

数据采集作业4
作业①
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
代码和结果
核心代码
目标爬取三个板块的股票数据,我们可以发现这三个板块分别都有自己的url,我们就采取url作为我们的爬取来源
点击查看代码
TARGET_BOARDS = [
("沪深京A股", "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"),
("上证A股", "http://quote.eastmoney.com/center/gridlist.html#sh_a_board"),
("深证A股", "http://quote.eastmoney.com/center/gridlist.html#sz_a_board")
]
就按源表的顺序按序提取各列对应数据,一开始一直爬取不出成交量和成交额两列的数据,检查发现是因为数据类型的问题,原数据中有中文万和亿,要先进行一下转换再提取
点击查看代码
def crawl_board(driver, board_name, board_url):
"""爬取单个板块 """
print(f"\n 爬取【{board_name}】")
all_data = []
page = 1
driver.get(board_url)
time.sleep(8) # 基础加载时间
while page <= MAX_PAGES:
# 定位所有数据行
rows = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.XPATH, "//tbody/tr"))
)
print(f"第{page}页:{len(rows)}条数据")
# 提取数据
for row in rows:
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) < 14:
continue
def safe_convert(val, dtype):
if not val:
return None
try:
val_str = str(val)
if "亿" in val_str:
num = float(val_str.replace("亿", "")) * 100000000 # 1亿 = 10^8
elif "万" in val_str:
num = float(val_str.replace("万", "")) * 10000 # 1万 = 10^4
else:
num = val
# 按目标类型转换(成交量int,成交额float)
return dtype(num)
except:
return None
# 提取并转换数据
stock_code = clean_value(cols[1].text)
stock_name = clean_value(cols[2].text)
volume = safe_convert(clean_value(cols[7].text), int) # 成交量
turnover = safe_convert(clean_value(cols[8].text), float) # 成交额
all_data.append((
stock_code, # 1:股票代码
stock_name, # 2:股票名称
safe_convert(clean_value(cols[4].text), float), # 4:最新价
safe_convert(clean_value(cols[5].text), float), # 5:涨跌幅
safe_convert(clean_value(cols[6].text), float), # 6:涨跌额
volume, # 7:成交量
turnover, # 8:成交额
safe_convert(clean_value(cols[9].text), float), # 9:振幅
safe_convert(clean_value(cols[10].text), float), # 10:最高价
safe_convert(clean_value(cols[11].text), float), # 11:最低价
safe_convert(clean_value(cols[12].text), float), # 12:今开
safe_convert(clean_value(cols[13].text), float) # 13:昨收
))
点击查看代码
# 翻页
if page < MAX_PAGES:
next_btn = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//div[contains(@class, 'pager')]//a[text()='>']"))#定位翻页按钮
)
driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", next_btn)
time.sleep(1)
next_btn.click()
print(f"翻页到第{page+1}页...")
