一些关于队列的理论:吞吐量、延迟和带宽
本文基本上是此文章的翻译
假设在 RabbitMQ 中有一个队列,你有一些客户端会消费这个队列。 如果没有配置QoS(Quality of Service),那么 RabbitMQ服务会以网络和客户端允许的速度将队列的所有消息推送到你的客户端, 客户端将所有消息存储在其内存中,内存压力会急剧增加。此时在RabbitMQ端查看队列,可能会显示它是一个空队列,因为此时所有消息都存在于消费者客户端的内存中等待客户端处理,此时,如果你增加一个新的消费者,这个消费者消费不到任何新消息,因为所有消息目前都存在于之前的消费者客户端,并且可能会存在很久,即便你新增加的消费者可以更快的处理这一类消息。这种情况是相当不理想的。
因此,默认的 QoS设置为客户端提供了无限的缓冲区,这可能会导致一些不理想的情况以及性能。 但是应该将 QoS 设置为多少呢? 这个值应该让消费者保持饱和,但同时要最小化客户端的缓冲区大小,以便更多消息的保留在 RabbitMQ 的队列中,从而可供新消费者使用或在其他消费者空闲时发送给消费者。
我们假设 RabbitMQ 从发送一条消息,被消费者端收到,一共需要50ms, 客户端收到消息之后处理这个消息需要花费4ms。 一旦消费者处理了消息,它就会向 RabbitMQ 发送一个 ack,这又需要 50 毫秒。 所以总往返时间为 104 毫秒。 如果我们将 QoS 设置为 1 ,那就意味着每104毫秒RabbitMQ才会开始发送下一条消息。因此,客户端每 104 毫秒中只有 4 毫秒处于忙碌状态,即 3.8% 的时间。 我们希望它 100% 的时间都处于忙碌状态。
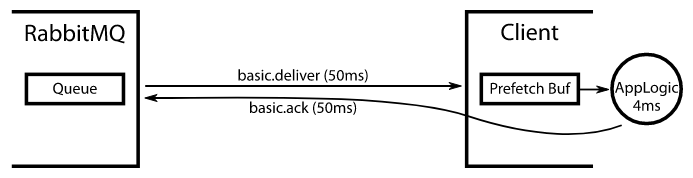
如果我们做一个除法:总往返时间 / 处理时间,即104 / 4 = 26。假设,我们将QoS设置为26:此时客户端有 26 条消息被缓冲等待处理。 (这是一个明智的假设:一旦设置了 QoS, 然后从队列中消费,RabbitMQ会向客户端发送尽可能多的消息,直至达到 QoS 限制。假设消息不是很大而且带宽很高,很可能 RabbitMQ 将能够以比客户端处理它们更快的速度将消息发送到客户端。因此,这个假设出发点是合理并且简单的)。每条消息需要 4 毫秒的处理时间,那么处理整个缓冲区总共需要 26 * 4 = 104 毫秒。前4ms是客户端对第一条消息的处理,然后客户端发出一个 ack 并继续处理来自缓冲区的下一条消息,该确认需要 50 毫秒才能到达RabbitMQ端。接着RabbitMQ向客户端发出一条新的消息,这又需要 50 毫秒,因此当 104 毫秒过去并且客户端处理完其消息缓冲区时,来自MQ的下一条消息已经到达并准备好等待客户端来处理。因此客户端会一直处在饱和状态:有更大的 QoS 不会让它更快;但是我们最小化了缓冲区大小,从而最小化了客户端中消息的延迟:客户端缓冲消息的时间不会超过它们所需的时间,以保持客户端的工作饱和。事实上,客户端能够在下一条消息到达之前完全排空缓冲区,因此缓冲区实际上是空的。
如果处理时间和网络行为保持不变,这个解决方案绝对没问题。 但是考虑一下如果网络速度突然减半会发生什么:预取缓冲区(就是QoS)不再足够大,现在客户端将处于空闲状态并等待新消息到达,因为客户端能够以比 RabbitMQ 提供新消息的速度更快地处理消息。
为了解决这个问题,我们可能需要将 QoS 增加一倍(或接近一倍)。如果我们将它从 26 增加到 51,客户端处理每条消息的时间依旧是 4 毫秒,那么我们现在缓冲区中有 51 * 4 = 204 毫秒的消息,其中 4 毫秒将用于处理一条消息,剩下的 200 毫秒用于发送一条ACK到 RabbitMQ 并接收下一条消息。因此,我们现在可以应对网络速度减半的情况。
