Java新特性扩展之List集合操作
java8的新特性使用起来非常的方便,详情参考Java8新特性。
1.map-获取集合中对象的某个属性值
1)需求:现有一个包含用户对象的集合,想只获取这些用户的姓名组成一个集合,如何去做?
2)演示
用户对象如下:
@Data public class User { private Integer id; private String name; private String phone; }
列表如下(演示数据):
List<User> userList = new ArrayList<>(); for (int i = 0; i < 5; i++) { User user = new User(); user.setId(i + 1); user.setName("张" + (i + 1) + "方"); userList.add(user); }
第一种方式:遍历用户对象的集合进行获取
List<String> nameList = new ArrayList<>(); userList.stream().forEach(user -> nameList.add(user.getName()));
第二种方式:使用流方式提前数据(推荐)
List<String> nameList = userList.stream().map(User::getName).collect(Collectors.toList());
2.filter-对集合元素过滤
1)需求:现有一个包含行政区对象的集合,根据父级id获取所有行政区的父级编码,如何去做?
2)演示
用户对象如下:
@Data @AllArgsConstructor public class AreaCode { private Integer id; private String name; private String code; private Integer parentId; private String description; }
列表如下(演示数据):
List<AreaCode> list = new ArrayList<>(); list.add(new AreaCode(1, "湖北省", "101", 0, null)); list.add(new AreaCode(2, "武汉市", "10101", 1, null)); list.add(new AreaCode(3, "黄冈市", "10102", 1, null)); list.add(new AreaCode(4, "洪山区", "1010101", 2, null)); list.add(new AreaCode(5, "江夏区", "1010102", 2, null)); list.add(new AreaCode(6, "江岸区", "1010103", 2, null)); list.add(new AreaCode(6, "阳新县", "1010201", 3, null));
使用get()过滤符合条件的元素
list.stream().forEach(l -> { String code = "0"; if (l.getParentId() != 0) { Optional<AreaCode> any = list.stream().filter(s -> s.getId().equals(l.getParentId())).findAny(); if(any.isPresent()){ AreaCode areaCode = any.get(); code = areaCode.getCode(); } } l.setParentCode(code); });
先对整个集合进行遍历,顶级元素除外,过滤出集合中id是当前元素父Id的元素,将其编码赋值给当前元素的对应属性。看起来有些绕,但对于数据的过滤是非常方便的。需要注意的是,这里必须先使用isPresent()方法进行判断是否有符合要求的数据,否则没有符合要求的数据时直接get会抛出空指针异常。
当然,除了获取单个值(findAny)之外,还可以把符合条件的值都查询出来返回集合list。
例如获取行政区中包含 湖 字的所有行政区
列表如下(演示数据):
List<AreaCode> list = new ArrayList<>(); list.add(new AreaCode(1, "湖北省", "101", 0, null)); list.add(new AreaCode(2, "湖南省", "201", 0, null)); list.add(new AreaCode(3, "江西省", "301", 0, null)); list.add(new AreaCode(4, "北京", "401", 0, null)); list.add(new AreaCode(5, "广东省", "501", 0, null)); list.add(new AreaCode(6, "甘肃省", "601", 0, null));
过滤符合条件的元素
List<AreaCode> codeList = list.stream()
.filter(item -> StringUtils.contains(item.getName(), "湖" )).collect(Collectors.toList());
其实filter只是对元素过滤,而对于结果如何处理,那就得根据实际场景处理。
上述只对某一个属性进行过滤,那么假如需要对几个属性进行过滤,且传入的参数不为空时才过滤(类似页面的输入查询条件),又该怎么解决?
直接上案例:如果输入的行政区名称不为空则根据输入的值筛选,输入的备注不为空则同样筛选:
/** * 判断字符串是否包含,如果查询的字符串为空则不包含 * * @param str * @param searchStr * @return */ public static Boolean contains(String str, String searchStr) { if (StringUtils.isNotEmpty(searchStr)) { return StringUtils.contains(str, searchStr); } return true; }
封装了一个方法,用于判断是否包含
//模拟用户输入查询 String queryName = "湖"; String queryDesc = ""; List<AreaCode> codeList = list.stream() .filter(item -> contains(item.getName(), queryName) && contains(item.getDescription(), queryDesc)) .collect(Collectors.toList());
如果是多个条件,那么就需要使用并来过滤,而判断是否为空或是否包含的逻辑交给封装的方法来判断。
3.findAny判断集合对象属性是否存在某个值
1)需求:现有一个用户对象的集合,判断其中是否包含姓名为张三的用户,如何去做?