page += 1
time.sleep(random.uniform(3, 4))
else:
break
print(f"【{board_name}】共爬取{len(all_data)}条数据")
return all_data
点击查看代码
def clean_value(text):
"""数据清洗:去除空格、逗号、百分号"""
return text.strip().replace(",", "").replace("%", "") if text.strip() else None
点击查看代码
def init_db():
"""初始化数据库"""
conn = sqlite3.connect(DB_FILE)
cursor = conn.cursor()
cursor.execute(f"""CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
bStockNo TEXT NOT NULL,
stockName TEXT NOT NULL,
latestPrice REAL,
priceChangeRate REAL,
priceChangeAmount REAL,
volume INTEGER,
turnover REAL,
amplitude REAL,
highestPrice REAL,
lowestPrice REAL,
todayOpen REAL,
yesterdayClose REAL,
crawlTime TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);""")
conn.commit()
conn.close()
print("数据库初始化完成")
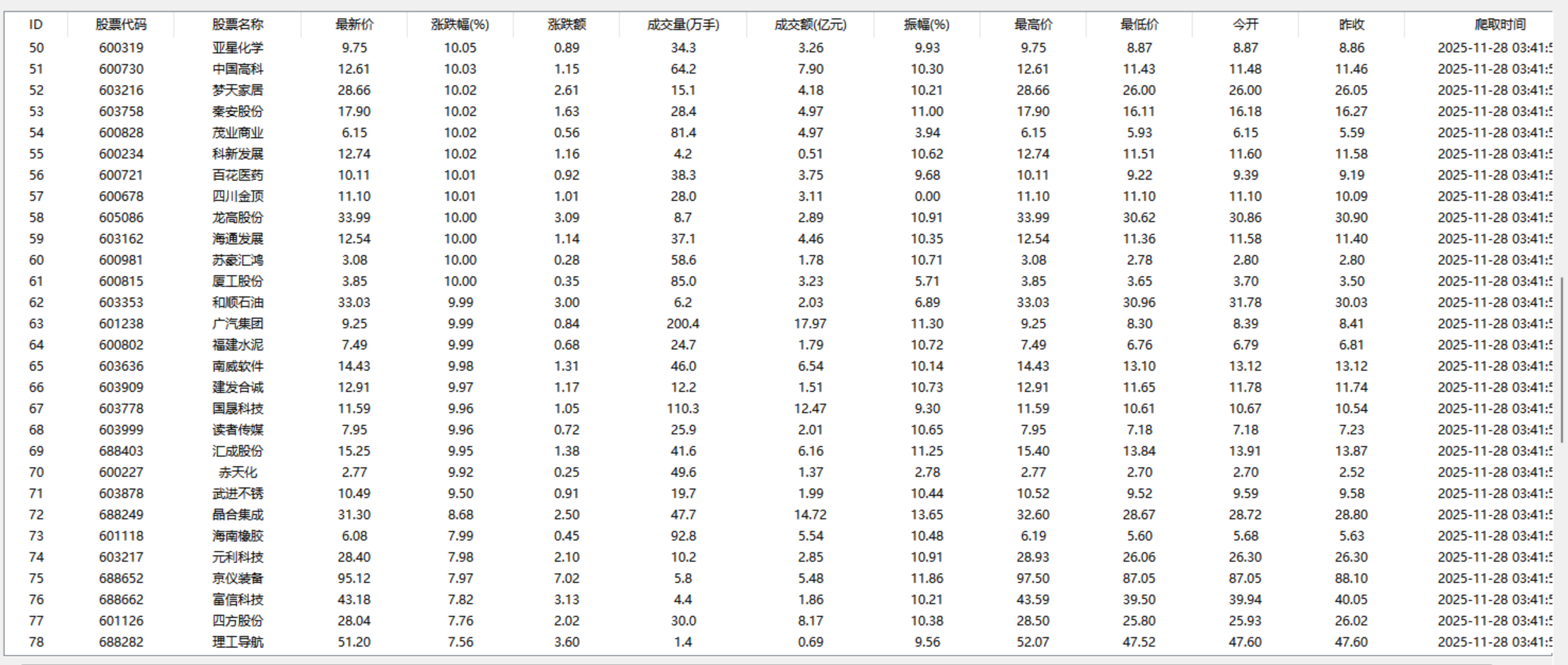
每一个板块爬两页
心得体会