但是,如果网络运行突然恢复正常,QoS 加倍意味着每条消息将在客户端缓冲区中停留一段时间,而不是在到达客户端后立即处理。同样的,假设此时客户端已经有了51条消息,我们知道新消息将在客户端处理完第一条消息后 100 毫秒(50 * 2)出现在客户端。但是在这 100 毫秒内,客户端将处理 50 条可用消息中的 100 / 4 = 25 条。这意味着当一条新消息到达客户端时,当客户端从缓冲区的头部删除时,它将被添加到缓冲区的末尾。因此,缓冲区将始终保持 50 - 25 = 25 条消息的长度,因此每条消息将在缓冲区中停留 25 * 4 = 100 毫秒,从而增加了 RabbitMQ 将其发送到客户端和客户端开始处理它之间的延迟,从 50 毫秒到 150 毫秒。
因此,我们看到通过增加QoS可以让客户端可以在保持饱和的同时应对突然恶化的网络,但是当网络恢复正常运行时,消息消费的延迟会大大增加。
同样地,如果网络一直保持稳定,客户端现在处理一条消息突然需要花费40毫秒而不是4毫秒了,会发生什么?如果 RabbitMQ 中的队列之前是稳定的(即入口和出口速率相同),现在它将开始快速增长,因为出口速率已降至原来的十分之一。你可能决定通过添加更多消费者来尝试解决这个不断增长的积压,但现在有一些消息被现有客户端缓冲。假设原始缓冲区大小为 26 条消息,客户端将花费 40 毫秒处理第一条消息,然后将 ack 发送回 RabbitMQ 并移动到下一条消息,ACK 仍然需要 50 毫秒才能到达 RabbitMQ,再需要 50 毫秒让 RabbitMQ发送一条新消息,但是在这 100 毫秒内,客户端只处理了 100 / 40 = 2.5 条后续的消息,而不是剩余的 所有25 条消息。因此,此时缓冲区的长度为 25 - 3 = 22 条消息。此时来自于 RabbitMQ 的新消息并不会被立即处理,因为在他之前还有22条消息待处理,也就是在 22 * 40 = 880 毫秒内新消息不会被客户端处理。鉴于从 RabbitMQ到客户端的网络延迟只有 50 毫秒,这个额外的 880 毫秒延迟占了目前总延迟的 95% :(880 / (880 + 50) = 0.946)。
更糟糕的是,如果此时QoS是51(为了应对网络恶化),处理完第一条消息后,将在客户端缓冲 50 条其他消息。 100 毫秒后(假设此时网络运行恢复正常了),一条新消息从 RabbitMQ 发到客户端,客户端此时正在处理 50 条消息中的第 3 条(缓冲区现在有 47 条消息),因此新消息将位于缓冲区中的第 48 位,并且在接下来的 47 * 40 = 1880 毫秒内不会被处理。同样,考虑到将消息发送到客户端的网络延迟仅为 50 毫秒,这进一步的 1880 毫秒占了目前总延迟的97% (1880 / (1880 + 50) = 0.974)。这是不可接受的:数据可能只有在及时处理时才有效和有用,而不是在客户端收到后大约 2 秒再处理,如果其他消费客户端空闲,则他们无能为力:一旦 RabbitMQ 向客户端发送了消息,这个消息就是这个客户端的责任,直到它确认或拒绝该消息。一旦消息发送到客户端,客户端就不能相互窃取消息。您想要的是让客户端保持忙碌,但让客户端缓冲尽可能少的消息,以便消息不会被客户端缓冲区延迟,因此新的消费客户端可以从 RabbitMQ的队列中快速获取消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号