2)演示
用户对象如下:
@Data @Accessors(chain = true) @AllArgsConstructor @NoArgsConstructor public class User { private Integer id; private String name; private String phone; }
列表如下(演示数据):
List<User> userList = new ArrayList<>(); userList.add(new User(1, "张三丰", "15645854585")); userList.add(new User(2, "张三", "15645857858")); userList.add(new User(3, "李四", "15945854566")); userList.add(new User(4, "王五", "15755554585")); userList.add(new User(5, "张三", "15852254585"));
使用isPresent()进行判断
boolean exist1 = userList.stream().filter(user -> "张三".equals(user.getName())).findAny().isPresent();
其返回boolean类型,包含时返回true,不包含时返回false。
当然可以使用get()方法获取此元素的值,其返回的值是第一个符合条件的元素:
User user = userList.stream().filter(user -> "张三".equals(user.getName())).findAny().get();
这里的user内容就是集合元素中的第2个元素(id为2的用户信息)。
4.reduce-数据累加
reduce是一种聚合操作,聚合的含义就是将多个值经过特定计算之后得到单个值,常见的 count 、sum 、avg 、max 、min 等函数就是一种聚合操作。
比如要计算集合的所有发票总金额,就可以简单实现
List<Invoice> list = new ArrayList<>(); list.add(new Invoice(new BigDecimal("123"))); list.add(new Invoice(new BigDecimal("12.97"))); BigDecimal reduce = list.stream().map(Invoice::getAmount).filter(Objects::nonNull).reduce(BigDecimal.ZERO, BigDecimal::add);
需要注意的是,建议对其进行非空的判断,否则会出现空指针异常。
5.groupingBy-对集合元素进行分组
stream是java8的新特性,其就包含分组的方法。
5.1简单分组
1)先送上示例需要的数据结构
学生表student
| id | 学号 | 姓名 | 性别 | 班级编号 |
| 1 | 10202 | 张三丰 | 男 | A02 |
| 2 | 10103 | 李能 | 男 | A01 |
| 3 | 10203 | 赵三五 | 男 | A02 |
| 4 | 20106 | 黄家豪 | 男 | C01 |
| 5 | 10109 | 张慧 | 女 | A01 |
班级表clazz
| id | 班级编号 | 班级名称 |
| 1 | A01 | 计算机1班(本科) |
| 2 | A02 | 计算机2班(本科) |
| 3 | C01 | 计算机1班(专科) |
需要是查询当前学生信息及班级名称信息。(仅写java的业务代码)
2)新手写法
public List<StudentVO> getList() {
//查询学生列表 实际是需要带查询条件,这里做演示不做条件查询
List<StudentVO> list = studentDao.selectList();
if (!CollectionUtils.isEmpty(list)) {
list.stream().forEach(studentVO -> {
// 根据班级编码查询班级信息
ClazzVO clazzVO = clazzService.selectByCode(studentVO.getClazzCode());
if (clazzVO != null) {
//设置班级名称
studentVO.setClazzName(clazzVO.getClazzName());
}
});
}
return list;
}
在这种写法中,每个学生都需要去查询一次数据库的班级信息,而且有很多学生是同一个班的,其实没必要同一个班级的学生都去查询一次数据库,查询一次就可以了,可以减轻数据库的压力。虽然数据量不会特别大,对数据库的影响也不是很大,但确实值得优化,重要的是有这种思维。
3)优化后的写法
优化的方式也不少,比如每查询一次班级信息后将信息存入缓存,后续可直接从缓存中获取;又或者先查询出所有的班级信息,然后利用stream的分组特性或filter特性.....
