

作业1
一:作业①:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
代码部分及结果
(1)代码部分
点击查看代码
import requests
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(url) # 向url发送get请求
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser') # 将html文本解析为soup对象,因为是简单页面,这里直接用python内置的html解析器
# 查看页面的源代码,发现排名的学校信息被包括在<table>的标签下,class为'rk-table'
table = soup.find('table', class_='rk-table') # 定位class为'rk-table'的表格,结果存入table
print("排名 学校名称 学校类型 总分")
# 遍历以提取数据
for row in table.find_all('tr')[1:]: # 遍历表格中所有行(<tr>标签),[1:]是为了跳过原表头行
leibiao = row.find_all('td') # 获取当前行所有单元格(<td>标签),存入列表
if len(leibiao) >= 6:
# 排名:从第1个单元格的'ranking'类div中获取
rank = leibiao[0].find('div', class_='ranking').text.strip() if leibiao[0].find('div', class_='ranking') else ''
# 学校名称:从第2个单元格的'name-cn'类span中获取中文名称
name = leibiao[1].find('span', class_='name-cn').text.strip() if leibiao[1].find('span', class_='name-cn') else ''
# 学校类型:第4个单元格的文本
schooltype = leibiao[3].text.strip()
# 总分:第5个单元格的文本
score = leibiao[4].text.strip()
#输出
if rank and name: #结果不为空的时候输出
print(f"{rank} {name} {schooltype} {score}")
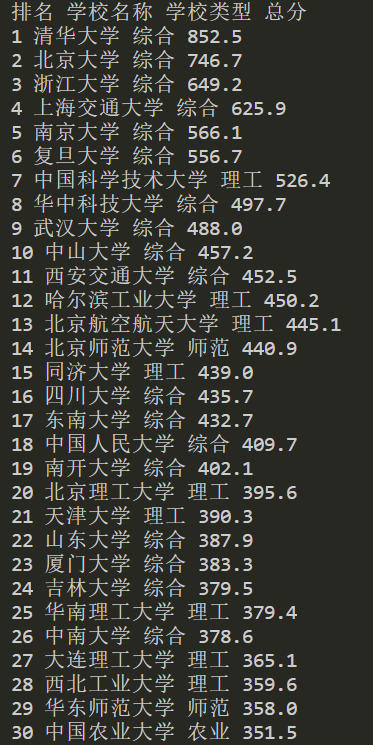
实验心得:
