
Spark中的Wordcount
通过scala语言基于local编写spark的Wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// Spark配置文件对象
val conf: SparkConf = new SparkConf()
// 设置Spark程序的名字
conf.setAppName("WordCount")
// 设置运行模式为local模式 即在idea本地运行
// local : 一个并行度
// local[2] : 两个并行度
// local[*] : 有多少用多少
conf.setMaster("local")
// Spark的上下文环境,相当于Spark的入口
val sc: SparkContext = new SparkContext(conf)
// 词频统计
// 1、读取文件
/**
* RDD : 弹性分布式数据集(可以先当成scala中的集合去使用)
*/
val linesRDD: RDD[String] = sc.textFile("scala/data/words.txt")
// 2、将每一行的单词切分出来
// flatMap: 在Spark中称为 算子
// 算子一般情况下都会返回另外一个新的RDD
val wordsRDD: RDD[String] = linesRDD.flatMap(kv=>kv.split(","))
// 3、按照单词分组
val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(kv=>kv)
// 4、统计每个单词的数量
val countRDD: RDD[String] = groupRDD.map(kv => {
val key: String = kv._1
val values: Iterable[String] = kv._2
// words.size直接获取迭代器的大小
// 因为相同分组的所有的单词都会到迭代器中
// 所以迭代器的大小就是单词的数量
val size: Int = values.size
key + "," + size
})
countRDD.saveAsTextFile("spark/data/wordcount.txt")
}
}

会报这个错
解决方案:
新建一个文件夹,放入这个文件

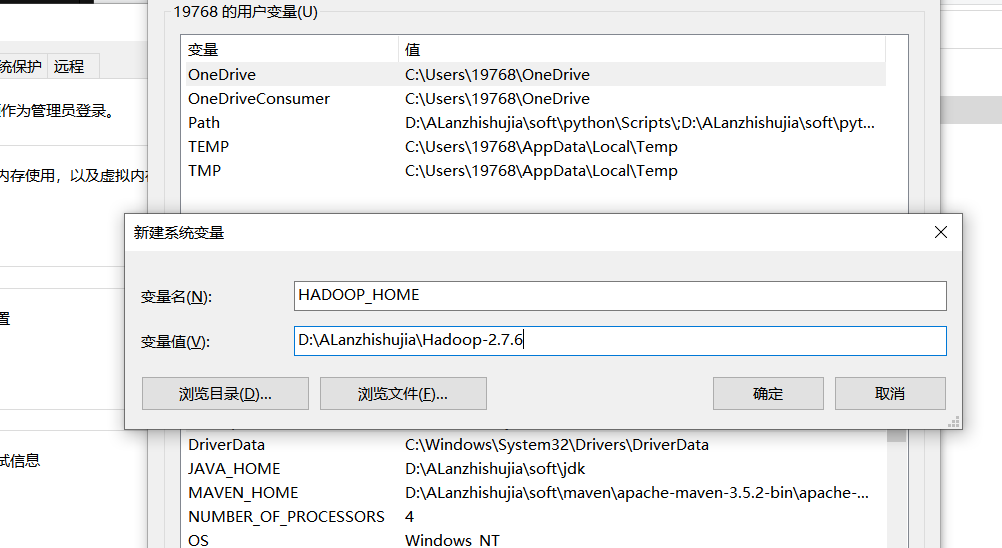
配置环境变量
需要导入的依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
基于yarn去调度WordCount
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 1、去除setMaster("local")
* 2、修改文件的输入输出路径(因为提交到集群默认是从HDFS获取数据,需要改成HDFS中的路径)
* 3、在HDFS中创建目录
* hdfs dfs -mkdir -p /spark/data/words/
* 4、将数据上传至HDFS
* hdfs dfs -put words.txt /spark/data/words/
* 5、将程序打成jar包
* 6、将jar包上传至虚拟机,然后通过spark-submit提交任务
* spark-submit --class WordCount2 --master yarn-client spark-1.0.jar
* spark-submit --class WordCount2 --master yarn-cluster spark-1.0.jar
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount2")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("/spark/data/words")
val wordsRDD: RDD[String] = linesRDD.flatMap(s=>s.split(","))
val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(s=>s)
val resRDD: RDD[String] = groupRDD.map(kv => {
kv._1 + "," + kv._2.size
})
// 使用HDFS的JAVA API判断输出路径是否已经存在,存在即删除
val conff: Configuration = new Configuration()
// core-site.xml
conff.set("fs.defaultFS", "hdfs://master:9000")
val sys = FileSystem.get(conff)
if (sys.exists(new Path("/spark/data/wordcount"))){
sys.delete(new Path("/spark/data/wordcount"),true)
}
resRDD.saveAsTextFile("/spark/data/wordcount")
}
}
打成jar包去运行
默认会有两个分区Task

可以通过sc.textFile(Path,分区个数)
on yarn的两种模式
yarn client模式:driverzai当前提交任务的节点上,可以打印任务运行的日志信息,而
yarn cluster模式:driver在AppMaster所有节点上,分布式分配,不能再提交任务的本机打印日志信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号