这里以stream的分组特性进行说明:
public List<StudentVO> getList() {
//查询学生列表 实际是需要带查询条件,这里做演示不做条件查询
List<StudentVO> list = studentDao.selectList();
if (!CollectionUtils.isEmpty(list)) {
//查询所有班级信息
List<ClazzVO> clazzList = clazzService.selectAll();
Map<String, List<ClazzVO>> clazzMap = null;
if (!CollectionUtils.isEmpty(clazzList)) {
// 以clazzCode为key进行分组
clazzMap = clazzList.stream().collect(Collectors.groupingBy(e -> e.getClazzCode()));
}
Map<String, List<ClazzVO>> finalClazzMap = clazzMap;
list.stream().forEach(studentVO -> {
if (finalClazzMap != null) {
//根据编码从内存获取班级信息
List<ClazzVO> clazzVOS = finalClazzMap.get(studentVO.getClazzCode());
if (!CollectionUtils.isEmpty(clazzVOS)) {
//设置班级名称
studentVO.setClazzName(clazzVOS.get(0).getClazzName());
}
}
});
}
return list;
}
虽然代码比优化前多,但相比效率和性能,是值得的。stream分组将班级信息按照编辑编码为key,班级信息为value放入内存中,在遍历学生列表时,可根据班级编码直接从内存中获取班级名称,前后只查询了1次数据库,极大提高了效率,节省了数据库资源。这只是一个示例,说明的是编程的思想,当遇到其他类似的情况时就可以举一反三,一个项目下来可以减少多次不必要的数据库连接,从而提高系统的性能。
5.2分组并统计个数
上述是对元素进行了分组,实际上也可以对分组后的数据添加序号等等。
下面采用上一小节学生信息进行说明,需求是按照学生班级进行分组,并标注相同班级中每个学生是第几次出现,以及同一个班级中学生的个数。
这里为了演示方便,模拟数据库数据,数据如下:
| id | 学号 | 姓名 | 性别 | 班级编号 |
| 1 | 10202 | 张三丰 | 男 | A02 |
| 2 | 10103 | 李能 | 男 | A01 |
| 3 | 10203 | 赵三五 | 男 | A02 |
| 4 | 20106 | 黄家豪 | 男 | C01 |
| 5 | 10109 | 张慧 | 女 | A01 |
| 6 | 10104 | 赵敏 | 女 | A01 |
| 7 | 10203 | 朱倩倩 | 女 | A02 |
| 8 | 10105 | 刘明华 | 男 | A01 |
| 9 | 20106 | 周强 | 男 | C01 |
| 10 | 10107 | 何欢欢 | 女 | A01 |
呈上最终的结果
StudentVO(id=1, stuNo=10202, stuName=张三丰, clazzCode=A02, sex=男, time=1, total=3) StudentVO(id=2, stuNo=10103, stuName=李能, clazzCode=A01, sex=男, time=1, total=5) StudentVO(id=3, stuNo=10203, stuName=赵三五, clazzCode=A02, sex=男, time=2, total=3) StudentVO(id=4, stuNo=20106, stuName=黄家豪, clazzCode=C01, sex=男, time=1, total=2) StudentVO(id=5, stuNo=10109, stuName=张慧, clazzCode=A01, sex=女, time=2, total=5) StudentVO(id=6, stuNo=10104, stuName=赵敏, clazzCode=A01, sex=女, time=3, total=5) StudentVO(id=7, stuNo=10203, stuName=朱倩倩, clazzCode=A02, sex=女, time=3, total=3) StudentVO(id=8, stuNo=10105, stuName=刘明华, clazzCode=A01, sex=男, time=4, total=5) StudentVO(id=9, stuNo=20106, stuName=周强, clazzCode=C01, sex=男, time=2, total=2) StudentVO(id=10, stuNo=10107, stuName=何欢欢, clazzCode=A01, sex=女, time=5, total=5)
其中time代表同一个班级中出现的顺序,total代表同一个班级的学生总数。
实现方式如下
public List<StudentVO> listSort() { //查询学生列表 实际是需要带查询条件,这里做演示不做条件查询 List<StudentVO> list = studentDao.selectList(); if (!CollectionUtils.isEmpty(list)) { // 以clazzCode为key进行分组,收集结果 Map<String, List<StudentVO>> listMap = list.stream().collect(Collectors.groupingBy(e -> e.getClazzCode())); //分组统计个数 Map<String, Long> count = list.stream().collect(Collectors.groupingBy(e -> e.getClazzCode(), Collectors.counting())); for (Map.Entry<String, List<StudentVO>> entry : listMap.entrySet()) { Long i = 1L; String key = entry.getKey(); List<StudentVO> values = entry.getValue(); for (StudentVO value : values) { value.setTotal(count.get(key)); // 总数 value.setTime(i++); // 次数 } } } return list; }