(1)实验步骤
因为requests+bps4只能爬取静态页面,查看网站的网络,我们可以发现这个页面是动态加载的,所以这里只能爬取html里内置的第一页数据
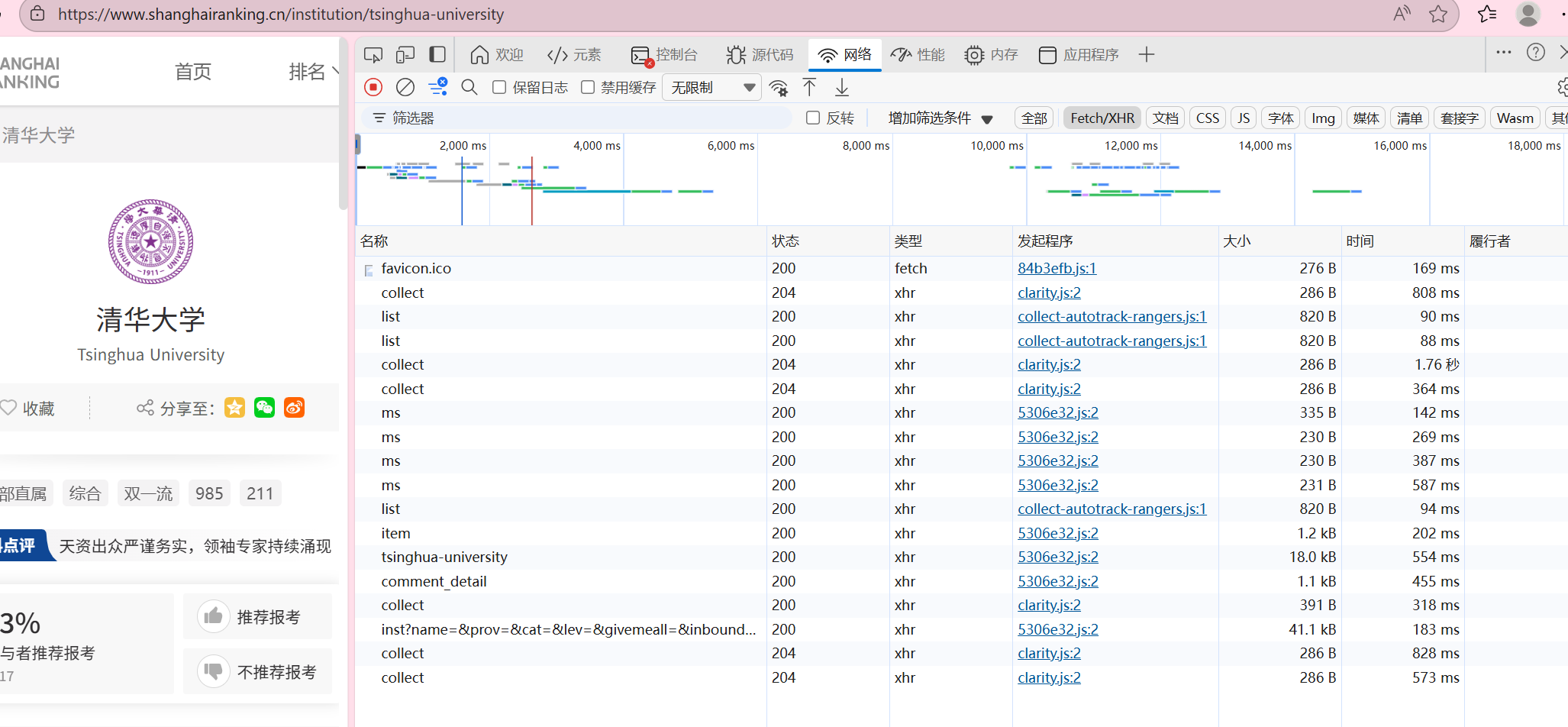
查看页面的源代码,可以查看到整个存储学校信息的结构
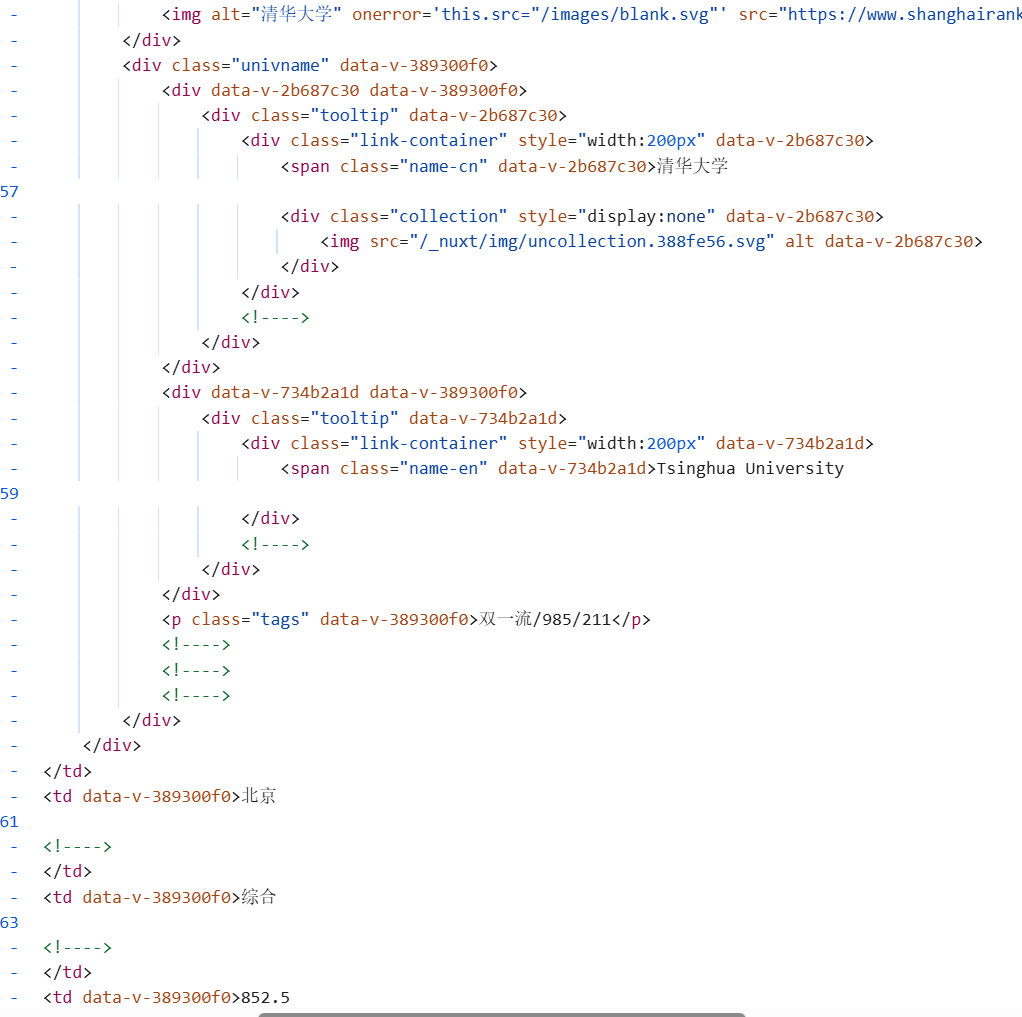
发现学校数据以表格结构存储,这里我们就可以查看一下表格的结构,定位一下每一个我们所需要的信息对应的位置,并把这个表格的信息存入我们代码中的表格,以便后续寻找
分析发现:
- 排名数据放在该单元格内一个class为ranking的div标签中
- 学校的中文名称放在该单元格内一个class为name-cn的span标签中
- 学校类型在第4个(即第4个单元格中),总分在第5个
(2)实验感想:
爬大学排名让我明白,抓数据得先摸清网页标签结构,精准定位才能顺利拿到想要的信息,以及针对不同的页面,我们可以有不同的爬虫方式。
二:作业②
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码部分及其结果
(1)代码
点击查看代码
import requests
import re
# 目标URL与请求头
url = "https://s.manmanbuy.com/pc/search/result?c=discount&keyword=书包"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
}
try:
# 发送请求并获取HTML
response = requests.get(url, headers=headers, timeout=10)
response.encoding = "utf-8"
html_text = response.text
# 1. 提取价格
price_pattern = r'<a target="_blank" title="[^"]*" href="([^"]*)">([0-9.]+元[^<]*)</a>'
price_dict = {href: price.strip() for href, price in re.findall(price_pattern, html_text, re.S)}
# 2. 提取商品名
name_pattern = r'<a target="_blank" title="([^"]*书包[^"]*)" href="([^"]*)">([^<]*书包[^<]*)</a>'