在本次实验中,通过使用 Selenium 爬取了东方财富网的股票数据。首先,提取数据时发现,表格 tr 标签下的 td 字段中,成交量、成交额数据带有“万”“亿”中文单位,直接进行类型转换会报错。为此,我优化了数据转换函数,通过识别单位并进行对应换算(万×10000、亿×100000000),成功将带单位的字符串转为标准数值,确保了数据与数据库字段的适配,提升了爬取结果的准确性。其次,我发现打开页面的时候他会有一个广告跳出来,会有一个透明遮罩挡住爬虫爬取数据,导致超时,这里其实可以有两种解决方案,一种是手动把广告关掉,一种是写一行代码绕过透明遮罩,这里为了代码简洁一点选用了前者,最后我发现爬虫在点击下一页的时候因为页面太长找不到翻页按钮,所以增加了一个滚动到按钮旁边的一个机制,解决了这个问题。
码云地址:https://gitee.com/yaya-xuan/zyx_project/tree/master/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86/%E4%BD%9C%E4%B8%9A4/%E4%BD%9C%E4%B8%9A4.1
作业②
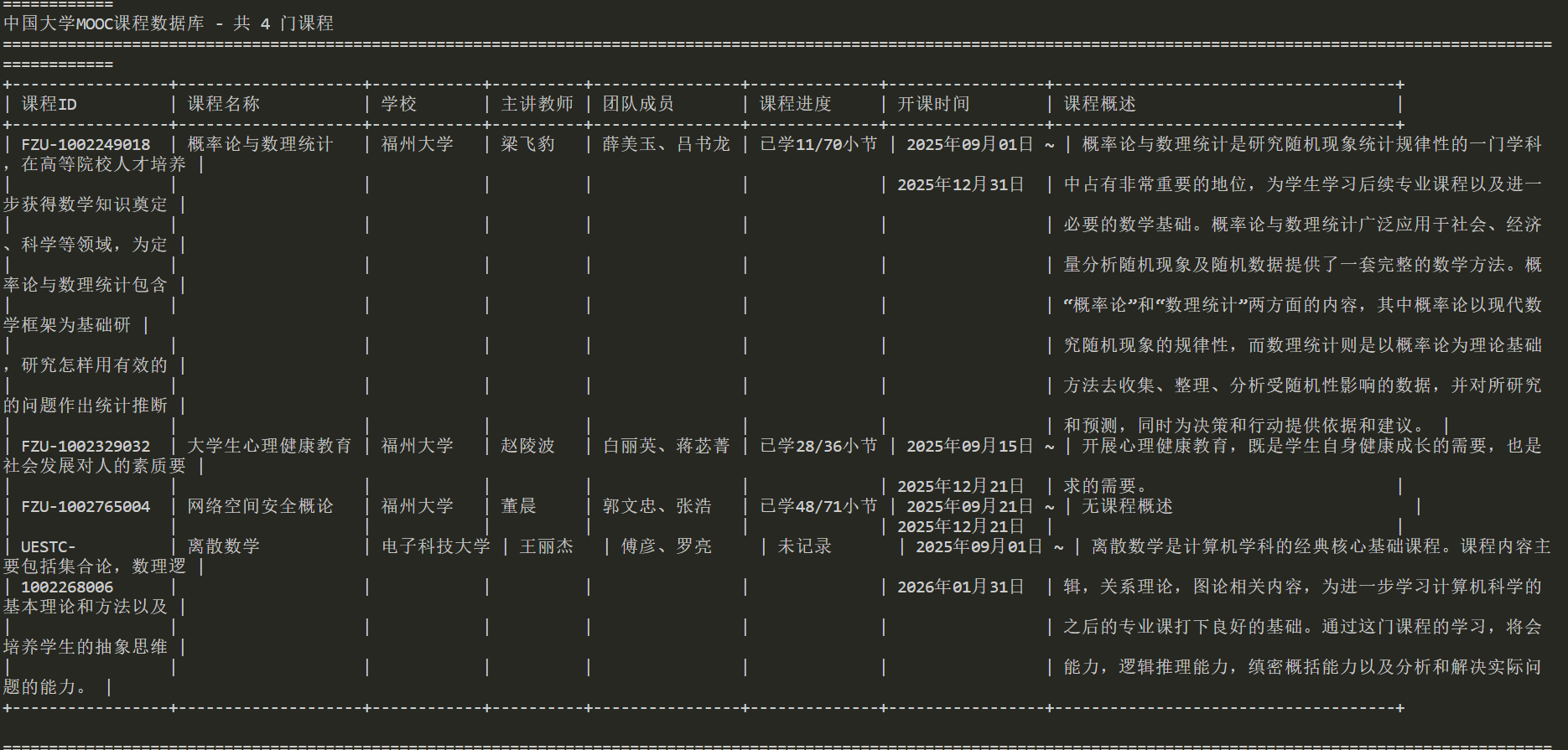
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
代码结果
核心代码
代码的整体思路是 :初始化(数据库+浏览器)→ 手动登录+加载课程列表 → 提取有效课程链接 → 循环爬取每门课程详情 → 数据入库+表格展示 → 关闭资源
我们采用手动登录加get个人课程中心的URL方式跳转到我们想要爬取的目标页面
这里加了一个强制等待避免页面没加载完就提取链接的报错
点击查看代码
def manual_login_and_load_courses(driver):
driver.get("https://www.icourse163.org/")
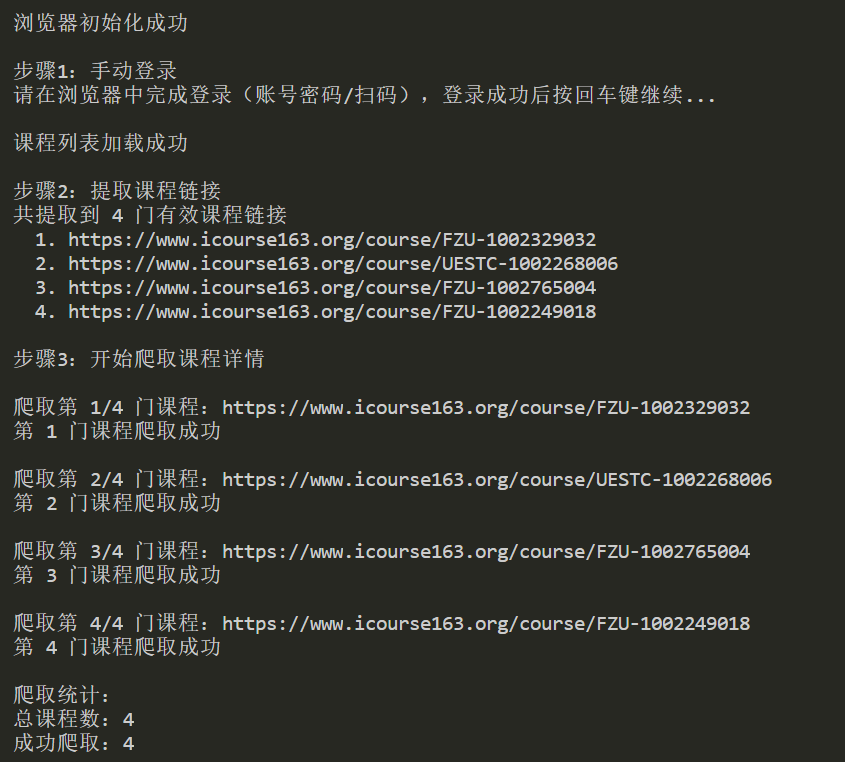
print("\n步骤1:手动登录")
print("请在浏览器中完成登录(账号密码/扫码),登录成功后按回车键继续...")
input()