我比较好奇的是,对于集合分组后,操作分组后的集合数据会影响到原时的集合,这样也简单的不少,但还未弄明白这其中的原理。
6.sorted-对集合元素进行排序
当对多个字段进行排序时,可直接在sql中进行排序,也可以在代码中利用stream进行排序(推荐)。
下面就对发票信息进行排序,
其中实体类为
package com.zxh.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.experimental.Accessors; import java.math.BigDecimal; /** * 销项发票实体 * @Author zxh * @Date 2025/1/3 星期五 */ @AllArgsConstructor @NoArgsConstructor @Data @Accessors(chain = true) public class OutputInvoice { /** * 发票号码 */ private String invoiceNo; /** * 发票代码 */ private String invoiceCode; /** * 发票明细行 */ private String invoiceItemId; /** * 税率 两位小数 */ private BigDecimal taxRate; }
①【单字段排序】根据发票号码升序排序
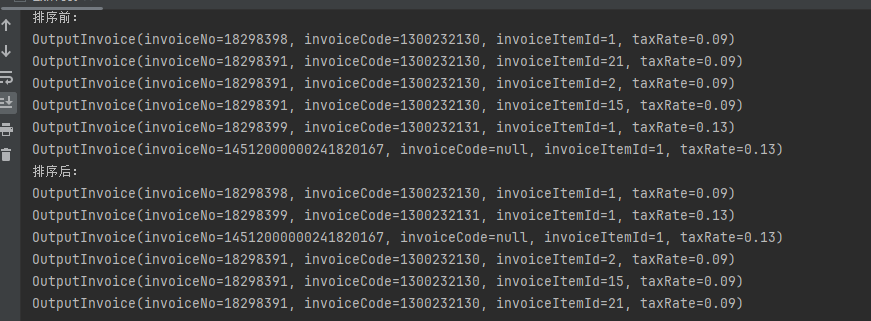
public static void main(String[] args) { OutputInvoice outputInvoice = new OutputInvoice(); OutputInvoice outputInvoice2 = new OutputInvoice(); OutputInvoice outputInvoice3 = new OutputInvoice(); OutputInvoice outputInvoice4 = new OutputInvoice(); OutputInvoice outputInvoice5 = new OutputInvoice(); OutputInvoice outputInvoice6 = new OutputInvoice(); outputInvoice.setInvoiceCode("1300232130").setInvoiceNo("18298398").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("1"); outputInvoice2.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("21"); outputInvoice3.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("2"); outputInvoice4.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("15"); outputInvoice5.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice6.setInvoiceNo("14512000000241820167").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); List<OutputInvoice> list = new ArrayList<>(); list.add(outputInvoice); list.add(outputInvoice2); list.add(outputInvoice3); list.add(outputInvoice4); list.add(outputInvoice5); list.add(outputInvoice6); System.out.println("排序前:"); list.stream().forEach(System.out::println); //根据发票号码排序 List<OutputInvoice> sortList = list.stream() .sorted(Comparator.comparing(OutputInvoice::getInvoiceNo)).collect(Collectors.toList()); System.out.println("排序后:"); sortList.stream().forEach(System.out::println); }
排序结果如下:

其中 java.util.Comparator 的comparing()方法,默认是按升序排序,降序时采用reverseOrder()方法即可
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceNo, Comparator.reverseOrder())).collect(Collectors.toList());
上述只是对一个字段进行排序,如果需要对多个字段进行排序,需要使用组合排序
②【多字段排序,null处理】根据发票代码、发票号码 升序排序
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceCode).thenComparing(OutputInvoice::getInvoiceNo)).collect(Collectors.toList());
运行时却发现报了空指针异常,其实代码看起来没问题,问题出在哪里?