name_matches = re.findall(name_pattern, html_text, re.S)
# 3. 输出
print(f"{'序号'} {'价格':<25} {'商品名'}")
print("-" * 100)
# 遍历数据并输出
for idx, (title, href, name) in enumerate(name_matches, start=1):
real_name = name.strip() if name.strip() else title.strip() # 确定商品名
price = price_dict.get(href, "未标注价格") # 获取对应价格
print(f"{idx:<6} {price:<25} {real_name}")
if not name_matches:
print("爬取结果为空")
except requests.exceptions.RequestException as e:
print(f"请求错误:{e}")
except Exception as e:
print(f"其他错误:{e}")
实验心得
(1)实验步骤
因为大网站的反爬机制太强烈,这里选取了一个小商城“慢慢买”爬取
查看页面,点击我们想要爬取的元素,商品名和价格,右击检查可以查看该元素对应的位置,如图所示
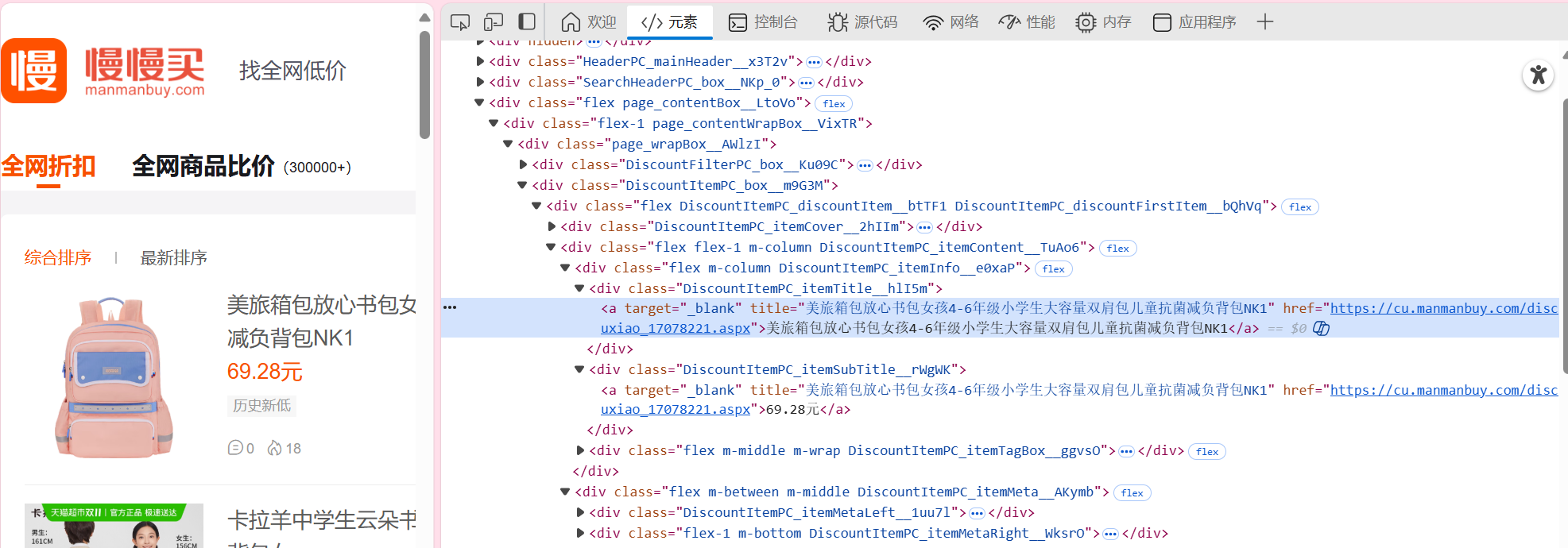
然后就可以编写对应的正则表达式
价格提取正则式

- <a target="_blank" title="[^"]*" href=":匹配 HTML 中标签的固定前缀(target="_blank"是新窗口打开属性,title="..."是标题属性,href="是链接属性)
- ([^"]*):第一个捕获组,匹配商品链接(href的值)
- [^"]*表示 “匹配除双引号外的任意字符
- ">:匹配标签中链接属性的结束部分
- ([0-9.]+元[^<]*):第二个捕获组,匹配价格
- [^<]*表示 “匹配除<外的任意字符”(直到标签结束的<)
- :匹配标签的闭合
商品名提取正则式
![image]()
- (["]*书包["]*):第一个捕获组,匹配title属性中含 “书包” 的文本(任意字符 + 书包 + 任意字符)
- ([^"]*):第二个捕获组,匹配商品链接(href的值),和价格提取中的href一致
- " href=":匹配title属性结束和href属性开始
- ([<]*书包[<]*):第三个捕获组,匹配标签内的文本(商品名)

(2)实验感想