driver.get(PERSONAL_COURSE_URL)#这里是我们前面配置时候配置的个人课程中心的url
time.sleep(5)
driver.refresh()
time.sleep(3)
# 保留必要等待
WebDriverWait(driver, 60).until(
EC.presence_of_all_elements_located((By.XPATH, "//a[contains(@href, '/course/')]"))#一直等待到页面有course的链接出现才代表加载成功
)
print("课程列表加载成功")

所以提取课程时候为了过滤无效链接(如条款页、帮助页),我们先提取页面中所有含“/course/”的链接,再用正则表达式匹配“学校代码-数字”格式的有效课程ID(如FZU-1002329032)
点击查看代码
# 提取课程链接
def extract_course_links(driver):
print("\n步骤2:提取课程链接")
course_link_elements = driver.find_elements(By.XPATH, "//a[contains(@href, '/course/')]")
course_links = []
# 有效课程ID正则(匹配 "学校代码-数字" 格式,如 FZU-1002329032)
course_id_pattern = re.compile(r'course/([A-Za-z0-9]+-[0-9]+)')
for elem in course_link_elements:
link = elem.get_attribute("href").strip()# 获取链接的实际地址(href属性)
# 只匹配含有效课程ID的链接
match = course_id_pattern.search(link)
if match:
pure_link = f"https://www.icourse163.org/course/{match.group(1)}"
if pure_link not in course_links:
