加到现在已经存在于模式空间的行的末尾。
/> sed -e '/northeast/h' -e '$G' testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
northeast NE AM Main Jr. 5.1 .94 3 13
#如果模板WE在某一行被匹配,h命令将使得该行从pattern space中复制到holding buffer中,d命令在将该行删除,因此WE匹配行没有在原来的位置被输出。第二个命令搜索CT,一旦被找到,G命令将从holding buffer中取回行,并追加到当前pattern space的行末尾。简单的说,WE所在的行被移动并追加到包含CT行的后面。
/> sed -e '/WE/{h;d;}' -e '/CT/{G;}' testfile
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
western WE Sharon Gray 5.3 .97 5 23
#第一个命令将匹配northeast的行从pattern space复制到holding buffer,第二个命令在读取的文件的末尾时,g命令告诉sed从holding buffer中取得行,并把它放回到pattern space中,以替换已经存在于pattern space中的。简单说就是包含模板northeast的行被复制并覆盖了文件的末尾行。
/> sed -e '/northeast/h' -e '$g' testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
northeast NE AM Main Jr. 5.1 .94 3 13
#模板WE匹配的行被h命令复制到holding buffer,再被d命令删除。结果可以看出WE的原有位置没有输出。第二个编辑命令将找到匹配CT的行,g命令将取得holding buffer中的行,并覆盖当前pattern space中的行,即匹配CT的行。简单的说,任何包含模板northeast的行都将被复制,并覆盖包含CT的行。
/> sed -e '/WE/{h;d;}' -e '/CT/{g;}' testfile
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
western WE Sharon Gray 5.3 .97 5 23
#第一个编辑中的h命令将匹配Patricia的行复制到holding buffer中,第二个编辑中的x命令,会将holding buffer中的文本考虑到pattern space中,而pattern space中的文本被复制到holding buffer中。因此在打印匹配Margot行的地方打印了holding buffer中的文本,即第一个命令中匹配Patricia的行文本,第三个编辑命令会将交互后的holding buffer中的文本在最后一行的后面打印出来。
/> sed -e '/Patricia/h' -e '/Margot/x' -e '$G' testfile
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
southeast SE Patricia Hemenway 4.0 .7 4 17
central CT Ann Stephens 5.7 .94 5 13
太长了,这里在项目上我主要使用sed -i命令进行替换,命令如下
行首替换 sed -i 's/^/替换的字符串/g' 文件名
行尾替换 sed -i 's/$/替换的字符串/g' 文件名
这里有时候进行行尾替换时,会自动加上^M,其实就是换行,在Windows下是\r\n,在Linux下是\n
所以在进行行尾替换的时候还需要加上一句 sed -i 's/^M//g' 文件名
这里需要注意的一个地方是,如何输入^M,在Linux命令行模式下是Ctrl+V+M三个一起按,但是Linux得vim里用这种方法无法实现,这里采用一个折中的方法。
在Windows的gVim下,插入模式中可以使用Ctrl+Q然后再Ctrl+M,这里可以先把.sh文件在Windows下的gVim里改好,再传到Linux上即可。
实例:
查看实时更新的日志
1、先切换到:cd usr/local/tomcat5/logs
2、tail -f catalina.out
3、这样运行时就可以实时查看运行日志了
Ctrl+c 是退出tail命令。
顺便讲一下linux中tail命令
tail 命令从指定点开始将文件写到标准输出.使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f filename会把filename里最尾部的内容显示在屏幕上,并且不但刷新,使你看到最新的文件内容.