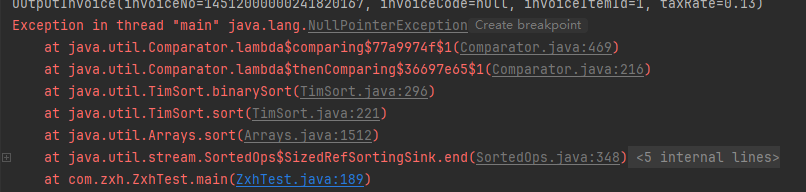
实际上如果排序字段有null值对于排序就会报错,所以需要对排序的可能为空的字段进行为空的处理(空值排在前、排在后),其提供了两种方式
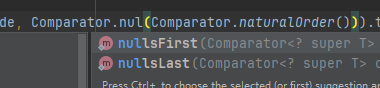
这里就视为把空值排在后,这样就不会报错了
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceCode, Comparator.nullsLast(Comparator.naturalOrder()))
.thenComparing(OutputInvoice::getInvoiceNo)).collect(Collectors.toList());
③【字符串排序】根据发票发票明细行 升序排序
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceItemId)).collect(Collectors.toList());
排序结果如下

为什么排序看似没生效?其实不是没生效,而是排序的字段是数字字符串,这样直接按常规的默认排序就会导致排序错乱。看其源码,发现对于字符串类型是排序,是按字符进行排序,那么对于数字类型,就会出现问题。
解决方案很简单,排序时指定排序的方法即可,这里按照double的方式排序(推荐)
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceItemId, Comparator.comparingDouble(Double::parseDouble))).collect(Collectors.toList());
排序结果就符合要求了
那么现在如果还需求对明细行进行空值的处理,应该怎么办?由于comparing()方法 只有两个参数,不能同时指定,那该怎么做?
其实 Comparator.nullsLast()的参数是 Comparator ,只不过上面我们指定的是 Comparator.naturalOrder(),既然不能直接使用,那就手动撸码
List<OutputInvoice> sortList = list.stream()
.sorted(Comparator.comparing(OutputInvoice::getInvoiceItemId, Comparator.nullsLast(Comparator.comparing(s -> { if (s == null) { return null; } return Double.parseDouble(s); })))).collect(Collectors.toList());
手动去处理。那么对于这种排序,建议封装为工具类进行处理
7.Collectors.toMap-判断集合元素是否重复
主要使用 Stream API和 Collectors.toMap判断重复的数据
①Collectors.toMap的用法
是 Java 8 中 java.util.stream.Collectors 类提供的一个非常有用的收集器,用于将流中的元素收集到一个 Map 中。它提供了一种简洁而强大的方式,将流中的元素通过映射函数转换为 Map 的键和值,并将这些键值对存储在 Map 中。
方法如下:
public static <T, K, U> Collector<T,?, Map<K,U>> toMap(Function<? super T,? extends K> keyMapper,
Function<? super T,? extends U> valueMapper,
BinaryOperator<U> mergeFunction)
是不是看着一脸懵逼,下面通过示例来说明:
import java.util.Arrays; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class ToMapExample { public static void main(String[] args) { List<String> fruits = Arrays.asList("apple", "banana", "cherry", "apple"); // 使用 Collectors.toMap 将列表元素收集到 Map 中 Map<String, Integer> fruitLengthMap = fruits.stream() .collect(Collectors.toMap( // 键映射函数:将水果名称作为键 fruit -> fruit, // 值映射函数:将水果名称的长度作为值 fruit -> fruit.length(), // 冲突解决函数:如果键冲突,保留旧值 (existingValue, newValue) -> existingValue) ); // 输出结果 fruitLengthMap.forEach((key, value) -> System.out.println(key + " -> " + value)); } }
其中对象如下:
package com.zxh.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.experimental.Accessors; import java.math.BigDecimal; /** * 销项发票实体 * @Author zxh * @Date 2025/1/3 星期五 */ @AllArgsConstructor @NoArgsConstructor @Data @Accessors(chain = true) public class OutputInvoice { /** * 发票号码 */ private String invoiceNo; /** * 发票代码 */ private String invoiceCode; /** * 发票明细行 */ private String invoiceItemId; /** * 税率 两位小数 */ private BigDecimal taxRate; /** * 开票金额(不含税) 两位小数 */ private BigDecimal invoiceAmount; /** * 发票税额 两位小数 */ private BigDecimal invoiceTax; /** * 价税合计 两位小数 */ private BigDecimal priceTaxTotal; }
②按单个属性判断
例如:按发票号码判断