course_links.append(pure_link)
print(f"共提取到 {len(course_links)} 门有效课程链接")
# 打印提取的链接,方便验证
for i, link in enumerate(course_links, 1):
print(f" {i}. {link}")
return course_links# 返回有效课程链接列表
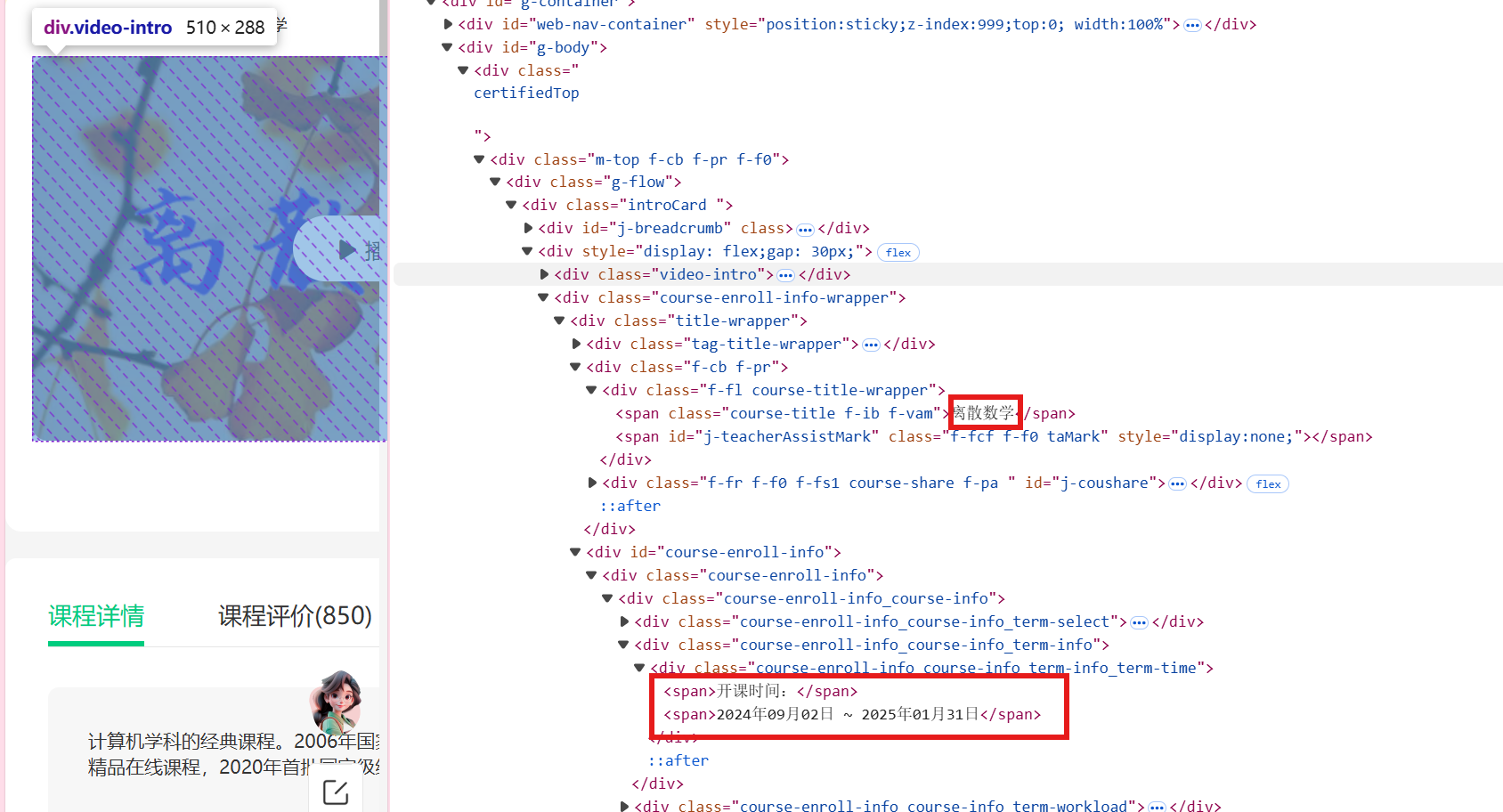
学校名称和开课时间部分
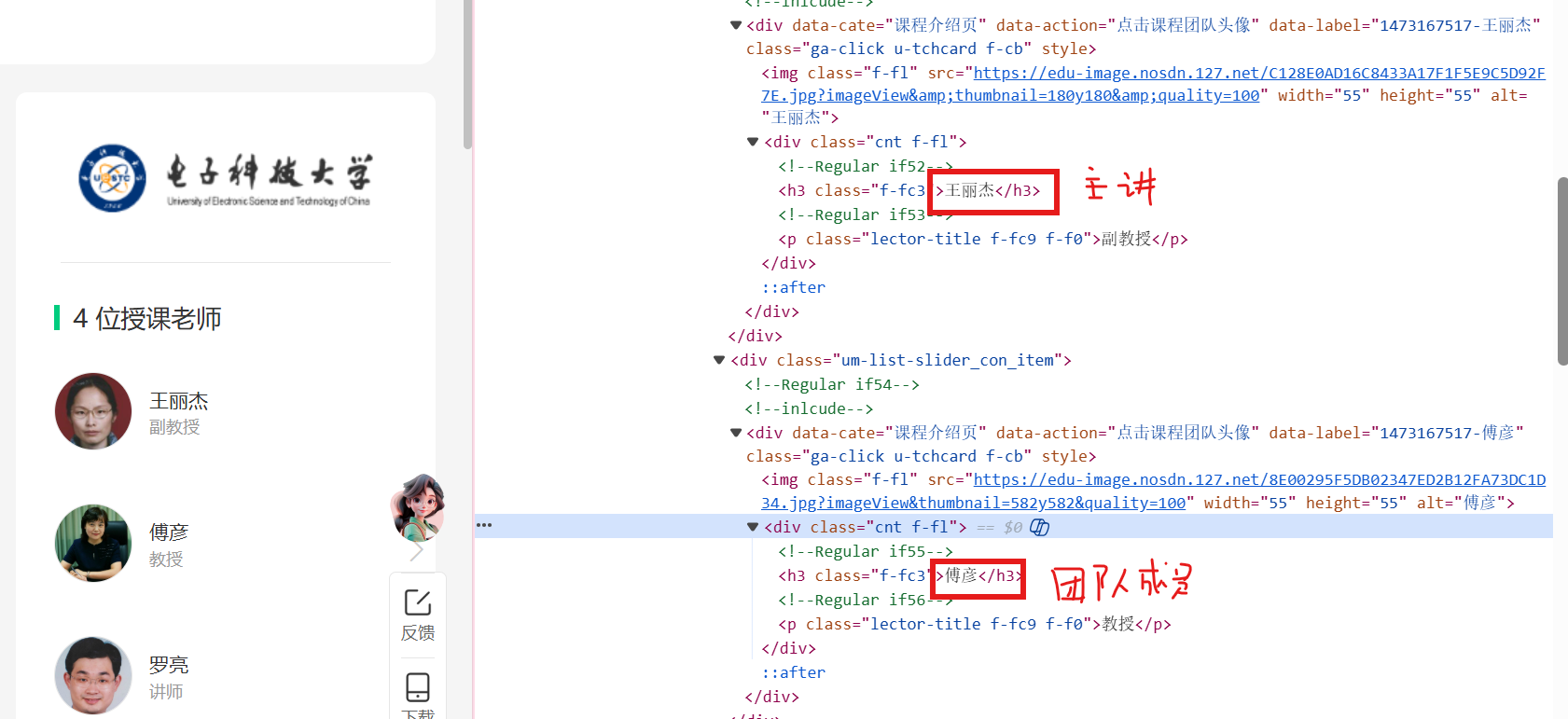
主讲教师和团队成员
课程进度

点击查看代码
# 爬取课程详情
def crawl_course_details(driver, course_links, conn, cursor):
print("\n步骤3:开始爬取课程详情")
main_window = driver.current_window_handle
success_count = 0
course_data_list = []
for idx, link in enumerate(course_links, 1):
print(f"\n爬取第 {idx}/{len(course_links)} 门课程:{link}")
driver.execute_script(f"window.open('{link}');")
time.sleep(2)
new_handles = [h for h in driver.window_handles if h != main_window]
driver.switch_to.window(new_handles[0])
# 等待核心元素加载
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, "//*[@id='g-body']/div[1]/div/div/div/div[2]/div[2]/div[1]/div[2]/div[1]/span[1]"))
