K折交叉验证
2019-06-01 20:59 zYaMei 阅读(12029) 评论(1) 收藏 举报交叉验证的思想
交叉验证主要用于防止模型过于复杂而引起的过拟合,是一种评价训练数据的数据集泛化能力的统计方法。其基本思想是将原始数据进行划分,分成训练集和测试集,训练集用来对模型进行训练,测试集用来测试训练得到的模型,以此来作为模型的评价指标。
简单的交叉验证
将原始数据D按比例划分,比如7:3,从D中随机选择70%的数据作为训练集train_data,剩余的作为测试集test_data(绿色部分)。如下图所示,这里的数据都只利用了一次,并没有充分利用,对于小数据集,需要充分利用其数据的信息来训练模型,一般会选择K折交叉验证。

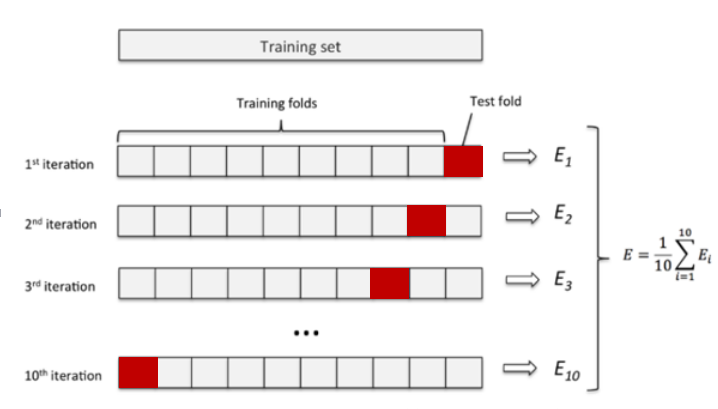
K折交叉验证
将原始数据D随机分成K份,每次选择(K-1)份作为训练集,剩余的1份(红色部分)作为测试集。交叉验证重复K次,取K次准确率的平均值作为最终模型的评价指标。过程如下图所示,它可以有效避免过拟合和欠拟合状态的发生,K值的选择根据实际情况调节。
python实现
使用scikit-learn模块中的方法KFold,示例如下:
1 from sklearn.model_selection import KFold 2 import numpy as np 3 x = np.array(['B', 'H', 'L', 'O', 'K', 'P', 'W', 'G']) 4 kf = KFold(n_splits=2) 5 d = kf.split(x) 6 for train_idx, test_idx in d: 7 train_data = x[train_idx] 8 test_data = x[test_idx] 9 print('train_idx:{}, train_data:{}'.format(train_idx, train_data)) 10 print('test_idx:{}, test_data:{}'.format(test_idx, test_data)) 11 12 # train_idx:[4 5 6 7], train_data:['K' 'P' 'W' 'G'] 13 # test_idx:[0 1 2 3], test_data:['B' 'H' 'L' 'O'] 14 # train_idx:[0 1 2 3], train_data:['B' 'H' 'L' 'O'] 15 # test_idx:[4 5 6 7], test_data:['K' 'P' 'W' 'G']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号