OutputInvoice outputInvoice = new OutputInvoice(); OutputInvoice outputInvoice2 = new OutputInvoice(); OutputInvoice outputInvoice3 = new OutputInvoice(); OutputInvoice outputInvoice4 = new OutputInvoice(); OutputInvoice outputInvoice5 = new OutputInvoice(); OutputInvoice outputInvoice6 = new OutputInvoice(); OutputInvoice outputInvoice7 = new OutputInvoice(); outputInvoice.setInvoiceCode("1300232130").setInvoiceNo("18298398").setTaxRate(new BigDecimal("0.09")); outputInvoice2.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("21"); outputInvoice3.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("2"); outputInvoice4.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("15"); outputInvoice5.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice6.setInvoiceNo("14512000000241820167").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice7.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("2"); List<OutputInvoice> list = new ArrayList<>(); list.add(outputInvoice); list.add(outputInvoice2); list.add(outputInvoice3); list.add(outputInvoice4); list.add(outputInvoice5); list.add(outputInvoice6); list.add(outputInvoice7); //判断是否有相同的发票号码 List<String> duplicateList = list.stream().collect(Collectors.groupingBy(OutputInvoice::getInvoiceNo, Collectors.counting()))
.entrySet().stream() .filter(entry -> entry.getValue() > 1) .map(Map.Entry::getKey) .collect(Collectors.toList()); if (CollectionUtil.isNotEmpty(duplicateList)) { duplicateList.stream().forEach(System.out::println); }
执行结果
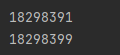
可以看出,其原理是按单个属性进项分组,判断分组后集合的数量
③按多个属性判断
例如:按发票号码,代码,税率,明细行判断
OutputInvoice outputInvoice = new OutputInvoice(); OutputInvoice outputInvoice2 = new OutputInvoice(); OutputInvoice outputInvoice3 = new OutputInvoice(); OutputInvoice outputInvoice4 = new OutputInvoice(); OutputInvoice outputInvoice5 = new OutputInvoice(); OutputInvoice outputInvoice6 = new OutputInvoice(); OutputInvoice outputInvoice7 = new OutputInvoice(); outputInvoice.setInvoiceCode("1300232130").setInvoiceNo("18298398").setTaxRate(new BigDecimal("0.09")); outputInvoice2.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("21"); outputInvoice3.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("2"); outputInvoice4.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("15"); outputInvoice5.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice6.setInvoiceNo("14512000000241820167").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice7.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("2"); List<OutputInvoice> list = new ArrayList<>(); list.add(outputInvoice); list.add(outputInvoice2); list.add(outputInvoice3); list.add(outputInvoice4); list.add(outputInvoice5); list.add(outputInvoice6); list.add(outputInvoice7); list.add(outputInvoice7); //判断是否有相同的发票,按号码,代码,税率,明细行 Map<String, Long> duplicateInvoiceNo = list.stream() .collect(Collectors.toMap(p -> p.getInvoiceNo() + p.getInvoiceCode() + p.getTaxRate() + p.getInvoiceItemId(), p->1L, Long::sum)); if (duplicateInvoiceNo.values().stream().anyMatch(count -> count > 1)) { System.out.println("有相同的发票信息"); }else{ System.out.println("无相同的发票信息"); }
这里我们把某一个发票重新加了一次,就有重复的发票信息。根据上述toMap的原理后,那么这代码逻辑就是将其按某些属性拼接后转为map,其中key是拼接的属性值,value是出现的次数(p->1L将每个元素映射为1L,然后Long::sum是一个 mergeFunction,当遇到相同键时,将对应的值相加。),然后判断出现的个数是否超过1即可。
8.Collectors.toMap-集合对象元素去重
对于字符串类型的集合,去重很简单,详见字符串去重。而如果是对象,按某些属性去重,方式有两种:
①重写equals与hashCode
A.利用set集合特性保持顺序一致去重