)
# 提取课程ID:从课程链接中用正则提取(如从link中提取FZU-1002329032)
course_id = re.search(r'course/([A-Za-z0-9\-]+)', link).group(1)
# 提取课程名称:用XPath定位元素,获取文本
course_name = driver.find_element(By.XPATH, "//*[@id='g-body']/div[1]/div/div/div/div[2]/div[2]/div[1]/div[2]/div[1]/span[1]").text.strip()
# 提取开课学校:定位学校Logo图片,获取alt属性(MOOC的图片alt文本就是学校名称)
school = driver.find_element(By.XPATH, "//a[contains(@class, 'm-teachers_school-img')]/img").get_attribute("alt").strip()
# ④ 提取主讲教师和团队成员
teacher_elements = driver.find_elements(By.XPATH, "//div[contains(@class, 'um-list-slider_con_item')]//h3") # 定位所有教师元素
teacher_names = [elem.text.strip() for elem in teacher_elements if elem.text.strip()] # 提取所有教师名称
teacher = teacher_names[0] if teacher_names else "未知教师" # 第一个教师是主讲教师
team = "、".join(teacher_names[1:]) if len(teacher_names) > 1 else "无" # 其余是团队成员,用顿号连接
# 课程进度:切回主课程列表页提取
driver.switch_to.window(main_window)