商城书包爬取实验,用request发送网络请求、re库提取数据,通过商品链接关联价格与商品名,成功筛选并输出目标商品信息。实验中,我既掌握了正则表达式匹配HTML标签的技巧(如用re.S处理多行结构),也明白User-Agent对规避反爬的重要性。
三:作业③
爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
代码部分以及结果
(1)代码
这次实验用到了requests加bs4+urllib.parse(处理 URL,将相对路径转为绝对路径)
并加入一些判断错误机制
点击查看代码
import requests
import os
import urllib.parse
from bs4 import BeautifulSoup
def download_webpage(url):
# 模拟浏览器请求头,避免被拦截
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
try:
return requests.get(url, headers=headers, timeout=10).text
except:
return ""
def download_all_images(html, base_url, save_dir):
os.makedirs(save_dir, exist_ok=True)
results = []
# 遍历所有<img>标签
for idx, img in enumerate(BeautifulSoup(html, 'html.parser').find_all('img'), 1):
src = img.get('src', '').strip()
if not src or src.startswith('data:'):
continue
# 处理图片URL和文件名
url = urllib.parse.urljoin(base_url, src)
fname = os.path.basename(urllib.parse.urlparse(src).path) or f'img_{idx}.jpg'
if '.' not in fname:
fname += '.jpg'
path = os.path.join(save_dir, fname)
# 下载并保存图片
try:
res = requests.get(url, timeout=10)
res.raise_for_status()
with open(path, 'wb') as f:
f.write(res.content)