public static void main(String[] args) { List<User> list = new ArrayList<>(); list.add(new User(1, "admin", "15623635555")); list.add(new User(2, "zhailiu", "15623635555")); list.add(new User(3, "lisi", "15623635566")); list.add(new User(1, "admin", "15623635775")); list.add(new User(3, "zhangsan", "15623621455")); list.add(new User(1, "zhangsan", "15623635555")); list = new ArrayList<>(new LinkedHashSet<>(list)); }
其中User对象如下:
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.util.Objects; @Data @AllArgsConstructor @NoArgsConstructor public class User { private Integer id; private String name; private String phone; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; User user = (User) o; return Objects.equals(id, user.id) && Objects.equals(phone, user.phone); } @Override public int hashCode() { return Objects.hash(id, phone); } }
需要注意的是,使用这种方式,必须重写equals与hashCode方法。在里面指定需要去重的属性,可以是一个,也可以是多个。这里是以id和phone进行去重。
B.使用Java8特性去重
public static void main(String[] args) { List<User> list = new ArrayList<>(); list.add(new User(1, "admin", "15623635555")); list.add(new User(2, "zhailiu", "15623635555")); list.add(new User(3, "lisi", "15623635566")); list.add(new User(1, "admin", "15623635775")); list.add(new User(3, "zhangsan", "15623621455")); list.add(new User(1, "zhangsan", "15623635555")); list = list.stream().distinct().collect(Collectors.toList()); }
前提是重写对象的equals与hashCode方法。
②使用 Stream API和 Collectors.toMap去重
其中对象如下:
package com.zxh.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.experimental.Accessors; import java.math.BigDecimal; /** * 销项发票实体 * @Author zxh * @Date 2025/1/3 星期五 */ @AllArgsConstructor @NoArgsConstructor @Data @Accessors(chain = true) public class OutputInvoice { /** * 发票号码 */ private String invoiceNo; /** * 发票代码 */ private String invoiceCode; /** * 发票明细行 */ private String invoiceItemId; /** * 税率 两位小数 */ private BigDecimal taxRate; /** * 开票金额(不含税) 两位小数 */ private BigDecimal invoiceAmount; /** * 发票税额 两位小数 */ private BigDecimal invoiceTax; /** * 价税合计 两位小数 */ private BigDecimal priceTaxTotal; }
A.按单个属性去重
例如:按发票号码去重
OutputInvoice outputInvoice = new OutputInvoice(); OutputInvoice outputInvoice2 = new OutputInvoice(); OutputInvoice outputInvoice3 = new OutputInvoice(); OutputInvoice outputInvoice4 = new OutputInvoice(); OutputInvoice outputInvoice5 = new OutputInvoice(); OutputInvoice outputInvoice6 = new OutputInvoice(); OutputInvoice outputInvoice7 = new OutputInvoice(); outputInvoice.setInvoiceCode("1300232130").setInvoiceNo("18298398").setTaxRate(new BigDecimal("0.09")); outputInvoice2.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("21"); outputInvoice3.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("2"); outputInvoice4.setInvoiceCode("1300232130").setInvoiceNo("18298391").setTaxRate(new BigDecimal("0.09")).setInvoiceItemId("15"); outputInvoice5.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice6.setInvoiceNo("14512000000241820167").