1.命令格式;
tail[必要参数][选择参数][文件]
2.命令功能:
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
3.命令参数:
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
4.使用实例:
实例1:显示文件末尾内容
命令:
tail -n 5 log2014.log
输出:
[root@localhost test]# tail -n 5 log2014.log
某个目录下查找文件里的第十行 有些特殊的字符error
head -10 路径/zz.txt|tail -1|grep "error" 第10行的包含“error”

ctrl+alt+F1 命令行全屏模式
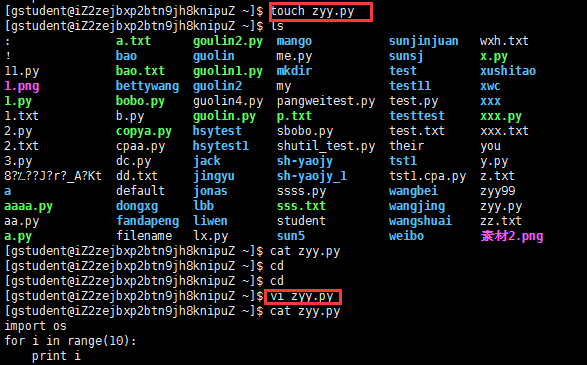
应用实例:创建一个.py 文件 touch zyy.py
第二步:输入vi zyy.py 进入该文件的编辑模式 输入i 进入插入模式,然后录入内容后,输入:wq!
第三步:cat zyy.py 可以查看zyy.py的内容
第一步:创建一个空文件: touch zyy1.py
第二步:向文件里写入内容:echo "print "helloworld"">>zyy1.py
或者
运行.py文件:python
ps命令常用方法
-
在日常生活中使用较多的ps命令的例子。
1. 不加参数执行ps命令
这是一个基本的 ps 使用。在控制台中执行这个命令并查看结果。
-
结果默认会显示4列信息。
PID: 运行着的命令(CMD)的进程编号 TTY: 命令所运行的位置(终端) TIME: 运行着的该命令所占用的CPU处理时间 CMD: 该进程所运行的命令
这些信息在显示时未排序。2. 显示所有当前进程
使用 -a 参数。-a 代表 all。同时加上x参数会显示没有控制终端的进程。
$ ps -ax
这个命令的结果或许会很长。为了便于查看,可以结合less命令和管道来使用。
$ ps -ax | less
-
3. 根据用户过滤进程
在需要查看特定用户进程的情况下,我们可以使用 -u 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令:
$ ps -u pungki
-
4. 通过cpu和内存使用来过滤进程
也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 aux 参数,来显示全面的信息:
$ ps -aux | less
-
当结果很长时,我们可以使用管道和less命令来筛选。
默认的结果集是未排好序的。可以通过 --sort命令来排序。
根据 CPU 使用来升序排序
$ ps -aux --sort -pcpu | less
-
根据 内存使用 来升序排序
$ ps -aux --sort -pmem | less
-
我们也可以将它们合并到一个命令,并通过管道显示前10个结果:
$ ps -aux --sort -pcpu,+pmem | head -n 10
5. 通过进程名和PID过滤
使用 -C 参数,后面跟你要找的进程的名字。比如想显示一个名为getty的进程的信息,就可以使用下面的命令:
$ ps -C getty
-
如果想要看到更多的细节,我们可以使用-f参数来查看格式化的信息列表:
$ ps -f -C getty
-
6. 根据线程来过滤进程
如果我们想知道特定进程的线程,可以使用-L 参数,后面加上特定的PID。
$ ps -L 1213
-
7. 树形显示进程
有时候我们希望以树形结构显示进程,可以使用 -axjf 参数。
$ps -axjf
-
或者可以使用另一个命令。
$ pstree
-
8. 显示安全信息
如果想要查看现在有谁登入了你的服务器。可以使用ps命令加上相关参数:
$ ps -eo pid,user,args
参数 -e 显示所有进程信息,-o 参数控制输出。Pid,User 和 Args参数显示PID,运行应用的用户和该应用。
-
能够与-e 参数 一起使用的关键字是args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart 和 start。9. 格式化输出root用户(真实的或有效的UID)创建的进程
系统管理员想要查看由root用户运行的进程和这个进程的其他相关信息时,可以通过下面的命令:
$ ps -U root -u root u
-U 参数按真实用户ID(RUID)筛选进程,它会从用户列表中选择真实用户名或 ID。真实用户即实际创建该进程的用户。
-u 参数用来筛选有效用户ID(EUID)。
最后的u参数用来决定以针对用户的格式输出,由User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME 和 COMMAND这几列组成。
这里有上面的命令的输出结果:
-
10. 使用PS实时监控进程状态
ps 命令会显示你系统当前的进程状态,但是这个结果是静态的。
当有一种情况,我们需要像上面第四点中提到的通过CPU和内存的使用率来筛选进程,并且我们希望结果能够每秒刷新一次。为此,我们可以将ps命令和watch命令结合起来。
