
Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
(1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上生命周期最长的一个分支,CDH3、CDH4虽然包含了0.21和0.22分支的新功能和补丁,但都是基于此分支。
(2)0.20- append:020- append支持HDFS追加,由于该功能被认为是一个不稳定的潜在因素,所以它被单独新开了一个分支,并且没有任何新的 Hadoop的正式版基于此分支发布。
(3)0.20- ecurity:该分支基于020并支持 Kerberos认证。
(4)0.20.203~0.20.205:这些版本包括了 Security分支所带功能,并且还包括错误修复和020分支的线上开发的改进。
(5)0.21.0:0.21是一个预研性质的版本,目的是强调那段时间开发的一些新功能,没有Security功能,但有 Append功能,不建议部署在生产环境。
(6)0.22.0:0.22.0包括HDFS的安全功能,并且更新不大
(7)0.23.0:在2011年11月, Hadoop023发布了,包括了 Append、 Security、YARN和HDFS Federation功能,该版本被认为是20.0的预览版本。
(8)1.0.0:1.0.0版本是基于0.20.205版本发布,包括了 Security功能,是一个值得部署的稳定版本。但是从上面可以看出,1.0.0并不是包含了所有分支
(9)2.0.0:2012年5月,基于0.23.0分支的20.0版本发布,它包含了YARN,但移除了MRvl,兼容了MRv1的API,但底层实现有明显不同,需要经过大量测试才能被用于生产环境。CDH4是基于此版本,但CDH4还提供了MRv1的实现。
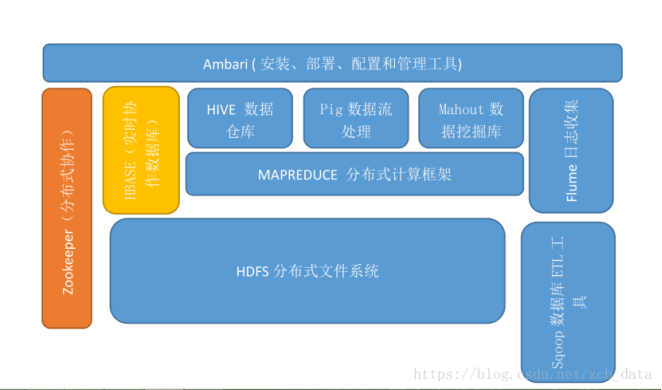
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
(1)HDFS(hadoop分布式文件系统):是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
(2)Mapreduce(分布式计算框架):mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
(3)HBase(分布式列存数据库):HBase是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。HBase是针对谷歌BigTable的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase与传统关系数据库的一个重要区别是,前者釆用基于列的存储,而后者采用基于行的存储。HBase具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来增加存储能力。
(4)Hive(基于hadoop的数据仓库):Hive是—个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储。Hive的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言——HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以将HiveQL语句转换为MapReduce任务进行运行,而不必开发专门的MapReduce应用,因而十分适合数据仓库的统计分析。
(5)Pig(基于hadoop的数据流系统):Pig是一种数据流语言和运行环境,适合于使用HadooP和MapReduce平台来查询大型半结构化数据集。虽然MapReduce应用程序的编写不是十分复杂,但毕竟也是需要一定的开发经验的。Pig的出现大大简化了Hadoop常见的工作任务,它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近结构化査询语言的接口。
(6)Mahout(数据挖掘算法库):Mahout是Apache软件基金会旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序:Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用ApacheHadoop库,Mahout可以有效地扩展到云中。
(7)Zookeeper(分布式协作服务):Zookeeper是针对谷歌Chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务,用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
(8)Flume(日志收集工具):Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于数据收集;同时,Flume提供对数据进行简单处理并写到各种数据接受方的能力。
(9)Sqoop(数据同步工具):Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据的互操作性。通过Sqoop可以方便地将数据从MySQL、Oracle.PostgreSQL等关系数据库中导人Hadoop(可以导人HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。Sqoop主要通过JDBC(JavaDataBaseConnectivity湘关系数据库进行交互,理论上,支持JDBC的关系数据库都可以使Sqoop和Hadoop进行数据交互。Sqoop是专门为大数据集设计的,支持增量更新,可以将新记录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。
(10)Ambari(安装、部署、配置和管理工具):ApacheAmbari是一种基于Web的工具,支持ApacheHadoop集群的安装、部署、配置和管理。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
(一)、hadoop安装及注意事项
(1)安装hadoop的环境,必须在你的系统中有java的环境。
(2)必须安装ssh,有的系统默认就安装,如果没有安装需要手动安装,可以用yum install -y ssh 或者 rpm -ivh ssh的rpm包进行安装。
(二)、安装并配置java环境
(1)进入选择相应的rpm包或者tar包,进行安装。
(2)检查java环境是否安装成功。
(三)、下载并安装hadoop
(1)进入hadoop的官网进行下载相应hadoop的版本。
地址为:http://hadoop.apache.org/releases.html
a.下载相应的tar包技术分享
b.进行tar解包
c.修改相应的配置文件信息,制定相应的java_home
d.配置hadoop的环境变量(使hadoop的命令加到path中,就可以使用hadoop的相关命令)
(2)编辑/etc/profile文件,在文件的后面加上如下代码:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.1
PATH=$HADOOP_HOME\bin:$PATH
export HADOOP_HOME PATH
(3)使修改的文件生效
source /etc/profile
这样就可以进入hadoop的安装目录去进行相关的命令操作了!
4.评估华为hadoop发行版本的特点与可用性。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号