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("1"); outputInvoice7.setInvoiceCode("1300232131").setInvoiceNo("18298399").setTaxRate(new BigDecimal("0.13")).setInvoiceItemId("2"); List<OutputInvoice> list = new ArrayList<>(); list.add(outputInvoice); list.add(outputInvoice2); list.add(outputInvoice3); list.add(outputInvoice4); list.add(outputInvoice5); list.add(outputInvoice6); list.add(outputInvoice7); System.out.println("去重前:"); list.stream().forEach(System.out::println); //根据发票号码,代码,税率,明细行去重 List<OutputInvoice> newList = list.stream().collect(Collectors.toMap( p -> p.getInvoiceNo(), //也可使用 OutputInvoice::getInvoiceNo,单个参数时二者选一 // OutputInvoice::getInvoiceNo, Function.identity(), (existing, replacement) -> existing )).values().stream().collect(Collectors.toList()); System.out.println("去重后:"); newList.stream().forEach(System.out::println);
执行结果如下,其实这里就是将发票号码作为key,使用默认的唯一值作为value,重复的值则不做处理,然后把map的value转为list
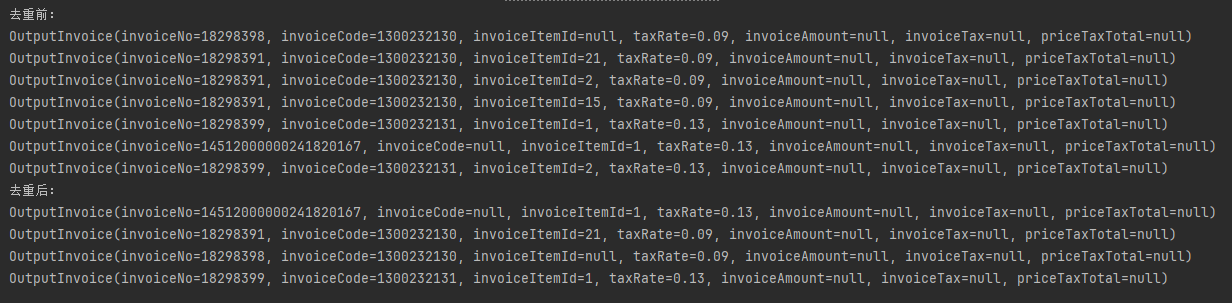
B.按多个属性去重
例如:按发票号码,代码,税率,明细行 去重
List<OutputInvoice> newList = list.stream().collect(Collectors.toMap( p -> p.getInvoiceNo() + p.getInvoiceCode() + p.getTaxRate() + p.getInvoiceItemId(), Function.identity(), (existing, replacement) -> existing )).values().stream().collect(Collectors.toList());
其实可以看出,和上述单个参数去重没太大差别,只是使用toMap时的key不一样。
9.flatMap-元素合并
它可以将流中的每个元素映射为一个流,然后将这些新生成的流合并(扁平化)成一个新的流。
<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper)
示例代码:
List<List<String>> listOfLists = Arrays.asList( Arrays.asList("apple", "banana"), Arrays.asList("cherry", "date"), Arrays.asList("elderberry") ); // 使用 flatMap 将嵌套的列表扁平化为一个列表 List<String> flattenedList = listOfLists.stream() .flatMap(List::stream) .collect(Collectors.toList()); System.out.println(flattenedList);
执行结果
[apple, banana, cherry, date, elderberry]
可以看出,其实flatMap就是将嵌套的list合并为一个list,在业务场景中很实用,比如下面的示例:
对象实体如下
package com.zxh.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.experimental.Accessors; import java.math.BigDecimal; import java.util.List; import java.util.Map; /** * 销项发票实体 * @Author zxh * @Date 2025/1/3 星期五 */ @AllArgsConstructor @NoArgsConstructor @Data @Accessors(chain = true) public class OutputInvoice { /** * 发票号码 */ private String invoiceNo; /** * 发票代码 */ private String invoiceCode; /** * 发票明细行 */ private String invoiceItemId; /** * 税率 两位小数 */ private BigDecimal taxRate; /** * 发票明细信息 */ private List<Map> detailList; }
现在有一个发票集合,需要获取对所有发票的明细信息,那么flatMap就需要出来站队了,比较用起来很简单,不再使用很low的for循环来合并
OutputInvoice outputInvoice = new OutputInvoice(); OutputInvoice outputInvoice2 = new OutputInvoice(); OutputInvoice outputInvoice3 = new OutputInvoice(); outputInvoice.setInvoiceCode("1300232130").setInvoiceNo("18298398").setDetailList(new ArrayList<>(Arrays.asList(new HashMap()))); outputInvoice2.setInvoiceCode("1300232130").setInvoiceNo("18298391").setDetailList(new ArrayList<>(Arrays.asList(new HashMap()))); outputInvoice3.setInvoiceCode("1300232130").setInvoiceNo("18298391").setDetailList(new ArrayList<>(Arrays.asList(new HashMap()))); List<OutputInvoice> list = new ArrayList<>(); list.add(outputInvoice); list.add(outputInvoice2); list.add(outputInvoice3); // 获取所有的明细列表 List<Map> allDetailList = list.stream().map(OutputInvoice::getDetailList) .flatMap(List::stream) .collect(Collectors.toList()); System.out.println(allDetailList);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号