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
-
如果输出太长,我们也可以限制它,比如前20条,我们可以使用head命令来做到。
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
-
这里的动态查看并不像top或者htop命令一样。但是使用ps的好处是你能够定义显示的字段,你能够选择你想查看的字段。
举个例子,如果你只需要看名为'pungki'用户的信息,你可以使用下面的命令:
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
-
结论
你也许每天都会使用ps命令来监控你的Linux系统。但是事实上,你可以通过ps命令的参数来生成各种你需要的报表。
例子:查看进程状态:ps -ef e代表全部 f代表全格式,不会裁剪
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户 --应用:
例子:上一次开机时间
开机时自动记录开机时间到history.txt里:
1.tail -f /proc/uptime>>/opt/history.txt
2.who -b>>/opt/history.txt 记录上一次开机时间
last rebootwho -buptime
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态 ps -aux
du 查看目录大小 du -h /home带有单位显示目录信息
df 查看磁盘大小 df -h 带有单位如G易于识别磁盘大小显示磁盘信息
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息 ---查看端口号netstat -tnl
man 命令 如:man ls 查看命令的使用方法
clear 清屏
alias 对命令重命名 如:alias showmeit="ps -aux" ,另外解除使用unaliax showmeit
kill 杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程。
gzip:
bzip2:
tar: 打包压缩
-c 归档文件
-x 压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示压缩或解压缩过程 v(view)
-f 使用档名
例:
tar -cvf /home/abc.tar /home/abc 只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc 打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc 打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了。
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机
halt 关机
reboot 重启
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
例:grep -r "close" /home/* | more 在home目录下所有文件中查找,包括close的文件,并分页输出。
dpkg (Debian Package)管理工具,软件包名以.deb后缀。这种方法适合系统不能联网的情况下。
比如安装tree命令的安装包,先将tree.deb传到Linux系统中。再使用如下命令安装。
sudo dpkg -i tree_1.5.3-1_i386.deb 安装软件
sudo dpkg -r tree 卸载软件
注:将tree.deb传到Linux系统中,有多种方式。VMwareTool,使用挂载方式;使用winSCP工具等;
APT(Advanced Packaging Tool)高级软件工具。这种方法适合系统能够连接互联网的情况。
依然以tree为例
sudo apt-get install tree 安装tree
sudo apt-get remove tree 卸载tree
sudo apt-get update 更新软件
sudo apt-get upgrade
将.rpm文件转为.deb文件
.rpm为RedHat使用的软件格式。在Ubuntu下不能直接使用,所以需要转换一下。
sudo alien abc.rpm
vim三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
/etc/passwd 存储用户账号
/etc/group 存储组账号
/etc/shadow 存储用户账号的密码
/etc/gshadow 存储用户组账号的密码
useradd 用户名
userdel 用户名
adduser 用户名
groupadd 组名
groupdel 组名
passwd root 给root设置密码
su root
su - root
/etc/profile 系统环境变量
bash_profile 用户环境变量
.bashrc 用户环境变量
su user 切换用户,加载配置文件.bashrc