results.append({"url": url, "path": path, "alt": img.get('alt', '')})
except:
pass
return results
def save_info(results):
# 保存图片信息到文件
with open('images_info.txt', 'w', encoding='utf-8') as f:
for i, img in enumerate(results, 1):
f.write(f"{i}. URL: {img['url']}\n 本地路径: {img['path']}\n 描述: {img['alt']}\n---\n")
def main():
url = "https://news.fzu.edu.cn/yxfd.htm"
save_dir = "images"
html = download_webpage(url)
if html:
imgs = download_all_images(html, url, save_dir)
save_info(imgs)
print(f"图片已保存至 {os.path.abspath(save_dir)}")
if __name__ == "__main__":
main()
实验心得
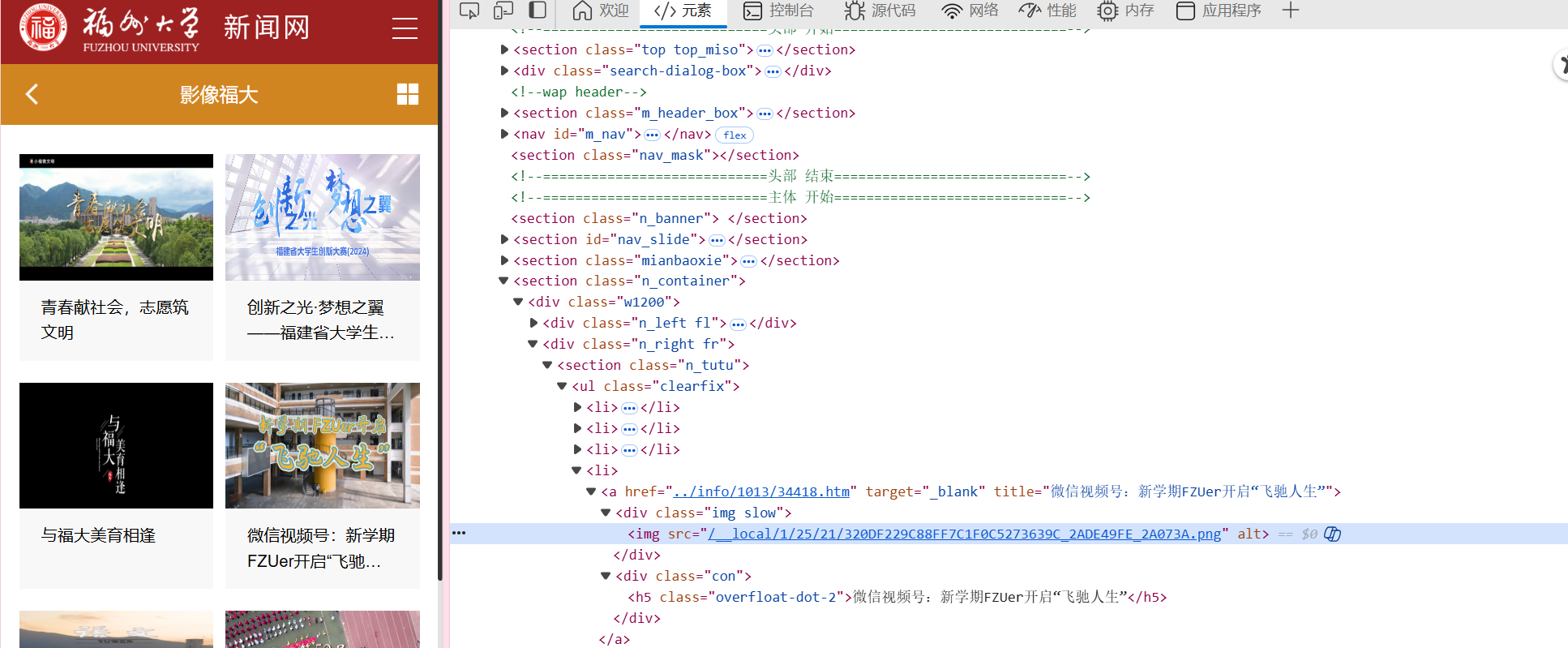
(1)实验步骤
查看页面源代码,检查图片所对应的标签,在下
整个代码实验的过程:
首先通过requests库模拟浏览器发送 HTTP GET 请求,携带User-Agent请求头规避网站反爬机制,获取目标网页的 HTML 源代码;接着利用BeautifulSoup解析 HTML 结构,提取所有标签,从中获取图片的路径(src属性)及描述(alt属性);针对网页中常见的图片相对路径(如/images/1.jpg),通过urllib.parse库的urljoin方法将其与网页基础 URL 拼接为可直接访问的绝对路径;最后借助os库实现本地文件系统操作,自动创建图片保存目录,将通过requests获取的图片二进制数据(content属性)以二进制写入模式保存到本地文件
(2)实验感想:
学会了处理路径,把相对路径转成能直接用的绝对路径,理解各库协同作用,学会处理异常。
gitee地址:
https://gitee.com/yaya-xuan/zyx_project/tree/数据采集与融合技术作业1/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号