try:
# XPath:通过课程ID定位对应课程卡片,再提取进度文本
progress_xpath = f"//a[contains(@href, '{course_id}')]/ancestor::div[contains(@class, 'course-card') or contains(@class, 'course-item')]//span[contains(text(), '/') or contains(text(), '已学') or contains(text(), '进度')]"
progress = driver.find_element(By.XPATH, progress_xpath).text.strip()
except:
progress = "未记录"
# 切回详情页继续提取其他字段
driver.switch_to.window(new_handles[0])
# 开课时间
try:
start_time = driver.find_element(By.XPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div[1]/div[3]/div/div[1]/div[2]/div/span[2]").text.strip()
start_time = start_time if start_time else "暂无开课时间"
except:
start_time = "暂无开课时间"
# 课程概述
try:
intro = driver.find_element(By.XPATH, "/html/body/div[5]/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/div[4]/div/p[1]/span").text.strip()
intro = intro[:300] + "..." if len(intro) > 300 else intro
except:
intro = "无课程概述"
结果
实验心得
本次MOOC个人课程爬虫,核心采用Selenium模拟浏览器交互的爬虫方法,结合XPath精准定位网页元素、正则表达式过滤有效课程链接与提取课程ID;实验中遇到的核心问题均针对性解决:浏览器被识别为爬虫则通过关闭自动化检测、最大化窗口规避反爬,混入无效链接则用“学校代码-数字”格式正则筛选有效课程链接,课程进度在详情页提取失败则优化为切回主课程列表页,通过课程ID定位对应卡片提取进度,让我学会了很多解决爬虫问题的方法。
码云地址:https://gitee.com/yaya-xuan/zyx_project/tree/master/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86/%E4%BD%9C%E4%B8%9A4/%E4%BD%9C%E4%B8%9A4.2
作业③
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
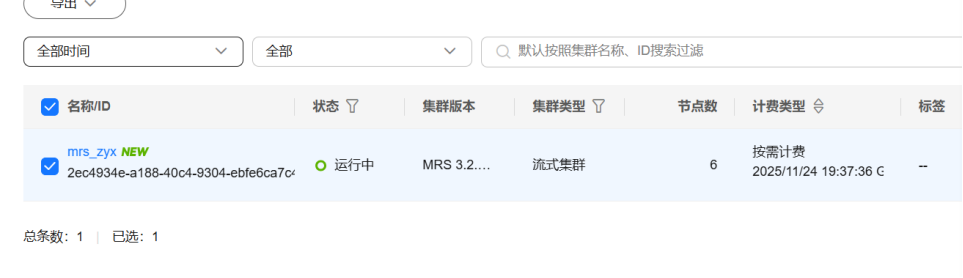
任务一:开通MapReduce服务

实时分析开发实战:
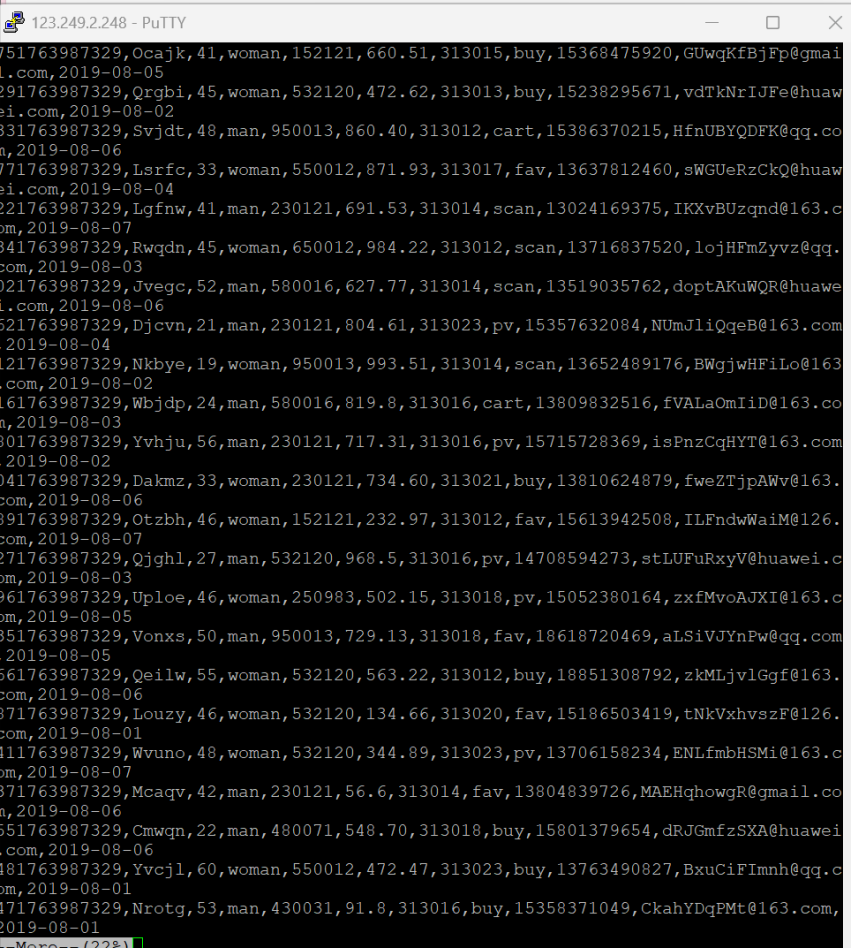
任务一:Python脚本生成测试数据
编写脚本


执行脚本测试
任务二:配置Kafka
下载Flume客户端

安装Kafka客户端

在kafka中创建topic


任务三: 安装Flume客户端
下载Flume客户端

安装Flume运行环境

安装fiume客户端

任务四:配置Flume采集数据
修改配置文件

创建消费者消费kafka中的数据

实验心得
通过Flume实验,我掌握了其配置与数据采集流程。编写配置文件、关联数据源与Kafka,实现数据实时传输,深刻体会到Flume在分布式系统中稳定采集的核心价值。过程中解决配置错误、数据传输中断等问题,提升了实操与故障排查能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号