su - user 切换用户,加载配置文件/etc/profile ,加载bash_profile
实例:切换用户
su是在用户间切换,可以是从普通用户切换到root用户,也可以是从root用户切换到普通用户。如果当前是root用户,那么切换成普通用户test用以下命令:
su - test
如果要切换回root用户,那么用以下命令:
su或su -
用户名root可以省略不写。
切换回root用户时要输入root密码。一般直接输入exit命令来切换回root用户,这样就不用输入密码。
更改文件的用户及用户组
sudo chown [-R] owner[:group] {File|Directory}
例如:还以jdk-7u21-linux-i586.tar.gz为例。属于用户hadoop,组hadoop
要想切换此文件所属的用户及组。可以使用命令。
sudo chown root:root jdk-7u21-linux-i586.tar.gz
用户类型主要是分为三类:
第一类:root(超级管理员),UID为0,这个用户有极大的权限,可以直接无视很多的限制,包括读写执行的权限。所以这个用户的使用要小心,因为他的权限太大了。
第二类:系统用户,UID为1~499。一般是不会被登入的。
第三类就是普通用户,UID范围一般是500~65534。这类用户的权限会受到基本权限的限制,也会受到来自管理员的限制。不过要注意nobody这个特殊的帐号,UID为65534,这个用户的权限会进一步的受到限制,一般用于实现来宾帐号。
实例:获取root权限
方法一:可以通过su命令切换到root用户来运行命令。需要输入root用户的密码。
用法示例:切换到root用户
$ su
方法二:使用sudo命令,针对单个命令授予临时权限。sudo仅在需要时授予用户权限,减少了用户因为错误执行命令损坏系统的可能性。sudo也可以用来以其他用户身份执行命令。
用法示例:以root用户的身份修改主机名为zhidao
$ sudo hostname zhidao
方法三:为root用户设置密码,然后使用root用户登录。
用法示例:为root用户设置密码。
$ passwd root
由于安全机制,输入的密码不会显示出来。
三种基本权限
R 读 数值表示为4
W 写 数值表示为2
X 可执行 数值表示为1

如图所示,jdk-7u21-linux-i586.tar.gz文件的权限为-rw-rw-r--
-rw-rw-r--一共十个字符,分成四段。
第一个字符“-”表示普通文件;这个位置还可能会出现“l”链接;“d”表示目录
第二三四个字符“rw-”表示当前所属用户的权限。 所以用数值表示为4+2=6
第五六七个字符“rw-”表示当前所属组的权限。 所以用数值表示为4+2=6
第八九十个字符“r--”表示其他用户权限。 所以用数值表示为2
所以操作此文件的权限用数值表示为662
更改权限
sudo chmod [u所属用户 g所属组 o其他用户 a所有用户] [+增加权限 -减少权限] [r w x] 目录名
例如:有一个文件filename,权限为“-rw-r----x” ,将权限值改为"-rwxrw-r-x",用数值表示为765
sudo chmod u+x g+w o+r filename
上面的例子可以用数值表示
sudo chmod 765 filename
http://www.daniubiji.cn/archives/25
常用的linux文件权限:
444 r--r--r--
600 rw-------
644 rw-r--r--
666 rw-rw-rw-
700 rwx------
744 rwxr--r--r
755 rwxr-xr-xr
777 rwxrwxrwx
从左至右,
1-3位数字代表文件所有者的权限,
4-6位数字代表同组用户的权限,
7-9数字代表其他用户的权限。
而具体的权限是由数字来表示的,读取的权限等于4,用r表示;
写入的权限等于2,用w表示;
执行的权限等于1,用x表示;
通过4、2、1的组合,
得到以下几种权限:
0(没有权限);
4(读取权限);
5(4+1 | 读取+执行);
6(4+2 | 读取+写入);
7(4+2+1 | 读取+写入+执行)
文件权限,实例:
以755为例:1-3位7等于4+2+1,rwx,所有者具有读取、写入、执行权限;4-6位5等于4+1+0,r-x,同组用户具有读取、执行权限但没有写入权限;7-9位5,同上,也是r-x,其他用户具有读取、执行权限但没有写入权限。
rwx权限数字解释 chmod也可以用数字来表示权限
如 chmod 777 file语法为:chmod abc file其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。
r=4,w=2,x=1若要rwx属性则4+2+1=7;
若要rw-属性则4+2=6;
若要r-x属性则4+2+1=7。
范例:chmod a=rwx file 和chmod 777 file 效果相同
chmod ug=rwx,o=x file 和chmod 771 file 效果相同
若用chmod 4755 filename可使此程序具有root的权限

 浙公网安备 33010602011771号
浙公网安备 33010602011771号